
具有特征选择的多源自适应分类框架
2020-09-29 06:56:08黄学雨徐浩特陶剑文
计算机应用 2020年9期
黄学雨,徐浩特*,陶剑文
(1.江西理工大学信息工程学院,江西赣州 341000;2.宁波职业技术学院电子信息工程学院,浙江宁波 315100)
0 引言
传统机器学习已经在当今的信息社会取得了瞩目的成就。而这些成就主要归功于大量的标记训练数据,并且基于以下假设:训练和测试数据独立于一个相同但未知的分布(Independent and Identically Distributed,IID)[1]。然而在实际各种领域应用中大量的数据都是属于非IID 数据。并且在这些领域中已标注的数据较少,需要人工准备充足的已标记训练数据,这是一个需要耗费大量人力物力的过程[2]。此外,收集样本的过程容易产生数据集偏差,从而导致由训练数据集中学习得到的模型在测试数据集下呈现并非十分理想的测试结果。因此,标记数据稀缺和数据集偏差是目前机器学习亟须解决的问题。由此领域适应学习(Domain Adaptation Learning,DAL)技术在现阶段得以迅速发展。在DAL 任务中学习领域通常分为两个相关但不同的类型,即源域和目标域[3]。旨在利用源域中的训练数据来解决目标域中的学习问题,两个域的数据分布可以相同或不同。但是强行将某些与目标域分布差异极大的源域自适应于目标域会导致DAL 中的“负迁移”问题[4]。为此,多源自适应学习被提出到DAL 的行列中,其旨在利用多个相关的源域,通过最小化源域之间的差异来辅助目标域的学习。多源自适应学习在现实中不同领域的应用上取得了出色的成绩。例如,文献[5]提出的A-SVM(Adaptive Support Vector Machine),该方法首先在多个源域上训练得到相应的分类模型,然后通过这些不同源域的分类模型来辅助目标域分类模型的学习。另外还有基于最小化均值偏差的学习的多源自适应方法如FastDAM(Fast Domain Adaptation Machine)[6]等。但目前的多源自适应方法仍存在一些问题至今没有得到妥善的解决:
1)如何处理域中训练数据可能含有部分无关或冗余的特征信息(例如,噪声和异常值)的问题。
由于源域的视觉训练数据可以从各种网站中随机获得,因此训练数据中的噪声和异常值比比皆是。现有方法盲目地将包含噪声和异常值的所有训练数据转换到共享子空间中,这可能导致学习得到的模型最终分类效果显著弱化。
2)如何有效挖掘多个源域中包含的相关信息的问题。
大多数多源自适应方法通常分别处理源样本而不考虑几个源之间的相关性,这将导致多源信息无法得到充分的利用使得最终的分类效果并非十分理想。
3)如何充分挖掘并利用目标域未标记数据内含有的潜在信息来提高模型性能。
近年来,虽然已有的一些方法能够应对上述的部分问题,但是目前还是没有一个统一的框架能解决上述的问题。文献[7]指出,通过L2,1范数对模型矩阵行稀疏化使其拥有稀疏特征选择功能,能够筛选出最具判别性的数据特征。除了剔除特征中存在的噪声信息以外,L2,1范数还可以通过消除冗余特征信息减小分类模型矩阵的特征维度提升算法计算效率。
具体来说,为了解决现有DAL 方法在视觉分类任务中存在的上述问题,本文提出一种具有特征选择的多源自适应分类框架(Multi-source Adaptation Classification Framework with Feature Selection,MACFFS)。所提方法主要创新点在于:
