
电力企业移动培训客户端学员学习状态监督方法
2020-10-15 05:26邓福兴焦日升曹盛楠
东北电力大学学报 2020年4期
薛 凯,邓福兴,王 菁,焦日升,曹盛楠
(1.国网吉林省电力有限公司培训中心,吉林 长春 132022;2.东北电力大学电气工程学院,吉林 吉林 132012)
在线学习又称虚拟课堂,是指通过网络开展的师生同步直播学习或者非同步的学习方式[1].基于移动客户端的在线学习因其具有学习方式和时间灵活,学习覆盖面大的特点已经成为企业常用的员工培训手段和高校的辅助教学手段.例如,南方电网在2013年就开始使用在线直播技术培训员工[1].高校在线学习的技术和手段则更为丰富.例如,高校普遍使用的超星学习通可以实现非同步的在线学习和同步的语音直播[2-3].另外,有些高校使用雨课堂进行同步的视频直播[4-5].由于2020年的新型冠状病毒疫情,学生的在线学习和员工的在线培训已经成为了高校和部分企业的必然选择.
然而,在线学习是在没有教师监督的情况下学员自主学习[6].从教师的角度看,在上课过程中难以面对面的监督学生的学习状态.从学员角度看,在上课过程中,由于缺少监督难免会产生不重视学习的心里.甚至自律性差的学员,可能仅仅是打开了在线学习客户端而没有真正学习.因此,在线学习客户端需要在不干扰学员学习的情况下采用技术手段对学员的学习状态进行监督.
本文提出了一种基于人脸识别技术的移动客户端学员学习状态监督方法.本方法的目的是在上课过程中实时监督学生是否在客户端屏幕前听课.为了达到监督的实时性和不干扰学员学习的目的.本文使用YOLOv3深度神经网络检测学员的人脸.YOLO网络是原名为“你只看一次”系列网络(You Only Look Once,YOLO)的缩写.YOLOv3是该系列网络的第三个版本.YOLOv3是一种准确且高效的图像检测方法.YOLOv3对尺寸为320×320的图片进行目标检测仅耗时22毫秒.因此,使用YOLOv3作为学员人脸检测方法可以做到不干扰学员听课.由于听课学员会有不同的姿势,学员的人脸会存在不同的角度和不同的尺度.本文采用了尺度不变特征(Scale-Invariant Feature Tansform,SIFT)提取人脸特征向量.提取到的人脸特征和预先上传的学员照片比对以识别学员身份.学习状态监督算法被学员客户端定期调用.人脸检测和识别这两个监督步骤在客户端的后台运行,监督过程不会被学员感知,因此不影响学员听课.
1 学员学习状态监督方法主要流程
本文提出的基于人脸识别技术的移动客户端学员学习状态监督方法流程图,如图1所示.每隔t时刻,学习客户端调用如图1所示的学员学习状态监督方法.该方法通过移动客户端(一般是智能手机)的前置摄像头拍摄照片.为了保证处理速度,我们将前置摄像头的图像尺寸统一缩放为800×800像素.之后,使用YOLOv3人脸检测神经网络检测该照片中是否存在人脸.若存在人脸则从检测框中的人脸图像中提取人脸的SIFT特征向量,并与学员注册时上传照片的特征向量进行比对识别.若YOLOv3未检测到人脸,或者人脸对比识别失败,则将人脸识别失败计数器fn加1.如果人脸识别多次失败,即fn大于阈值n,则学习状态监督程序将所拍摄的照片发送给该课程的讲师或者系统管理员以提示相关人员该学员可能没有专心学习.
