
紧凑的神经网络模型设计研究综述*
2020-09-13 13:53夏应清
计算机与生活 2020年9期
郎 磊,夏应清
华中师范大学物理科学与技术学院,武汉 430079
1 引言
近年来,卷积神经网络(convolutional neural networks,CNN)在计算机视觉[1-6]、自然语言处理[7-9]、数据挖掘[10-12]等领域获得广泛的应用,并取得了优秀的表现。这些技术上的突破与庞大的数据量和强大的计算资源密切相关。例如,AlexNet[13]在自然图像识别领域取得了突破性进展,它使用了约120万张图像在多个运算设备上进行训练。从那时起,人们意识到CNN的性能要优于其他方式,进而对其性能的需求不断提高。与此同时,CNN的计算复杂度以及存储需求也急剧增加,如VGG[14]、GoogleNet[15]等网络需求100 MB以上的储存空间和上亿次的计算操作。
由于配备了丰富的内存资源和计算单元的GPU和CPU集群的出现,可以在较为合理的时间内训练出功能更强大的CNN。与此同时,人们在无人驾驶[16]、无人机[17]、智能手表[18]、智能眼镜[19]等移动设备取得了巨大的进步,在这些设备上部署CNN模型的需求变得愈发强烈。可是,这些设备在存储能力、计算单元和电池电量等资源上显得十分匮乏,因此在低成本环境中使用CNN模型成了真正的挑战。
当前的关键问题是如何在不显著降低网络性能的情况下为移动端或嵌入式设备配置有效的神经网络模型。为了解决这个问题,在过去的几年时间里,提出了许多压缩与加速模型的方法[20-23]。本文主要对紧凑的神经网络模型设计这种方法进行详细的探讨和叙述。
2 网络压缩与加速
从模型是否预先训练的角度,网络模型加速与压缩方法可分为以下两大类,分别是神经网络的压缩和紧凑的神经网络设计。
2.1 神经网络压缩
通过对现有的预先训练网络模型进行压缩,变成一个轻量级的神经网络,有以下四种不同的方法。
(1)网络修剪(network pruning)删除了深度网络中不重要或不必要的参数,提高了网络参数的稀疏性,修剪后的稀疏参数需要较少的磁盘存储空间,且省略了网络中不重要参数计算,降低了网络的计算复杂度[24-28]。
(2)低秩分解(low-rank decomposition)利用矩阵或张量分解技术估计并分解深度模型中的原始卷积核,通过分解4D卷积核张量,可以有效地减少模型内部的冗余性,从而降低网络的参数和计算量[29-30]。
(3)网络量化(network quantization)将计算程序中使用的浮点数由32 bit或者64 bit存储大小替换为1 bit、2 bit的方式,减少程序内存占用空间,以此来减少计算复杂度和参数占用内存大小[31-32]。
(4)知识蒸馏(knowledge distillation)使用大型深度网络训练一个更加紧凑的神经网络模型,即利用大型网络的知识,并将其知识迁移至紧凑模型中[33]。
这些方法可以有效地将现有的神经网络压缩成较小的网络。但它们的性能很大程度上依赖于给定的预先训练的网络模型,没有架构层面的改进,无法进一步提高准确性。
2.2 紧凑的神经网络设计
紧凑的神经网络设计方法并未对预先训练网络模型进行压缩,而是直接设计出具有较小计算复杂度和参数量的新型网络。如何设计一个紧凑的神经网络是近年来的研究热点。
采用不同的空间卷积运算方式构建一个精确而轻量级的网络,是常用的设计方法。例如:在NIN[34]模型中提出了网络内嵌网络的架构,利用1×1卷积来增加网络容量,同时保持整体计算复杂度较小。GoogleNet中使用平均池化层代替了全连接层,减少了网络模型的存储需求。SqueezeNet[35]利用1×1卷积和分组卷积方法,在AlexNet上实现了约50倍的压缩,并且具有相当的精度。MobileNetV1[36]中提出了深度可分离卷积方法,并将该方法应用得很好,模型比VGG-16模型缩小了96.8%,且速度快27倍;Mobile-NetV2[37]是在MobileNetV1的基础之上添加了残差结构和线性瓶颈结构。ShuffleNetV1[38]利用分组卷积和Channel Shuffle的方法缩减网络模型大小,提高运行效率。ShuffleNetV2[39]是对ShuffleNetV1的网络结构的进一步的改进。ESPNetV2[40]提出深度可膨胀可分离卷积,且对ESPNetV1[41]模型结构进行通用化改进,运行效率高,模型小,准确度强。
此外,采用移位运算和卷积运算相结合的方式同样可构建出较为紧凑且强大的网络模型,例如:ShiftNet[42]采用移位运算与逐点卷积相结合的方式,构建出一个紧凑的网络模型。As-ResNet[43]使用主动移位代替深度可分离卷积运算,并针对移位卷积运算设计了主动移位层(active shift layer,ASL),提高了模型学习和运行的效率,减少了参数量。FE-Net[44]中稀疏移位层(sparse shift layer,SSL)是对ASL层的改进,消除了无意义的移位操作,进一步加快了模型运行的速度。
紧凑的神经网络设计原则虽有不同,但其均是设计特殊的结构化运算核或紧凑计算单元,减少模型的参数量,降低计算复杂度。本文主要对紧凑神经网络模型设计的相关技术进行进一步的讨论,并选取近3年提出的6种紧凑神经网络模型进行学习和比较,分析各自性能特点,同时对实现轻量化的方法进行总结。6种模型分别是MobileNetV2、ShuffleNetV2、ESPNet-V2、ShiftNet、As-ResNet和FE-Net。其中MobileNetV2是MobileNetV1的改进版,ShuffleNetV2的网络结构也是基于ShuffleNetV1的网络结构,ESPNetV2是对ESPNetV1进行通用化的结果,FENet的基础运算方式是基于ShiftNet和As-ResNet的基础运算方式改进而来的。这4类网络在实现轻量化的方法上具有极高的参考价值。
3 紧凑的神经网络
紧凑的神经网络模型设计,是指参考现有的神经网络结构,改变基本运算方法,并重新设计网络结构,以此设计出参数量少、运算复杂度低的新型网络。本文首先对基础运算方式进行介绍,根据运算方式的不同,将模型设计分为基于空间卷积运算的模型设计和基于移位卷积运算的模型设计,并分别介绍了3个典型网络模型。
3.1 基本运算
在神经网络中,基本运算单元主要的作用是聚合空间信息,提取局部特征值。空间卷积运算和移位卷积均可实现该功能,下面主要针对这两种基本运算单元进行描述。
3.1.1 空间卷积运算
常用的空间卷积运算主要有标准卷积、分组卷积(group convolution)、逐点卷积(pointwise convolution)和膨胀卷积(dilated convolution)。标准卷积是一种有效提取空间信息特征的运算方式,一般使用卷积核遍历空间中的每一个区域,对重合区域内的值进行求和,再加偏激值后,得到输出空间的特征图,其结果与每个通道特征都有关。假设W×H为输入输出特征图的空间尺寸,M为输入特征的通道数,N为输出特征的通道数;卷积核尺寸为K×K×M,数量为N计算如图1所示。

