
面向申威众核处理器的LZMA并行算法设计与优化*
2020-09-13 13:53李秉政黄高阳许瑾晨
计算机与生活 2020年9期
李秉政,黄高阳,许瑾晨
1.数学工程与先进计算国家重点实验室,郑州 450000
2.江南计算技术研究所,江苏无锡 214125
1 引言
随着高性能计算机性能的提升,其规模不断扩大。大规模的高性能计算集群系统必须保持长期稳定的不间断运行,其传输、存储和处理的数据量不断增长,随之产生的系统日志数据量也呈现出爆炸式增长。当前以及今后一段时期,可以预见的是,社会计算数据和科学计算数据规模也将随着信息化程度的提高而不断增长,这都给高性能计算数据处理带来了新的挑战。必须进行有效的压缩,才能够减少数据存储所需空间,最大限度利用有限的通信带宽,使高性能计算集群系统发挥最大的效能。
无损压缩算法开源实现种类繁多,算法思想成熟。国产异构众核高性能计算机系统中,现有的数据压缩算法包括zlib-Deflate、xz、lz4等,在移植应用过程中并没有对压缩算法进行并行优化,仅使用单核对数据进行压缩解压处理,其处理效率没有太大的提升空间。在压缩算法中,普遍存在着压缩速率与存储空间使用的矛盾、数据局部性差等特性,要想获得有效的性能提升,必须针对特定的多核异构处理器进行深度的算法重构与优化。
目前为止,已有多项研究采用多核处理器架构进行压缩算法的并行化。BWT(Burrows-Wheeler transform)压缩算法并行化研究较早出现,由Pankratius等在文献[1]中提出,获得线性的加速比,并应用于bzip软件。Pigz是一个并行版本的gzip压缩算法,由Gristwood等在文献[2]中提出,并获得广泛应用,但该并行算法压缩率较低。Patel等采用GPU对BWT无损压缩算法二叉树搜索过程进行并行化[3],加速效果显著。Wu等研究了基于CUDA(compute unified device architecture)的压缩算法[4],并采用分块并行的策略在GPU上优化LZ77压缩算法。Gilchrist使用MPI(message passing interface)编程实现分布式的MPIBZIP[5]压缩算法,适用于分布式内存计算。Wright则在分布式内存结构和共享内存结构中分别使用MPI和Pthreads编程实现bzip2并行算法[6]。基于BWT的压缩算法虽然易于并行化,但在压缩率上不如LZMA(Lempel Ziv-Markov chain algorithm)等压缩算法。