
融合用户行为网络信息的个性化餐馆推荐
2020-10-09 01:04:02傅晨波郑永立周鸣鸣
浙江工业大学学报 2020年5期
傅晨波,郑永立,周鸣鸣,宣 琦
(浙江工业大学 信息工程学院,浙江 杭州 310023)
近年来,随着互联网技术的快速发展,在线餐饮平台服务越来越受到人们的喜爱,但是大量用户和商家菜品信息的涌入,也造成了信息过载的问题。因此,推荐系统作为一种高效的信息过滤系统对食物信息的搜寻者和传播者显得十分重要。目前,推荐系统已经广泛应用于各种在线餐饮服务中,如Yelp,OpenTable,以及国内的大众点评网,饿了吗等餐饮平台。
推荐系统主要是从大量的用户信息中,挖掘探索用户的就餐喜好模式或者用户之间相似性等进行推荐。其中,所需要的用户信息包括显式信息和隐式信息,显式信息比较准确,例如用户评分和评论等,隐式信息如浏览历史,用户资料,位置信息、社会关系等难以准确描述用户喜好。由于隐式辅助信息种类众多,处理方法各有不同,仍然是个性化餐馆推荐研究领域关注的热点。笔者从用户的行为信息和复杂网络的角度,挖掘了用户就餐序列之间的行为网络的拓扑结构关系,提出了一种融合用户行为网络信息的个性化餐馆推荐系统。笔者将首先介绍推荐系统的相关工作;然后介绍研究的数据集和融合用户行为网络信息的餐馆推荐模型,包括就餐位置转移网络和口味转移网络的构建,网络表征及用户行为信息的融合;接下来介绍模型对比方法、评价指标、实验设计参数及实验结果分析;最后进行总结和展望。
1 相关工作
传统的餐馆推荐系统主要分为两种类型,分别是基于内容的推荐系统[1](Content-based,CB)和协同过滤的推荐系统[2](Collaborative filtering,CF)。基于内容的推荐系统主要考虑餐馆之间或者用户之间的属性描述信息的相似度来进行推荐,而基于协同过滤的推荐系统则主要考虑外部的关系,例如用户-用户、餐馆-餐馆之间的相似性关系等。在协同过滤算法中,根据用户的餐馆评分信息,构建用户-餐馆评分矩阵,来进一步刻画用户之间或者餐馆之间的相似性并进行餐馆推荐,例如UserCF,ItemCF等。研究表明:基于协同过滤的推荐算法效果优于基于内容的推荐算法,并且基于内容的推荐系统也容易受限于属性描述的质量[3]。基于单一评分信息的协同过滤推荐算法仅仅依靠用户的评分信息[4],久而久之,缺少更多详细的用户喜好信息容易使用户对推荐物品感到厌倦。因此基于多标准评分信息的协同过滤推荐系统也逐渐被提出来[5-6]。
