
LSC-TGT:基于字符串聚类和模板生成树的在线日志解析方法
2020-09-03 08:38方晓蓉
小型微型计算机系统 2020年8期
祝 蓓,李 静,方晓蓉,王 亮
1(南京航空航天大学 计算机科学与技术学院,南京 211106)
2(国网上海市电力公司信息通信公司,上海 200000)E-mail:zhubei99@163.com
1 引 言
系统日志记录了系统的运行信息,作为系统在线监控和异常检测的重要数据,可帮助管理者调试系统故障及异常分析,进一步保证系统的安全性[1].日志具有海量的特点,随着大数据、云计算等技术的发展,系统规模不断增大,导致日志量爆炸式增长,每小时可产生大量数据,例如商业云应用程序每小时产生大约10GB的日志[2].此外,日志是非结构化的,是由开发人员编写的输出语句生成的一行文本,它们的格式和语义在不同系统之间存在很大区别.为了提高基于海量非结构化日志异常检测方法的效率,第一步也是最重要的一步就是将非结构化日志自动解析为结构化数据,日志解析技术成为异常检测领域的研究热点.
日志解析方法可分为离线方法[3-12]和在线方法[13,14].离线方法是脱机解析日志,需收集到系统在一个时间段内的日志,并加载到内存中训练解析模型,再利用模型解析日志.范惊[3]等人提出一种结合系统源代码解析日志的方法,但是现实中大部分系统的源代码并不是公开的,这种方法有很大局限性.程世文[4]等人提出利用正则表达式识别日志模板的方法.这类方法需要人工根据应用程序源代码的输出语句创建和更正新正则表达式,鉴于日志输出语句的数量及其更新的快节奏,手动创建和更新正则表达式将是一项繁琐且容易出错的任务[13].Vaarandi提出了第一个基于聚类的自动日志解析方法SLCT[5],将具有相同单词集合且其出现频率高于设定阈值的日志视为同一类.但是当SLCT分割较大的数据集设置较低的阈值可能导致过度拟合,获得的日志模板过于具体.Makanju等人在2011年提出IPLoM[6],该方法属于分层聚类算法,分别通过消息长度、令牌位置和映射关系迭代地聚类日志,与SLCT不同,IPLoM不需要阈值,但对类别划分提供了细粒度控制.2015年,Vaarandi R等人改进SLCT方法,提出LogCluster[7],该算法允许一条日志模板内的参数长度可变,有效避免解析结果拟合过度.崔元[8]等人提出了一种基于DBSCAN聚类的网络日志模板提取方法,该算法需要确定单词之间的密度、距离、半径以及最少数点的值4个参数.钟雅[9]等人利用选取日志中具有代表性的签名组成系统事件模板.王卫华[10]等人利用凝聚层次聚类算法挖掘相日志模板.孙名松[11]等人采用密度聚类算法聚类日志.离线方法一直是学者们的研究热点,但随着系统日志量爆炸式增长以及异常检测要求的提高,采用离线方法解析日志存在局限性.一是由于离线方法是脱机解析日志,系统管理者无法及时发现系统异常行为.二是离线方法需将日志加载到内存中训练,如果在训练后添加了新的日志类型就必须再次训练解析模型[14].因此,在线方法成为了新的研究方向.与离线方法不同的是,在线方法可以实时解析新生成日志,系统管理者能够及时发现并处理系统异常.Du等人在2016年提出的Spell[13]基于最长公共子序在线聚类日志,其优势在于前缀树和子序列匹配能够提高搜索效率,其不足之处在于仅基于最长公共子序容易导致聚类不足.He等人在2017年提出的Drain[14]使用深度固定树聚类日志,树的第一层是根节点,第二层是日志长度相同的日志分组,接下来的每层依次储存日志内容.当前在线日志解析方法存在两个缺点.一是现有在线方法在准确性和效率方面都有改进空间.二是在反复试验之后,需要针对每个要解析的日志微调其参数,例如固定树深度,这使得这种方法既不可扩展,也不高效[15].
针对现有的解析方法不能实时解析日志和解析不同系统日志参数不通用导致的解析效率低,准确度差等问题.本文提出准确且高效的在线日志解析方法LSC-TGT.本方法首先将日志按照长度分类,再计算日志字符串相似度,基于相似度对日志二次聚类,最后使用模板生成树提取日志模板.本方法不需要分析源代码和领域专家的参与,对于每一条新生成的原始日志都能够自动解析并快速提取模板.
R:i-j的路径集合,路径r=1,2,…,|R|,考虑到南沙港水上“巴士”及拖车运输与深圳港水上“巴士”有竞争关系,故主要路径如下:
本文的贡献主要有:
1)提出一种在线日志解析方法LSC-TGT,它能够高效而准确地从非结构化日志中提取日志模板,为系统管理者提供简洁直观的信息和干净规范的结构化数据,方便数据分析师对日志进行更高级分析和处理.
2)提出日志字符串的概念,并计算日志字符串相似度,基于相似度对长度相同的系统日志在线聚类,减少日志模板提取时无效的比较步骤,提高LSC-TGT的日志解析效率.
