
SentiBERT:结合情感信息的预训练语言模型*
2020-09-13 13:53宋晓宁
计算机与生活 2020年9期
杨 晨,宋晓宁,宋 威
江南大学人工智能与计算机学院,江苏无锡 214122
1 引言
随着经济社会的发展,互联网中的用户信息呈爆发式增长。爬虫、数据库等技术为收集这些信息提供了极大的便利,而如何使用这些数据则成了一个很重要的研究议题。这其中,最有价值,最让企业、机构或个人重视的就是用户舆论的情感信息,比如微博上对热点事件的评论,豆瓣上对电影的评价等。对用户的情感进行分析、分类,对企业和有关部门的发展、运营有重大的意义。
计算机技术的发展为海量数据的处理提供可能,特别是深度学习的出现,使得计算机模型对自然语言的理解能力大大提高。长短期记忆网络(long shortterm memory,LSTM)[1-2]、卷积神经网络(convolutional neural networks,CNN)[3-4]在情感类任务上都取得了很好的效果。近年也有研究使用降噪自编码器[5],通过区分领域独有特征和共享特征以及进行二次干扰的方式来进行跨领域的情感分类。
许多研究考虑任务的多元特征或加入外部信息来增强模型的效果。Yu等[6]结合产品信息来训练词向量用于分类不同产品的评论情感。Zheng等[7]通过词的语义规则来提取关键句,实现高效的情感分析。Yu等[8]通过加入辅助任务,删去文中情感词来增加模型的泛化能力。
情感分类模型精度的不断提升一定程度上受益于在大规模预料上预训练模型的发展,作为预训练语言模型的最初应用形式,预训练的词向量[9-10]已经证明在许多任务中都有着明显的积极效果。近些年来,研究者不满足于词向量保留的浅层语义信息,进而追求一个能够像ImageNet一样保留深层次特征的可迁移的预训练模型[11]。Howard等[12]提出了一种适用于文本分类任务的通用可微调模型,该模型在6个数据集上获得了先进的效果。随后不久,Radford等[13]提出了预训练语言模型OpenAI GPT,该模型仅仅需要很微小的改动就可以用于各种下游任务,最终在包含文本蕴含、情感分析、文本相似度在内的9个数据集上达到了最先进的效果。
近期,预训练语言模型BERT(bidirectional encoder representations from transformers)引发了最激烈的讨论,在自然语言处理领域的多个任务11个数据集上都取得了最先进的效果[14]。目前,大量的研究已经聚集在如何利用其执行下游任务上,以进一步提高目标任务上的性能。Liu等[15]将预训练的BERT模型和多任务学习进行结合,进一步刷新了BERT的效果。Sun等[16]通过对输入数据进行改造,将单句分类问题改造成BERT更擅长的双句分类问题进行处理。Sun等[17]着重研究了BERT在多个文本分类任务上的表现,对后续的研究有很强的借鉴意义。
然而,BERT在预训练阶段,尽管通过多个任务学习了句法、语法等文本结构和单词语义信息,却并没有考虑任何情感信息,这使得其在情感任务上的表现并不如文本推理、阅读理解等。同时,作为一般的分类问题,BERT在许多情感数据集上已经获得了最先进的效果,但很明显的是,该过程还有细化和提升的空间,特别是当样本量较少时,情感文本带来的变化和噪声使得准确率差强人意。
针对以上问题,为BERT定制了一个新的预训练任务,使得其在大量的、更容易获取的无监督的语料上也能获取一定的情感信息。首先,在目标领域数据集上使用改进的掩盖词预测任务和下一句预测对BERT在目标领域数据上进一步预训练。然后,利用被掩盖单词蕴含的情感极性作为标签,让模型根据上下文来预测该标签,该任务与前两个任务一同计算损失,训练参数,以防止“灾难性遗忘”问题[18]。实验证明,相较于原版的BERT模型,这样的训练方式使其在具体的情感数据集上可以用更少的样本获得更好的效果。
2 相关基础
BERT是一种基于Transformer的双向文本表征,作为最新的预训练语言模型的一种,最重要的特点是可以使用大规模无监督数据集进行预训练,然后在特定任务数据集上进行微调。由于预训练阶段引入了大量先验知识,加上Transformer强大的特征抽取能力,BERT在11个数据集上都取得了最先进的效果。
2.1 掩盖语言模型
和传统的n-gram语言模型不同,BERT使用掩盖语言模型(masked language model,MLM)作为主要任务训练模型参数,其任务目标是使用类似于“完形填空”的方式,将一个句子里的多个词使用特殊的标记遮盖掉,让模型去预测被掩盖的单词,复原整个输入。
掩盖语言模型需要随机遮盖输入文本序列中的单词,然后模型给出遮挡目标可能的单词的概率分布。理论上来说,替换后的句子引入了噪声[MASK],模型通过获取降噪的上下文特征对被掩盖的目标单词进行重新编码,因此掩盖语言模型本质上是一种自编码的语言模型。
然而,掩盖语言模型对不同类别单词进行重新编码效果不尽相同。图1展示了BERT对某个样本(“电影太糟了,我从来没有提前离场过,除了这次”)的不同单词进行掩盖并编码产生的损失。其中颜色越深代表该单词产生的损失越大,模型对该词的预测效果也就越差。

