
基于DeepLab v3的西藏地区降雨云团分割方法
2020-09-29 06:57:08张永宏王剑庚
计算机应用 2020年9期
张永宏,刘 昊,田 伟,王剑庚
(1.南京信息工程大学气象灾害预报预警与评估协同创新中心,南京 210044;2.南京信息工程大学自动化学院,南京 210044;3.南京信息工程大学计算机与软件学院,南京 210044;4.南京信息工程大学大气物理学院,南京 210044)
0 引言
降雨是高原山地滑坡、泥石流等自然灾害的主要的诱发因素,并且对流性降水具有易突发、分布广的特点,因此加强监测对流天气对于防灾减灾有重大意义。目前以数值预报法和雷达回波外推法为主的降雨预测方法在平原地区预测较为准确,如陈森发等[1]、赵欣等[2]使用数值预报法利用函数关系建立物理方程,模拟大气运动模型,进而意味着降水变化将被规律化、公式化,计算机对初始状态演变的预测具有很大的不确定性,并且数学模型建立复杂,反而会限制模型的准确性;而文献[3]使用的雷达回波外推法虽然应用在平原地区时精度较高,但先后使用光流估计法和外推雷达回波两种方法容易产生累积误差,要设置合理的模型参数就变得很困难,模型参数的好坏会直接影响预报是否准确,实际雷达回波在生长、消亡的过程中反射因子不守恒,利用偏微分方程求解光流场只适用于回波间运动较小的情况,对移速较快的回波误差较大。所以对于面积广阔、地面雷达观测站稀少、自然条件复杂、气候多变的青藏高原,数值预报法与雷达回波外推法并不适用。因此本文利用我国新一代的气象卫星风云四号A 星多通道扫描成像辐射计(FengYun-4A/Advanced Geostationary Radiation Imager,FY-4A/AGRI)高光谱分辨率、高时间分辨率、高空间分辨率的特点,弥补以上雷达观测手段在监测、预警方面的不足,再结合深度神经网络进行短时降雨云团分割,提取对流云团降水特征,以此提升对流等高时空变化天气现象的监测预警水平,得到有价值的卫星云团降水检测预警信息。
国内外对于对流云团识别已开展很多研究,卢乃锰等[4]通过气象卫星红外云图发现降水云团云顶亮温与温度梯度具有较强的相关性;李森等[5]通过“逆向搜索法”提取强对流云团的轮廓信息,再对其进行平滑处理以识别卫星云图中的强对流云团;赵文化等[6]利用静止气象卫星红外通道数据对比分析微波观测数据获得对流云团与雷达回波强度的关系,从而确立对流云团识别阈值;周晓丽等[7]分析红外、水汽通道及通道差的光谱特征,利用统计方法确定阈值范围后建立对流云团多阈值识别方法;吴晓京等[8]利用模糊支持向量机(Fuzzy Support Vector Machine,FSVM)建立雨强与云团特征之间的机器学习数学关系标识强降雨云团;Wolf等[9]针对不同强度的对流云团分别设定亮温阈值的方法检测对流云团;Mahović等[10]通过气象卫星的通道差值自动识别对流云团。以上采用设定阈值识别对流云团的方法要求较高的先验知识,不能自适应提取降雨云团特征,并且其泛化、分类能力不佳。