
一种结合实体邻居信息的知识表示模型
2020-09-03 08:38:26洪锦堆
小型微型计算机系统 2020年8期
洪锦堆,陈 伟,赵 雷
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)E-mail:zhaol@suda.edu.cn
1 引 言
在自然语言处理、信息检索和推荐系统等领域中,知识图谱得到了广泛应用.通常将知识图谱视为储存大规模知识的网络,其中三元组(h,r,t)是知识图谱组织知识的常用形式,头实体h和尾实体t是网络中的节点,关系r表示一条由h指向t的带有标记的边.如(北京,首都,中国)表示北京是中国首都的事实.可是,基于网络形式的知识表示面临以下挑战:1)在大规模知识图谱的计算中效率低下;2)因为数据稀疏而不能有效地处理罕见实体[1].为应对这些挑战,学者们提出了知识表示学习方法,将知识图谱映射为连续的向量空间,采用低维向量进行运算来提高计算的效率.而且对低维向量的学习使罕见的实体也可以捕捉到全局的信息从而较好的缓解数据稀疏问题.目前的知识表示模型利用衡量给定三元组置信度的评分函数fr(h,t)来学习知识的向量表示.例如TransE[2],ComplEx[3],ConvE[4],RotatE[5]等,其中RotatE在公开数据集上取得了最优结果.上述知识表示模型使用三元组来学习知识图谱的结构信息.但是,真实世界的知识图谱中存在着大量可以丰富知识表示模型的扩展信息,包括从外部获取的图像、属性、实体描述文本等外部信息和从知识图谱内部挖掘的关系路径、实体邻居等内部特征和信息.
在已有的研究中,一些研究者把知识图谱的扩展信息引入到了知识表示模型中.TA-DistMult[6]通过引入时间信息来丰富关系的表示.但是来自外部的信息往往获取的成本高昂或者含有大量的噪声.PTransE[7]则将从知识图谱内部挖掘的关系路径信息融入TransE模型中.然而,不是所有的数据都含有较多的关系路径.相比于知识图谱中数量较少的关系,为数量庞大的实体引入扩展信息具有更大的研究价值和发展潜力.DKRL和Jointly等模型[8-10]通过引入外部的实体描述文本信息来强化实体的向量表示.然而,目前为实体引入扩展信息的模型中存在以下不足:1)在现实世界中,从外部获取完整有效的扩展信息存在较大困难.来自外部的扩展信息往往带有较大的噪声,而且由于较高的信息获取成本或者其它技术原因容易导致缺失部分扩展信息;2)对扩展信息和结构信息的整合效率较为低下.在这类模型中,实体除了有一个表示结构信息的结构向量,还会有一个表示扩展信息的扩展向量.这些模型一般使用较为简单的联合表示方法将实体的结构向量和扩展向量结合在一起作为实体的向量表示.可是,目前的联合表示方法不仅没有考虑结构向量和扩展向量因为不同来源表示的不同语义,而且容易使知识表示模型丢失结构信息.这些问题导致目前基于扩展信息的模型的效率都较为低下.
最近,NKGE[11]引入实体的邻居作为扩展信息,该模型中实体的邻居由从文本获取的语义邻居和从知识图谱三元组获取的结构邻居组成.实体邻居的引入有效地降低了扩展信息中可能含有的噪声.但是NKGE的主要目标是编码实体邻居得到扩展信息的有效表示,在扩展信息和结构信息的整合上仍然较为低效.
针对扩展信息和结构信息在整合上较为低效的问题,本文提出了一种基于线性变换的短接联合表示方法.该方法首先对结构向量和扩展向量使用不同的线性变换,将两个不同来源的向量变换到同一个语义空间.然后,结合两种经过变换的向量得到基础联合表示.最后,为了保持结构信息,受残差网络启发[12],通过加法运算把结构向量和基础联合表示短接在一起得到实体的联合表示,将结构向量从实体的联合表示中直接传递出去.此外,考虑到实体的邻居具有丰富的特征和信息以及从外部引入信息时可能遇到的问题,本文在不引入外部信息的条件下,从给定知识图谱内部的三元组集合中为实体构建扩展信息.首先获取实体的邻居列表,接着考虑到数据集的实际情况,利用实体邻居的统计特征使用自动关键词抽取技术[13]从邻居列表中选取部分邻居作为实体的扩展信息.
