
融合语言知识的神经网络中文词义消歧模型
2020-08-25 06:56:40穆玲玲程晓煜昝红英韩英杰
郑州大学学报(理学版) 2020年3期
穆玲玲, 程晓煜, 昝红英, 韩英杰
(郑州大学 信息工程学院 河南 郑州 450001)
0 引言
词义消歧是自然语言处理中的基础任务之一,用于确定目标词在特定上下文语境的词义[1],是信息抽取、机器翻译和阅读理解等任务的基础。词义消歧主要有3种方法:基于知识库的方法、有监督方法和无监督方法。其中有监督词义消歧通常使用传统机器学习模型实现,如支持向量机[2]、最大熵[3]和贝叶斯分类器[4]等,其准确率高于另外2种方法。
目前在有监督词义消歧任务中大量使用了神经网络模型[5],并取得了优于传统统计模型的结果。例如,文献[6-7]分别使用双向长短时记忆网络和多任务学习方法成功实现了词义消歧。基于神经网络的词义消歧方法虽然取得了较好的效果,但其存在以下两个问题:① 需要大规模的标注语料,否则将导致神经网络模型准确率下降。② 没有使用相关的语言知识,忽略了语言学家已建立的丰富资源。有研究表明,在神经网络中融合语言知识有助于提高模型的有效性,可以在保证准确率的前提下,降低模型训练对大规模标注语料的需求。文献[8]在循环神经网络中使用外部语言知识,提高了机器阅读的准确率。文献[9]在神经网络中使用了WordNet的释义信息,利用记忆网络[10-12]建模目标词上下文和释义的内在联系,在英文数据集上取得了非常高的准确率。文献[13-14]分别利用释义和WordNet[15]中的语义增强了词义向量的表示,并将其作为SVM分类器的特征,使得词义消歧的准确率提高了1%以上。文献[16]将WordNet的词根向量化后与GloVe词向量拼接,作为双向长短时记忆网络的输入用于词义消歧。上述研究均是针对英文词义消歧,而中文的神经网络词义消歧中融合语言知识的研究文献尚未被发现。本文在文献[9]基础上,利用外部记忆机制将目标词的释义和例句信息融入神经网络词义消歧模型中,通过注意力机制构建目标词的上下文与由释义和例句表示的词义之间的语义关系。在SemEval-2007中英文词义消歧数据集上的实验结果显示,本文模型的宏平均准确率和微平均准确率均比基线模型有所提高。
1 词义消歧模型
通过双向长短时记忆网络[17]分别实现目标词的上下文表示和目标词的词义表示,目标词词义由释义+例句联合表示,通过注意力机制构建目标词的上下文与词义之间的语义关系。
融合释义、例句信息的词义消歧模型如图1所示,该模型包括上下文表示模块、词义表示模块、记忆模块和打分模块4个部分。
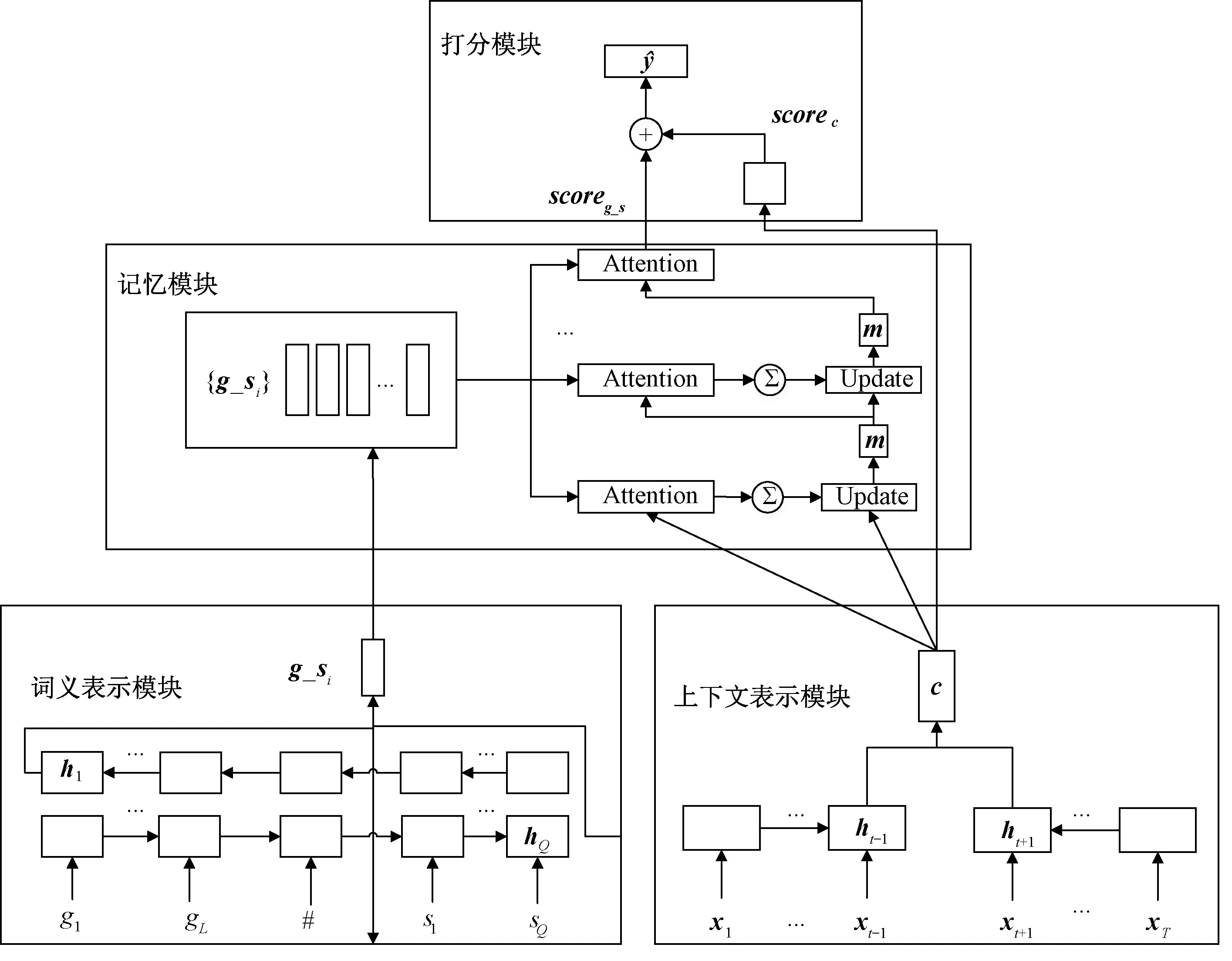
图1 融合释义、例句信息的词义消歧模型Figure 1 A word sense disambiguation model leveraging glosses and example sentences
1.1 上下文表示模块