Fig.1 Standard convolution calculation图1 标准卷积计算
分组卷积是对标准卷积的一种变形,最早在Alex-Net中出现,解决了硬件资源有限的问题。输入特征图在通道上被分成G组,这种分组仅在深度上进行划分,每组通道数为M/G。卷积核的深度变成M/G,而卷积核的大小并不需要改变,此时卷积核的数量变为N/G。经过卷积运算后,将不同组的内容进行拼接起来,最终输出通道仍为N。相对于标准卷积,分组卷积的参数量缩小1-1/G,计算量降低为1/G。分组卷积虽然大大降低了计算复杂度和参数量,但是其仅聚合了组内的空间信息,组间“信息流通不畅”。
逐点卷积是一种特殊的标准卷积运算,卷积核K值为1。逐点卷积主要用于改变输出通道的特征维度,且能够有效地“混合”通道间的信息,解决了分组卷积中存在的“信息流通不畅”的问题。
膨胀卷积是一种特殊的卷积运算,改变了卷积核的计算方式[45]。膨胀卷积引入了膨胀率r,用于表示扩张大小,即卷积核中值与值之间的间隔,如图2为不同膨胀率的3×3卷积计算示意图。r=1时为标准卷积核;r=2时,可看出卷积核的内容并未发生改变,仅改变了卷积运算时,卷积核所感受的图像视野大小,中间空着的像素并未参与具体运算。因此其对计算复杂度和参数值大小并未发生变化。在相同计算条件下,膨胀卷积运算拥有更宽的视野,可以捕捉到更长的依赖关系,非常适用于需求宽视野小卷积核的计算。膨胀卷积主要用于增强信息间的关联度,防止信息的丢失。

Fig.2 3×3 convolution calculations at different expansion rates图2 不同膨胀率下的3×3 卷积计算
3.1.2 移位卷积运算
目前,常用的移位卷积运算主要有标准移位、分组移位(grouped shift)、主动移位(active shift)和稀疏移位(sparse shift)。标准移位如图3所示,标准移位由两个步运算完成,分别是移位运算和逐点卷积运算。移位运算是将通道向一个方向进行移位,移位内核中存储移位方向信息。逐点卷积运算主要是对移位运算后的信息进行“混合”。与深度卷积不同,移位运算本身不需要参数或浮点运算,它仅是一系列内存方面操作,而逐点卷积运算占用了大部分的参数和浮点运算操作。