最后,结合上述的短接联合表示方法和由邻居集合构建的扩展信息,本文提出了结合邻居信息的知识表示模型CombiNe.该模型从实体的邻居集合为实体引入扩展信息来丰富实体的表示,避免了从外部获取扩展信息时可能遇到的问题.而且该模型通过提出的短接联合表示方法有效地整合了不同语义的信息向量,提高了基于扩展信息的模型的效率.在两个公开的基准数据集FB15k-237和WN18RR上的评估了知识表示模型CombiNe在链接预测任务上的效果.实验结果表明,CombiNe优于最优模型RotatE.
2 相关工作
2.1 知识表示学习
近年来,知识表示学习受到研究者们的广泛关注.TransE基于h+r≈t的基本思想建模三元组(h,r,t),其中加粗字母h、r、t分别是头实体、关系、尾实体的低维向量表示.TransH[14],TransR[15]等致力于解决TransE在处理自反及一对多、多对一和多对多等复杂关系时表示能力不足的问题.还有大量的工作从另外的角度出发,致力于满足模型对不同关系模式的完全表达能力.DistMult[16]是一个能够建模对称关系模式的简单双线性模型.ComplEx可以看作是DistMult在复数空间的扩展,该模型可以满足非对称关系模式和逆关系模式.RotatE则将每个关系定义为在复数空间中从头实体到尾实体的旋转,该模型可以同时满足对称/非对称关系模式、逆关系模式以及组合关系模式,并且在用于知识表示学习的基准数据集中取得了最优结果.此外,ConvE利用非线性的卷积网络从拼接的实体和关系向量中提取特征然后建模三元组.以上都是经典的知识表示模型,这些模型仅利用了知识图谱的结构信息,而引入扩展信息则能够进一步丰富实体的表示提高性能表现.
2.2 实体的联合表示方法
已有为实体引入信息的模型主要是从含有噪声的扩展信息中,通过长短期记忆网络(LSTM)、卷积神经网络(CNN)等深度学习方法获得扩展信息的有效表示,然后由实体联合表示方法融合结构向量和扩展向量得到实体的联合表示.目前对扩展信息的学习已经有了较好的研究,但是针对实体联合表示方法的研究还停留在较为初级的阶段.有以下常见的实体联合表示方法可以结合结构向量和扩展向量:
1)DKRL[8]中结构向量和扩展向量未经任何处理的经过组合,得到多组输入后,分别输入到评分函数中计算得到多个评分,再通过不同的权重,组合多个评分得到最后的评分.这种联合表示方法虽然能将部分结构向量直接传递到评分函数,但是更为混乱的输入不仅增加了计算量而且破坏了知识表示模型原有的结构.
2)如图1左边所示,两种不同的向量经过预处理后通过加法运算组合在一起从而得到实体联合表示.在加法运算前还有几种预处理的方法.AATE[9]引入了一个权重因子,利用权重因子调整不同向量的重要性,但是各个维度的重要性被一致对待,忽略了可能只有部分维度是比较重要的情况;门控机制则能较好的应对不同的维度,Jointly[10]中每个实体都有自己的一个门控向量,通过sigmoid函数控制联合表示的每一维是依赖于结构向量还是扩展向量.门控机制不仅增加了大量参数,而且门控单元中结构向量和扩展向量是相互排斥的,不能同时兼顾两种向量.
