
SCONV:一种基于情感分析的金融市场趋势预测方法
2020-08-25 06:57林培光周佳倩温玉莲
计算机研究与发展 2020年8期
林培光 周佳倩 温玉莲
(山东财经大学计算机科学与技术学院 济南 250014)(llpwgh@163.com)
股票市场是一个与我们日常生活息息相关的市场,对于我国甚至全球的经济发展都十分重要.股民作为股票市场的重要参与者,其情绪的变化会迅速反映到市场上.随着近些年,互联网技术的迅速发展,信息传播的速度与渠道也越来越多,股民们获取信息的方式也越来越多样化.金融新闻、财经新闻、社交媒体等等逐渐开始影响股民们投资的决策.因此,股票价格不仅仅会受政治、经济、军事的影响,还会受“情感”因素的影响.随着新闻、微博、博客、贴吧、论坛等等社交网络的影响.金融新闻更加快速直观地诱导放大了投资者对于股票市场的态度倾向,导致股票价格的不确定性和波动性很大,使股票价格的预测成为研究的一大难题.
近年来,深度学习[1]开始成为学习热潮,经过近几十年的发展,深度学习已经成为了一门热门技术[2],并且不断在各大领域有所突破,如股价预测[3-5]、时间序列预测、文本分析、计算机视觉[6]等等.
本文提出了一种基于情感分析的卷积LSTM模型SCONV(semantic convolutional),该模型从股民评价与交易数据中动态提取金融市场趋势的潜在数据,利用股民评价来提取情感特征,帮助提高股价预测的准确率和稳定性,使用word2vec模型对文本数据进行训练、获取词向量表示并提取出“情感”权重后,通过卷积的局部特征,使用卷积LSTM模型[7]来捕捉金融交易数据的特征.
本文利用4种评价指标,通过与其他3种传统模型的比较以及对不同的数据集进行独立测试,并对实验结果进行分析,实验结果表明:本文提出的模型在不同长度的样本中依旧具有更好的预测性能,适用性更强.
本文的主要贡献有3个方面:
1) 通过融合语义分析与带有卷积的LSTM模型来进行金融市场的走势预测.SCONV模型仅将原始金融交易数据以及股民评价作为输入,没有任何中间的人为干预,是一种纯端到端的方法.
2) 用股吧评价来挖取股民的“情感”因素作为辅助信息,提高了预测的准确性.
3) 不同于以往的8~10年的数据训练量,本文尝试使用小一些的样本(3年以内的交易数据以及股吧评论)来训练模型,并用金融和机器学习标准评估它.实验结果表明:与基本模型(如RNN、普通LSTM网络)相比,SCONV为所有实验样本提供了更加稳健的预测效果.
1 相关工作
目前,用于时间序列预测最常用的模型是AR模型及其衍生的ARMA,ARCH,GARCH等模型,但是,时间序列的高度非线性与不稳定性,限制了AR模型的适用性.随着机器学习与深度学习的发展,开始衍生出很多其他的时间序列预测模型,如结合K-最近邻和支持向量机的混合模型,添加了隐马尔可夫模型的对抗非线性股价时间序列模型,以及基于和谐搜索的神经网络.
尽管传统的神经网络具有处理非线性数据的能力,但是这并不足以尽可能多地找到时间序列中的长期依赖关系以及特征提取.为了记住时间序列数据的长期上下文特征,激发了门控存储单元的使用,从而出现了目前用于股票研究的预测的最广泛使用的模型之一:LSTM模型.LSTM是Hochreiter等人[8]在1997年首次提出的,是递归神经网络RNN的变体,它是一种可扩展的动态模型,很好地实现了时间序列数据的长期上下文.在2016年Akita等人[9]用LSTM采用历史数值和文本数据来预测价格.2015年,Rather[10]等人提出了股票收益预测的递归神经网络和混合模型.
Zhang等人[3]提出了一种通过离散傅立叶变换增强的LSTM变体,以发现多频交易模式;2017年,Tsantekidis等人[11]提出了基于CNN模型的股票价格预测,实现了神经元的局部连接和权值共享,保留重要参数,减少了大量不重要的参数.
2015年提出的卷积LSTM[7]将深度卷积神经网络的局部特征提取能力与LSTM的时间特征保持相结合,已经被应用于许多领域,例如天气预报[7]、图像压缩[12]以及一般算法任务[13].
尽管有很多方法可以预测股票价格[14-15],但是这些工作都没有考虑到股民作为股票市场参与者的影响,实际上,随着互联网的迅速发展,信息的传播速度越来越快,金融类新闻更加快速直观地诱导放大了投资者对于股票市场的态度倾向,股民的情绪开始更加快速直观地影响股价,为了更加准确地预测股价走势,本文提出了一种基于情感分析的金融时间序列预测方法SCONV.除固定的结构化历史数据之外,还爬取了非结构化的股民评论来提取“情感”因素与股票价格一起,利用ConvLSTM模型进行股票预测.
实验表明:本文提出的SCONV模型在较小样本的情况下依旧具有稳定性,SCONV模型的各类结果参数RMSE,MSE,MAE和MAPE的值比对照的传统模型CNN,LSTM,LSTM-CNN的值要小,可以得出,本文提出的SCONV模型在不同长度的样本下依旧具有优势,证明了本文提出模型的有效性.
