
基于XGBoost 的航班延误预测
2020-11-02 07:59庄刚强王欣
现代计算机 2020年27期
庄刚强,王欣
(中国民用航空飞行学院计算机学院,广汉 618307)
0 引言
根据《2019 年全球机场&航空公司准点率报告》显示,2019 年中国大陆地区机场实际出港航班量达480.23 万架次,出港延误率达到了24.43%,起飞平均延误时长达到28.11 分钟,由于飞机延误问题长期困扰着旅客,不正常航班也成为消费者投诉最多的服务类型。查阅中国民航局“月度消费者投诉通报”发现,2019 年1-10 月份航空运输消费者投诉类型中,排名前三位的分别为:不正常航班服务、票务服务和行李服务,尽管不同月份投诉件数和占比有差别,但不正常航班服务的投诉比例始终在50%左右浮动。因此航班延误预测可以对航班动态的掌握,提前做好相关应急措施,从而减少不利影响。
在目前航班延误研究分析中,文献[1]结合航班数据的特点构建了基于C4.5 决策树的航班延误预测模型,对国内某大型机场的真实数据集,该研究设计了大量实验,实验结果表明所提模型正确率接近80%。文献[2,3]采用支持向量机回归方法建立航班到港延误预测模型,实验结果表明,能够有效预测航班延误。文献[4]从某个枢纽机场航班延误出发,对其关联机场的衔接航班的延误影响进行分析,提出了基于贝叶斯网络的航班延误传播模型,实验表明所提出的方法能有效地分析航班延误从局部到全局的传播。文献[5]针对航班延误预测数据量大、特征提取困难而传统算法处理能力有限的问题,提出一种基于双通道卷积神经网络(DCNN)的航班延误预测模型,实验结果表明准确率达到92.1%。文献[6]考虑对机场中长期航班延误的预测需求,以时间序列预测算法为基础,选择建立ARIMA模型,实验结果表明,模型对机场中长期航班延误预测有良好的效果。文献[7]介绍了一种新的多层输入层神经网络算法,该方法应用于预测在肯尼迪机场延误的航班,与传统的梯度下降反向传播神经网络模型进行了比较,所提出的模型在预测误差(均方根误差)和训练神经网络模型所需的时间方面都优于传统的反向传播方法。
在本次研究中,选择极限梯度提升算法XGBoost来进行航班延误预测,基于树模型的XGBoost 在训练样本有限、训练时间短、调参具有独特优势。在代价函数中加入了正则项,用于控制模型的复杂度;支持并行处理和支持用户自定义目标函数和评估函数,灵活性高;具有缺失值自动处理能力;内置交叉验证,可以很方便的获取最优迭代次数。相比于近年流行的神经网络能够更好的处理表格数据,并具有更强的可解释性,另外具有易于调参、输入数据不变等优势。本文首先介绍了XGBoost 算法,然后基于该算法构建了航班延误预测模型,对模型所用到的实验数据集进行预处理和特征工程。实验分析部分,为了实现对原XGBoost模型的改进,通过网格搜索与交叉验证相结合的方法实现模型的参数优化。实验结果表明,与GBDT 与随机森林两种预测模型相比,XGBoost 模型预测更加准确,拟合优度更好,可以为航班延误预测研究提供有价值的参考。
1 基于XGBoost的航班延误预测
1.1 XGBBoooosstt算法介绍
XGBoost 全名叫(eXtreme Gradient Boosting)极端梯度提升,是对梯度提升算法的改进。对于XGBoost的预测模型可以表示为:
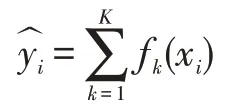
其中K 为树的总个数,fk表示第k 颗树,表示样本xi的预测结果。
XGBoost 是实现了模型表现和运算速度的平衡算法,它引入了模型的复杂度来衡量算法的运算效率,以此来防止模型过拟合。XGBoost 的目标函数被写作:传统的损失函数+模型复杂度。

其中i 代表数据集中的第i 个样本,m 表示导入第k 棵树的数据总量,K 表示建立的所有树的数目,式子中第一项代表传统的损失函数,衡量真实标签yi与预测值之间的差异,通常是调节后的均方误差RMSE。第二项代表模型的复杂度,使用树模型的某种变换Ω 表示,这个变化代表了一个从树模型的结构来衡量树模型的复杂度式子,可以表示如下所示。

其中γ和λ为人工设置的参数,T 为叶子总数,w为叶子节点的分值为 w 的 L2 模平方。
1.2 航班延误预测模型构建
航班延误预测的大致流程首先对数据进行预处理,采用嵌入法对特征进行选择,剔除对模型预测准确度用无用的特征,将选择之后的数据集作为最终模型的输入数据集,对数据集进行划分为训练集和测试集两部分,采用网格搜索与交叉验证相结合的方法实现模型的参数优化得到最优参数值组合,使用XGBoost算法对训练集进行训练生成模型再用测试集进行预测,具体流程如图1 所示。