1)引入迹范数正则化来探索多个源之间的共享信息,并通过优化得到的权重值整合多源信息,利用L2,1范数损失函数来减轻噪声或离群值的影响,提出了一种具有特征选择的鲁棒多源自适应分类框架。
2)将框架的全局优化解转换为一个广义特征分解问题,并对整个过程进行了详细的理论证明。同时给出了基于该框架的简单有效的算法步骤。
3)分别在几个不同应用场景所对应数据集上进行了全面的实验,以验证所提出的框架的高效性与鲁棒性。
1 多源适应无监督分类框架
为便于描述,此处先提前介绍文中符号的意义。本文用A∈Rd×n表示大小d×n的矩阵,Ai,j对应于矩阵中的(i,j)元素。此外,分别用表示矩阵的L2,1范数和Frobenius 范数。矩阵A的迹表示为tr(A)。用In定义大小为n×n的单位矩阵。用1n∈Rn表示元素都是1的列向量。
1.1 问题描述
为解决现有方法存在的问题,MACFFS 框架需具备以下两个主要特性:1)有区别地利用多个标签丰富的源域来协助标签稀缺的目标域中的学习任务;2)通过目标领域潜在信息增强模型的分类性能。本文所提方法将联合共享子空间学习与多源模型迁移,并利用图流形正则化[8]有效提升目标学习性能,最终形成一个统一的框架。
1.2 框架的提出
给定包含n个d维向量的目标数据集X=[x1,x2,…,xn]∈Rd×n,其对应的标签集为Yt∈{0,1}n×c,c是类的数量。在多标签分类问题的情况下,对于每个输入向量xi∈X∈Rd×n(1 ≤i≤n),假设yi∈Yt是与之相关的输出标签,如果xi被标记属于j类别,则yi,j=1;否则yi,j=0 。本文提出的无监督框架假设目标数据集不含有任何标签,即目标域的标签集为一个标签预测矩阵F∈{0,1}n×c(初始为一个全零矩阵)。将样本大小为nv的第v(v=1,2,…,M)个源域数据集表示为,其对应的标签集为
传统的有监督学习算法通过将原始数据x映射为某个类别标签值y从而获得预测函数f(x)[9]。即最小化如下正则化经验误差函数:

其中:loss(⋅,⋅)为某个损失函数,Ω(⋅)为正则化函数,μ≥0 为正则化参数。视觉数据的特征之间存在某些共享属性,通过这些相关信息可以强化分类模型的学习。基于该思想,本文通过线性变换矩阵Pv∈Rd×r将第v个源域的特征投影至共享子空间中,其中r是特征子空间的维数。因此,可在(1)的基础上将第v个源领域的分类模型学习形式化为以下优化问题:
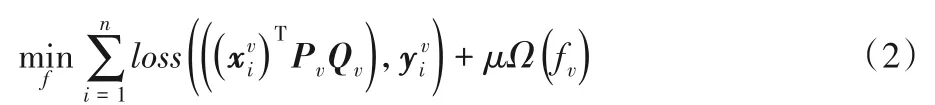
其中:Qv∈Rr×c为共享子空间内的权重矩阵,μ是正则化参数。通常可以使用经典的最小二乘损失函数来学习(2)中的预测函数,但是极易受异常值和噪声的影响。因此,在本文的框架中使用L2,1范数损失函数增强其鲁棒性减轻噪声/异常值对目标数据的干扰,并利用正交约束使得在新空间中的各个特征相对独立。则该源域的共享特征子空间学习目标函数(2)可描述为:
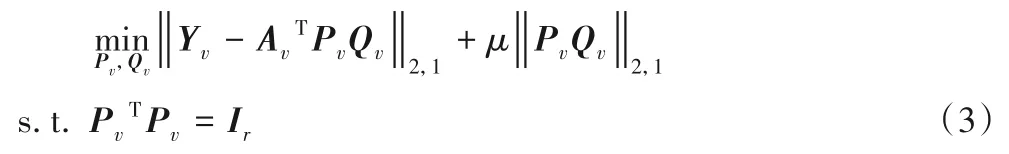
与源域类似目标域的学习函数为:
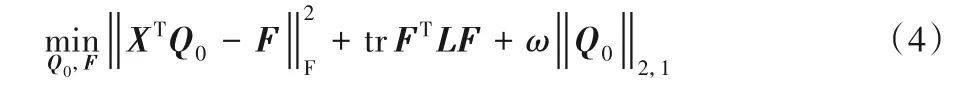
