
基于深度强化学习的机场出租车司机决策方法
2020-08-17 13:59:54王鹏勇陈龚涛赵江烁
计算机与现代化 2020年8期
王鹏勇,陈龚涛,赵江烁
(中国矿业大学数学学院,江苏 徐州 221100)
0 引 言
随着我国航空业的不断发展,机场的人流量不断增加,因而对机场主要交通工具之一的出租车的调度需求也不断增加。对于送客到机场的出租车司机来说,通常有2种选择,排队等待或者空驶离开,出租车司机根据实际情况做出合理决策。而现存的交通调度方法[1-2]往往不是从出租车司机的角度考虑问题,无法很好地衡量排队等待和直接空驶离开的利弊,从而无法使出租车司机的利益最大化。本文以最大化出租车司机的利益为原则,充分考虑排队等待的时间损失、空载离开的油耗损失、机场接客的收益、市区接客的收益等因素,建立合理的司机决策模型。
传统的决策模型比如层次分析方法、模糊综合评价方法等,往往需要专家确定其中关键参数与关键权重的取值,具有很强的主观性。在复杂的环境中,其表现很难令人满意。
近年来,一系列强化学习[3]的方法为决策问题拓宽了方向。强化学习是一种从状态映射到动作的学习,其思想是通过与环境的交互,采集到真实环境中的样本,并从所采集到的样本中学习,以试错的方式学习到最优的策略。强化学习任务通常用马尔可夫决策过程(Markov Decision Process, MDP)[4]来描述。机器处于环境E之中,状态空间为X,其中每个状态x∈X是机器感知到的环境的描述。机器所能采取的动作空间为A,若某个动作a∈A作用于当前状态X上,潜在的转移函数P将使得环境从当前状态按某种概率转移到另一个状态。同时,环境通过潜在的奖项函数R反馈给机器一个奖赏。反复进行这个过程,使机器最终学习到一个最优策略。传统的强化学习算法由于环境的多样性和复杂性,存在学习时间长、收敛速度慢、状态描述困难等问题。为了解决这种问题,DeepMind用神经网络去拟合状态-动作值函数(Q值函数),在强化学习经典算法Q-learning算法中引入了深度学习的思想,提出了深度Q网络(DQN)开创了一个新的研究热点,即深度强化学习[5-6]。目前,深度强化学习在工业制造[7]、机器人控制[8]、算法设计[9]、计算机视觉[10]等方面有着广泛的应用。
本文使用基于深度强化学习的研究策略实现机场出租车司机的决策过程。以司机的状态参数作为DQN的输入,用DQN拟合状态-动作值函数。同时利用经验回放机制和策略目标梯度网络,将包含司机当前的状态、做出的决策动作、决策后的状态、获得的奖励的信息存储到经验回放池中,再定期地以每一个时间步从经验回放池随机提取一组参数,作为训练样本更新策略网络参数,并延时赋值给目标网络。本文根据出租车司机决策问题的特点,作了3点改进:1)根据机场环境和对应的市区环境的不同,采用了不同的策略网络,并让其交叉训练;2)根据状态参量量纲不一致的特点,网络中加入了嵌入层表示;3)根据司机在接到乘客从而处于载客状态之后,在送乘客到达目的地之前的一段时间内一直处于载客状态,司机无法做出动作改变自身状态的特点,推广了Q值Bellman函数。
1 相关工作
1.1 机场出租车调度