Fig.3 Standard shift operation图3 标准移位运算
分组移位是对标准移位的一种变形,其关系类似于分组卷积与标准卷积,操作方式如图4(a)所示。将通道划分为若干组,其中每组通道采用同一方向的移位运算,然后进行逐点卷积运算。分组移位具有较少的参数量和移位空间,能够有效地加速网络训练。分组移位最早在ShiftNet中出现,用于解决搜寻最佳位移值计算量过大的问题。
主动移位是标准移位量化形式的另一种体现,相较于分组移位而言,通道移位的可能性更多,对通道间信息的“混合”程度更高。操作方式如图4(b)所示,每个通道均进行了移位运算,且移位方向更多,后由逐点卷积运算“混合”通道信息。假设M为输入特征的通道数量,Dk为水平和垂直最大移位量,主动移位运算有种移位可能性。在网络训练中,需要计算所有可能性下的输出特征图,找出最佳移位值,这需要极大的计算量,而且主动移位运算将在网络中多次使用,网络训练所需计算成指数上升。在As-ResNet中,采用水平移位参数α和垂直移位参数β表示移位方向,同时提出了α和β可微的方法,最终实现移位参数可学习的目的,提高了网络训练的速度。
稀疏移位是一种特殊的主动移位,将移位通道划分为两部分,一部分进行移位运算,而另一部分保持不变,其操作方式如图4(c)所示。稀疏移位中并非所有的通道都参与移位运算,仅有部分特殊通道参与了移位运算,而后进行逐点卷积运算。假定参与移位运算的通道数量为M′,其中M′<M,移位内核的数量同样由M降低至M′,稀疏移位运算有种移位可能性,极大地缩小了搜寻范围,降低了网络的参数量。与主动移位相比,稀疏移位减少了不必要的操作,降低了参数量。此外,解决了较多移位运算会造成重要信息丢失的问题,保证了信息的完整度。在FE-Net中,引入移位惩罚因子实现稀疏移位运算,降低了网络的参数,提高了网络运行的效率。

Fig.4 Different shift operations applied to feature maps图4 应用于特征图的不同移位操作
3.2 基于空间卷积的模型设计
MobileNetV2、ShuffleNetV2和ESPNetV2均是对基础模型的空间卷积运算改进而成的。因此,本节主要对空间卷积运算进行分析,进而给出合适的构建块,最终给出整体网络结构,并总结模型特点。
3.2.1 MobileNetV2
MobileNetV2[37]是Google公司为移动设备和嵌入式视觉应用提出的一个尺寸小、延迟低的卷积神经网络,是MobileNetV1的改进版。整体网络沿用了MobileNetV1的深度可分离卷积作为基础运算单元,从而实现较低参数量和计算量。
标准卷积可分解成一个深度卷积和一个逐点卷积,这就形成了深度可分离卷积。假设H×W×M表示输入特征,输出特征为H×W×N,标准卷积核如图5(a)所示,标准卷积层参数量为K2MN,标准卷积的计算复杂度为K2MNHW。深度卷积核如图5(b)所示,深度卷积运算的计算复杂度为K2MHW,参数量为K2M。深度可分离卷积从参数量和计算复杂度方面均有了明显的下降。
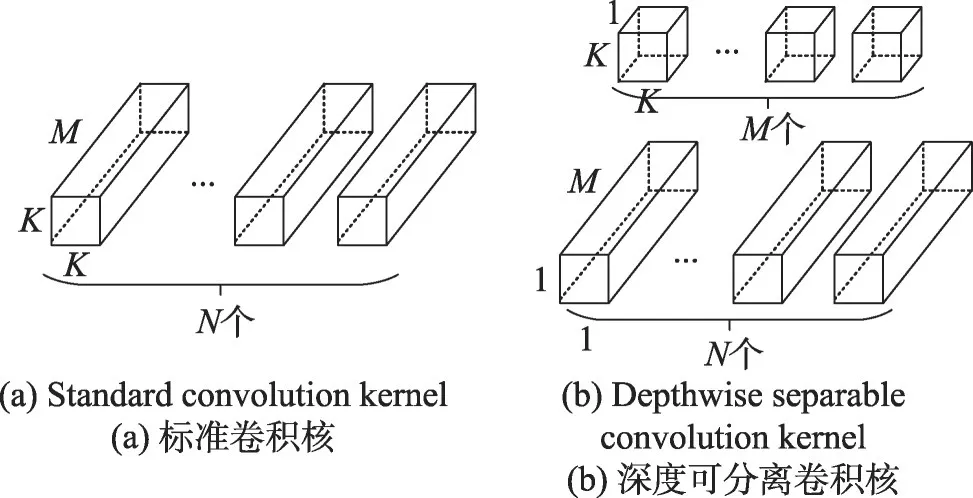
Fig.5 Standard convolution kernel and depthwise separable convolution kernel图5 标准卷积核和深度可分离卷积核
此外,MobileNetV2在结构上借鉴了ResNet[46],并进行了以下两方面改进:一是引入了线性瓶颈结构,即删除了在低维度输出层后所连接的非线性激活层,保证了信息的完整性;二是引入了反向残差结构。采用先“升维”再“降维”的方式,保证了特征信息的有效传递。
MobileNetV2基本构建块是具有反向残差的深度可分离卷积块,该基本构建块的详细结构如图6,首先通过1×1卷积层,对其输入通道维度升高;随后使用深度可分离卷积混合信息;最后经过1×1卷积运算降低维度。