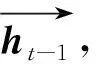
1.2 词义表示模块
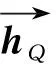
1.3 记忆模块
记忆模块用于建模目标词的上下文向量与词义表示向量的语义关系,提取与上下文相关的词义信息,词义表示由释义、例句联合向量表示。该模块的输入为目标词的上下文向量c及其词义向量集合{g_s1,g_s2,…,g_sN}(N为目标词的词义个数),包括注意力计算和记忆向量更新2个部分,注意力计算建模上下文向量c与词义向量g_s之间的语义信息。为了提高模型对释义、例句以及上下文语义的理解,记忆模块采用多轮注意力计算。在每轮计算后,根据当前计算结果更新记忆向量。
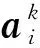

(1)
式中:mk-1是第k-1轮的记忆向量,初始记忆向量m0使用上下文向量c。第一轮计算中,注意力反映的是词义向量和上下文向量的相似度,在以后每一轮的计算中,注意力反映的是词义向量与上一轮记忆向量的相似度。
为了突出正确词义,在每一轮的注意力计算时都加入词义向量。通过计算词义向量的加权累加和来保存记忆状态uk,可以表示为

(2)
根据上一轮的记忆向量mk-1、上下文向量c以及记忆状态uk,采用文献[10]和文献[13]中效果最好的方法更新记忆向量mk,可以表示为
mk=Relu(W[mk-1:uk:c]+b),
(3)
其中“:”为拼接操作。
1.4 打分模块
打分模块根据记忆模块和上下文表示模块的输出,计算目标词各个词义的分布概率。目标词w的第i个词义的分数由记忆模块最后一轮的注意力确定,可以表示为
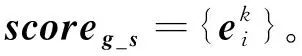
(4)
上下文分数由上下文向量经过全连接层得到,可以表示为
scorec=Wwc+bw,
(5)
式中:Ww和bw是全连接层的权重矩阵和偏置向量。对于每个目标词wt,都有其对应的权重和偏置。
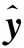

(6)
2 实验数据和方法
2.1 数据集和词典
实验使用的数据集是SemEval-2007 中英文词义消歧数据集[18],该数据集包含2 686条训练语料和935条测试语料,40个用于词义消歧的目标词中包括21个动词和19个名词,平均每个目标词有3个词义。SemEval-2007中文消歧语料的词义来自《汉语语义词典》(CSD)[19]。CSD是北京大学构建的语义词典,其中的“释义”字段为该词语的解释,“备注”字段为用法示例,“word”字段为对应的英文单词或短语。SemEval-2007中词义描述为英文,并且和CSD中的“word”字段对应。本文以“word”字段为词义对齐标记,将CSD中的“释义”和“备注”字段分别作为词义的解释和例句。对于CSD中缺失的释义和例句,根据《现代汉语词典》(DCC)[20]进行补充和完善。补充的释义和例句,使用中科院分词系统NLPIR(https:∥github.com/NLPIR-team/NLPIR)进行分词。