2 SCONV方法模型
本文提出的SCONV的体系结构如图1所示,通过从股吧爬取股评,经过数据清洗之后,创建单词到索引和矢量的映射、转换训练和测试词典,使用word2vec模型获取股票评论信息的词向量表示,将词向量特征使用lstm模型进行情感分类,赋予情感权重.同时,将股价信息进行特征提取与降维处理后,与对应日期的情感权重一起组合,利用ConvLSTM模型通过2个步骤处理二维数据帧:
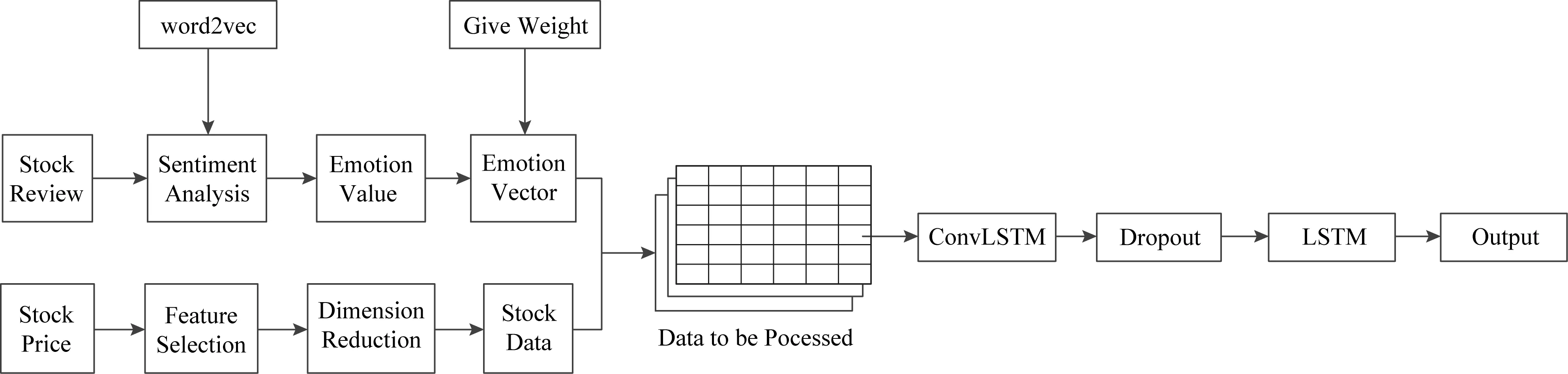
Fig. 1 SCONV model structure diagram图1 SCONV模型结构图
1) 卷积核捕获局部特征;
2) 基于局部特征,LSTM网络用门控递归网络捕获瞬时特征.
在后一个叠加的LSTM进行训练之前,模型中添加了一次dropout来避免过拟合.
2.1 数据预处理
本文的数据预处理主要为对股民评价的原始数据清洗、删选、去除噪声以及无关内容,得到高质量的数据,使之后的情感分析更为准确.
首先进行数据清洗,删除有缺失或缺失比例较高的股评.
随后,使用jieba分词工具的精确模式将文本数据进行分词处理,去掉换行符,对于无关向量进行删除操作来去除噪声,并创建词语字典,返回每个词语的索引、词向量以及每个句子所对应的词语索引,为之后的情感分析做铺垫.jieba分词具有3种模式:精确模式、全模式以及搜索引擎模式.其中,精确模式可以将句子以最精确的方式进行切分,此模式常被用于情感分析.创建每个词语的索引、词向量以及每个句子所对应的词语索引的过程具体会在2.2节进行介绍.
2.2 股票评论文本情感提取
有关情感的论述可以追溯到19世纪末的James[16],在情感分析的发展过程中,Subasic等人[17]将自然语言处理技术与模糊逻辑技术相结合,基于手动创建的模糊情感词典,对新闻故事和电影评论进行情感分析.随着文本情感倾向分析研究的不断深入,对于具有倾向性的特殊句式的研究也逐渐展开,在倾向性分析应用以及倾向性分析与其它任务相结合的研究也在逐渐展开,例如倾向性文本摘要、倾向性信息检索[18]等.
如图2所示,本文构建的情感分析模块由预处理与情感分析2部分组成.
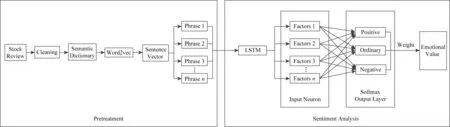
Fig. 2 Emotional analysis module图2 情感分析模块
2.2.1 预处理
预处理包含了情感分析模块的输入部分以及词向量表示部分,将股票评论文本的一条评论信息输入模块进行处理,先对句子进行分词,去掉换行符,并创建词语字典,返回每个词语的索引、词向量以及每个句子所对应的词语索引,此过程为:
1) 创建单词到索引的映射;
2) 创建单词到矢量的映射;
3) 转换培训和测试词典.
预处理中,记录了所有频数超过10的词语的索引以及所有频数超过10的词语的词向量,对于每个句子中所含词语对应的索引,若句子中含有频数小于10的词语,则索引为0.
2.2.2 情感分类
1) word2vec
word2vec模型可以构建文本特征词向量,可以用于情感分析.word2vec是由Mikolov[19]等人开发的工具,它是在Log-Bilinea和NNLM这2个模型的基础上发展生成的.word2vec可以将词从高维空间映射到低维空间,并且保留了词向量之间的位置关系,从而解决了语义联系和向量稀疏2个问题.
