
基于深度学习的三维目标检测方法综述*
2020-09-22 01:10:20彭育辉郑玮鸿张剑锋
汽车技术 2020年9期
彭育辉 郑玮鸿 张剑锋
(福州大学,福州 350116)
1 前言
有别于机器视觉传感器,激光雷达传感器具有受环境和天气等因素影响小、测距精准等优点。随着多线激光雷达传感器价格的逐年下降,基于车载激光雷达进行汽车外界环境感知成为实现汽车无人驾驶的主流技术方案,同时也是汽车无人驾驶领域的关键技术和研究热点。
基于激光雷达实现车外环境信息的感知就是在汽车行驶过程中,通过车载激光雷达准确地估计出车外不同三维目标的类别和位置,即分类和定位[1-6]。车载激光雷达获取的物体三维点云具有稀疏、分布不均、无序的特点,从而衍生出不同的数据处理算法。其中,基于深度学习的点云处理方法因其优秀的分类准确性和实时性而受到国内外学者的普遍关注。
深度学习的一般表现形式为一种深层神经网络,具有很强的特征提取能力,在监督式学习的目标分类上取得了很好的结果。图像是最早、最常用的视觉信息载体,摄像头等设备采集的图像信息大量使用,因此,图像信息的处理十分重要。2010 年,Felzenszwalb 团队提出的可变形部件模型(Deformable Part Model,DPM)[7]使传统的二维图像目标检测与识别达到一定的高度,但是算法的效果并不令人满意,梯度方向直方图(Histogram of Oriented Gradients,HOG)特征提取存在的遮挡物影响问题仍然比较突出。2013年,Girshick 等提出区域卷积神经网络(Region-based Convolutional Neural Network,R-CNN)[8],揭开了基于深度学习的二维目标检测与识别的帷幕。目前,基于深度学习的二维图像目标检测方法不断完善[9-13],已广泛应用在人脸识别、交通管理、文字识别等方面[14-17],技术成熟可靠。
在处理激光雷达获取的三维点云方面,借鉴二维图像的目标检测成为一种重要的技术途径。将三维点云数据降维后,利用图像目标检测的方法进行特征提取是初期的处理手段,算法耗时长且精度不足,局限性明显。随着车载激光雷达和计算机硬件的不断进步,苹果公司提出了VoxelNet[1]对三维点云进行编码处理,美国斯坦福大学于2017 年提出了PointNet[18],首次将原始点云数据投入深度神经网络训练的模型,清华大学与百度公司联合开发了MV3D(Multi-View 3D networks)[6],实现了点云多视图融合图像处理。上述方法都通过直接或融合处理点云的方式逐渐取代了间接的手段,成为三维目标检测方法的发展趋势。
本文将在回顾二维目标检测方法的基础上,对目前国内外基于深度学习的三维目标检测方法进行综述,为车载激光雷达目标检测方法的选择提供参考依据。
2 二维目标检测
二维目标检测主要解决图像中的目标分类和定位问题。由于图像的像素具有十分丰富的目标纹理信息,所以主流的方法是利用提取特征能力优异的深度卷积神经网络对图像进行目标检测。近10 年来,随着信息获取技术的不断进步,出现的ImageNet、PASCAL VOC和COCO(Common Objects in Context)等数据集为深度神经网络模型的训练提供了可靠的数据来源,可以使模型减少不必要的误差,快速地靠近最优解,对模型的学习训练起到重要的作用。