图1 基于XGBoost的航班延误预测流程
2 航班延误影响因素及特征选择
2.1 航班延误影响因素
目前航班延误的主要原因有4 种:一是由于天气,自然灾害等不可抗拒的原因造成的,往往每年的七八月份是航班延误的高发季节;二是空管部门为了保证航空安全,采取航班流量控制;三是由于航空公司自身原因造成的;四是由于旅客原因,比如迟到之类。以上这四大原因中,恶劣的气象条件造成航班延误的占70%;空中交通管制造成航班延误的占15%;由旅客自身原因造成航班延误的占5%;由航空公司本身原因造成的航班延误占10%左右。
2.2 数据预处理
本文研究所用的数据是所有数据文件均从OST 网站下载,该网站存储了1987 年至今的航班准点数据,本文选取了2018 年一整年的美国航班数据作为实验,由于数据量过于庞大,筛选了其中由亚特兰哈兹菲尔德-杰克逊机场(ATL)为出发机场,芝加哥奥黑尔际机场(ORD)、肯尼迪际机场(JFK)、洛杉矶际机场(LAX)、旧金山际机场(SFO)、西雅图际机场或西雅图∕塔科马机场(SEA)为目的地的样本数据23665 条,每条样本包含了航班日期、航空公司代码、出发及目的机场代码、计划出港时间、实际出港时间、起始机场距离、计划到港时间、实际到港时间等27 个特征。考虑到月份为天气影响的重要特征,对于航班日期的文本数据拆分并转换为年月日的数值型。
(1)缺失值处理
通过检查数据发现包含缺失值为计划进出港时间与实际进出港时间相等时,进出港延时为空值缺失,因此采用0 填补缺失值,进港滑行时间的空值采用中位数填补。对于其他含有缺失值的样本,由于占比非常少便直接删除含有空值的样本。
(2)数据编码及转换
对于航空公司代码等非数值型的数据需要进行编码,本次样本中包含了15 个航空公司,其中有些是廉价航空,不同的航空公司的延误率是不一样的,往往廉价航空的延误率较高。因此航空公司的代码有序变量需要进行编码,于是将航空公司的延误率按从小到大的顺序进行排列,并将样本中的航空公司代码替换为1到15 即可。
2.3 特征选择
特征选择有助于我们发现感兴趣的输出结果的特征,如果特征中包含有无关的特征属性,就会降低算法的准确度。嵌入法是一种让算法决定使用那些特征的方法,即特征选择和算法训练同时进行。先使用XGBoost 模型进行训练后,得到各个特征的权值系数,而权值系数往往代表了特征对于模型的某种贡献程度或者重要性,XGBoost 算法中feature_importance 属性可以列出各个特征的对树建立的贡献,在sklearn 中使用SelectFromModel 方法设定阈值参数,对于低于该阈值的特征则认为该特征不重要,本次实验设置的阈值为0.0009,最后选择的特征如表1 所示。
3 实验及结果分析
XGBoost 算法是通过在数据上构建多个弱评估器,然后汇总所有弱评估器的建模结果的集成算法,算法模型中有多种超参数,为了找到最佳的参数组合采用了网格搜索交叉验证的方法。网格搜索是指定参数的一种穷举搜索方法,将各个参数可能的取值进行排列组合,列出所有可能的组合结果,然后将各组合用于XGBoost 训练,并使用交叉验证对表现进行评估[8]。在拟合函数尝试了所有的参数组合后,返回一个合适的分类器,自动调整至最佳参数组合,通过best_params_获得参数值。首先根据网格搜索的原理,将需要的超参数值设定区间范围,然后不断地训练模型,通过评分函数对每个超参数值进行打分并选择得分最高的参数值,最后得到所有最优参数组合。在scikit-learn 中使用GridSearchCV 来实现对参数的调整与评估,从而得到最优参数如表2 所示。

表1 特征字段解释说明

表2 最优参数值
将处理后的数据样本划分为70%为训练样本集,30%划分为测试样本集。使用构建的模型对训练样本集进行训练,对测试集进行预测得到R-Squared 为0.9805106,平均绝对误差为4.09 分钟,均方根误差为6.77 分钟。得到最后真实值与预测值的对比如图2所示。

图2 基于XGBoost的航班延误预测
最后采用相同的样本数据集使用了GBDT 算法、随机森林算法预测,并通过R-Squared、平均绝对误差(MAE)以及均方根误差(RMSE)与本文的XGBoost 算法进行对比如表3。其中R-Squared 越接近1,代表预测值越接近真实值;MAE 值能更好地反映预测值误差的实际情况,RMSE 是用来衡量观测值同真实值之间的偏差。结果显示本文的XGBoost 算法模型的RMSE 为6.77 最小,说明XGBoost 预测值偏差最小,预测精度最高。

表3 算法结果的对比
4 结语
本文提出了基于XGBoost 集成算法的航班延误预测模型,首先分析了航班延误预测的影响因素,对美国的亚特兰哈兹菲尔德-杰克逊机场(ATL)飞往芝加哥奥黑尔际机场(ORD)等五大国际机场2018 年全年的航班数据进行预处理和特征工程,采用网格搜索与交叉验证相结合的方法实现模型的参数优化,通过随机抽样把数据分为训练集与测试集,最后在测试集上进行预测,结果显示R-Squared 为0.9805106,平均绝对误差(MAE)为 4.09 分钟,均方根误差(RMSE)为 6.77分钟。相比于GBDT、随机森林算法,改进的XGBoost算法在R-Squared、MAE、RMSE 指标方面均优于比较算法,表现出较高的预测精度。考虑到对航班延误的影响因素众多,本文的模型还有较大优化空间,例如对于数据集中加入天气的详细数据,法定节假日信息等特征以及增加航班数据样本量来进一步提高算法模型预测精度。
猜你喜欢
金桥(2021年10期)2021-11-05
金桥(2021年9期)2021-11-02
金桥(2021年8期)2021-08-23
金桥(2021年7期)2021-07-22
大飞机(2021年4期)2021-07-19
伙伴(2020年1期)2020-02-14
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
