
学龄前人工耳蜗植入儿童与健听儿童情感语调发音的分析研究
2020-10-14 07:42:46张芳晁欣黄露史泱杨洋崔丽娜
中国听力语言康复科学杂志 2020年5期
张芳 晁欣 黄露 史泱 杨洋 崔丽娜
语调是表情达意的一种手段,其最重要的功能之一便是情感功能,可以帮助说话者表达情绪,如高兴、害怕、忧伤等情感。当我们带着不同情绪表达同样一句话时, 会产生完全不同的效果[1]。人工耳蜗植入儿童在情感语调识别和发音两方面存在缺陷,他们能够依靠韵律线索区分高兴和悲伤语调,但是却和同龄健听儿童存在显著差异[2,3];人工耳蜗植入儿童在情感语调识别中的表现在一定程度上预示着他们情感语调发音的表现[4,5]。异常的情感语调不仅影响他们言语的可懂度,还影响他们对语义和情感的理解及其自身的表情达意。这种情感语调的异常不利于人工耳蜗植入儿童与他人沟通交流,成为回归主流社会的阻碍。由于在接收声音信号输入方面的延迟,人们一般预期人工耳蜗植入儿童理解和表达情感信息的能力也出现延迟,且人工耳蜗所传输的韵律线索并不足以支持人工耳蜗植入儿童和健听儿童一样享受全方位的语音交际[6]。他们对情感语调的处理存在问题,情感交流存在一定障碍。
目前研究情感语调使用最多的基本情感为高兴、害怕、生气、难过、厌恶5种。由于儿童的害怕、生气、厌恶3种情感在学前阶段还发育不完善,因此本研究选择在日常生活中儿童接触最多的情感——高兴和难过,以3~5岁人工耳蜗植入儿童和健听儿童为研究对象,通过对高兴和难过语调的模仿考察3者之间的差异,探讨人工耳蜗植入儿童情感语调发音的特征。
1 资料与方法
1.1 研究对象
选择在北京市普通幼儿园就读的3~5岁的人工耳蜗植入儿童55名(其中3岁20名;4岁21名;5岁14名,平均年龄3.89±0.80岁)、健听儿童44名(其中3岁10名,4岁12名,5岁22名,平均年龄4.27±0.82岁)。人工耳蜗植入儿童的助听听阈范围为18~43 dB HL,平均听阈为33.47±5.57 dB HL,助听效果均为最适,使用普通话康复1年以上且已具备较好的发音能力,无任何其他功能障碍,均熟悉普通话。
1.2 测试材料
考虑到儿童的语言和认知水平,兼顾儿童的句长能力,本研究的6个语义中性的测试句(其中1句用于受试者练习使用)均为6字句,且句中词语均为日常生活常用词(见表1)。儿童对女性说话者所表达的情感语调更容易识别[1],因此本文以高兴和难过两种基本情感语调为研究内容,首先请1名有表演经验的女性用2种不同语调(高兴、难过)表达6个语义中性的句子(其中1句用于被试练习使用),共12句话。然后请15名成人对测试语句进行评定,测试语句的正确识别率均在85%以上。
1.3 测试方法
测试由言语治疗师担任主试,测试地点的背景噪声低于45 dB(A),使用计算机语音工作站进行声音的录制及处理。实验采用一对一的方式,模仿复述形式进行。进入正式测试前,先使用练习句进行练习,主试随机播放某一情感练习句的标准音,播放完毕后让被试跟随标准音复述(可借助图片诱导),同时注意其模仿标准音的情感;之后再播放该情感的另一短句,同样让被试模仿复述。被试明确实验要求后,开始正式实验。当某一情感的两个短句均复述完毕后,再随机播放另一情感的短句按照上述流程进行,直至两种情感的10句短句均复述结束为止。若被试跟读中有字词错误或语句不完整,则重复模仿复述一次。

表1 自编测试语料
测试结束后由3名言语治疗师进行听辨记录。言语治疗师仔细听每个人工耳蜗植入儿童和健听儿童的语句,并对每一个语句与示范语句的一致程度进行打分(0分完全不一致、1分比较不一致、2分一致、3分比较一致、4分非常一致),最后计算每个儿童的平均得分。
1.4 信度
3名言语治疗师对同一测试语料进行打分,对结果进行信度分析。结果显示,3名言语治疗师之间具有较高的一致性,Person相关系数在0.9以上。
1.5 统计学分析
采用SPSS 16.0进行统计学分析,采用混合实验设计,其中儿童类型为组间变量,分为人工耳蜗植入儿童和健听儿童两个水平;儿童年龄为组间变量,包括3岁、4岁和5岁三个水平;以情感语调类型为组内变量,分为两个水平,包括高兴和难过语调。以P<0.05为差异具有统计学意义。
2 结果
人工耳蜗植入儿童与健听儿童高兴与难过的语调发音得分及方差分析结果见表2,表3。
