
一种基于序列到序列时空注意力学习的交通流预测模型
2020-08-25 06:57杜圣东李天瑞洪西进
计算机研究与发展 2020年8期
杜圣东 李天瑞 杨 燕 王 浩 谢 鹏 洪西进
1(西南交通大学信息科学与技术学院 成都 610031)2(台湾科技大学计算机科学与信息工程系 台北 10607)(sddu@swjtu.edu.cn)
随着城市化进程的加速发展,交通拥堵、尾气排放等问题导致城市交通管理面临挑战,如何有效预测未来的交通流趋势以提前干预疏导,被认为是智能交通管理决策需解决的关键问题之一[1].一般来讲,观测点采集到的交通流量表示每个时间间隔通过的车辆数量,采集到的流量数据还包括交通速度、通行时间和道路情况等多个属性.由于复杂的交通路网和越来越庞大的车辆数量,通常采集到的与交通流相关的时空序列数据具有数据规模大、高维度、动态性和突变性等特征,因此传统的时间序列分析方法越来越难以对其进行有效建模和预测[2].而且,很多传统的交通流预测模型通常仅限于单步预测,但在实际应用中,需要能提前预测多个时间步长后的交通流量变化情况,这对智能化的交通管理和拥堵分析预警来讲至关重要.
在过去几十年中,许多研究者提出了各种城市交通流量预测方法,并取得了一系列理论和应用研究成果[3].这些研究中的大多数方法主要基于统计模型或浅层机器学习方法来描述交通网络流量的演变,例如ARIMA[4],ANN[5]和SVR[6]等.但是交通流量变化通常会受到出行、天气、事故等因素的影响,而且呈动态变化趋势,因此传统方法面临较大的瓶颈.另外,随着交通大数据的发展,基于物联网技术采集到的真实交通数据通常是多变量时空序列,往往包括多个变量属性,例如交通流量、交通速度、交通密度、交通路程时间(通过时间)等.由于交通状况的快速变化,在非一般性交通流动的情况下(例如高峰时段、事故发生时段等),交通流量预测面临很大的挑战,因为交通流受上述多个变量属性的影响,交通相关时间序列数据通常具有非线性或突变性特点,而且相互影响依赖.如图1所示,仅仅交通流量与通行速度两者就有着非线性相关联系.如何让模型学习到交通时序数据中的多个变量之间的非线性相关特征,对于有效的交通流预测建模来讲十分重要.
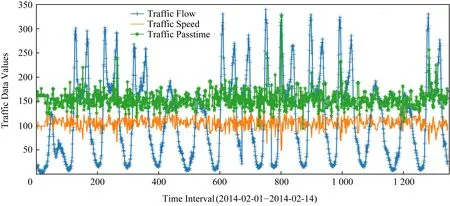
Fig. 1 Nonlinear correlation diagram of multivariate traffic flow related time series data图1 多变量交通流相关时序数据的非线性相关示意图
另外,众所周知,相邻交通网络节点之间的交通状况是相互影响和依赖的,如何分析和利用这种相互依赖性,如图2所示,不同位置采集点的交通流数据存在时空关联性,包括不同采集站点的空间依赖性,和同一采集点在不同时间步下的交通流长时依赖性,这对于提高交通流预测模型的性能也很重要.如何针对上述2个关键点:一个是学习到多变量时空序列之间的非线性相关性特征,另一个是学习到多站点交通流序列之间的时空关联性特征,是所提出的序列到序列时空注意力学习模型要解决的核心问题.
Fig. 2 Spatiotemporal correlation diagram of traffic flow data collected at different locations图2 不同位置采集点的交通流数据时空相关性示意图
深度学习由于其多层非线性映射原理的深度特征抽取学习能力,如在图像处理、语音识别和自然语言处理等多个领域取得突破性进展[7-9].由于不同交通时序数据之间通常存在复杂的非线性时空相关关系,传统方法模型难以挖掘与交通流量相关的各类城市时空序列数据之间的深层关系,而深度学习方法对于交通流预测任务来讲是一个很好的选择,因此也越来越受到研究者们的关注[10-11].这也是为什么提出新型的深度学习模型来进行交通流量预测研究.针对上述2个关键问题,提出了一种基于序列到序列学习结构并结合时空注意力学习机制的深度学习模型.该模型采用序列到序列学习框架,基于卷积LSTM并扩展编码器解码器的时空注意力学习模块,以自动学习多变量交通时空序列数据中的隐含时空表示和长时空依赖相关性深度特征.研究贡献主要包括3个方面:
1) 提出了一种新的基于时空注意力机制的序列到序列端到端深度学习模型,并将其应用于多变量交通时空序列建模任务.通过基于卷积 LSTM和扩展时空注意力模块的编码器,将交通时空序列数据中的深度时空特征编码为时空上下文向量,另一个LSTM用于解码时空向量以进行预测.
2) 引入了编码器网络与解码器网络之间的时空注意力学习机制,可以在所有时间步中选择与预测目标更相关的编码器隐藏状态,从而提高模型对多变量交通时空序列数据的深度表示能力,使得该模型可以学习到多变量交通时空序列数据中的长时空依赖特征和非线性相关等特征.
3) 基于3个真实的交通数据集实验,实验结果表明,该模型具有良好的预测性能和多步交通流预测能力,而且所提出模型的预测性能要优于其他基准模型.
1 相关工作
一直以来,为了提高智能交通的拥堵分析与管理决策能力,研究人员提出了大量的交通流量预测模型[1],其中大部分研究基于经典统计方法或浅层机器学习方法.例如Williams等用ARIMA对交通流进行建模,该方法为将单变量交通流序列数据建模为自回归移动平均过程,从而进行交通流预测[4].Chan等人[5]提出了一种使用混合指数平滑策略和Levenberg-Marquardt优化的ANN模型,以支持短时交通流量预测.Zhao等人[12]采用高斯过程模型对交通流进行建模,并提出了基于四阶高斯过程的动态交通流预测模型,该模型使用神经网络来训练模型参数.Sun等人[13]通过分析相邻路段的交通流量影响关系,提出了基于贝叶斯网络的交通流量预测方法.Lippi等人[3]在概率图模型的通用视图下,回顾了现有的短时交通流量预测方法,并进一步进行了实验比较和性能分析.
最近几年,随着智慧城市的高速发展[14],交通时空大数据呈爆炸式增长,数据建模面临的高维度、动态性和非线性相关性等问题越来越突出.一些研究人员尝试使用数据驱动的深度学习方法进行时间序列预测分析和建模[15-16],深度学习自然也成为了交通流预测研究的热点[2].深度学习由于其捕获非线性深度特征的能力而受到广泛关注,当然也可用于自动提取和学习城市时空序列数据中的深层次表示.由于交通拥堵过程和交通流演化本质上是动态变化、多因素非线性相关和序列突变的[17],因此深度学习模型无需先验知识即可学习交通时空数据的深层特征,这也非常适合处理交通流建模问题.因此,越来越多的研究者提出了基于深度学习的交通流量预测模型[10-11,18].例如Lv等人[10]提出了一种基于深度学习的交通流量预测方法,该方法采用堆叠式自动编码器模型来学习交通流量数据中的深层次特征和时空相关性.Huang等人[11]在交通流研究中也应用了深度学习方法,该方法将多任务学习纳入了深度学习架构,通过实验验证了其预测性能要优于传统模型.