如今,许多研究人员将迁移学习应用到遥感图像分割领域:许玥等[11]结合U-net架构与全连接条件随机场,在缩短预测时间的同时提升精度并得到更加细致的分割边缘;周明非等[12]使用均值漂移算法对经过纹理去除的遥感图像进行无监督聚类,达到分割的目的;夏勇等[13]提出了一种基于数学形态学的多重分形估计算法,描述遥感图像中的纹理信息,并构造了基于图像四叉树的多尺度分割方法来降低计算复杂度。
因此,本文提出了一个能够充分提取新一代气象卫星FY-4A/AGRI 多个通道光谱特征信息,并且具有高精度,适用于高原地区、复杂地形的降雨云团分割预测模型。陈天华等[14]首次将DeepLab v3应用于遥感图像分割得到较好的像素级分割结果,并且此分割网络具有高性能和结构简单的特点,因此本文以DeepLab v3 为基础,优化上采样方式及空间金字塔网络结构,通过融合语义分割模型中不同卷积层的特征,学习从低层到物体层次的多尺度边缘信息,为语义分割提供丰富准确的物体边界信息[15],添加注意力机制模块,并使用同步长卷积替代池化层,组成完整的检测、分割降雨云团的流程,为高原地区的降雨预测、预报提供参考价值,为易发生高原山地泥石流、滑坡等自然灾害的地区提供预警。
1 降雨云团分割模型
1.1 模型总体框架
本文是对西藏地区的高原降雨云团进行检测分割,然而受复杂山地的下垫面影响,其光谱特征复杂多变,并且降雨云团刚性结构差,边界轮廓多变,大小变化无规律,无法使用同一尺度提取特征,降雨区域与背景的比例严重失衡,为降雨云团检测与分割大大增加了难度。为了解决这些难点,本文在网络结构的设计和优化过程中,着重于小降雨云团的检测分割与边缘轮廓的提取,增强模型的泛化能力。同时,基于深度卷积神经网络的语义分割模型对样本中正负样本的平衡度非常敏感,平衡的数据集很大程度上提升模型的分类性能,本文改进多尺度特征采样,并且加入注意力机制模块解决正负样本不平衡的问题。模型训练和测试流程如图1所示。

图1 降雨云团分割模型训练和测试流程Fig.1 Training and testing process of rainfall cloud segmentation model
本文使用的改进后的DeepLab v3 语义分割模型如图2所示。
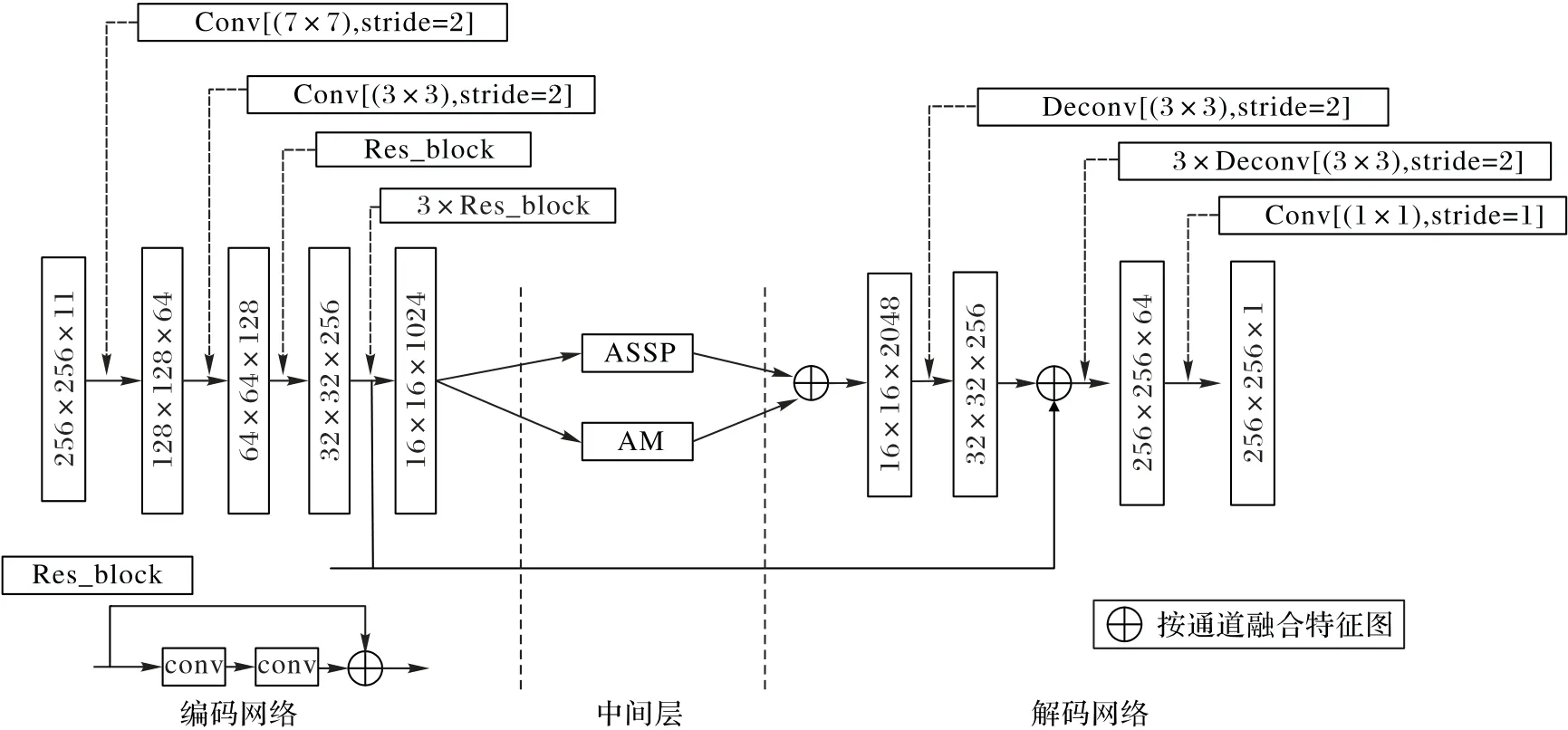
图2 降雨云团分割模型Fig.2 Rainfall cloud segmentation model
使用Tensorflow深度学习框架进行构建,该模型主要由编码网络、空间金字塔模块(Atrous Spatial Pyramid Pooling,ASPP)、注意力机制模块(Attention Module,AM)、解码网络四部分组成。编码网络的输出通过注意力机制模块和空间金字塔模块的输出融合作为解码网络的输入,并且当下采样输出步长(output_stride)为8 时,将低层级提供的细节特征信息融入到上采样过程中。
