
基于同态加密的隐私保护推荐算法
2020-08-25 07:03:16刘文超杨晓元周潭平涂广升
郑州大学学报(理学版) 2020年3期
潘 峰, 刘文超, 杨晓元,2, 周潭平,2, 涂广升
(1.武警工程大学 密码工程学院 陕西 西安 710086; 2.网络与信息安全武警部队重点实验室 陕西 西安 710086)
0 引言
互联网技术的进一步发展引起信息过载问题:信息量的大幅增长使用户难以从过量信息中获取所需信息。因此过滤用户不需要的信息成为亟须解决的开放性问题。解决信息超载的一种重要途径是使用搜索引擎,但是存在如必须主动搜索、没有个性化推荐等问题。推荐算法是目前被广泛应用的一种信息过滤的手段,根据用户或者项目(如音乐、商品、视频等)的特征建立模型用以预测用户对其尚未考虑项目的偏好。推荐算法的出现,从大量可用项目中预测了用户需求,使用户有更合适的选择,产生了巨大的经济效益。好的推荐算法能够吸引用户长期使用。因此,推荐算法从用户角度考虑,可以为用户提供个性化的服务,而从服务提供商角度考虑,则能提高用户忠诚度,防止用户流失。
好的推荐系统需要提供个性化和准确的推荐,因此需要尽可能多地掌握用户的个性化信息。用户提供越多的信息,则获得的推荐越准确,但是泄露的隐私信息也就越多,从而导致推荐系统与用户隐私保护之间的矛盾[1]。常见推荐系统的隐私保护方法包括:k-anonymous方法[2]、分布式推荐系统[3]和代理组件[4]等设计架构、同态加密[5]等手段。随着同态加密效率的提高,涌现出许多基于同态加密的研究成果[6-7],使用同态加密来保护推荐系统中的用户隐私将成为一种越来越有前景的方法。
本文提出了一种基于TW16协议的同态隐私保护推荐算法,TW16是文献[8]提出的一种基于好友关系的推荐协议,该协议可以基于用户好友以及陌生人的评分来对用户未评分的项目进行预测,并使用同态加密技术保护用户的隐私。本文在该方案基础上,通过增加活跃用户的评分权值、对参数设置进行优化和增加计算缓存的方法,构造并实现了一种准确高效的基于同态加密的隐私保护推荐协议。
1 推荐算法
本节对基于好友关系的推荐算法和类同态加密方案(somewhat homomorphic encryption,SHE)进行介绍。
X代表数据集,x←X表示从X中随机均匀地选取一个x,|X|表示X的大小。如果χ是一个分布,那么s←χ表示s是从χ分布中抽样得到的。给定两个向量X和Y,使用X·Y表示两个向量的内积,使用‖X‖表示X的欧氏距离。
在推荐算法中,推荐条目集合表示为I=(1,2,…,b,…,M),用户x的评分表示为向量Rx=(rx,1,…,rx,b,…,rx,M),其评分r∈{0,1,2,3,4,5}。如果某个条目i尚未被评分,则其评分值rx,i=0,评分结果为一个矩阵。推荐算法用来预测用户尚未评分的rx,i。
给定两个用户x和y,其对应的评分向量Rx和Ry,余弦相似度定义为
sim(x,y)=(Rx·Ry)/‖Rx‖·‖Ry‖。

本文使用平均绝对误差(mean absolute error,MAE)来衡量推荐算法的推荐是否准确,
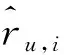
2 基于同态加密的隐私保护推荐算法
