
融合自注意力机制和BiGRU网络的微博情感分析模型
2020-09-03 08:38陈亚茹陈世平
小型微型计算机系统 2020年8期
陈亚茹,陈世平
(上海理工大学 光电信息与计算机工程学院,上海 200093)E-mail :1639008937@qq.com
1 引 言
近年来,人们通过在以微博等为代表的社交媒介进行信息交流、情感表达和意见发表.对这些海量用户数据进行情感分析,有助于了解用户的情感状态,及时获取用户的观点态度,对于政治、社会科学、经济等方面的发展具有重要的现实意义.
研究发现,微博文本中的表情符号和一般文本语义之间存在着很大的差异.自然语言中的文本语义都具有一定的语法功能,在构造文本内容时必须遵守相应的语法规则.然而,表情符号不具有语法功能,并且通常以独立的形式表达情感信号.此外,情感词通常比表情符号具有更加复杂的情感信息.鉴于这些差异,将表情符和文本语言共同作为情感分析模型的决定因素进行研究,成为本文的研究关键.
本文提出了一种融合自注意力机制和BiGRU网络模型的微博情感分析方法:
1)根据现有的微博数据集进行统计和分类,构建了一个带有情感标签的微博情感语料库.
2)将表情符引入微博文本情感分析研究,利用BiGRU网络学习纯文本的低纬度表示,然后利用自注意力模型将文本词向量和表情符向量共同进行权重计算,使得远距离依赖特征之间的距离被大大缩短,能够提取出文本更深层次的语义关系,增强了文本情感分析的能力.
3)通过对比分析实验,证明了本文模型相比其他模型更有效地提高了微博文本情感分类的准确率.
2 相关工作
卷积神经网络(CNN)和递归神经网络(RNN)是文本情感分析领域中的两种广泛使用的深度学习模型.Lecun等人[1]将卷积神经网络应用到文本情感分类中,提高了分类的准确性.Mikolov等人[2]提出的RNN模型可以处理序列数据并学习长期依赖性.RNN可以考虑当前输出与前一序列输出之间的关系,使得RNN能够充分学习上下文文本之间的信息.但RNN存在梯度扩散和梯度爆炸的问题,为了解决这一问题,长短期记忆模型(LSTM)[3]和门控递归单元(GRU)[4]等众多变体被提出并广泛应用于情感分析领域.但是LSTM和GRU模型只具有前向信息记忆能力,而不能对后向序列进行记忆,故双向RNN结构被随之提出.如Graves等人[5]提出的双向长短期记忆网络(BiLSTM),该模型在LSTM上增加了反向层,使得LSTM能够同时考虑上下文信息,对双向序列信息进行记忆,获得双向无损的文本信息;Zhang等人[6]提出了一种基于双向递归神经网络的分层多输入输出模型,该模型采用两个独立的双向门控循环(BiGRU)来生成部分词性和句子表示,然后对语音表达中softmax激活输出来考虑词法信息.
针对微博的情感分析,表情符号具有较强的情感表现,越来越多的研究者将表情符引入到情感分析中,如Jiang等[7]提出了表情空间模型(ESM),将所有单词向量投射到表情空间后,使用支持向量机(SVM)模型进行情感分类.何炎祥等[8]采用表情符号向量来增强多通道卷积网络(MCNN)学习情感语义的能力,利用常见的表情符号和单词构建情感空间的特征表示矩阵,然后通过MCNN对情感表示矩阵进行建模,实现对微博文本的情感分类.
虽然文献[7,8]考虑到表情符号在情感表现的重要作用,但未考虑情感符号自身对文本的作用机制.