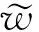
2) 情感权重计算
由预处理部分得到词向量后,本文使用LSTM层来提取股评信息特征,进行情感分析,提取的特征信息在输入神经元(input neuron)生成用于情感分类的特征值,最后在输出层(output layer)使用softmax函数输出情感类别,积极情感为1,普通为0,消极情感为-1,最终赋值整合成情感权重.
随后对词向量进行分类后得出该条股评的类别(label)为1(积极情感)或0(普通情感)或-1(消极情感),并计算每一条股评的价值,再进一步整合成每一天的情感值sentiment_label.
如表1所示,本文通过情感分析的input neuron模块,对每一条股评的类别label进行判别,并计算出该条股评的情感值sentiment_value.具体计算过程如式(1)至式(6)所示:

Table 1 Theemotional Value and Label of Stock Evaluation表1 股评情感值与标
ft=σ(Wf[ht-1,xt]+bf),
(1)
it=σ(Wi[ht-1,xt]+bi),
(2)
其中,σ表示sigmoid函数,ft和it分别代表遗忘门和输入门,xt表示输入端的股评分词向量,W表示权重矩阵,b表示偏差矩阵.
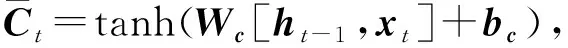
(3)
(4)
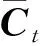
ot=σ(Wo[ht-1,xt]+bo),
(5)
ot为输出门,此时ot表示sentiment_value,即每一条股评的情感值,sentiment_value∈[0,1],sentiment_value=1时表示该条股评情感强烈,反之,则表示该条股评情感所占比重不多.
(6)
ht表示t时刻LSTM单元的输出,此时ht代表sentiment_label,即每日的情感值,通过累加每一条的sentiment_value×label并向上取整,可以得出如表2所示的每天的情感权重sentiment_label.
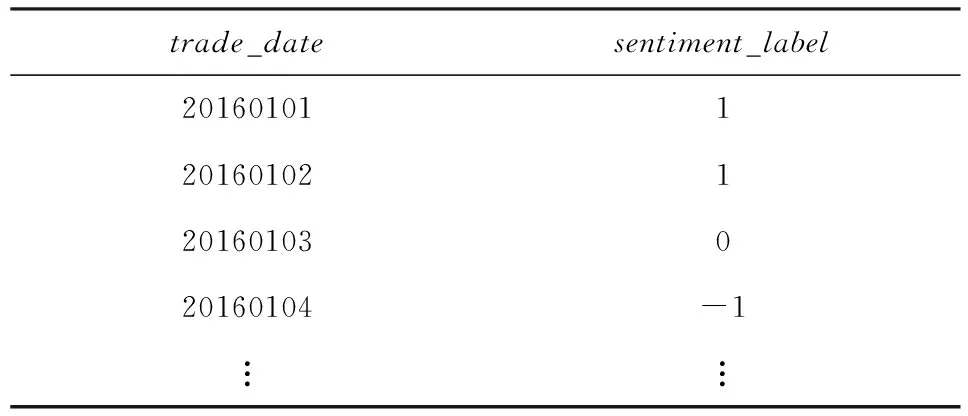
Table2 Daily Emotional Value表2 每日情感值
2.3 股票时间序列预测
2.3.1 卷积LSTM
卷积LSTM是在2015年由Shi等人[7]提出的,起初其用于降水预报.如图3所示,相比于传统的LSTM,ConvLSTM中先使用了卷积操作提取数据特征,再对数据进行训练,可以更好地预测数值的趋势走向.相比卷积网络叠加LSTM,ConvLSTM中门的计算引入了卷积,输入可以是二维图像(可以是多个通道的),而后者的卷积操作叠加LSTM,其中的卷积层只是用来提取特征,特征转换为一维向量后作为输入送入LSTM,LSTM中门的计算是全联接的.ConvLSTM自提出以来,已经被应用于许多领域,例如天气预报[7]、图像压缩[13]以及一般算法任务[11].
普通LSTM网络中的所有隐藏层都是完全连通的层,它对于语音识别和自然语言处理等任务非常有效,因为它可以将语音和文本完美地映射到可训练的向量空间中[18].然而,它无法更好地处理纯数字数据的标记化.卷积LSTM单元通过用卷积核替换完全连通的层来解决这个问题.