在本节中,首先对TW16中描述的推荐算法进行介绍,然后说明对该系统进行的改进和优化。
给定一个用户u和一个陌生人集合Tu,输入陌生人集合Tu对项目b的评价,预测算法定义为
(1)
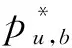
给定一个用户u和一个好友集合Fu,输入好友集合Fu对项目b的评价,预测算法定义为
(2)

(3)
2.1 中心化的单预测协议
推荐算法中有大量的用户参与提供数据,用户之间并不直接联系,故需要一个中心化的服务提供商来沟通参与协议的所有用户,并向请求推荐结果的用户提供服务。系统中存在中心化的服务提供商和大量的用户,用户好友之间可以单向关注也可双向关注,简化的系统架构图如图1。
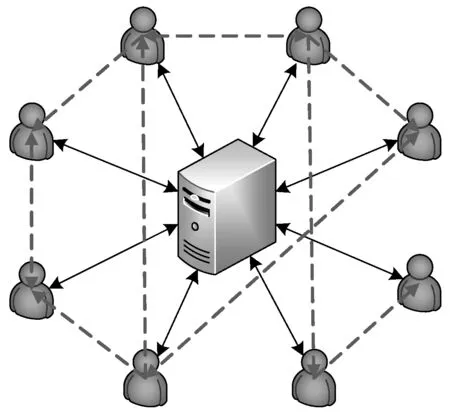
图1 中心化的推荐算法结构图Figure 1 Structure of centralized recommendation algorithm
当用户想要预测某未评分项目b的预测评分时,进行如下协议。
参考上文中的预测算法,协议共分为3个阶段。第1阶段,服务提供商根据公式(1)获取陌生人的加密输入;第2阶段,服务提供商根据公式(2)获取好友的加密输入;第3阶段,用户u根据公式(3)可得知预测结果,而服务提供商没有获取用户隐私信息。
用户u生成二进制向量Ib,第b个元素为1,使用SHE加密算法采用逐比特加密的方式将Ib加密为[Ib]u=Enc(PKu,Ib)=([Ib]u(1),…, [Ib]u(M))并将结果发送到服务器。服务器再将PKu发送至随机选择且愿意参与计算的陌生人集Tu,将[Ib]u转发给Tu中的每个陌生人。每个陌生人t使用PKu和(Rt,Qt),作如下同态运算,
用户u将加密后的权重[wu,f]u=Enc(PKu,wu,f)发送到服务提供商,服务提供商向用户的好友f∈Fu发送[wu,f]u和[Ib]u,f使用PKu,[Ib]u,[wu,f]u和(Rf,Qf)计算
完成后将结果发送给服务提供商。
服务提供商首先计算[nT]u、[dT]u、[nF]u、[dF]u,然后计算[X]u和[Y]u。
服务提供商将结果发回给用户u,u解密后获得结果。
2.2 中心化的前n项预测协议
与单预测协议类似,当用户想获取前n个未评分项目的评分时,进行如下协议。
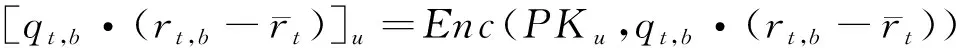
用户u将加密后的权重[wu,f]u=Enc(PKu,wu,f)发送给每个朋友f∈Fu,好友f使用PKu、[wu,f]u和(Rf,Qf)计算
并将结果发回服务提供商。
用户u和服务提供商进行如下交互:用户u生成两个矩阵MX、MY,生成M·M单位矩阵; 随机置换列以获得MY;对于每个项目b,若已被评分,则将MY第b列中的元素1替换为0,得到矩阵MX。用户u逐个元素加密矩阵,并将加密结果[MX]u、[MY]u发送到服务提供商,然后进行计算。
服务提供商首先按照单预测协议中的方法计算[nT]u、[dT]u、[nF]u、[dF]u、[X]u和[Y]u,然后根据公式(3)计算
服务提供商置换密文向量(([X1]u,[Y1]u),([X2]u,[Y2]u),…,([XM]u′[YM]u)):