3)提出了基于模板生成树的模板提取方法.利用生成树提取、更新模板,提高LSC-TGT的准确度.
4)通过在5个真实数据集上与3个现有的日志解析方法的对比实验,验证本文所提方法在日志解析效率和准确度上都有明显提升.
为了解决上述问题,我们引入一个新概念——日志字符串,它是由Tm中每个tm的首字母组成的字符串.与日志长度相比,日志字符串是对日志更具代表性的描述方式.如图4(c)所示,虽然每条日志的长度都相同,但是其日志字符串都是唯一的,计算其相似度,基于相似度对每个GL中的日志再次聚类,能得到模板相似度更高的日志组,用Gs表示.
本文后续章节安排如下:第二节介绍了日志解析方法;第三节介绍基于字符串聚类和模板生成树的在线日志解析方法LSC-TGT;第四节主要通过4组实验验证LSC-TGT的优势和有效性;第五节对本文方法进行总结及进一步的研究方向.
2 日志解析
日志解析是通过高效且准确的方法将非结构化的日志转化为结构化的形式,可从海量的系统日志中获取隐藏的信息,以指导后续操作.在日志解析过程中,每一条原始日志消息可以表示为:
m={mh,mc}
其中mh表示日志头,mc表示日志内容,如图1所示.日志头包括时间戳,定位,日志类型等琐碎的信息,日志解析仅需要对mc进行处理.因为mh所包含的信息属于结构化的消息类型,非常直观易于系统管理者理解,只需简单的正则表达式就可以实现日志头的识别和匹配.
我国历史悠久,是世界四大文明古国之一,是东方文化的代表,如孔孟之道、孙子兵法、造纸术……中国文化有数千年的思想与经验,动漫专业学生应当学习中国古代文化,学习民族文化精神,弘扬民族文化传统。在学习我国古文明的同时,吸收西方经典文化,坚持中学与西学并重,吸取东、西方文化精髓,拓宽学生见识,熔铸调和创造出新文化。
全省区域中以瑞丽、红河、永德、云县、石屏、永平、墨江、耿马、盈江、曲靖、保山、富民、东川、施甸、临沧等地的多样性较大。

图1 系统日志示例
日志解析的过程就是在日志内容中提取日志模板.一条日志由日志模板和参数值两部分组成,举个例子,一个日志输出源代码printf(“connected to%s successfully.”,ip),包括一个固定部分,connected to%s successfully;一个可变部分,组件 ip地址.日志解析的目标就是抽取原始系统日志中的固定部分即日志模板 connected to * successfully,其中占位符*代表可变的参数部分.
图2展示了在真实数据集BGL[12]上的日志解析过程.抽取原始日志数据中固定的部分,就得到了日志模板.

图2 日志解析示例
3 基于字符串聚类和模板生成树的日志解析
LSC-TGT是基于字符串聚类和匹配树的日志解析方法.聚类算法通常作为数据挖掘的预处理步骤,在对数据类别不了解的情况下,将数据条目分成多个类别,每一个类别称之为簇.聚类旨在发现密切相关的数据条目,使得与属于不同簇中的数据条目相比,同一簇中的数据条目尽可能相似.结合原始日志数据无类别标记的特点,聚类算法是解析日志的合理方法,它可以有效降低方法复杂度,提高解析效率.
自2000年以来,经济型双相不锈钢已成为双相不锈钢的发展方向.经济型双相不锈钢主要通过N,Mn代替Ni,Mo来降低成本,其中2101经济型双相不锈钢是典型代表[4].但已有的经济型双相不锈钢热加工难度大、薄板延伸率低,基于此,一种具有相变诱导塑性(transformation induced plasticity,TRIP)效应[5]的经济型双相不锈钢被开发出来,其热加工性能优于已有经济型双相不锈钢.本工作的研究对象Fe-21Cr-3Ni-1Mo-N便是上海宝钢公司设计并开发的具有TRIP效应的经济型双相不锈钢.
本文方法的基本思想是:首先基于日志长度将日志分类,接着获取日志字符串并计算相似度,基于相似度对长度相同的日志聚类,实现日志类型的进一步细分,最后基于前缀树的思想构建模板生成树,完成日志模板提取和模板更新.整体框架如图3所示.