而xz、7zip等开源压缩软件多线程并行化过程中,仅对LZMA算法中的字符匹配核心函数并行化,加速效果不理想且受到处理器数量的限制[7-8]。Leavline等在文献[9-10]中使用FPGA(field programmable gate array)专用集成电路加速LZMA算法,可以获得较高的加速比,但应用成本较高,不具有普遍的适用性。
神威太湖之光异构众核计算系统[11]中,基本单元为一个申威异构众核处理器和32 GB内存与其他控制器组成的计算节点,其处理器体系结构如图1所示。256个计算节点构成一个超节点,总计160个超节点提供93PFLOPS的实测性能。其中,从核采用轻量级的核心设计,其指令集功能非常精简,不支持中断等操作,仅在用户态下运行。每个从核包含16 KB指令L1级cache和64 KB LDM(local directive memory,片上局部数据空间),支持256位向量操作。从核可与主核共享内存,采用DMA(direct memory access)方式进行内存与LDM的数据交换。从核阵列中,处于同一行或列的从核可通过寄存器通信方式进行数据交换,每次传输数据量最大为256 bit,延迟较低。

Fig.1 General architecture of SW26010 processor图1 申威26010处理器结构图
图2为从核CPE(computing processing element)存储层次结构图。从核可通过寄存器直接访存和寄存器LDM访存两种方式读取数据。由于主核与从核之间没有共享缓存,寄存器直接访存的延迟达到近百个时钟周期。解决问题的方式之一就是通过DMA方式将数据拷贝至LDM进行访存来提高访存速度。这增加了并行程序设计的难度,需要程序合理地设置DMA调度策略,尽可能实现计算通信重叠,提高并行效率。从核间数据交换,可采用寄存器通信方式进行。根据主从并行编程模型的特点,神威太湖之光提供了Athread加速线程库,分为主核加速线程库和从核加速线程库两部分。

Fig.2 Memory hierarchy of computing processing element图2 从核CPE存储层次结构图
本文主要研究是设计一个面向国产申威26010异构众核处理器的LZMA并行算法,并结合异构众核处理器的特点,对算法进行重构与性能优化。
2 LZMA算法分析
本章就LZMA算法中的空间需求、访存方式、数据局部性、热点函数等影响其算法性能的特点,结合国产异构众核处理器关键技术进行分析,以便更有针对性地对算法进行重构与优化。