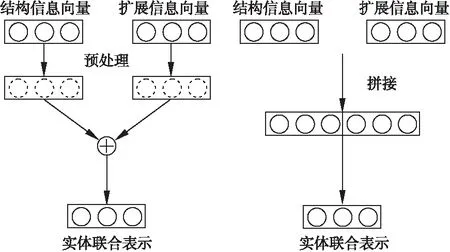
图1 常见的实体联合表示方法
3)如图1右边所示,两种向量被拼接在一起后作为输入,之后使用线性或者非线性的方法还原维度得到实体的联合表示.LiteralE[17]中使用了类似的方法,将实体的结构向量和扩展向量拼接在一起,经处理之后,使用类似于门控循环单元(GRU)的门控机制来得到实体的联合表示.该方法运算量较大而且门控机制中的问题依然存在.
但是,这些联合表示方法都没有考虑到两种信息的不同作用,存在着若干问题.首先,使用简单的方法直接将两种向量直接结合在一起,忽略了两种向量是由不同来源学习而来的,需要变换后才能结合在一起;其次,结构向量和扩展向量被混合隐藏在实体的联合表示中,忽略了知识表示模型最后往往是用学习结构表示的评分函数来计算评分,容易让评分函数在计算评分时失去原有的结构向量信息,造成引入信息的知识表示模型效率低下.
3 结合实体邻居信息的知识表示模型
3.1 问题定义
知识表示学习的目标是将实体和关系映射为有效的低维向量,如将(h,r,t)中的实体和关系分别映射为低维向量h∈Rk、t∈Rk和r∈Rk,符号Rk表示k维的向量空间.
可以通过用来判断给定的三元组是正例还是反例的评分函数fr(h,t)→R来优化学习低维向量.评分函数fr(h,t)也可被写作f(h,r,t)→R.如果评分函数f(h,r,t)能有效的给三元组打分,区分正确的三元组和错误的三元组则说明低维向量学习到了有效的信息.例如,预测(北京,首都,中国)是正确的,(南京,首都,中国)是错误的.
知识图谱是有向的多关系图,记作G= {(h,r,t)}⊆E*R*E,其中E表示实体集合、R表示关系集合,G表示三元组的集合,(h,r,t)表示知识图谱中的一条记录,h、r和t分别表示头实体、关系和尾实体.
3.2 模型介绍
结合邻居信息的CombiNe模型结构如图2所示,可以分为关键邻居抽取,实体联合表示和知识表示学习三层.
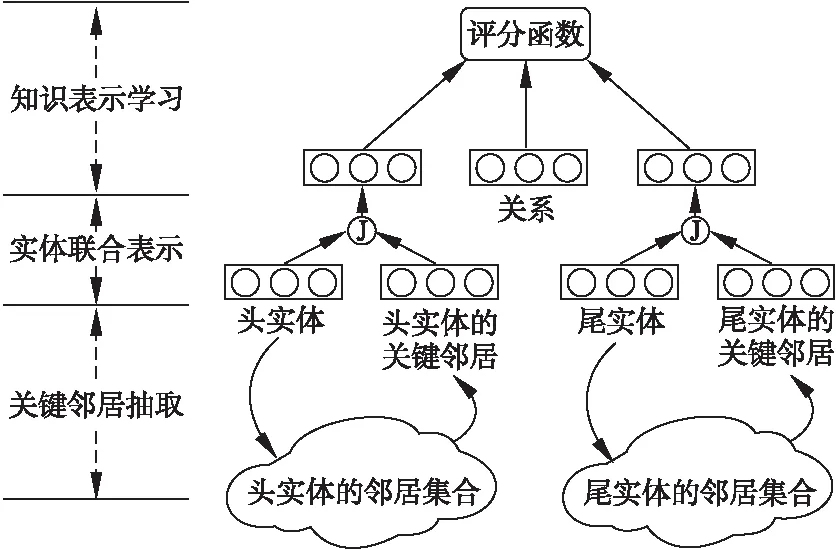
图2 CombiNe的结构
关键邻居抽取层会从实体的邻居集合Ne={h|(h,r,e)∈G,h∈E,r∈R}∪{t|(e,r,t)∈G,t∈E,r∈R}中为实体e抽取出关键的邻居key(Ne)⊆Ne.在本模型中从实体e的邻居集合Ne中为实体抽取一个实体邻居kn作为关键邻居,则e的关键邻居可以重写为key(Ne)={kn},抽取出的邻居仍属于实体集合E;在实体联合表示层中,输入的是实体e的结构向量es∈Rk和扩展向量ea∈Rk,该层将输出实体的联合表示向量ej∈Rk.在CombiNe模型中,因为关键邻居抽取层输出的key(Ne)仍属于实体集合E,则不需要再学习扩展向量的表示,而是将kn对应的实体结构向量赋值给ea,即ea=kns;在知识表示学习层中,可以采用现有学习结构信息的大部分知识表示模型.CombiNe模型采用ComplEx模型作为知识表示学习阶段使用的知识表示模型.