以机场为代表的大型交通枢纽的出租车调度问题一直是研究的热点问题。近年来,Yan等[11]提出了一种基于拉格朗日松弛法和子梯度法的启发式算法求解车队路径调度模型,以减少乘客转移次数并完成所有乘客和出租车匹配。Qi等[12]将一天分为几个时段,将动态的出租车调度问题转换为静态调度问题,基于多对多取货和送货问题建立出租车调度模型,经测试效果良好,尤其适用于大规模的道路网络。欧先锋等[13]为减少乘客的等待时间和出租车的空载率,通过K均值聚类算法和矩阵迭代法建立模型使出租车行驶路径最短,取得了一定成效。曾伟良等[14]针对乘客出行需求的动态不确定性的共享问题,着重讨论了自动驾驶出租车在不同路径共享模式下的路径规划,以及共享合乘定价和智能调度系统构建的关键技术。谢榕等[15]运用群智能的思想,提出基于人工鱼群算法的出租车智能调度方法,以实现对出租车资源的全局调度与合理分配。
1.2 深度强化学习
近年来,深度强化学习成为人工智能领域的热门研究方向。Mnih等[16]首次将强化学习的经典算法Q-learning算法与深度学习结合,并且在一些Atari游戏中取得了不错的成果,从而开创了深度强化学习这一研究方向。随后,Mnih等[17]改进之前的工作,在DQN中引入经验回放机制和策略目标网络机制,在多个Atari游戏上都达到了人类级别的水准。van Hasselt等[18]针对在拟合Q网络的过程中会不可避免地存在一些预估误差的问题,提出了引入另一个Q网络来进行决策的方法。文献[19-22]分别在Q值函数、经验回放机制、并行训练、奖励函数等方向做出了改进。文献[23-24]将深度强化学习分别应用到交通路径优化和信号控制方向,展示了深度强化学习广阔的应用空间。
2 模型建立
2.1 环境模拟
在深度强化学习中,机器(出租车司机)在当前的环境中根据当前状态采取动作,从而进入下一个状态,并且同时接收环境给机器的反馈,包括惩罚或者奖励。所以,模型建立的首要条件就是对环境进行模拟,即合理地定义状态、动作、奖励和状态转移。
2.1.1 状态
从司机的利益为出发点,本文建立如下状态参量:
1)机场环境下的状态参量。
机场的航班数及人数:本文为了简单起见,选取每架航班搭乘人数的期望值作为每架航班载乘客数,这样可以把这2个状态参量统一化,作为一个状态参量来处理。“蓄车池”排队车辆数:排队车辆数和机场等待人数是影响司机决策的最直观、最具决定性的因素。
2)市区环境下的状态参量。
市区人流量:当前市区人流量也会影响司机的决策,如果人流量大,司机接到乘客的希望也就大,司机就可能选择空驶回去接客。市区规模:市区规模是影响司机载客收益的因素之一,市区规模决定了订单的里程数,是司机决策要考虑的因素。市区拥堵程度:市区拥堵程度也是影响司机载客收益的因素之一,决定了驾驶状态的持续时间和单位时间的收益。
3)出租车状态参量。
出租车状态有3种:原地等待、空驶以及载客。
4)其他状态参量。
机场与市区的距离:机场与市区的距离也是要考虑的因素,决定了司机空载的惩罚与司机载客的收益。
2.1.2 动作与状态转移
司机可以主动选择的动作只有2个:原地等待和继续空驶。
状态与状态转移如图1所示。