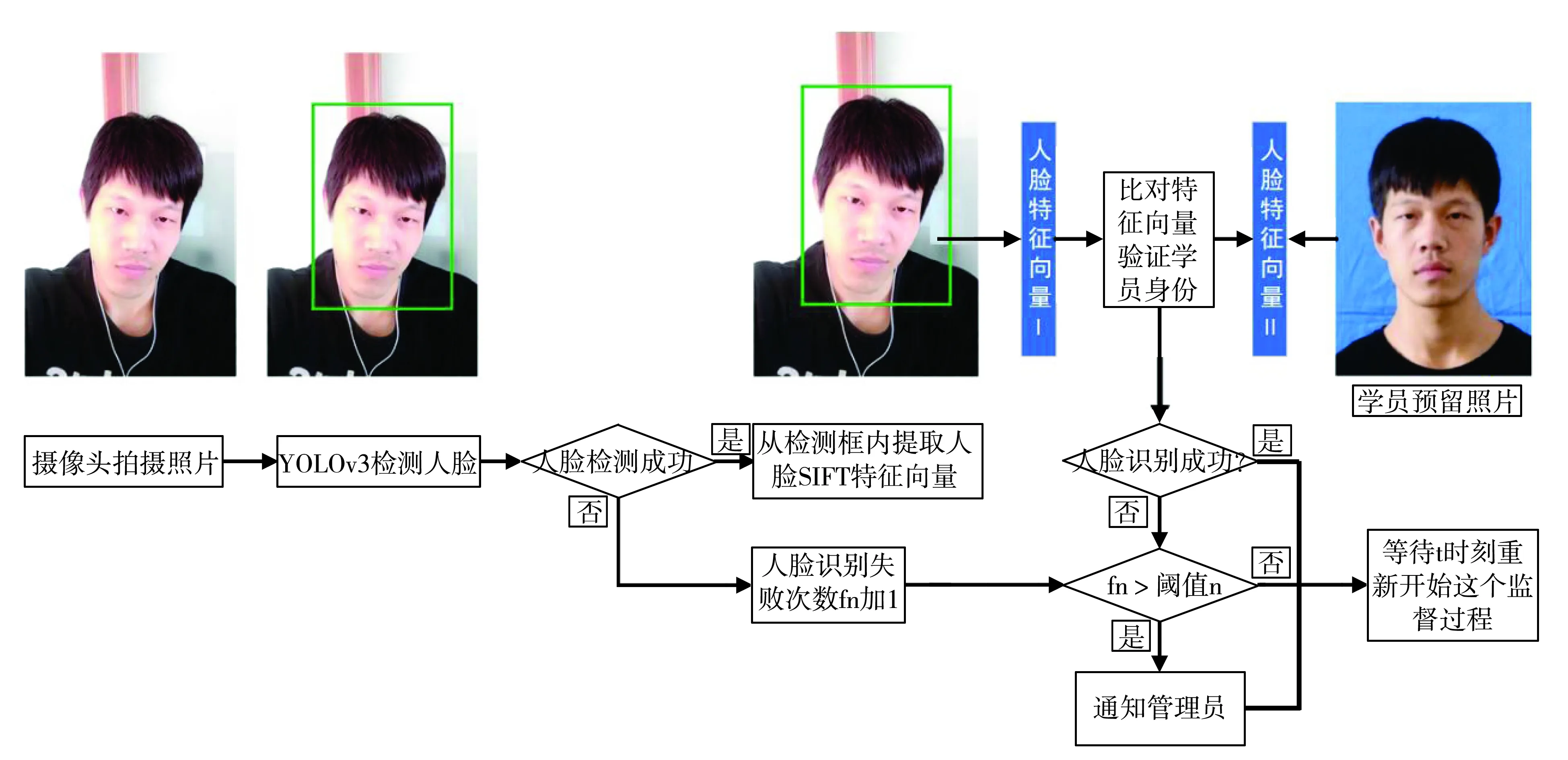
图1 学员学习状态监督方法流程
学习状态监督方法中相关参数可以由系统管理员设置.参数t表示两次调用学习状态监督过程的时间间隔.由于人脸检测和识别过程会受到学员听课姿势,光照,摄像头是否有效等多种情况干扰.为了避免误报对课堂造成干扰,在某学员的客户端人脸识别失败的情况下系统并不立刻通知讲师或者系统管理员,而是要等待人脸识别失败计数器fn大于阈值n,即该学员在一定时间内人脸识别失败次数达到一定数量时才认为该学员未认真听课.阈值n表示当有多少次人脸识别失败的情况下系统通知讲师或者系统管理员.阈值n的值可以由系统管理员根据实际情况设置.
2 基于YOLOv3神经网络的人脸检测
2016年,Redmon[8]首次提出了一种基于端到端的检测算法:“你只看一次”神经网络(You Only Look Once,YOLO).该算法通过一个卷积网络同时预测图像中目标的类别和坐标.YOLO只包含一个神经网络,因此称之为端到端的检测算法.YOLO系列目标检测深度学习神经网络是一种端到端的一共有三个版本[7,8,11].YOLO的检测速度远高于之前的很多两阶段的检测方法[9-10],但版本1和版本2对图像中一些较小的目标检测性能较差.YOLOv3版本的网络结构使得该网络对于各个尺度目标的检测能力都显著提高.YOLOv3网络结构的简略示意图,如图2所示.