形式上,在ConvLSTM的网络结构中,将股票时序数据连同其对应的前1天、前3天均值、前一周均值的情感数据一起作为输入,使其在ConvLSTM底部的卷积层CNN中不仅能够得到时序关系,还能够像卷积层一样提取空间特征,这样ConvLSTM就可以同时提取时间特征和空间特征,并且状态与状态之间的切换也换成了卷积运算,具体模型如图3所示.ConvLSTM单元的信息更新过程如式(7)~(11)所示:
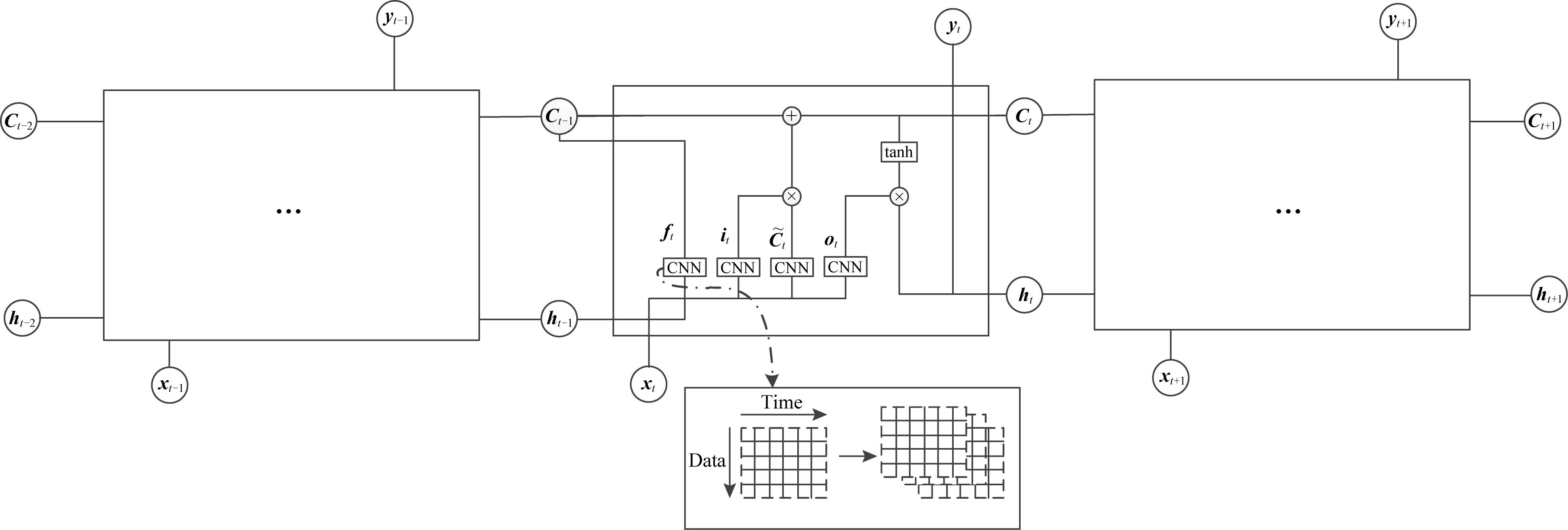
Fig. 3 ConvLSTM cell structure图3 ConvLSTM单元
it=σ(Wxi*Xt+Whi*Ht-1+
Wci∘Ct-1+bi),
(7)
Ct=ft∘Ct-1+it∘tanh(Wxi*Xt+
Whi*Ht-1+bc),
(8)
ot=σ(Wx0*Xt+Wh0*Ht-1+
Wc0∘Ct+b0),
(9)
ft=σ(Wxf*Xt+Whf*Ht-1+
Wcf∘Ct-1+bf),
(10)
Ht=ot∘tanh(Ct),
(11)
其中,σ表示sigmoid函数,tanh是双曲正切函数,*表示卷积运算.Xt,Ht,Ct分别表示时间步长t处的输入数据、隐藏状态和单元状态.it,ft,ot表示在时间步长t时输入门、遗忘门和输出门的输出.Wxi,Whf,Wcf表示输入、输出和遗忘门的卷积核.bc表示输入门的偏置,bf表示遗忘门的偏置,b0表示输出门的偏置,∘表示逐点乘法.
由于参数共享是深度学习模型泛化的关键因素,其通过核和数据之间的卷积运算,使核的参数在输入数据之间共享,因此卷积操作对于从数据中提取泛化特征更有效.
然而,由于金融交易数据的性质,我们不能直接使用卷积LSTM单位的原始设计.虽然交易数据可以组织成二维框架,但我们不能应用二维卷积,因为二维框架的行包含不同类型的特征,包括开盘价、收盘价、最高价、最低收和交易量.
相反,本文使用一维卷积的修改版本:通道只在二维数据帧的时间线列之间水平移动,同时它们也在不同类型的数据之间共享,以保证参数共享.请注意,我们遵循Shi等人[7]的设计,即在卷积过程中不压缩输入帧的大小,这意着如果输入的Xt是6*5,输出通道是32,则最终隐藏状态输出Ht应该是6*5*32,并且它们被展平为矢量,作为后续分类器层的输入.
2.3.2 LSTM
从ConvLSTM中生成的数据,再添加一次dropout来避免过拟合,LSTM模型单元内部结构如图4所示.LSTM单元的信息更新过程如式(12)~(17)所示:
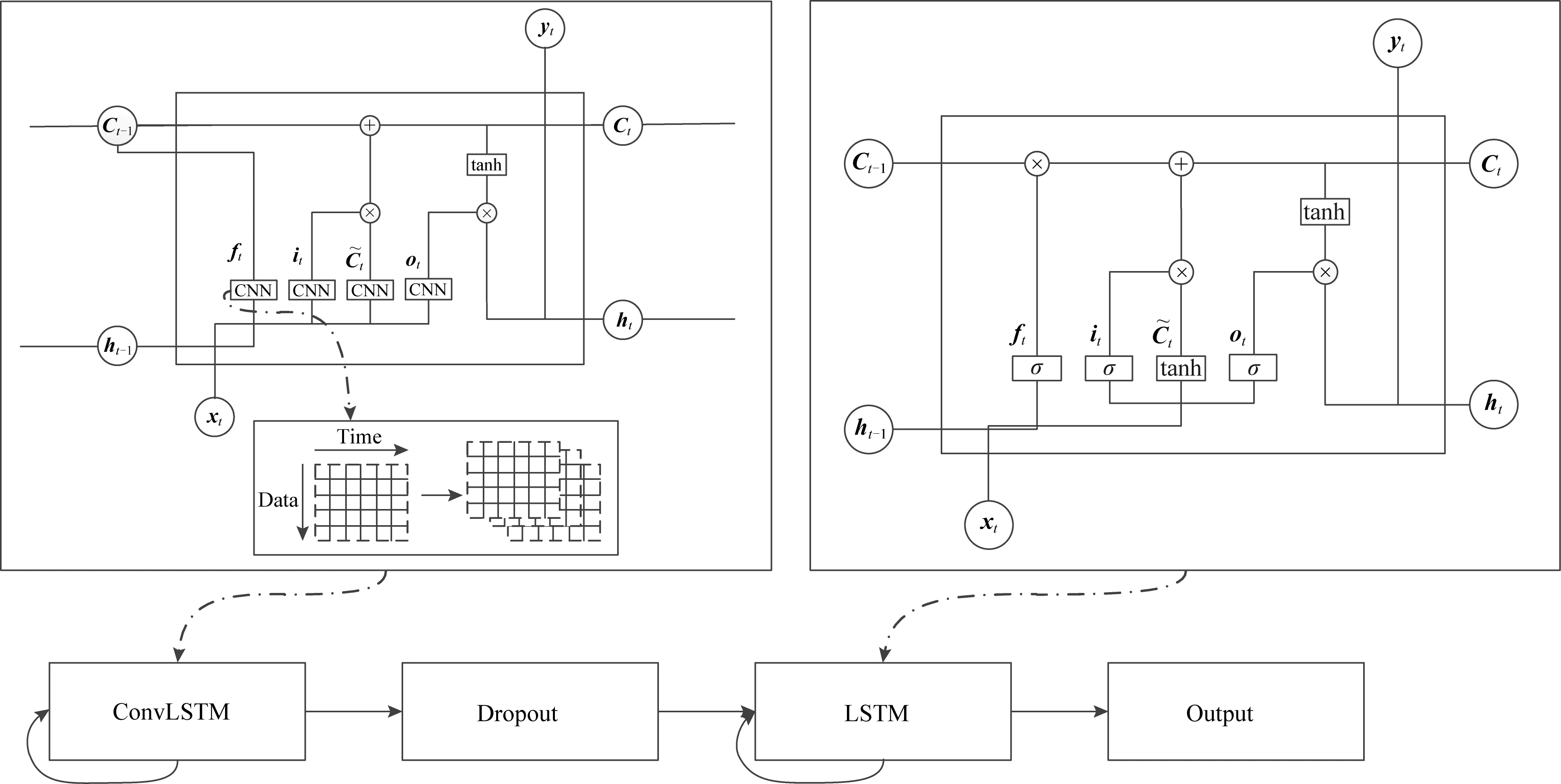
Fig. 4 Stock prediction module图4 股票预测模块
it=σ(Wixt+Uiht-1+bi),
(12)
ft=σ(Wfxt+Ufht-1+bf),
(13)
(14)
(15)
ot=σ(Woxt+Uoht-1+Vo*ct+bo),