注意力机制最早运用在图像处理领域[9],后来Bahdanau等人[10]首次将注意力机制应用在自然语言中.在自然语言处理领域,注意力机制广泛应用在机器翻译、问答系统[11]、情感分析[12]等方面.自注意力机制是注意力机制层的一个特例,它是一种内部注意力机制,能够关注到句子内部词语之间的语义关系.它通常不需要额外的数据信息,可以单独作为一层来使用,许多研究者将自注意力机制与深度学习模型相结合,实现文本情感的分类.如邵清等人[13]通过引入自注意力机制处理词向量,然后根据卷积神经网络和关键词提取技术实现特征向量的分类,有效提高了分类的准确性;石磊等人[14]提出了一种将自注意力机制和Tree-LSTM相结合,并且引入了Maxout神经元,有效地提高了情感分析的准确率和解决了空间方向的梯度下降问题.本文提出的自注意力机制和BiGRU网络模型,利用自注意力机制能够关注文本的关键信息,实现了将文本和表情符共同加入计算,得到结合表情符作用的语义编码信息,有效提高了文本分类的准确率.
3 模 型
为了实现微博情感分析的目标,本文提出了融合表情符的自注意力机制和BiGRU网络模型结构,具体结构如图1所示.该模型共包括四层结构:第一层是词向量输入层,将输入的文本句子利用词向量模型来进行编码;第二层是BiGRU层,完成的任务是将文本向量输入BiGRU模型以获取上下文相关信息;第三层是自注意力机制层,主要是将文本特征和表情符向量进行融合加权,从句子中抽取相关信息;最后一层是情感分类层,通过softmax分类器完成文本情感分析工作.

图1 融合自注意力和BiGRU模型框架
3.1 词向量输入层
本文模型的输入是由整个数据集中的文本和表情符号的词向量表示矩阵组成.首先,通过大规模语料采用词向量训练模型学习得到整个词向量词典的表示矩阵Mw∈Rd×N,其中d代表单个向量的维数,N代表词典中词语的数量.对于由词典元素组成文本序列S=(w1,w2,…,wT),第j个词语的向量Xj通过公式(1)获取:
Xj=MwVj,1≤j≤T
(1)
此操作可看作是查字典,查找操作可被看作使用二进制向量Vj的投影函数.其中Vj∈RN,除了在第j个索引取值为1之外,其它位置取值都为零.
最后通过行向量拼接的操作获得整个文本序列的词向量表示:
Rw=X1⊕X2⊕…⊕XT
(2)
对微博文档中表情符号序列的词向量表示Re也要通过上面的步骤获得.
3.2 BiGRU层
作为RNN的变体的双向门控循环(BiGRU)神经网络,它类似于LSTM,但只有两个门:重置门r确定新输入和先前信息的组合方式,更新门z确定要传递多少先前信息.GRU的基本框图如图2所示.
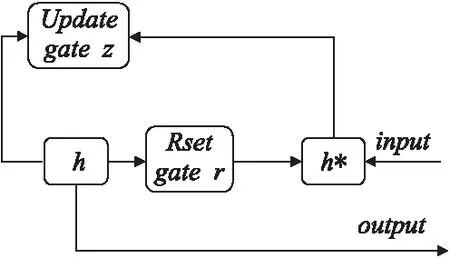
图2 GRU模型框架
一个GRU单元的输入为第t个单词向量xt∈Rw,和前一输出隐状态ht-1,具体更新方式如公式(3)至公式(6)所示:
rt=σ(wr·[ht-1-xt])
(3)
zt=σ(wz·[ht-1,xt])
(4)
(5)
(6)
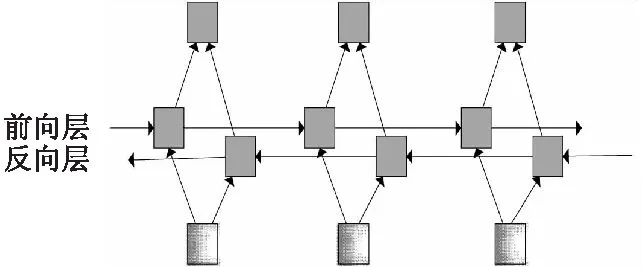
图3 BiGRU网络框架

(7)
3.3 自注意力机制层
自注意力机制,又称内部注意力机制,是注意力机制的一个特例.注意力机制一般发生在Target的Query和Source的所有元素之间,而且Source和Target是不相同的.而自注意力机制指的是Target内部元素之间或者是Source内部元素之间发生的注意力计算机制,也可以认为是Target=Source这种特殊情况下的注意力机制.因此,自注意力机制可以捕获同一个句子中单词之间的一些语义特征或句子特征,且更容易捕获句子中长距离的相互依赖关系.