其中:ω为正则化系数;Q0为是针对目标域数据的权重矩阵,同时利用‖ ⋅ ‖2,1保证Q0的行稀疏。为了充分利用目标域的信息用于目标分类器的学习,加入了另一个正则化项:流形正则化项[8]。其中L为定义于目标领域数据邻接图上的Laplacian 矩阵且L=Δ-Γ。其中:Δ为一个对角矩阵,第i个元素为为图权值矩阵,当样本xi和xj为k近邻时,矩阵元素Γi,j=1,否则Γi,j=0。
为了将M个源域的知识共同作用在目标域中,进而统一学习目标域分类模型提出具有特征选择的多源自适应分类框架:
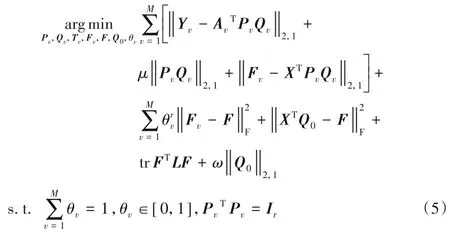
其中Fv为目标域实例通过每个源分类器所得到的目标分类标签。而是一个全局正则项,它要求目标域特征数据在每个源分类模型中得到的分类结果与一个统一的分类结果F对齐。本质上其目的为使Fv在不同的源分类标签矩阵之间建立桥接,使来自一个源的信息可以被利用到另一个源。其中参数θv表示不同源对目标预测的不同贡献度。
图1 为MACFFS 的示意图。结合图1 可以看出框架学习的具体过程如下:将多个源域的视觉数据投影至不同的隐空间并利用L2,1范数的稀疏特性选择有效特征剔除冗余信息,最后学习得到M个源域分类器。将无标签的目标域数据通过M个源域分类器得到M个标签矩阵,并根据不同的权重整合所有的标签矩阵最终得到一个统一的目标域标签矩阵用以目标分类器的学习。

图1 MACFFS示意图Fig.1 Schematic diagram of MACFFS
2 优化算法
本文将采取交替优化的策略来对目标函数(5)进行求解。其主要原因为避免式中关于L2,1范数的非平滑变量导致整体目标函数不能形成一个闭合的形式。为便于优化,定义Tv=PvQv。另外在优化过程中,将采取先设θv为已知常量从而优化其他变量的策略。因此,得到目标函数的优化求解表示为如下形式:


3 半监督式MACFFS
3.1 半监督框架与算法的提出



算法1 由里外两个循环组成,外循环为一个迭代循环,而里循环依次对每个源域的相关变量进行优化更新。当遍历完所有源域后,将所有更新后的变量代入到式(19)得到一个值Ωt,并继续进行下一轮的迭代。当达到条件时,预示着算法收敛迭代完成。最后输出所有优化完成的变量。
3.2 目标域样本标签计算方法
本文将这些多个源域分类模型得到的决策值通过不同源域的贡献度θv线性融合作为最终决策值。换句话说,来自目标域的样本xi对应的标签决策值yi由下式给出:

4 实验与结果
4.1 实验设置
分别对本文提出的MACFFS与相关的多源自适应方法在Caltech-256+Office 数据集和TRECVID 2005 数据集上进行实验分析,以证明所提方法对各种任务的广泛适用性和相较于其他方法性能方面的优异性。
根据实际的视觉分类任务,将所提方法与几个多源自适应方法进行比较。具体方法如下:
1)TCA(Transfer Component Analysis)[10];
2)A-SVM[5];
3)DSM(Domain Selection Machine)[11];
4)FastDAM[6];
5)Multi-KT(Multi Model Knowledge Transfer)[12];
6)MACFFS变体方法:MACFFS_1和MACFFS_2。
