
面向数字资源的自动标签模型
2020-08-26 14:56雷智文黄玲
哈尔滨理工大学学报 2020年3期
雷智文 黄玲

摘 要:针对数字资源标签数量不足,获取困难的问题,提出了一种新的自动标签方法,对于收集的公共文化资源数据集和其它公开数据集,能够有效的进行标签扩展。提出过程依据神经网络理论和生成学习理论,采用隐含狄利克雷分布(latent dirichlet allocation, LDA)和Word2Vec方法分别对资源和初始标签进行处理,生成资源和初始标签的表示向量,然后以此两种向量作为深度结构语义模型的输入,建立面向数字资源的自动标签模型。从结果来看,该方法的标签扩展效果在精确度、平均排序倒数、平均准确率等指标上表现上总体优于文中提到的其它对比方法,能够解决某些情况下资源标签不足的问题,提高资源的利用率。
关键词:标签扩展;隐含狄利克雷分布;Word2Vec
DOI:10.15938/j.jhust.2020.03.022
中图分类号: TP181
文献标志码: A
文章编号: 1007-2683(2020)03-0144-07
Abstract:In this paper, we proposed a novel automatic tagging system which aimed at the lack of tags about digital resources and the difficulty of extending tags. This tagging system can effectively extend tags for public cultural resources we collected and other public data sets. The algorithm of tagging system based on neural network and generative learning. We use Latent Dirichlet Allocation (LDA) and Word2Vec to process resources and initial tags, generating the representation vectors of resources and initial tags, then use these two kinds of vector to build this automatic tagging system focused on digital resources. From the results, the Precision, MRR, MAP and other indexes of this method is better than other comparison tagging methods mentioned in this paper, and it can solve the lack of tags in some cases. Increasing utilization of resources.
Keywords:automatic tagging; latent dirichlet allocation; Word2Vec
0 引言
在互联网应用中,对象和标签的结合方法是一种非常有用的技术,标签能够大幅度提高信息检索的效率,高质量的标签还能够帮助对资源进行分类和整合,使得资源的利用变得更加有效。对图像、视频及文本等资源进行自动标注的方法通常有两类,一类是关键词提取方法,另一类是近年来逐渐兴起的关键词生成方法,关键词提取只依赖于文本本身的信息,不能生成新的信息,标签提取的效果已经到了瓶颈。因此,能够生成新信息的标签提取方法近年来越来越受到人们的重视,这种新的标签提取方法和传统基于关键词提取的方法最主要的不同点就是它往往拥有更加优化的词库和非线性結构,从而能够取得更好的标签提取效果。