与现有引入扩展信息的模型相比,虽然CombiNe也将扩展信息引入已有的知识表示模型,但是除了在联合表示阶段需要增加额外的参数,该模型不会引入其他的参数用于学习实体的扩展向量.因为模型中实体的扩展向量来自关键实体邻居对应的结构向量.使用实体的结构向量作为实体引入的扩展信息不仅使实体的联合表示能从邻居中学到更丰富的信息,而且邻居也将由于参与到实体的表示中得到更多的信息.下面将具体地描述模型中各层的实现.
3.3 关键邻居抽取
如果两个实体具有相似的邻居,也就是说它们的大多数邻居是相同的,则它们应该具有相近的信息,进而有相似的表示.然而,由于知识图谱的不完整,在给定的知识图谱中通过实体邻居确定相似的实体面临着一定的挑战.而且知识图谱中实体邻居的分布可能跨度极大,如在数据集FB15k-237上单个实体的邻居数量范围低至一两个高达几千个.因此,模型要避免使用邻居集合中的所有实体作为扩展信息,采用有效的方法来选取部分邻居作为扩展信息更符合实际情况.
从实体的邻居集合中抽取出的邻居要能反映邻居集合的主要信息.不同于NKGE[11]认为出现次数少的邻居更有代表性.有更多链接的邻居不仅具有更丰富的信息,而且能较好的表示实体邻居集合的特征.在部分邻居的选取上,利用邻居的频率统计信息是一类有效的方法.自动关键词抽取技术中的TFIDF[13]恰好符合关键邻居抽取的要求.实体e的邻居n的频率可以分为两个部分,一部分是e的邻居集合中n出现频率,即局部频率l(e,n)=|{(e,r,n)∈G}∪{(n,r,e)∈G}|;另一部分是n在整个知识图谱中作为邻居出现的频率,即全局频率g(n)=|{h|{(h,r,n)∈G}∪{t|(n,r,t)∈G}|,这里的全局频率参考TFIDF做了一定的修正.
TFIDF广泛用于自动关键词抽取,而且该技术不关心词在文档中的位置,使用词频(TF)和逆文档频率(IDF)的乘积(TF×IDF)来衡量词语对文档内容的描述能力[13].类似于TFIDF只关心词的频率,在抽取关键邻居时,CombiNe更关心链接的数量,也就是邻居的频率.如果一个实体经常在同一个邻居集合中作为实体的邻居出现,那么该实体对这个邻居集合来说是较为重要的,但若是该实体频繁的在各实体的邻居中出现则说明该实体过于平凡不太重要.使用式(1)中的m(e,n)可以有效计算e中邻居n的重要性,局部频率高的邻居重要性会得到提高,全局频率高的邻居则会受到抑制.式(1)中|E|表示实体集合中实体的数量.
(1)
最后获取{m(e,n1),m(e,n2),…,m(e,n|Ne|)}中具有最大值的邻居ni作为实体e关键邻居,即key(Ne)={ni}.
3.4 实体联合表示
知识表示学习模型一般通过结构信息来学习实体的表示,但是这并不常常有效.因为知识图谱中有些实体仅出现在少量的三元组中,导致这些实体缺乏足够的结构信息.引入扩展信息可以为实体提供更多的可学习信息.