(16)
ht=ot∘tanh(ct),
(17)
其中,σ表示sigmoid函数,tanh表示双曲正切函数,xt为输入的股票向量,ct表示内存状态向量,ht是从ct输出的隐藏状态向量.Wi和Ui以及Vi表示权重矩阵,bi为偏差矢量,调节流入存储单元的允许的新的股票价格.ft为遗忘门,控制在该单元中应保留多少信息.ot为输出门,定义了可以输出的信息量.∘表示逐点乘法.
3 实验与结果
本节使用我们的技术构建了用于金融时间序列预测的SCONV混合模型,并且在不同时间长度、不同文本数量的数据集上测试了本文的方法.
3.1 度量标准
本文选用准确率(mean average precision,MAP)、平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)、均方误差(mean square error,MSE)和均方根误差(root mean square error,RMSE),作为模型预测评价指标,计算过程如式(18)~(22)所示:
(18)
(19)
(20)
(21)
其中,预测值为predict_yi,i∈[0,n],真实值为y={y1,y2,…,yn},则RMSE,MSE,MAE和MAPE的取值范围是[0,+),若其越靠近0则表示模型预测性能越好,反之,越差.
(22)
MAP的范围是[0,1],当MAP=1时,即完美模型,股票预测值和真实值之间的误差越小,MAP值越大,模型的预测性能越好,反之,则越差.
3.2 数据集
本文采用的数据集包括2部分:股评信息以及股票交易数据.股票交易数据来源为英为财情网站和锐思数据库,从中选取影响股票价格波动的主要的4个技术指标:开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close).股民评论信息来源为东方财富网站.选用的数据集为阿里巴巴(BABA.us)、平安银行(000001.sh)、格力电器(000651.sz).
其中阿里巴巴(BABA.us)选用的股票交易日期和股民评论日期为2016-01-02—2019-12-31,爬取的股评数目为11 390条;平安银行(000001.sh)选用的股票交易日期和股民评论日期为2016-04-02—2017-09-30,爬取的股评数目为112 307条;格力电器(000651.sz)选用的股票交易日期和股民评论日期为2019-06-26—2019-12-30,爬取的股评数目为27 911条.
随后将这些爬取到的股评数据集先进行预处理.如表3所示,将股价日数据集分为80%的训练集train和20%的测试集test,对应的股评文本按照日期同样进行划分,并分别计算出对应股价日期前1日的情感值、前3日的情感均值与前一周的情感均值,使用训练集train对模型进行训练,随后使用测试集test对模型的各预测指标进行测试并统计.