1 介绍
在信息检索领域,快速增长的信息量和日益困难的数据收集不断带来新的挑战,亟需新的方法应对这些挑战。为了解决资源可用标签过少的问题,我们使用了一种新的自动标注方法,通过计算标签之间的语义关系,对公共文化资源的已有标签进行扩展,此方法已经在以前的工作[1]中进行了发表。在本文中,我们在前文研究工作的基础上,改进了模型,同时对数据集进行了扩展,使用了新的评估指标和对比算法。在实验中,我们使用了如下过程对标签和资源进行处理。
对于文本资源,使用LDA模型,根据主题的分布生成频率共现矩阵,矩阵的每一行即是一项资源的向量,表示该资源在该矩阵空间中的位置。
对于标签,使用Word2Vec模型进行处理,将初始标签映射到同一个向量空间中,同时生成初始标签的表示向量。
通过使用如上的方法,我们完成对资源的标签的向量化,然后我们根據资源和标签的对应关系构建资源-标签向量对,再构建深度结构语义模型(deep structured semantic model, DSSM)并使用向量化后的资源和标签对模型进行训练,训练完成后再次利用训练好的模型计算出资源和初始标签集中每个标签的相似度,利用相似度的大小对初始标签进行排序,并取和该资源相似度最高的一批初始标签作为该资源的扩展标签。
2 相关研究
许多研究者都对自动标签技术进行过讨论,文[2]设计了一种名为TagAssist的系统,能够利用现有的标签内容为新的博客自动分配标签。Belem等人[3]提出了一种为目标对象分配标签的新方法,使用了启发式的方法,能够将新的度量方式加入现有的方法中,并使用一些生成备选词语描述目标对象的内容。Huang等人[4]设计了一种新的深度结构语义模型,能够将信息检索中的询问词和检索结果分别映射到相同的低维向量空间中,并使用询问词和检索结果在对应向量空间中的距离表示它们的相似程度。文[5]提出了一种名为TagHats的分级自动标注系统,能够根据目录、主题以及关键词生成出三种类型的标签,根据目录生成的标签能够在不同的维度上对文档进行分类。Chirita等[6]提出了一种叫做P-TAG的技术,能够为网页生成个性化标签。
在自动标签的效率提升方面,文[7]提出了一种针对稀疏短文本的自动标签方法。Si等人[8]提出了一种可扩展的实时标签推荐方法。通过建立LDA模型,可以实时的计算出将某个标签分配给一个文档的概率,然后选择概率最高的进行分配。
在自动标注使用的算法和数据及上,也有人进行了大量的前期研究,文[4]使用了词散列(word hashing)的处理方法,能够扩大模型的规模,并能够对字典进行扩展,使得模型能够用于大型网页搜索引擎。文[3]采用了RankSVM和遗传算法,用于生成排序函数,精确分析给定标签和对象之间的相似度。文[9]测试了不同的标签排序方法,构建标签云表示目标资源数据集。文[5]使用了层次分类法和关键词提取算法,分别负责分配目录标签和主题标签,和负责构建文档模型。文[7]中使用了BibSonomy数据集对其提出的方法进行了验证,结果表明了所采用方法的有效性。文[10]对其提出的方法在Flickr上的一组经过标签的数据上进行了验证。文[11]采用了分布式训练过程,使用了真实博客文章数据。
3 自动标签扩展模型
在以前的工作[1]中,已经详细介绍了基于DSSM的自动标签系统的原理,对之前所做工作进行简单回顾。首先介绍数据的预处理过程。数据的预处理分为两步,对于资源数据,使用LDA[12]模型去生成资源的主题分布,以此分布在每个主题上的概率组成的向量代替资源,对于资源的初始标签,使用百度百科的几乎所有词条对Word2Vec模型进行训练,并生成这些词条的向量表示,在结果中找出初始标签和其对应的向量表示,完成数据的处理后,我们使用此数据对DSSM模型进行训练,然后使用训练好的模型计算资源和所有初始标签之间的相似度并对结果进行排序,取相似度最高的一批标签作为自动标注的结果。