目前,我国中小型企业的内部审计基本上是账目基础上的手工测试,主要采用详细审计或依赖于审计人员个人经验判断的抽样审计,审计内容较少运用统计抽样和计算机辅助审计软件,使得审计工作的风险无法量化。
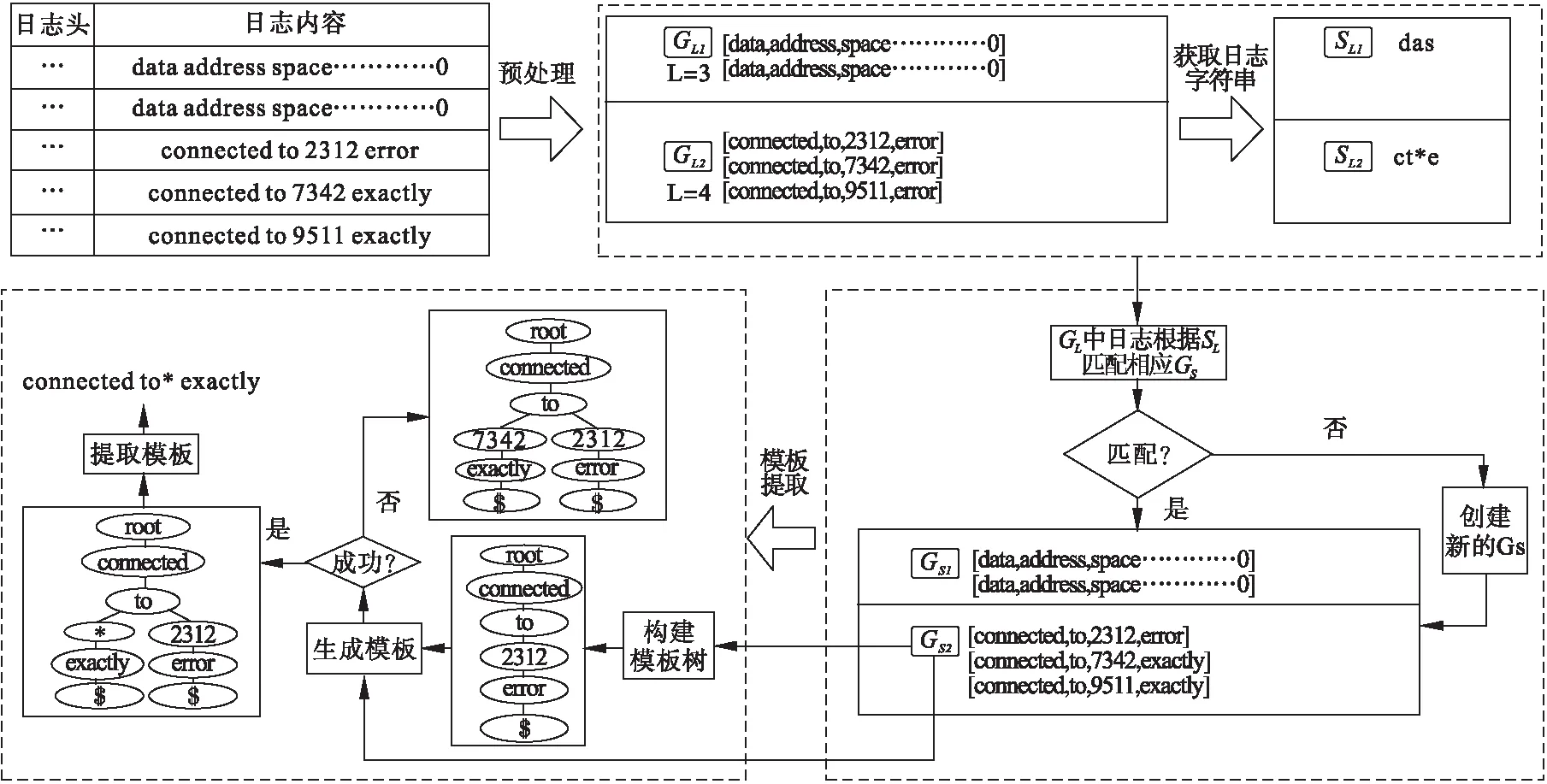
图3 LSC-TGT框架图
3.1 日志预处理
日志解析是在日志内容中提取模板,首先利用正则表达式识别日志头mh中与之匹配的变量信息并删除获得日志内容mc.此步骤中的正则表达式非常简单,因为它只需配匹出例如时间戳、IP地址等简单的标记,最多只需两个正则表达式就可以识别数据集中的所有日志头.接着利用预先定义的分隔符对每一条原始日志内容mc进行划分,空格分隔符通常能够解决大部分系统日志的分割问题.分隔符将日志划分成单词的序列Tm:
Tm=[tm1,tm2,…,tmL]
每个单词用tmi表示.Tm的大小称之为日志的长度,用L表示.最后,将Tm分到不同组中,每个组包含所有拥有相同L的Tm,用GL表示这样的组.实际上,在长度相同的日志组中也存在模板不同的日志,如图4(a),图4(b)所示,图中数据来自BGL日志的日志内容部分,日志集中每条日志长度都为4,但是日志的模板都不相同.所以如果仅仅在此步骤后对日志进行模板提取会导致更高的复杂度.
