
基于信息量和逻辑回归耦合模型的滑坡易发性评价
2020-08-29 07:43郭建飞刘华赞常志璐李怡静黄发明
科学技术与工程 2020年21期
田 钦,张 彪,郭建飞,刘华赞,常志璐,李怡静,黄发明
(南昌大学建筑工程学院,南昌 330031)
滑坡是最常见的自然灾害之一,多发生于山地丘陵地区,常造成巨大的经济损失和人员伤亡[1]。近年来,江西省内滑坡发生的频率逐渐增高,其多发生在雨季,以小型浅层土质滑坡为主[2]。江西省平均每年因滑坡造成的经济损失达几千万元,人员伤亡20~30人。因此,开展滑坡易发性评价研究对减灾防灾具有十分重要的现实意义和社会价值。
滑坡易发性评价是指通过研究多个影响因子的共同作用,进而探究特定地区滑坡发生的概率大小。其一般包括滑坡编录、评价单元划分、基础环境因子选取、建立模型、结果检验五个过程[3]。模型建立对易发性评价至关重要,相关模型主要分为定性、半定性和定量,常见的定性分析是通过专家打分对主要因素进行评判和确定[4],如层次分析法[5-7]。半定性模型有结合层次分析法和频率比模型的二元统计法、模糊数学[8-9]。定量模型主要有信息量模型[10]、支持向量机[11-12]、逻辑回归[13]、神经网络[14]、证据权重法[15]以及多个模型的对比综合研究[16-18]。
上述模型中信息量和逻辑回归在易发性评价中的应用非常广泛。但这两种模型在滑坡易发性评价方面各有优缺点。例如信息量模型建模效率高,且能判断每个因子不同因子状态对滑坡发生的权重,却不能判断不同因子对滑坡发生的影响程度的相对大小。逻辑回归模型可以判断各个因子对滑坡发生的权重但不能表现出不同因子状态对滑坡发生的权重。目前大多数研究采用的评价模型之间彼此相互独立,建模精度和建模效率往往不高。
研究表明通过模型之间的耦合不仅可以表现出模型之间的内在联系,有时甚至能起到优劣互补的作用[19]。因此,拟提出信息量-逻辑回归耦合模型,充分利用各模型的优点,克服各单一模型存在的缺点,提高模型易发性评价精度。
以江西省宁都县南部为例,考虑了地形地貌、水文环境、基础地质和地表覆被因子,分别采用信息量模型、逻辑回归模型以及信息量-逻辑回归耦合模型进行滑坡易发性评价,采用成功率曲线进行精度检验,最终获得更准确、有效的滑坡易发性评价结果,以期为相关部门防灾减灾提供理论指导和帮助。
1 方法
1.1 信息量模型
信息量,即所获滑坡信息的质量与数量,指的是研究区已发生滑坡的具体情况,包括滑坡位置、滑坡数量、滑坡面积等。滑坡的发生(h)受多种因素(xn)影响,并且在各种不同的地质环境中,各种因素在滑坡发生过程中所起的作用大小、性质是不同的,存在最佳因素组合[20]。基于概率论和信息论以及工程地质类比法,采用信息量去表征各种因素共同作用下滑坡发生可能性的相对大小,即信息量越大,滑坡发生的可能性越大[21-22]。其原始公式如式(1)所示:
I(h,x1,x2,…,xn)=
(1)