对于数据集中的文本资源,使用了LDA算法[13-15]去生成每个资源所对应的向量,LDA是一种文本主题模型,通过在文本资源上进行训练,能够生成文本资源的主题分布,使用此分布能够计算出文本资源在确定主题数量下的向量表示。
对于各数据集的初始标签,使用了Word2Vec去生成其表示向量,Word2Vec是一种用于提取词向量的工具,包括CBOW模型和Skip-gram模型[16-17]中,使用的是CBOW模型,它能够将不同的词语签映射到同一个向量空间中,同时获得每个词语的向量表示。
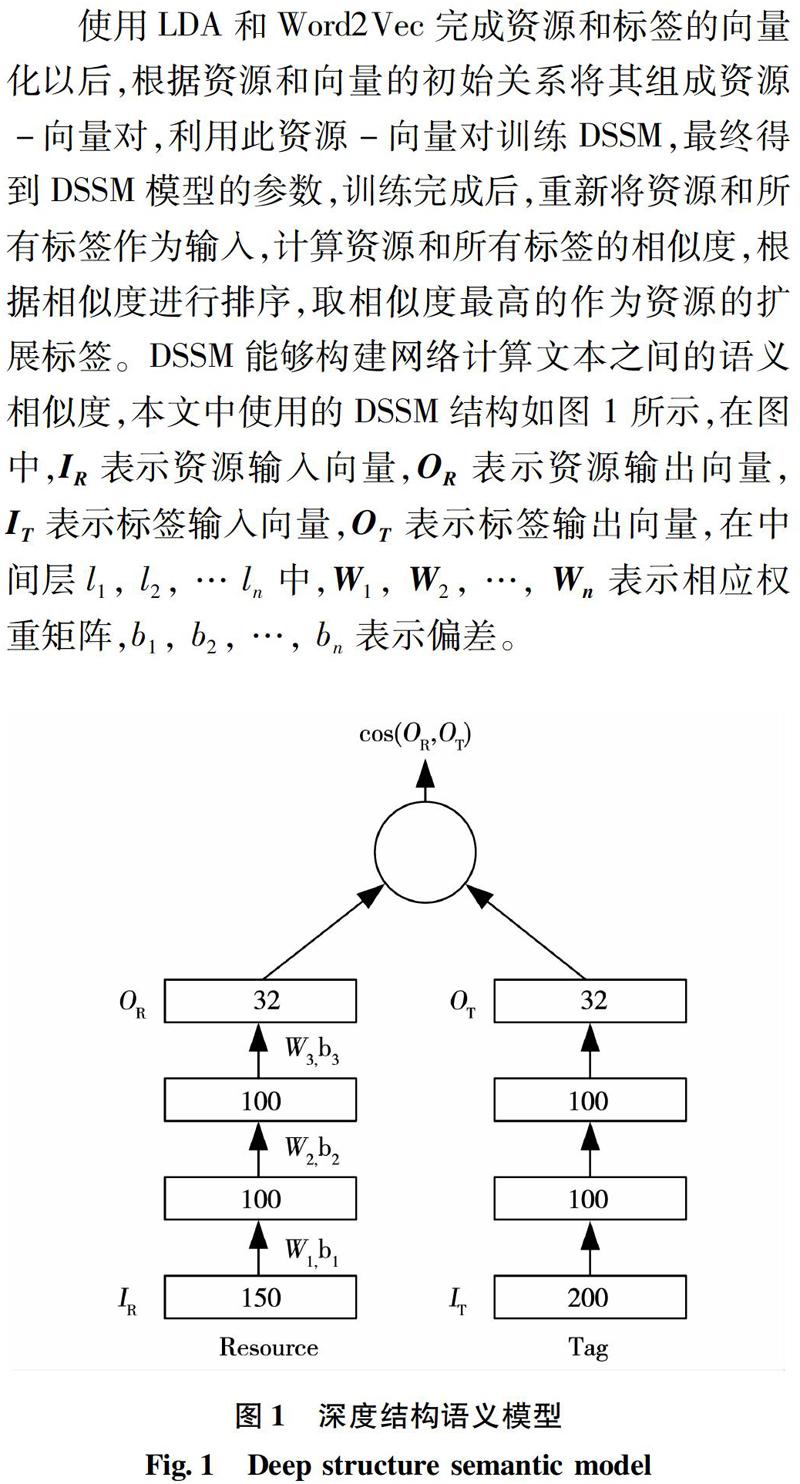
使用LDA和Word2Vec完成资源和标签的向量化以后,根据资源和向量的初始关系将其组成资源-向量对,利用此资源-向量对训练DSSM,最终得到DSSM模型的参数,训练完成后,重新将资源和所有标签作为输入,计算资源和所有标签的相似度,根据相似度进行排序,取相似度最高的作为资源的扩展标签。DSSM能够构建网络计算文本之间的语义相似度,本文中使用的DSSM结构如图 1所示,在图中,IR表示资源输入向量,OR表示资源输出向量,IT表示标签输入向量,OT表示标签输出向量,在中间层l1, l2, … ln中,W1, W2, …, Wn表示相应权重矩阵,b1, b2, …, bn表示偏差。
在训练过程中,使用了梯度下降法进行迭代,训练过程如下:
步骤1):输入:N=迭代次数
RA=资源网络初始结构参数, TA=标签网络初始结构参数
RD=资源输入向量, TD=标签输入向量
WR=资源初始权重矩阵, WT=标签初始权重矩阵
步骤3):对RA,TA,WR,WT进行初始化
步骤4):For n=1:N
步骤5):NR←RD
步骤6):NT←TD
步骤7):使用NR和NT对WR和WT进行更新
步骤8):End
步骤9):输出: WR=资源权重矩阵, WT=标签权重矩阵
4 实验
在此部分中,阐述了实验过程。包括实验环境、实验数据、评估指标、对比算法、实验步骤、实验结果和分析。
4.1 实验环境
在实验中,硬件环境为Intel Core i7 6700+NVIDIA GeForce GTX 1080。软件环境为PyCharm+TensorFlow 1.4.0。PyCharm是一款Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。TensorFlow是一个以数据流图计算单元的开源软件库,图的节点代表数学运算,图的边代表多维数组(张量),这种结构使得用户能够不用重复代码就将计算任务部署在计算机或服务器的多个CPU或者GPU上,在本文中我们使用了TensorFlow中现成的模块和工具。
4.2 实验数据
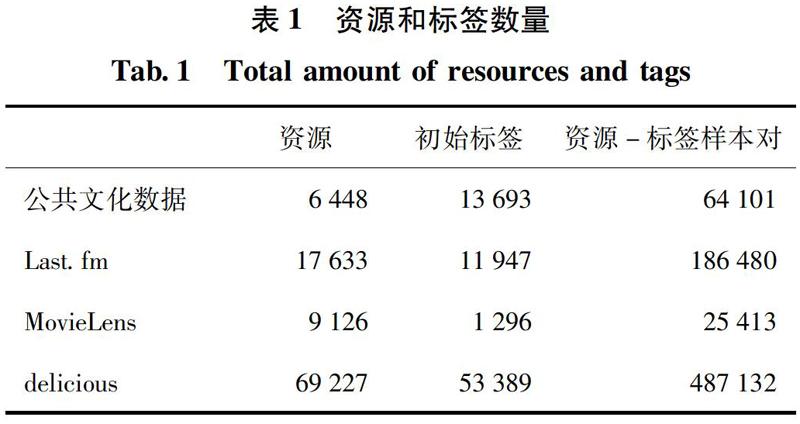
使用的数据除了公共文化数据之外,还包括Last.fm数据集、MovieLens数据集和delicious数据集,公共文化数据来自于相关项目的大数据平台,数据包括公共数字文化相关资源数据和其所对应的初始标签,公共文化资源包括文化视频的文本描述,博物馆藏品介绍,文化相关书籍介绍等。Last.fm数据集包括音乐作者信息和用户对作者的手动标注的标签,MovieLens数据集包括电影信息和其对应的初始标签,delicious数据集包括书签信息和对应的初始标签,各数据集的资源和标签数量如表1所示。
对于数据中的资源,使用收集到的公共数字文化资源和另外三种公开数据集分别对LDA模型进行训练,分别获取在每种数据集下每个资源文档的概率分布和模型的参数。训练完成后,可以根据模型的参数计算出每个主题相对于资源文档的条件概率p(topic|doc),资源向量每一维的数值即为此条件概率的值。对于新的资源,根据训练好的参数直接为其生成资源向量。