“真是冤死我了。红头巾,本是我和老刀结婚时,团长老婆送的。开始是恨它不肯戴,后来是不舍得用没戴。去照全家合影时用了一次,所以只洗一水,压在箱子底。你来了,想着你迟早要有一条头巾用,不如乘早送给你。我心想,我的日子过得还算幸福,你用了我这红头巾,日子也会幸福。哪知今天就这么赶巧,真是人算不如天算。”

图4(a) 日志长度为4的日志集

图4(b) 图4(a)中日志对应模板集
3.2 基于日志字符串相似度在线聚类
数学是一门运动、变化着的科学,其很多知识点都是发现一种运动的数学规律,或者是用运动规律来表示数字之间的关系,这也是对函数最简单、直接的解释。在传统教学中,教师很难处理和展现数学的运动性,只能简单地给学生看静态的数学,导致在解决动态问题时,非常吃力。信息技术的出现,突破了这一教学方法所运用技术的瓶颈,产生了新的教学方案。如学习“动点”的轨迹,原本教师只能在黑板上“笨拙”地画出几个点,学生勉强明白。现在,教师可以利用信息技术来处理数字信息,整合为图像,画出更多的轨迹变化,学生既能看到运动的结果,也能看到运动的过程。如此直观的演示,对学生研究动态运动方程非常有帮助。

图4(c) 图4(a)中日志对应日志字符串集
3.2.1 获得日志字符串
在Tm中每个tmi代表一个单词,为了避免字符串提取算法过高的时间复杂度,我们提取每个tm的第一个字符作为其代表字符.为避免日志字符串种类数量爆炸,当字符为数字或标识符时,则用“*”将之替代.最后将所有字符和“*”按所属tmi在Tm中的位置组成一个字符串,称之为该原始日志的日志字符串,用Sm表示.具体算法如算法1所示.
算法 1 .一种获取日志字符串的算法
输入:GL,长度相同日志的Tm的集合
在问题MPM中,式(1)、式(5)和式(6)为P-M模型的非线性扩散方程问题;式(2)、式(3)和式(4)为达西渗流问题.
选取高硫铝土矿试样,分别考察了盐酸(1+1)和水对试样的溶样效果,结果见表1。由表1可见,用盐酸(1+1)溶样的结果比用水的均高;随着盐酸(1+1)用量的增加,硫酸根的测定结果随之增大后保持稳定;当盐酸(1+1)用量为40~60mL时,滤液的颜色最深,表明被硫酸根置换出的铬酸根浓度最高,说明此时试样中硫酸根可基本被提取完全。实验选择40mL盐酸(1+1)溶解试样。
1.Sm←{ }
2. forGL中的每个Tm
3. forTm中的每个tmi
4. 确定第一个字符ui
5. ifui包含数字或标识符 then
6.ui←′*′
14. for eachTminGs[1,n-1] do
1、灌溉渠道监测。监测结果显示:江华水库周边为林地分布,沟渠分布较少,灌区的宁远县内耕地分布较多的地方沟渠分布较多,道县、江永的耕地区有部分沟渠分布。由于扩建后监测采用的影像为2017年度9-11月,灌区的渠道建设工程到监测时间还未全部完成,本监测仅提取了影像上可明显识别的灌溉渠道进行分析。根据灌区规划数据统计,工程将新建干渠以上渠道240公里、支渠170公里,扩建后的灌区将成为湖南省最大的灌区,扩建最大的效益就是灌溉效益。
8.Sm←Sm∪{ui}
企业保障安全生产的过程中,不仅要明确危险源识别范围和具体内容,还应当准确识别其危险因素,这就要求科学采用危险源识别方法来辨别,以强化危险源管理和防范。
9. end for
10. end for
广东盆距兰发现于贵州榕江县小丹江边喀斯特树林中,生境海拔766 m,生于潮湿朽木上,伴生种有马尾松、茅栗、豆叶九里香等。仅发现5个相对独立的植株,2株有花。2013年10月21日采集,凭证标本:HXQ13102105HT,引种保存于贵阳药用植物园。
3.2.2 基于相似度在线聚类
在每个GL中创建一个日志字符串集用于存储字符串的种类,表示为S.将新生成日志的字符串与S中的字符串计算相似度.若存在相似度大于相似度阈值st的字符串,则将日志加入该字符串对应的日志组Gs,若不存在则新建日志组Gs并更新S.相似度计算公式如公式(1)所示:
(1)
其中Sm1和Sm2代表两条日志字符串,len(|Sm1|,|Sm2|)代表两条日志字符串的长度,Ⅱf(x,y)定义如公式(2)所示:
(2)
x,y表示两个字符.当sim(Sm1,Sm2)大于st时,表示Sm1和Sm2日志字符串相似.例如在图2所示的日志中,因为log1,log2日志字符串都为icpec,log3的日志字符串为*dae.所以log1,log2被归为一类,log3为另一类.我们用Gs表示该步骤的结果,表示拥有相似日志字符串的所有日志Tm的组.经过此步骤后每个组内日志数量减少,日志拥有同一模板的概率提高.在日志相似度高的Gs内进行后续模板提取可大大提高算法效率.
3.3 基于生成树获取模板
Trie树又称前缀树或字典树,是一种有序树,其中的结点通常保存字符串.Trie树是一种在字符串查找,前缀匹配等方面应用广泛的算法,每次匹配时只与被查询的字符串长度有关,时间复杂度只有O(1).标准Trie树的结构:所有含有公共前缀的字符串将挂在Trie树中同一个结点下,简明的存储了存在于字符串中的所有公共前缀.