当前,序列到序列深度学习已广泛应用于序列数据处理问题,在许多情况下具有出色的性能,尤其是自然语言处理任务[19].序列到序列深度学习模型使用编码器将输入序列编码为固定维数的向量,然后基于该编码向量进行目标序列解码作为预测输出,该方法可以理解为一种通用的序列数据处理端到端框架,备受研究人员的关注.例如Sutskever等人[20]提出了一种通用的端到端序列学习方法,该方法提出了一种观点,即简单直接的模型也可以实现有效的机器语言翻译;Venugopalan等人[21]提出了一种序列到序列模型来生成视频字幕,该模型相比传统模型,在图像字幕生成任务中具有更佳的性能;Kuznetsov等人[22]对基于序列到序列深度学习的时间序列预测框架进行了深入的理论分析,并将序列到序列学习与经典时间序列方法进行了实验性能比较;Li等人[23]提出了一种基于编码器解码器的扩散卷积循环神经网络(diffusion convolutional recurrent neural network, DCRNN),该交通流预测深度学习框架能够学习到深层的时空依赖性特征.
尽管如此,基于序列到序列学习结构的交通流预测模型,还鲜有系统深入的研究.现有的研究方法也很少从时空注意力机制的角度来扩展长时空序列的建模能力,此外,时空序列的多步预测要比单步预测更加困难,而结合注意力机制的序列到序列学习结构有望提升预测性能.与经典的统计分析和机器学习方法不同,本文通过基于时空注意力扩展的序列到序列学习构建模型并应用于交通流的多步预测.实验结果表明,该模型可以进行有效的多步交通流预测.
2 序列到序列学习
首先对序列到序列学习这种新的深度学习结构进行分析和论述,经典的序列到序列学习模型将可变长时序数据编码为固定长度的向量表示,然后将学习到的固定长度向量表示进行解码作为预测输出.从概率的角度来看,序列到序列模型是一种通用的学习框架,采用其进行城市交通序列建模的本质是学习以一个可变长度序列为条件的另一个序列的条件分布,所以序列到序列学习模型的计算过程可以描述为
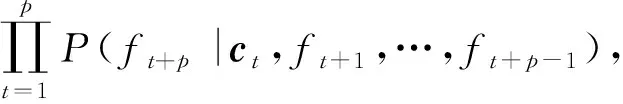
(1)
其中,(Xt-l,Xt-l+1,…,Xt)是作为模型输入的历史交通流相关时序数据,(ft+1,ft+2,…,ft+p)是模型的多步预测输出序列,其长度p(prediction size)为多步预测数,模型输入时序数据窗口大小为l(lookup size).该模型的编码器首先对输入序列(Xt-l,Xt-l+1,…,Xt)进行编码,生成并构建其隐含的特征表示,即上下文向量ct.模型解码器在获取最后一个隐藏状态输出之后,可对上下文向量ct进行解码,然后预测输出(ft+1,ft+2,…,ft+p).
在实际应用中,编码器和解码器可以有多种深度神经网络供选择,如编码器和解码器都是RNN,接下来分析整个序列到序列学习模型的计算过程.对于可变长输入序列,在每个时间步t,RNN的隐藏状态输出计算为
ht=RNN(ht-1,xt).
(2)
编码器RNN网络,顺序读取输入序列的每个值,同时RNN的隐藏状态根据式(2)进行改变.读取到序列结束位置后,RNN的隐藏状态即为时间步t的编码器隐藏状态,其计算为
ht=RNNenc(ht-1,ft-1,ct).
(3)
解码器RNN网络,可以通过预测给定隐藏状态条件下的下一个时间步数值来作为模型的预测输出,这里需要同时结合上一步预测输出和编码后的上下文向量作为输入.所以解码器时间步t的隐藏状态计算为
P(ft|ft-1,ft-2,…,f1,ct)=
RNNdec(ht,ft-1,ct).
(4)
整个序列到序列学习模型的2个组件(编码器网络与解码器网络)经过联合训练,最小化损失函数:
(5)
其中,θ是代表整个时空注意力模型的参数空间,n代表训练样本数,λ代表训练损失函数的正则项参数.
3 序列到序列时空注意力学习模型
3.1 模型总体框架设计
基于经典的序列到序列学习结构进行交通流预测过程,如式(6)所示,模型需学习以可变长度输入序列为条件的预测序列条件分布,而对交通序列进行编码和解码组件之间的唯一联系是上下文矢量.换句话说,编码器需要将整个输入交通序列编码压缩表示为固定长度的向量.
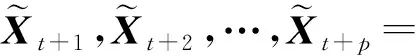
(6)
但是上述直接编码解码过程面临2个问题:1)上下文矢量不能完全表示整个输入交通序列的深层特征;2)前面输入序列数据编码获取的深度特征有可能被后续的输入序列编码特征所覆盖或冲淡,当输入序列越长,这个问题就越严重.这2个问题使得基于经典序列到序列学习结构的交通流多步预测面临挑战,随着与输入交通流有关的序列数据长度的增加,多步交通流预测性能会迅速下降.
为了解决上述2个问题,所提出的模型引入了时空注意力机制来处理多步交通流预测任务(如图3所示),另外经典的RNN或LSTM只能获取时间依赖特征,难以获取多站点序列的空间依赖特征[24],所以模型设计进一步引入了卷积LSTM作为编码器组件,来对时空序列数据中的空间依赖特征和时间依赖特征同时进行深度表示和编码学习.
基于时空注意力编码器-解码器结构的交通流预测模型包括3个部分:卷积LSTM编码网络、LSTM解码网络和时空注意力层,如图3所示.编码器从输入交通流相关的时空序列学习其隐藏特征(包括长时依赖性特征和时空关联性特征),并通过上下文生成向量结合时空注意力向量构建历史交通序列数据的深度潜在时空表示,即注意力上下文向量.LSTM解码器基于编码的时空注意力向量进行解码,以重建交通流序列作为目标预测值.图3展示了该模型框架的详细设计图.
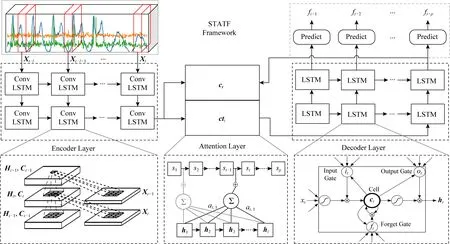
Fig. 3 The diagram of the spatial-temporal attention model for traffic flow prediction (STATF)图3 基于序列到序列时空注意力的交通流预测模型(STATF)框架图.