式(1)中:h表示滑坡事件;xn表示第n个影响因子;I(h,x1,x2,…,xn)表示n个因子共同作用下的信息量;P(h)表示滑坡发生的概率;P(h|x1,x2…,xn)表示所有因子组合下滑坡发生的概率。由条件概率定义,式(1)可写为
I(h,x1,x2,…,xn)=I(h,x1)+Ix1(h,x2)+…+Ix1,x2,…,xn-1(h,xn)
(2)
式(2)中:Ix1,x2,…,xn-1(h,xn)表示在x1,x2,…,xn-1确定的前提下,xn对滑坡发生所贡献的信息量。考虑到区域滑坡预测一般采用面积比来计算,式(2)可写为
(3)

(4)
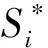
1.2 逻辑回归模型
逻辑回归分析模型是一种基于Logit变换的数学分析方法。因其在滑坡预测中运用的简便性和相对准确性而得到比较广泛的运用。逻辑回归分析模型以所选取因子作为自变量,以滑坡发生与否(发生为1,不发生为0)为因变量,是一种对二分类因变量进行回归分析时经常采用的非线性分类统计方法[23],计算公式为
Y=B0+B1x1+B2x2+…+Bnxn
(5)
(6)
(7)
式中:xn表示第n个因子;Pv为频率比,作为模型指标值;B0表示逻辑回归常数项;B1~Bn为逻辑回归回归系数;P为滑坡预测概率。
研究区共有2 087个滑坡单元,通过随机选取同等数量的非滑坡数据单元共同作为训练数据导入SPSS 22软件计算出逻辑回归的常数项和回归系数,其中以频率比Pv作为训练数据的具体代入计算值。最后根据式(6),计算出每个单元的P,用以表征滑坡易发性。
1.3 信息量-逻辑回归耦合模型
信息量-逻辑回归耦合模型是将式(4)计算所得的信息量I代替式(7)的频率比Pv,进而作为逻辑回归模型的指标值,选取同样的滑坡与非滑坡训练数据单元,将数据导入SPSS 22软件计算出逻辑回归的常数项和回归系数,代入式(6)后得到P。耦合模型实现过程如图 1所示。

图1 耦合模型实现路径
2 研究区概况及数据源
2.1 宁都地区概述与滑坡评价单元划分
选取滑坡较发育的江西省赣州市宁都地区作为研究案例,研究区位于北纬26°05′~26°31′,东经115°40′~116°17′,地处江西省东南部,总面积约1 709 km2。如图 2所示,该研究区高程介于154.9~1 059.7 m,地势起伏不平,北高南低,四周高中间低,丘陵和山地众多。该区属于中亚热带季风湿润气候,一年中夏季高温且多暴雨,年平均气温在14~19 ℃,年降水量在1 500~1 700 mm。宁都地区水系遍布,沟壑纵横,加上发源于北部的梅江贯穿流过,流域面积近1 500 km2。同时,研究区岩石类型丰富,以变质岩类和碳酸盐岩类为主,断层褶皱发育,地质构造复杂,这样的地理环境条件为滑坡的发生提供了有利的物质条件。

图2 研究区概况及滑坡编录
研究区滑坡分布广泛,滑坡点共297个,滑坡总面级约为1.88 km2,划分为2 087个滑坡栅格。中上部滑坡相对较少,滑坡在南部表现较为集中,且滑坡多见于地势较低之处,呈现出沿水系分布的特点。滑坡体以第四纪堆积层为主,运动方式主要是牵引式整体滑动。连续强降雨和人类工程活动是诱发滑坡的两大重要因素。