转染48 h后,MTT检测各组SHG-44细胞增殖水平,结果显示,miR-543 mimic组与mimic NC组相比细胞增殖水平明显降低(P<0.01),miR-543 inhibitor组与inhibitor NC组相比细胞增殖水平明显升高(P<0.01),见图2;由此可见miR-543过表达可抑制SHG-44细胞增殖,抑制miR-543的表达可促进SHG-44细胞增殖。
我们基于Trie树的思想构建每个Gs的模板生成树,将新生成的日志作为查询项与树中模板匹配共同的节点.Gs内日志相似度高,模板种类少,模板生成树空间复杂度低,有效提高了从日志中提取模板的效率和准确性.
对于一条日志mc,经上述步骤后已经被分割成序列Tm,遍历序列Tm,将其中的tm依次插入树结构.将每条分支最后的节点标记为特殊字符‘$’,那么从根节点到任意一个‘$’所经过的路径表示一条日志mc的匹配路径,树深度为L+1,L为日志长度.接下来生成的一条日志Tm中的tm作为L个询问采用先深搜索遍历每一条路径.从根节点P开始搜索,取得要查找tmi的所在节点,若不存在匹配节点,则将该Tm插入树结构作为新分支;若存在匹配节点,根据该节点选择对应的子树并转到该子树继续进行搜索.设tmi与第i个节点Q存储的tm相同,则P=Q,tmi变为tm(i+1)继续搜索.若tm(i+1)与第i+1个节点匹配失败,那么记录匹配失败的节点,更新根节点P为第i+2个节点,tm(i+2)继续匹配第i+2个节点,直到完成L个询问,对于一条日志的搜索结束.提取匹配成功节点存储的tm,匹配失败节点则返回通配符‘*’,以此获得日志模板.模板生成过程如图5所示.判断模板是否生成成功,我们引入一个界定值X,如公式(3)所示:
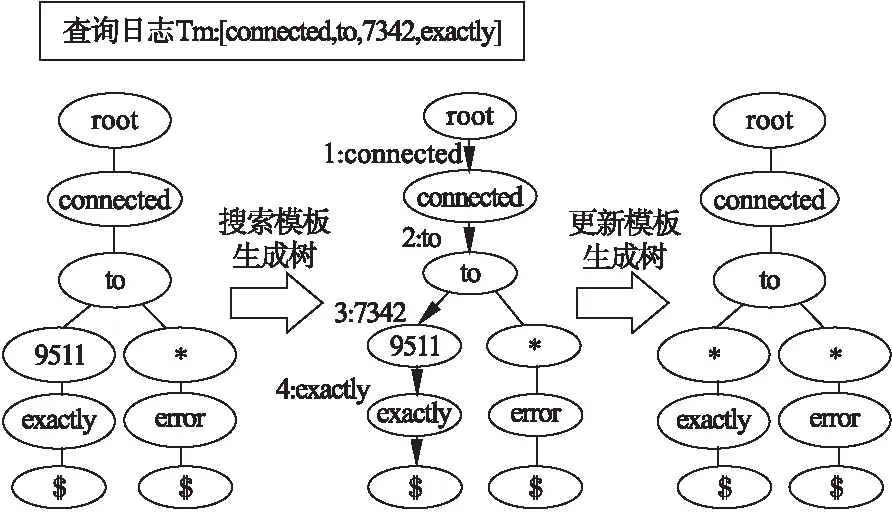
图5 日志模板生成过程
(3)
其中∑unmatch(tmi)表示匹配失败的节点数量,L为日志长度,σ为该搜索路径上通配符‘*’的数量.
当X小于或等于阈值λ,表示模板生成成功,更新模板生成树,将未匹配节点更新为通配符‘*’.当X超过阈值λ,那么将该条日志作为新的分支插入模板生成树.图5展示了查询日志Tm:[connected ,to,7342,exactly]与模板生成树匹配成功获得模板并更新模板生成树的过程.为了防止树深度过大,定义了最大树深度参数MaxDepth,如果叶子节点数量已经达到MaxDepth,Tm所有未遍历tmi的将不再插入树,剩余tmi都将用通配符‘*’替代.具体日志模板提取算法如算法2所示.