编码网络对输入数据下采样,由一个步长为2、卷积核大小为7×7 的卷积层,一个步长为2、卷积核大小为3×3 的卷积层和4 个残差模块组成,输入数据每经过一次卷积或残差模块,特征图的宽和高都会缩小为上层的1/2,但特征图的深度为上层的2 倍,此下采样过程将高维向量转换为低维向量,实现了高维特征的低维提取,残差模块的使用有利于减少深层神经网络训练时产生过拟合的现象。原始的DeepLab v3在下采样过程中使用的最大池化层虽然能够捕捉降雨云团的平移不变性特征,多个最大池化下采样层可以为分类器鲁棒地获取更多的平移不变性,但是得到的特征图空间分辨率会相应地降低[16],不利于云团的边缘特征提取,损失了特征图重要的边界分割信息,因此使用了相同步长卷积层来代替最大池化层,使得特征图中云团的边界部分得以保存,更有利于一些细小云团的检测。在模型的中间层除了原有的空间金字塔结构,本文加入了全新的注意力机制模块,进一步提升模型的特征提取能力,极大提升了中间层提取降雨云团高维特征的能力。解码网络上采样恢复特征图分辨率,由4 个步长为2、卷积核大小为3×3 反卷积层和1 个步长为1、卷积核大小为1×1的卷积层组成,每经过一次反卷积特征图的宽和高都会放大2倍,但特征图的深度为上层的1/2,最后一层卷积使特征图达到同标签相同维度。算法伪代码描述如下:

1.2 空间金字塔模块
多尺度采样的空间金字塔模块由3 个空洞卷积和1 个1×1 的卷积组成,从而可以多尺度地提取降雨云团高光谱特征。一般情况下,当下采样输出步长为16,ASPP 模块的空洞卷积使用了[6,12,18]的空洞率,但是对于背景区域面积远大于降雨区域面积的数据来说,[6,12,18]的空洞率过大,会遗漏很多降雨云团的轮廓特征,不利于提取小云团特征。因此,采用了标准化设计(Hybrid Dilated Convolution,HDC)的方法[17],将空洞率设置为锯齿状,其设计方法如式(1):
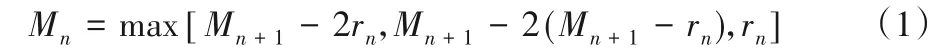
其中:rn第n层空洞率;Mn第n层最大空洞率。空间金字塔结构如图3所示。
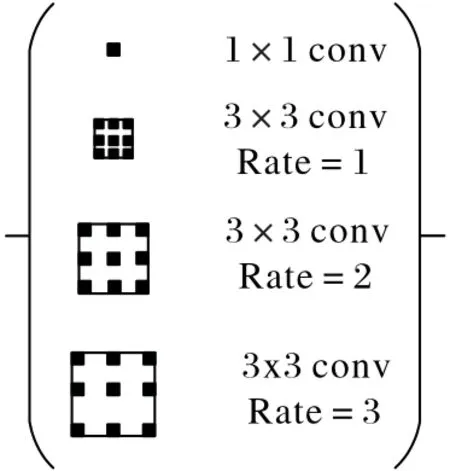
图3 空间金字塔结构Fig.3 Spatial pyramid structure
1.3 注意力机制模块
注意力机制模块主要是为了细化阶段的特征,首先特征矩阵经过一个2×2 的卷积层、归一化和激活函数Sigmoid,再与初始特征矩阵相乘,计算注意力向量提升特征学习,可以在多尺度采样后进一步细化小像素点降雨云团的特征结构。
利用注意力机制模块不需要任何的过采样操作就能获得全局语义信息,以此来修正特征图,注意力机制模块捕获全局上下文信息,并计算一个注意向量来指导特征学习。此设计可以细化上下文中各阶段的输出特性,并且它几乎不需要额外的计算资源,其结构如图4所示。

