
基于Q-学习的果园机器人避障算法研究
2020-10-17 01:16毛鹏军张家瑞黄传鹏李鹏举
农机化研究 2020年11期
毛鹏军,张家瑞,黄传鹏,耿 乾,李鹏举
(河南科技大学 农业装备工程学院,河南 洛阳 471003)
0 引言
在我国,林果生产已成为大部分林果产区经济发展和农民增收致富的新亮点和支柱产业[1],而果园机械化程度仍处于起步阶段,其作业管理仍依靠人工完成。究其原因:①果园果树树冠大、冠层低,传统动力农机无法进入作业,且其生产过程不仅充满了剪枝、套袋、采摘等精细化作业环节,还有施肥、除草等传统农业作业环节[2];②水果品种多、种植模式差异大,进一步增加了农机适配难度[3]。
随着人工智能的发展、自动化水平的提高,无人值守、智能化产业在农业工程领域取得了较快发展,并得到相关学者的高度重视。聂森等[4]对采集的树行视觉信息用HSV和最大类间方差法进行增强处理,并对果树树行进行Hough拟合,得到果园机器人运动的导航路线。张磊等[5]基于图像处理的方法将获得的农田场景图像进行分割和归类处理,然后使用特征匹配的方法获取障碍物信息,正确率可达95%。葛君山[6]将获取的GPS信息发送给单片机,在单片机内进行分析和处理后得到果园机器人的控制时间和位置信息,进而控制其完成导航。孙曼晖等[7]在大范围环境中使用基于GIS和SLAM的方法,解决了SLAM在大范围环境中建图难的问题。曹起武[8]将农业机器人的控制系统存放在云计算机中,使用蚁群算法,完成农业机器人的路径规划。艾长胜等[9]基于支持向量机的算法对农业机器人作业路径进行规划,发现该算法拟合的导航路线与实际中心线平均角度偏差为0.72°。陈顺立[10]在建立的几何环境模型基础上,采用遗传算法进行了全局规划,得到了最短路径。
但是,一些果园中,果树连续种植且行间距不明显,这种环境障碍物结构复杂,增加了机器人环境建模的难度。激光雷达传感器具有抗干扰性强、精度高的特点,广泛应用于机器人自动避障。为此,设计的果园机器人搭载激光雷达,实时获取果园实况数据信息,应用数据差方式,标定出果园中障碍物,并依此生成栅格地图,然后采用Q-学习的方式得到最优路径。
1 果园机器人系统结构与运动模型
