
面向不平衡数据集的一种基于SMOTE的集成学习算法
2020-10-28 09:00杨毅,梅颖
丽水学院学报 2020年5期
杨 毅,梅 颖
(丽水学院工学院,浙江丽水323000)
0 引言
不平衡数据集广泛地存在于实际生活中,如医疗诊断、垃圾邮件过滤、卫星图像中的石油泄漏等。不平衡数据集是相对于平衡数据集而言的,指的是数据集的类别分布相差很大。
通常,样本数目多的类别称为多数类,样本数目少的类别称为少数类。分类器往往会因为数据的不平衡性而无法满足分类的要求,因此在构建分类模型前,需要对不平衡数据集进行预处理[1-2]。
目前,处理不平衡数据集的分类问题主要分两类。一类是从训练集入手,改变训练样本的分布,改善数据集的不平衡性。另一类是从学习算法入手,标准的分类算法在处理不平衡问题时存在缺陷,分类结果会错误地倾向于多数类样本,因此需要适当调整算法使之适用于不平衡数据集的分类问题。改善训练集不平衡性的方法主要有随机采样和训练集分类。学习算法层面的方法主要有分类器集成、代价敏感学习和特征选择等。
随机采样的方法是通过增加少数类样本和减少多数类样本来改善不平衡数据集的不平衡性,从而提高分类器对少数类样本的识别率。Chawla等人提出的SMOTE算法[3]是一种简单有效的过采样方法,该方法在少数类样本中随机选择k近邻,通过与k近邻插值增加少数类样本的数量,改善了不平衡数据集的分布。文[4]提出的B-SMOTE(Borderline-SMOT)算法是建立在SMOTE算法的基础上的,它把少数类样本分成噪声、边界样本及安全样本,对其中的边界样本进行近邻插值,从而进一步改善数据集的不平衡分布。文[5]在B-SMOTE算法的基础上提出了RB-SMOTE(Refined Borderline-SMOTE)算法,该方法根据边界样本的具体分布设置了不同的采样倍率,再通过内插的方式合成新生的少数类样本,进一步优化了不平衡数据集的分布。
