
基于小型化YOLOv3的实时车辆检测及跟踪算法
2020-08-26 06:45许小伟陈乾坤李浩东唐志鹏
公路交通科技 2020年8期
许小伟,陈乾坤,钱 枫,李浩东,唐志鹏
(武汉科技大学 汽车与交通工程学院,湖北 武汉 430081)
0 引言
随着汽车保有量的快速增长,大量学者对高级辅助驾驶系统(Advanced Driver Assistance Systems,ADAS)展开了深入研究,车辆检测已经成为了ADAS研究中的一个重点[1-2],对前方道路车辆的有效检测及跟踪,是安全辅助驾驶系统做出判断和预警的重要组成部分,而对检测算法模型的小型化成为车载嵌入式设备快速、实时运行的前提与手段。
基于传统方法的目标检测算法中,通过人工设计梯度直方图(Histogram of gradient,HOG)[3]、尺度不变特征变换(Scale-invariant feature transform,SIFT)[4]、哈尔特征Haar-like[5]等特征提取器来提取目标特征,再输入到支持向量机(Support vector machine,SVM)[6-7],迭代器AdaBoost[8-9]、随机森林(Random Forest,RF)[10]等分类器中进行分类识别。但是传统人工设计的特征泛化性差,不同场景需要设计选择不同的特征,提取出合理特征难度较大,运算复杂度高,限制了实际应用[11]。
基于深度学习的检测算法可以分为基于区域法和基于回归法两种。基于区域的方法通过选择性搜索(selective search)算法来生成候选区域,再使用卷积神经网络进行分类处理,主要方法有R-CNN[12],Fast R-CNN[13],Faster R-CNN[14-15],Massk R-CNN[16],SPP-Net[17]等。此种基于区域的方法分两步进行检测,检测精度高,但存在网络复杂,检测速度慢的缺点。基于回归法的方法如SSD[18]、YOLO[19]把目标检测问题当成回归问题,可直接回归出物体类别概率及坐标位置。采用基于回归的YOLO系列算法处理速度快,正确率高,在实际工业部署中得到了广泛应用[20]。YOLOv2[11,21],YOLOv3[22]在YOLO算法的基础上进一步改进,使得检测效果进一步加强。但速度较快的基于回归的检测算法网络结构仍然较大,移植部署到实车嵌入式设备的运行速度较慢,实际部署成本高。
针对以上目标检测网络检测精度与检测速度相矛盾问题,本研究提出一种改进的YOLOv3网络采用K-means++算法聚类来提取先验框,通过构建残差网络层数更少、网络深度更浅的基础网络结构来将卷积模型小型化,同时利用不同的尺度卷积特征多层次提取车辆特征信息来保证精度,解决网络模型大、精度不高的问题。通过卡尔曼跟踪算法和匈牙利算法进行数据关联,实现对多个目标的精确定位与跟踪。在保证准确性的前提下,小型化了网络模型,提高了检测速度,保证了车辆检测时对准确性以及实时性的要求。
1 车辆检测及跟踪算法流程
本研究设计的小型化网络车辆检测及测距流程如图1所示。首先改进YOLOv3结构的骨干Darknet-53网络,构建了一种网络层次较浅、速度较快的检测网络结构,并对此网络进行训练学习,用该网络模型确定前方车辆在图像中的位置信息,实现前方车辆的快速检测。其次利用卡尔曼滤波对下一时刻的车辆位置进行预测,并采用匈牙利分配算法关联视频相邻帧中的车辆,实现车辆的稳定检测。

图1 车辆检测及跟踪流程图Fig.1 Flowchart of vehicle detection and tracking
2 YOLOv3深度网络模型原理及小型化改进
2.1 YOLOv3基本原理及流程