其中加入MACFFS变体方法的目的为验证本文所提框架各个组件的必要性,其具体形式与验证目的如下:
1)设置θv=1/M的MACFFS,简称为MACFFS_1:通过此设置使框架在相同权重多源适应的情况下进行性能评估。
2)设置μ=0 和ω=0 的MACFFS,简称MACFFS_2:此设置的目的为评估没有特征选择项的MACFFS的性能。
关于TCA、DSM、FastDAM、Multi-KT 和A-SVM 中的参数按照各自文献中的最优设置来选择。其中高斯核参数γ通过在源集上交叉验证得到一个公共值。
在本文的方法中主要有3 个模型参数,即α,μ和ω,这些参数在{10-6,10-5,…,106}范围内进行调整,根据经验设置最近邻数k=5。本研究将使用五重交叉验证法针对每个参数选取最优值,每次参数的设置都将重复5 次实验,并取平均值作为最终的实验结果。
4.2 数据集描述
4.2.1 目标识别任务数据集
Caltech-256+Office 数据集包含来自4 个域的图像:Amazon(A)、DSLR(Digital Singular Lens Reflex)(D)、Webcam(W)和Caltech-256(C)。Caltech-256与Office数据集之间共有10 个通用类,总共包含2 533 张图像[13]。在实验中,所有图像均按保留比例调整大小为150×150 并对所有图像使用6 种特征表示:CH(Color Histogram)、LSS(Local Self-Similarity)、PHOG(Pyramid Histogram of Oriented Gradients)、SIFT(Scale-Invariant Feature Transform)、CSIFT(Color Scale-Invariant Feature Transform)[14]和SURF(Speeded Up Robust Feature)[15]特征。将每幅图像的6 种特征表示拼接组合为一个新的特征向量。当作为源域时,Amazon/Caltech 每类使用20 个训练样本,而DSLR/Webcam 每类使用8 个训练样本。当其作为目标域,都仅使用3 个已标记的样本作为训练数据,目标域中的其余数据用于测试。另外,本文从Caltech-256中随机抽取10类和20 类组成两个集合分别进行目标识别。第二组是在第一组的基础上再随机添加10 类获得。在基于Caltech-256 数据集的多源适应任务中,将依次把其中一个类别视为目标域,其余的视为源域,最终得到的平均识别率用于评估几个方法在Caltech-256 数据集中多源情况下的识别性能,该数据集包含256 个对象类别的图像以及杂乱类别的图像,这些杂乱类别用作对象与背景问题的负类别。
4.2.2 视频概念识别任务数据集
TRECVID 2005[16]是最大的视频语料库之一。该数据集由从6 个不同广播频道收集的108 个小时视频节目的61 901个关键帧组成,包括2 个汉语频道CCTV 与NTDTV(New Tang Dynasty Television),3 个英语频道CNN(Cable News Network)、MSNBC(Microsoft National Broadcasting Corporation)和NBC(National Broadcasting Company),以及一个阿拉伯语频道LBC(Lebanese Broadcasting Corporation Television)。