评价单元划分是滑坡易发性评价过程中的一个重要环节,栅格和斜坡单元被很多学者广泛采用。其中,斜坡单元虽然更符合实际地质情况,但其操作性较低,且更适用于大比例尺地形图。而栅格单元划分操作性更强,且适用于中小型比例尺地形图,综合研究地概况和研究的可行性后,采用栅格单元作为评价单元[3]。此外,选择合适大小的栅格对研究的准确性和合理性也至关重要[24]。栅格大小的选择主要依据研究精度和效度,既要满足研究问题的需要,又要方便电脑进行运算,提高研究效率。结合研究区实际情况,选取30 m×30 m栅格进行分析研究,研究区内共有1 898 935个栅格。
2.2 基础环境因子选取
2.2.1 数据源
研究数据来源包括:①空间分辨率为30 m的数字高程数据(DEM),用于滑坡编录;②野外调查相关资料和滑坡编录信息;③比例尺为1∶50 000的宁都地区地质图,用于提取岩性因子信息;④宁都地区遥感数据,用于提取地表植被指数(normalized difference vegetable index, NDVI)和地表房屋建筑指数(normalized difference building index, NDBI)。
2.2.2 基础环境因子选取
滑坡易发性评价是通过分析基础环境因子的空间分布和在没有外部诱发因子作用时对滑坡发生的交互作用,获得在同等工程地质环境下区域滑坡发生的可能性[25]。其中,基础环境因子比较全面地包括了与滑坡发生密切相关的各种因子,主要有地形地貌、基础地质、水文环境和地表覆被因子4大类[3]。通过综合考虑研究区的地理环境条件,选取了与滑坡发生相关性较强的因子建立评价指标体系如表1所示。
2.2.3 基础环境因子频率比分析
在获取基础环境因子之后,需探讨滑坡与其基础环境因子之间的非线性响应关系。频率比法可以很好地处理这个问题,其体现了基础环境因子各属性区间对滑坡易发性的联动性的定量统计。通过ARCGIS 10.2,采用自然间断点法把选取的基础环境因子划分5个等级(其中,地层岩性因子按照地层组合划分),进而求得各因素各个区间内包含的栅格数和滑坡栅格数,通过式(7)求得频率比值,结果如表 1所示。当频率比值大于1,表明该种条件下有利于滑坡发生;当频率比值小于1,表明该种条件下不利于滑坡发生[26]。
计算出因子各个状态的频率比后,为防止信息重复需要判断因子间是否存在共线性,选取滑坡栅格和同等数量非滑坡栅格对应的数据组成数字矩阵导入SPSS 22统计软件对10个基础环境因子间的相关性进行分析,结果发现,因子间相关性系数均小于0.3,为弱相关,该10个因子可用于建立滑坡易发性评价指标体系。
(1)地形地貌因子。高程是影响滑坡的重要因素。如图2、表1所示,当高程在154.906 ~ 342.969 m时,频率比大于1,滑坡较易发生。坡向和坡度均从DEM数据提取而来。如表1、图3(a)~图3(b)所示,当坡度在4.56°~14.85°(栅格百分比约为50.4%)时,频率比大于1,该种条件下利于滑坡发生,有73%的滑坡发生在该区段内,表明中等坡度更易发生滑坡。