2.2 实验方法
为了验证本文模型的效果,以双向长短时记忆网络(Bi-LSTM)为基线模型,对本文模型进行了消融实验,评价指标使用微平均准确率和宏平均准确率[18]。实验中选用文献[21]训练的300维词向量,在模型训练中随着模型迭代更新词向量。
本文模型以词语作为基本单位,在上下文表示模块中,以目标词为中心,前后窗口分别设置为30个单位;在词义表示模块中,释义+例句的词语长度设置为40个单位。长短时记忆网络设置为1层,包括300个隐藏单元,损失函数为交叉熵。
学习参数设置如下:Batch size为100,droupout为0.5,迭代次数为100,学习率为0.001,学习方法为Momentum。
3 实验结果与分析
3.1 实验结果
Bi-LSTM模型将目标词的上下文作为输入,利用Bi-LSTM+释义、Bi-LSTM+例句、Bi-LSTM+释义+例句方法分别表示Bi-LSTM模型中融合目标词释义、例句以及释义+例句信息。不同方法的实验结果如表1所示。从表1可以看出,本文提出的方法准确率最高。融合语言知识的神经网络模型比仅使用上下文信息的神经网络方法在微平均准确率和宏平均准确率方面均有超过1%的提高。单独使用例句比单独使用释义在两种准确率上均有提高,说明例句的作用比释义更大。
对本文方法和基线方法的消歧结果进行成对样本t检验,P值为0.013,说明本文方法与基线方法的消歧结果存在显著差异。

表1 不同方法的实验结果Table 1 Results of different methods
Bi-LSTM方法与本文方法对每个目标词的消歧准确率对比结果表明,本文提出的消歧模型提高了40%目标词(16/40)的准确率,40%目标词(16/40)的准确率没有变化,20%目标词(8/40)的准确率有所下降。可见,本文方法对大多数目标词的消歧结果有正面的影响。
3.2 释义和例句的作用分析
表2 列举了词义消歧准确率提升或下降幅度较大的目标词。从表2可以看出,Bi-LSTM模型融合释义和例句对名词、动词的词义消歧准确率均有影响。
本文的模型更容易识别出用释义和例句表示的词义与目标词上下文的语义相似度,从而提高了模型的准确率。例如,目标词“叫”在语料中的词义分别为“ask”“name”“call”和“cry”,其对应的释义分别为“使;让,命令”、“称为;是”、“招呼,呼唤;雇”和“人或动物的发音器官发出较大的声音”,对应的例句分别为“~他早点回家/~人操心”、“~他老李/他没~过你/这~聪明/这~莽撞不~勇敢”、“有人~你/~他去睡午觉/你~老何/车子~了”和“~下去/小鸟~着/小鸡会~了/~坏了嗓子可不好”。在例句“去了三天,蚊香厂却停机三天,叫厂里开机一试,却说机器坏了,所以无法检验”中,Bi-LSTM模型将“叫”的词义错误地识别为“name”,而本文模型则正确地识别出其词义为“ask”,这是由于本文方法识别出词义“ask”的释义和例句与该句中目标词的上下文有更高的语义相似度。