随着数据采集技术的不断完善,越来越多的在线数据能够被采集和利用,如用户或者商品资料信息[7-8]、评论信息[9]、用户位置[10]及用户社交关系[11-12]等。研究者通过这些辅助数据信息,挖掘出用户的潜在的喜好信息,进一步提高了个性化推荐系统的效果。例如,Bao等[9]通过同时考虑用户的评分和评论文本信息,利用矩阵因子分解技术,提出一个更高效的餐馆推荐模型TopicMF。Zhang等[10]利用用户历史就餐行为的位置信息,餐馆评论数,餐馆属性来探索用户的就餐偏好,进而设计一个组合的集成推荐模型框架,并在实际数据集上验证了模型的推荐效率。Zhang等[13]根据用户的评分信息将用户进行分组,然后通过结合组之间和用户之间的相似性,进一步提升个性化餐馆推荐模型的效率。
在现实生活中,复杂网络[14]是普遍存在的,许多复杂的系统都可以建模成网络图来进行表示,比如常见的计算机网络、交通网络以及社交网络等。复杂网络能够捕获网络系统中节点的各种拓扑结构特性,为具体的应用研究提供了一种重要的科学方法[14-15]。
随着网络科学的发展,基于网络图嵌入的推荐系统受到研究者的关注。例如,Ha等[16]利用用户的历史商品购买记录,构建了用户的购买商品网络,并提出一种基于商品网络的协同过滤推荐系统。Shi等[17]利用不同元路径的随机游走策略,从异质信息网络(Heterogeneous information network,HIN)中学习得到用户的向量表征,并应用到矩阵分解推荐模型中,能够取得较好的效果。Jiang等[18]在HIN中利用随机游走策略设计了一个贝叶斯个性化排序算法,依次来学习网络中连边的权重来进行标签推荐。Gao等[19]基于用户-商品的二分网络提出一种新的二分图嵌入算法,通过有目的地进行有偏随机游走策略来学习节点的向量表征,进而计算用户和商品之间的得分,进行排序推荐。
上述中,在基于用户商品网络或者用户-商品二分网络嵌入的推荐模型中,研究者从网络的角度挖掘了用户就餐序列之间的网络拓扑联系,并没有考虑辅助信息网络的隐含关系。在多尺度的辅助信息推荐模型中,已有的推荐工作中缺少考虑用户行为网络的拓扑结构之间的联系。笔者从用户就餐行为网络的角度,挖掘行为序列网络中隐含的地理和口味偏好信息,并提出了一种融合用户行为网络信息的个性化推荐系统。具体来说,从用户去过的历史餐馆列表中,提取用户的地理位置转移序列和口味转移序列并构建了就餐位置转移网络和口味转移网络。然后,利用复杂网络的知识方法挖掘用户历史数据中包含的行为喜好信息,并结合用户的评分信息构建组合的协同过滤餐馆推荐系统。
2 数据集介绍