Fig.1 Loss of MLM on an example sentence图1 掩盖语言模型在某例句上的损失
从图1中可以看到,一些介词,例如“a”“the”等,由于有特定的语法规律和固定的搭配,模型可以对它们预测得非常准确。一些名词,例如“cinema”,模型注意到了前文特征词“movie”,因此也能给出一定的判断。然而,注意到,虽然下文表达了消极情感的语义特征,情感词“bad”,仍旧产生了很高的损失,通过获得模型的输出,发现模型给出的概率分布中,前三的单词分别为“great”“wonderful”“bad”。也就是说,模型没有很好地提取到下文的情感特征,甚至给出了情感极性相反的判断。从这一点来说,降低掩盖语言模型对情感词的预测损失,可以一定程度上增强模型对情感特征的提取能力,从而在具体情感任务上获得更好的效果。
2.2 使用BERT进行单句分类
在BERT中,每个输入到Transformer[19]的句子都要预先在开头加入一个特殊的词例[CLS],一般分类问题是将Transformer在[CLS]对应位置的输出看成是一个编码输入端全句分类特征的向量,然后将该特征向量放入分类器进行分类。
由于BERT是一个预训练模型,可以直接使用,将目标数据集放在大语料环境下预训练得到的BERT上进行微调,将目标输入编码为一个固定大小特征向量进行分类。但在这之前,还可以通过进一步预训练[17]的方式,即在目标任务微调前,使用目标数据集(或目标领域)的数据对模型进一步预训练,使用掩盖语言模型和下一句预测任务微调BERT的参数,相当于先将模型从一般领域向目标领域进行迁移,然后再执行目标分类任务。图2展示了BERT在具体领域分类任务上的流程。

Fig.2 BERT classification flow chart图2 BERT分类流程图
大量的实验证明,进一步预训练由于模型提前适应了目标领域的数据,往往能取得更好的效果。这在本文的实验部分也有体现。具体来说,通过掩盖词的预测任务,模型学习到了更多的目标领域的语义、语法等信息,而这些信息则显著地增强了模型的分类效果。同样地,由于本文的目的是判断目标的情感,因此希望模型在该阶段能更好地利用上下文的情感信息去监督学习,以增强在具体情感数据集上的分类能力,特别是当用于分类的数据不足时,模型仍然能够将预先学习到的大量情感信息迁移到小数据集上来。
3 用于学习情感特征的多任务BERT模型
在BERT中,文本特征的提取主要依赖掩盖词预测任务。第2章分析了BERT对不同掩盖词编码的效果,相较于可以被准确预测的介词、连词和副词,情感词有两个显著的特点,这是导致其预测效果不佳的原因。一是情感特征,特别是上下文中不包含情感词的隐式情感表达难以被模型注意;二是情感词出现频率相对较小,导致其在预训练阶段对情感特征提取不充分。针对这两个问题,在BERT的基础上进行了两点改动:
(1)通过加权的方式,提高掩盖语言模型对情感词的预测效果。
(2)根据情感词典,设计了基于目标上下文的单词情感极性预测任务,向模型中加入外部情感信息。
本文通过WordNet情感词典获取情感词,同时为了使得该标注拥有跨领域的性能,尽可能选取情感极性单一且鲜明的单词。
3.1 具有情感偏向性的掩盖语言模型
直觉上,当下游任务为情感任务时,在预训练阶段给予情感词更多的关注有利于模型更好地提取全文的情感特征。但在实际应用中,情感词出现较少,如果将情感词典中所有情感显著的情感词看作正类,非情感词看作负类,则一般情况下情感词仅占被掩盖词的1%,作为处理不均衡数据的常用手段。为了能在情感词预测时产生更大的梯度,对模型参数产生更大的影响,挑选了样本中所有的情感词,并在计算损失时对其加入了更大的样本权重。
假设一个不定长序列S中的特殊词例w[CLS]和w[MASK],其经Transformer提取特征后的对应表征为x[CLS]和x[MASK],R为事先定义的情感词集合,则对于掩盖词预测任务,定义损失函数为:

3.2 词粒度情感预测任务
在预训练阶段,单词本身所蕴含的情感信息也非常重要,许多研究从词向量入手[6,20],通过拼接情感向量或者相乘的方式向词向量中加入情感因素。然而,BERT作为一个预训练模型并不适用,本文的出发点是将该信息以有监督的方式提供给模型,通过反向传播修改参数并学习情感信息。因此设计了一个无需手工标注的预训练任务,其任务具体描述为:在预测一个被掩盖单词的语义的同时,根据上下文预测该单词所蕴含的情感极性。
例如,对于输入“The food was [MASK]and the service was good”,从未被掩盖的描述“the service was good”可以得知,这是对某个餐厅的正面评价,而“and”作为连词连接的是两个表达相似的句子,因此可以推理出被掩盖的单词也表达正面情感。同理,给模型提供被掩盖词的情感信息,则模型也应可以预测出其前后文所表达的情感色彩,从而在大语料环境下发现有关情感的隐式表达。BERT在许多文本推理和阅读理解任务中都取得了不错的效果,该任务也不例外。
具体地,本文对被掩盖单词的单词情感极性进行批量标注,作为在预训练阶段提供给模型的额外监督信息。数据输入模型后,该任务在Transformer中与其他任务共享参数,用被掩盖单词所对应的表征作为编码了上下文信息的动态词向量,将该向量作为特征使用softmax交叉熵损失函数对其表达的情感进行预测:


和式(1)不同的是,式(3)使用随机初始化的矩阵W作为任务参数,而在掩盖语言模型中则使用BERT的词嵌入矩阵E作为参数进行“反嵌入”,并计算损失。
3.3 模型结构
和基础的BERT模型一样,本文的模型也主要由三部分组成,整体上如图3所示。
(1)输入层。输入层即嵌入层,BERT的词嵌入分为三部分,分别为词嵌入(word embedding)、位置嵌入(position embedding)、片段嵌入(segment embedding),最终的输入是这三个嵌入向量的和。
(2)Transformer。上一阶段输入的词嵌入经Transformer神经网络提取上下文特征,获得每个输入对应的表征。
(3)多任务层。BERT主要通过NSP(next sentence prediction)和MLM任务在大规模无监督文本上提取特征,保留了NSP任务(loss1),改进了MLM(loss2)任务,同时加上本文提出的单词情感预测任务(loss3),模型最终的损失函数是三个任务产生的损失之和:

Fig.3 Model structure图3 模型结构
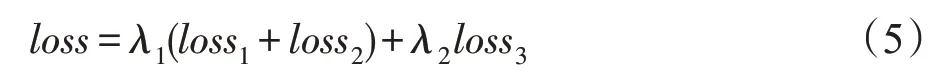
其中,λ表示为不同任务分配的权重。BERT的下一句预测和改进后的掩盖词预测任务是提取文本特征的基础任务,因此没有改动loss1和loss2相对权重,而本文的单词情感预测任务作为一个情感相关的辅助任务,用于添加情感信息同时辅助学习情感特征,则是本文参数调整的对象。一般来说,多个任务之间互相影响,对其权重也十分敏感,将其看作超参数,通过实验来选取最优的λ1和λ2参数组合。
4 实验结果及分析
为了检验BERT以及本文改进的BERT模型在情感任务上的性能,选取了两个情感分类领域的流行数据集进行实验,选取了训练集的少部分样本作为训练集,其余训练集样本去掉标签信息作为预训练语料。
4.1 数据集
表1展示了本文所使用的相关数据集的统计信息。其中,IMDB情感数据集来自美国最大的互联网电影资料数据库,包含5万条不同电影的用户评论信息,是一个倾向性明显的二分类影评数据集。除此之外,该数据集还提供了不同于训练集和测试集的额外5万条无标注数据。
Yelp-L数据集是Yelp情感分析数据集的一个子集,来自于美国最大的点评网站Yelp.com,包含了餐饮领域的3万条用户评论,数据集的标签来自于用户的原始评分,是一个5分类的餐饮领域评论数据集。