YOLOv3采用类特征金字塔网络(Feature Pyramid Networks,FPN)[23]的多尺度变换和类ResNet的残差网络,设计了分类网络基础模型Darknet-53[24]。此网络同时具有较快的检测速度以及较小的网络复杂度,相比于常用的VGG-16基础特征提取网络降低了模型运算量[25]。
Darknet-53通过多层卷积核卷积形成深层次卷积层。在不同卷积层上分别采用1,2,8,8,4多个类ResNet的残差网络跳层连接,将残差网络经过多次卷积后与原始残差网络进行叠加,保证了残差网络在较深的情况下,仍能较好收敛。同时采用类FPN的多尺度变化预测的方法,利用3个尺度进行检测,最终网络输出3个不同尺度的特征图,在不同尺度特征图上分别使用3个不同的先验框anchors进行预测识别,最终使得远近大小目标均能得到较好的检测。

图2 小型化YOLOv3网络模型结构Fig.2 Miniaturized YOLOv3 network model structure
2.2 针对小型化目标检测的网络结构设计
YOLOv3中有较多的残差结构以及1×1,3×3的卷积层,为了满足ADAS系统的实时性需求,需进一步减小网络层数、使网络小型化,加快网络运行速度。对YOLOv3网络结构进行修改,不再采用Darknet-53为骨干网络,而是借鉴和darknet19类似的YOLOv3-tiny的结构,主干网络采用一个7层的Conv卷积层,在每一Conv卷积层的残差网络结构中,采用更少的重复残差单元,通过减少卷积层,以降低网络深度。
改进提出的小型化YOLOv3网络结构如图2所示。网络输入尺寸为416×416×3,采用一个包含16个3×3卷积核的卷积层对输入网络进行初步特征提取。特征卷积提取公式为:
(1)
式中,ai,j为新生成特征提取层坐标为(i,j)的值;wd,m,n为第d层F×F卷积核的坐标为(m,n)的值;xd,i+m,j+n为输入第d层坐标为(i+m,j+n)的值;wb表示卷积核的偏置项。
将上一层提取得到的特征层网络输出作为下一层的输入,然后采用32个步长为2的3×3卷积核进行滤波,并且采用一个残差块来加强网络特征提取,如图3所示,该残差块由16个1×1的卷积核和32个3×3的卷积核连接构成。残差网络公式为:
Outputlayer=H(Inputlayer)+Inputlayer,
(2)
式中,Inputlayer为类ResNet的残差网络的输入层;H(Inputlayer)为将Inputlayer的输入层进行多次卷积操作;Outputlayer为残差网络的输出层。

图3 残差块结构Fig.3 Residual block structure
采用相同原理方法,对后续的网络结构分别依次采用64,128,256,512,1 024个步长为2的3×3卷积核进行滤波,使特征提取层长宽变小深度变深,能提取到更深层次特征。同时对后续的前4个不同卷积核分别依次采用2,2,4,4个残差块进行连接,加强特征提取,同时也因相较于YOLOv3减少了大量网络层数,小型化了网络结构,可加快学习和网络正向推理运行速度。
将大小为52×52,26×26,13×13的特征提取卷积层,共3层单独提取出来,他们的深度分别为128,256,1 024。对13×13特征层依次采用512个1×1卷积核、1 024个3×3卷积核、18个1×1卷积核进行卷积,使特征层网络输入为13×13×18。多次采用1×1卷积核的可以对卷积层进行降维,减少卷积核通道数,增加非线性激励,提升网络表达能力。13×13的特征提取层不仅单独输出给后续函数进行预测计算,同时将13×13的特征提取卷积层的信息通过上采样的方式放大到26×26大小,并与原有的26×26特征层相连接,对26×26层进行卷积后同时进行输出。原有的26×26层也采用相同方式与52×52相连接进行输出,以此得到多尺度的特征提取。采用多尺度特征提取的方式,可在网络小型化的基础上,仍能提取到较多待检目标卷积层信息,保证了小型化网络目标检测的精度。