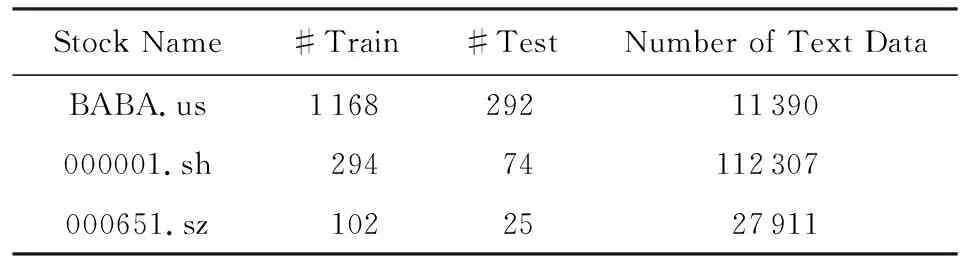
Table 3 Stock Data Set Statistics表 3 股票数据集统计
3.3 实验结果
本节为了验证我们提出的SCONV混合模型的可行性和高效性,实验以阿里巴巴(BABA.us)、格力电器(000651.sz)、平安银行(000001.sh)不同时间段、不同文本评论数据条数作为数据集进行数据预处理,并使用CNN,LSTM,LSTM-CNN方法进行对比实验.各个模型在不同数据集上的评价指标结果如表4所示,其中,SCONV(1),SCONV(3),SCONV(7)分别表示在模型运行中使用了对应股价日期前1天情感值、前3天情感均值、前一周情感均值的结果.
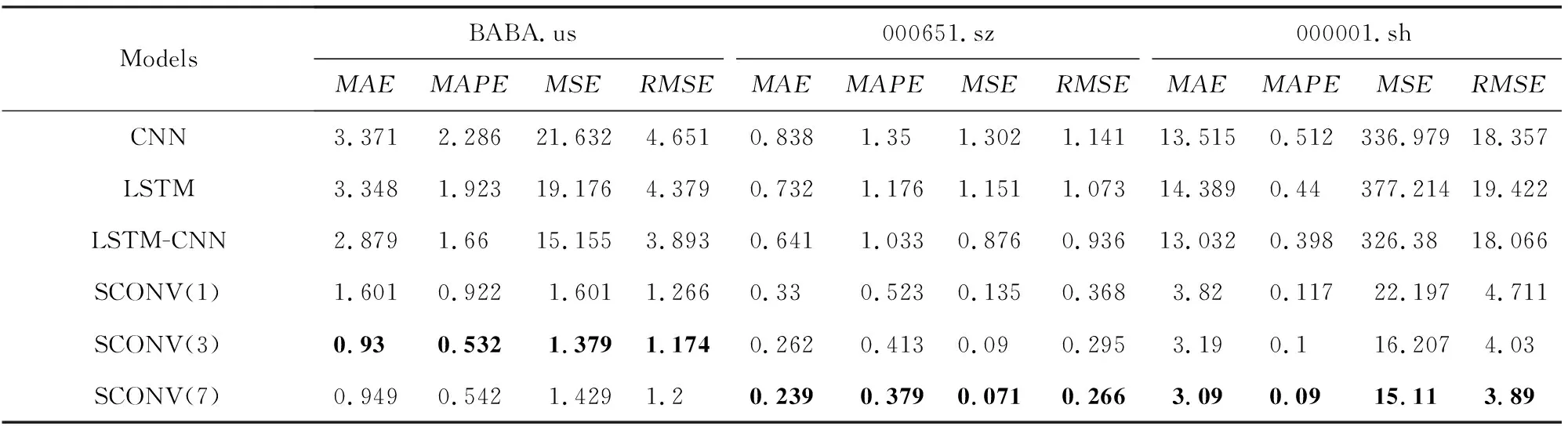
Table 4 Comparison of Experimental Prediction Indexes of Each Model表4 各模型的实验预测指标对比
从表4的结果可以得出,SCONV远远优于其他模型,接下来进行对结果的具体分析.
3.3.1 实验结果综合分析
从表4中可以看出,LSTM模型的预测结果明显比CNN好,MAE,MAPE,MSE,RMSE值更小,说明LSTM模型的预测值更接近真实值,主要是因为LSTM模型克服了CNN模型不能长期有效记忆的能力,对时序数据的预测效果更好.
LSTM-CNN的模型预测结果均小于LSTM,说明作为2个模型的外部叠加,经过CNN提取特征后,可以更好地预测股票价格.
SCONV作为本文提出的模型,预测结果均强于前3个模型,说明相比LSTM-CNN,ConvLSTM作为卷积网络与LSTM内部结合的模型,SCONV可以比仅在外部叠加的LSTM-CNN更有鲁棒性,无论是3年、1.5年还是5个月的数据集,SCONV依旧有着稳定性,相比单纯的LSTM-CNN,由于文本分析的加入,SCONV的预测效果更好.
从结果中也可以看出,使用较长时间的情感均值可以更好地预测股票价格走向,说明股民的情绪对股价走势有着一定缓慢程度上的影响.