图4 注意力机制模块Fig.4 Attention mechanism module

对比注意力机制模块的输入A和输出C,代表降雨云团的元素值变大,能够有效地学习降雨云团特征,使模型集中“注意力”于降雨云团,从而提高模型精度。
1.4 反卷积上采样技术
空间金字塔和注意力机制模块的特征图融合后作为解码网络的输入,在解码的过程中使用分层的反卷积代替原有的双线性插值的方法,其计算方法如式(2)。对特征图进行上采样学习特征,恢复特征图到原像素空间,以便计算损失并反馈到网络训练的过程中,预测每个像素类别[18]。反卷积恢复了更多的边界信息,优化了模型对于小降雨云团的分割效果以及降雨云团的轮廓提取。

2 实验结果与分析
2.1 数据集制作
2.1.1 标签制作
本文使用的实验数据为FY-4A/AGRI 气象卫星全圆盘数据,其空间分辨率4 km,全圆盘扫描时间15 min,实验标签以全球降水观测计划多星集成降水(Global Precipitation Measurement,GPM)产品为参考标准,GPM 产品是高时空分辨率GPM 卫星群的红外、微波相互校准反演而得,并利用地面实际降雨数据修正后的卫星降水观测产品,因此具有较高的客观准确性,如图5 所示。实验使用了时间跨度为2018 年4 月至2018 年7 月的降水时刻数据。FY-4A/AGRI 气象卫星具有多通道的特点,但西藏地区的降雨多发生在夜间,因此去除了3个可见光通道,使用了剩余的11个通道数据,作为原始数据。本文实验标签由labelme 工具手动标注,根据GPM 降雨产品将降雨区域在相应时间的FY-4A/AGRI 卫星影像上进行标注,将降雨区标注为1,非降雨区域及其他背景标注为0,标注结果如图6所示。

图5 GPM产品Fig.5 GPM product

图6 手工标注标签Fig.6 Manual labeling
2.1.2 训练数据预处理
在获取原始HDF 格式FY-4A/AGRI 数据后,需要对其进行预处理。主要的数据预处理步骤包括:数据格式转换、数据中心化、原始样本切割和重叠采样,经过预处理后的数据输入语义分割模型中进行训练。
利用python 读取HDF 格式的FY-4A/AGRI 数据,并转换为数组后,计算每个通道的均值,然后使每个通道特征维度都减去相应的均值,使数据变成均值为0,数据中心化预处理有利于提升模型的收敛速度。
西藏地区截取尺寸为高256 像素、宽512 像素的矩形区域,由于计算机硬件资源有限,需要将原始数据直接分割后作为输入放入网络中训练,并且在实际选取的样本中背景与降雨区域比例存在严重不均衡的问题,背景像素占总像素比例超过了99%。若将样本尺寸切割过小进行训练,则训练数据会出现大量样本全部为背景,少量样本包含降雨云团,这对模型训练及检测分割是不利的。太大的切割尺寸在训练时会消耗大量的显卡显存、时间、内存,越大的切割尺寸就会导致越小的样本数据量,训练过程中就会更加容易出现过拟合的情况。为了使每个输入样本都包含降雨云团,并且在有限的计算机资源下顺利输入样本,提高模型对于降雨云团的检测分割精度,本文实验最终选择了256×256 的切割尺寸。由于深度语义分割模型训练需要大量的数据集作为支撑防止过拟合问题的发生,在水平方向上对其进行步长为16 像素的重叠切割来扩充数据量达到数据增强的作用,重叠切割可以减少分类过程中的拼接痕迹,提高分类效果。