虽然与标准RNN相比,LSTM已被证明是学习时序数据长时依赖特征的最有效模型.但是,与交通流相关的时空序列数据不仅包含时间特征,而且还包含空间分布特征,由于经典的LSTM只能学习到时间依赖特征,难以有效地抽取空间相关性特征,卷积LSTM通过卷积运算代替传统的乘法计算,可以在一定程度上克服这一问题.所以为了对交通流相关的时序数据中的时空相关特征进行抽取和学习,首先提出卷积LSTM作为序列到序列注意力模型的编码器组件.卷积LSTM是对经典LSTM的扩展,该模型在LSTM的基础上用卷积运算代替原来的矩阵乘法运算,如图4所示.卷积LSTM不仅保留了LSTM可以学习不同时间步的长时依赖性特征的优势,同时还可以捕获多序列数据中的空间时空关联特征.因此,STATF模型使用卷积LSTM作为Encoder组件.
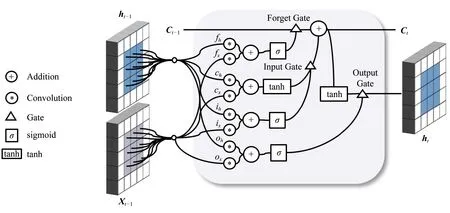
Fig. 4 Diagram of ConvLSTM Cell Block[25]图4 卷积LSTM单元内部结构示意图[25]
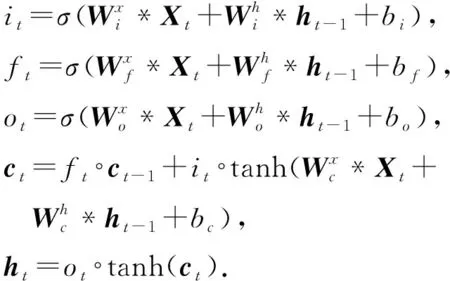
(7)
式(7)定义了卷积LSTM的详细计算过程,其中*表示卷积运算(卷积LSTM与LSTM的矩阵乘法运算不同,关键区别就在于*表示卷积运算而不是矩阵乘法运算),∘表示逐元素乘法,σ表示S型函数.it,ft,ot分别表示t时间步的输入门,忘记门和输出门,ct是t时间步的单元输出,ht是t时间步的单元隐藏状态输出,与经典LSTM不同,上述符号表示的都是3D张量.
3.2 时空注意力学习机制
本节介绍基于序列到序列结构的时空注意力机制计算原理及过程,设输入的交通流序列和预测目标序列分布表示为X={x1,x2,…,xT}和f={f1,f2,…,fp}.卷积LSTM编码器接受每个时间窗口的时序数据输入以及上一个时间步的隐藏状态,输出ht和ct分别是第t个时间步的隐藏状态和编码的上下文潜在向量:
ht,ct=ConvLSTMenc(xt,ht-1,ct-1),
(8)
(9)
如式(9)所示,cti是模型构建的时空注意力向量,由卷积LSTM编码器输出的隐藏状态求加权平均值获得,其中每个编码器的隐藏状态相对应的权重计算如下:
(10)
其中,eij是一个得分函数,通过使用LSTM解码器的隐藏输出状态和卷积LSTM编码器的隐藏状态来计算得分:
(11)
模型中的LSTM解码器基于编码的上下文潜在向量,结合上一个时间步接受的目标序列输出和隐藏状态输出进行解码计算:
st=LSTMdec(ft-1,st-1,ct-1).
(12)
最后,对时空注意向量cti与LSTM解码器的隐藏状态输出st进行连接计算,通过一个全连接网络层计算作为预测输出:
(13)
通过上述计算过程,结合梯度下降策略来训练所提出的模型,可以最大程度地减少预测交通流量值和真实交通流量值之间的误差,逐步降低模型的损失函数值,从而得到更优的预测结果,损失函数计算如式(5).整个模型训练过程的伪代码描述如算法1.
算法1.STATF模型训练过程.
输入:交通流相关的多变量时空序列数据集{xi,j|i=1,2…,n;j=t-l,…,t-1}、输入窗口l、前向预测步p;
输出:训练好的STATF模型.
①Dtrain←∅;
② 根据输入数据构建训练集Dtrain=(X,Y);
/*训练模型*/
③ 初始化STATF模型的参数空间θ;
④ repeat
⑤ 从训练集Dtrain中选择批处理样本Db;
/*基于深度注意力编码的交通流序列表示学习*/
⑥ht,ct=ConvLSTMenc(xt,ht-1,ct-1);
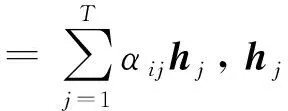
⑧st=LSTMdec(ft-1,st-1,ct-1);
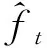
⑩ 最小化目标函数(式(5))获得最优参数空间θ;
算法1描述了STATF模型的训练过程,首先从输入的交通序列数据中构建训练实例样本,然后通过反向传播和Adam优化器对模型进行逐批次迭代训练.通过上述序列到序列的时空注意力计算过程可以获取并学习历史交通流时空序列数据中的深层时空关联特征,从而提升模型的多步交通流预测性能.接下来进一步对该模型进行实验评估和分析.
4 实验设置与结果分析
为了测试所提出模型的性能,基于3个真实的城市交通数据集进行实验.通过与经典的浅层学习模型和基准深度学习模型(包括最新提出的交通预测模型)对比,验证了该模型的交通流预测性能和有效性.
4.1 数据集
第1个数据集来源于英国政府开发数据平台,简称为Highway England Dataset[26],该平台发布有关英格兰的2类主要公路网的交通流数据信息,所有主干战略高速公路网络和本地化的公路网.Highway England交通流数据集是一个典型的多变量时空序列,该数据集采集了每间隔15 min的平均通行时间,通行速度和交通流量等信息,实验所用的数据集时间跨度为2013-01-01—2014-02-31.第2个实验数据集简称为PEMS-BAY[27],该交通数据集来源于美国加利福尼亚州运输部门的PeMS系统,实验选择了在湾区的325个传感器采集点数据,一共收集了5个月的数据,时间范围跨度为2017-01-01—2017-05-31,图5显示了该数据集的采集点位置分布.第3个实验数据集简称为METR-LA[23],该数据集来源于洛杉矶高速公路网的交通流采集设备,实验选择了其中207个传感器采集的数据,时间跨度范围为2012-03-01—2012-06-30的4个月数据.
Fig. 5 Sensor distribution of the PEMS-BAY dataset[23]图5 PEMS-BAY数据集的采集点位置分布图[23]
4.2 基准对比模型与超参数设置
本节描述实验的硬件和软件环境以及相关模型参数的配置情况,首先基于Tensorflow为Backend的开源深度学习库Keras,来构建各类深度学习实验模型,包括提出的STATF模型,采用Scikit-learn机器学习库用于构建基准对比浅层学习模型.所有实验均在PC服务器上进行,该服务器配置为Intel®Xeon®CPU E5-2623 3.00GHz,4个GPU每个配置为12 G NVIDIA Tesla K80C,内存为128 GB.另外,为了验证模型的预测效果,将STATF模型与以下8个基准模型进行比较:
1) VAR.向量自回归模型可以对多变量时间序列数据之间的隐含关系进行建模,可以把VAR模型看做是集合多元线性回归的优点(可以加入多个因子)以及时间序列模型的优点(可以分析滞后项的影响)的综合模型.