2.1 LZMA算法流程
LZMA压缩算法由Pavlov于1998年发明[12],其核心是基于LZ77压缩算法的改进。LZMA中使用了基于滑动窗口的动态字典压缩算法和区间编码算法,具有压缩率高、解压缩空间需求小及速度快等优势。图3所示为LZMA算法流程,包含基于LZ77[13]的滑动窗口算法和区间编码[14](range encoding)两级压缩。
LZMA算法支持4 KB到上百MB的字典空间,在提升压缩率的同时也导致其搜索缓存空间变得很大。为了减小匹配最长的字符串所需时间,快速搜索匹配字符,LZMA算法实现中,将多个可能的最长匹配存储于Hash散列表中,使用Hash链表或二叉查找树的数据结构来查找匹配数据。如图4所示,Hash函数中,将搜索缓存头两个字节的散列值作为一个散列数组的索引,散列数组存放着对应匹配字符组的起始位置。该散列数组大小为字典大小一半的2的整次幂。LZMA编码器针对2、3、4个相邻字节设置了不同级别的散列函数,用以实现对应不同字典大小的高效定位。

Fig.3 Flow diagram of LZMA图3 LZMA算法流程
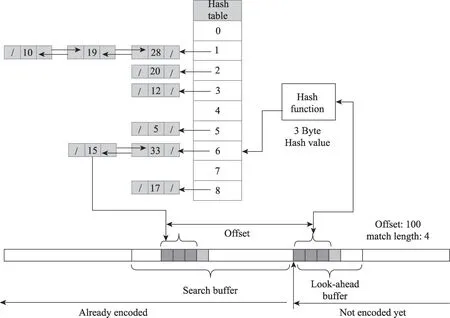
Fig.4 LZMA sliding window algorithm based on Hash table图4 基于Hash查表的LZMA滑动窗口算法示意图
2.2 空间需求分析
在异构众核系统中,每个从核处理器都配有64 KB的LDM。为保证从核能够获得较高的加速性能,需将计算数据拷贝至从核LDM空间访存,这就要求必须精确控制从核变量空间的使用。表1是LZMA算法热点函数局部变量的使用情况,其中主要包含了占用空间较大的局部数组大小,局部标量空间占用空间较小,忽略不计。
基于Hash查表的字符串匹配函数中,由于字典空间较大,其Hash散列表hash_buf预留的较大的散列空间,远超从核64 KB的LDM空间,需要进行优化,压缩局部空间的使用。可以在压缩率损失允许的范围内尽可能减小字典搜索的范围,从而减小Hash查表函数散列空间的大小。
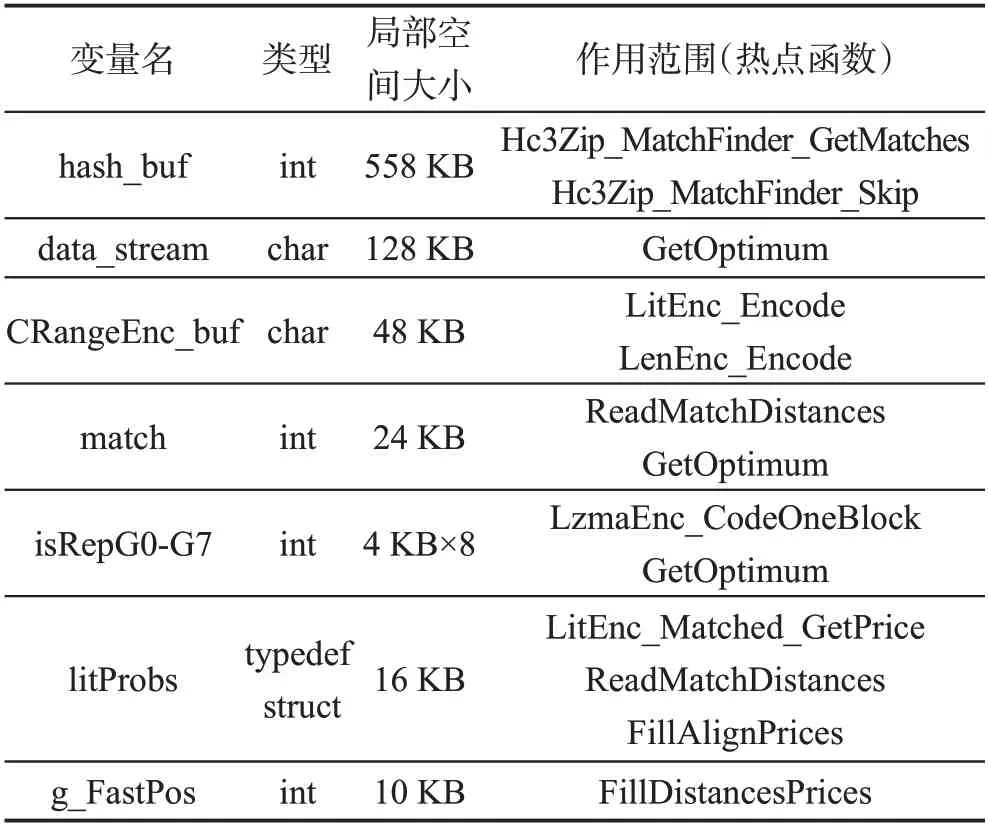
Table 1 Local variable size of hotspot function表1 热点函数局部变量空间大小
2.3 访存特性分析