样本切割完成后,对其进行旋转,分别旋转了90°、180°、270°,利用数据增强的方式增加了样本量,也保证了分类的准确性。最终生成用于模型训练的数据集如表1所示。
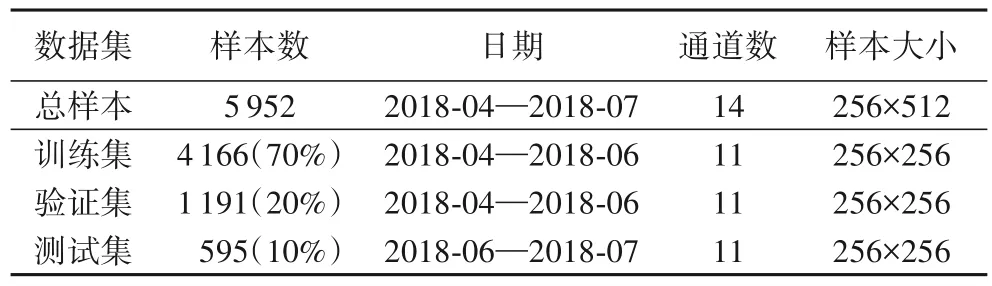
表1 数据集大小及特征Tab.1 Dataset size and characteristics
2.2 实验参数设置
在训练前对语义分割网络模型进行主要的参数设置,总训练次数(iterations)为18 000,学习率(learning rate)初始值设为0.000 2,并且当迭代次数为5 000 和9 000 时,学习率为之前的1/10,在保持模型收敛速度的同时,又不会导致发散。动量参数(momentum)设置为0.9,其目的是加快模型收敛速度。权重衰减参数(weight decay)设为1E-5。调整模型复杂度对损失函数的影响,空洞率设置为[1,2,3]。
2.3 精度评价指标
分类模型训练结束之后需要判断其分类的性能,尤其对于二分类而言,常用的评价模型精确度指标有平均交并比(Mean intersection over union,Miou)、准确率(accuracy)、精确度(precession)、召回率(recall)、F1分数(F1-score)。但正负样本存在不平衡的问题,背景占总比例极高,为了保证评价指标的客观准确,本文采用基于混淆矩阵(confusion matrix)的评价指标Miou 对降雨云团的分割结果进行精度评估。Miou计算公式:

其中:pij表示真实值为i,被预测为j的数量;pji表示真实值为j,被预测为i的数量;pii表示真实值为i,被预测为i的数量;m表示除背景外的正样本种类数量,计算第0项至m项总和。
2.4 各阶段优化对于分割结果的影响
为了对比不同阶段优化方式对于分割结果的影响,以2018-07-21 20:00:00 为例分割降雨云团,真值如图7 所示,对比在不同的网络结构下,对比降雨云团的分割结果、分割精度与损失的影响。以下预测图中黑色区域为降雨云团。
图7 2018年7月21日20点0分0秒降雨云团Fig.7 Rainfall cloud at 2018-07-21 20:00:00
2.4.1 上采样方式对分割结果的影响