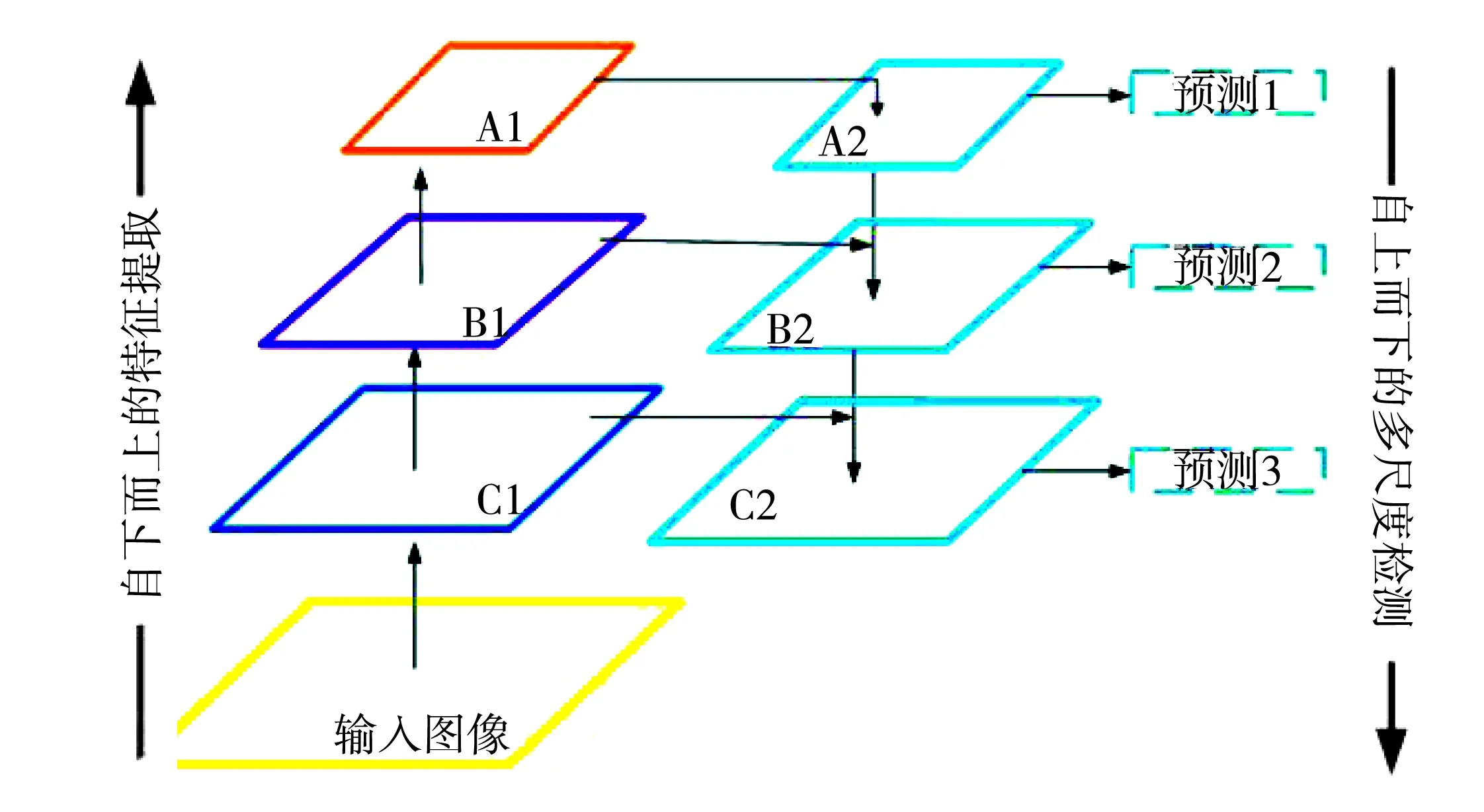
图2 简化的YOLOv3网络结构示意图
YOLOv3网络由两部分组成,即自下而上的特征提取网络和自上而下的多尺度检测网络.前者负责提取输入图像的低层细节特征.后者从底层细节特征中提取高层语义特征.然后将这些高层次特征与相应的低层次特征连接起来,对检测网络中的不同尺度的目标进行检测.自上而下的特征提取网络的骨干作者称为Darknet53.Darknet53的深度为75层,由53个卷积层和22个快捷连接层叠加而成.Darknet53网络可细分为单个DBL模块和Res1、Res2、Res8、Res8、Res4五个残差模块.DBL是YOLOv3的基本组成部分.DBL由卷积层、批处理规范化操作和ReLU激活函数组成.Resn表示每个残差模块含n个剩余单元.每个残差模块由两个串联的DBL模块组成.为了便于分析,我们将Darknet53分为三个阶段.每个阶段Darknet53提取到的特征图的尺寸各不相同.我们用图2左侧的三个方框A1、B1、C1来表示Darknet53的三个阶段所提取到的特征图.由图2可知,特征图尺寸由下至上越来越小.