2) ARIMA.自回归综合移动平均值法是一种广泛用于时间序列分析的模型,它结合了移动平均值和自回归方法.
3) SVR.支持向量回归是支持向量机模型的一种变体方法,经常用于时间序列预测,一般使用3种不同核函数(RBF,POLY和LINEAR)的SVR模型.
4) RNN.这是用于处理序列任务的最为传统的深度学习方法,LSTM和GRU(门控循环单位)是2种最流行的基于RNN变体的深度学习模型.
5) ConvLSTM[16].经典的卷积LSTM网络,采用其作为城市交通流量预测实验的基准模型.
6) SEQ2SEQ[20].经典的序列到序列深度学习网络,编码器解码器都为LSTM,不包含注意力网络层,SEQ2SEQ可以视为STATF模型的一种简单变体.
7) SAE[10].Lv等人提出的一种基于深度堆叠自编码器(Stacked Auto-encoder)框架的交通流预测模型.
8) DCRNN[23].Li等人提出了一种基于编码器解码器的扩散卷积循环神经网络(DCRNN),该深度学习框架能够学习到交通流数据中的时空依赖性特征.
STATF模型训练过程中的参数设置情况如下,首先选择均方误差(MSE)作为模型训练的损失函数,交通流建模的训练集和测试集分割策略为:数据集的前70%作为模型训练集,剩余30%作为测试集.此外,采用了min-max函数将交通流相关序列数据都标准化到[0,1]区间.基准深度学习模型和STATF模型的基础超参数配置一样,具体配置为:训练迭代次数为100,批处理大小为96,每层的神经元丢弃率为0.3,学习率参数为0.01,基准深度学习模型的默认神经网络层数设置为1,每个隐藏层神经元数量为100,所有深度学习模型均采用Adam函数用作模型训练优化器.卷积LSTM的filters和kernels参数大小分别设置为64和(1,5),解码器的LSTM网络每层神经元数量也设置为100.模型输出层的激活函数采用linear线性函数,用于最终预测.最后,将RMSE和MAE作为模型误差分析指标,用于评估各个模型的预测性能,误差指标计算公式为:
(14)
(15)
4.3 实验结果分析
基于3个真实的交通流数据集进行实验分析和评估,在实验过程中对STATF模型与其他对比模型的总体预测性能进行比较.实验对比结果如表1所示,其中给出了STATF模型与对比模型从t+1到t+12的未来12个时间步内的多步交通流预测平均误差RMSE和MAE结果,包括经典的浅层学习模型VAR,ARIMA,SVR和基准深度学习模型RNN,LSTM,GRU等,以及针对交通流预测任务而设计的如SAE[10]和DCRNN[23]深度学习模型.从表1可知STATF模型在多步交通流量预测性能方面要优于其他对比模型.与经典浅层学习和基准深度学习模型相比,STATF模型在未来12个时间步从t+1到t+12的预测都能保持最低的RMSE和MAE平均预测误差,在一定程度上提升了多步交通流预测的准确性.此外,实验结果还表明,基准深度学习模型,例如LSTM,GRU的预测性能要明显优于传统的浅层学习方法.这是因为与浅层学习模型相比,深度神经网络结构可以学习到时空序列数据中更为复杂的模式和特征.而相比简单的变体模型,如SEQ2SEQ与ConvLSTM和针对交通流预测而设计的新型深度学习模型,如SAE与DCRNN,STATF模型更进一步降低了模型的预测误差.
在多个数据集总体平均预测误差对比基础上,继续对单个数据集的多步预测性能进行比较分析.首先基于Highway England交通流数据集进行实验分析和评估,实验对比结果如表2所示,其中给出了STATF模型与基准模型的多个特定时间步t+1,t+3,t+6,t+12的交通流预测误差RMSE和MAE结果.从表2可知,STATF模型在多步交通流量预测性能方面要优于其他基准对比模型.与基准浅层学习和深度学习模型相比,STATF模型不管是在预测时间步大小为3(t+3)还是预测时间步大小为12(t+12)时,都能保持最低的RMSE和MAE预测误差.此外,实验结果还表明,基准深度学习模型,例如LSTM,GRU的预测性能要明显优于传统的浅层学习方法,尤其是在长时间步预测的情况下.而相比基准方法和针对交通流预测而设计的深度学习对比模型,如SAE与DCRNN,以及相比如SEQ2SEQ不含注意力机制的简单变体模型,STATF模型能够从多个深度网络的分层结构中提取不同级别的时空表示特征,提升了模型的多步预测性能.
通过实验结果分析,进一步发现预测时间步长的选择对模型的预测性能有很大影响.如表2所示,长时间步条件下模型的预测性能,要明显低于短时间步长预测的性能.产生这种现象的原因是,模型每个时间步的预测都需要考虑前一个时间步长的预测结果,这种情况下随着预测时间步长的增加,前面时间步的模型预测误差会逐步累积,从而使得整个模型的预测误差越来越大.这也符合人们的直观认知.所以,随着预测时间步长的增加,每个实验对比模型的预测性能都在逐渐下降.但从实验结果中可以看到,与基准的深度模型和浅层模型相比,在不同的预测时间步长条件下,STATF模型都能保持最低的预测误差.