每一个输出尺度都采用3个不同的先验框进行预测,先验框尺寸是在数据集上通过聚类得到,由于K-means聚类算法对初始点选取较为敏感,需多次聚类得到较优解。本研究提出采用K-means++算法[26]计算聚类,K-means++算法在初始点选择进行改进,能使聚类中心之间距离尽可能的远。K-menas++算法关键步骤如下:
(1)从数据集中随机抽取一个样本作为初始聚类中心u1。
(2)计算数据X每个样本x1与最近聚类中心距离D(xi)。
D(xi)=argmin|xi-ur|2,
(3)
式中,r=1, 2,…,kselected。
(4)重复步骤(2)、(3)步直至选出k个聚类中心。
依据聚类中心得到9个先验框后,其中较大的52×52特征提取卷积层上采用较小的3个先验框,有最大的感受野,中等的26×26特征提取卷积层上采用中等的3个先验框,较小的13×13特征提取卷积层上采用较大的3个先验框,有最小的感受野,并使用logistic回归函数对不同尺度上的每个先验框进行置信度回归,并预测出物体边框值,根据置信度选出最合适的目标类别区域。logistic回归函数预测公式为:
(4)
式中,cx,cy为网格的坐标偏移量;pw,ph为先验框长宽的边长;tx,ty,tw,th为深度网络学习的目标值;bx,by,bw,bh为最终通过公式计算得到的预测边框的坐标值。
3 车辆跟踪
在车辆行驶道路中由于摄像头采集的前方路况信息会因其他车辆、物体的干扰遮挡和角度、光照、天气等因素的影响而发生变化,从而导致深度学习检测算法出现检测不连续、漏检的情况,继而影响后续车辆测距,本研究对检测到的车辆运动进行跟踪处理。为解决遮挡、光照变化可能导致的跟踪失踪问题,提高多目标跟踪的准确率,在采用卡尔曼滤波跟踪框架的基础上,考虑到同时跟踪多个车辆目标、多个目标在图像上的坐标位置靠近,加入匈牙利算法进行目标关联,能实现对多个目标的精确定位与跟踪。跟踪算法具体流程如下:
(1)卡尔曼预测,即卡尔曼滤波算法根据上一时刻检测出的车辆坐标位置预测出目标在本时刻的坐标位置。首先根据深度学习检测算法检得到的车辆框坐标计算出被检测物体质心坐标(x,y),将此坐标表示为目标当前状态Xt|t,Xt-1|t-1为上一时刻目标状态,Xt|t-1为上一时刻预测出当前时刻的目标状态,观测状态Zt为实际检测到的物体质心坐标,Pt|t为当前时刻估计误差协方差,Pt-1|t-1为上一时刻估计误差协方差,Pt|t-1标识上一时刻预测出当前时刻的估计误差协方差。A为状态转移矩阵,H为观测矩阵,Kt为卡尔曼滤波的增益矩阵,Wt-1|t-1为上一时刻的激励噪声,Q、R分别为激励噪声和观测噪声的协方差矩阵。卡尔曼滤波跟踪具体公式为:
Xt|t-1=AXt-1|t-1+Wt-1|t-1,
(5)
Pt|t-1=APt-1|t-1AT+Wt-1|t-1,
(6)
Xt|t=Xt|t-1+Kt(Zt-Xt-1|t-1),
(7)
Pt|t=Pt|t-1-KtHPt|t-1,
(8)
Kt=Pt|t-1HT(HPt|t-1HT+R)-1。
(9)
利用公式(5),(6)来预测上一时刻检测到的车辆在当前时刻的位置,利用公式(7),(8),(9)来跟新卡尔曼滤波器状态。

图4 实车检测结果对比Fig.4 Comparison of real vehicle detection results
