
基于压缩激活机制的轻量级人脸识别网络设计
2020-08-31 07:03:10黄伦文
数字通信世界 2020年8期
黄伦文
(安徽四创电子股份有限公司,安徽 合肥 230031)
0 引言
人体生物特征识别技术包括人脸、指纹、手掌纹、虹膜、声音、体型等,其中,人脸识别是最容易被用户接受的身份认证方式之一。目前,高精度的人脸验证模型多是以对计算资源要求高的深度卷积神经网络为基础建立的,这些模型使用大量的数据进行训练,模型复杂且具有非常多的参数,需要消耗大量计算资源,难以在移动设备和嵌入式设备中运行。因此,低内存占用、低计算资源消耗的轻量级神经网络成为当前的研究热点。
非轻量级人脸识别网络具有较高的识别精度,但是参数量较大,如DeepFace、DeepFR等。本文提出了一种基于压缩激活机制的轻量级人脸识别网络,减少了MobileFaceNet网络头部卷积核的数量,降低模型的复杂度;并且引入squeeze-and-excitation结构[1],增加网络的感受野和学习特征的能力,使得网络具备从整个图像更多地关注人脸关键部位的能力,进而提高网络的识别精度。
1 基于压缩激活机制的轻量级人脸识别网络
1.1 网络结构设计
基于压缩激活机制的轻量级人脸识别网络(Squeeze and Excitation Mobile Face Net,SEMFN)结构见表1。每一行代表网络的一层,每一列的含义依次为:输入流,具体操作,输出通道数量,瓶颈层中扩展的通道数,卷积核的大小,卷积计算的步长,重复次数,NL表示使用的非线性变换函数,本文使用PReLU[2]作为非线性激活函数。
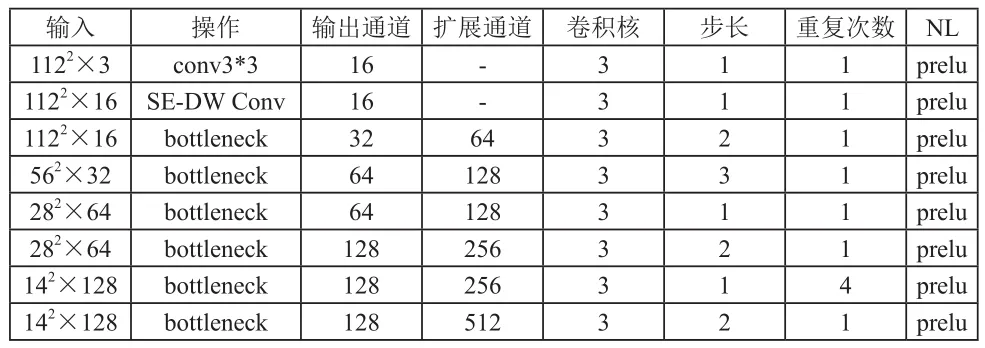
表1 基于压缩激活机制的轻量级人脸识别网络

72×128 bottleneck 128 256 3 1 2 prelu 72×128 linear GDConv 128 - 7 1 1 -12×128 linear conv 128 - 1 1 1 -
为了降低网络参数数量,SEMFN头部卷积核通道数降低为16,保证网络精度的前提下,减少了网络头部的参数,节省网络的计算成本;SE-DW conv层具有Depthwise Convolution[3]和SEBlock[9]两种计算,在网络的最开始阶段引入了轻量级注意力机制,使得网络能够更准确地抓取输入信息最值得注意的区域,精准地学习输入人脸特征。GDConv是指DepthwiseConvolution计算。此外,我们在瓶颈层使用了一个快速的下采样策略,在最后几个卷积层使用了提前降维策略,并在linear GDConv层之后使用线性1×1的卷积层作为特征输出层。最终形成的模型参数量为80万,相对于MobileFaceNet的99万参数量,降低了近20%。
1.2 引入压缩激活机制
Sequeeze and Excitationblock是一种网络子结构[1],能够方便地嵌入到其他网络结构中,其核心思想是:引入了轻量级注意力机制,通过网络学习特征通道的权重,使得部分有效的特征通道具有较高的权重,其他通道具有低权重,促使模型自适应抓取高权重通道特征,提高识别精度。
本文在网络开始阶段SE-DW Conv层引入了轻量级注意力机制,使得网络能够更准确地抓取输入信息最值得注意的区域,精准地学习输入人脸特征,具体结构如图1所示。