2010年,Felzenszwalb 团队提出的DPM 是当时检测效果最好的模型。这种由人工选取特征的目标检测模型随着信息量的增大呈现出很大的局限性,因此在目标检测上逐渐引入了深度学习方法。2013年,Girshick 等提出了R-CNN[8],使用区域候选的方式替代了滑动窗口,再通过卷积神经网络(Convolutional Neural Network,CNN)提取候选目标的特征。R-CNN 在每次特征提取时都要重新进行CNN 的训练,增加了计算成本。2015年,Girshick 等对R-CNN 进行改进,提出快速区域卷积神经网络(Fast Region-based CNN,Fast R-CNN)[9],采用将感兴趣区域(Regions of Interest,RoI)与CNN结合的方式平行输出分类和边框回归的结果。由于R-CNN 和Fast R-CNN 运算量大且无法很好地使用图形处理器(Graphics Processing Unit,GPU)进行运算,因此检测速度很难提高。同年,Ren等提出了端到端的更快速区域卷积神经网络(Faster Region-based CNN,Faster RCNN)[10],目标区域候选由区域候选网络(Region Proposal Networks,RPN)来完成,所有运算过程都可以在GPU 上运行,检测速度得到提高。受R-CNN 的启发,He 等提出了掩模区域卷积神经网络(Mask Regionbased CNN,Mask R-CNN)模型[19],Zhang等提出了局部-区域卷积神经网络(Part-based R-CNN)模型[20]等。
基于目标区域候选的检测算法都要先提取目标候选区域,明显增加了运算的负荷。Redmon 提出了基于回归的YOLO(You Only Look Once)模型[11],从图像的输入到检测结果的输出,只使用了1 个深度神经网络模型,把点云的处理当作回归问题,精度低于Faster RCNN模型,但是检测速度至少提高了5倍。继YOLO模型之后,Liu 等提出了单发多框检测器(Single Shot MultiBox Detector,SSD)模型[12],速度比YOLO 更快的同时,可获得与R-CNN相媲美的精度。YOLO和SSD高效的处理速度再次证明了深度神经网络在提取特征和分类任务上具有很强的性能,但是处理结果的精确度有待提高。YOLO 经过不断改善,出现了YOLOv2[13]和用于研究三维目标检测的YOLO3D[21]。对于目标检测的研究,算法的处理速度和精确度是相互矛盾的,若以保证处理速度为主,算法就会精简,对特征的提取可能会变得简单。表1 所示为二维目标检测方法在PASCAL VOC 2007 数据集上测试的结果,其中,Faster R-CNN(VGG)是指以视觉几何组(Visual Geometry Group,VGG)网络为特征提取器的Faster R-CNN,SSD(300)是指输入图像尺寸大小为300×300 的SSD。由表1 可知,平均精度最高的是SSD(300),处理速度也达到了59 帧/s,相比最高速度的Fast YOLO模型,平均精度高21.6百分点,检测精确度和处理速度取得了一定的平衡。
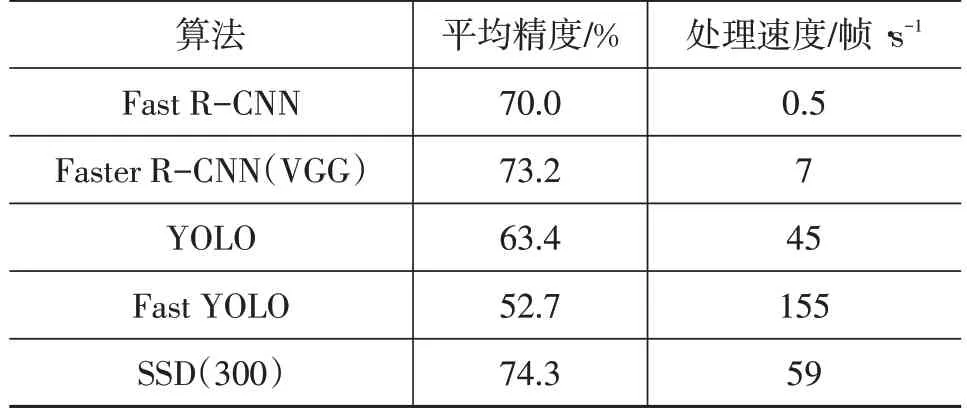
表1 二维目标检测方法测试结果
本质上,对目标检测方法的探索就是对深度神经网络的研究,二维目标检测的深度神经网络对三维目标检测方法研究具有启发性的作用,如RPN 和基于回归的YOLO设计等。
3 三维目标检测
随着近年车载激光雷达在汽车智能驾驶领域的广泛应用,由车载激光雷达获取的三维点云数据逐渐成为国内外研究的热点。点云数据携带的信息主要是以激光雷达为原点的空间坐标和反射强度。相继出现的机器人三维扫描库(Robotic 3D Scan Repository)、悉尼城市目标数据集、KIITI 数据集[22]等多个开源数据集为网络的训练及验证提供了有效的数据支撑,由KITTI数据集节选出并经过处理的点云和相对应的高清图片如图1 所示。基于深度学习的三维点云处理方法总体上可分为3 类,即间接处理、直接处理和融合处理。间接处理点云的方法主要是对点云进行体素化或降维后再投入已有的深度神经网络进行处理;直接处理点云的方法主要是重新设计针对三维点云数据的深度神经网络对点云进行处理;融合处理点云的方法则是融合图像和点云的检测结果再进一步处理。随着图像硬件的发展,融合处理点云的方法将是点云处理的主要技术。