Fig.6 Basic building blocks of MobileNetV2图6 MobileNetV2的基本构建块

Table 1 MobileNetV2 architecture表1 MobileNetV2整体网络结构
MobileNetV2整体网络结构如表1所示。其中t表示模型的核心构建块中的扩展因子,c为输出通道数,n为每层重复运行的次数,s为重复计算中第一次的步长,其余步长均为1。MobileNetV2中使用ReLU6作为非线性激活函数,在低精度计算时具有较高的鲁棒性。模型训练时,利用Batch Normalization[47]和Dropout[48]避免了梯度消失和退化的问题。
MobileNetV2创新点在于采用MobileNetV1的深度可分离卷积作为基础运算单元,降低了模型的大小,引入了线性瓶颈和反向残差结构,保证了信息的完整性,有效地解决了梯度消失等问题。但在应用中存在一定局限性,网络尺寸大小应高于一定数值,即网络通道数量不应设置过少,否则会导致信息传递过程中丢失过多信息,进而大幅度降低精确度。
3.2.2 ShuffleNetV2
ShuffleNetV2是旷视科技提出的一种高效的CNN模型,和MobileNetV2一样适用于移动端的轻量级网络模型。网络同样采用深度可分离卷积作为基础运算单元。
ShuffleNetV2构建模块如图7所示。对于步长为1的模块,引入了一种名为通道分片(channel split)的运算方法,该方法将输入通道一分为二,其中一部分向下直接传递,另一部分进行卷积运算,将二者结果进行合并,且后不加ReLU操作,输出信息前进行Channel Shuffle操作,增加通道之间的信息交流。对于步长为2的采样模块,该层需要将通道数量翻倍,即直接将输入通道传向两个部分,最后结果进行合并。

Fig.7 ShuffleNetV2 basic building blocks图7 ShuffleNetV2基础构建模块
ShuffleNetV2中Channel Shuffle操作主要是为了解决不同组卷积间信息交流不畅的问题。如图8(a)所示,输入特征被分为3组,若存在3组卷积,组与组之间信息并无交流,影响了模型的表达能力,因此需要增加组件信息交流的机制。图8(b)中所示,对不同组卷积后的特征图进行“重组”操作,这样同样可以完成组间信息交流的目的,但是Channl Shuffle采取的“重组”策略更为优秀,即按照一定规律进行重组,具体实现如图8(c)所示。ShuffleNetV2整体网络结构如表2所示。
ShuffleNetV2的创新点在于采用了Channel Shuffle操作,来提高组间的信息交换。此外,提出了轻量级网络结构设计的四项实用准则:一是输入通道数与输出通道数保持相等可以最小化内存访问成本;二是分组卷积中使用过多的分组会增加内存访问成本;三是网络结构太复杂(分支和基本单元过多)会降低网络的并行程度;四是元素级别的操作消耗不能够忽视。但ShuffleNetV2模型对内存访问效率提出了更高的需求,内存访问效率直接影响Channel Shuffle的运行速度,进而改变网络预测快慢。
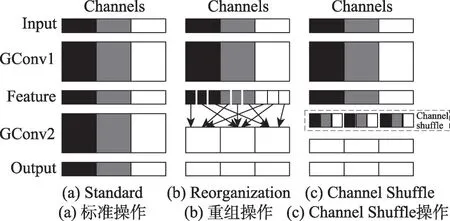
Fig.8 Channel Shuffle图8 Channel Shuffle操作

Table 2 ShuffleNetV2 architecture表2 ShuffleNetV2整体网络结构
3.2.3 ESPNetV2
ESPNetV2是对应用于语义分割的卷积神经网络ESPNetV1进行通用化后推出的网络结构。该网络的核心构建模块是EESP单元,它使用可膨胀可分离卷积来代替标准卷积运算。深度可膨胀可分离卷积(depthwise dilated separable)通过将标准卷积分解为两层,来实现过滤器的轻量化:一是深度可膨胀可分离卷积引入了膨胀率r,该参数能够有效提高卷积运算的感受野(receptive field);二是逐点卷积学习输入的线性组合,降低了计算成本。假设输入通道数为M,输出通道数为N,卷积核大小为K×K。深度可膨胀可分离卷积计算复杂度是标准卷积的1/N+1/K2倍。表3中提供了不同类型卷积之间的比较。其中EFF代表的是有效感受野值,g为分组的数量,Kr=(K-1)×r+1。

Table 3 Comparison of different convolution EFF values表3 不同卷积EFF值对比
下面具体介绍ESPNetV2的核心构建模块EESP(extremely efficient spatial pyramid of depthwise dilated separable convolutions)单元,其结构如图9所示。步长为1的EESP单元如图9(a),首先是1×1分组卷积,然后是3×3的深度可膨胀可分离卷积,紧接着使用层次特征融合(hierarchical feature fusion,HFF)对结果进行融合,有效地消除由膨胀卷积引起的gridding artifacts[49-50]问题。对于带有Stride的EESP单元如图9(b),在原有EESP基础上,将深度可膨胀可分离卷积的步长设置为2,并对输入通道进行3×3平均池化,所得结果和输出进行拼接;此外,将输入图像进行P次3×3平均池化,然后进行3×3卷积和1×1卷积,最后结果与拼接特征图相加。其中每个卷积层表示的含义如下:Conv-n,n×n标准卷积;GConv-n,n×n组卷积;DConv-n,n×n膨胀卷积;DDConv-n,n×n深度膨胀卷积;括号内表示的分别为输入通道数、输出通道数和膨胀率。
ESPNetV2的整体网络结构如表4所示,为了增加网络深度,该网络会重复使用EESP单元。在EESP单元之后使用batch normalization和PReLU[51],但最后一次卷积运算除外。在实验中,将膨胀率r与EESP单元中分组数g设置为正比关系,其感受野随着g增大而增大。同时限制了每个空间感受野维数,以此减少梯度消失问题的出现。