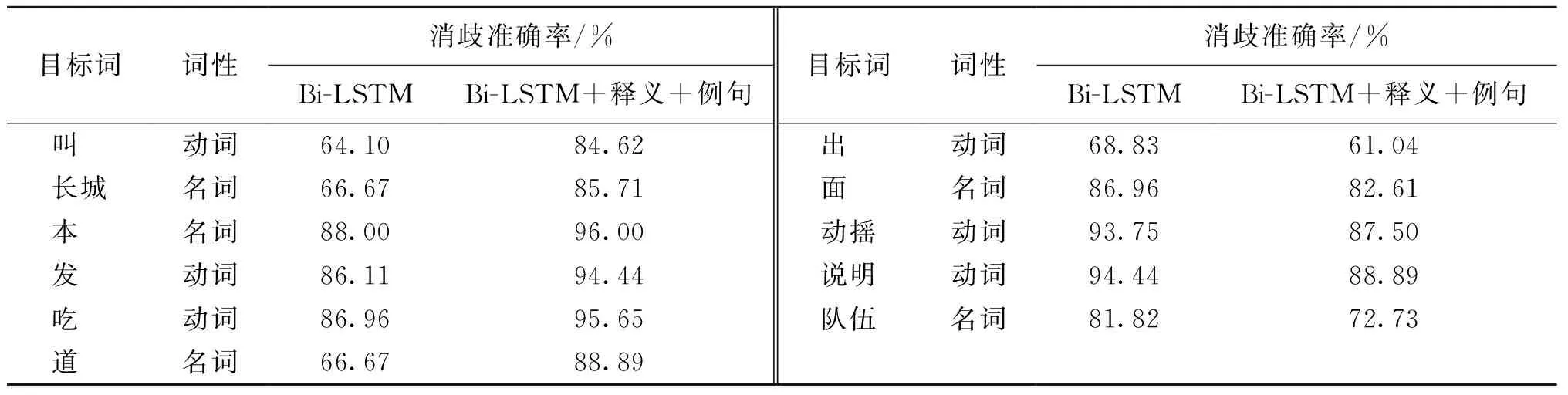
表2 消歧准确率提升或下降幅度较大的目标词Table 2 Target words with higher disambiguation accuracy increase or decrease
外部信息的加入也降低了一些动词和名词的消歧准确率,造成这种情况的主要原因是例句和释义的不完善降低了模型理解词义的能力。例如目标词“出”共有8个词义,其中4个词义缺少例句。目标词“动摇”的第2个词义的释义用其自身解释为“使动摇”,语义信息不明显。这种例句和释义的不完善使模型不能很好地发现释义和例句与目标词上下文的关系。
3.3 注意力计算轮次的影响
对比了记忆模块中注意力计算轮次对消歧准确率的影响,结果如表3所示。从表3可以看出,在3种语言知识添加的方法中,随着注意力计算轮次的增加,准确率大都有所提升。这是因为随着注意力计算轮次的增加,模型提高了正确词义的注意力。当更新轮次达到3次时,3种语言知识添加的方法大都取得了最高的准确率;随后消歧准确率有所下降,说明多轮注意力虽然能更好地反映目标词上下文与其用释义和例句表达的词义之间的语义关系,但是计算轮次并不是越高越好,需要通过实验确定。

表3 注意力计算轮次对消歧准确率的影响Table 3 The effect of attention calculation rounds on disambiguation accuracy
4 小结
本文在神经网络中文词义消歧模型中融合了释义和例句信息,实验结果表明,相对于仅利用上下文信息的神经网络方法,本文模型的宏平均准确率和微平均准确率均提高了约2%,说明在知识指导下的神经网络模型在词义消歧任务中有明显的作用。下一阶段的工作主要包括以下3个方面:第一,利用搜索引擎和已标注的词义语料库[22]扩充例句来提高模型的准确率。第二,改善知识融合方法。本文只是将目标词释义和例句进行简单的拼接,后续的工作可以尝试将释义和例句进行多种方式的结合,把更多的外部知识以及上下文的词性、句法等特征加入到神经网络词义消歧中。第三,完善语言资源的建设。虽然融入语言知识提高了词义消歧的准确率,但是如何解决未登录词以及语言知识不完备的问题还需要进一步的研究。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
少年博览·初中版(2018年12期)2018-01-18 09:17:58
小天使·一年级语数英综合(2016年4期)2016-11-19 10:22:17
小天使·一年级语数英综合(2016年6期)2016-05-14 12:21:05
小天使·一年级语数英综合(2015年10期)2015-10-14 06:30:06
语言与翻译(2014年3期)2014-07-12 10:31:59