集成学习算法[6-7]是构建并结合多个分类器来完成学习任务的。一般先产生一组基分类器,再用某些方法把基分类器组合成集成分类器。集成学习主要有两个问题需要解决,一个是如何得到一组基分类器,另一个是如何选择组合方法把基分类器合成一个集成的强分类器。组合方法主要有平均法、投票法和学习法等。集成分类器通常可以得到比单一分类器具有更加显著的泛化性。经典的集成学习法有 bagging[8]、boosting[9]、随机森林[10]、stacking[11]等等。
本文在RB-SMOTE算法的基础上结合集成学习的投票法,提出了面向不平衡数据集的一种基于SMOTE的集成学习算法。该算法合成不平衡率不一的多个新训练样本集,利用这些新数据集训练相应的支持向量机作为基分类器,剔除具有错误分类倾向的基分类器,通过投票的方式把剩余的基分类器组合成集成分类器。
1 相关工作
1.1 SMOTE算法
设原始训练样本为T,分为少数类样本P和多数类样本 N。其中 pi∈P,i=1,2,…,pnum 表示少数类样本,ni∈N,i=1,2,…,nnum 表示多数类样本。
SMOTE算法首先计算少数类样本中的每一个样本pi与少数类样本P的欧式距离,得到k近邻;再根据采样倍率,在k个近邻中选择适合的个数s;然后把该样本pi与s个近邻进行线性插值,合成新增加的少数类样本;最后新增加的少数类样本与原始数据合并,构成新的训练样本。
1.2 RB-SMOTE算法
在SMOTE算法的基础上,B-SMOTE算法把少数类样本划分为安全样本、边界样本和噪声。先计算少数类样本中的每一个样本pi与训练样本T的欧式距离,得到k近邻;再根据采样倍率,在k个近邻中选择适合的个数s,少数类中的边界样本插值合成新的少数类样本。
RB-SMOTE算法在B-SMOTE的基础上对少数类中的边界样本加以区分,选择合适的采样倍率,精细化分配新生成的样本数量,进一步改善不平衡数据的不平衡性。
1.3 集成学习法
在集成学习的分类任务中,通过训练m个基分类器C1,C2,…,Cm,选择合适的组合方法,把多个基分类器合并成一个集成的强分类器。如图1,输入测试样本到m个基分类器中,得到相应的m个预测结果q1,q2,…,qm,选择投票方式获得分类结果。