LZMA算法中,使用了Hash链表的数据结构来快速查找匹配字符。由于其搜索缓存比较大,其Hash查表空间范围随之增长,在几百KB到数十MB范围内随机访存。同时,LZ77算法基于滑动窗口的流式压缩中,因为未编码的数据不断输入,已编码的数据在达到搜索缓存空间上限后便丢弃不用,其数据局部性较差。
由于事先无法判断未编码数据中重复字符串的长度和位置,也无法预测其匹配字符串的距离,因此LZMA算法中难以对数据进行预取。压缩过程中,其字典规模随着匹配字符串的增多而逐渐增长,压缩当前数据块,依赖于先前压缩过程所获得的字典。LZMA算法具有随机访存和数据依赖特性,属于访存密集型算法,其性能优化的关键就在于结合国产异构众核系统的存储结构,对算法的数据结构和访存进行重构,以减小访存开销,最大限度地发挥从核的加速性能。
2.4 热点函数分析
LZMA压缩算法主要的耗时函数集中于LZ77字符串匹配核心函数中。核心函数模式匹配过程如算法1所示。其中,耗时的操作主要为Hash查表和字符匹配,以及Hash散列表的更新。
算法1基于滑动窗口的LZ77压缩算法

热点函数中,字符匹配过程访存具有一定的连续性,即由当前字节位置开始,匹配搜索缓存中连续相同的最长字符串。而每一次匹配的字符,则由输入数据给出,可能出现最长匹配字符的位置在Hash表中散列存放,其查表访存具有一定的随机性。针对热点函数的特点,主要有两点优化思路:一是在空间使用上精细划分,最大程度将访存密集的操作集中于LDM;二是对算法进行适当重构,使用两字节Hash函数替换三字节Hash函数,进一步压缩LDM空间的使用,减小访存延迟。同时也要注意LDM缓存空间大小与数据传输的负载均衡,实现最大限度的计算通信隐藏。
3 LZMA异构众核并行算法
3.1 任务划分
将待压缩数据均匀地分配给64个从核,从核直接访问主存读取待压缩数据,并将压缩后的数据添加首部信息后,直接输出至主存,最后再由主核将数据块按照顺序写入文件。在本文中,采用了主从异步并行,将LZMA算法中LZ77压缩算法和区间编码的核心计算任务交给从核阵列,主核只负责数据划分和I/O操作。线程并行算法的步骤如下。
步骤1数据分块。根据从核的数量,将待压缩数据划分成若干子数据块。划分时,按照内存页大小的整数倍进行划分。由于压缩算法中计算量和输入数据量近似呈正比关系,只需满足所划分的数据块大小均等,即可实现并行任务负载均衡。
步骤2两级压缩。各个数据块由从核独立进行压缩,包含两步压缩。在LZ77算法中,首先初始化压缩字典。随着滑动窗口的推进,待压缩数据持续输入,字典大小随之增长。随后,经LZ77算法压缩的数据结构作为区间编码的输入数据进一步进行压缩并输出。