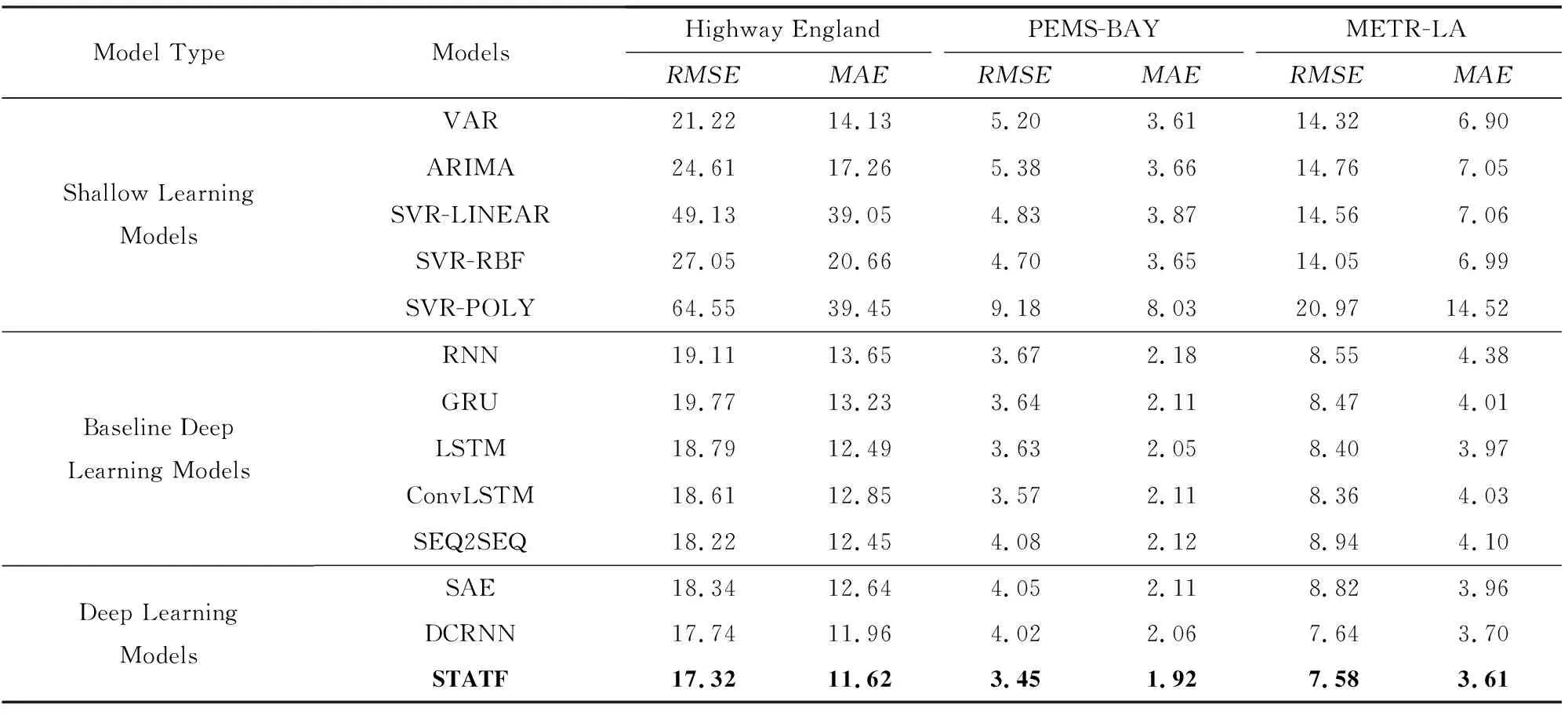
Table 1 Comparison of the Average Prediction Error of Different Models表1 不同模型的平均预测误差对比
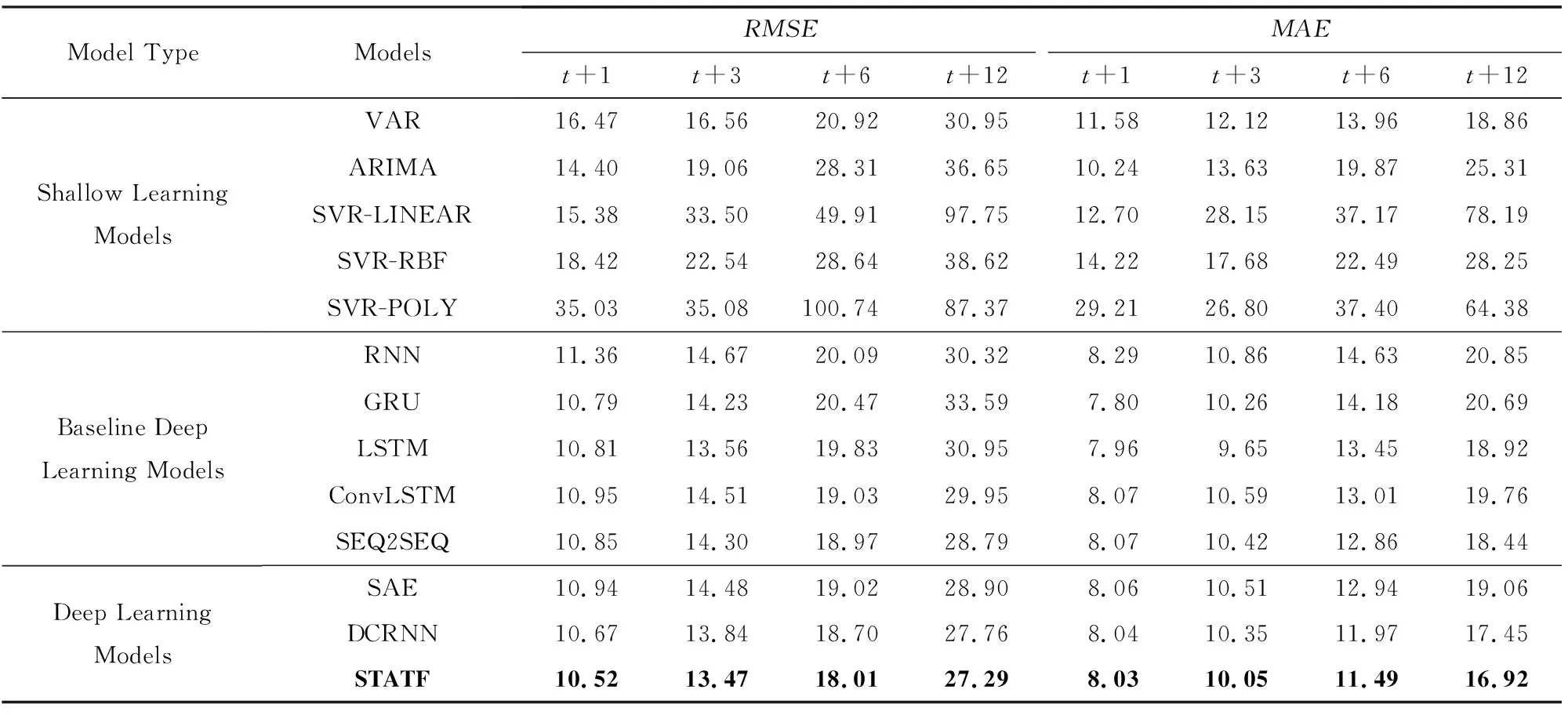
Table 2 Comparison of the Prediction Error of Different Models表2 不同模型的预测误差对比
为了进一步比较STATF模型和其他基准模型在不同时间步长条件下的预测性能,分析并显示了不同模型在一个工作日内(包括96个时间步,每个时间步间隔15 min)、在不同预测时间步长大小条件下的交通流量预测性能,以及一周内(包括672个时间步、每个时间步间隔同样是15 min)的比较情况.如图6和图7所示,分别为一个工作日(2013-11-18)和一周(2013-11-18—2013-11-24)的预测情况,比较SVR-RBF,RNN和本文提出的STATF模型的实际观察到的交通流量值和预测交通流量值对比曲线,其中x坐标表示观测时间步长,y坐标表示该时间步的交通流量值.从2个曲线对比图可以看到,不管是一个工作日内还是拉长到一周时间范围内,STATF模型的预测性能都要优于以SVR-RBF为代表的浅层模型和以RNN为代表的深度学习模型.还有就是不管是在工作日情况下,还是在周末情况下,如图7最后2个波峰,特别是在交通流波峰和波谷时间范围内的预测情况,STATF模型预测性能都能保持最优.另外,2个图示分析都表明:RNN模型的预测性能要优于SVR-RBF模型,随着预测时间步长的增加,浅层学习模型的预测性能会显著下降,而STATF模型和基准深度学习模型可以保持良好稳定的性能.上述实验结果分析表明,在不同的时间步长预测条件下,STATF模型在Highway England数据集上的多步预测性能要优于基准浅层学习模型和深度学习模型.