(2)匈牙利最优匹配算法,进行关联匹配时,采用计算两不同集合坐标的欧几里得距离作为费用矩阵,再采用匈牙利算法进行特征关联,即为求解不同上一时刻预测质心坐标与本时刻检测坐标的欧几里得距离的最小值dmin,对上一时刻预测坐标和本时刻检测坐标进行指派关联。欧式距离计算具体公式为:
(10)

当本时刻的检测值未被分配到任何上一时刻预测值时,即上一时刻预测坐标数量小于本时刻检测坐标数量时,则将此检测值作为新目标进行跟踪。具体公式如下:
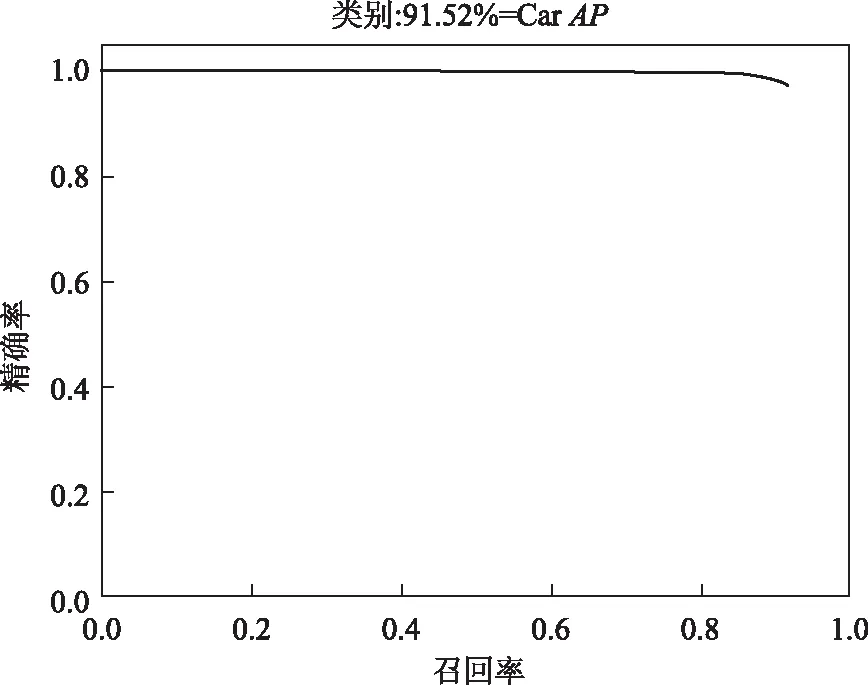
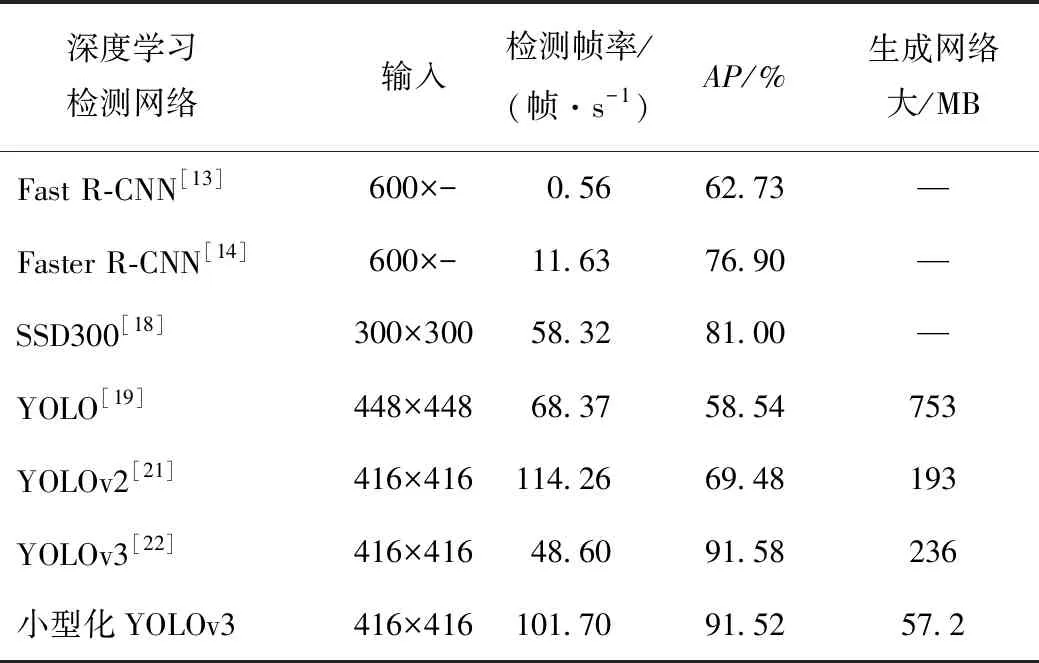
nt-1 (11) 式中,t-1时刻的预测坐标数量为nt-1,t时刻的实际检测坐标数量为nt。 在实际跟踪情况中,考虑到漏检、跟踪失效的情况,当计算的欧几里得距离超过设置的阈值时或者多帧未成功检测到该车辆物体,则判定为跟踪丢失。具体公式如下: f>fmax∨d>dmax, (12) 式中,f为未连续检测到目标帧数;fmax为目标最大丢失帧数;d为欧几里得距离;dmax为最大距离阈值。 算法基于python编译环境完成程序设计,运行环境为CPU:i5-8500,GPU:NVIDIA GTX 2080,8G内存。本研究试验分为检测算法试验与跟踪算法试验。 在自采集道路行车视频以及公开的数据集KITTI上评估改进YOLOv3方法的性能。为验证实际检测效果,以某标志408车型在武汉多段道路采集的视频对改进的小型化网络检测算法进行验证。图4为不同环境下检测结果。 图4中目标车辆上方显示的为目标类别及置信度。可以看出,小型化改进的YOLOv3检测模型检测精度与原始YOLOv3算法相当,能检测较远目标;在某些情况下优于原YOLOv3算法,能检测原YOLOv3算法未检出车辆,且检测出的目标车辆置信度均高于原始算法。这说明小型化改进的YOLOv3算法在检测精度控制上是有效的。 为进一步准确验证小型化改进YOLOv3算法的先进性及性能,在公开数据集KITTI上进行评估验证。KITTI包含市区、乡村和高速公路等场景采集的真使数据,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集[27]。对KITTI数据集原有的标签信息进行整理,将KITTI的标注格式转为便于改进YOLOv3算法训练的VOC格式,选取该数据集7 481张图像中的Car,Van,Truck和Tram4类车辆标签图片进行保留并合并为Car类标签共4 980 张图像,并把此数据集按照0.9,0.09,0.01的比例分为3部分如表1所示:训练数据集4 482张,测试数据集448张,验证数据集50张。 表1 数据样本数量Tab.1 Number of data samples 对小型化YOLOv3算法进行58 000次训练迭代,动量为0.9,权重衰减为0.000 5,初始学习率为0.001,学习率后期随训练次数而减小。K-means++算法在处理后的KITTI数据集上的聚类中心为:(28,21),(40,31),(55,45),(68,31),(80,62),(103,44),(137,73),(194,116),(311,180)。检测结果如图5所示。 图5 在KITTI测试集不同场景上的检测结果Fig.5 Detection result in different scenarios of KITTI test set 图5为不同交通环境下的检测结果。