算法 2.一个日志模板提取算法
输入:Gs,字符串相同日志的Tm的集合
输出:E,每条日志mc的模板
12. end if
2.λ
3. for eachTminGs[1,n-1] do
4.P=ROOT
5. fori=1 to |Tm|do
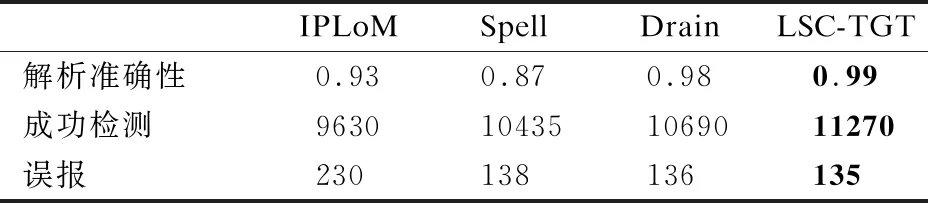
6. ifi 7. ifP→child(tmi)=NULLthen 8.P→addChild(tmi,newNode()) 输出:Sm,每条日志的日志字符串 9. end if 10.P=P→child(tmi) 11.P→markEndPoint() 1.MaxDepth 13. end for 7. end if 15.P=ROOT 16. forj=1 to |Tm| do 17. ifP→child(tmi)=tmjthen 18.e←tmj 19. else 20.e←‘*’ 21.E=Ejoine 22. end if 23. calculateX 24. ifX>λthen 25. repeat line:5-14 26. else 29. end for 28. end if 27. returnE 30. end for 31. end for 为了验证LSC-TGT方法的有效性,分别在5个真实日志数据集上进行解析效率和准确性的实验,为了进一步验证LSC-TGT方法的效率,分别在不同大小和类型的20个数据集上进行解析效率实验,并于现有的解析方法比较.最后还验证了本文聚类算法的优越性以及本文方法在实际异常检测应用中的效果. 本实验从文献[16]提供数据集中选取了5个真实的日志数据集.数据集来自4个领域,分别是分布式系统(HDFS),超级计算机(BGL,HPC),手机系统(Android),操作系统(Linux).其中HDFS是从亚马逊EC2平台收集的日志数据集.BGL是从BlueGene/L超级计算机收集的日志数据集.HPC是从高性能计算集群收集的日志数据集.安卓是由谷歌开发的移动操作系统,文献[16]提供了一个安卓日志文件,该日志文件是作者在实验室中测试仪器化的安卓智能手机生成的.Linux包含Linux服务器260多天的运行日志.5个数据集总结如表1所示. 表1 系统日志数据集 由2个重要指标评定一个日志解析方法是否是优秀的. 1)效率:测量一个方法基于上述数据集从接收系统日志到获得所有日志模板所需要的时间.时间越短,方法的效率越高. 2)准确性:评价一个日志解析方法获得正确日志模板的能力.每个日志是否对应正确的组,其中每个组是否对应正确的模板.我们采用了之前研究中使用的指标[16,17],F-measure: (4) 其中Precision和Recall分别定义如公式(5)、公式(6)所示: (5) (6) 其中TP表示拥有相同模板的日志被分到同一个组,FP表示拥有不同模板的日志被分到同一个组.FN表示拥有相同模板的日志被分到不同组. LSC-TGT参数都是凭经验设置,但相似度阈值st除外.在设置st时,通过更改其值并在HDFS数据集上运行LSC-TGT测试,从而获得使LSC-TGT解析效果达到最优的值.根据表2所示,当st为0.4时,解析准确性最高. 为了对比基于以上数据集的日志解析结果,我们选择了3个现存的方法与本文方法比较.1个离线方法IPLoM[6],2个在线日志解析方法Spell[13]、Drain[14].IPLoM有三个参数:集群良好阈值、上限距离、下限距离、创建新分区的最小支持.Spell有一个参数:消息类型阈值.Drain有两个参数:相似度阈值、所有叶节点的深度.在所有实验中,我们使用[16]给定的每个日志解析方法在解析表1各个数据集时使用的最优参数. 