步骤3数据合并。从核完成压缩后,主核负责将压缩数据合并。首先写入5 Byte header,其内容为字典大小、最大比配长度等压缩参数信息。然后将各压缩块按照排列顺序,添加4 Byte的首部信息block_size之后输出。block_size内容为压缩后数据块的大小。
3.2 DMA访存双缓冲设计
通过3.1节分块并行方式,串行LZMA压缩算法的核心计算部分可移植至从核阵列。然而,从核直接访问主存时,其访存开销将使得并行算法的性能严重下降,其加速效果不足以弥补访存延迟带来的性能损耗。另外,在串行版本LZMA压缩算法中,待压缩数据存储于动态分配的一块内存空间中,由指针指向的地址来确定其当前压缩的滑动窗口。由于压缩数据规模较大,从核LDM空间有限,即使按照线程任务进行分块,其大小也远超LDM的64 KB最大容量,待压缩数据块无法一次性装入。因此需要对算法进行重构优化,压缩LDM空间的使用。
为了改善数据局部性,本文根据LZ77滑动窗口算法的特点,结合LDM空间资源使用情况,采用基于非阻塞DMA的访存双缓冲技术。如图5所示,从核不直接访问主存读取压缩数据,而是通过DMA方式将当前压缩窗口的数据及其前后部分数据作为一个压缩单元传输到LDM缓冲区,实现快速访存;与此同时,下一个压缩单元已发起DMA传送,进行数据预取,待当前压缩单元任务完成后,便可直接进行压缩计算,实现计算访存重叠,这进一步减小了访存开销。同时,输出数据也设置缓冲区,通过DMA方式拷贝至内存。算法2为使用Athread接口实现的LZMA算法多线程并行的示例。
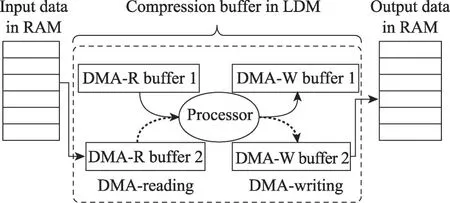
Fig.5 DMA double buffer图5 DMA双缓冲示意图
算法2基于Athread接口的LZMA并行算法


3.3 LDM空间布局优化
LZMA算法串行版本中,使用指针直接指向待压缩数据的内存空间,以位移的形式实现基于滑动窗口的字典压缩算法。而在从核多线程并行中,需要将压缩数据拷贝至LDM缓存区进行访存。为了实现DMA双缓冲,充分利用LDM空间,本节采用手动方式对LDM地址空间进行细粒度的管理分配,并对滑动窗口算法进行了重构。设置一个连续的双缓冲空间,指针bufferbase指向该地址空间起始地址,即第一块缓冲区起始位置。指针buffer_middle指向缓冲空间的中间位置,即第二块缓冲区的起始位置。指针pos_start和pos_end分别指向当前滑动窗口的起始位置和结束位置。