本研究工作主要基于在线餐饮网站Yelp平台官方发布的第8届Yelp Dataset Challenge公开竞赛数据集。原始数据集中包含了2004年10月12日到2015年12月24日期间,242 个城市中的25 071 家餐馆信息,388 612 个用户就餐记录。每个餐馆具有一个或者多个口味标签,例如印度菜、意大利菜、快餐等,这也可以用来表征用户的就餐时的口味喜好。数据集中也包含每个餐馆精确的经纬度信息,此外还有评论,评分等信息。
为了更好地研究餐馆推荐问题,选取评论次数为50 次及以上的平台活跃用户作为研究对象。此外,依据用户的就餐行为数据,选择数据集中在线活动人数最多的两个城市作为实验数据集,分别为Charlotte和Scottsdale。实验数据中的具体描述信息如表1所示。

表1 Yelp平台中两个城市数据集的数据信息Table 1 The preprocessed data of two cities in Yelp platform
3 餐馆推荐模型设计流程
融合用户行为网络信息的个性化餐馆推荐模型整体流程框图如图1所示。该流程主要包括6 部分:1) 在原始数据中提取用户历史就餐行为的地理位置数据和口味信息数据;2) 构建用户基于地理位置的转移网络GFN(Geography forage network)和基于口味的转移网络TFN(Taste forage network);3) 通过网络图嵌入的方法得到网络中地理位置标签和口味标签的向量表征;4) 将用户历史行为序列用位置和口味的嵌入向量表征,融合用户行为信息,挖掘用户潜在就餐偏好信息;5) 将用户行为偏好信息和用户评分信息整合到协同过滤算法中;6) 最后得到融合用户行为信息的个性化推荐系统。
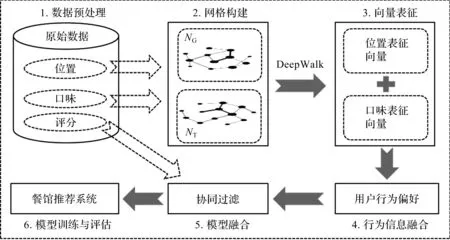
图1 融合用户行为网络信息餐馆推荐模型整体框图Fig.1 The overall framework of the recommender combining the user behavior network information
3.1 用户就餐地理位置迁移网络
Yelp数据集中提供了餐馆所在的具体经纬度信息,根据用户的历史就餐记录,可以得到用户的就餐历史位置序列。由于地理坐标过于精细化,因此将城市中的餐馆划分若干个区块,类似于真实生活中的具体商圈。采用文献[20]中的DBSCAN聚类算法来对餐馆进行区块聚类,使得数据集中每个餐馆对应唯一的一个地理位置区块。
对于用户u,其就餐的历史餐馆序列为{R1,R2,…,Rn},其中n表示用户u的去过的餐馆个数,Ri表示用户u第i次就餐时去的餐馆。根据餐馆的地理位置区块ci,可以得到用户的历史地理位置转移序列,进而可以构建用户的地理位置转移网络GFN。具体来说,网络中节点表示用户去过的餐馆的地位位置区块ci,如果用户访问了位置区块ci之后,下一次访问了位置cj,则产生了有向连边ci→cj。统计用户的所有连边信息,连边ci→cj的权重wij表示用户ui从位置区块ci向cj转移的频次。图2展示了某Yelp用户的地理位置迁移网络示意图。节点越大,连边越粗,表示该用户偏好在这几个地理位置之间就餐。最后,融合所有用户的GFN网络得到平台用户的就餐地理位置转移网络NG。