3.3.2 实验结果综合比较
为了更加直观地对比SCONV与各个模型的效果差异,本文将各个数据集在不同模型中的测试集输出整合到了一张图表上(SCONV选取了使用了SCONV(7)的结果数值来画图),如图5~7所示,Alibaba(BABA.us)的测试集相对而言最长,随后是平安银行(000001.sh),最后是格力电器(000651.sz),
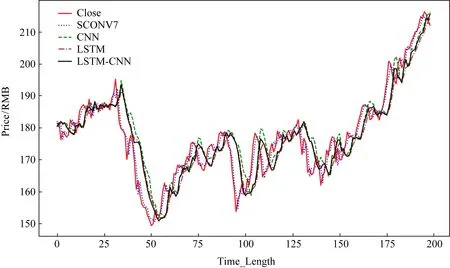
Fig. 5 AliBABA forecast integration chart图5 AliBABA预测整合图
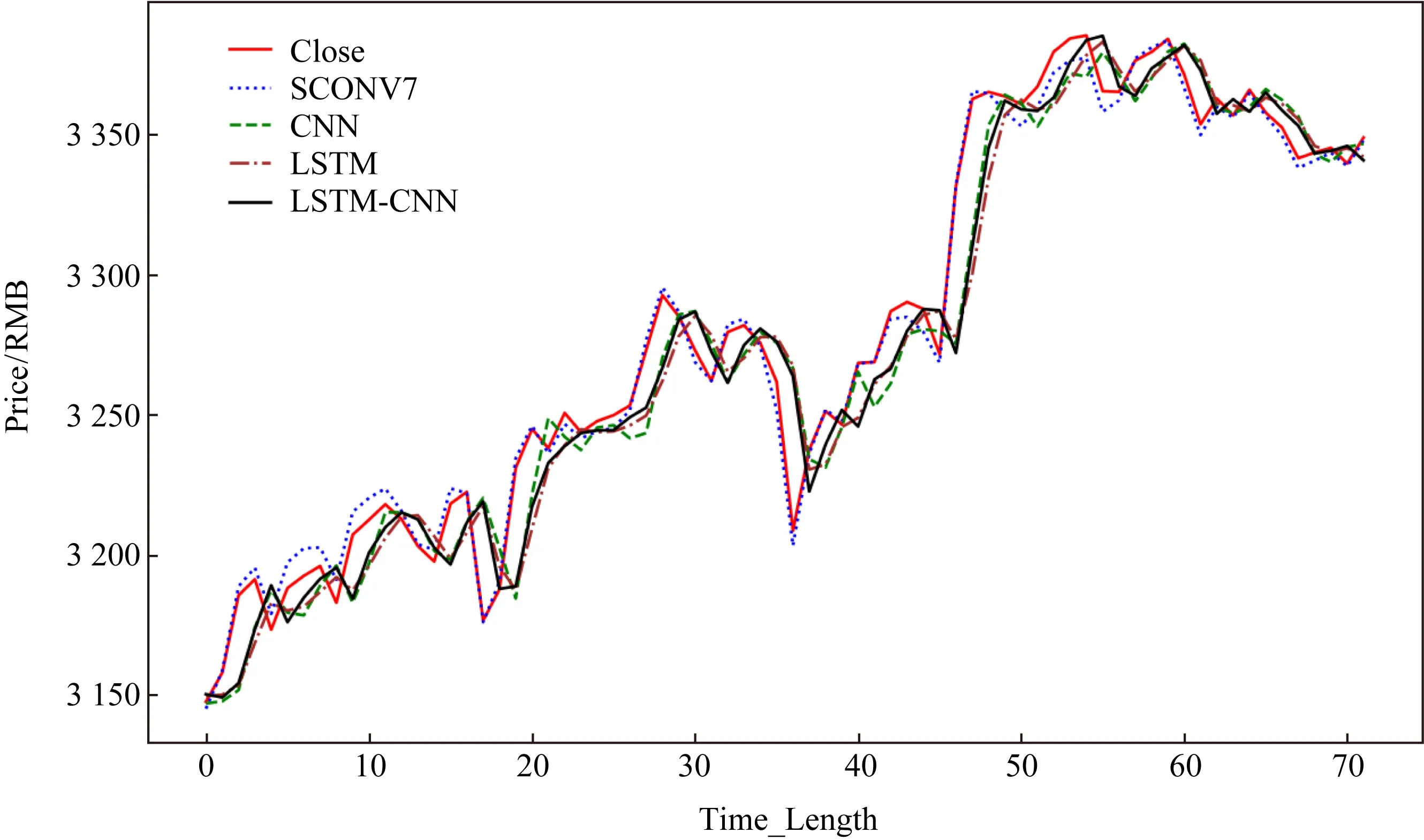
Fig. 6 PingAN bank forecast integration chart图6 平安银行预测整合图
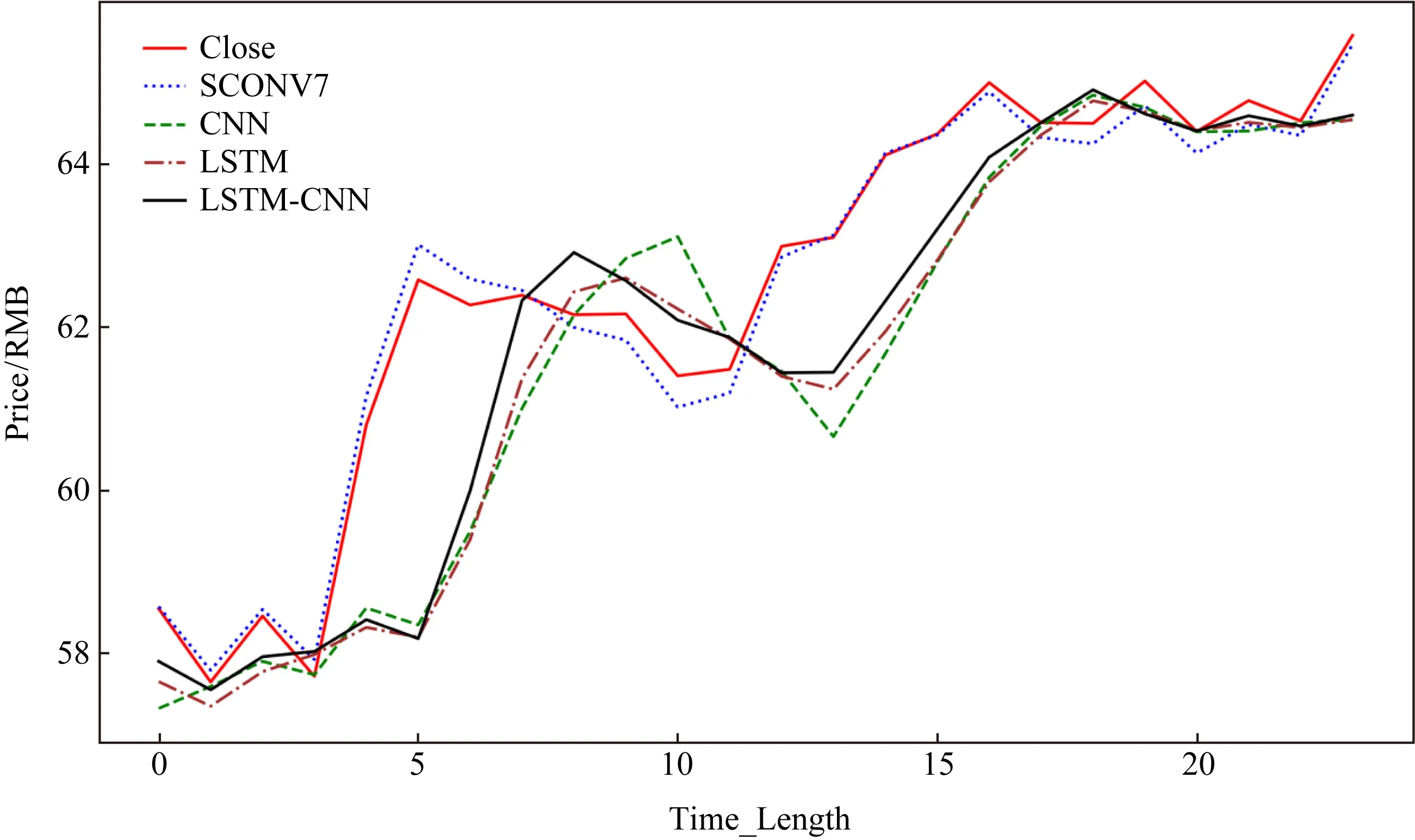
Fig. 7 GeLi forecast integration char图7 格力电器预测整合图
从图5~7中可以看出,无论测试集长短如何,SCONV模型与实际收盘价(Close)的拟合程度始终优于其他对比模型.
3.3.3 稳定性分析
MAP作为本文实验的准确率判别标准,计算过程由式(17)给出,为了更加直观地显示SCONV的稳定性与文本分析在SCONV中的角色地位,本节实验中将3个实验数据的实验集进行时间长度统一化,并统一只使用对应日期前1天的股评情感加入模型训练.
本文实验中3个数据集经过时间长度统一后的MAP如表5所示,每个MAP的范围均由同一个数据集近50次训练得出.
由表5可以进行分析,首先看归一化与原数据集的比对,阿里巴巴(BABA.us)和平安银行(000001.sh)归一化后的MAP小于其均归一化前,并且归一化后的MAP的动荡范围变大,说明实验集的长短对于预测的准确率有一定的影响.