Table 4 ESPNetV2 architecture表4 ESPNetV2整体网络结构

Fig.9 ESPNetV2 basic building blocks图9 ESPNetV2的基础构建块
ESPNetV2创新点在于提出了深度可膨胀可分离卷积代替深度可分离卷积的方法,并采用层次特征融合(hierarchical feature fusion,HFF),消除gridding artifacts问题,降低了网络计算复杂度,提高了网络的感受野。但在应用中,膨胀率r不会随着输入图像分辨率的大小而改变,需要根据经验设置膨胀率数值大小。
3.3 基于移位卷积的模型设计
ShiftNet、As-ResNet和FE-Net是将基础模型中空间卷积运算替换为移位卷积运算改进而成,采用不同的移位卷积运算,但其网络结构均由基础构建块组合而成。因此本节同样从基础运算、核心构建块和整体网络结构三方面进行分析,并对模型特点进行总结。
3.3.1 ShiftNet
ShiftNet是由伯利克大学的研究人员提出的一种无参数、无FLOP的移位运算代替空间卷积运算的一种新型网络结构。此网络结构的核心构建模块是CSC(conv-shift-conv module)。CSC模块是对残差单元模块的改进,使用分组移位替换了常用的空间卷积运算。
分组移位是一种特殊的标准移位,具有较少的移位内核。对于标准移位而言,给定移位内核大小为Dk,通道大小为M,有种移位内核的可能性。在此状态空间上搜索最佳移位内核成本过高,因此采用分组移位方式,将M个通道平均分为组,每组通道采用同一种移位方向,大大减少了状态空间,提高了移位搜寻的效率。
CSC结构如图10所示,首先输入特征通过逐点卷积进行处理,然后执行移位运算,重新分配空间信息,最后使用逐点卷积来混合通道间的信息。其中,在两个逐点卷积运算前均进行了Batch Normalization和ReLU非线性激活函数。参照ShuffleNetV1中核心构建块的设计特点,若步长为1时,即输入和输出的尺寸相同,采用加性操作进行连接;若步长为2,即输出通道数翻倍,对输入特征图进行平均池化,二者结果采用通道级联进行连接。其中,移位运算的内核大小用于控制模块的感受野;膨胀率d表示为“膨胀移位”后数据采样的空间间隔,类似于膨胀卷积。