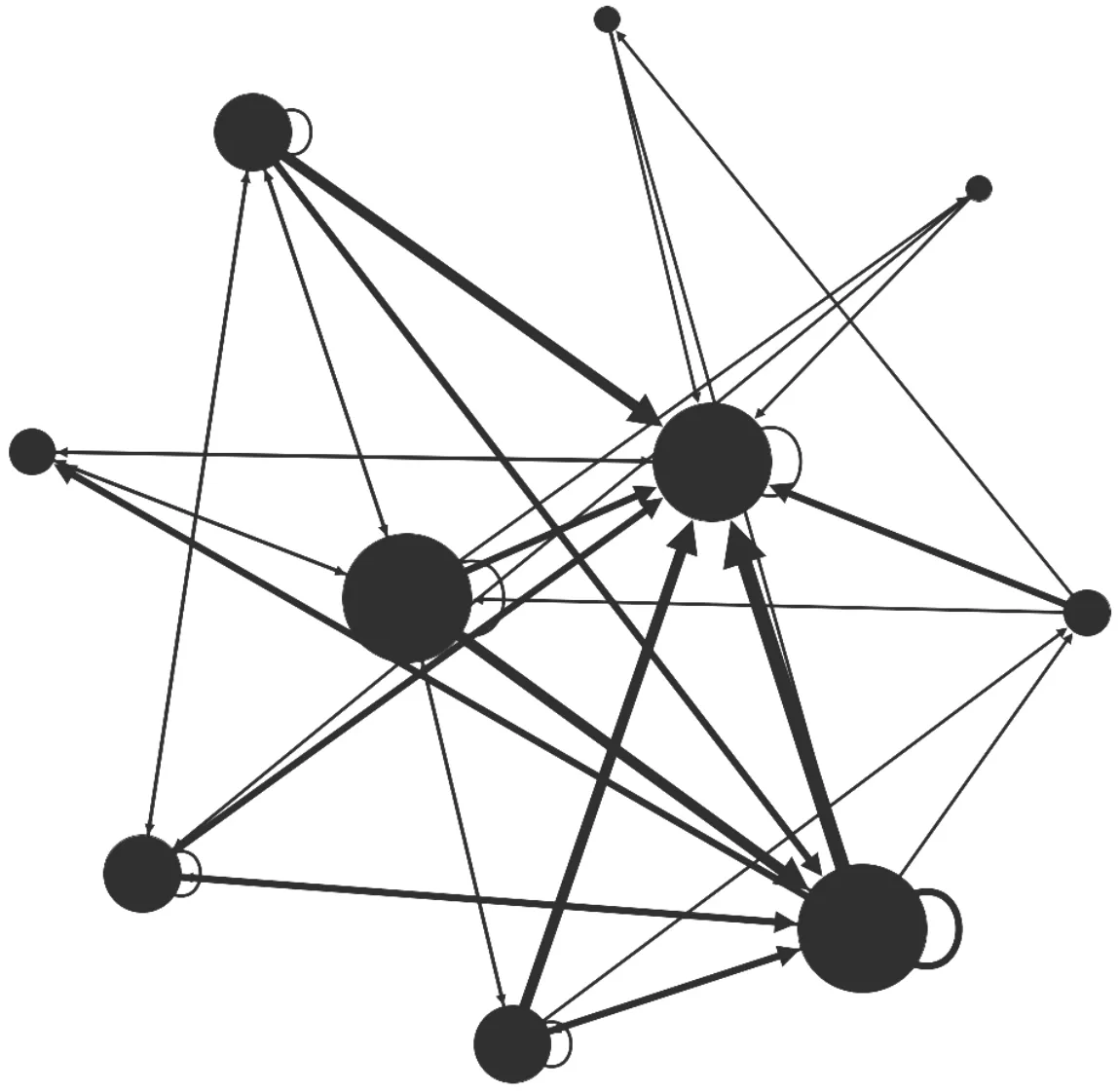
图2 某Yelp用户的地理位置迁移网络GFN示意图Fig.2 A transfer network GFN based on geography location of one user in Yelp
3.2 用户就餐口味迁移网络
在Yelp数据集中,餐馆的口味标签大部分不止一个。为了更好地描述用户在每次就餐时的口味喜好,采用高斯密度函数估计GDA(Gaussian denoise algorithm)[21]的方法来提取用户u每次就餐时的最中意的口味标签t。因此,根据餐馆的口味信息,得到用户的就餐口味转移序列。同理,按照上节中地理位置转移网络的构建方法,可构建用户的口味转移网络TFN。在网络TFN中,节点表示用户每次的就餐口味标签ti,有向连边ti→tj表示相邻的两次就餐餐馆的口味转移情况,连边权重表示用户u从口味标签ti向tj迁移的次数。图3展示了某Yelp用户的就餐口味转移网络,节点越大,连边越粗,表示该用户偏好于在这几个口味的餐馆之间就餐。最后,融合所有用户的GFN网络得到平台用户的就餐地理位置转移网络NT。
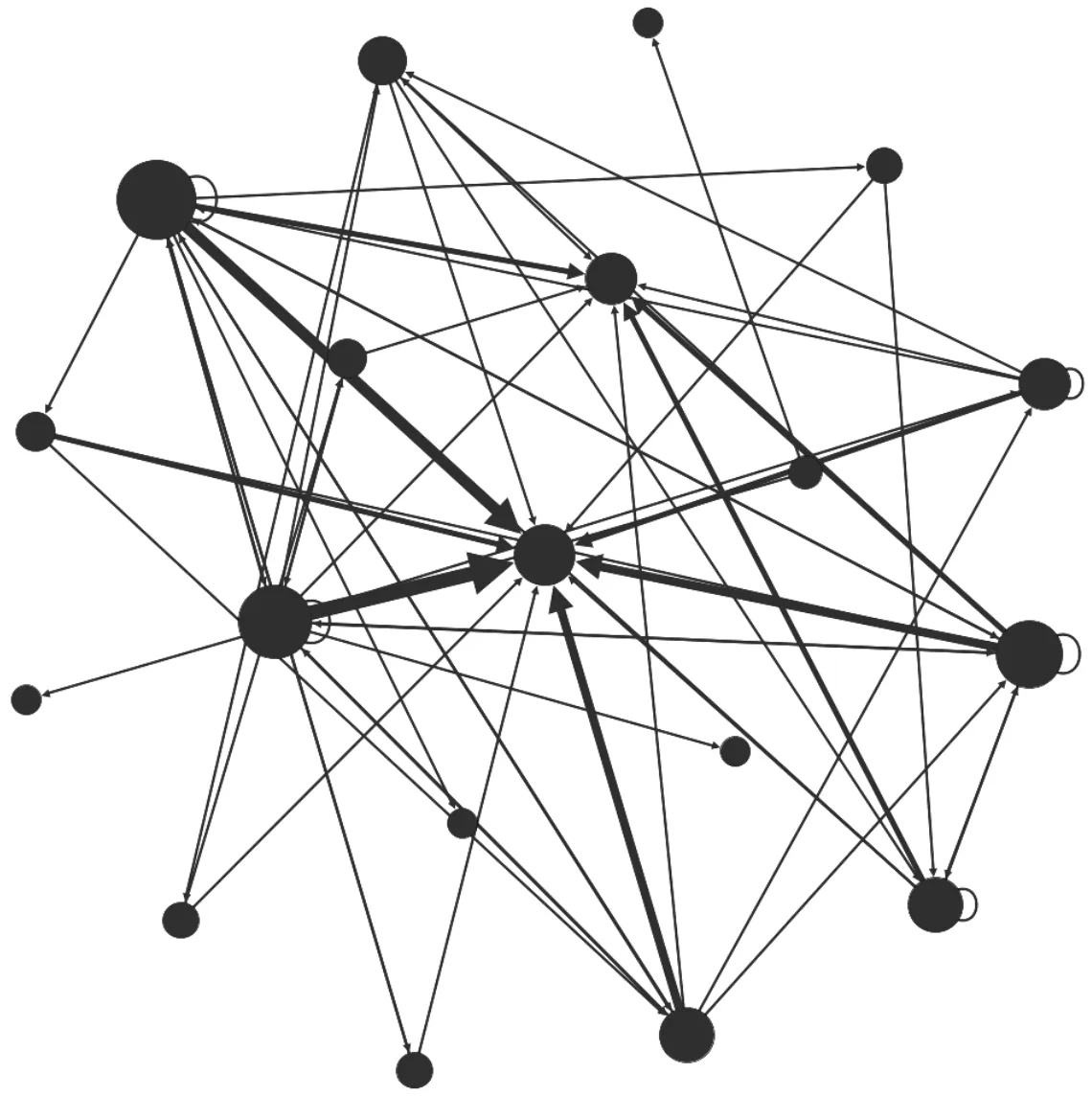
图3 某Yelp用户的就餐口味迁移网络TFN示意图Fig.3 A transfer network TFN based on cuisine tag of one user in Yelp
3.3 网络表征学习
网络是一种重要的表达对象之间联系信息的载体,如何合理地表示网络中的特征信息,一直以来是复杂网络研究领域的重要课题之一。网络表征学习[22]的目的在于将复杂网络中的节点用低维的向量来表示,从而将网络内在的拓扑结构信息转换成容易表示的空间向量形式,便于应用到后续的任务场景。
其中,DeepWalk算法[23]类比于自然语言处理领域的词表示学习算法Word2vec[24],将网络节点以向量的形式表达出来。Word2vec算法的主要思想是通过Skip-Gram模型,用词向量间的空间距离来表征文本中单词与其周围单词的亲疏关系。在DeepWalk算法中,首先以网络中每个节点作为起点,进行随机游走,然后合并每次随机游走的结果作为一整个随机游走序列。假设在网络G(V,E)生成的由节点V组成的随机游走序列中,将节点vi的左右两侧窗口区间为d的一组序列表示为vi-d,…,vi-1,vi+1,…,vi+d,Skip-Gram模型要求以节点vi为中心所产生的这组两侧序列的概率最大化,换言之,即可以通过当前节点来推测出周围节点。其目标函数为