果园机器人系统结构由感知层、决策层和执行层组成,如图1所示。感知层是果园机器人感知外界环境的部分,由激光雷达组成,主要完成环境中障碍物位置信息的采集。决策层是果园机器人的“大脑中枢”,由一台ROS机器人系统的工控机组成,主要完成果园机器人运动控制、处理激光雷达数据,并发送速度信息给底层控制系统;对于接收到的激光雷达数据,首先将其转换到机器人坐标系,然后进行栅格化处理,将不规则的障碍物都补齐为正方形,再进行避障路径规划。执行层是机器人的运动执行层,其底层控制系统的核心是STM32F103单片机,用来完成决策层发送指令,控制两侧电机驱动机器人移动完成避障。
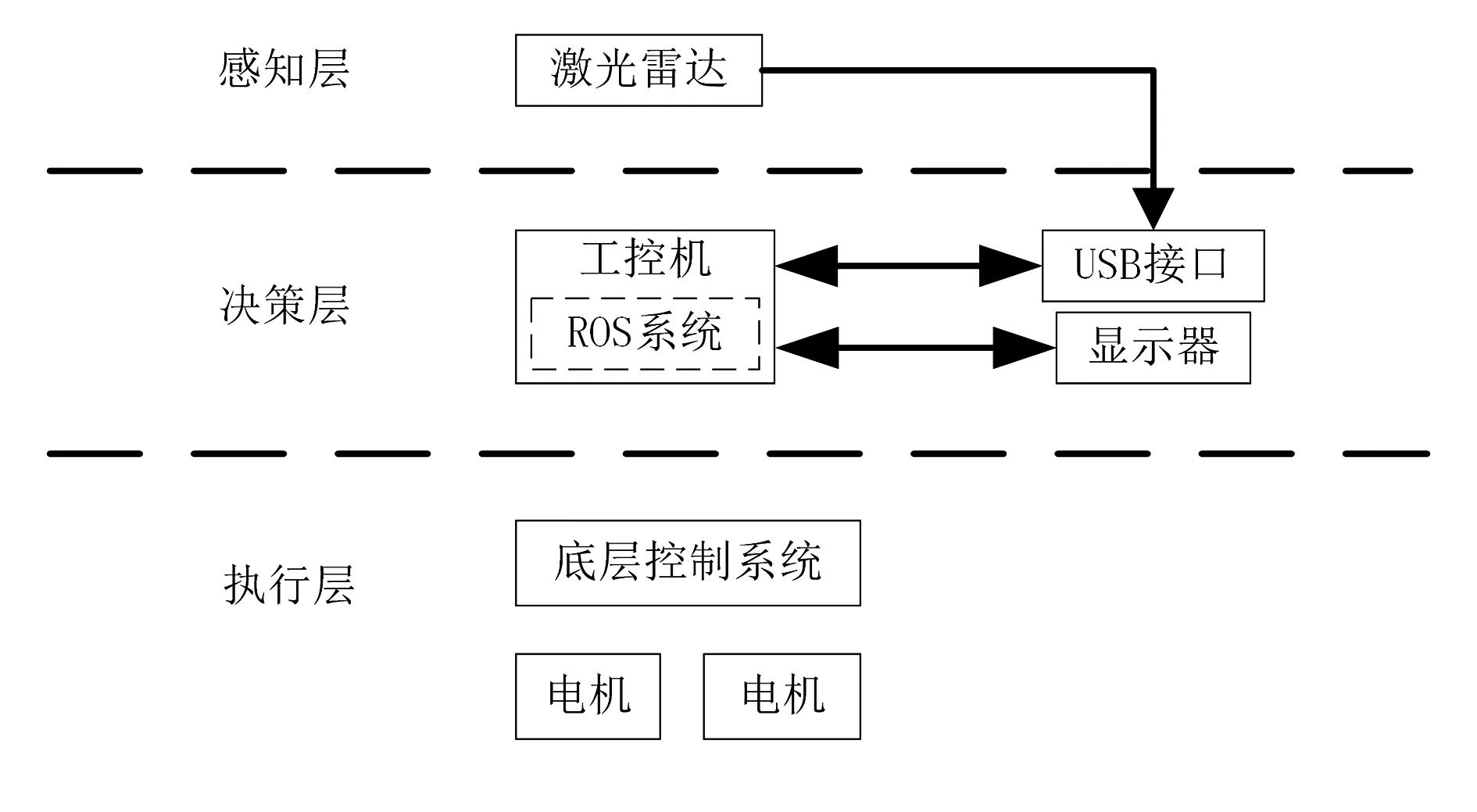
图1 果园机器人系统结构图Fig.1 Orchard robot system structure diagram
1.1 环境与位置信息获取
系统中获取环境中障碍物信息主要由激光雷达传感器完成。机器人判断障碍物依据为
(1)
式中ni—该段时间内第i个激光雷达距离数据;
d—障碍物与机器人之间的距离;
a—第i个激光雷达数据与i-1数据的差的阈值。
当得到障碍物的信息后,此段时间内障碍物的最大直径计算公式为
s=f(ni)-f(mj)
(2)
由于果园背景环境复杂,使得检测到的障碍物形状不一,所以需要将障碍进行规则化处理[11]。首先,以果园机器人为中心,机器人的步长L为参数,将激光雷达采集的数据进行栅格化处理,然后将障碍物全部补齐为正方形。行列栅格数为
(3)
为了进一步降低激光雷达数据冗余度、提高运算速度,当机器人与树干距离为d时,只处理夹角在α内的数据,用公式表示为
(3)
其中,θi为该段时间内第i个激光雷达角度数据。
某一段时间内激光雷达数据如图2所示。图2中,果园机器人坐标位于图中坐标点(9,18)处,虚线表示未进行冗余处理前的环境信息,实线表示冗余处理后保留的结果,黑色方块表示障碍物信息处理后补齐到正方形的结果。

图2 障碍物地图Fig.2 Obstacle map
1.2 果园机器人运动模型
果园环境下道路崎岖不平,当雨雪天气过后道路更是泥泞不堪,为了让果园机器人能在这种恶劣环境下运行稳定,采用了差速转向机构,用两电机完成左右轮速度控制。果园机器人的差速模型简图如图3所示。图3中:xoy为全局坐标系;XOY为果园机器人坐标系;θ为果园机器人与水平方向夹角;v1为果园机器人右侧轮速度;v2为果园机器人左侧轮速度;B为轮距;ω为转向角速度;R为转向半径。