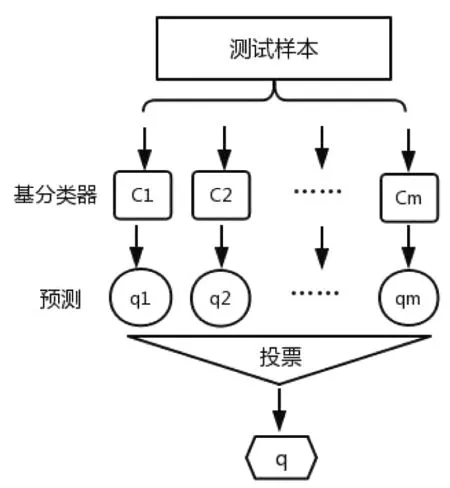
图1 集成学习流程图
2 基于SMOTE集成学习算法的具体步骤
反映不平衡数据集各类之间不平衡程度的一个重要指标是不平衡率,二分类数据集的不平衡率表示为:

下面给出基于SMOTE的集成学习算法的具体步骤:
步骤1 获得少数类样本的k近邻。
计算少数类样本 pi,i=1,2,…,pnum 与训练样本T的k近邻,k近邻中有k'(0≤k'≤k)个样本属于多数类样本。
步骤2 划分少数类样本。
如果0≤k'<k/t(适当选取参数t),则pi属于安全样本;如果k/t≤k'<k,则pi属于边界样本;如果k'=k(适当选取参数t),则pi属于噪声;其中,边界类样本记为 p't,t=1,2,…,dnum。
步骤 3 设置采样倍率 Ut,t=1,2,…,dnum。

步骤4 训练样本的不平衡率rIR设置为m种情况,确定m种情况下需要增加的少数类样本的个数。设置采样倍率,边界样本p't与其近邻插值合成 st个新增的少数类样本。cj=p't+rj×dj,t=1,2,…,dnum,j=1,2,…,st,其中 s1+s2+…+sdnum为某一平衡率下增加的少数类样本的个数,rj为0到1之间的随机数,dj为p't与其近邻的欧式距离。
步骤5 新增的少数类样本分别与原始训练样本合并,构成新训练样本 T'1,T'2,…,T'm,m 个新训练样本与支持向量机构成m个基分类器。
步骤6 输入测试样本到m个基分类器中,剔除具有错误分类倾向的分类器,利用剩余的分类器进行投票分类。
3 仿真实验
实验采取了5折交叉验证法,运行30次,取其均值。仿真软件为Matlab R2018a,实验环境为操作系统Windows10 64 bit,处理器为Intel(R)Core(TM)i5-7200U CPU@2.50GHz 2.71GH,内存为8GB。利用支持向量机(SVM)[12-13]作为分类器,径向基核选取的核宽为0.8[14]。