平面曲率定义为坡向的坡度,在水平方向上反映了地表所有山脊线和山谷线,如表1、图3(c)所示。剖面曲率定义为坡度的坡度,在垂直方向上表征坡度的变化程度,如表1、图3(d)所示,地形起伏度是一个描述地形宏观性的指标,其在数值上等于一定区域内高程的最大值减去最小值,如表1、图3(e)所示。
(2)水文环境因子。水是导致滑坡发生的重要因素之一。它不仅会加速岩石土体的侵蚀作用,还会使得滑动面间的夹层土更易软化搓动,从而导致滑坡更易发生。通过ARCGIS 10.2软件,对DEM数据经过填洼、流向流量提取、河流连接得到水系分布,再进行多环缓冲区分析。如表1、图 3(f)所示,当距水系距离为300 m以内时,频率比超过了2,表明距水系距离越近越容易发生滑坡。
(3)基础地质和地表覆被因子。岩性是滑坡发生的重要内部因素,如表1、图3(g),全部处于西北方向的岩浆岩类和大多处于东南方向的变质岩类,其对应的频率比值均大于1,有利于滑坡发生。NDVI用来表征地表植被覆盖程度,而NDBI用来表征地表建筑密度,它们的范围都是-1~1。如表1、图3(h)~图3(i)所示,当NDVI小于0.334(栅格百分比约为73.1%)和NDBI大于-0.360(栅格百分比约为70.1%)时,频率比大于1,表明该区段有利于滑坡发生。
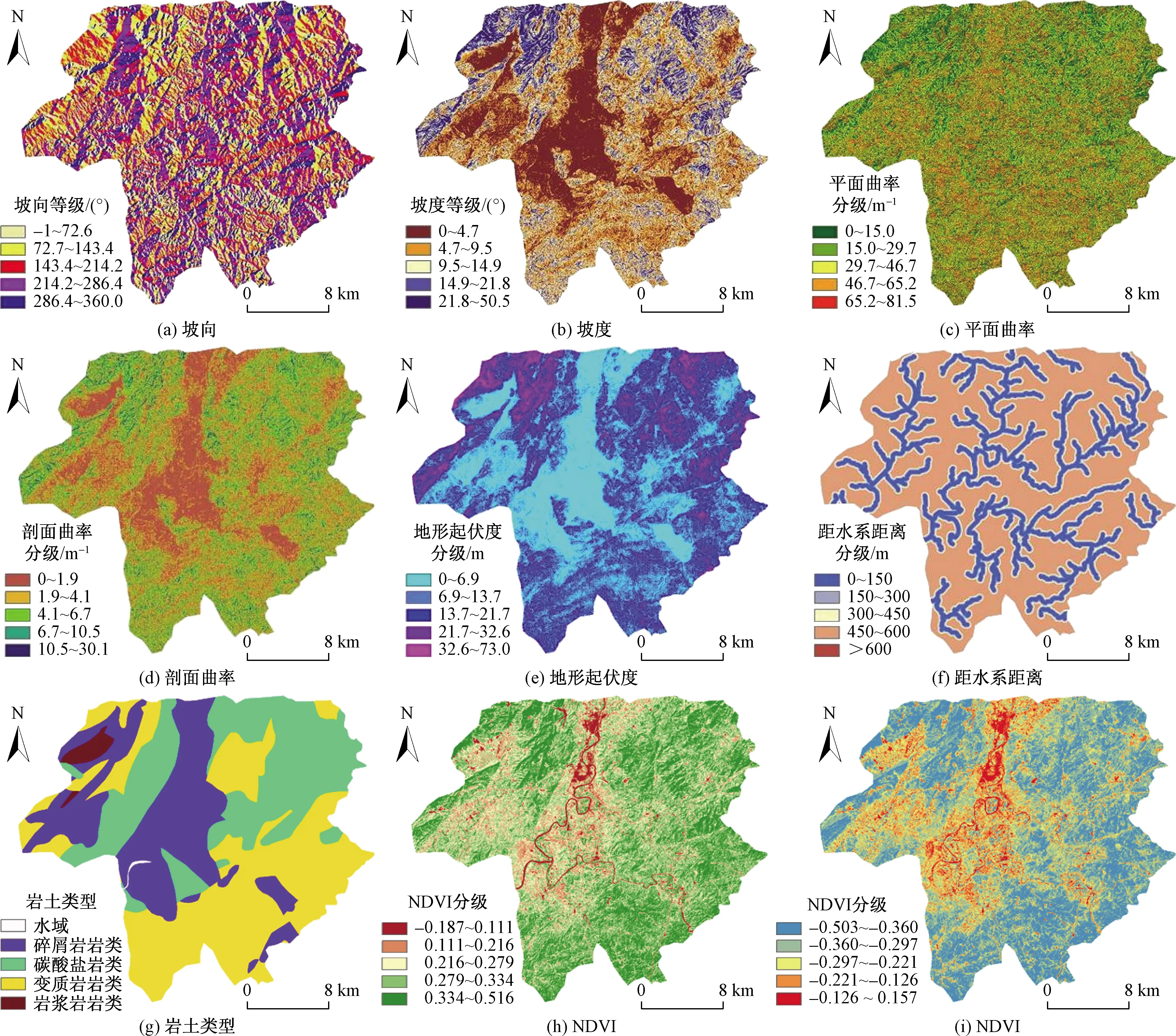
图3 评价因子分级

表1 各因子频率比和信息量
3 滑坡易发性模型评价分析
3.1 信息量模型评价
对各因子间相关性进行检验后,选取了10个指标因子建立滑坡易发性评价指标体系,然后按式(3)计算各因子状态对应的信息量值,再依据式(4),将每一个因子的信息量值进行叠加,每个栅格被赋予一个总的信息量值,信息量值越大表示滑坡越容易发生,故用信息量的大小来表征滑坡的易发性。
利用ARCGIS 10.2自带的自然间断点法,如图4(a)所示,获得滑坡易发性分区图。如表 2所示,它将易发性指数划分为5个等级:高易发区(3.527~3.871)、较高易发区(3.365~3.527)、中等易发区(3.219~3.365)、较低易发区(3.063~3.219)和低易发区(2.542~3.063),各等级所占比例分别为17.8%、22.9%、27.7%、22.4%、9.2%。
3.2 逻辑回归模型评价
研究区滑坡栅格单元共有2 087个,从滑坡之外的非滑坡区随机选择产生2 087个非滑坡栅格单元。将滑坡点赋值为1,非滑坡点赋值为0。将频率比值作为指标值,组成数字矩阵后导入SPSS 22软件进行分析。
逻辑回归分析要求各样本间不存在共线性关系,即显著性检验指标应小于0.05,结果表明剖面曲率不满足要求,故将其剔除,剔除后的结果如表3所示。从表3可以看出,各因子对滑坡发生的影响程度从大到小依次为岩性(1.72)、距水系距离(1.593)、坡向(1.419)、NDBI(1.357)、高程(1.299)、平面曲率(1.253)、NDVI(0.621)、坡度(0.614)和地形起伏度(0.407)。其中,岩性和距水系距离对应的权重最大,表明这两个因子在很大程度上影响滑坡发生。NDVI、坡度和地形起伏度对应回归系数均小于1,表明它们对滑坡发生的影响程度最小。