图3 机器人转向图Fig.3 Robot steering diagram
果园机器人两侧的速度为
v1=(R-0.5B)ω
(4)
v2=(R+0.5B)ω
(5)
中心速度为
v=Rω
(6)
果园机器人两侧线速度为
v1=ω1r
(7)
v2=ω2r
(8)
式中ω1—果园机器人右侧轮角速度;
ω2—果园机器人左侧轮角速度;
r—驱动轮半径。
所以
v1=ω1r=(R+0.5B)ω
(9)
v2=ω2r=(R+0.5B)ω
(10)
得到
(11)
(12)
v=0.5r(ω2+ω1)
(13)
整理最后得到差速模型为
(14)
2 Q-学习的避障算法研究
2.1 算法基本原理
Q-学习属于强化学习[12],不需要建立环境模型,是一种基于数值迭代的规划方法,其示意图如图4所示。在Q-学习过程中,机器人根据当前状态St选择一个动作At,执行该动作后会得到环境的激励Rt,机器人需要根据该激励值和环境状态选择下一个动作。
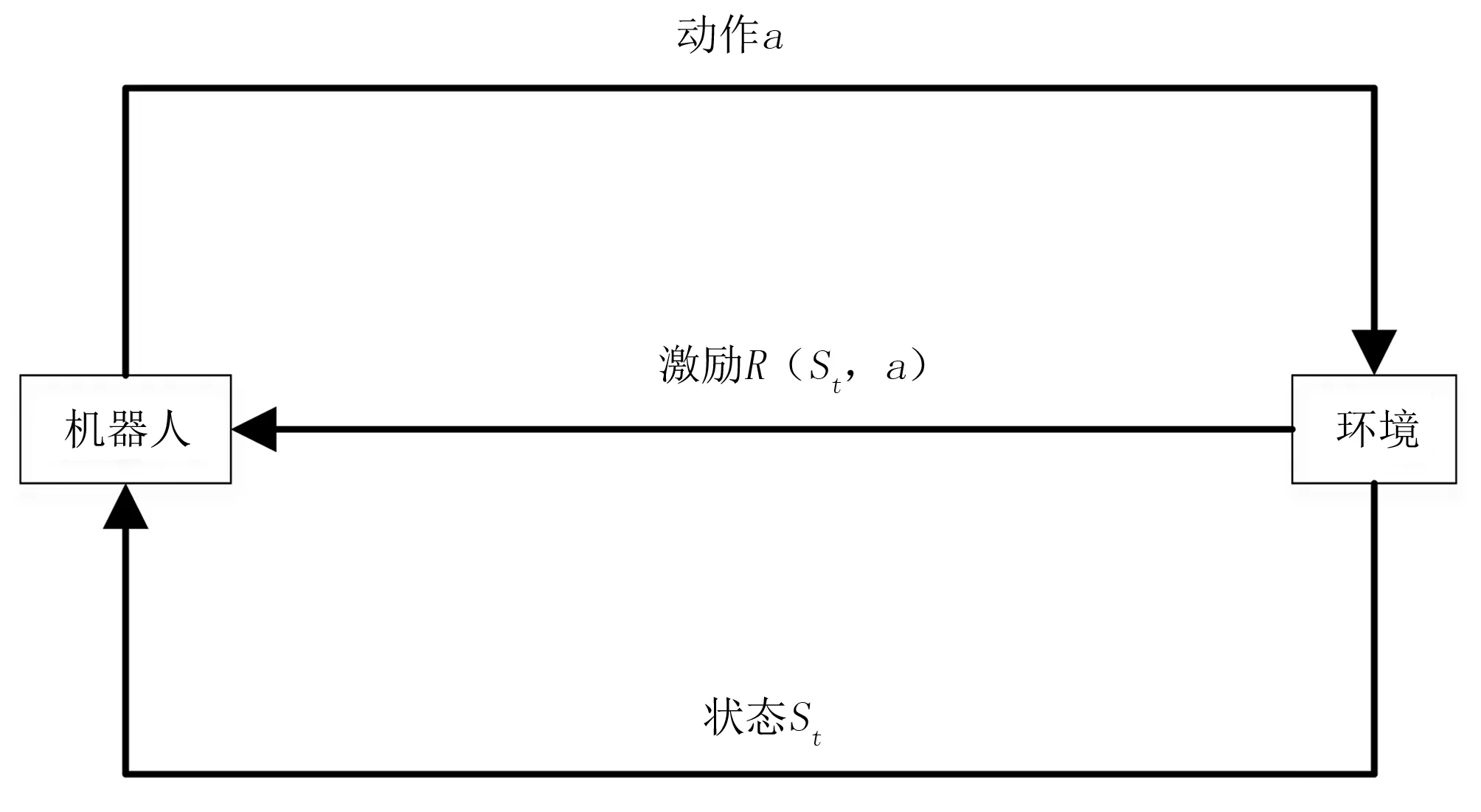
图4 强化学习基本模型图Fig.4 Basic module of reinforcement learning
2.2 模型建立
1)激励值表R的设计。依据果园机器人的作业环境,确定机器人与障碍物的距离和方位角分别为d和θ,并规定机器人前进时的方位角范围为(0°~45°)和(315°~360°),当机器人方位角处于该范围时激励值取100。当机器人与障碍物间的距离为0.6~0.8m时激励值取100。激励值表如表1所示。

表1 R值表Table 1 R value table
2)动作设计。把果园机器人在果园中的运动分为左转、右转和前进,结合果园机器人的差速模型,得到动作值表如表2所示。

表2 动作值表Table 2 Action value table
3)动作选择策略。定义动作策略是选择当前状态下的Q值最大的动作,Q函数的方程为
(15)
式中R(St,a)—当前状态下,系统采取的动作a获得的回报;
St′—当前状态St和当前动作a下系统转入的下一个状态;
γ—权值系数,γ∈(0,1),是将未来的回报转换为当前的因子,γ值越大,对当前的影响越大;