图1 SE-DW conv层结构图
第一步,对输入的通道进行Squeeze压缩操作,对输入层进行特征压缩,将每个二维的特征通道变成一个实数,这个实数具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。Squeeze操作为全局平均池化,如公式(1):

式中,uk为输入层数据;k为输入通道数;W和H为输入通道数据的宽和高;Fs为Squeeze操作结果,是大小为k的向量。
第二步,对Squeeze的结果进行激活操作Excitation,如公式(2),通过参数为每个特征通道生成权重,用来显示地建模特征通道间的相关性。

式中,W1和W2为全连接层操作;δ和σ为非线性激活函数;W1的维度是k/r*k,r是缩放参数,本文算法r=4。即,先对Squeeze的结果Fs进行全连接层操作,并根据r降低维度,经过ReLU非线性激活函数层处理;为了保持输出维度k不变,再经过W2全连接层操作,这里W2的维度是k*k/r;最后在经过sigmoid函数,得到激活后的结果Fe。
第三步,根据Excitation操作获取的通道权重系数Fe,对输入数据进行加权处理Fw,如公式(3):

式中,uk为输入层数据;Fe为步骤二中求解的Excitation权重。通过乘法逐通道加权到输入特征上,完成通道维度上的原始特征的重标定。自适应学习输入通道的权重,尤其是引入了轻量级注意力机制,通过网络学习特征通道的权重,促使模型自适应抓取高权重通道特征,提高识别精度。
第四步,对输入通道数据进行depthwise卷积处理,其优势在于大幅降低卷积参数的数量,例如本文网络的第二层,输入层和输出层大小均为112*112*16,卷积核大小为3*3时,普通卷积核参数为3*3*16*16=2304;对于depthwise卷积,则参数为3*3*16=144,大幅降低参数量。
BN是Batch Normalization层,将卷积层计算之后的数据归一化,忽略整体数据的大小变化而保留卷积后数据之间的相对关系。Act.是激活函数,此处采用了PReLU非线性变换。
第五步,对步第四步中获得的depthwise卷积结果和第三步中获得的加权结果进行重组,具体方法为计算二者的内积。
1.3 Bottleneck瓶颈层结构设计

图2 Bottleneck层结构图
Bottleneck是一种瓶颈层结构,可以帮助网络综合性地理解输入信息,学习输入特征。
第一块和第三块类似,由Conv1x1、BN、Act构成。其中,Conv1x1是指卷积核大小为1的卷积层;如前文所述,BN是Batch Normalization层,将卷积层计算之后的数据归一化;Act是激活函数,这里采用了PReLU激活函数,使该神经元具备分层的非线性映射学习能力。
第 二 块 由 DWConv3x3、BN、Act组 成, 其 中,DWConv3×3是指卷积核大小kernel_size=3的Depthwise ConvolutioBN。
SEMFN使用大量的Bottleneck瓶颈层作为网络的主体结构,输入信息可以在网络内部充分流动,使网络有足够的参数理解输入信息并记录信息特征。
2 实验结果分析
2.1 数据集
CASIA-WebFace[10]数据集包含了10,575个人的494,414张图像。本文使用CASIA-WebFace作为训练数据,并使用人脸验证数据库LFW[11]来检查不同条件下算法的改进情况,训练数据与测试数据没有重叠。
2.2 实验设置
(1)数据准备:对每张图片进行双线性插值缩放,将所有图片统一为112×112的分辨率;将所有图像颜色信息归一化处理,即每个像素的颜色信息减去127.5,然后除以128。
(2)训练设置:由于GPU内存有限,我们采用随机梯度下降(SGD)作为优化器,批量大小为恒定为128。与大模型相比,轻量级模型可以使用相同的GPU服务进行相对大批量的训练,这也是DCNNs训练阶段的一个常见但关键的实际问题。动量参数设置为0∶9,初始学习速率设置为0.1,并在28、38、48、58个时点周期性降低为前一步的0.1倍,以适应训练计划。
2.3 实验对比和分析
表2为引入Squeeze and Excitation结构的实验对比分析,可见:模型参数量仅增加了128,识别率由98.91%提升至99.13%,证明了SE结构能够提升模型的识别精度。