表1列出了每个频道中关键帧的总数(除MSNBC 以外)。为所有关键帧提取6 个视觉特征:SIFT、SURF、GiST(Generalized Search Tree)[17]、LBP(Local Binary Pattern)、PHOG 和WT(Wavelet Texture)。每个样本的多个特征经过与目标识别任务中相同的方法组合得到新视觉特征向量。从LSCOM-lite词典中选择了36个视频概念,该词典涵盖了广播新闻视频中存在的36个主要视觉概念,包括对象、位置、人物、事件和节目。通过手动注释这36 个概念,以描述TRECVID 2005 数据集中关键帧的视觉内容。在实验中,本文将两个英语频道(CNN 和NBC)和两个汉语频道用作源域,选择阿拉伯语频道作为目标域,并在其中随机采样10 个样本以进行标记加入到训练数据中。另外本文还通过设置CNN_ENG 为目标域,其余的频道为源域测试不同目标域标记样本的数量对性能的影响。在所有设置中除训练数据外,来自目标域的其余样本用作测试数据集。
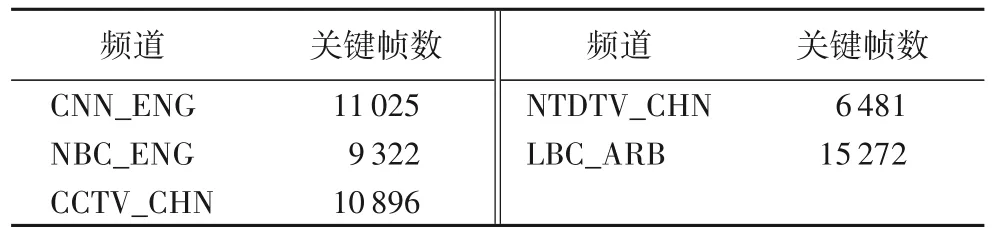
表1 TRECVID 2005数据集说明Tab.1 Description of TRECVID 2005 dataset
4.3 实验结果与分析
实验中分别比较了本文的方法与其他基准方法在多个源适应设置中对上述两个跨域学习任务的识别性能,并在图2~5中报告了实验结果。其中,图4和图5(b)分别显示了所有比较方法在不同标记目标样品数量下的识别结果。根据不同的算法在不同实验设置中的识别率,可以分析得到如下几个结论:
1)如图2、3 与图5(a)所示,Multi-KT 和FastDAM 的性能不稳定。这可能是因为所选的内核函数并不适合所有情况。从图5(a)可以观察到,Fast-DAM 和Multi-KT 实现了相似的性能。但是,在大多数情况下,Multi-KT 比Fast-DAM 稍差一些。这是由于在多源自适应在视频识别这样的复杂场景中,Multi-KT 几乎无法有效地估计要自适应的源域的权重。而另一个有趣的观察结果是,在大多数情况下,TCA 与A-SVM 通常比其他DAL 方法差,这可能是由于TCA 在多个源域的情况该方法只能平均分配给每个源相同的权重,而A-SVM 表现较差的原因是由于目标域中的有价值的未标记数据在A-SVM 中未被完全利用。在大多数情况下,本文所提出的方法的性能都要优于其他比较方法。例如,在图2 中,在大多数情况下所提方法的结果始终优于其他算法(除了在D,A→W 目标识别任务中识别率略低于DSM 方法)。这证明了本文的模型在视觉识别中具有较高的有效性。
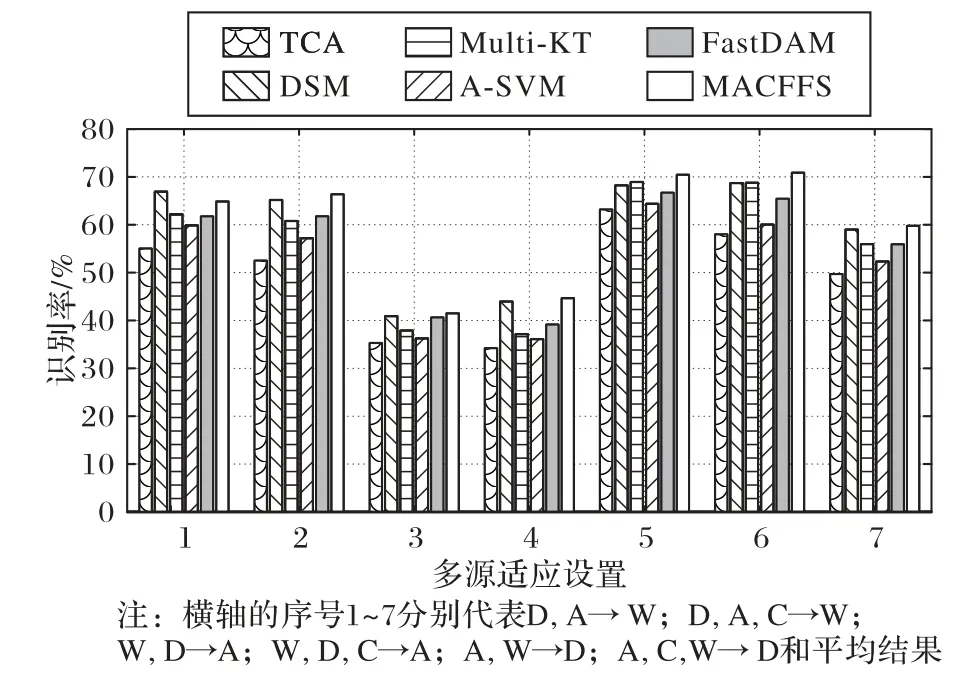
图2 Caltech-256+Office数据集的识别率Fig.2 Recognition rate on Caltech-256+Office dataset

图3 Caltech-256数据集的识别率Fig.3 Recognition rate on Caltech-256 dataset