原始的DeepLab v3网络使用了双线性插值的方式上采样恢复特征信息,双线性插值原理是利用图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,但是这种上采样方式不能完全恢复云团的边界信息,导致一些小的像素点被误认为是背景。使用反卷积代替双线性插值,将上一层的特征图放大,本质上依然是利用卷积的计算方式恢复目标信息,包含更多的细节信息,能够较好地将特征图中的主要信息提取出来,去除冗余的特征信息,不同的上采样方式分割结果如图8(a)和图8(b)所示。
对比图8(a)和图8(b)可以发现:使用双线性插值上采样时,分割结果较差,只能分割出较大的降雨云团,遗漏了较小的降雨云团;而采用反卷积的上采样方式时,由于反卷积层的存在,加强了网络模型的学习能力,虽然误测与漏测依然存在,但整体分割效果有了很大的提升,部分较小的降雨云团被成功检测出来。
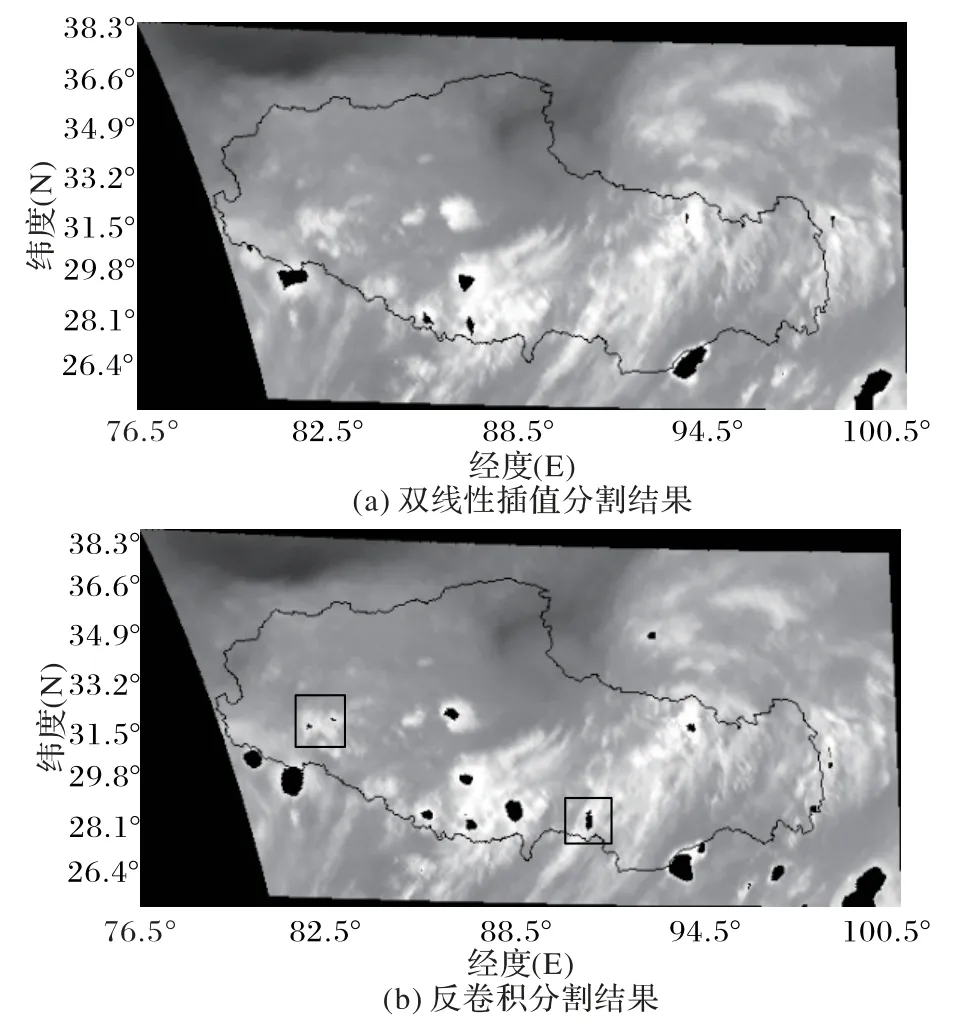
图8 不同方法分割结果Fig.8 Segmentation results of different methods
2.4.2 添加注意力机制模块
在改进上采样方式后,仍有很多遗漏,较小的降雨云团信息在上采样的过程中并没有成功被恢复,因此本文加入的注意力机制模块,其分割结果如图9所示。

图9 添加注意力机制模块后分割结果Fig.9 Segmentation results after adding attention mechanism module
在网络结构中加入了注意力机制模块后,进一步提升了网络模型对于小降雨云团的检测分割能力,在右半个预测区域多发生小范围降雨,大部分的小降雨云团都被分割出来,并且分割出的降雨云团整体性更好。
2.4.3 同步长卷积层代替池化层
在池化的过程中,会丢失特征图的细节信息,一个3×3 的最大池化层,就会丢失近1/9 的原图信息,对于负样本比例远大于正样本比例的样本中,这是不利于微小特征提取的。因此,本文研究方法使用步长相同的卷积层替代原有网络模型中的池化层,能够较好地将特征图中的主要信息提取出来,改进后的网络分割结果如图10所示。
虽然使用卷积层代替池化层,增加了网络参数和训练时间,但是成功减少了东经87°北纬33°处的误测点,改进之前的很多遗漏的细小降雨云团也被成功检测出来,如东经95°北纬26°处,东经97.5°北纬29.8°处的云团,在改进前东经94°北纬27°处云团整体被分断开,改进之后被成功分割为整体,达到了较好的分割结果。

图10 卷积代替池化后分割结果Fig.10 Segmentation results after convolution replacing pooling
从最基础的DeepLab v3 原型到改进后的DeepLab v3,其分类后的Miou 指数不断提升,对于降雨云团的检测效果也逐步提升。原始DeepLab v3网络模型与改进后的DeepLab v3的精度变化及损失下降曲线,如图11所示。
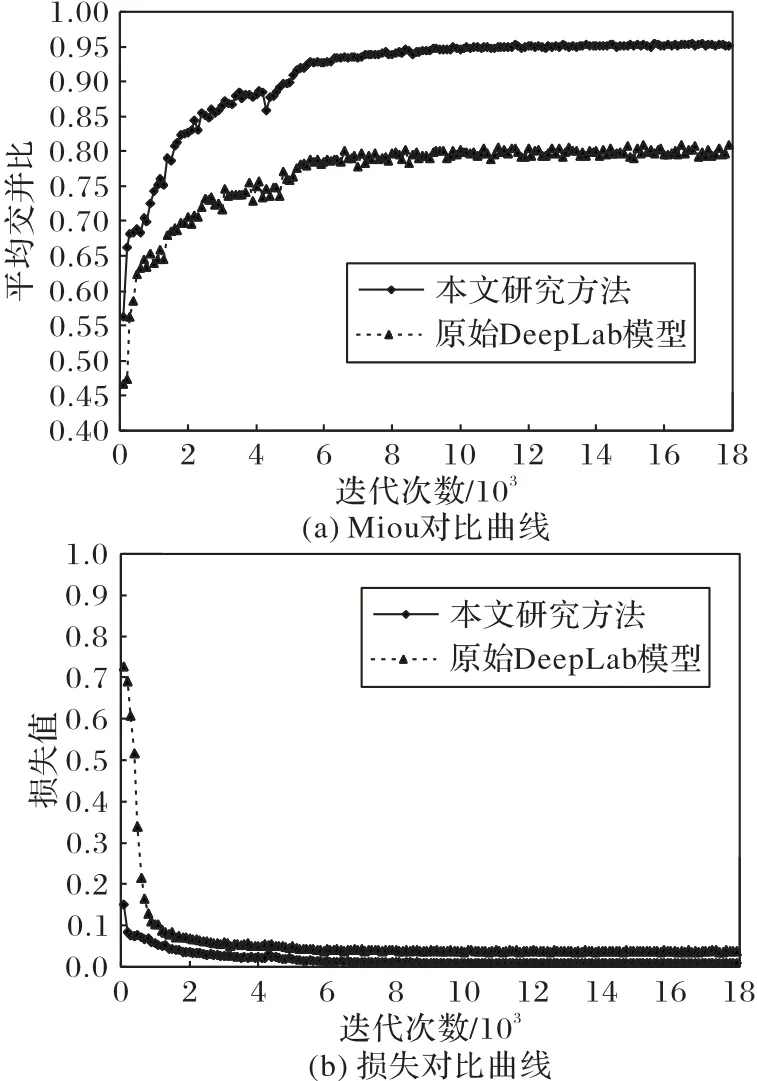
图11 初始模型与改进模型精度及损失对比Fig.11 Comparison of accuracy and loss between initial model and improved model