Table 1 Dataset表1 数据集
对原数据集的训练集进行进一步划分,测试集不变,以测试模型在小样本下的性能。IMDB数据集取原数据集(25 000)的1%,即250个训练样本用于任务微调,其中正负样本各125个。Yelp数据集取原训练集的3%,即300个训练样本,其中每类别样本60个。剩余的训练样本用于无监督预训练和词粒度情感预测任务(word sentiment prediction,WSP)。
4.2 超参数设置
使用BERT-base为基础模型,该模型隐层节点数为768,有12个自注意力头部和12个Transformer块(Block)。为了使模型拥有足够的上下文信息,仅掩盖了10%的单词,且对每个训练样本反复取样20次,每次取128个词例。对于词粒度情感预测任务,将情感词典中情感评分大于0.6的标记为积极词汇,小于0.4的标记为消极词汇。在训练时,批量大小设置为28,学习率为5E-5,在一块GTX1080ti训练100 000步。
在微调阶段,将批量大小设置为16,对数据集迭代了2次,模型中所有dropout概率都为0.1。在4块GTX1080ti上使用adam优化器训练,β值为0.9和0.999。在训练过程中使用学习率为2E-5的动态三角学习率,预热率为0.1,训练过程中保存在验证集上表现最优的模型在测试集上进行测试。对于超过限制长度的样本使用首尾分割的方式,保留前210个词例和尾部300个词例。
为了得到最佳效果,通过多组实验验证最优的参数值,即改进后掩盖语言模型的k值和多任务损失的损失权重λ1和λ2。k值取大于1的常数。为了避免梯度问题,λ1和λ2之和一般为1,可看成是不同任务所占比重。取IMDB数据集中与训练集和测试集不相交的2 000个样本作为验证集来完成该实验。
从表2可以看出,两种改进方式在验证集上较原方法精度都有所提升,情感词的损失也有效下降,但是较依赖于权值的选择。可以看出,当单词情感预测任务所占比重超过0.3后,反而会取得更差的效果,而k值设为10时,模型也在情感词上产生过拟合。最终选取表现最好的取值k=2、λ1=0.90、λ2=0.10作为超参数,测试模型的泛化性能。

Table 2 Accuracy with different hyper-parameters表2 不同超参数下的精度
4.3 实验结果对比
表3展示了不同模型在这两个数据集上的效果。其中,表的第一行为实验数据集名称,IDMB+表示使用了额外5万无监督数据进行预训练。LSTM+ATTN代表加入自注意力机制的双向长短期神经网络模型,其结果来自对文献[2]的复现,非预训练模型很难在少量训练数据上取得好的效果,表格第二行给出了上述模型在全数据集下的表现。表的后半部分是预训练语言模型的相关实验数据,ULMFIT(universal language model fine-tuning for text classification)的实验结果来自文献[8],是基于LSTM的预训练语言模型。BERT代表使用原BERT模型在目标数据集上直接进行微调的结果。FP(further pre-training)代表在目标领域内进一步预训练之后的模型的实验结果,SentiBERT(sentiment BERT)为本文改进后的BERT模型。

Table 3 Test accuracy in different models表3 不同模型下的测试精度 %
实验结果表明,在训练数据较小的情况下,预训练的语言模型由于吸收了大量复杂语言知识,结果远好于基于词向量的LSTM神经网络模型,而进一步预训练使得BERT在进行具体任务的微调前适应了相关语境,使得结果明显优于前者。最后,本文的模型由于实现情感信息的预先获取,使得最终结果再上升1个百分点。除此之外,还测试了BERT相关模型在不同数量训练样本下的性能。
从图4可以看出,相较原BERT模型,本文方法在不同数量的训练数据集下均能取得较好的效果,特别在样本数量较少的情况下,BERT的3种训练方式差异较大,随着训练数据增多,本文的模型精度收敛更加迅速。最终,在全数据集下,3个模型的差距较小样本下已经不够明显,猜测足够的人工标注样本使得BERT推断出了一定的情感,补偿了加入的单词情感信息。