本层的输入集合表示为X=[h1,h2,…,hT;Ve],其中,hi为纯文本经过BiGRU层的输出表示,Ve为表情符向量的平均值,为了防止单个表情符号的权重过大的情况发生,我们首先对微博文本中的表情符向量求取平均值:
(8)
其中et表示表情符词向量,k表示一条微博文本中的表情符的数目.
自注意力机制的权重矩阵的计算由公式(9)可得:
(9)
其中,xi∈Rd,d表示词向量维度,αi,j>0是自注意力机制的权重,使用正则化技术让∑jαi,j=1.自注意力权重的计算由公式(10)和公式(11)得到:
(10)
(11)
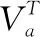
3.4 情感分类层
本文通过Softmax分类器来预测目标方面上文本的情感极性.
Py=softmax(WyS+by)
(12)
(13)
其中Wy为权重矩阵,by为偏置向量,Py为输出的预测标签,C为情绪标签数目.
模型通过交叉熵损失函数来表征情感标签的真实概率分布与预测概率分布之间的距离.
(14)
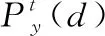
4 实 验
4.1 实验环境
本文的实验环境如表1所示.

表1 实验配置
4.2 数据集
本文选取了NLPCC2013和NLPCC2014的微博公开数据集,和从网上爬取了2万多条新浪微博的文本内容作为本次情感评测任务的微博数据集.为了更好地验证本文模型的情感分类效果,本文选取的数据集的微博语句都是带有表情符号的语句,并且将每一条微博语句都标注情感标签,分别为生气(anger)、厌恶(disgust)、伤心(sadness)、害怕(fear)、高兴(happy)、喜爱(like)、惊喜(surprise)和无情感(none)八类标签,具体的语料信息如表2所示.
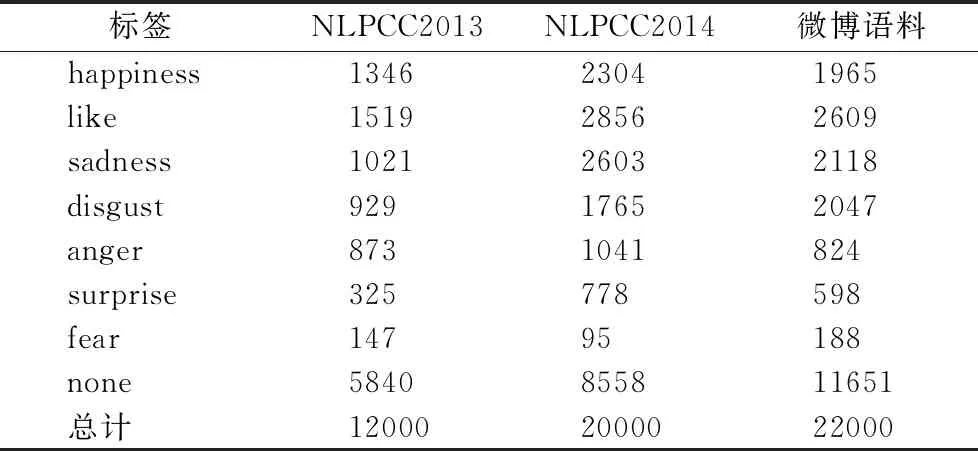
表2 微博语料库
本文设计了主客观二分类和正负极情感二分类两项基本情感分类任务,其中在主客观二分类中none为客观标签,其它7种为主观标签;据表2的3种数据集统计发现,7种情感的使用频率差别很大,其中happy、like、sadness、disgust这4种情感使用次数最多,且happy、like和surprise为积极情感,anger、disgust、sadness和fear为消极情感,所以将happy、like和surprise作为正向标签,将anger、disgust、sadness和fear作为负向标签来实现情感正负极二分类任务.具体实验信息如表3所示.