Fig.10 ShiftNet kernel building block CSC图10 ShiftNet的核心构建块CSC
ShiftNet的整体网络架构如表5所示。为了进一步压缩模型,ShiftNet采用扩展因子ε控制中间通道的数量,其方法与MobileNet中宽度因子α相似,控制每个基础构建块的大小,表5中描述的架构称为ShiftNet-A。对于更小的网络架构ShiftNet-B和ShiftNet-C而言,ShiftNet-B是将所有CSC模块中的通道数量减少2;ShiftNet-C则是把ShiftNet-A组{1;2;3;4}中使用CSC模块数量更改为{1;4;4;3},通道数量变更为{32;64;128;256}。
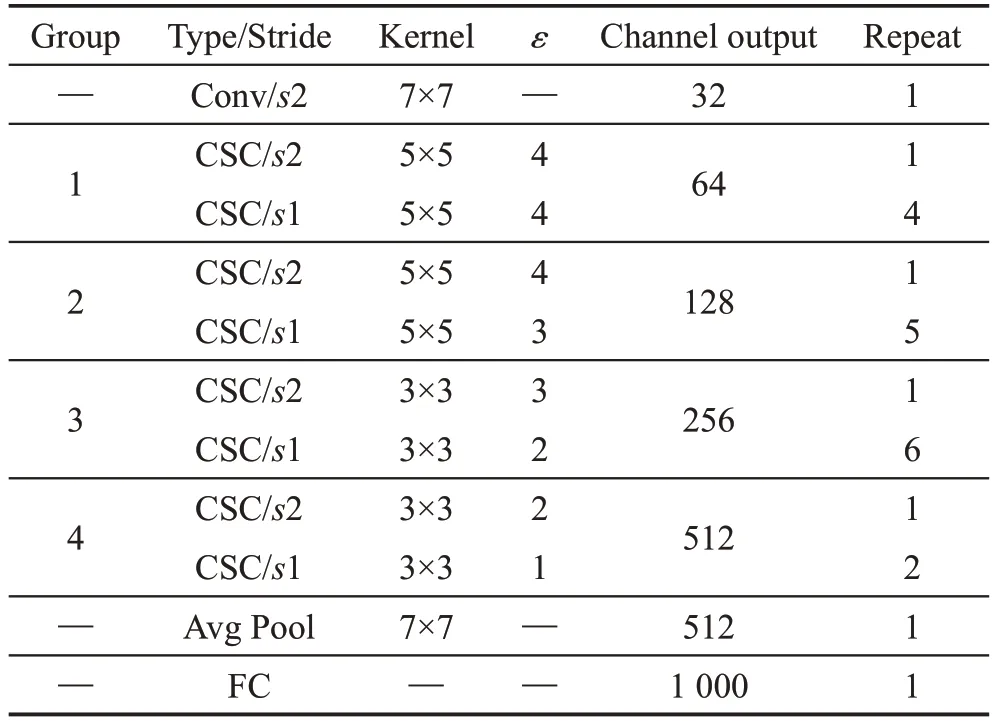
Table 5 ShiftNet architecture表5 ShiftNet整体网络结构
ShiftNet创新点在于提出了使用移位运算和逐点卷积代替空间卷积完成聚合空间信息的方法,利用移位运算本身不需要参数和计算的优势,有效地减少了计算复杂度和参数量。同时,为了提高网络的训练效率,采用了分组移位的方法,减少了状态空间的大小。此外,网络的基础模块引入扩展因子ε,用于均衡网络大小和准确度。但ShiftNet在实际应用中仍有限制,模型训练时间相对较长,而且训练结果未必为最优值。
3.3.2 As-ResNet
ShiftNet采用移位运算和逐点卷积代替空间卷积的方式,减少计算复杂度和参数量。但网络中移位量采用启发式进行分配,网络训练时间较长且优化困难,并不能达到网络压缩最优的目的。参照反向传播算法的特点,结合ShiftNet的标准移位,提出了主动移位,并应用于ResNet网络,形成新型网络As-ResNet。其网络主要对基础运算方式进行改进。
不同于标准卷积运算,主动移位将卷积运算解构为两个操作步骤进行实现,分别是移位运算和逐点卷积运算。其具体解构卷积如图11所示,观察标准卷积运算基本构成,标准卷积等价于逐点卷积的总和,利用移位输入代替卷积核参与运算,最后共享移位输入,形成这种运算方式。该运算方式具有较少的计算量和内存访问,但是在移位方向仅有一个的情况下,运算的性能会大打折扣。为了保证移位输入具有较高的性能,设计了主动移位层(ASL)。ASL使用深度移位方法,为每个通道引入移位参数α和β,并提出了α和β可微的方法,即在运算中,将α和β的整数约束放宽为实值,并放宽对双线性插值的移位运算。因此,该方法的参数具有可学习的能力,通过反向传播算法进行优化,以达到计算速度更快、网络更小的目的。
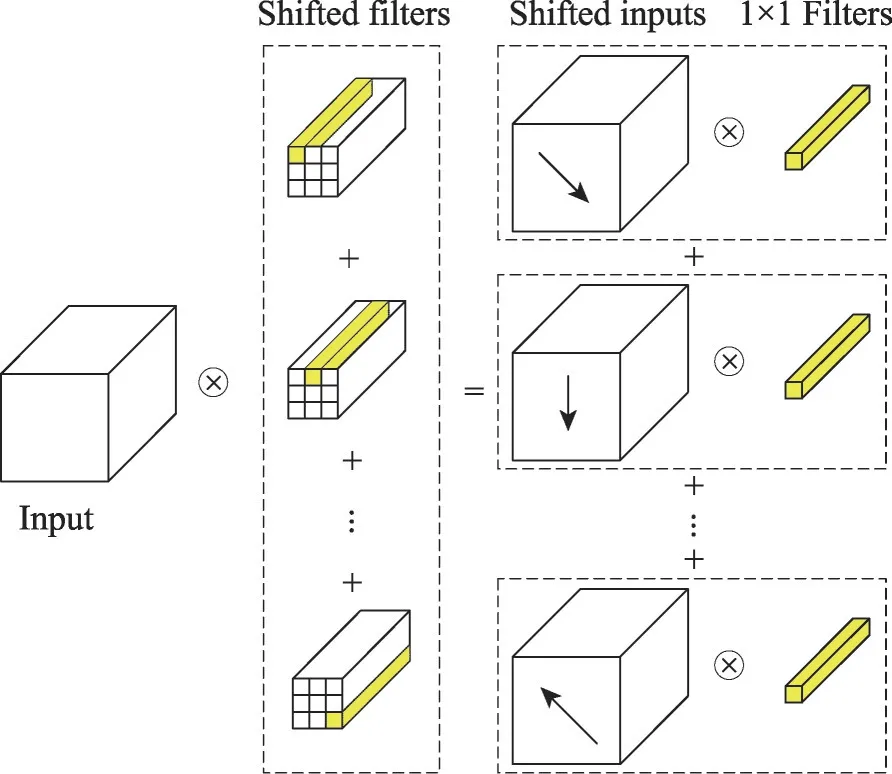
Fig.11 Deconstructed convolution图11 解构卷积示意图
As-ResNet的整体网络结构如表6所示,其中基础构建块是由BN-ReLU-1×1 Conv-ASL-BN-ReLU-1×1 Conv顺序构成,与ShiftNet中CSC模块相似,n为重复运行该层的次数,s为步长。网络整体结构仅在第一层使用了空间卷积运算。随着网络深度的增加,辅助层的数量增多,为了进一步控制网络的大小和准确性,采用与MobileNet、ShuffleNet同样的方法,加入了基本宽度参数w,控制输出通道数。