(1)
其中概率函数p(vi+j|vi)的计算式为
(2)
式中:wv,w′v分别为节点v的输入向量与输出向量。
利用DeepWalk算法,分别对3.1,3.2节中用户的就餐地理位置转移网络NG与口味转移网络NT进行网络节点的表征学习,得到每个地理区块c所对应的嵌入向量wgeo,以及每个口味标签t所对应的嵌入向量wtas。
3.4 融合用户行为信息
对于每个餐馆,都对应着一组地理位置标签-口味标签(c,t),将地理位置标签c和口味标签t分别用嵌入向量wgeo和wtas来表征,合并两组一维向量,得到基于用户行为信息的餐馆向量表征w=[wgeo,wtas]。
因此,对于一个历史就餐的餐馆序列为{R1,R2,…,Rn}的用户u,则其历史就餐的餐馆序列可以表征为
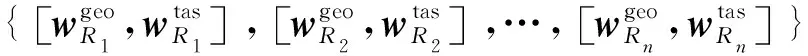
(3)
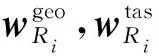
(4)
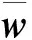
(5)
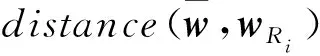
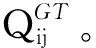
(6)
式中:a,b∈[0,1],表示两种模型预测得分的加权系数,选择模型评价指标作为目标函数,通过贪婪算法寻优选择最优的参数a,b。
4 实验设计及结果
本节主要介绍了4 种推荐系统的对比方法以及模型的评价指标,并介绍了模型的实验设计来验证融合行为信息的个性化餐馆推荐系统的效果。
4.1 对比方法介绍
1) 基于流行度的推荐算法(POP):该方法直接根据物品的流行度来对商品进行排序并推荐给目标用户。
2) 基于用户的协同过滤推荐算法(UserCF):根据用户对商品的评分信息,选择与目标用户最相似的用户,将其购买过的商品推荐给目标用户。
3) 基于商品的协同过滤推荐算法(ItemCF):根据用户的评分信息,选择与目标用户购买过的商品最相似的商品,将其推荐给目标用户。
4) 基于二分图嵌入的推荐算法(BiNE):BiNE