将剔除剖面曲率后的回归系数代入式(5)、式(6),从而计算出每个栅格对应的滑坡发生的概率值,利用概率值来表征滑坡易发性,同样采用自然间断点法进行分级,易发性分区图如图 4(b)所示。如表 2所示,共分为5个等级:高易发区(0.792~0.993)、较高易发区(0.584~0.792)、中等易发区(0.386~0.584)、较低易发区(0.209~0.386)和低易发区(0.007~0.209),各等级所占比例分别为15.9%、14.9%、19.0%、24.0%、26.2%。
3.3 信息量-逻辑回归耦合模型评价
信息量-逻辑回归耦合模型将计算所得信息量值作为指标值,评价过程与逻辑回归模型基本一致,通过SPSS 22软件分析,发现剖面曲率对应的显著性检验指标Sig依然不符合模型要求,将其剔除后的结果如表 3所示。
回归系数结果如表 3所示,表示各因子对滑坡发生的影响程度从大到小依次为距水系距离(1.416)、岩性(1.057)、高程(0.997)、NDBI(0.98)、平面曲率(0.68)、坡向(0.626)、NDVI(0.539)、坡度(0.359)、地形起伏度(0.192)。对滑坡发生与否影响程度最大的依旧是岩性和距水系距离,而影响程度最小的仍然是NDVI、坡度和地形起伏度。
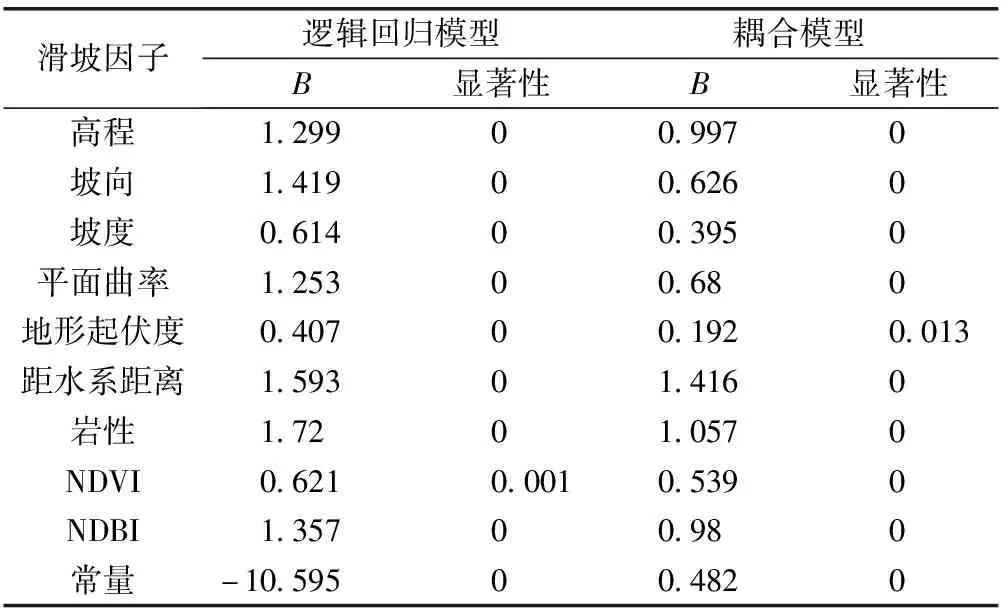
表3 逻辑回归模型与耦合模型显著性结果
如图4(c)所示,利用自然间断点法分级获得易发性分区图。如表 2所示,将易发性分为五个等级:高易发区(0.790~0.991)、较高易发区(0.588~0.790)、中等易发区(0.391~0.588)、较低易发区(0.201~0.391)和低易发区(0.004~0.201),各等级所占比例分别为16.9%、15.4%、17.0%、23.2%、27.5%。

表2 各易发区灾害分布
4 模型讨论
4.1 宁都滑坡易发分区图分析
(1)由表2可知,从高易发区到低易发区,三个模型的频率比都逐渐降低。信息量、逻辑回归和信息量-逻辑回归耦合模型在高易发区频率比分别为2.558、3.014、3.074,可以得出耦合模型评价结果最优。由表3可知,在整体上各因子权重与逻辑回归模型结果趋势一致,但在局部各因子的权重排序上,信息量-逻辑回归耦合模型与逻辑回归模型存在一定差异,具体原因还有待进一步研究。
(2)由图4可知,总体上,高和较高滑坡易发区沿着水系表现出集中分布,这与表1、实际情况及前人研究结果一致,进一步证实了水在滑坡发生过程中的重要作用。信息量模型的高和较高易发性分区相比其他两个模型,表现得比较分散,逻辑回归模型的高和较高易发性分区表现出沿着水系过于集中,而耦合模型既表现出沿着水系的集中趋势,也呈现一定的分散性。这个结果也在一定程度上表明耦合模型在滑坡易发性评价中表现出更好的效果。