b—下一个状态所采取的动作;
Q(St,a)—系统在当前状态St和动作a下得到的总计期望回报的估计。
调整规则由以下公式表示,即
(16)
3 Q-学习的避障算法仿真及试验
3.1 算法流程图
在ROS环境中启动激光雷达rplidar_ros功能包后,激光雷达便开始采集环境信息。该信息通过tf坐标转之后,将数据送入果园机器人控制程序中,完成障碍物边缘提取,然后得到障碍物地图矩阵。在Q-学习阶段,首先建立Q空矩阵,随机选择初始状态;若该状态不是目标状态,便在改状态下选择行为a,得到新的状态,然后计算Q值,并更新Q矩阵,直到Q矩阵收敛为止。果园机器人便按照该矩阵规划的路线前进,并实时判断是否有新的障碍物:若有,重新学习规划新的路线;若无,判断是否到达终点。若没有到达终点,则更改机器人速度,直到到达终点位置。其路程图如图5所示。
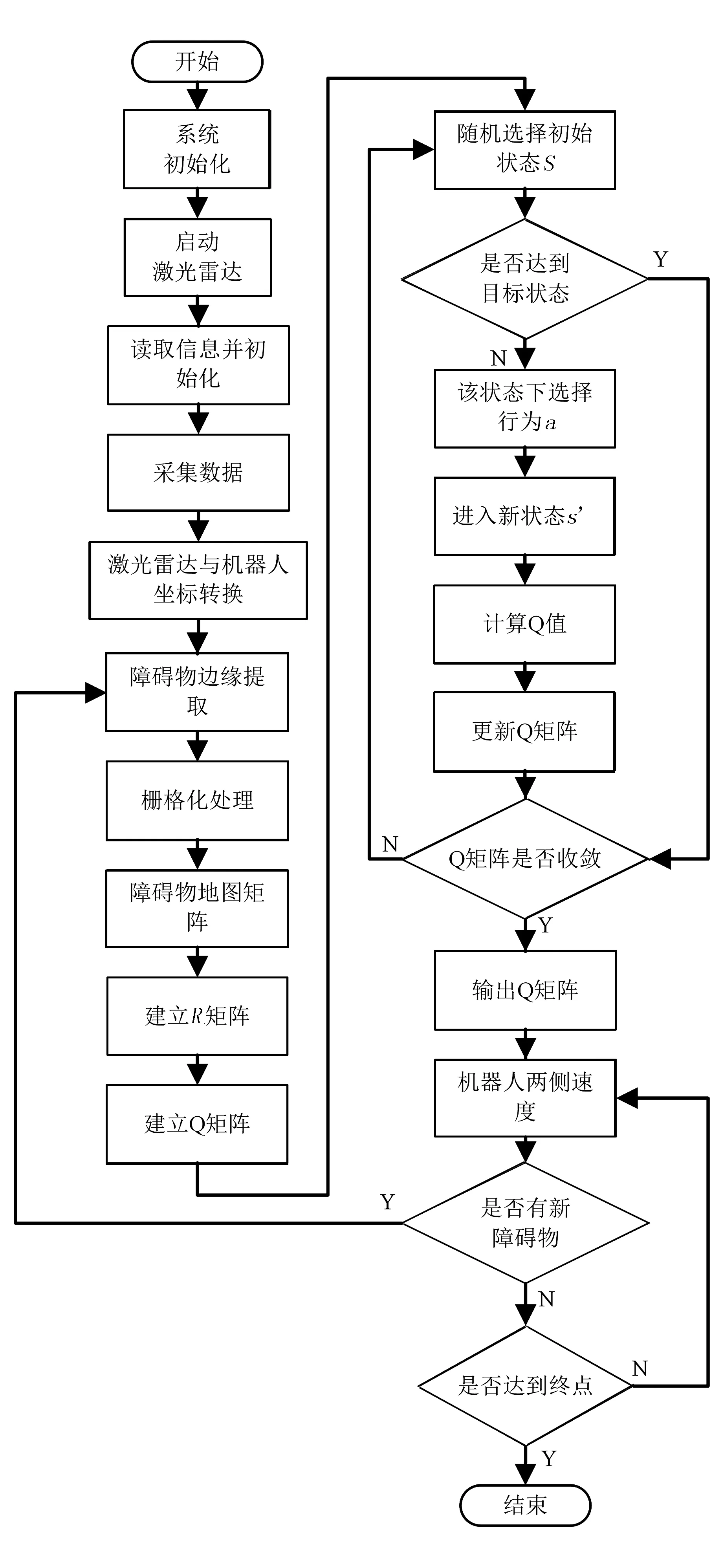
图5 算法流程图Fig.5 System flow chart
3.2 算法仿真
为验证所设计的果园机器人自主避障算法可行性,利用MatLab软件对其进行仿真验证。在仿真中,随机s生成各种大小的障碍物,机器人位于坐标原点,终点位于(35,35)。其输入信息为激光雷达所测的障碍物的距离以及所在方位角,输出是机器人的两侧电机速度,学习率α=0.5,权值系数γ=0.8,训练结果如图6所示。

图6 仿真图Fig.4 System flow chart
由图6可知:机器人能够及时躲避环境中的障碍物,并规划出一条较优路径。
3.3 室内外试验
为验证机器人的避障可行性,对果园机器人进行室内模拟试验。试验场地为河南科技大学西苑校区10号楼楼道,在测试试验环境中放置了2个形状不一的障碍物模拟果园环境中的障碍物。试验过程如图7所示。

(a) 起始位置 (b) 开始避障
图7(a)是起始位置,将机器人和障碍物放置在一条线上,终点位于第2个障碍物后方;图7(b)是躲避第1个障碍物的过程;图7(c)是完成第1个避障的过程,可以看出机器人能很好的躲避第1个障碍物并和障碍物保持一定的距离;图7(d)是完成第2个障碍物躲避。由试验可以看出,机器人能及时躲避环境中放置的障碍物。