对于一个日志解析方法解析日志的效率,方法本身的时间复杂度是重要影响因素.Spell计算的是每两条原始日志的最长公共子序,时间复杂度为O(L1·L2).Drain的时间复杂度为O((d+gL)N),其中d表示解析树的深度,g表示叶节点中候选日志组的数量,L表示日志消息长度,N表示系统日志的数量[14].Drain在大型数据集上或者生成的日志模板数量过多都会导致较低的效率.IPLoM复杂度与Drain相似,但IPLoM是离线方法,需要将所有数据加载到内存中,这一步骤导致IPLoM在解析较大数据集时将十分耗时,如表2中HDFS数据集含有2.55GB日志数据,IPLoM解析时间远远高于其他解析方法.本文提出的方法在结果在线聚类步骤后,同一组中的日志模板数量大大减少,比较次数随之减少.每次比较的时间复杂度是O(L1+L2),L1,L2分别表示被比较对象的长度,相较与其他方法的O(L1·L2),大大提高了解析效率.从图6中可以看出,本文方法的效率更胜于其他方法,效率至少提高了22%,在HPC数据集上更是提高了68.8%. 图6 日志解析方法的解析效率 随着系统的扩大和更新,系统日志越来越庞大,日志种类越来越多.一个健壮的日志解析方法需要有能力处理不同大小,不同样式的数据集.我们从真实数据集中随机抽取数据,组成20个各种大小的数据集用于实验,结果如图7所示. 从图7中可以看到,在Linux_21.6k数据集上LSC-TGT低于IPLoM算法,离线算法在小数据集上有一定优势,但在实际操作中解析过程十分消耗内存,对硬件性能要求较高,局限了算法使用范围.在大数据集HDFS_2m、BGL_2m等上,LSC-TGT解析速度都优于其他解析方法.总体上看,LSC-TGT更稳定,在不同大小不同种类的数据集上都能保持非常快的解析速度. 图7 日志解析方法在不同大小数据集上的运行时间 由于缺少日志对应的真实模板,我们从表1各数据集分别随机选择了2000条日志,并手动标记其真实的日志模板用于实验.各个日志解析方法的准确性如表3所示. 表3 日志解析方法的解析准确性 注:表中加粗数字为准确性最高结果,数字越大准确性越高 根据表3可知,LSC-TGT在5个数据集上都获得了最高的准确性.离线日志解析方法IPLoM在高效率的数据集上不能同时保证相符的准确性.Spell是基于最长公共子序的解析方法,对比每条日志与现有模板的获得最长公共子序作为日志模板,如果现有模板长度比实际模板小,可能导致匹配不足的情况,在日志长度较长的数据集上准确性相对较低.Drain结合日志长度和前几个字符串,也能确保较高准确性.通过解析准确度进一步验证了LSC-TGT方法在不同数据集上的有效性. 4.5.1 聚类算法选择 聚类问题历经长期的研究与发展,产生出一系列聚类算法,如划分方法、层次聚类、基于密度等.基于划分的方法,如K-Means算法,需要创建一个初始聚类簇数k,日志数据庞大复杂且更新快,无法提前得知类别数,因此基于划分的方法不适用于在线日志解析.层次聚类方法不需要预先定义聚类数,但是计算复杂度相对较高,通常为O(n2)[18],无法实现高效率解析.基于密度的聚类如DBSCAN 算法,需要定义两个重要参数:半径eps和密度阈值MinPts,针对日志解析问题,不同系统日志差异性大,过多参数设置不利于方法扩展.各个聚类算法都存在应用限制,很少有算法能同时满足在线日志聚类的要求.本文基于字符串聚类与传统方法不同,不需要提前设置聚类数;基于单个字符计算相似度,复杂度为O(k·n),其中k为类别数,n为日志条目数,k通常为常数,复杂度可近似于O(n),复杂度相对较低;无需标记数据,无需训练模型,聚类边界整齐,能够实现在线聚类,在在线日志解析问题上具有优越性. 基于聚类思想的日志解析方法,最终聚类簇数等于日志模板数.为了证明字符串聚类可行性,从HDFS数据集挑选300条日志用于实验.从图8中可以看出,簇内数据点密集,簇间边界分明,一共识别4个聚类数,分别正确对应实际模板.即使“倒三角形”簇间相对距离较大,基于字符串相似度聚类仍可实现正确划分,相应日志能正确获取其模板.由此说明将字符串聚类应用于本文方法是可行的. 图8 基于日志字符串聚类结果 4.5.2 字符串聚类效果 为了证明基于日志字符串相似度聚类方法的有效性,我们在HDFS数据集中随机挑选了1000条原始日志,并手动标记日志的真实模板,用唯一的数字分别表示不同的日志长度,日志字符串和日志模板,再基于日志长度、日志字符串划分日志模板,如图9和图10所示.