表2 引入Squeeze and Excitation结构实验对比
为了验证本文算法的性能,与当前人脸识别领域主流的算法进行了实验对比,包括:MobileNetV1/V2[3][4]、Light CNN-29[5]、ShuffleNet[6]、MobileID[7]、MobileFaceNet[8]、LMobileNetE[12]等, 结 果 详 见 表3。Light CNN-29和LMobileNetE的识别精度较高,但是其训练数据集分别是4M和3.8M,模型参数数量分别是12.8M和26.7M,均明显高于本文算法,难以应用于移动平台;MobileNetV1/V2的模型参数数量降低至3.2M和2.1M,但是其识别率均未达到99%,识别精度不高;MobileID参数量降低至1.0M,但是识别精度大幅降低;ShuffleNet使用逐点群卷积等方式进一步降低了参数量,识别性能优于MobileID。
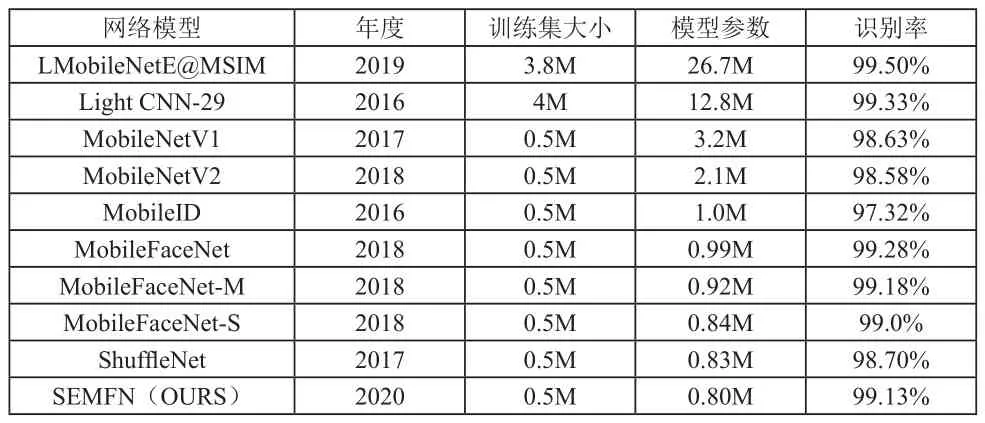
表3 主流算法结果对比
MobileFaceNet的整体性能较好,包括三个不同的网络类型,其中,MobileFaceNet的识别率得到99.28%,但是其网络参数数量为0.99M,相对本文算法,识别率提升0.15%,参数量多了约20%;MobileFaceNet-M参数量0.92M,仍然较高;MobileFaceNet-S参数量降低至0.84M,识别率为99%。本文算法在模型复杂度和识别率上均优于MobileFaceNet-S,是因为本文引入了基于压缩激活机制的轻量级注意力机制,能够有效地增加网络的感受野和学习特征的能力,使得网络具备从整个图像更多地关注人脸关键部位的能力,进而提高网络的识别精度。
3 结束语
为了保持识别精度的同时进一步降低轻量级人脸识别网络的参数量,提高网络的运行速度,本文提出了一种基于压缩激活机制的轻量级人脸识别网络,通过降低头部卷积核通道数量降低了模型的复杂度;进一步引入了squeeze-and-excitation结构,自适应计算特征通道的权重,使得网络在降低参数的同时,保持较高的识别精度。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
学生天地(2020年31期)2020-06-01 02:32:06
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年11期)2019-07-04 00:34:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国交通信息化(2016年2期)2016-06-06 07:28:02
计算机工程(2015年8期)2015-07-03 12:19:07