(Bipartite network embedding)是目前最好的二分图嵌入推荐算法[19]。它从两个方面来构建二分网络,分别是观察到的边所证明的显式关系和未观察到但传递的链接所暗示的隐式关系。并通过随机游走策略学习得到网络图中用户和商品的向量表征,计算用户与商品的向量内积得到用户对商品的喜好得分排序,进行推荐。
4.2 评估指标介绍
采用3 个常用的评价指标[25],来度量评价不同推荐算法的优劣,分别是准确度(Precision,P),召回率(Recall,R),F1-分数(F1-Measure,F1)。令U表示测试集中的用户集合,ui∈U。Q(ui)表示用户ui实际去过得餐馆集合,则这3 种指标的计算式为
1)P@k:准确度表示用户对推荐的餐馆感兴趣的比例,其计算式为
(7)
(8)
式中:top@k(u)表示模型向用户u推荐的前k个餐馆列表;hits(Q(u),top@k(u))=Q(u)∩top@k(u)表示在推荐的餐馆列表top@k(u)中用户u实际去过的餐馆个数,即被正确预测的餐馆的个数。
2)R@k:召回率表示推荐列表中让用户感兴趣的餐馆占所有感兴趣餐馆的比例,计算式为
(9)
(10)
3)F1@k:F1-分数可以看作是评价指标准确率与召回率的一种加权平均,在推荐系统中F1@k的计算式为
(11)
4.3 实验设计
在实验中,选择数据集中从2012年9月1日到2014年9月1日之间的数据作为训练数据,并构建Yelp社区的用户就餐地理位置转移网络NG和就餐口味标签转移网络NT。设定协同过滤算法UserCF和ItemCF方法中最相似的用户或者餐馆个数为50。此外,提出的组合推荐模型UserCF+GT和ItemCF+GT中各个单独模型的权重参数a和b调整范围为{0,0.1,0.2,…,1.0},选择模型评价指标F1-分数作为贪婪算法寻优模型的目标函数,通过网络搜索选择最优的权重系数a和b。在对比方法BiNE中,设置损失平衡参数α=β=0.01,γ=0.1;模型的学习率设置为0.025,最大迭代次数设置为100。随机游走模型中的最大、最小游走数maxT和minT分别设置为32和1。实验重复50 次,并记录平均值。
4.4 结果分析
首先在Yelp平台中活跃用户数最多的两个城市Charlotte和Scottsdale中比较了不同类型的餐馆推荐模型top@10的推荐效果,如表2所示。对比基本的协同过滤算法UserCF和ItemCF,组合推荐模型UserCF+GT和ItemCF+GT均展示出更好的推荐效果。这也验证了用户的历史就餐行为信息中包含着潜在的用户行为偏好信息,例如地理位置偏好,就餐口味偏好等。由于通过构建用户的就餐行为转移网络来挖掘计算用户的行为偏好信息,因此,也与最好的用户-商品二分网络嵌入的推荐方法BiNE进行比较,结果显示组合模型UserCF+GT在3 种评价指标上均表现最好。