图4 模型评价结果
4.2 模型精度检验
采用预测率曲线对三种模型的精度进行对比评价,并通过各易发性分区的滑坡栅格比例来验证模型预测与实际情况的符合程度。预测率曲线是以预测滑坡面积比为横坐标,以实际滑坡面积比为纵坐标,通过曲线与横轴围成的面积(AUC)来评价模型精度,AUC越大,表示模型精度越高,预测效果越好。三个模型的预测率曲线如图 5所示。信息量、逻辑回归及其耦合模型对应的AUC分别为0.838、0.864、0.876。由图5可以看出,尽管耦合模型的精度只比逻辑回归模型高0.012,主要原因可能是耦合模型的耦合主体是逻辑回归模型,二者在本源上是一致的。但通过模型的耦合确实提高了评价精度,在一定程度上,体现出信息量-逻辑回归耦合模型在滑坡易发性评价中的优越性。
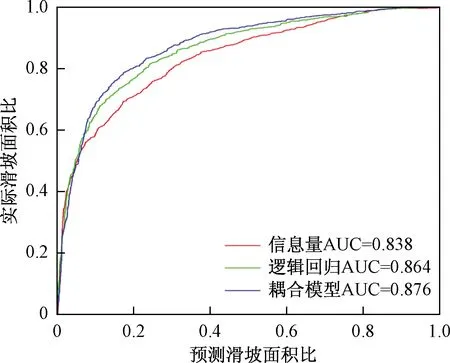
图5 滑坡易发性评价精度的预测率曲线
各易发性分区的滑坡栅格比例是通过将历史滑坡分布与易发性分区图叠加分析得到的。如表 2所示,高易发区中,信息量、逻辑回归和信息量-逻辑回归耦合模型的滑坡栅格比例分别为45.5%、47.8%、51.9%,低易发性分区,信息量、逻辑回归和信息量-逻辑回归耦合模型的滑坡栅格比例分别为6.3%、6.7%、5.3%,表明耦合模型与实际情况更符合,模型预测更准确。
5 结论
以宁都地区为例,选取10个环境因子,通过建立信息量模型、逻辑回归模型以及信息量-逻辑回归耦合模型,对滑坡易发性进行评价。得到如下结论。
(1)宁都地区各模型滑坡易发性的AUC精度分别为0.833(信息量模型)、0.864(逻辑回归模型)、0.876(耦合模型)。表明信息量-逻辑回归耦合模型反映滑坡更全面并且评价精度更高。
(2)信息量-逻辑回归耦合模型计算出的高易发性分区的滑坡栅格比例为51.9%,大于信息量(45.5%)和逻辑回归模型(47.8%)。而低易发性分区的滑坡栅格比例为5.3%,小于信息量(6.3%)和逻辑回归模型(6.7%),这表明信息量-逻辑回归耦合模型与实际情况更符合。
(3)研究所建立的易发性分区图表明,3个模型的易发性分区图有一定的相似性,都主要沿水系分布,表明水在滑坡发生中的重要作用,同时高程、岩性等也对滑坡发生具有较大的影响。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
房地产导刊(2022年1期)2022-02-28
今日农业(2021年10期)2021-11-27
科技创新与应用(2021年31期)2021-11-09
今日农业(2021年1期)2021-03-19
中北大学学报(自然科学版)(2020年4期)2020-07-13
导弹与航天运载技术(2017年6期)2018-01-29
成才之路(2016年18期)2016-07-08
试题与研究·教学论坛(2015年5期)2015-09-02