图5(a)为道路有较多车辆及车辆遮挡场景的城市道路,此场景车辆种类数量多,干扰因素复杂,车辆距离涵盖中近距离;图5(b)为车辆距离较远的高速道路场景,此场景车辆车速较快,车距较远,车辆距离涵盖中远距离;图5(c)为乡村公路场景,此场景树木较多,受光照影响强烈,图像某一区域会过亮或过暗;图5(d)为道路情况复杂的十字路口,含有较多指示杆,含有4个行驶方向车辆。可以看出小型化YOLOv3算法能准确识别远中近距离、遮挡、光照变化强烈、种类数量多等路况复杂场景下的车辆,有较高的检测精度。 为准确评价此小型化网络模型性能、检测速度以及小型化效果,采用绘制此模型在KITTI测试集上的精确率-召回率曲线(Precision Recall,PR)曲线,计算平均准确率(Average Precision,AP)进行评价。PR曲线能同时包含待检测车辆的精确率与召回率两个指标,而AP则是一个能反映全局检测模型性能的指标,通过计算PR曲线的包含面积得到AP,其中交并比iou值设为0.45。AP具体计算公式为: (13) (14) 图6 PR曲线图Fig.6 PR curve 图6为在KITTI测试集上的PR曲线图。通过计算如图6的PR曲线可得到此改进模型对车辆检测的AP为91.52%。为说明本研究检测算法的先进性,与其他算法进行对比,这些算法均使用KITTI数据集进行检测[28]。算法检测结果如表2所示。 表2 不同检测方法在KITTI数据集上的 检测结果对比Tab.2 Comparison of detection results of different detection methods on KITTI data set 表2显示了不同深度学习检测算法在KITTI数据集上的检测结果。经典的基于区域式神经网络Faster R-CNN取得了62.73%的检测AP,Faster R-CNN取得了76.90%的检测AP,同时因基于区域式检测框架将物体识别和定位分为两个步骤完成,导致网络模型较大,检测速度极慢,不具有实时检测能力。经典的基于回归式神经网络SSD300,YOLO,YOLOv2,YOLOv3分别取得了81.00%,58.54%,69.48%,91.58%的检测AP,因为将物体识别和定位放在一个步骤中完成,检测速度较快。虽然 YOLOv2有较快的检测速度达到每秒114.26帧,但是只有69.47%的AP,检测效果较差;YOLOv3的检测精度高,为该YOLO系列最先进算法,有91.52%的AP,但是相应检测速度较低。小型化YOLOv3相较于上述算法,因仍有多层残差网络以及多尺度检测,拥有较高的检测精度,达到91.52%,基本与YOLOv3持平。同时因精简了网络结构,减少了网络参数,生成网络大小从236 MB减小为57.2 MB,为原来1/4,检测速度大大加快,达到每秒101.70帧,检测速度为YOLOv3的两倍以上。可以看出,改进模型检测速度有明显提升,证明改进的小型化网络结构是有效的,同时也达到了较高的检测精度,本研究所提算法有较强先进性。 为验证卡尔曼滤波和匈牙利匹配的多目标跟踪算法的有效性,同以某标志408车型在武汉市区道路拍摄的视频注入跟踪算法进行验证,视频帧率为每秒30.00帧。跟踪算法中按经验设置参数最优值fmax=8,dmax=30。目标出现遮挡无法稳定检测情况下,实际多目标跟踪效果如图7、图8所示。 图8 多目标交叉时的多目标跟踪效果Fig.8 Multi-target tracking effect when multiple targets crossing 图7为连续视频中的3帧图像,从图7(a)可以看出,第33帧时,3台车辆同时被准确检测,并被赋予物体标签ID,在7图(b)第34帧时,右侧栏杆后的车辆因受栏杆遮挡,无法被稳定连续检测,但此时物体标签仍然保留,并继续预测跟踪,直至如图7(c)第37帧所示时,右侧车辆被重新检测,而此时,右侧车辆的物体标签仍然不变。