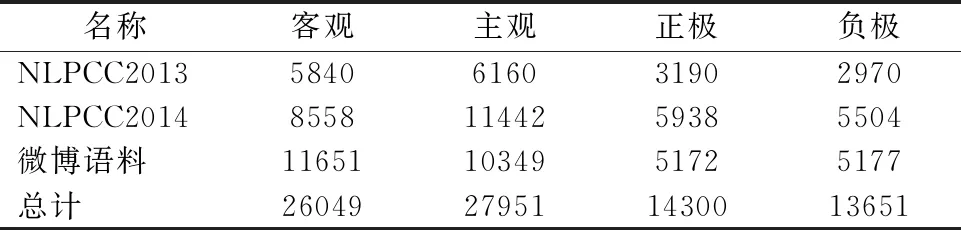
表3 实验统计信息
4.3 实验设置
本文采取交叉验证的方式,将每种数据集分为训练集、验证集和测试集,并且划分比例为8:1:1.本次实验的参数由30次迭代对比调整得到,将平均实验结果最优的参数组合作为最终结果,最终所采用的超参数取值如表4所示.

表4 超参数列表
4.4 实验结果和分析
本文选用了两个实验分别对本文模型的情感分类效果进行衡量.
实验1.为了验证模型的有效性和准确性,设计以下常见的5组模型进行性能对比.
1) ESM模型[8],通过表情符词向量和文本词向量进行余弦距离运算得到词语到情感空间的映射关系,然后输入到SVM模型完成情感分类.
2) EMCNN模型[9],首先使用表情符号构建情感空间映射,然后通过MCNN模型进行语义特征学习,实现情感分类.
3) ARC模型[15],从BiGRU中提取的隐藏向量通过注意机制层提取情感重要信息,然后输出到CNN层的混合神经网络模型.
4) SA-TLSTM-M模型[13],通过将Tree-LSTM网络与self-Attention机制相结合,之后输入到maxout神经元完成情感分类.
5) E-BiLSTM-SA模型,将本文模型中的BiGRU层换成BiLSTM网络,用于对比BiGRU相较于BiLSTM在情感分类任务中的优越性.
本文通过采用准确率(Acc)、精确率(Pre)、召回率(Rec)和宏F1值4个参数完成对模型的相关评价.
从表5-表10可以看出,E-BiGRU-SA模型在所有的指标上都取得了最好的结果,在正负极情感二分类中,E-BiGRU-SA模型在3个数据集准确率分别达到90.83%、92.25%和93.68%;在主客观二分类中,该模型在三个数据集准确率分别达到88.43%、89.33%和90.07%.相较于目前已知情感二分类效果最好的E-BiLSTM-SA模型,在正负极情感二分类任务中,E-BiGRU-SA型在三种数据集中分别提升了1.84%、0.96%和2.31%;主客观二分类任务中,E-BiGRU-SA模型相较于E-BiLSTM-SA模型,分别提升了2.64%、1.92%和2.36%,可以看出BiGRU网络相比BiLSTM网络在提取文本重要信息方面更有优势.