([U1]u,[U2]u,…,[UM]u)=[MX]u·([X1]u[X2]u,…,[XM]u)T,
([V1]u′[V2]u,…,[VM]u)=[MY]u·([Y1]u′[Y2]u,…,[YM]u)T。
元素之间的加法和乘法以同态运算函数的加法和乘法进行计算,密文矩阵和密文向量的乘法以标准方式进行。服务提供商使用密文上的比较协议,将Ui/Vi(1≤i≤|B|)进行排序。然后服务提供商将Top-n的索引发送给用户u,用户u解密后即可恢复真实的索引。
2.3 去中心化的预测协议

图2 去中心化的推荐算法结构图Figure 2 Structure of decentralized recommendation algorithm
半诚实的服务提供商往往是中心化的预测协议中的弱点,所以可以通过去除中心化的服务提供商,让用户之间进行沟通的方式来减少隐私泄露的可能性。假设所有用户在推荐算法中被唯一标记,并且用户之间共享社交网络图SG。在协议初始化阶段,用户u使用SHE方案生成其公私钥对(PKu,SKu)并公开其公钥以供他人验证。用户u生成其评级向量Ru和社交图SG,并为其每个朋友f∈Fu分配权重wu,f。其他用户也执行相同的操作。在本协议中,用户u的好友的好友(FoF)作为u的陌生人备选集合,系统结构的示意图如图2。去中心化的预测协议计算如下。

陌生人t′收到计算结果后,进行如下运算:
① 同中心化协议类似,计算[nT]u、[dT]u、[nF]u、[dF]u、[X]u和[Y]u;② 计算得到结果。
2.4 安全性分析
在基本安全模型中,假定服务提供者是半诚实的,将遵循协议规范并且不作为用户参与协议。此外,用户信任他的朋友是半诚实的。对于用户之间的通信信道,假设所有通信在完整性和机密性方面受到保护(具有前向保密性)。在最坏情况下的安全模型中,假设某些朋友可能会受到攻击。
本文中的推荐系统在两个模型中都是安全的,所有计算都是在用户u的公钥下以密文形式完成的,并且在协议中服务提供商不为SHE加密方案生成公私钥对,因此,协议避免了密钥恢复攻击。
在给定的安全模型中,推荐系统的信息泄露主要取决于参数α和β的大小以及陌生人集合的大小,若α/(α+β)增大,陌生人集合选择较小,则来自用户好友的信息比重更高,隐私信息更容易泄露。在协议中,用户u不与其他用户进行通信,因此u无法确定某特定用户是否参与计算;每次预测的陌生人集合都是随机选择,所以攻击者无法利用累积的信息进行攻击;用户的评分r∈{0,1,2,3,4,5},因此已知的某个评分不能推断出该评分来自于哪个用户。
3 实验
通过实验对本文所提出的改进与预测算法的准确性进行测试。数据集由MovieTweetings数据集构建而来(https:∥github.com/lux-jwang/Experiments/tree/master/code2016)。MovieTweetings为电影评分数据,本文所用测试数据集为FMT和10-FMT数据集,共包含359 908个评分、35 456个用户和20 156个条目。在FMT数据集中,每个用户至少有1个朋友,每个朋友至少有1个评级;在10-FMT数据集中,每个用户至少有10个朋友,每个朋友至少有10个评级。将每个数据集分为训练集和测试集,其中训练数据占80%,测试数据占20%。表1和表2描述了推荐算法在10-FMT数据集上的MAE值。软硬件环境为:系统为Ubuntu 18.04;处理器为Inter(R)Core(TM)i7-3610QM;内存为8 G。