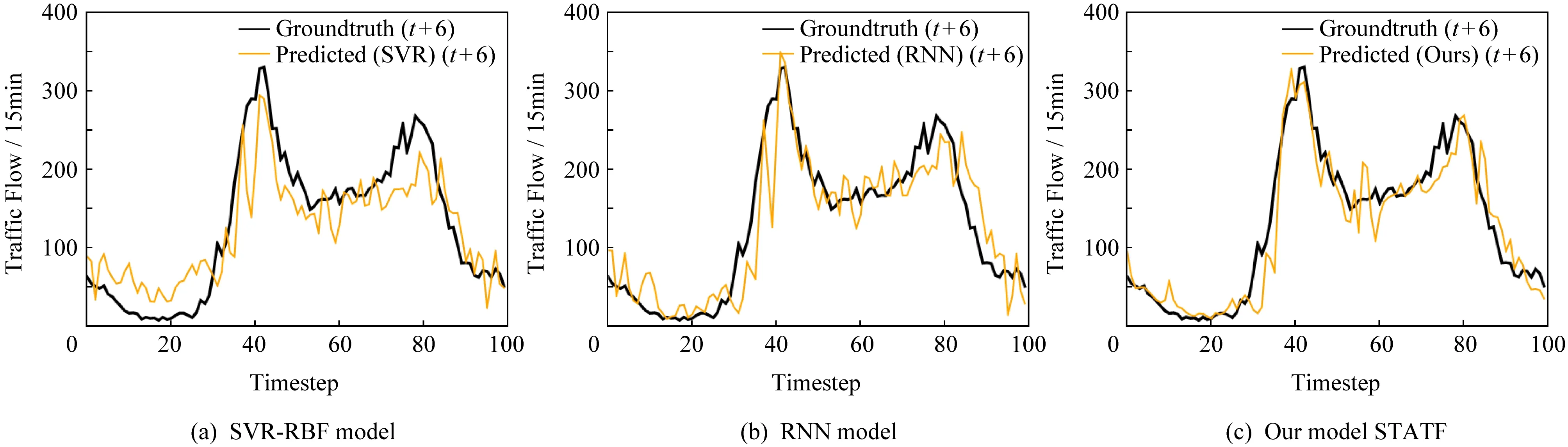
Fig. 6 Comparison of ground truth value and predicted traffic value of different models during one day图6 不同模型在一个工作日内的交通流预测值与真实值对比
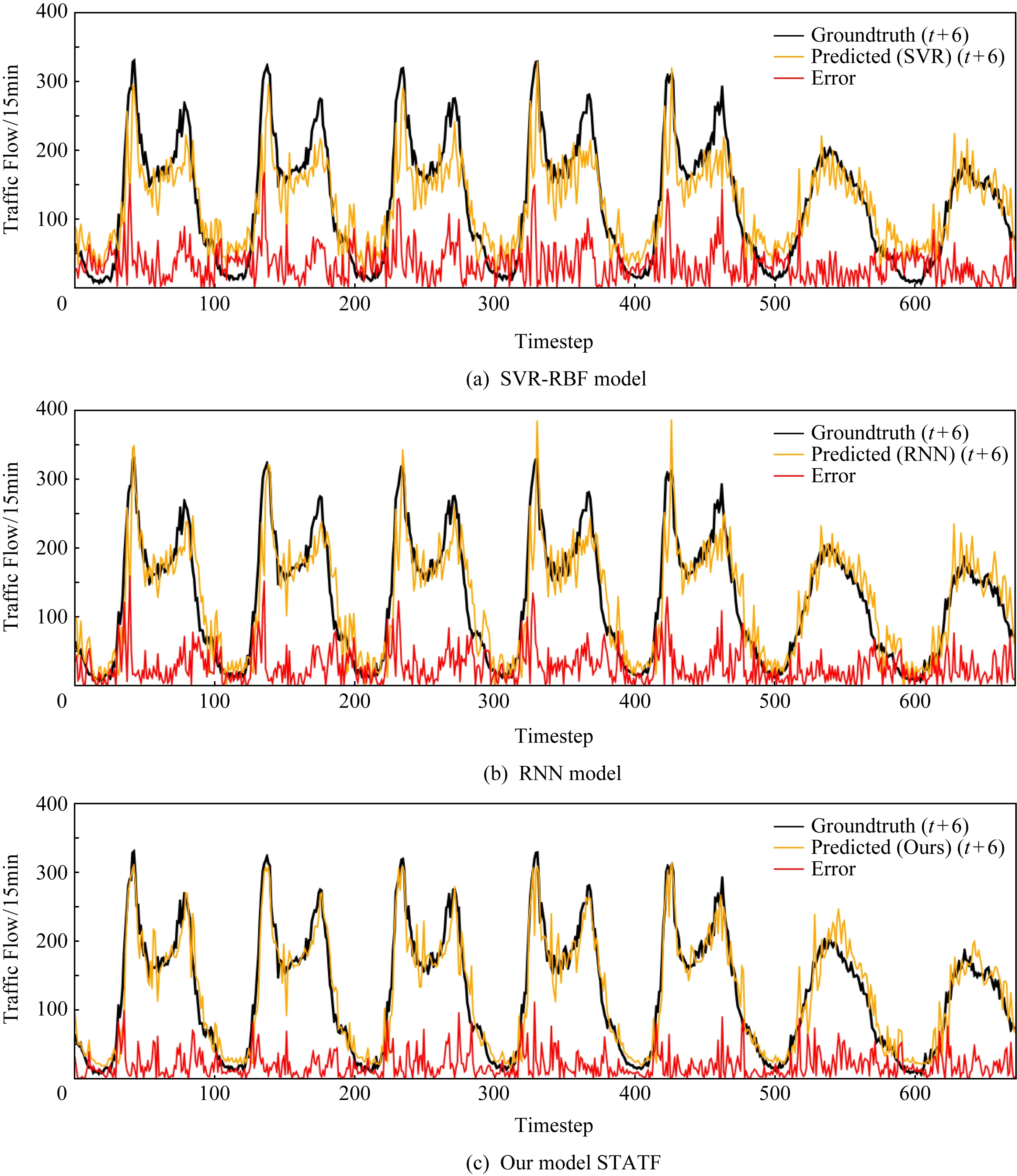
Fig. 7 Comparison of ground truth value and predicted traffic value of different models during one week图7 不同模型在一周内的交通流预测值与真实值对比
继续对PEMS-BAY数据集进行各模型的多步预测性能比较.在实验过程中对STATF模型与其他基准模型、当前最优模型等的预测性能进行比较,实验对比结果如表3所示,其中给出了STATF模型与基准模型的多个时间步下的交通流预测误差结果.从表3可知,在PEMS-BAY数据集实验中,无论预测时间步长是多少,STATF模型的预测性能同样都比其他基准模型要好,即使对于未来12个小时后的长时间步预测,STATF模型预测性能也是所有对比模型中最好的.具体到RMSE与MAE误差指标值,与基准浅层学习模型和深度学习模型相比,当预测时间步大小为3时,STATF模型的RMSE和MAE值分别为3.04和1.72,预测误差值最小;当预测时间步长为12时,STATF模型的RMSE和MAE值分别为4.81和2.52,预测误差值同样能保持最低.