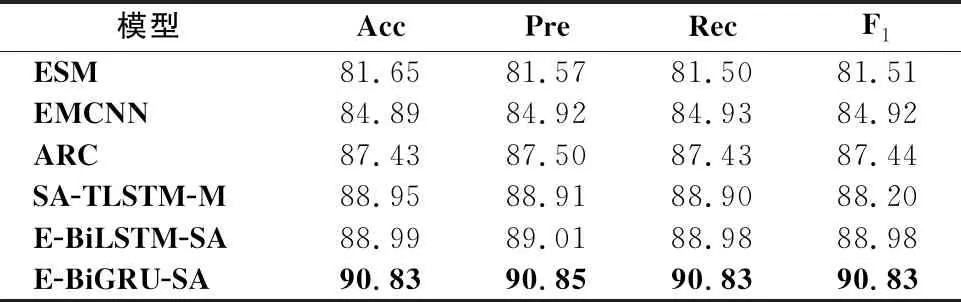
表5 在NLPCC2013中正负极二分类模型信息对比
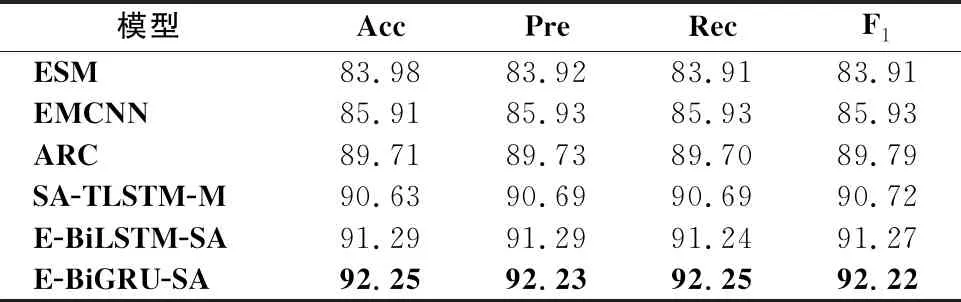
表6 在NLPCC2014中正负极二分类模型信息对比
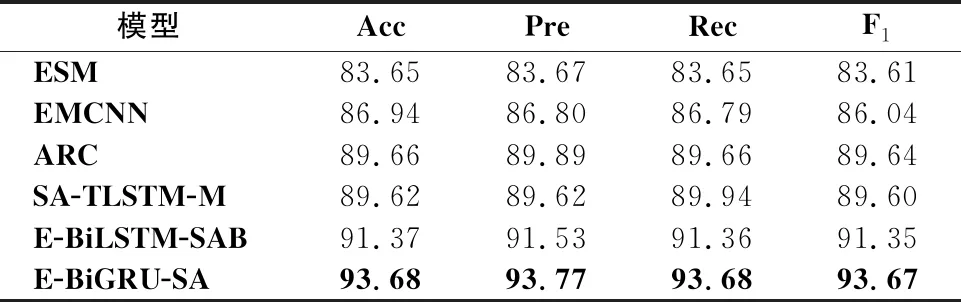
表7 在微博语料中正负极二分类模型信息对比
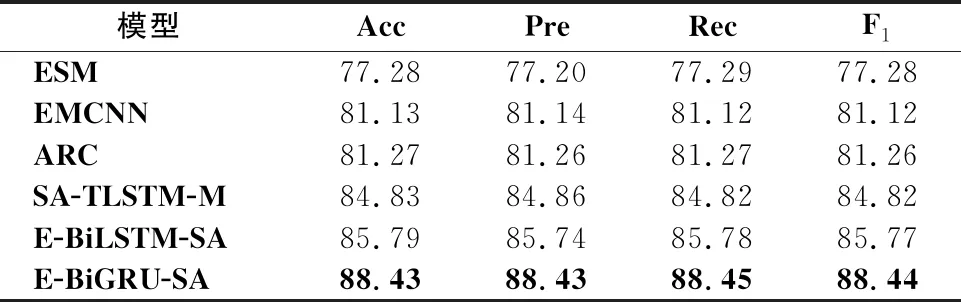
表8 在NLPCC2013中主客观二分类模型信息对比

表9 在NLPCC2014中主客观二分类模型信息对比
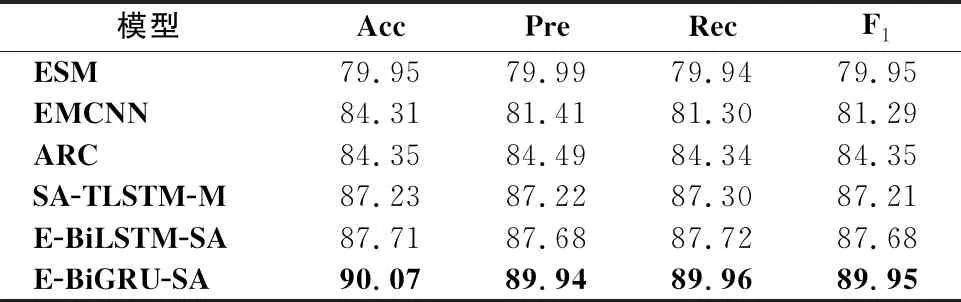
表10 在微博语料中主客观二分类模型信息对比
实验2.为了验证表情符号对于微博情感倾向的作用,同时验证本文模型对于不同极性语料集的影响,本次实验采用以下3种处理方法进行对比实验:
1) BiGRU-SA模型,去掉微博中的表情符,仅用纯文本输入BiGRU-SA网络模型,得到最终的语义编码.