以平安银行(000001.sh)与阿里巴巴(BABA.us)归一化前后作对比,平安银行(000001.sh)在归一化后剩下了3.6万条左右的文本数据,阿里巴巴(BABA.us)在归一化后剩下了0.5万左右的文本数据,可以对比前者的动荡区间变化比后者相对小一些,说明文本数量以及文本分析在SCONV中占有着一定的重要地位.
再来看归一化后有着相同实验集长度的3个不同股票数据集(表5的第2,4,6列),其MPA基本稳定在一个固定区间内,相较于以往传统模型的5~8年数据集,SCONV在5个月的数据集上依旧可以稳定发挥,说明SCONV具有一定的稳定性.

Table 5 The MAP of SCONV表5 SCONV模型的MAP
4 总 结
本文提出的基于情感分析的金融市场趋势预测方法SCONV,在引入文本分析的前提下,通过word2vec进行情绪分析,进行输入神经元与输出层的情感分析,得到分为“积极”、“普通”、“消极”的3种情感分类,并得出每日的情感权重.再使用卷积LSTM进行股价预测.本文采用阿里巴巴(BABA.us)、平安银行(000001.sh)、格力电器(000651.sz)作为实验数据,并且不同以往的股价预测中使用5~8年的数据,本文实验中分别使用了3年左右(BABA.us)、1.5年左右(000001.sh)、5个月左右(000651.sz)较小的样本来进行实验,使用CNN,LSTM,LSTM-CNN等传统模型进行对比,实验结果表明,本文提出的SCONV的预测性能更好,在不同时间长度、不同文本数量的数据集中依旧可以稳定预测,具有一定的鲁棒性.
未来的工作会尝试研究国家政策、市场、突发事件等不确定性因素影响,尝试使用长周期样本以及更小的样本来进一步试验完善模型和参数,提高模型的性能.
猜你喜欢
黄河之声(2022年10期)2022-09-27
农业工程学报(2022年12期)2022-09-09
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