对于初始标签,为了能够生成初始标签的向量表示,提取了百度百科中的几乎所有(864,705)词条构建语料库,然后将初始标签中不存在于此语料库中的词添加进去,语料库中词语最终数量达到872,705,使用此语料库对CBOW模型进行训练,训练完成后,这些词语被映射到同一个向量空间中,同时得到这些词语的向量表示,我们在此结果中对公共文化数据和其它公开数据集中的初始标签进行搜索,找到初始标签和其对应的向量表示。
4.3 评估指标
为了对算法的性能进行度量,使用以下几种评估指标。
平均排序倒数(mean reciprocal rank, MRR),计算排序后的标签中被正确排序的标签的序列倒数在整个测试数据中的平均值。MRR的计算方法如下:
其中R(tag)表示扩展后的标签在初始标签集中的位置。
精度(Precision),计算初始标签在扩展后标签中所占的比重。精度的计算方法如下:
其中σ(R(tag)≤N)为指示函数,表示当R(tag)≤N是返回1,否则返回0。在实验中使用了P@1和P@5两种指标。
平均准确率(mean average precision, MAP),计算资源的标签扩展准确率的平均值。平均准确率的计算方法为:
归一化折损累计增益(normalized discounted cumulative gain, NDCG),计算公式为:
4.4 对比算法
将实验的结果和常用标签扩展算法进行了对比,参与对比的标签扩展算法有TF-IDF[18],TextRank[19-20],N-gram[9,13],基于LDA的关键词提取[15],TPR [13-15]。
TF-IDF是一种用于提取文本关键词的常用技术,通过统计单词的词频(term frequency)和逆文档频率(inverse document frequency),并将结果相乘的方式计算单词的重要程度,词频表示单词在文档中出现的频率,逆文档频率和包含单词的文档数有关,包含单词的文档数越多,逆文档频率越高,說明单词有很好的类别区分能力。TextRank是一种基于图的排序算法,通过把文本分割成不同的单元单词并建立图模型,利用投票机制对文本中的单词进行排序,取票数最多的单词为文本的标签,TextRank的优点是不需要实现对文档进行学习训练,并且计算较为简便,因而使用较为广泛。N-gram的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成长度为N的字节片段序列。每一个字节片段称为gram,对所有的gram的出现次数进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,最终以频率最高的gram作为提取出的标签。基于LDA的关键词提取首先使用文本集对LDA模型进行训练,完成训练后得到一篇文章的主题分布和文章中词的主题分布,然后通过KL散度来计算这两个分布的相似性。如果文章的某一主题z的概率很大,而该文章中某个词对于该主题z也拥有更大的概率,那么该词就会有非常大的概率成为扩展的标签。TPR是LDA与TextRank相结合的方法,其思想是文本的每个主题单独运行各自的带偏好的TextRank,每个主题的TextRank都会偏好与该主题有相关度较大的词,对于每个主题z,根据LDA的训练都可以得到每个主题下的词的分布,可以把每个词的概率值单做该主题下Textrank的跳转概率来计算,从而优化每个词的得分。
4.5 实验步骤
在实验中,我们首先使用了LDA和Word2Vec生成资源和标签的表示向量,然后使用初始的资源-标签对训练DSSM模型,资源向量和标签向量的维度分别为200和150。训练完成后,我们计算每个资源和所有标签的相似度,然后根据相似度由高到低对标签进行排序,取前N个相似度最高的标签作为资源的扩展标签,图2表示这一过程。