右边的三个蓝色框A1、B1、C1表示一个自上而下的多尺度检测网络.该网络主要用于预测三种不同尺度的输出特征图.
学员学习时面部距离摄像头的远近不同,这就导致所拍摄的人脸占画面的比例不同.因此YOLOv3神经网络能够检测大、中、小不同比例目标的特性就特别适合学员人脸检测任务.
我们使用无约束自然场景人脸检测数据集(FDDB)[12]作为训练数据集,训练YOLOv3神经网络.FDDB数据集包含了2845张图像.在这些图像中包含5171个人脸.每个人脸在图像中的坐标位置都进行了标注.我们将训练得到的YOLOv3人脸检测模型的参数直接导入到学习状态监督APP的中YOLOv3网络中.这样学习状态监督APP的中YOLOv3网络就可以直接应用训练完毕后的模型参数进行人脸检测.
3 基于特征点的人脸识别
尺度不变特征变换[13](Scale-Invariant Feature Transform,SIFT)是一种提取图像局部特征点的算法.因SIFT对于图像的尺度、旋转和位置具有非常高的鲁棒性,出现了大量使用其作为局部特征点提取的应用[14-15].将SIFT应用于人脸识别[16-17]可以解决因人脸尺度、不同姿势、不同角度而造成的识别率降低,而且SIFT具有占用内存空间小,实时性高等优点.
提取图像SIFT特征的主要步骤有建立多尺度空间、极值点搜索、确定关键特征点、特征向量生成.SIFT算法尺度空间,如图3所示.
通过对尺度空间中的每个像素点与其同尺度的8邻域、以及相邻尺度的8邻域共26个点相比较,找到尺度空间中的极值点.之后对于极值点进行筛选.删除对比度低的和不稳定的边缘极值点,筛选后剩下的点为关键特征点.将关键特征点邻域内像素用提法方向直方图表示.该直方图中最大值所对应的梯度方向为关键特征点的主方向.将关键特征点为中心的16×16像素的区域4等分.分别计算每个小区域内的8个梯度方向,最后可以得到4×4×8=128维的特征向量.我们只提取人脸检测算法所确定的检测框中像素的SIFT特征向量.对每个人脸提取的特征点数为N.特征点的数量可以由用户指定.特征点数越多识别准确率越高,但会使得识别速度降低,相反则有更高的识别速度.在本文中我们通过试验发现设置人脸特征点的个数为40时效果就能令人满意.