Table 6 As-ResNet architecture表6 As-ResNet整体网络结构
As-ResNet的创新点在于使用主动移位替代空间卷积,并以此设计了主动移位层(ASL),将移位运算量化为具有参数的函数,而且可以通过反向传播来学习移位量,能够模仿各类型卷积运算。但As-ResNet中移位运算依靠于内存操作,其直接影响网络运行效率,选用合适的硬件设备十分重要。
3.3.3 FE-Net
移位卷积运算是一种有效的超越深度可分离卷积的方法,在ShiftNet和As-ResNet中均有了较好的成效,但它的实现方式仍是一大难题,即内存移动。因此,FE-Net提出了基于稀疏移位层(SSL)的卷积神经网络构建方法,即使用稀疏移位运算代替标准卷积,具体实现方法为:在损失函数中,给移位操作添加惩罚项,去除无用的移位操作。随后,采用量化感知的移位学习方法,使移位运算可微,确保了移位卷积的可学习性。最后,为了最大程度发挥SSL的作用,FE-Net重新设计了基础构建块,并对网络体系结构进行相应的改进。
FE-Net的核心构建块FE-Block(fully-exploited computational block)是网络的重要组成部分,其结构如图12所示。在这个构建块中,每次基本计算仅有一部分特征参与其中。对于不同的计算块,参与计算的特征图数量会随着计算的深入逐渐增加。对于具有n=3个基本单元的计算块,输入特征图被均匀划分为2n-1部分,第m个计算块进行计算时,有2m-1部分参与其中。FE-Block的基本计算单元如图13所示,图13(b)主要用于核心构建块中使用,但对于每个计算块的最后一个计算单元,使用图13(a)来更改下一个计算块的通道数量,或者使用图13(c)进行空间向下采样。

Fig.12 FE-Block:FE-Net kernel building block图12 FE-Net的核心构建块FE-Block

Fig.13 FE-Block basic calculation unit图13 FE-Block的基本计算单元
FE-Net的整体网络结构如表7所示,其中t表示基础运算单元中,第一个1×1卷积输入通道的扩展率;该运算块重复n次,输出通道数为c,步长为s。为了进一步平衡网络的大小和准确率,网络中引入了宽度因子作为超参数。
FE-Net的创新点在于引入了SSL,能够快速准确地建立神经网络,减少了无意义的移位操作;随后采用量化感知的移位学习方法,保证移位卷积的可学习性,同时避免了推理过程中的插值;最后根据SSL的特点,设计了一个紧凑的神经网络。FE-Net尺寸不能设置过小,该方式不仅导致稀疏层无效化,而且影响信息传递的完整性。

Table 7 FE-Net architecture表7 FE-Net整体网络结构
4 网络性能对比
为了更直观地分析6个紧凑的神经网络性能,在ImageNet2012数据集上进行实验,实验结果如表8所示,主要参数有模型的参数量、FLOPs和分类准确率。表格按照参数量数值大小分为4组进行对比,即1.2、3.6、6.5和10+Parames/106。与此同时,表格中加入了3个常规网络在该数据集上运行的参数。在模型训练时,通过调整超参数,均衡网络在精度及速度方面的性能,其中超参数多指宽度因子,即各个基础构建块间衔接时输入输出通道数量,若减少该值大小,网络精度会有所下降,但预测速度加快。另外,存在部分网络通过调整网络中的重要参数,进一步改善网络的精度和速度,如MobileNetV2的扩展因子t、ESPNetV2的膨胀率r、FE-Net的扩展率等。
分析表8中数据不难看出,在同等模型参数量的条件下FE-Net的分类准确度要高于其他5个网络框架,而ShuffleNetV2的表现也同样出彩。将其按照基本运算方式进行分类,即MobileNet、ShuffleNet和ESPNet是基于空间卷积的模型,简称为第一类网络;ShiftNet、As-ResNet和FE-Net是基于移位卷积的模型,简称为第二类网络。
对比第一类网络模型,在同等计算复杂度的情况下,ShuffleNetV2表现要优于其他两个网络结构,且参数量也并无较为明显的差距。在具体硬件设备上进行测试,ShuffleNetV2预测速度最快,而ESPNetV2的准确度虽略逊于ShuffleNetV2,但其功耗最低,主要由于ESPNetV2网络结构设计较为简单,且没有采用通道混洗的方法,减少了对内存的访问操作,在保持功耗较低的情况下拥有相当的准确度。