3.1 数据集描述
实验数据来源于UCI数据集(https://archive.ics.uci.edu/ml/index.html) 和 KEEL数据集(http://sci2s.ugr.es/keel/study.php?Cod=24),其中选取了不平衡率不相同的10组数据集(表1),并且数据归一化到[0,1]进行预处理。
在本文的仿真实验中,新算法步骤5的m取11,分别设置不平衡率 rIR为 0.5,0.6,…,1.4,1.5 等11种情况。利用这11个数据集分别训练得到11个分类器,剔除3个分类结果过于倾向于负类样本和3个分类结果过于倾向于正类样本的分类器,利用剩下5个基分类器进行投票。
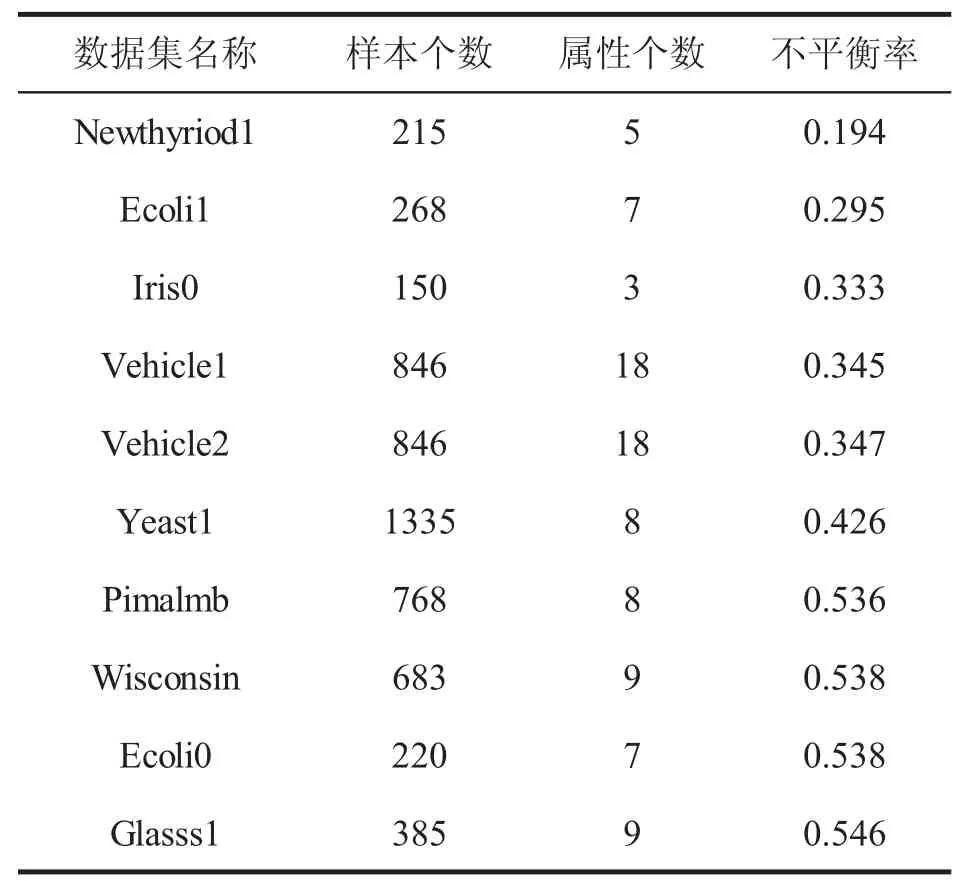
表1 数据集的描述
3.2 分类准则
目前,不平衡数据集的分类问题常用的评价标准有查全率、查准率、G-mean值、Fvalue值等等,这些评价标准兼顾了各类样本的分类精度,能更好地评价不平衡数据集的整体性能。
表2给出了混淆矩阵,它是常用的一种评价分类性能的方法。表2中TP、TN分别表示正确分类的少数类和多数类样本个数。FP、FN分别表示错误分类的少数类和多数类样本个数。
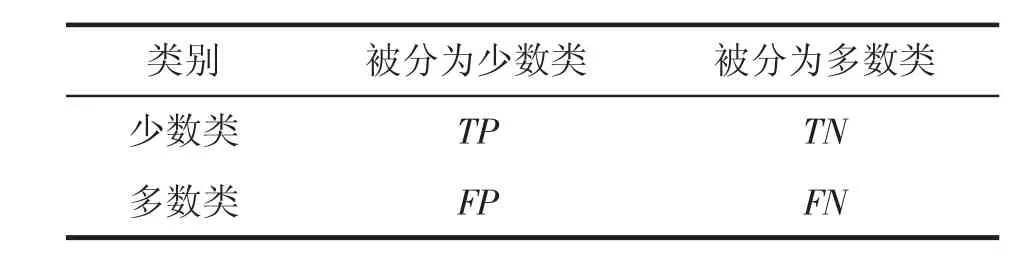
表2 混淆矩阵的描述
查全率rTP、rTN及查准率公式如下:
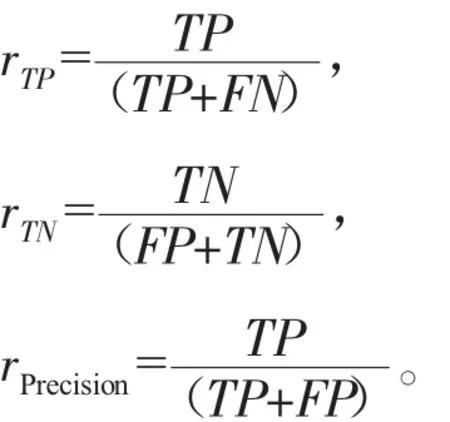
综合查全率和查准率的F值公式如下:
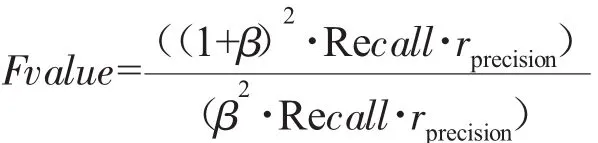
G-mean值公式如下:
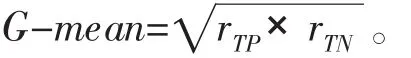
3.3 仿真实验结果
图 2 给出了 SMOTE、B-SMOTE、RB-SMOTE、11个集成、5个集成等5种方法的G-mean值比较。