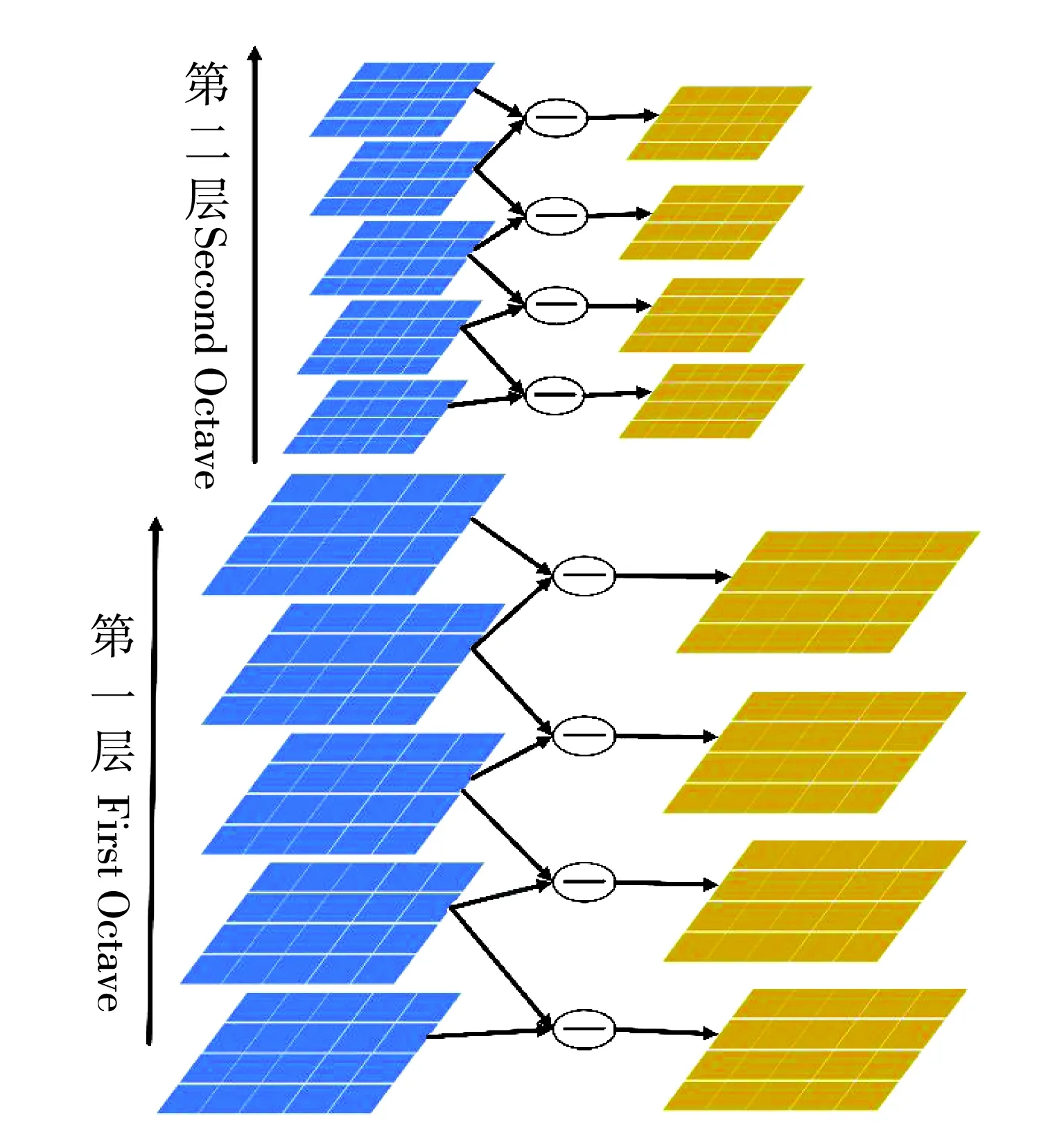
图3 SIFT算法尺度空间示意图
我们使用欧式距离衡量所提取到的人脸特征向量和学员上传的证件照片的人脸特征向量的差值.如果欧式距离的最小值与欧式距离的次小值的比值小于某一阈值时则认为这一对特征点匹配成功.当两个人脸图片的匹配成功的特征点数量超过总特征点数量的一定比例时认为两个图片为同一个人的人脸.在实验中我们设置这个比例为85%.
4 实验结果和分析
为了验证本文提出的基于人脸识别技术的移动客户端学员学习状态监督方法的有效性,我们实现了基于Android客户端的学习状态监督程序并进行了如下实验.我们首先使用学员的听课图片测试了人脸检测算法的效果.之后,我们建立了一个学员照片数据集,并采用人脸检测率、人脸识别率和有效监督率来衡量所提出的学员学习状态监督方法在学员照片数据集上的表现.最后,我们从图片的处理效率角度衡量了所提出的学习效率监督方法.
4.1 人脸检测算法检测效果测试
人脸检测算法是学员学习效果监督的第一个步骤.我们使用学员的听课图片测试了人脸检测算法的效果.为了增加测试难度,我们还选择了一些带有遮挡,甚至遮挡较大的人脸图片作为测试图片.人脸检测的效果,如图4所示.