表明本研究跟踪算法能准确跟踪多目标,具有一定的抗遮挡能力,能改善检测算法不稳定的情况。图8为在连续视频中取相同帧间隔截取3张图像,车辆出现相互交叉遮挡,车辆检测算法正确检测,并为目标车辆分配ID值,从图8中可以看出,连续视频帧中目标ID值并未改变,说明本跟踪算法在目标之间交叉干扰的情况下仍能准确跟踪多目标。 为准确评价检测跟踪整体算法的检测精度,借鉴论文[9]的方法,采用检测率DR和误检率FPR来进行评价,检测率的公式计算如下: (15) (16) 式中,TP为被正确检测出的车辆数量;FN为漏检的车辆数量;FP为错误检测成车辆的数量。 选取实车视频采集的图片进行检测率与误检率计算,其中普通道路环境与包含遮挡、阳光阴影等干扰道路环境的比例为4.67∶1,并与其他检测算法进行比较,结果如表3所示。 表3 检测跟踪算法对比Tab.3 Comparison of detection and tracking algorithms 从表3可以看出,本研究检测跟踪算法相比于其他检测算法保持了较高检测率,达到97.50%,依据参考文献[15, 29, 30]的标准,当检测率达到95%以上,能满足实车对检测率的要求。同时,检测速度大幅缩短,为11.3 ms/帧,远低于其他检测算法,并小于采集每秒30帧视频帧率每一帧间隔时间33 ms,满足实时性的要求。当本车行驶速速度为60 km/h时,车辆每行驶0.19 m更新一次前方车辆检测信息;当本车行驶速度为120 km/h时,每0.38 m 更新一次。 基于小型化YOLOv3深度学习网络的实时车辆检测算法,在保证提取多层特征的前提下,采用K-means++算法聚类提取先验框,通过减小残差网络层数、网络深度,改变基础网络结构,达到减少网络参数数量、模型小型化的目的,能加快网络训练、正向推理速度,使深度网络能快速检测车辆位置。试验表明,在复杂道路环境中有较强的鲁棒性,检测速度为每秒101.7帧,计算平均准确率AP为91.52,高于其他深度学习算法,相比与YOLOv3,在精度损失0.06%下,检测速度提高一倍以上,且网络生成模型大小为原来1/4。然后采用卡尔曼滤波进行车辆目标跟踪,并利用匈牙利算法进行数据关联。跟踪算法能确定被检测目标唯一标签ID,能较好实现多目标稳定跟踪,可改善检测不稳定的情况。检测跟踪整体算法的检测率达到97.50%,并且检测速度大幅减小,为11.3 ms/帧。小型化网络检测跟踪算法可以满足实际智能驾驶过程中的车辆检测及跟踪需求。 在后续的研究中,将考虑侧后方车辆检测,弯道测距需求,并将人-车-路环境考虑其中,进行碰撞预警模型的搭建与研究,并形成一个考虑检测帧率、AP、生成网络大小3个参数的检测算法总合评价指标。4 试验设计与验证
4.1 检测算法试验


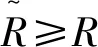
4.2 跟踪算法试验


5 结论
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年15期)2019-08-27
自动化学报(2019年6期)2019-07-23
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中国惯性技术学报(2015年1期)2015-12-19
噪声与振动控制(2015年4期)2015-01-01
中国卫生(2014年7期)2014-11-10
汽车与新动力(2012年5期)2012-03-25