算法开始时,如图6所示,首先发起阻塞式DMA请求,读取数据块至缓冲区1,之后调用滑动窗口压缩函数,同时发起非阻塞式DMA请求读取下一个数据块至缓冲区2。当滑动窗口指针pos_end移动至buffer_middle位置时,检查非阻塞式DMA请求完成,便可继续压缩。之后,滑动窗口指针pos_start移动至buffer_middle位置时,同时发起非阻塞DMA请求读取下一个数据块至缓冲区1。指针pos_start和指针pos_end移动至缓冲区结束位置时,循环移动至起始位置继续压缩,直至全部数据压缩完毕为止。
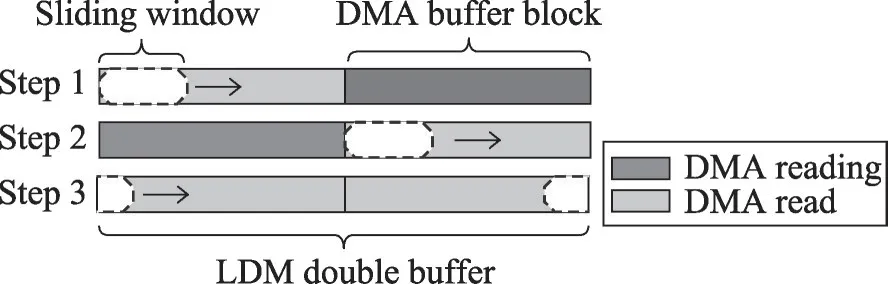
Fig.6 LDM address space partition of sliding window encoding based on DMA double buffer图6 DMA双缓冲滑动窗口压缩的LDM空间布局
4 实验结果与分析
本章主要对LZMA异构众核并行算法的压缩率和压缩时间等性能指标进行测试和分析。测试的基准性能为串行LZMA算法在主核上运行的压缩率和压缩用时。测试的计时方法为使用Athread计时接口统计算法运行所经过的节拍数,并由此计算出运算时间。
4.1 基准测试语料库和测试平台
Silesia压缩测试语料库由Deorowicz于2003年提出[15],提供涵盖当前使用的典型数据类型的文件数据集,其文件大小介于6 MB和51 MB之间。该语料库的提出主要为了解决传统Canterbury语料库缺少大型文件和文件类型单一的问题。基准测试集的测试用例如表2所示。
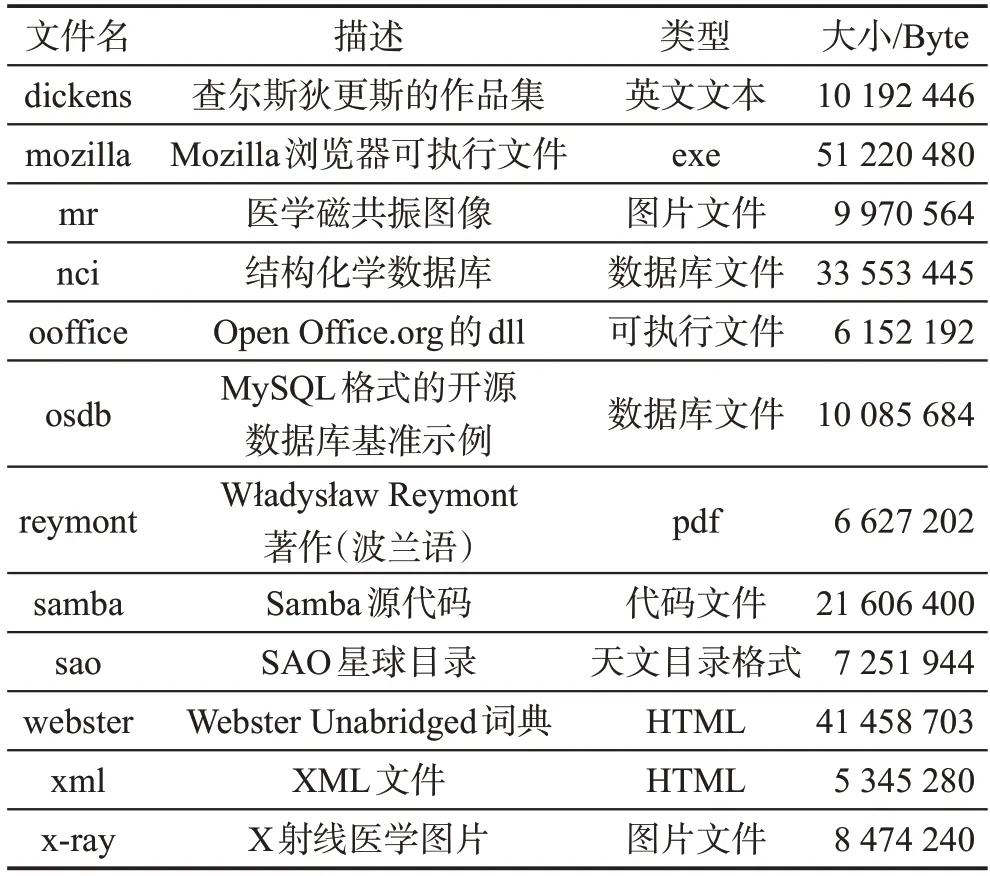
Table 2 Silesia corpus test contents表2 Silesia语料库测试用例
实验的平台为神威太湖之光异构众核系统,其参数如表3所示[11]。实验中使用的压缩算法基准测试集为Silesia语料库基准测试集。同时,为了测试大数据量的压缩性能,将Silesia语料库测试集文件复制并打包,组成了GB级的数据进行压缩测试。

Table 3 Experiment environment表3 实验环境
4.2 从核性能测试结果