从图中可以看出,实验包括3个步骤,第一步是分别使用LDA和Word2Vec对资源和初始向量进行处理,向量化后的资源和标签维度分别为200和150。第二步是使用资源和初始标签的表示向量对DSSM模型进行训练,实验中采用的DSSM网络层数和每一层的节点数如表2所示。
模型训练完成后,可以计算给定标签的资源概率,给定标签的资源的先验概率通过softmax函数进行计算。
其中γ为平滑因子,通常由经验给出。资源和标签之间的cos相似度,可以用以下公式进行计算。
最终收敛后,WR和WT都为近似的最优解,同时得到模型的参数结构。
对于每个资源-标签对,使用(R,T+)去代替(R,T),其中T+为初始标签,获取模型参数的目标函数为最大化给定标签的资源的似然:
第三步是使用训练好的网络对资源进行标签扩展,在这一步中,网络的参数固定,对数据集中的每一个资源,将其向量分别和所有初始标签向量作为输入,计算它们之间的相似度,然后根据资源和所有初始标签的相似度的大小对初始标签进行排序,取前N个标签作为资源的扩展标签,分别取N为10、20、30、40、50进行了实验。
4.6 实验结果和分析
在各个数据集上都用本文所提出的方法和对比算法进行了实验,当扩展标签数量N=20时,在不同数据集上各指标的实验结果如表3所示。
分析实验结果,可以看出在公共文化数据集和其它公开数据集上,DSSM标签扩展的结果在P@1,P@5,MAP上明显优于TF-IDF、TextRank、N-gram、LDA,这是因为DSSM是通过提取资源和标签的特征,计算它们之间的相似度的方式进行标签扩展,能够挖掘出资源与标签之间的深层信息,并且能够以整个初始标签作为备选库进行标签扩展。而TF-IDF、TextRank、N-gram是通过计算资源中词语的重要程度,然后排序的方式提取标签,词语和资源之间没有联系,同时备选库较少,所以扩展的精度不如DSSM。LDA虽然采用提取主题的方式进行标签扩展,但是也没有考虑资源和初始标签之间的关系,所以结果也低于DSSM。而融合了TextRank和LDA的TPR在精度的表現上则与DSSM相当,说明在既考虑到单词重要性又进行主题提取的情况下,标签扩展的准确率能够得到显著改善。在MRR的表现上,可以看出在公共文化数据集上DSSM的MRR值略优于其它算法,而其它公开数据集上DSSM的MRR值并不突出,这表明DSSM在中文数据集中有一定的优势,比较适合于中文资源的标签扩展,其原因可能是因为在对初始标签进行向量化时,Word2Vec的训练集中的中文词汇较多所致。在NDCG@3的表现上,DSSM和其它算法并无显著差异。
同时,分别取标签扩展数量N为10、20、30、40、50进行了实验,不同N在各数据集上的MAP结果如表4所示。
从结果来看,总体上标签扩展精度随N的增加而增加,但当N达到一定数量时,精度不再增加,这是因为资源的初始标签数量有限,当扩展标签数量持续增加时,不能提供更加完善的对比。
在各个数据集上,本文所使用方法在总体上优于其它标签扩展方法。
5 结 论
讨论了使用深度结构语义模型进行标签扩展的可能性,通过实验和比较,对于所使用的各数据集,MRR值和精度能够优于实验中采用的其它对比算法,证明本文所提出方法在标签扩展方向的优势,在实际应用中,通过本文扩展的标签在后续的使用中被认为是非常有效的。
我们未来的工作中,在以下方面将进行扩展研究,首先是数据的数量不是特别充分,未来还会在更大的数据集上对所提出方法进行验证。其次,扩展标签优劣程度还需要更加系统的进行衡量。
参 考 文 献:
[1] LEI Zhiwen, YANG Yi, HUANG Weixing, et al. Tag Recommendation for Cultural Resources[C]// 2018 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Lisbon, 2018: 566.