2)为了进一步评估在具有不同先验信息的情况下算法的性能,本文在实验中通过更改标记目标样本的数量,以研究所提方法的性能。从图4 和图5(b)可以看出除DSM 以外,所有方法在所有情况下都可以通过标记更多的目标样本实现更高的识别精度,这表明利用标记的目标数据来改善学习性能是有益的。当带标签的目标样本数量逐渐增加时,FastDAM 方法获得最为显著的性能提升。此外,可以观察到本文的方法在所有多个源设置中性能都可以平滑地提升。这说明即使仅使用较小数量的标记目标数据,MACFFS 仍可以获得较高的识别准确率。但是,其他DAL 方法(尤其是FastDAM)只能在标记的目标样品数量相对较大时,才能得到令人满意的性能。
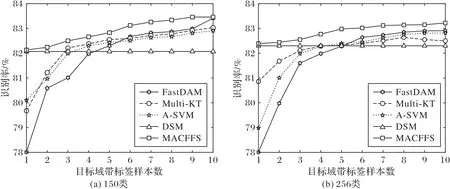
图4 多源扩展性Fig.4 Multi-source scalability
3)在图3 中,20 类的识别率在某种程度上明显高于10 类的识别率。在其他任务(例如在图5(a)的视频概念识别任务)上也可以观察到相同的结果,即当源域数量逐渐增加时,本文的方法在性能上获得了明显的改善。此外,可以在图5 中观察到,图5(b)中各方法的性能比5(a)要更好,可以由A-SVM与Multi-KT 两个方法在两图中的比较观察得到。具体的,在图5(a)中A-SVM 与Multi-KT 识别率大概为30%(A-SVM 甚至在30%以下),而在图5(b)中,两个算法的识别率都有提升(在标记样本数达到10 时,两个方法的识别率都高于35%)。这是由于在图5(b)任务中源域中有与目标域类似的英文频道因此源域可迁移至的目标域的有用信息会更多。在进行实验之前,本研究期望通过增加相关源域的数量,从而增加找到适用于目标域的有用先验知识的可能性。而这些实验结果验证了该方法的有效性:结合从更多来源领域中获得的判别信息可以进一步提高适应性能。
4)对于任何开放式学习系统,已知对象类别的数量会随着时间的增长而增加。由于需要针对新任务检查每个已知模型的可靠性,随着源域的大量增加可能会在领域适应学习中存在能否扩展的问题。具体而言,对于100数级以上的源域个数,上述领域适应方法在计算方面变得极为昂贵且对识别性能会有所影响。因此本文对来自Caltech-256数据集的150个和256个对象类进行了实验,分别在图4 中报告了MACFFS、Multi-KT、DSM、FastDAM 和A-SVM的实验结果。在这两种情况下,可以看出对于极少的已标记目标训练样本,正确选择每个源域的权重相对于所有来源的平均值是更有效的方式:在少于三个目标训练样本时,MACFFS和Multi-KT优于FastDAM和A-SVM。同时这也表明了当拥有足够的训练样本和丰富的域集时,最有效的方法是不要忽略任何源域的信息。
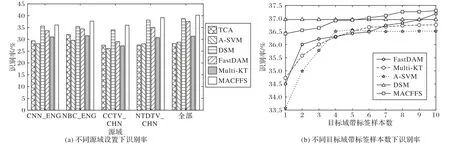
图5 视频概念识别任务中不同设置下的识别率Fig.5 Recognition rates under different settings in video concept recognition task
除此之外,本文还在两个视觉识别任务中分别测试了MACFFS 与MACFFS 变体方法(MACFFS_1 和MACFFS_2)的实验性能,其结果显示在图6中。通过分析可得到如下结论:
1)MACFFS 性能明显优于MACFFS_1。这些效益归因于每个源域在信息迁移至目标域时具有不同的权重可以达到减少冗余信息的效果,从而有利于提高性能。
2)通过MACFFS 与MACFFS_2 的性能比较可知,如果去除特征选择项,MACFFS 的性能将在一定程度上退化。原因是由低级视觉特征表示的图像可能会引入过多的噪声信息,导致其降低性能。这同时也证明了协同回归中特征选择的必要性。

图6 MACFFS变体方法在多个识别任务中的识别率Fig.6 Recognition rates of MACFFS variant methods in multiple recognition tasks
4.4 算法收敛性与时间复杂度分析
由上述可知,本文所提算法1 为一个交替优化过程,图7显示了在上述两个真实数据集上的算法的收敛曲线。从图7可以看出,目标值通常会在10 次迭代中收敛。这是由于所需优化的函数为一个凸函数,因此函数可以在少量次数的迭代后收敛。另外可以从图8 中看出本文的算法在计算时间并不占优势(计算时间与最快的A-SVM 方法相差10 s 左右)。导致这个现象的主要原因是由于算法中对一些矩阵逆的计算所需要的时间复杂度为O(d3),另外对矩阵的特征分解的时间复杂度为O(d3)。因此,算法整体的计算时间会相对较长。但是从各个实验结果中可以看出通过牺牲一定的时间效率所获得的性能的提升还是非常可观的。
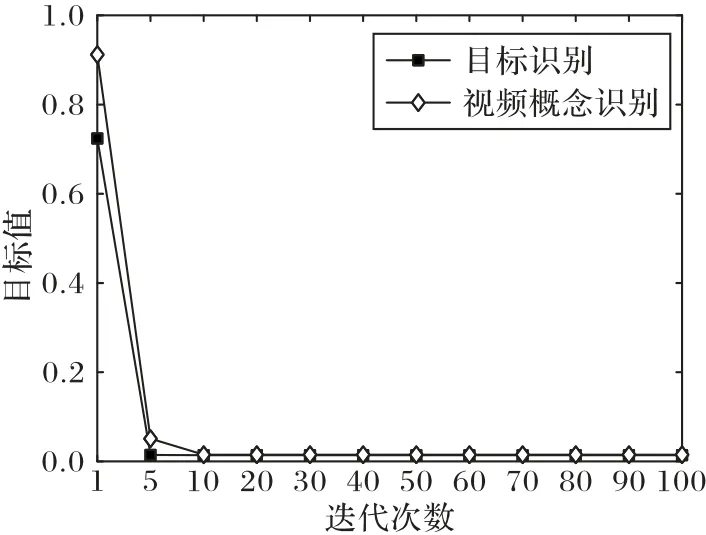
图7 算法收敛曲线Fig.7 Algorithm convergence curves
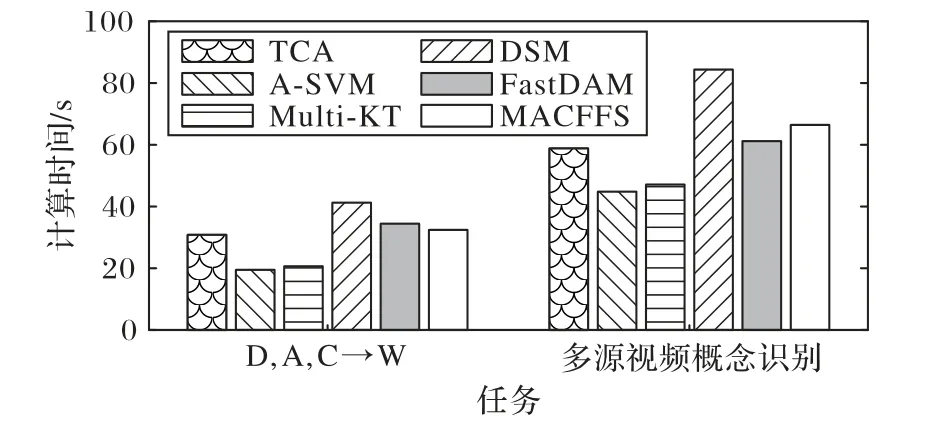
图8 算法计算时间Fig.8 Calculation times of algorithms
5 结语
本文提出了一种新的具有特征选择的多源自适应分类框架(MACFFS),旨在将来自多个源域的多个特征数据同时在不同潜在空间中学习得到分类模型,并将得到的源域分类模型用以目标数据的分类,最终对得到的分类结果进行整合并有区分性地帮助目标分类模型的学习。此外,还通过在几个跨域视觉识别任务上进行实验和分析,证明本文的方法与其他相关的最新算法相比的优越性与框架中几个组成项的重要性。然而,在MACFFS 中仍然存在两个问题需要在后续的工作中展开研究并设法解决。第一个问题是如何降低该方法在高维和大规模数据集中计算的时间复杂度。MSMFR 中的最佳模型参数是数据相关的。因此,另一个问题则是如何自动确定所提方法的最优参数。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
计算机技术与发展(2020年11期)2020-12-04 07:50:46
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
车迷(2018年11期)2018-08-30 03:20:32
中国交通信息化(2018年3期)2018-06-13 03:27:58
海峡姐妹(2018年3期)2018-05-09 08:21:02
中国交通信息化(2016年2期)2016-06-06 07:28:02
公民与法治(2016年10期)2016-05-17 04:12:58
电子与信息学报(2015年12期)2015-08-17 11:14:42