为了测试LZMA并行算法在众核处理器上的加速效果,选取主核串行版本LZMA算法作为基准,来对比不同优化方案的性能。其在Silesia语料库基准测试的压缩速率和压缩率如图7所示。从核直接读取主存数据的线程并行版本中,由于访存瓶颈较大,64线程从核并行仅获得了2倍的平均加速比,甚至在某些用例中用时超过了串行压缩。而使用DMA双缓冲方式进行计算通信重叠的优化版本,压缩速率获得了3.7倍的平均加速比和4.1倍的最大加速比,表明使用DMA双缓冲并行性能得到了较大提升。在压缩率方面,并行与串行版本算法的压缩率基本相同。
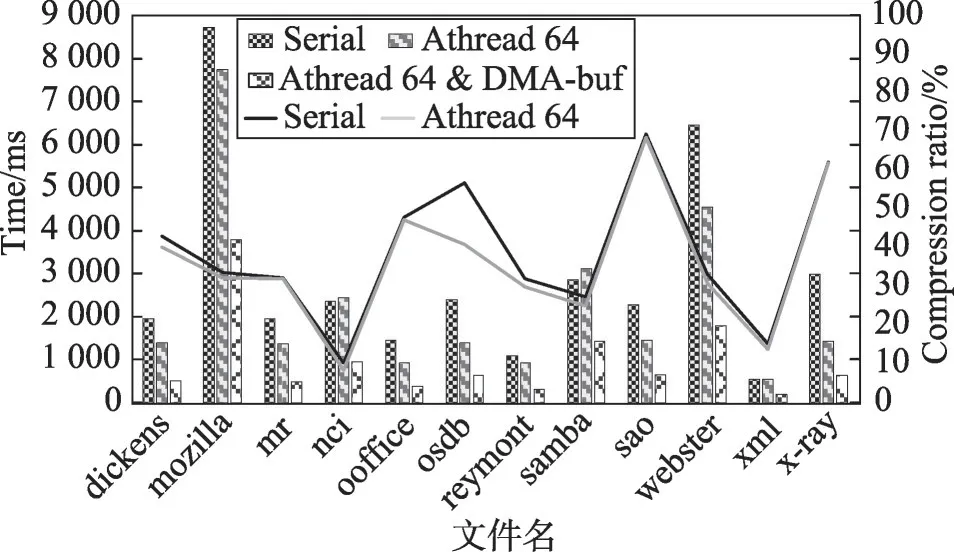
Fig.7 Test performance results of Silesia corpus图7 Silesia语料库测试性能结果
进一步分析,本文讨论了DMA双缓冲设计中单个缓冲区大小buffer_size的选择对消息传递次数及压缩速率的影响。如图8所示,当buffer_size小于20 KB时,因单次DMA拷贝数据量较小,计算与通信不能实现全部重叠,同时DMA次数增多,相应的DMA开销增大,压缩速率略有下降。当buffer_size大于25 KB时,压缩速率随缓冲区大小变换不大。理论上,缓冲区的设置应当使得DMA通信延迟与计算达到负载均衡,但由于LDM空间有限,并且需要预留给其他局部变量使用,无法继续扩大缓冲区,故取当前性能最佳的缓冲区大小作为最优参数,实现计算通信的重叠收益最大化。
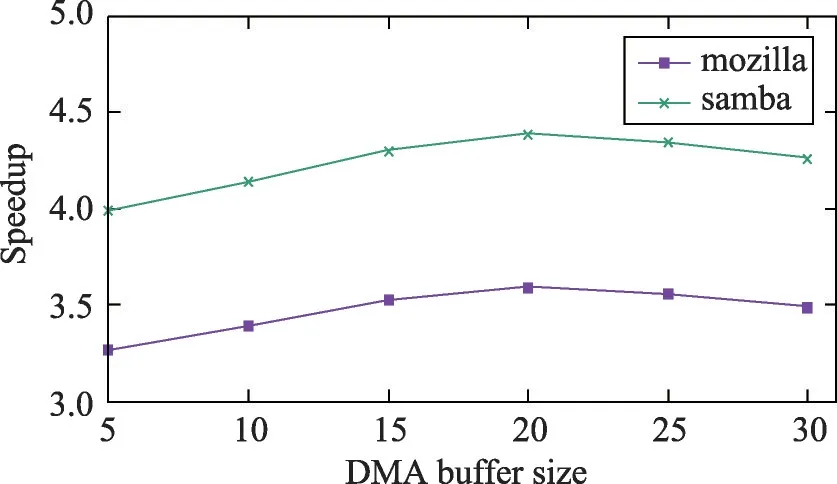
Fig.8 DMA buffer size influence on speedup performance图8 DMA双缓冲块大小对加速比的影响测试

Table 5 Performance test comparison between Intel x86 and Sunway 26010表5 Intel x86与申威平台性能测试对比
绝大部分压缩测试语料集数据规模较小,均未提供GB级的测试用例。本文基于Silesia语料库组合生成大文件测试集,以测试LZMA并行算法在大规模数据中的压缩性能。表4显示了大规模数据压缩中串行LZMA算法和并行算法的性能比较。由数据表可知,当数据量超过500 MB时,并行压缩速率有着明显的提升,最大能达到5.3倍的加速。该并行压缩算法在大规模数据的压缩方面有更好的适应性。
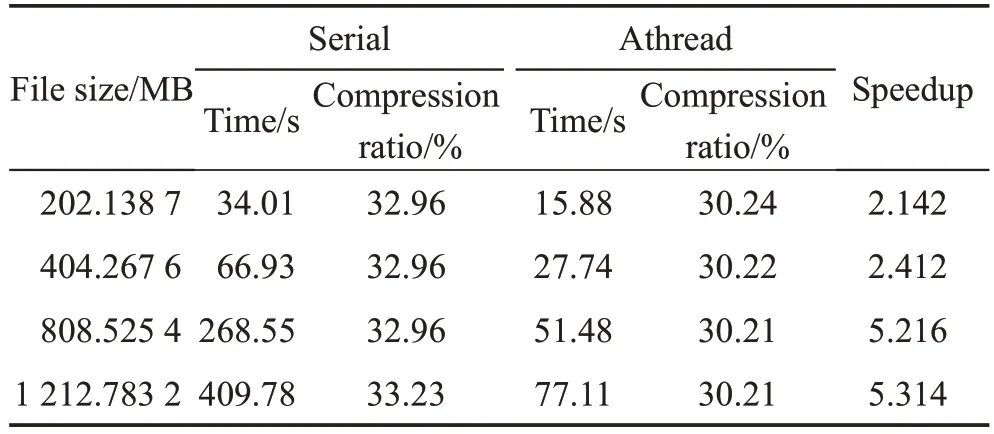