2) T*-BiGRU-SA模型,将微博语料里的表情符直接转换为表情符对应的文本,例如将微博文本“如果明天下雨,我的旅行就泡汤了”转换为文本“如果明天下雨,我的旅行就泡汤了哭泣”,然后转化为文本词向量,输入到BiGRU-SA模型.
3) E*-BiGRU-SA模型,因为表情符号在微博文本中只是起着加强语义表达的作用,没有直接的上下文依赖关系,所以将表情符词向量输入到无时序联系的全连接网络,之后和同时输入BiGRU-SA网络的纯文本特征进行语义合并,得到最终的语义编码.
从图4和图5的实验结果看出,相比于其他三种模型方法,本文中提出E-BiGU-SA模型在正负两种极性分类中的准确率都取得了最优值.将BiGRU-SA模型和T*-BiGRU-SA模型相比较,T*-BiGRU-SA模型的准确率并没有得到明显的提升,甚至在2013年的负极分类的准确率出现了降低情况,因为表情符转化为文字后,不能完全替代表情符在微博文本所包含的语义信息,所以直接将表情符转换为文本的分类方法是不可取的.E*-BiGRU-SA模型和E-BiGU-SA模型相较于BiGRU-SA模型准确率都得到了较大程度的提升,说明将表情符转化为词向量在情感分类中发挥着积极的作用.相较于将表情符输入全连接层的E*-BiGRU-SA模型,E-BiGU-SA模型在正负极分类中准确率都有明显的提升,说明利用自注意力机制将表情符向量和文本向量的进行加权融合,可以更好地捕捉文本的语义特征,证明了本文模型在微博情感分类任务中的有效性.
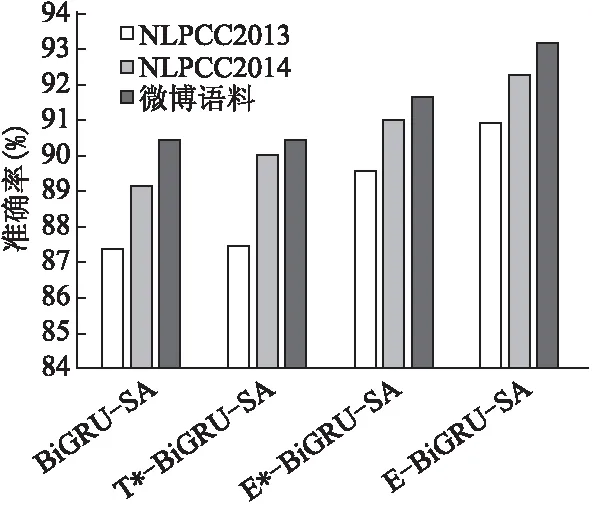
图4 正向极性分类结果对比图
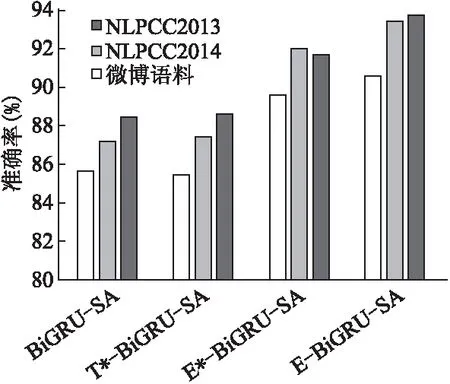
图5 负向极性分类结果对比图
从图4和图5对比可以看出,负向极性的增长幅度要大于正向极性的增长幅度,说明加入表情符号的研究对于负向极性的识别效果更加明显.结合表11的文本实例可以看出,当代微博用户常常使用隐晦或者反讽的语言表达自己的情感,只从文字角度出发很难挖掘出准确的语义信息,加入对表情符的研究则很好地解决了这一问题,说明了本文提出的模型具有一定的实用价值,也进一步说明融合表情符的E-BiGU-SA网络在微博情感分类任务中的优越性.