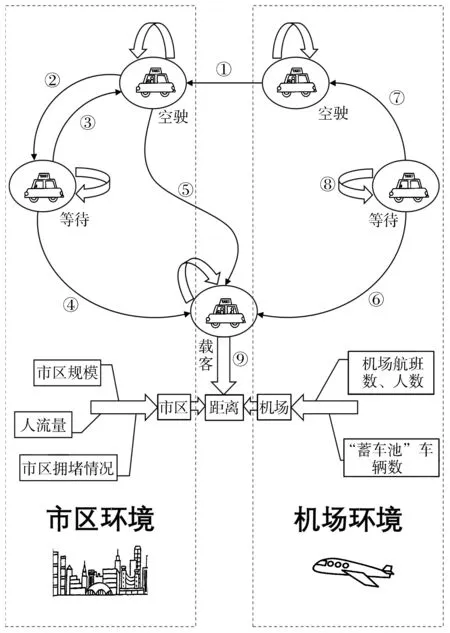
图1 状态与状态转移图
图1中箭头的标号具体解释如下:
①模型假设司机在机场空驶状态时,没有任何几率接到乘客,只能到市区接客,所以此状态转移表示司机从机场空驶到达市区。
②当空驶的惩罚很高时,司机可以选择从空驶状态转移到原地等待状态。
③因为空驶有更高的概率接到乘客(司机可以选择往人流量大的地方接客),司机可以选择从等待状态变为空驶状态。
④表示司机接到乘客,从市区等待状态转移到载客状态。
⑤表示司机接到乘客,从市区空驶状态转移到载客状态。
⑥表示当机场前方排队车辆数为0,而机场等待人数不为0时,司机从机场等待状态变为载客状态。同时,模型默认任何乘客都是前往市区的,所以载客没有机场和市区2种状态。
⑦表示从机场等待状态变为空驶状态,该转移说明了司机放弃在机场载客,选择空驶去平均收益更高的市区。
⑧机场等待状态的自转移,此时相比于上一时刻状态,前方等待车辆数减少,而前方等待人数由减少参量(每辆车可乘人数)和增加参量(降落航班所带来的新的人数)共同控制。
⑨表示从机场载到的乘客都会选择去市区,那么机场订单的里程数可以假设为服从以机场市区距离为均值的正态分布。
2.1.3 奖励函数
1)当司机处于等待状态时,司机既没有载客而获得收益,也没有因为空载而得到惩罚,设计此状态的奖励为0;
2)当司机处于空驶状态时,司机因为消耗汽油而得到惩罚,从而设计其奖励为-1;
3)当司机刚刚处于载客状态时,司机获得的奖励为:
reward=r·tm+a·c·tm
(1)
其中,r代表无拥堵情况下单位时间获得的奖励,tm代表此次订单无拥堵情况下预计行驶时间;c代表城市拥挤参量;a代表由于车辆拥堵、红绿灯等因素导致行驶时间增加而额外获得奖励,通常a要小于r。
2.2 深度强化网络建立
本文以Mnih等在Nature杂志上提出的DQN模型[17]作为基础,针对机场出租车决策问题的特殊性作了3点改进,分别是Double Policy改进、嵌入层表示改进以及推广Q值Bellman函数改进。综合以上改进,提出一种全新的基于深度强化学习的机场出租车决策方法。
2.2.1 Double Policy改进
针对机场出租车决策问题,本文设计2种状态:
机场状态表示为(x1,x2,x3,x4,x5,x6,x7,x8,x9),其中,x1为等待车辆数;x2为等待人数;x3为机场到市区的距离;x4为市区人流量;x5为市区规模;x6、x7、x8分别表示是否等待、是否空载、是否载客,皆为one-hot向量;x9为待行驶的时间步数,只有当x8为1时,才有意义。
市区状态表示为(x1,x2,x3,x4,x5,x6),其中,x1为市区人流量;x2为市区规模;x3、x4、x5分别表示是否等待、是否空载、是否载客,皆为one-hot向量;x6为待行驶的时间步数,只有当x5为1时,才有意义。
因为环境中的2种状态的维度不一致,所以原始的DQN模型无法适用,要对其作出一定的改进。本文的改进方案是分别为每种状态设计一个策略网络和一个目标网络,让2大类共4种网络进行交叉训练,所以此改进方案叫做Double Policy改进。