另外,基准深度学习模型(例如LSTM,GRU和ConvLSTM)的预测性能同样明显优于传统的浅层学习方法,特别是在长时间步预测的情况下.传统的时间序列预测方法(例如VAR和SVR)在交通流预测任务上难以获得与深度学习模型一样的性能,是因为它们仅仅依赖于交通流历史记录本身来预测未来值,而与交通流相关的其他城市时空序列数据难以一起建模,所以传统模型方法无法捕获与交通流相关的城市时空序列数据中的隐藏长时依赖特征和非线性时空关联关系.STATF模型可以在一定程度上降低上述问题的影响,因此在与其他基准深度学习模型、及当前最优深度学习模型等(如SAE模型[10]与DCRNN模型[23])的实验对比中能具有最佳的预测性能.
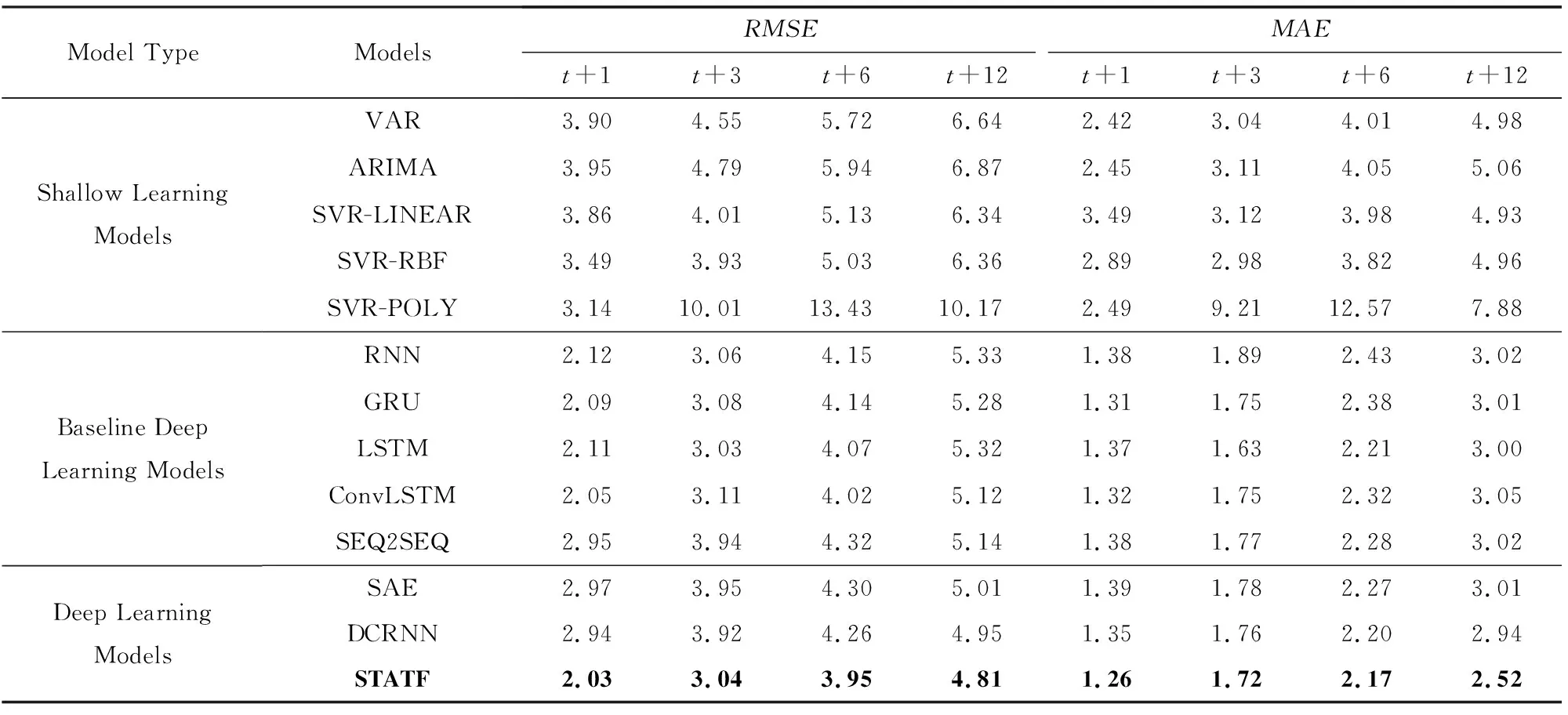
Table 3 Comparison of Traffic Flow Prediction Error Indexes of Different Models表3 不同模型的交通流多步预测误差指标对比
为了进一步分析和比较STATF模型与基准方法在PEMS-BAY数据集上的预测表现,如图8所示,其中水平轴表示观测的时间步长,垂直轴代表交通序列值,该图展示了SVR-RBF,RNN,STATF模型在单步预测t+1和多步预测t+6条件下的交通流预测误差情况.从图8中可以看到,STATF模型在不同时间步预测情况下都能保持最优的预测性能,图8中预测值曲线与真实值曲线能够很好的匹配.STATF模型的预测性能,不管是在波峰还是波谷时段,都要优于以SVR-RBF为代表的浅层模型和RNN为代表的基准深度学习模型.另外,随着预测时间步长的增加,SVR-RBF模型和RNN模型的预测性能在急剧下降,但STATF模型的预测性能下降趋势要比SVR和RNN模型更为缓慢,可以相对较好地保持更优的交通流预测准确性.不同深度学习模型在单步预测条件下性能差异较小,而在长时间步预测情况下,STATF模型的性能优势更为明显.