图1 KITTI数据集节选[22]
检测的主要目标有车辆、行人和骑行者,其中行人和骑行者的点云数据比车辆的点云数据稀疏,可提取的特征信息少,检测难度大。目前的检测算法都以车辆的检测为主,兼容行人和骑行者的检测。
3.1 间接处理点云
间接处理点云的对象,最初主要有RealSense、Kinect 等三维智能传感器采集的深度图像(RGB-D)和经过人工处理的CAD模型。间接处理点云的方法大都源自前期二维目标检测的深度神经网络模型,先利用统计的方法或者卷积网络模型将点云数据转化为体素网格的形式或其他二维特征,再利用深度神经网络模型进行学习训练。
最初,人们并未对点云的性质进行深入研究,而是受图像像素处理方法的启迪,将点云和图像一样进行“像素”的处理,即对点云进行体素网格处理,再对体素网格进行研究分析,初期主要的间接处理方法[4,23-26]特点如表2所示。
苹果公司针对无人驾驶场景下的三维目标检测提出了一个端到端的深度神经网络——VoxelNet,实现对点云的逐点处理。其设计的特征学习网络层(Feature Learning Network)对输入的点云进行体素分块(Voxel Partition)、点云分组(Grouping)、随机采样(Random Sampling)、多层体素特征编码(Stacked Voxel Feature Encoding)、稀疏张量表示(Sparse Tensor Representa⁃tion),经过卷积网络的压缩提取后接入RPN 层进行高效检测。VoxelNet 模型仅利用车载激光雷达的点云数据输入进行模型训练,保证了点云的原始三维特征。重庆大学的Yan等受VoxelNet的启发,提出了稀疏嵌入式卷积检测网络(Sparsely Embedded Convolutional Detec⁃tion,SECOND)模型[27],采用2 个串联的体素特征编码(Voxel Feature Encoding,VFE)架构,采用稀疏卷积神经网络进行连接,利用RPN 完成目标的检测工作,如图2所示[27]。SECOND 充分利用了点云的稀疏性,改善了VoxelNet中的特征提取效果。

表2 初期主要的间接处理方法比较

图2 SECOND模型[27]
有别于体素网格处理方法,将点云的深度信息投至图像而形成的融合深度图像方法是另一种重要的点云间接处理途径。受到Dolson[28]和Andreasson[29]等人的启发,2014年,Cristiano[30]指出了点云所具有的深度信息在行人检测中起到重要的作用。紧接着,Alejandro结合深度图一并考虑行人的朝向,提出了多视图随机森林(Multiview Random Forest)算法[31],并指出算法中的一些简易模块可以使用卷积神经网络进行特征表示,检测效果会进一步提高。2016 年,斯坦福大学的Qi 等提出多视角卷积神经网络(Multi-View CNN,MVCNN)[32],利用一个神经网络辅助预测目标分类,设计了非均质的探测过滤器将三维数据投影至二维空间做目标分类。在训练的过程中,做了数据扩增,并根据三维物体设计了多方向池(Multi-Orientation Pooling)。该方法对Model⁃Net40 模型库的检测精度已经达到了86.6%,超过了之前的所有检测算法。百度公司的李波[5]将数据以二维点图的形式表示,移植了图像处理的端到端深度神经网络,能够同时预测目标置信度和边界框。