对比图11(a)和图11(b),原始DeepLab v3 的分割精度较低,Miou 指数0.795 8,损失最小值0.038 45,模型性能不佳,本文研究方法对比原始模型,分割精度大幅提升,Miou 指数达到了0.951 2,损失最小值0.009 07,虽然本文研究方法加入了大量的卷积层和反卷积层,增加了模型复杂度,但当迭代次数在2 000~6 000,精度依然大幅、快速地提升。
2.5 不同方法的分割效果对比
为了测试本研究的分割性能,使用不同的方法分割2018-07-21 20:00:00 的FY-4A 数据,对比标签为同时间段内GPM产品实际降雨云团,如图12(a)所示。DeepLab v3+和双侧分割网络(Bilateral segmentation network,Bisenet)作为新型的分割模型已经在PASCAL VOC 等诸多公开数据集上取得优秀的表现,而语义分割网络(Sementic segmentation network,Segnet)和FSVM 作为经典的分割模型,在多个行业领域有着广泛的应用,因此选用以上四种分割模型和初始DeepLab v3在验证集上进行分割结果比较,如图12 所示。从图12(b)中可以看出DeepLab v3 只能分割出一些较大的降雨云团,有较多的漏测区域;图12(c)中Segnet的分割结果大致上能与实际的降雨区域相符,但是对于局部的细节分割还是有待提升;相比DeepLab v3 有较好的分割结果,DeepLab v3+作为较新的语义分割网络结构,分割结果如图12(d),无论对整体的降雨云团分布还是细小的降雨云团提取,均优于DeepLab v3 和Segnet,但是DeepLab v3+的分割结果出现大量的误测区域,并且分割出的降雨云团面积过大,在空间分辨率4 km,0.1°×0.1°的范围下,一个像素点代表约11 km 的实际范围,DeepLab v3+预测的降雨区域远大于实际发生降雨的区域;图12(e)中Bisenet 分割结果出现了尖角状的降雨云团,并不能良好地提取出云团的轮廓信息,这与实际云团状况是不相符的。因此,DeepLab v3+与Bisenet 模型的泛化能力较差,分割效果不佳。FSVM 的分割结果如图12(f)所示,高亮的云团被认为是降雨云团,亮温值相近的降雨云团和非降雨云团没有成功被区分,此方法并不能自适应地提取降雨云团特征。本文方法的分割结果如图12(g)所示,相较于其他网络的分割结果,在保证整体性的同时,突出了小降雨云团的分割与识别,也和实际情况最为相符。
不同的模型训练时间、单张分割时间及评价指标如表2所示。

表2 不同分割方法实验结果Tab.2 Experimental results of different segmentation methods