结构信息和扩展信息的不同来源表明将结构向量和扩展向量直接结合起来是不合理的.使用线性变换可以统一不同的来源和空间,具体如式(2)所示.
e′s=Wses+bs,e′a=Waea+ba
(2)
式(2)中Ws∈Rk*k和Wa∈Rk*k是用于线性变换的k×k矩阵,bs∈Rk和ba∈Rk是偏置向量.接着使用加法运算结合两种向量得到基础联合ebj表示,具体如式(3)所示.
ebj=h(es,ea)=e′s+e′a
(3)
线性变换和加法运算的使用不仅使不同来源的信息结合得更加合理可靠,而且还使基础联合表示能从各个维度自动学习结构向量和扩展向量.进一步地,实体的联合表示在知识表示学习阶段将由用于学习结构向量的评分函数计算,结构向量在联合表示中应被谨慎地处理.但是,在基础联合表示中,结构向量和扩展向量被混合在一起,当按照传统的知识表示模型学习的时候,评分函数在计算阶段容易丢失实体的结构信息.为了将结构信息暴露给评分函数,如图3所示,将结构向量直接短接基础联合表示,具体如式(4)所示.
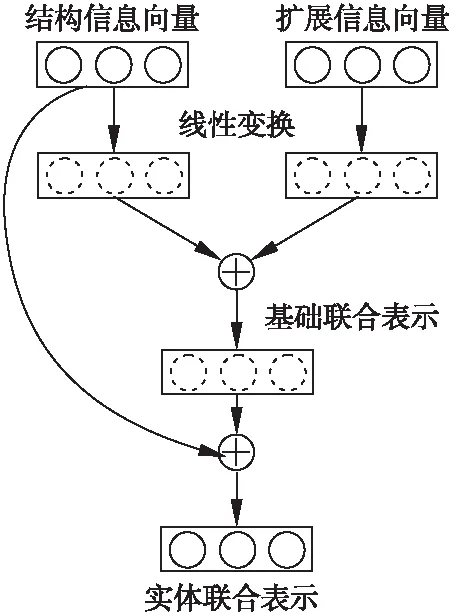
图3 短接实体联合表示
ej=h(es,ea)+es=ebj+es
(4)
通过短接方式连接,结构向量中的结构信息将直接输出到实体联合表示,实体联合表示将保留原始的结构向量.在残差网络中[12],原始的输入被保留下来用于训练非常深的网络.短接实体联合表示不仅保持了原始的结构向量,而且还使模型更容易训练.
3.5 知识表示学习和训练
CombiNe只是通过引入的邻居信息丰富实体的表示,同Jointly[9],NKGE[10],LiteralE[16]等一样易于扩展到传统的知识表示模型中.CombiNe在知识表示学习阶段中使用ComplEx模型.在ComplEx模型中,实体和关系由实数和虚数两个部分的向量组成.在标准的短接实体联合表示中共享参数也要区分为实数和虚数两个部分.
不同于ComplEx原文中的实现,CombiNe参考ConvE采用了一些能够加速训练速度同时提升模型性能的训练方式.对于一个三元组(h,r,t),使用标准二元交叉熵损失函数(binary cross-entropy loss)和1-N打分策略,具体如式(5)所示.
(5)
其中|E|表示所有实体的数量,i表示实体集合E中的一个实体;pi是三元组(h,r,i)的评分;yi的值若为1表示三元组(h,r,i)是在训练集中出现的正例,其它未知情况的三元组则填充0;由于给定的都是知识图谱中的正例,大部分方法训练时需要通过替换正例三元组中的部分实体来生成负例,而且在计算时要独立地计算每一个三元组.1-N打分策略则能同时计算多个元组而且不用耗费时间在主动生成负例上.
1-N打分策略指对于一个三元组(h,r,t)同时计算(h,r,E)或者(t,r-1,E)的评分,在1-N打分策略中(h,r)或者(t,r-1)首先被计算,然后通过矩阵乘法运算一次计算在全部实体E上的评分,该策略能够显著加速训练和测试的速度.为了受益于该策略,需要为数据集中的全部三元组添加逆关系r-1.由于实际情况中实体的数量远远大于关系的数量,虽然逆关系会增加关系表示的参数数量,但是少量参数的增加相比于性能的提升和加速是值得的.