从图9中可以看出,日志长度4对应两个日志模板3.0、4.0;日志长度6也对应两个日志模板7.0、7.5.而在图10中,日志字符串3,4;7,7.5能区分日志模板3.0、4.0;7.0、7.5.由此可说明,长度相同的日志,模板可能不同.如果仅仅在长度相同的日志组中提取日志模板,会导致复杂度较高或者模板提取不充分的问题.而日志字符串能更加明确划分出不同模板的日志,一个日志字符串对应一个日志模板.利用日志字符串相似度聚类后的各组内的日志相似度更高,可降低后续日志模板提取步骤的复杂度. 图9 基于日志长度划分日志模板 图10 基于日志字符串划分日志模板 一个好的日志解析方法不仅需要高效率和高准确性,还需要能保证后续异常检测任务有良好的性能.为了评估LSC-TGT在异常检测任务的有效性,我们在HDFS数据集上与4.3节提到的3个方法对比实验.HDFS数据集的原始日志消息记录了575061个HDFS块上的操作信息,共有29种日志模板.在这些区块中,有16838个被标记为异常.异常检测包括日志解析和日志挖掘两个步骤[14].在日志解析步骤中,将所有日志解析为结构化的日志消息,每个结构化的日志消息均包含相应的HDFS块id和日志模板.在日志挖掘步骤中,首先使用解析后的日志生成模板计数矩阵,其中每一行代表一个HDFS块,每列代表一种日志模板,数字代表该模板的在对应块内的计数.然后,我们使用词频-逆向文本频率(term frequency-inverse document frequency,TF-IDF)预处理模板计数矩阵.最后,将模板计数矩阵传入主成分分析模型(principal components analysis,PCA),自动将块标记为正常或异常[19].得到异常检测结果如表4所示.从表中可以看出LSC-TGT不仅拥有最高解析准确性,而且能成功检测11270个块异常,误报也是最低.与其他方法相比,具有最优的异常检测效果. 表4 日志解析方法的异常检测效果 在本文中,我们提出了一种最新的日志解析方法LSC-TGT.传统方法都是离线日志解析方法,本文方法是能够及时解析日志的在线方法.首先将日志按照长度分类,再获取日志字符串,计算日志字符串相似度,基于相似度进行二次聚类,最后使用模板生成树提取模板.我们用Python实现了该方法,在五个真实日志数据集上与现有的解析方法进行对比实验,实验结果表明,本文方法的效率和准确性都优于目前最新的日志解析方法.另外我们将研究如何在在线自动解析的基础上提取日志语义信息,进一步提高基于日志异常检测方法的效率和准确性.4 实验与分析
4.1 数据集介绍

4.2 评价标准和参数设置
4.3 日志解析效率实验
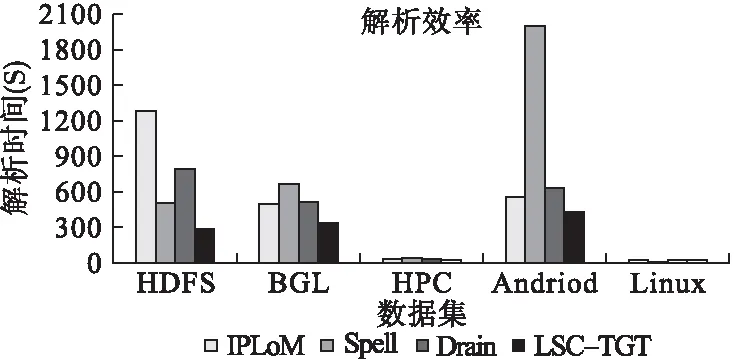
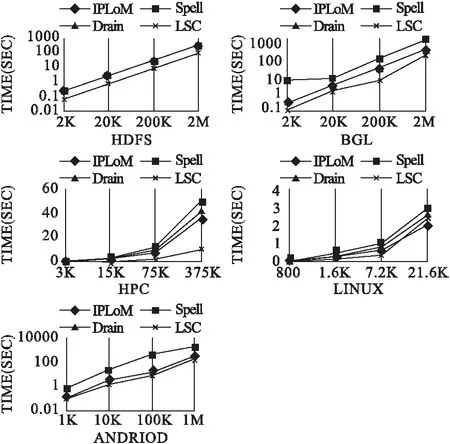
4.4 日志解析准确性实验

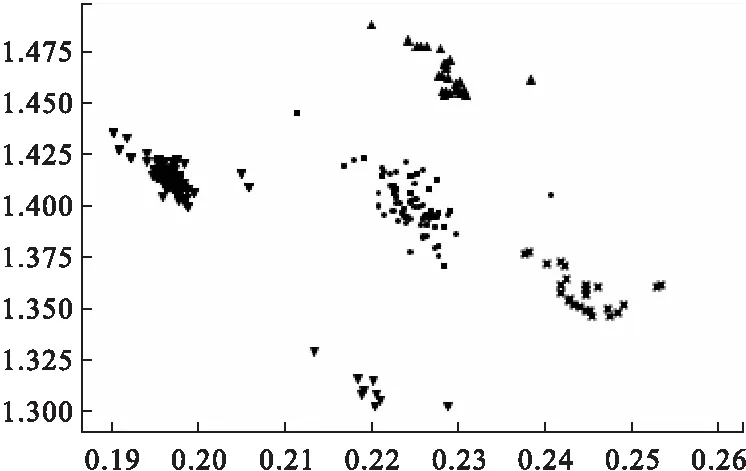
4.5 字符串聚类分析
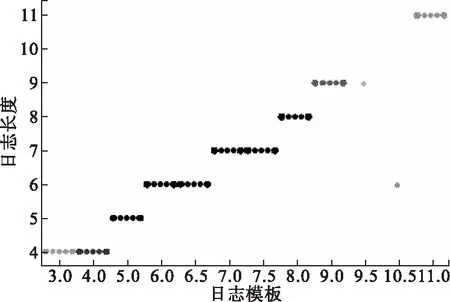
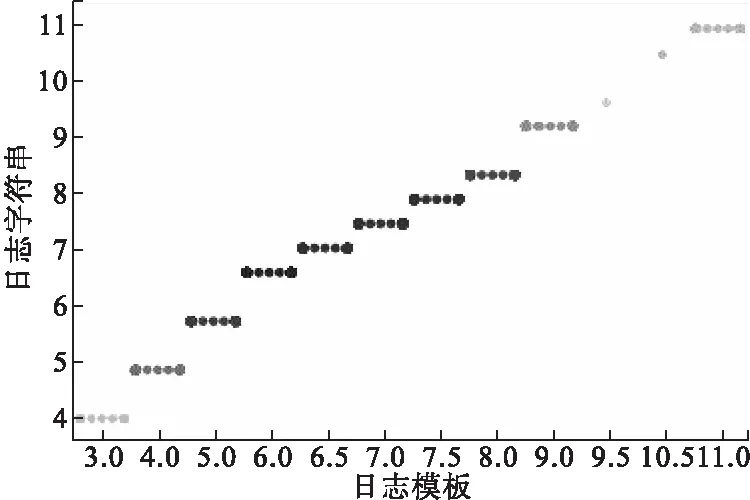
4.6 实际异常检测效果
5 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
华人时刊(2021年13期)2021-11-27
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
诗选刊(2020年12期)2020-12-03
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
数字技术与应用(2017年3期)2017-05-17
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