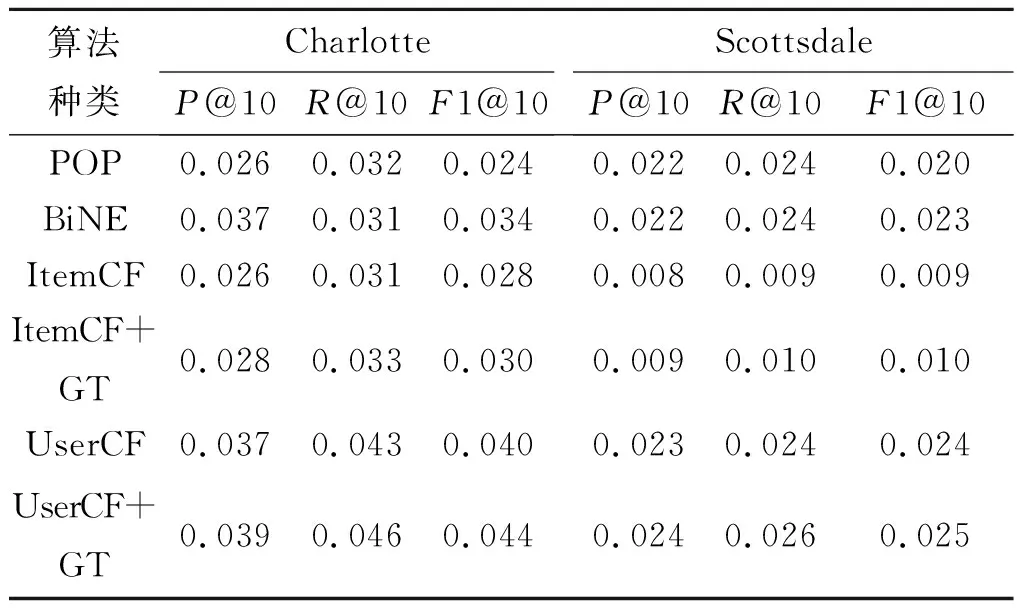
表2 不同的餐馆推荐方法在两个城市数据中的top@10推荐结果比较
此外,调整k的取值范围为[5,10,15,20,25,30],分析了不同推荐模型在top@k上的3 种评价指标的变化趋势,如图4所示。图4中展示,融合用户行为信息的组合推荐模型UserCF+GT和ItemCF+GT始终优于基本的协同过滤算法UserCF和ItemCF。模型UserCF+GT在k值较小时,表现出更好的推荐效果。随着k值的增加,不同的推荐算法模型的推荐效果也趋于相近,其中,F1分数和准确度P趋于稳定。
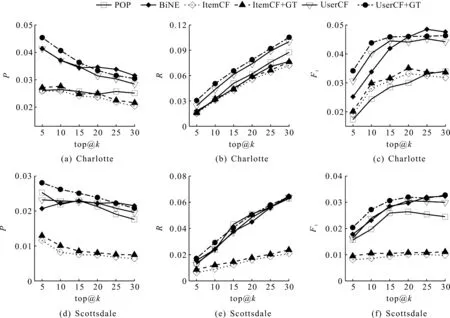
图4 6 种推荐模型在城市Charlotte和Scottsdale数据上随着不同k值的结果变化曲线Fig.4 The curve of the results of six recommendation models on Charlotte and Scottsdale with different k values
5 结 论
主要基于用户的历史就餐行为数据,构建了用户的地理位置转移网络和口味转移网络,利用复杂网络的方法挖掘了用户潜在的就餐偏好,并用怀旧指数具体刻画了用户每次就餐行为与历史就餐行为的差异变化。然后将该指标作为行为信息结合用户的评分信息,调整权重,改进传统的协同过滤推荐算法。最后,在真实的在线餐饮平台Yelp数据集中进行实验,发现融合用户行为信息的个性化餐馆推荐模型优于已有的协同过滤和二分图嵌入推荐模型。众所周知,用户就餐偏好是不断变化的,后续的工作可以研究用户行为偏好的时间变化情况,进而改进推荐模型。此外,也可以将怀旧指数融入到深度学习序列预测模型中,进而改进餐馆推荐模型的预测效果。
猜你喜欢
青少年科技博览(中学版)(2023年1期)2023-04-06 05:51:36
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
文苑(2020年5期)2020-06-16 03:18:10
故事作文·低年级(2017年9期)2017-09-12 20:02:01
漫画月刊·哈版(2017年2期)2017-03-27 14:21:01
漫画月刊·哈版(2016年7期)2017-01-20 21:08:49
漫画月刊·哈版(2016年5期)2016-07-11 11:23:05
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