CombiNe模型采用PyTorch框架实现.其中批归一化(batch normalization)、Dropout、标签平滑被用来加速训练和防止过拟合.批归一化作用在计算(e,r)时的实体e上.Dropout被应用在实体联合表示之前的结构向量es和扩展向量ea上,具体如图3中的线性变换前.
另外在CombiNe中还对联合表示的共享参数矩阵使用了L2正则化.因此,最终的损失函数如式(6)所示.
L=Lscore+λ(‖Ws‖2+‖Wa‖2)
(6)
4 实 验
4.1 实验数据集
可以通过在知识图谱上的链接预测任务来评估知识表示模型的性能表现.知识图谱的链接预测任务已经有了较为通用的基准数据集、测试方法和评估指标.实验采用的基准数据集是FB15k-237和WN18RR.为了避免测试泄露,没有采用之前使用较多的FB15k和WN18数据集.详细的数据集统计信息如表1所示.

表1 实验数据集的统计信息
FB15k-237是 FB15k的子集.FB15k是从FreeBase抽取的一个大规模通用知识图谱.验证集和测试集中包含大量在训练阶段出现的反关系,导致简单的模型在FB15k上也能有较好的表现.FB15k-237是FB15k移除反关系后的子集.
WN18RR是WN18的子集.WN18是从WordNet创建的,包含词语之间关系的知识图谱.WN18和FB15k同样面临着测试泄露的问题.在WN18RR中,反关系被移除.传统知识表示模型在该数据集中的推理效果显著下降.
4.2 评估指标与实验设置
链接预测旨在预测给定的(h,r,?)或者(?,r,t)中缺失的实体.对于一个待测试的三元组,固定它的头实体h和关系r,将尾实体替换为实体集中的所有实体或者固定尾实体t和关系r,将头实体替换为实体集中的所有实体.然后计算评分并将所有的实体按照评分进行排序.
在评估阶段,测试集中的所有三元组并未在训练过程中出现.实验报道了广泛使用的“filter”设置的结果,该设置过滤掉所有已被模型观测到的事实.采用了五个常用的评测指标:平均排序(MR)、平均倒数排序(MRR)、hits@10、hits@3、hits@1.MR是全部测试样本中正确答案排序值的平均值;MRR是全部测试样本中正确答案排序值的倒数的平均值.hits@k是全部测试样本中正确答案排名不大于k的占比.除了MR指标越低越好之外,其它指标全是越高越好.
设置结构向量和扩展向量的Dropout取同样的参数设置.批量大小(batch size)设置为128,标签平滑率设置为0.1.为了更公平地和大部分模型做比较,向量表达空间的维度d取值100.实验的其它超参数设置使用网格寻优法搜索,根据验证集上MRR的表现选择最优参数.采用Adam优化器,学习率α的搜索范围是{0.001,0.003,0.005},指数学习率衰减(exponential learning rate decay)β的搜索范围是{0.99,1.0},Dropout丢弃率γ的搜索范围为{0.0,0.2,0.3,0.4,0.5},L2正则化参数λ的搜索范围为{1e-3,5e-4,1e-4,5e-5,1e-5}.实验时每训练5轮进行一次测试,在第600轮时停止,报道在MRR指标上表现最优时的结果.
在数据集FB15k-237上,最优参数设置为α=0.001,β=0.99,γ=0.5,λ=5e-5;在数据集WN18RR上最优参数设置的为α=0.003,β=1.0,γ=0.5,λ=1e-3.