Table 4 Large-scale data compression test results表4 大规模数据压缩测试结果
4.3 相关工作对比
Alakuijala和Kliuchnikov等人使用Canterbury压缩测试语料库对Bzip2、LZMA等压缩算法进行了性能测试和对比分析[16]。其实验平台为Intel E5-1650 v2 3.5 GHz处理器。本文用申威异构处理器平台的测试结果与之对比。由于压缩数据集不同,故仅分析平均压缩率和平均加速比的情况,结果如表5所示。在CPU频率差距明显的情况下,申威主核串行算法性能不及Intel CPU,而从核并行的加速模式较Intel CPU加速效果十分明显,表明从核加速模式具有较好的性能优势。
5 结束语
超级计算机性能的快速提升,使得传统科学计算应用和以大数据、人工智能为代表的社会计算应用得以不断扩展,其应用数据和集群系统运维数据的规模也在不断扩大,带来了机遇与挑战。近年来,异构多核的体系架构成为高性能计算的主流发展方向,其硬件结构和并行编程模式的复杂性使得应用性能的提升面临一定的挑战。在压缩算法中,普遍存在着压缩速率与存储空间使用的矛盾、数据局部性差等特性,要想获得有效的性能提升,必须针对特定的多核异构处理器进行深度的算法重构与优化。
本文的主要工作是将LZMA压缩算法移植至神威太湖之光国产异构众核系统中,针对异构众核处理器的特点对算法进行了并行化重构与优化。使用Athread接口对LZMA算法进行多线程分块并行,设计基于DMA的双缓冲模式,实现计算通信的重叠。进一步优化中,对LDM地址空间进行细粒度的管理和布局优化,合理设置缓冲区大小,获得最佳的计算通信重叠效果。测试结果表明,在Silesia语料库基准测试集中,并行压缩算法最大获得了4.1倍的加速比。在大文件压缩测试中,并行压缩算法最大获得了5.3倍的加速比。与主流CPU串行算法相比,并行LZMA算法在申威异构众核处理器上加速效果明显,大幅降低了算法执行时间,具有较好的性能优势。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
外语学刊(2021年1期)2021-11-04
家庭影院技术(2021年6期)2021-07-28
福建基础教育研究(2019年11期)2019-05-28
师道·教研(2017年11期)2017-12-10
改革与开放(2010年6期)2010-06-04
微型计算机(2009年17期)2009-05-19
电子设计应用(2004年7期)2004-09-02