间接处理点云的方法借鉴二维目标检测的设计,如数据预处理中的“体素化”或者合成深度图,网络模块中的RPN 或者稀疏卷积神经网络等,都会导致网络训练过程中失去一部分三维特征信息,甚至引入误差。在网络模块的设计中可以加入池化(Pooling),大量的卷积运算会使数据的提取产生偏移,池化不仅可以改善这种错误,还可以减小过拟合并且提高模型的鲁棒性。
3.2 直接处理点云
随着研究的不断推进,学术界愈发重视点云数据本身的特性,如无序性、稀疏性和分布不均等。直接处理点云的方法是直接把原始的三维点云数据投入重新设计的深度神经网络进行训练,并不对点云数据做任何预处理,而且深度神经网络的设计不受以往图像检测网络设计的影响。
斯坦福大学的Qi 等提出了PointNet[18],直接从点云中学习点对点特征。PointNet 使用多层感知机(Multi-Layer Perceptron,MLP)提取单点特征,训练最大池化层作为对称函数,整合来自全局的点云信息并解决了点的无序性问题,最后得到全局特征。其中,设计的空间变换网络可保证输入点云的不变性。PointNet 在三维物体检测、三维物体部分分割和逐点语义分割任务中取得了良好效果。PointNet 解决了无序和不变性问题,提取了全局特征,但是没有考虑到全局信息的问题,经过改进,Qi等提出了PointNet++[33],该模型考虑了点与点之间的距离度量,通过层级结构利用局部区域信息学习特征,还解决了采样不均等问题,使得网络结构鲁棒性更好。PointNet和PointNet++的提出对三维目标检测技术具有深远的意义。香港大学的Shi等利用PointNet++模型提出了PointRCNN[34]。PointRCNN 主要分为2 个阶段处理点云,先利用具有强大实例分割能力的PointNet++进行点云的初步分割,提出目标候选框,再进行目标候选框的精细化处理以精准地检测目标。新加坡国立大学的Uy等成功地将PointNet模型和NetVLAD[35]结合,提出了端到端的PointNetVLAD[36],并使用度量学习[37]的训练方法,准确地得到点云的全局描述信息特征,解决了基于点云检索的位置识别问题。香港大学的Yu等利用PointNet 的点特征聚合能力将点云的三维坐标映射到特征空间,再结合特征扩展组件[38]和全连接网络完成点云的三维坐标重建任务。德国慕尼黑工业大学的Deng等人提出PPFNet[39],使用多个PointNet 提取多个对应面片区域的特征,再利用最大池化层聚合和融合,得到全局特征。PointNet 的提出起到了很大的启发作用[40-48],其对点云特征提取的优异效能得到了学者们的肯定和广泛应用。
德国的Valeo Schalter und Sensoren GmbH(简称法雷奥公司)和德国伊尔曼诺理工大学借鉴YOLOv2提出Complex-YOLO[49],其继承了YOLOv2 的网络架构,将方向向量转换为实值和虚值,并设计了欧氏区域建议网络(Euler-Region-Proposal Network,E-RPN),在英伟达的Titan X显卡上识别速度达到了50.4 帧/s,但是精确度有所偏差,而且忽略了小目标物体,如行人和骑行者。因此,法雷奥公司又提出了YOLO3D[21],吸收了MV3D模型的数据处理方法,设计了双输入通道,修改YOLOv2 的架构,并优化损失函数,精度得到有效提高。
目前,主流的研究手段均基于PointNet 或者YOLOv2。基于PointNet 或之后的PointNet++的层级训练特点是能很好地得到点云的局部或者全局区域特征,基于YOLOv2 的方法继承了YOLOv2 的高效识别速度。直接处理方法最大的难点在于设计的针对三维数据的神经网络架构能否符合点云无序性、局部性和不变性等特点,并且如何准确地表征出来。
3.3 融合处理点云