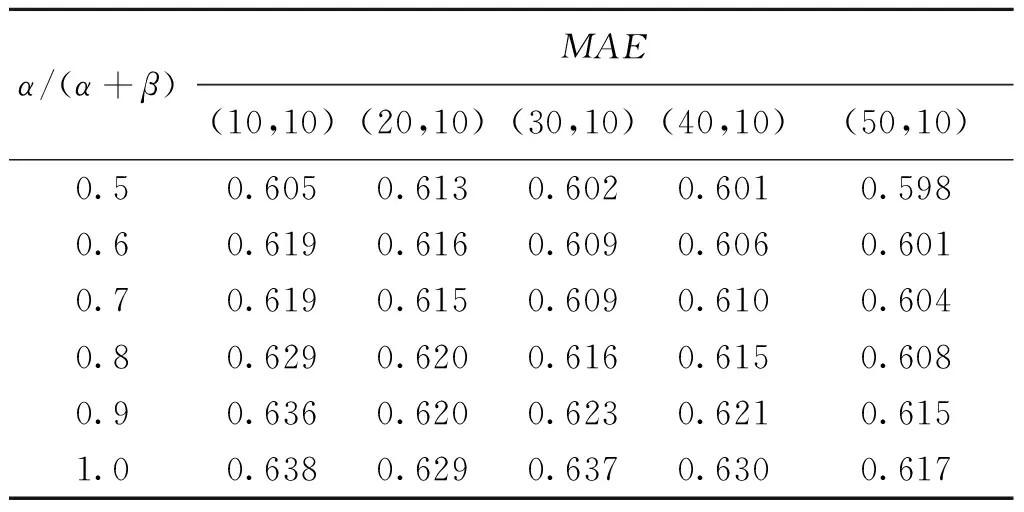
表1 中心化预测算法在10-FMT数据集中的MAE值Table 1 The MAE of the centralized prediction algorithm in the 10-FMT data set
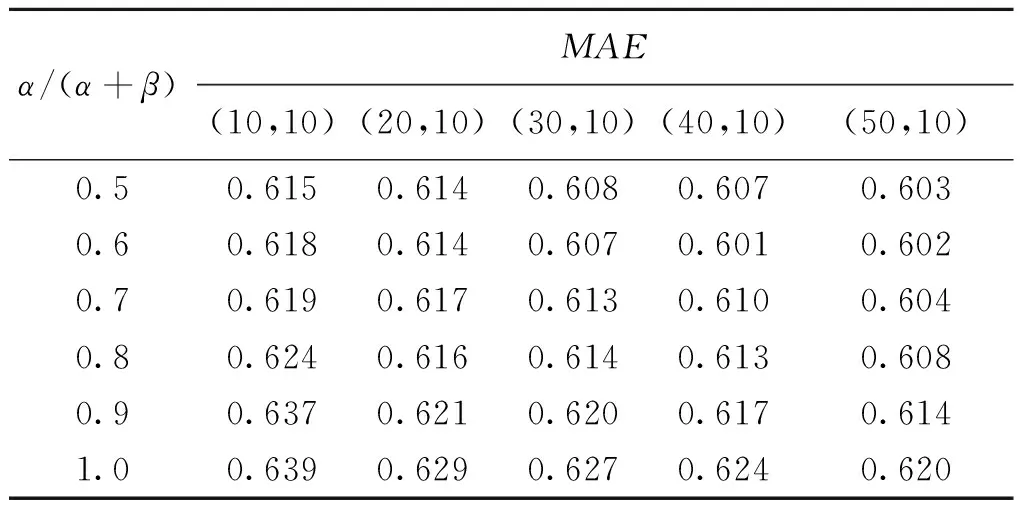
表2 去中心化预测算法在10-FMT数据集中的MAE值Table 2 The MAE of the decentralized prediction algorithm in the 10-FMT data set
首先在数据集中对算法的准确性进行测试。
从表1和表2中可以看出,推荐算法的MAE值随着好友用户参与的比重和用户好友集的增加而减少,预测准确度增加。相比于文献[8]方案,准确率有所提升。
将运算中常用的数据进行缓存,修改传递参数中一些多余的循环方式对代码进行优化,算法的运算效率提升如表3、表4所示。
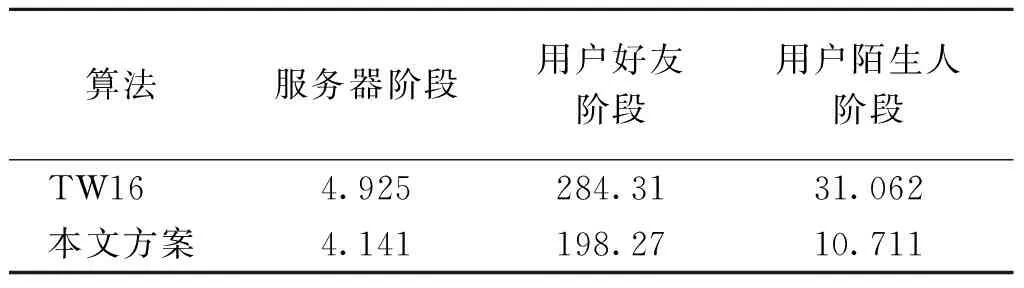
表3 数据处理阶段执行时间Table 3 Data processing time 单位:s

表4 算法运行阶段执行时间Table 4 Algorithm execution time 单位:s
通过实验证明,协议中数据预处理过程和算法执行过程中的效率都得到提升,单预测协议运算时间减少了13.4%,Top-n协议运算时间减少了12.7%。
4 结束语
本文构造并实现了一种准确高效的基于同态加密的隐私保护推荐协议,针对推荐算法中存在隐私泄露问题,在TW16方案基础上,增加活跃用户的评分权值提升推荐协议预测的准确性,对参数设置进行优化,提升协议的效率,并对方案进行实验验证,结果表明推荐算法的准确性和效率均有所提升。今后可对本文的基础同态加密方案进行优化,进一步研究方案效率的提升。
猜你喜欢
吉首大学学报(自然科学版)(2020年2期)2020-09-14 08:15:02
五邑大学学报(自然科学版)(2020年1期)2020-06-17 04:13:04
中国经贸导刊(2020年2期)2020-06-01 07:53:52
计算机世界(2018年36期)2018-10-15 09:29:18
儿童绘本(2017年8期)2017-05-10 18:18:21
软科学(2017年3期)2017-03-31 17:18:32
作文评点报·低幼版(2017年8期)2017-03-11 18:35:29
信息安全研究(2016年3期)2016-12-01 06:06:28
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
小天使·五年级语数英综合(2014年11期)2014-11-06 09:52:39