人工耳蜗植入儿童的情感语调得分显著落后同龄健听儿童(P<0.05)。人工耳蜗植入儿童与健听儿童不同年龄间得分无显著差异(F=0.479,P>0.05);不同情感语调(高兴和难过)的识别得分无显著差异(F=0.051,P>0.05);不同类别的儿童的平均分存在显著差异(F=362.436,P<0.05)。此外,各变量间均无交互作用(P>0.05)。
对不同年龄组进行多重分析可知,人工耳蜗植入儿童与健听儿童高兴和难过语调的发音在3岁和4岁无显著差异(P>0.05)、3岁和5岁之间以及4岁和5岁之间存在极显著差异(P=0.000<0.01)。
3 讨论
在言语中的情感语调变化是儿童交际能力和社会能力的核心,然而,目前对于儿童表达最基本情感(如高兴或难过)的韵律研究甚少。本研究证实并扩展了关于汉语人工耳蜗儿童情感语调发音缺陷的发现。
本研究中,两类儿童对情感语调的模仿发音随着年龄增长没有显著提高。进一步分析年龄差异发现,3岁与4岁之间没有显著差异,而3岁与5岁、4岁与5岁之均存在极显著差异。这说明情感语调发音能力的发展在5岁左右会出现快速发展阶段,且将会持续到学龄期。该结果与以往研究中结果一致:儿童主要的韵律区分发展在5岁[7],对韵律线索的熟练控制直到7岁才发展的比较完善[8]。
表2 3 ~5 岁人工耳蜗儿童与健听儿童情感语调发音得分(±SD )
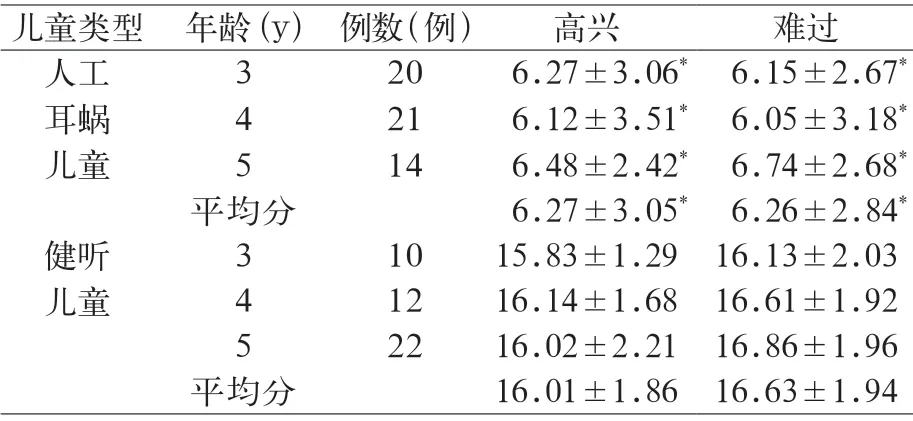
表2 3 ~5 岁人工耳蜗儿童与健听儿童情感语调发音得分(±SD )
与同龄健听健听儿童比较*P<0.05
儿童类型 年龄(y) 例数(例) 高兴 难过人工耳蜗儿童3 20 6.27±3.06* 6.15±2.67*4 21 6.12±3.51* 6.05±3.18*5 14 6.48±2.42* 6.74±2.68*平均分 6.27±3.05* 6.26±2.84*健听儿童3 10 15.83±1.29 16.13±2.03 4 12 16.14±1.68 16.61±1.92 5 22 16.02±2.21 16.86±1.96平均分 16.01±1.86 16.63±1.94

表3 情感语调发音的方差分析结果
相比于平静的语调,高兴表现出更高的音高、更宽的音域、更大的强度和更快的语速,而难过则表现出较低的平均音高、较窄的音域、较小的强度和较慢的语速[9、10],高兴和难过的声学差异比较大,容易从另外一个语调中识别出目标语调。通过现有研究分析,人工耳蜗植入儿童常见的错误是将高兴与生气或害怕混淆,将难过和平静混淆,而对有较大对比性的语调,如高兴与难过语调则表现良好[11]。儿童对于高兴和难过语调的识别并没有显著差异[3],因此本研究中高兴和难过语调的模仿发音也没有表现出显著差异。
在本研究中,人工耳蜗植入儿童比同龄健听儿童所产生的可识别情绪更少:人工耳蜗植入儿童模仿高兴和难过语调的平均得分仅为6~7分,而健听儿童的平均得分为16分左右。这种差距不仅显示人工耳蜗植入儿童和健听儿童在情感语调发音方面存在显著差异,还说明人工耳蜗植入儿童基本不能有效的模仿情感语调发音,模仿效果很差。究其原因,除了人工耳蜗植入儿童本身对韵律线索的处理困难,也可能由于在目前康复训练中,我们更多地关注语音清晰度,而不是语音韵律。这样的训练模式导致了人工耳蜗植入儿童在表达情感的句子中可以产生高度可理解的词汇,但是句子的情感部分往往不能被正确理解[12]。
综上所述,人工耳蜗植入儿童与健听儿童模仿高兴和难过情感语调发音存在显著差异,人工耳蜗植入儿童基本不能正确模仿情感语调。在人工耳蜗植入儿童的康复训练中,除了关注语音感知和语音可懂度的训练,特别要注意扩大对情感表达的关注,需要重视情感韵律的训练。
猜你喜欢
中国听力语言康复科学杂志(2021年6期)2021-12-21 07:21:54
厦门大学学报(哲学社会科学版)(2021年5期)2021-12-21 06:32:48
中华诗词(2019年1期)2019-08-23 08:24:12
乡村地理(2018年4期)2018-03-23 01:53:58
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:11
北方音乐(2017年4期)2017-05-04 03:40:10
海南医学(2016年8期)2016-06-08 05:43:00
听力学及言语疾病杂志(2015年5期)2015-12-24 01:47:05
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
华东理工大学学报(自然科学版)(2015年5期)2015-02-27 13:50:02