[2] SOODS C, HAMMOND K J, OWSLEY S H, et al. TagAssist: Automatic Tag Suggestion for Blog Posts[C]// ICWSM, Colorado, USA, Mar 26-28, 2007.
[3] BELEM, FABIANO, EDER MARTINS, et al. Associative Tag Recommendation Exploiting Multiple Textual Features[C]// Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 2011. 1033.
[4] HUANG Posen, HE Xiaodong, GAO Jianfeng, et al. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data[C]// Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management, ACM, 2013: 2333.
[5] NISHIDA KYOSUKE, FUJIMURA KO. Hierarchical Auto-tagging: Organizing Q&A Knowledge for Everyone[C]// Proceedings of the 19th ACM International Conference on Information and Knowledge Management, ACM, 2010: 1657.
[6] CHIRITA, PAUL-ALEXANDRU, STEFANIA COSTACHE, et al. P-tag: Large Scale Automatic Generation of Personalized Annotation Tags for the Web[C]// Proceedings of the 16th International Conference on World Wide Web, ACM, 2007: 845.
[7] DIAZ-AVILES, ERNESTO, MIHAI GEORGESCU, et al. Lda for On-the-fly Auto Tagging[C]// Proceedings of the Fourth ACM Conference on Recommender Systems, ACM, 2010: 309.
[8] SI Xiance, SUN Maosong. Tag-LDA for Scalable Real-time Tag Recommendation[J].Journal of Information&Computational Science, 2009, 6(2): 1009.
[9] HARA SUNAO, KITAOKA NORIHIDE, TAKEDA KAZUYA. On-line Detection of Task Incompletion for Spoken Dialog Systems Using Utterance and Behavior Tag N-gram Vectors[C]// Proceedings of the Paralinguistic Information and its Integration in Spoken Dialogue Systems Workshop. Springer, New York, 2011: 215.
[10]SKOUTAS, DIMITRIOS, MOHAMMAD ALRIFAI. Ranking Tags in Resource Collections[C]// Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2011: 1207.
[11]ZHANG Hongbin, JI Donghong, YIN Lan, et al. Product Image Sentence Annotation Based on Kernel Descriptors and Tag-rank[J]. Journal of Southeast University, 2016, 32(2): 170.
[12]FRIGYIK B, KAPILA A, GUPTA R. Introduction to the Dirichlet Distribution and Related Processes[R]. Department of Electrical Engineering, University of Washignton, Uweetr-2010-0006, 2010.
[13]CHEN LINCHIH. An Effective LDA-based Time Topic Model to Improve Blog Search Performance[J].Information Processing & Management, 2017, 53(6): 1299.
[14]PAVLINEK MIHA, PODGORELEC VILI. Text Classification Method Based on Self-training and LDA Topic Models[J].Expert Systems with Applications, 2017, 80: 83.
[15]LU Yue, MEI Qiaozhu, ZHAI Chengxiang. Investigating Task Performance of Probabilistic Topic Models: An Empirical Study of PLSA and LDA[J].Information Retrieval, 2011, 14(2): 178.
[16]LE QUOC, MIKOLOV TOMAS. Distributed Representations of Sentences and Documents[C]// International Conference on Machine Learning, 2014: 1188.
[17]MIKOLOV TOMAS, TOMAS, CHEN Kai, GREG CORRADO, et al. Efficient Estimation of Word Representations in Vector Space[C]// arXiv Preprint arXiv:1301.3781, 2013.
[18]HUANG Chenghui, YIN Jian, HOU Fang. A Text Similarity Measurement Combining Word Semantic Information with TF-IDF Method[J].Jisuanji Xuebao(Chinese Journal of Computers), 2011, 34(5): 856.
[19]李鵬,王斌,石志伟,等. Tag-TextRank:一种基于Tag的网页关键词抽取方法[C]// 全国信息检索学术会议,2010:456.
LI Peng, WANG Bin, SHI Zhiwei, et al. Tag-TextRank: A Tag-Based Keyword Extraction Method[C]. National Conference on Information Retrieval, 2010:456.
[20]LI Peng, WANG Bin, SHI Zhiwei, et al. Tag-TextRank: A Webpage Keyword Extraction Method Based on Tags[J].Journal of Computer Research and Development, 2012, 49(11): 2344.
(编辑:温泽宇)