4.3 实验结果与分析
几个具有代表性且被广泛引用的知识表示模型TransE、DistMult、ComplEx和ConvE被选取作为CombiNe的结果对比,同时CombiNe还与目前性能最优的RotatE模型作对比.另外还与引入外部信息的方法KBlrn[18]、NKGE[11]、LiteralE[17]作对比.由于实验用的数据集和测试方法均保持一致,直接引用了现有文献的部分实验结果.其中TransE引自文献[11],DistMult引自文献[4].按照CombiNe的训练步骤和优化方法重新实现了ComplEx,在使用Dropout优化技术和保持CombiNe的学习率一致的情况下取得了比之前文献报道更好的性能表现.为了降低模型的参数量另外扩展了CombiNe的一个简化版本CombiNe-simple.在简化版本中,共享参数不作区分的同时处理实数和虚数部分.还将CombiNe中的联合表示方法替换成由Jointly提出的门控机制并记作CombiNe-gating.剩余的实验结果均引自原文献.所有的实验结果均在表2中给出,表中加粗突出显示的是每列中的最优结果.
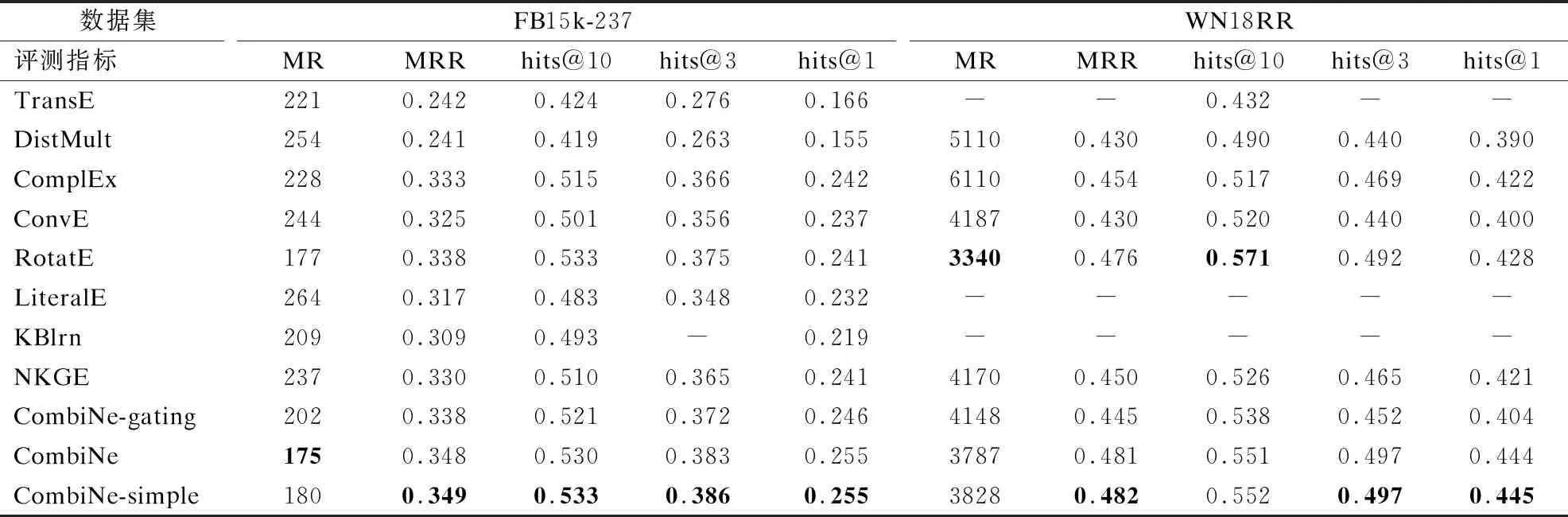
表2 在FB15k-237和WN18RR上的链接预测结果
从表2中最后两行的实验结果对比可以看到,简化版本CombiNe-simple不仅降低了参数数量,而且在两个实验数据集上相比于标准版本均取得了轻微的性能提升.CombiNe-gating相对于ComplEx主要提升在hits@10和hits@3上,但是在全部评测指标上均落后于CombiNe模型.从结果对比上可以看到,短接联合表示方法优于目前的门控机制联合表示方法.