其避障轨迹如图8所示。从机器人的轨迹图上可以看出:机器人能顺利避开所设障碍物,并能到达指定终点,且路径较为光滑。

图8 避障轨迹图Fig.8 Obstacle avoidance trajectory diagram
在试验过程中,记起点位置为A点,方形障碍物为B点,圆形障碍物为C点,终点位置为D点,具体标记如图8所示。果园机器人在避障过程中的试验数据,如表3所示。

表3 试验结果Table 3 Test results
表3中,距离为点到点的中心距离,理论距离为机器人的测量数据。机器人从A点到D点所用时间为12s,AD直线距离为6.80m,机器人所走路程为7.24m,平均速度约为0.60m/s。其运动过程中距离测量平均误差为3.6%,是由于激光雷达自身误差和障碍物表面反射造成的。B点到障碍物的表面实际测量距离为0.30m,规划的路线距离为0.28m,误差为7.14%。这是因为在开始阶段,机器人进行了栅格化和障碍物信息补齐到正方形造成的。
4 结论
1)对激光雷达数据进行了冗余处理,将激光雷达的信息映射到平面坐标中进行栅格化;在栅格化之后,将所有障碍物补齐为规定的正方形。该方法减少了激光雷达的数据量,提高了机器人的运算速度。
2)将得到的障碍物栅格地图信息送入Q-学习中,通过学习得到一条较优路径,驱使机器人沿着该路线前进。当机器人经过的路线中再次出现障碍物,可再次更新障碍物位置信息,进行Q学习得到当前障碍物下的较优路径。该方法将连续的状态空间离散化,解决了状态-动作过多的“维数灾难”问题。
3)通过仿真分析,证明了该方法的可行性。在楼道环境进行了避障试验,结果表明:机器人能及时躲避障碍物,到达指定地点,具有较好的应用价值。
猜你喜欢
北京测绘(2022年5期)2022-11-22
今日农业(2022年16期)2022-09-22
快乐语文(2021年27期)2021-11-24
汽车观察(2021年8期)2021-09-01
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
阅读(低年级)(2019年9期)2019-11-15
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
小学生作文(低年级适用)(2017年9期)2017-10-13