Fig.4 Accuracy with different number of training samples图4 不同数量训练样本下的模型精度
4.4 BERT词向量分析
情感类任务的一个重要特征是模型的改变可以直观地反映在词向量的微调上。使用余弦相似度可以非常直观地度量词向量的语义相关性,而经过情感任务训练得到的词向量往往也可以蕴含情感倾向,具体表现为情感倾向相同的词其相似度会增加,而情感表达相反的词其相似度会降低。
BERT的词向量的组成和训练过程比较复杂,将BERT的词嵌入进行分离,分析了预训练后SentiBERT的词嵌入的语义部分,虽然BERT的词向量在整体上不具有word2vec[9]所表达的直观语义特征,但是也发现了类似的情感倾向性。
选取了6个情感倾向明显的词例,其中正负类别各3个,分别计算其在原BERT模型和本文模型上的余弦相似度,并将其变化记录在表4中。

Table 4 BERT word vector表4 BERT词向量参数
表4中的值代表该行该列对应的单词对在模型改进前后的词嵌入参数变化量(差值),可以看出,表中情感倾向相同的单词对,其词嵌入的相似度变化都为正值,即在本文的模型中相似度相较原模型有所提升,而表中颜色加深部分的情感倾向相反的词对,相似度则相应降低,这和本文的预期相符,也说明通过单词情感预测任务,BERT的确从无监督文本中学到了有效的情感信息。
4.5 不同情感信息加入方式比较
BERT区别于其他预训练语言模型的一大特点就是使用了自编码语言模型,这是本文的单词情感预测任务的基础。为了验证在单词情感预测任务中对单词进行掩盖的重要性,设计了一组对照实验,分别通过预测掩盖词和非掩盖词的情感来给模型加入外部情感信息,来进一步训练BERT模型,结果如图5、图6所示。
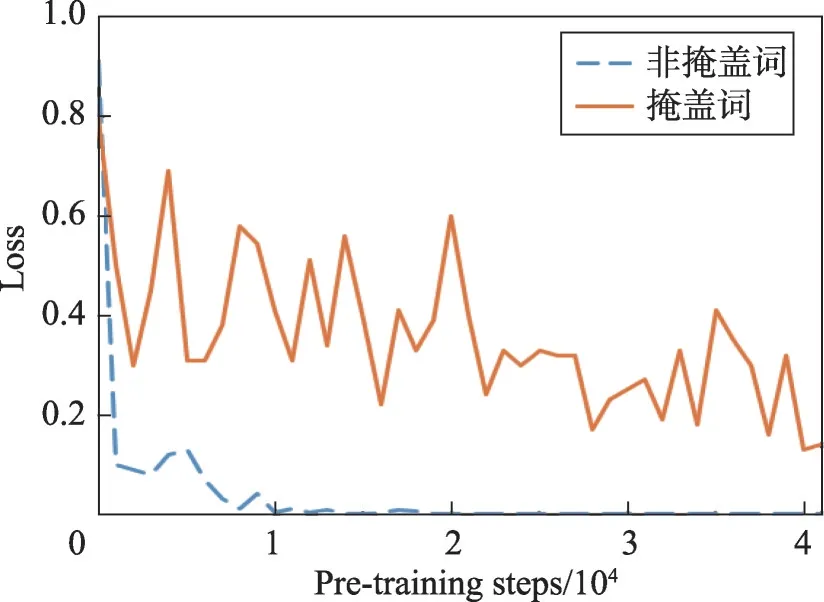
Fig.5 Loss curves of two pre-training methods图5 两种预训练方法的损失曲线

Fig.6 Accuracy curves of two pre-training methods图6 两种预训练方法的精度曲线
从图5可以看出,对非掩盖词进行情感预测,损失非常迅速地下降至0,而掩盖词的损失则下降得更加曲折、缓慢。而在图6中,掩盖词情感预测任务则在目标数据集上明显取得更好的效果,而通过对非掩盖词添加情感信息的方法则对情感任务提升不大,其效果甚至低于原BERT模型。由此推测,由于在本文的词粒度情感预测任务中,所有的被预测单词在输入端都被掩盖,这使得模型无法建立具体某个单词和其对应情感标签的对应关系,以防止该任务出现过拟合。
5 结束语
本文就训练语言语言模型BERT在情感分类任务上的应用进行了研究。提出的改进版模型实现了无监督数据中情感信息的提取,相较原模型在小样本下有较大提升。在实际生产生活中,大规模语料数据容易获得,而手工标注相较比较费时。但是本文对模型的改进停留在目标数据集,并非一个从零开始训练得到的情感模型,下一步尝试从零开始训练BERT。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
计算机研究与发展(2022年1期)2022-01-19
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
文苑(2015年9期)2015-09-10
小学生时代·大嘴英语(2014年9期)2014-11-04