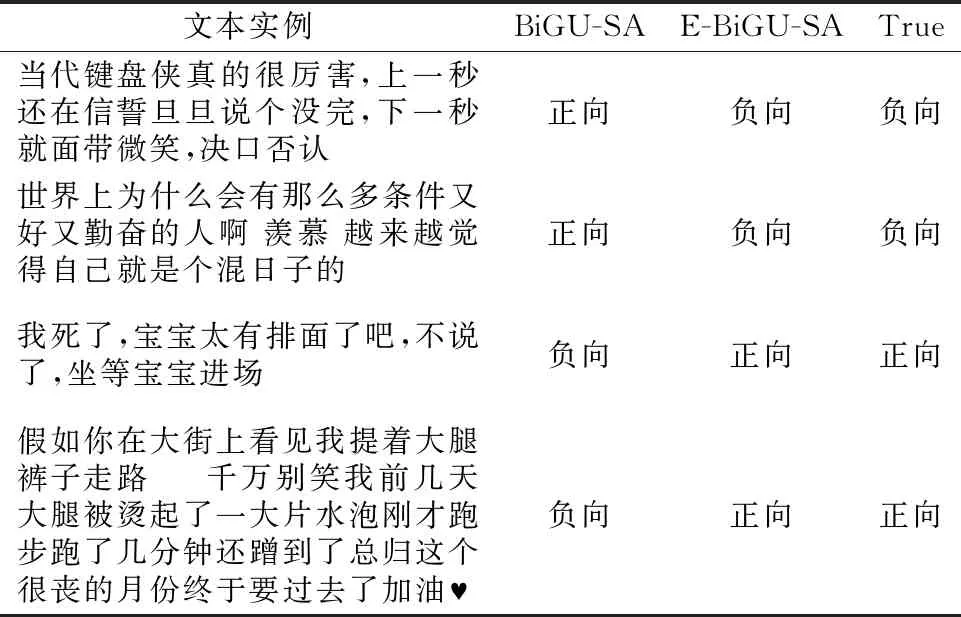
表11 部分实例识别结果
5 结束语
本文提出了一种BiGRU网络和自注意力模型相结合的情感分类方法,不仅考虑了微博纯文本的情感表达,还考虑了文本中情感符号的情感表达.本文提出的模型中利用自注意力机制将表情符向量和文本向量结合生成新的特征表示,促进了微博文本的情感分类能力.在本次实验中我们采集了三种数据集,在这些数据集中,本文提出的模型在多个任务中都取到了良好的效果,并在多个指标上超过了已知的其他模型.
虽然BiGRU模型相较于BiLSTM模型,具有参数数量少,计算速度快,提取文本重点信息准确率高等方面的优势,但是随着数据量的增多,BiGRU模型的准确率也会下降,难以体现该模型的优势,所以下一步将研究更适用于大型数据集中的情感分析模型.
猜你喜欢
消费电子(2022年6期)2022-08-25
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·新阅版(2020年11期)2020-12-21
第二课堂(课外活动版)(2016年2期)2016-10-21
大作文(2016年7期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年10期)2015-10-19