根据表2:由于DeepLab v3 和Bisenet 在上采样时采用了双线性插值算法,因此训练时间较短,但模型精度低、泛化能力差;本文方法、Segnet 与DeepLab v3+网络结构更加复杂,由于上采样过程中存在多层卷积层,且将下采样时的一些特征融合到上采样的过程中,导致了模型训练时间长;FSVM 模型分割精度最低,并不适用于分割无规则、小目标的分割对象。在单张分割时间上,改进后的模型虽然单张分割时间相比原始模型的单张分割时间略微增加,但与相似结构的Segnet 与DeepLab v3+相比,单张分割时间更短,改进后的模型的泛化能力更好,精度也达到了最佳,适用性也更强。遥感数据对于目标检测分割实时性及模型训练时间的要求并不高,提升模型精度及泛化能力与分割精度是最主要的任务,因此本文的研究方法最终实现了较好的效果。

图12 各方法分割效果对比Fig.12 Comparison of segmentation effects of different methods
3 结语
本文提出了一种基于改进DeepLab v3的降雨云团分割的方法,改进的空间金字塔模块可以多尺度地分割不同大小的降雨云团,注意力机制模块细化了降雨云团的边界特征提取,解码网络与编码网络相对应,在下采样后经过多尺度的特征采样,恢复编码网络输出特征图的分辨率,在测试集的分割实验中Miou 指数达到95.12%。由于本文实验标签参考的GPM产品是反演校正后的降雨数据,比普通的GPM 降雨数据晚4~6 个月发布,因此,改进后的DeepLab v3 模型分割结果具有较高的参考性与准确性,其实时性远超现有GPM卫星产品。
改进后的DeepLab v3网络可以较为准确地对降雨云团进行分割,避免了传统分割的人工特征设计及提取方法的缺点,利用气象卫星覆盖面积大、高时空分辨率的特性,有效解决了西藏地区面积广阔、雷达观测站站点少,传统的雷达观测精度易受自然条件影响的问题,克服了复杂自然条件下不平衡样本对分割结果的影响。因此,可利用本文提出的分割模型近实时、连续地检测高原山地降雨云团,着重于易发生滑坡、泥石流易发的中尼公路沿线及藏东南地区,最终得到有价值但难以定量描述的降雨云团监测及预警信息,为当地基础建设居民人身安全及防灾减灾提供帮助。下一步工作将在已有的分割基础上,实现对降雨等级的划分,并估算降雨量。
猜你喜欢
少先队活动(2021年3期)2021-12-04 13:08:26
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
物理学报(2017年11期)2017-08-09 07:34:04
水利科技与经济(2017年6期)2017-04-28 08:30:36
润·文摘(2016年4期)2016-07-13 04:13:03
水利科技与经济(2016年5期)2016-04-22 03:43:46
发明与创新(2015年29期)2015-02-27 10:39:44
电视技术(2014年19期)2014-03-11 15:38:20