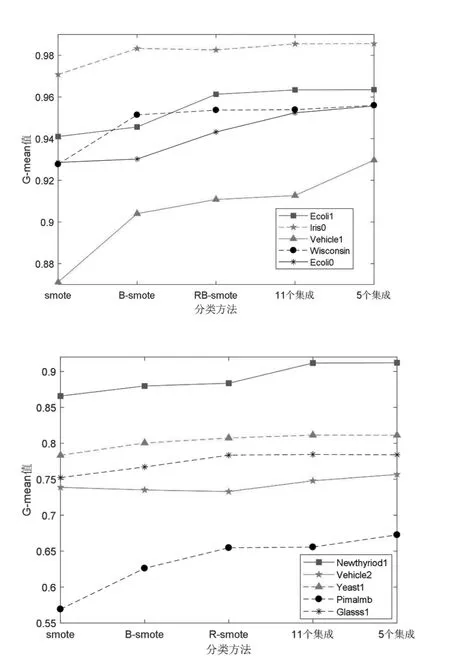
图2 各种算法的G-mean值比较
从G-mean值的角度看,RB-SMOTE结合集成学习的算法优于单一的RB-SMOTE算法,5个集成学习的算法略优于11个集成学习的算法,如图2。
表 3、表 4分别给出了 SMOTE、B-SMOTE、RB-SMOTE、11个集成、5个集成等5种算法的rTP值与Fvalue值比较。表中显示,11集成与5集成不论是rTP还是Fvalue值都优于其他算法。
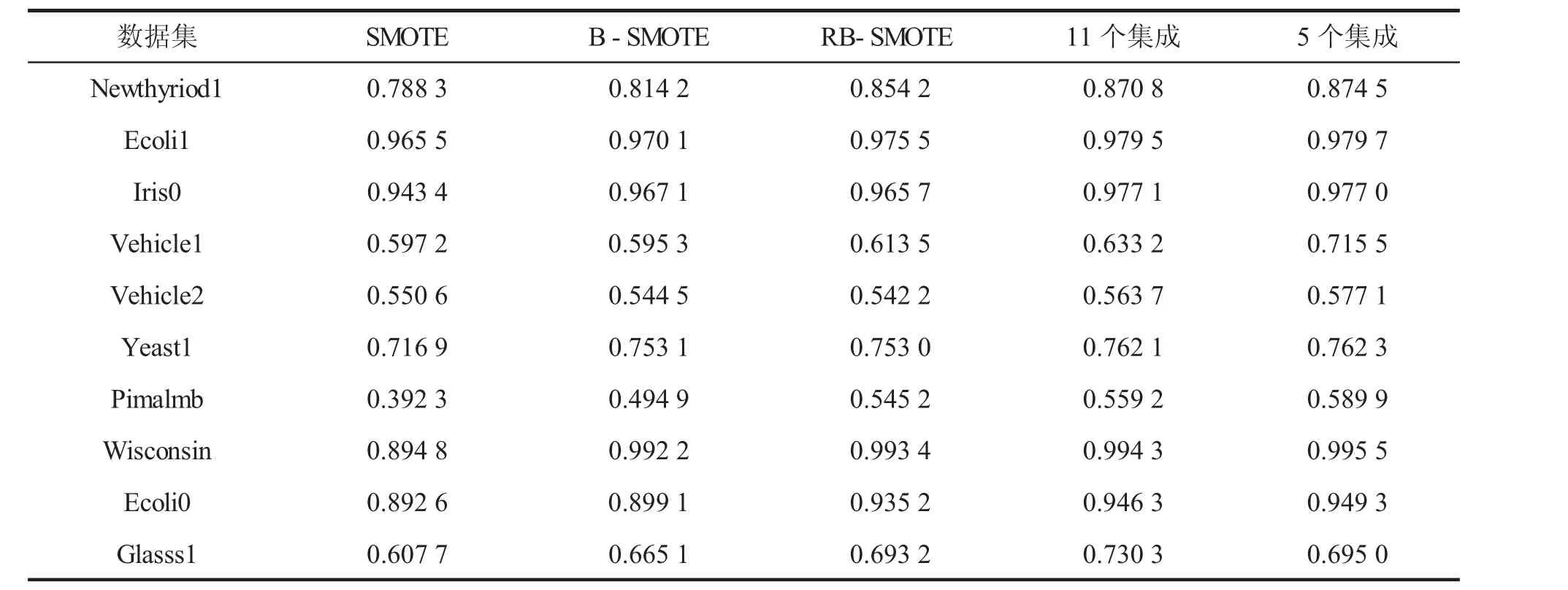
表3 各种算法的rTP值比较
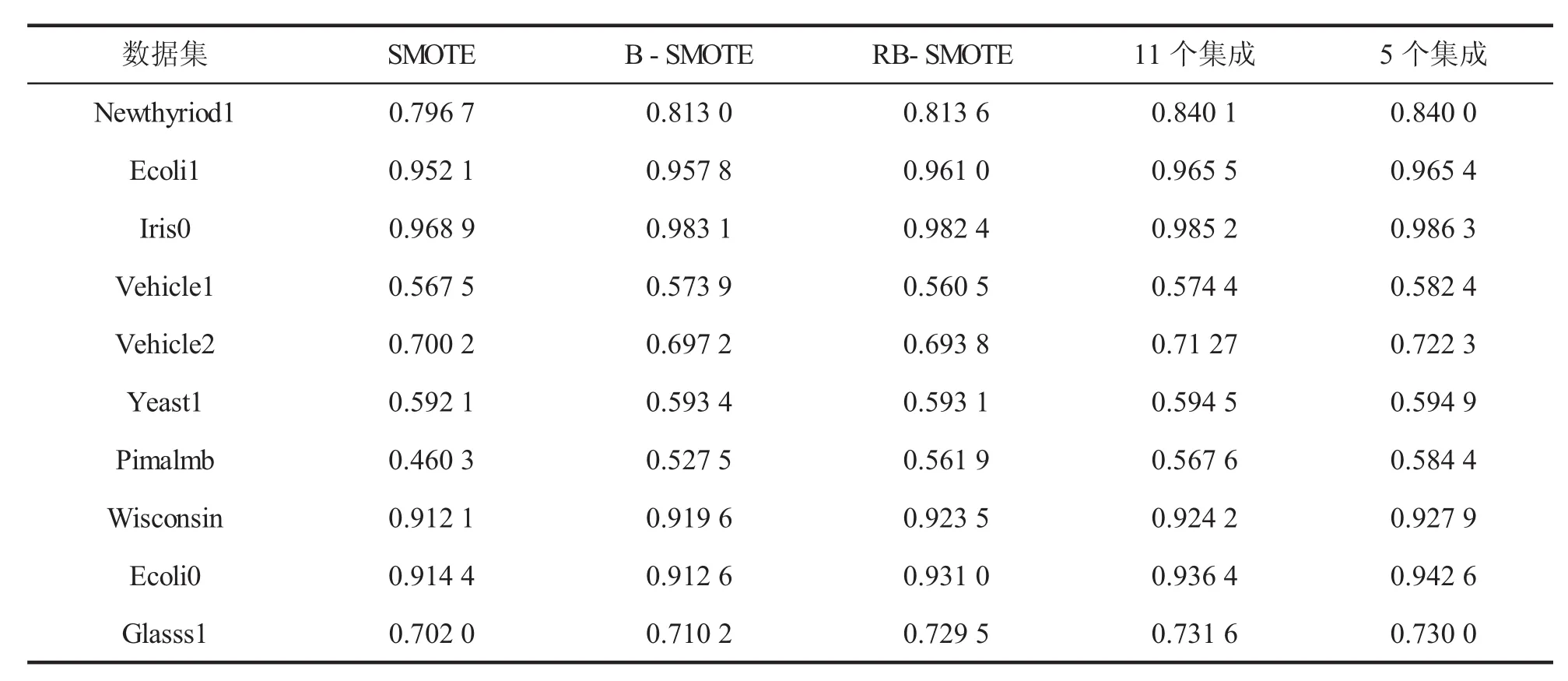
表4 各种算法的Fvalue值比较
4 结语
本文提出了一种基于SMOTE的集成学习算法。B-SMOTE算法是在SMOTE算法的基础上建立起来的,RB-SMOTE算法精细化了B-SMOTE算法,新算法是把RB-SMOTE算法结合了的集成学习算法,分别设置11个与5个平衡率不同的数据集,并投票获得分类结果。新算法结合了RB-SMOTE方法与集成学习方法的优势,使得新分类器稳定性更强。仿真实验表明基于SMOTE的集成学习分类器比 SMOTE、B-SMOTE和RB-SMOTE整体上更优。
猜你喜欢
探索科学(学术版)(2021年3期)2021-05-18
建筑机械化(2020年10期)2020-11-23
科技创新与应用(2020年6期)2020-02-29
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
制造业自动化(2017年2期)2017-03-20
北京理工大学学报(2016年6期)2016-11-22
系统工程与电子技术(2016年7期)2016-08-21
中国塑料(2015年6期)2015-11-13
航天返回与遥感(2014年5期)2014-07-31