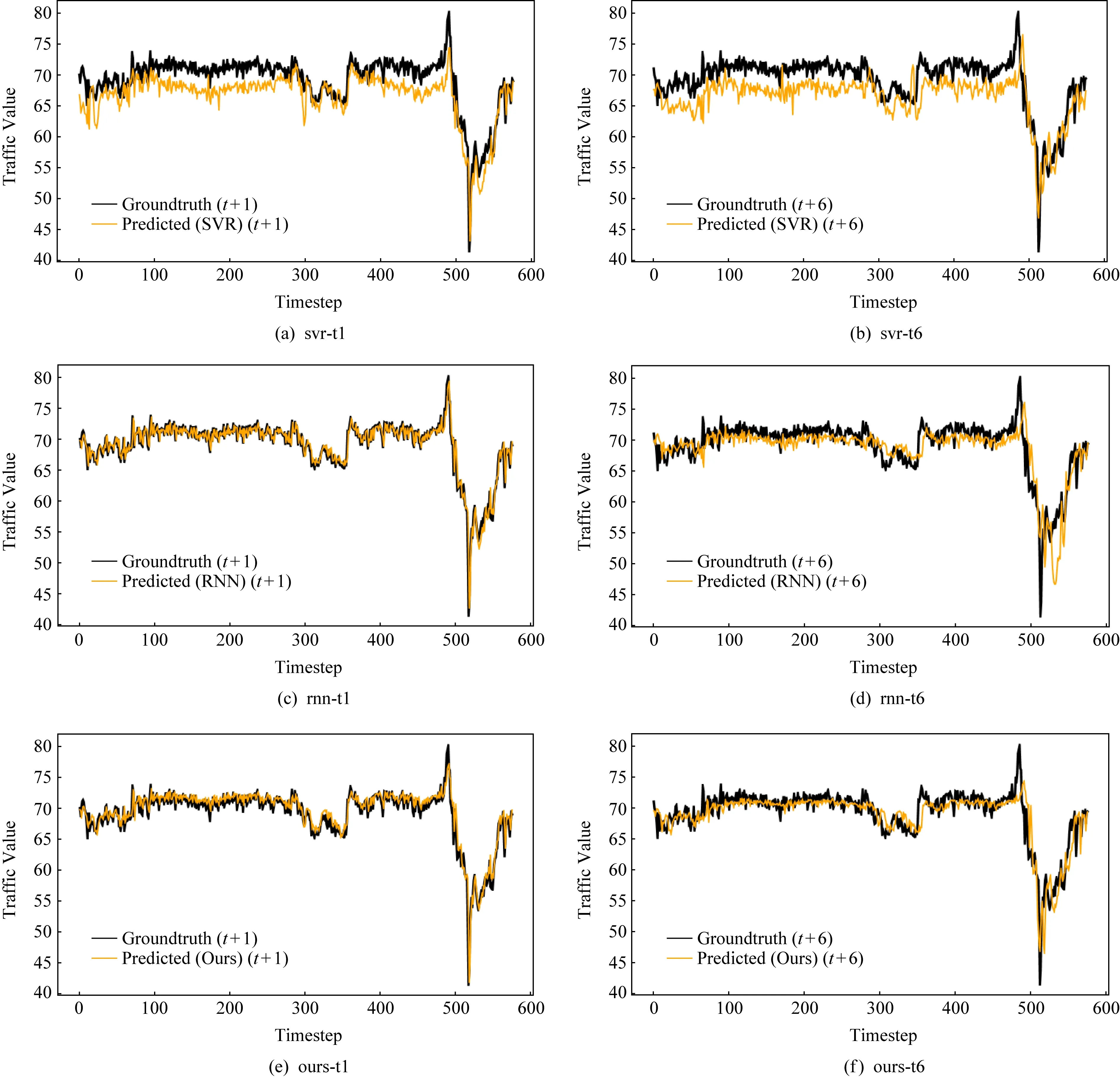
Fig. 8 Comparison of ground truth value and different time-step (t+1 and t+6) predicted traffic value of different models图8 不同模型在t+1和t+6时间步下的交通流预测值与真实值对比
最后,为了分析多个时序特征相比单序列特征对交通流建模的影响,对STATF模型在不同数据集上的单变量预测和多变量预测性能进行了对比.表4的结果给出了STATF模型在3个交通流数据集下的对比实验结果,包括在单变量时序输入条件(unvariate)和多变量时间序列输入条件(multivariate)下的预测误差值RMSE与MAE.以Highway England数据集为例,在单变量输入条件下,仅将traffic flow单变量序列输入模型;而在多变量时间序列输入条件下,则将traffic flow变量本身和其他变量一起输入模型,例如通行速度speed、通行时长pass time等.如表4所示,与单变量输入条件下的预测误差相比,多变量时间序列输入条件下的模型预测误差有一定程度降低,这表明STATF模型可以有效学习多元交通流序列数据中非线性相关性特征.
综上所述,通过在3个真实交通流数据集上进行的实验结果分析,所提出的基于序列到序列时空注意力深度学习的交通流量预测模型STATF,相比基准模型和当前最新提出的模型,具有更好的预测性能.不管是在单步预测还是在长时多步预测条件下,STATF模型的交通流预测值都可以与真实值保持较好的匹配.同时,在各种时间步长预测条件下,该模型的预测误差也比基准模型更低.这验证了STATF交通流预测模型的性能,可以有效地学习多变量交通流相关时空序列数据中的深层非线性相关特征和时空依赖特征.
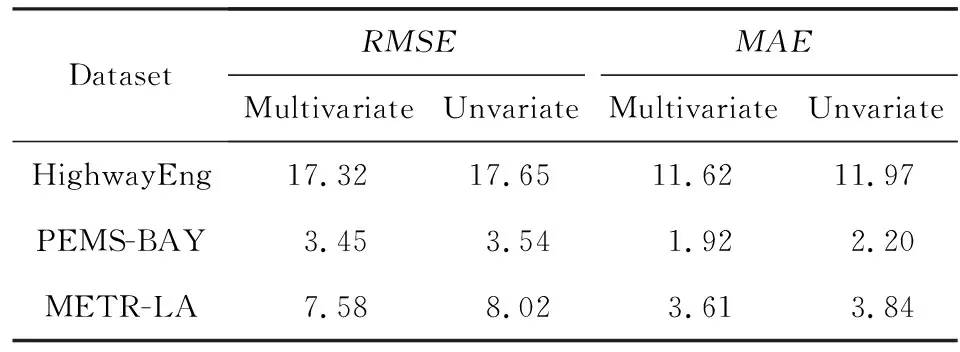
Table 4 Comparison of Unvariate and Multivariate Prediction Error of Different Models on Three Datasets表4 STATF模型在3个数据集上的单变量预测与多变量预测误差指标对比
5 总 结
针对交通流预测面临的两大关键挑战性问题,提出了一种新的交通时空序列端到端深度学习框架,该模型将序列到序列深度学习结构、卷积LSTM网络和时空注意力机制进行模型集成,并对模型的核心框架设计与时空注意力机制原理过程等进行了详细分析和论述.所提出的STATF模型不仅考虑了交通流相关数据中的时空相关性特征,而且还能捕获与交通流有关的多变量城市时空序列中的非线性相关性特征.在3个真实交通流数据集上进行的实验结果表明,STATF模型相比经典浅层学习模型、基准深度学习模型、以及当前新提出的2种交通流深度学习模型,具有更优的预测性能,验证了该模型可以探索和学习到多变量交通序列数据中的隐含时空依赖性特征和非线性相关特征.
未来的主要工作是收集有关交通事故或极端天气事件的数据,进一步对该模型进行深入研究和改进,实现对未来的长时多步城市交通流量,尤其是在交通事故或极端天气等突发情况下的有效预测,以及适应其他更复杂的交通流预测情况.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
东南大学学报(自然科学版)(2022年3期)2022-06-19
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
科技资讯(2017年19期)2017-08-08
科技创新与应用(2017年16期)2017-06-10
珠江水运(2016年23期)2017-01-04
中国市场(2016年36期)2016-10-19