图4 人脸检测效果图
从图4中可以看出,当学员面部没有遮挡的时,检测算法可以从学员的正面、侧面、歪头、托腮等听课姿势图片中找到人脸的位置.当学员面部有不严重遮挡时(例如图4中第三排照片1和照片4,学员只遮挡了嘴巴),检测算法仍可以检测到人脸.当学员面部有严重遮挡时(例如图4中第三排照片3和照片5),检测失败.图4中第三排照片2虽然遮挡不严重,但是遮挡位于面部中心,使得人脸的连续性被破坏,检测算法也不能检测到人脸.
使用严重遮挡的图片测试检测算法效果的目的是测试检测算法的弱点.在实际应用学习状态监督方法时,应当提示学员尽量避免遮挡面部.

(a)

(b)图5 测试集图片样本
4.2 学员学习状态监督方法测试
我们采集了10位学员的110张在线学习照片.在这个学习照片数据集中,每个学员都有11种听课姿态分别为:面向屏幕、左/右托腮、左/右歪头、左/右侧脸、仰头、低头、有轻微遮挡、人离开屏幕.其中两位学员的在线学习照片,如图5所示.我们采用人脸检测率、识别率和有效监督率三个指标来衡量所提出的学员学习状态监督方法的表现.人脸检测率是为了衡量人脸检测算法的性能.数据集中学员11种学习动作对应的照片如果被检测出有人脸则认为检测正确.数据集中共有10张人离开屏幕的照片.如果这些照片未被检测出人脸则认为检测正确.即被正确检测的照片数等于存在且被检测到人脸的照片数加上没有人脸且没有被检测到人脸的照片数.被正确检测的照片数除以总人数就是人脸检测率.人脸检测率的计算公式定义为

(1)
在人脸检测之后,再对被检测到的人脸做进一步的身份识别.人脸识别率是为了衡量人脸识别算法的性能.人脸识别率等于被人脸识别算法正确确认身份的人脸数除以存在人脸且被正确检测到的人脸数.人脸识别率的公式定义为

(2)
有效监督率是为了衡量所提出的学习监督方法的性能.在所有存在人脸的照片中,被正确的检测出人脸且被正确确认身份的照片是被进行了有效监督的照片.对于数据集中的无人照片,如果这些照片未被检测出人脸,则认为这些照片被进行了有效监督.有效监督率的计算公式定义为

(3)
采用学员照片数据集测试本文所提出的学员学习状态监督方法得到的人脸检测率、识别率和有效监督率,如表1所示.

表1 学员学习状态监督方法的测试结果
在人脸检测的过程中,99张有人脸的图片检测到人脸,有1张存在人脸的照片检测失败,10张无人脸的照片均未检测到人脸(即检测成功).之后,使用有人脸且检测成功的99照片测试人脸识别算法.人脸识别算法成功识别了其中97张照片的身份.人脸检测算法中有1张照片检测失败,人脸识别算法中有2张照片识别失败.因此,其余的107张照片被认为是进行了有效监督的照片.

表2 各算法的平均耗时(毫秒ms)
4.3 学员学习状态监督算法执行效率
我们在学员听课照片数据集上分别运行了人脸检测算法,人脸识别算法和我们提出的学员学习状态监督算法.我们测试算法的Android手机的参数为:CPU主频2253MHz,运行内存6GB,操作系统内核版本4.9.1.各个算法处理数据集所有照片的平均耗时,如表2所示.从表2中可知,本文提出的学习状态监督算法处理数据集中110张照片的平均耗时为502毫秒,即0.5秒,可以满足实时性的监督需求.
5 结 论
本文提出了一种基于人脸识别技术的移动客户端学员学习状态监督方法.该方法分别采用YOLOv3神经网络和SIFT特征点作为人脸检测和识别算法.为了验证本文所提出方法的有效性,本文建立了含有100张学员在线学习图像的测试数据集.在该数据集上的测试结果表明,本文所提出的移动客户端学员学习状态监督方法对于学员是否认真听课的识别率达到了97%.同时该方法对于一张图片的处理速度约为0.5秒,满足实时识别和监督的需要.因此,该方法可以在不干扰课程的情况下,准确的识别出未认真听课的学员.
猜你喜欢
新作文(高中版)(2022年5期)2022-11-22
——稳就业、惠民生,“数”读十年成绩单
人民周刊(2022年17期)2022-10-21
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
学生天地(2020年31期)2020-06-01
科技传播(2019年24期)2019-06-15
电子制作(2019年9期)2019-05-30
中国记者(2016年2期)2016-05-25