当硬件计算速度足够支撑算法的多维度计算时,便产生了以图像为辅助的融合处理点云方法。融合处理点云的方法主要着眼于融合图像和点云检测的结果,其中图像的检测利用已有的二维目标检测算法,点云的检测利用以上提到的直接或者间接的处理方式得到检测结果,再进一步对两者的结果进行融合处理,得到最终检测结果。融合处理点云的方法由于增加了高清图像的辅助,在平均准确度上有一定的优势。
清华大学和百度公司联合提出MV3D[6],设计的三维候选网络将点云的数据分成了鸟瞰和前视2个视图,都利用卷积神经网络处理,以点云的前视图处理作为辅助,主要处理鸟瞰视图得到点云的坐标及强度特征信息编码,结合图像(RGB)的初步卷积处理后,三者都经过池化再进行融合处理,结果接入基于区域的融合网络,得到分类和边框回归结果。针对PointNet,Qi等人提出了针对无人驾驶中障碍物检测的Frustum PointNets[3],先对高清图像进行目标的候选,给定目标在图像中的区域,然后用平截头体框出对应位置的点云,其中包含了其他非目标的点,最后利用PointNet精确地把目标点云分割出来,如图3所示[3]。加拿大滑铁卢大学的Jason Ku等人提出的AVOD[50]神经网络结构使用改进的RPN 分别对三维点云和RGB图像中的目标生成各自的三维候选区域并进行融合处理,通过全连接神经网络层连接至第二阶段检测网络,进行三维边界框的精确回归和分类,预测目标障碍物。融合处理点云的算法模型,结合图像RPN,使得融合后的处理效果得到明显提升,其还有许多值得研究的融合算法,如深度连续融合算法[51]、针对车辆检测的一般融合算法[52]等。

图3 Frustum PointNets模型[3]
3种处理方法的优、缺点如表3所示,融合处理在对行人和骑行者这类稀疏的三维点云数据的检测上具有很好的效果。间接处理和直接处理的方法在车辆检测上平均精度可达82%,但是在行人和骑行者的检测平均精度为30%~60%;融合处理的方法得益于结合了图像检测,不仅车辆的检测精度超过85%,而且行人和骑行者的检测平均精度已超过70%。
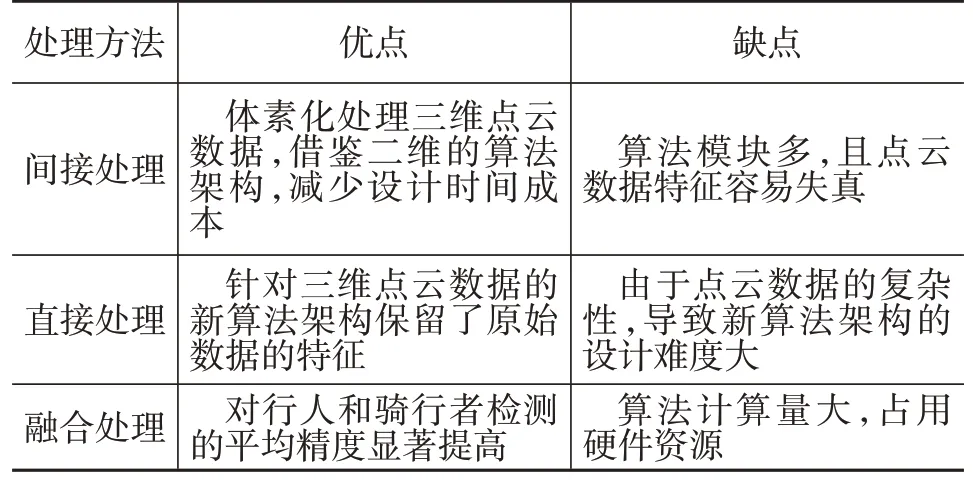
表3 不同处理方法的优、缺点对比
硬件的发展必然使点云处理手段的重心偏向融合处理,点云的间接或直接处理最大化地利用了三维信息,但是对小目标物体的识别能力很差,需要结合图像的高精度识别才能使三维目标检测的结果更加准确。Frustum PointNets 的融合方式过于依赖图像的检测结果,与MV3D或AVOD等将图像和点云并行处理再融合的方式有明显的差距,在同样的KITTI 数据测试样本中,Frustum PointNets、MV3D、AVOD 的 平均精度 为81.2%、89.05%、84.41%,图像和点云并行处理再融合的方式优势突出,将是融合处理点云的主流设计方法,其攻克的重点在于如何设计融合算法,引入神经网络可增强融合处理算法的适应性和智能化。
4 结束语
针对车载激光雷达获取的三维点云的目标检测方法是实现汽车无人驾驶的关键技术。深度学习算法使得基于三维点云的目标检测取得了突破性进展,但在训练大量样本数据或在实际应用场景下,仍会出现数据易失真、运行效率低、识别精度不高等问题。
综合当前基于深度学习的三维目标检测的研究现状,本文对今后的研究提出以下建议:
a.必须有效地对原始点云进行数据预处理,减少数据采集过程中因设备或者环境产生的误差,以有效提高检测的效率和精度。
b.采用线性的卡尔曼滤波算法或者非线性的深度神经网络改进融合算法,是提高融合算法的学习性能、增强融合效果的有效途径。
c.高清图像的辅助可以有效弥补激光雷达点云数据稀疏的缺点,所以图像与三维点云的融合处理方法将成为三维目标检测的主要技术发展趋势。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