在FB15k-237数据集上,CombiNe在所有评测指标上均取得了最优结果.在WN18RR数据集的评测指标MRR、hits@3、hits@1上,CombiNe也取得了最优结果,在评测指标MR和hits@10上,虽然CombiNe未能超过最优结果,但是也取得了次优的性能表现.需要注意的是,RotatE使用了其它方法中没有使用的自对抗负抽取技术(self-adversarial negative sampling),从作者公开的代码实现上还可以看到RotatE使用了较大的维度,如在FB15k-237上的维度d为1000.虽然CombiNe使用的维度d被限制为100,但是除了WN18RR数据集上的2个评测指标,在剩余的评测指标上CombiNe使用更少的参数量却优于RotatE.实验结果表明CombiNe优于最优模型RotatE.
同引入邻居信息的NKGE相比.NKGE与其使用的基础知识表示模型ConvE对比,在FB15k-237的MRR上提升幅度为1.5%,在WN18RR的MRR上提升幅度为4.7%.CombiNe同ComplEx模型对比,在FB15k-237的MRR上提升幅度为4.8%,在WN18RR的MRR上提升幅度为6.2%.从提升幅度上看,使用关键邻居的CombiNe效率高于使用更多低频邻居的NKGE.
和知识表示学习阶段使用的ComplEx模型相比,在评测指标hits@3和hits@1上两个数据集的提升幅度都有5%以上.引入的邻居信息有效的融合到实体表示中,显著提高了实体的表示能力.CombiNe通过添加少量用于实体联合表示的参数更有效地利用了ComplEx中学习到的实体表示和参数.
通过控制训练集中三元组的数量测试实体邻居,可以进一步探索引入实体邻居的作用.将FB15k-237训练集中的三元组随机保留80%得到新的数据集FB15k-237-0.8.使用和FB15k-237一样的训练步骤和参数设置进行训练和测试.结果如表3所示.
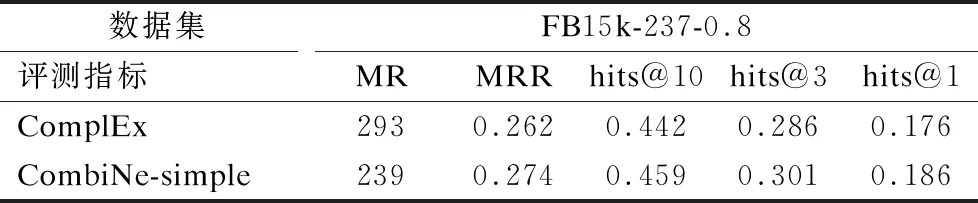
表3 在FB15k-237-0.8上的链接预测结果
从表3可以看到当训练样本减少时,ComplEx和CombiNe的性能均下降严重,但是CombiNe的表现依然优于ComplEx模型.CombiNe能从邻居学习到有效的表示.同完整的FB15k-237数据集上的评估结果对比,更多的邻居对CombiNe带来的提升大于对ComplEx的提升.
5 总结与展望
本文提出了一种结合实体邻居信息来丰富实体表示的知识表示模型CombiNe.该模型通过能融合不同来源的信息和保持结构向量传递的短接联合表示方法有效提高了引入信息的知识表示模型的效率.针对目前主要是从高昂的外部数据引入扩展信息的困境,利用现有的自动关键词抽取技术TFIDF从实体的邻居列表中为每个实体抽取关键实体邻居.然后,使用线性变换结合不同来源的实体结构向量和引入的实体扩展向量.最后为了将结构向量传递给下游的知识表示模型在实体联合表示中短接结构向量.实验结果表明CombiNe不仅相对于基础的知识表示模型有较大的提升而且利用更少的参数实现了在大部分评测指标上对目前最优模型的超越.
目前CombiNe仅在ComplEx模型进行了扩展,未来可以在TransE、RotatE等其它知识表示模型上进行扩展.另外当前使用的关键实体邻居抽取技术仅考虑了统计特征,还可以考虑增加其它特征.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