Table 8 Performance comparison of multiple network models on ImageNet2012 dataset表8 多网络模型在ImageNet2012数据集上性能对比
对于第二类网络模型,在同等参数量的条件下,FE-Net的分类准确度最优,这主要因为稀疏移位比主动移位和分组移位在空间信息特征提取度高,减少了无用的移位操作,节省了资源。
对比第一类和第二类网络结构可发现,第二类网络结构的计算复杂度普遍较高,即FLOPs较高。FLOPs虽然被广泛应用于比较模型的计算复杂度,并且认为它与时间运行成比例,但在文献[39,43]均提出,FLOPs仅是衡量模型计算复杂度的间接指标之一。内存访问成本(memory access cost,MAC)和模型并行度也是影响模型间接计算复杂度的情况之一。此外,第一类的FLOPs主要由深度可分离卷积提供,而第二类的FLOPs主要由1×1卷积提供。文献[43]对1×1卷积运算和3×3深度可分离卷积的运算效率进行对比,尽管1×1卷积的FLOPs要大很多,但是它的运行效率要远高于3×3深度可分离卷积。这一点在实验中得到了验证,在同等的计算能力设备上,As-ResNet和FE-Net模型在GPU和CPU上的运行速度快于MobileNetV2。
最后,对比紧凑的神经网络和3个常规网络的准确度、FLOPs和网络参数量,常规卷积神经网络AlexNet、GoogleNet和VGG-16在各个方面的参数都略逊于这6个紧凑的神经网络,甚至在准确度方面已经远超于常规网络。这表明,紧凑的神经网络设计并不是必须牺牲网络准确度来获取更小的网络模型尺寸的,在降低网络模型尺寸的同时,也可拥有较高的准确度。
5 紧凑神经网络设计技巧
本文所列的六个模型对于人工设计紧凑神经网络架构有着重要的意义,其设计方法典型有效。首先,对这六个模型的设计方法进行梳理和总结,然后得出紧凑神经网络架构设计的要点,最后讨论紧凑神经网路的发展方向。
MobileNetV2使用深度可分离卷积降低了计算复杂度,减少了参数量。此外,引入了反向残差和线性瓶颈,有效解决了梯度消失的问题,同时极大提高了网络的准确性,降低了计算复杂度。ShuffleNetV2提出了Channel Shuffle操作,解决了不同组间“信息交流不畅”的问题,提出了轻量级网络结构设计的四项实用准则。ESPNetV2提出了深度可膨胀可分离卷积,提高了网络的感受野。采用分层特征融合方法,有效解决了膨胀卷积运算引起的gridding artifacts问题。最终达到分类准确度在同等计算复杂度情况下与ShuffleNetV2基本一致,且具有较低的功耗。
ShiftNet采用分组移位运算,具有较高的运算速度。As-ResNet对ShiftNet的移位操作进行改进,提出了主动移位运算方法,并设计了主动移位层(ASL),使得移位卷积可通过反向传播学习移位量。FE-Net将稀疏移位应用于卷积神经网路中,是对移位卷积的又一次“升华”,去除了无用的移位操作,极大发挥了移位操作的优势。
六大紧凑网络模型对比分析如表9所示,具体从设计技巧、优缺点、应用建议三方面进行介绍。从表9中可以看出,基础运算直接影响网络的表现,网络结构也应根据不同的基础运算做出相应的调整。在网络结构设计时,网络深度并非越深越好。具体应用网络时,根据网络特点,选用匹配的硬件器件,并对其做出相应优化。

Table 9 Comparative analysis of six compact network models表9 六大紧凑网络模型对比分析
对比这六个模型设计紧凑神经网络的方法,残差单元是紧凑神经网络模型的重要参考结构。残差网络有效地解决了网络退化和梯度消失问题,在网络准确度较低的情况下,可以通过增加网络的深度来提高网络的性能。这一结构特点有利于紧凑神经网络模型的设计的集中性,无需考虑网络深度对其准确度的影响,极大地缩减了模型设计的时间。
再者,采用不同的基础卷积运算对设计紧凑神经网络模型设计有很大的提升,MobileNet和Shuffle-Net采用深度可分离卷积作为基础卷积运算单元,降低了卷积运算计算复杂度,减少了参数量;ESPNet采用深度可膨胀可分离卷积作为基础卷积运算单元,在深度可分离卷积的基础上增加了运算的感受野。因此,选用适当的基础卷积运算对设计紧凑神经网络模型有着重要意义。
与卷积运算相比,采用标准移位运算同样能够实现聚合空间信息的目的,是一种有效的替代方法。标准移位先将输入信息进行移位运算,重新排列空间信息,后进行逐点卷积,聚合空间信息。标准移位运算在速度上要优于标准卷积运算,且其计算代价与核大小无关。因此,这样的运算方式有利于紧凑神经网络模型的设计。
此外,可以采取与其他方法相结合的方式,进一步提高网络性能。例如,网络可配备SE模块(squeezeand-excitation)[52],一般放置于基本构建块的输出位置,利用通道间的相关性,强化重要通道的特征,提升准确度。虽然SE模块可以提高原有网络的准预测准确度,但会降低一定运行速度。因而,这一方法仅适用于提高网络准确性,具体使用还需权衡。
另外,神经网络架构搜索(neural architecture search,NAS)是近年来提出的自动化设计神经网络的方法,可自动设计网络结构[53-56]。在网络架构搜寻前,需要对卷积层、卷积单位和卷积核的大小等参数进行预先设定,随后使用预设定的参数在一个巨大的网络空间上搜寻。其中文献[54-55]对MobileNetV2进行了改进,并取得了良好的效果,但对资源消耗量较大,有一定的局限性。对于资源较为充沛设计人员,不失为一种设计轻量化模型的好方法。
最后,计算复杂度和参数量仅能代表网络的部分性能优劣,对于紧凑的神经网络模型性能的测试,应在具体设备上进行测试,比较网络的性能。与此同时,为了打破算法建模和硬件实现之间的鸿沟,硬件-软件协同设计方法也将成为未来的发展趋势。
6 结束语
深度神经网络在广泛的应用中得到了优秀的表现,让神经网络真正地走向生活中,需要对网络模型在大小、速度和准确度方面做出平衡,以能够成功实现网络运行在资源紧缺的移动端或嵌入式设备。本文首先简述了网络压缩与加速的两种方法,即神经网络压缩和紧凑神经网络设计。随后重点介绍了紧凑神经网络设计的主流方法,并根据不同的基本运算分为空间卷积和移位卷积两大类。同时,还对这两大类中典型网络模型进行了梳理和论述,并且分析了网络性能的优缺点。最后,总结了紧凑神经网络设计的技巧,并对其发展方向进行了展望。
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
无线互联科技(2022年7期)2022-06-23
昆明医科大学学报(2022年4期)2022-05-23
社会科学战线(2022年2期)2022-03-16
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
数学学习与研究(2020年22期)2020-01-11
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