2.2.2 嵌入层表示改进
在机场状态(x1,x2,x3,x4,x5,x6,x7,x8,x9)之中,x1、x2、x9表示数量大小,x3表示距离大小,其取值范围为(0,+∞),x4、x5是表示程度的量,其取值范围为(0,1),x6、x7、x8为one-hot向量,取值范围为{(0,0,1),(0,1,0),(1,0,0)}。
在市区状态(x1,x2,x3,x4,x5,x6)之中,x6表示数量大小,其取值范围为(0,+∞),x1、x2是表示程度的量,其取值范围为(0,1),x3、x4、x5为one-hot向量,取值范围{(0,0,1),(0,1,0),(1,0,0)}。
由上可见,输入样本数据拥有不同的量纲,不同的形式,直接输入神经网络中进行训练往往很难获得不错的效果。一般来说,需要对数据进行预处理,让其拥有相对统一的形式,但是,预处理数据忽略了神经网络强大的拟合能力。鉴于此,本文不选择预处理输入,而是选择为每个网络加入一个嵌入层,即一个不包含激活函数的全连接层,让神经网络在训练中学得状态的合理表示。图2所示为DQN的网络结构。
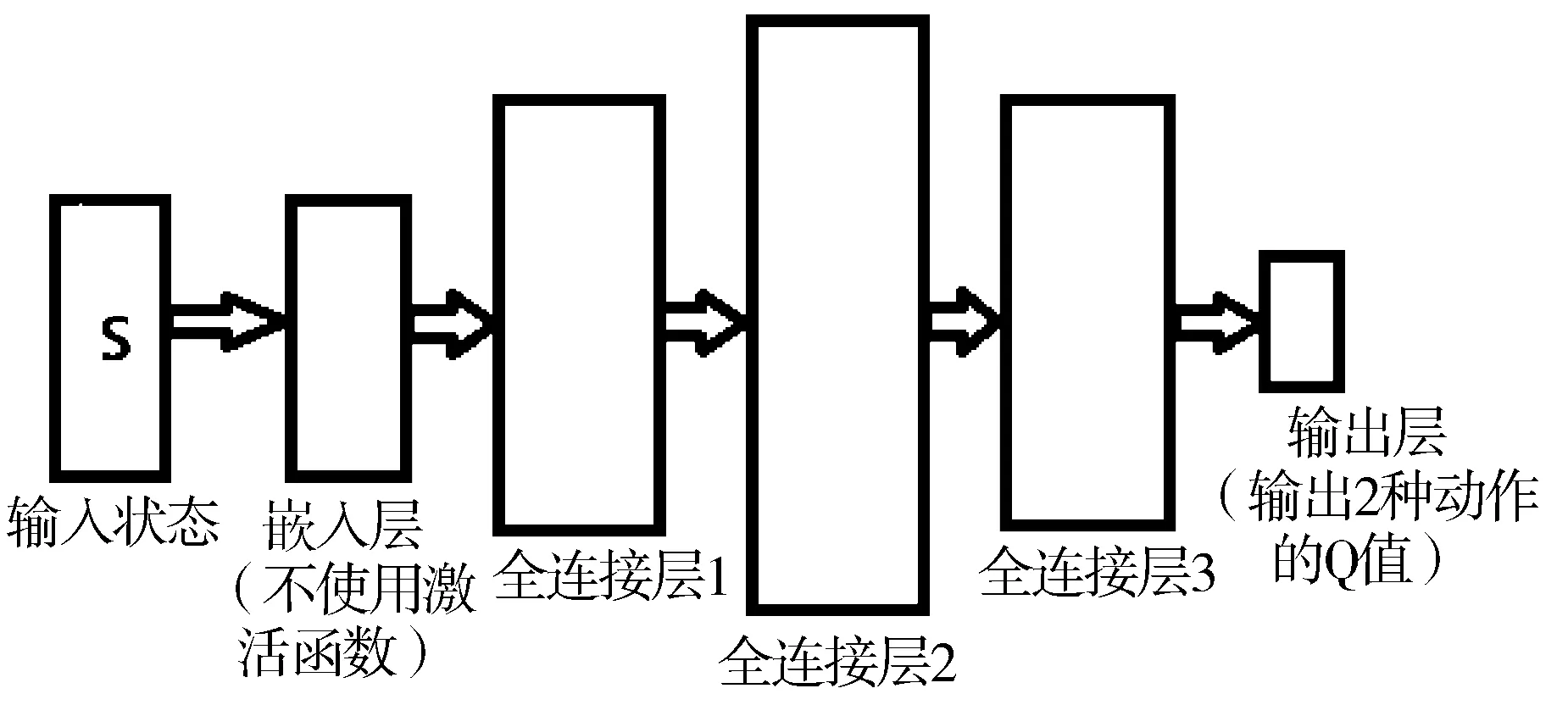
图2 DQN网络结构
2.2.3 推广Q值Bellman函数改进
与一般的强化学习环境不同的是,由于司机在接到乘客从而处于载客状态之后,接下来在送乘客到达目的地之前的一段时间内一直处于载客状态。此时,司机无法做出2.1.2节中所定义的2种动作,所以载客状态是不存在Q值函数的。同时,本文假设司机从机场空驶离开后,在途中无法接到客人,只能返回市区接客,所以在机场空驶状态司机只能做出持续空载的动作,无法做出原地等待的动作,因此机场空驶状态不存在Q值函数。
基于此分析,本文定义以上2种状态为确定性状态。确定性状态不存在Q值函数,确定性状态的状态转移是确定的,即载客状态的下一状态也是载客状态,机场空载状态的下一状态也是机场空载状态。在一定的时间步之后,载客状态因为已经送达乘客到目的地而转变为原地等待状态,机场空载状态因为已经到达市区而转变为市区空载状态。
由于不确定性状态有可能转化为确定性状态,确定性状态在一定的时间步之后又有可能转化为不确定性状态,得到推广的Q值Bellman函数:
(2)
其中,x′为下一个不确定性状态,Δt为2个不确定性状态的时间步数,π为当前的策略,P为状态转移概率,V为状态值函数。
同时,为了最大限度地减小误差,本文使用Huber损失函数。当误差很小时,Huber损失函数表现得像均方误差一样,但是当误差很大时,它就像平均绝对误差——这使得它在Q值的估计时有更强的鲁棒性,对于异常值处理更加稳健。Huber损失的具体形式如下:
(3)
基于以上分析,本文的优化目标函数如下所示:
∑x∈XcLoss{Qcd(x,a)-[r+γΔtmaxaQct(x,a)]}
(4)
其中,Xa、Xc分别表示机场和城市环境的样本集合;机场决策网络Qad(x)、Qat(x)、Qcd(x)、Qct(x)分别表示机场决策网络、机场目标网络、市区决策网络和市区目标网络;Loss函数为式(3)。
2.2.4 DQN模型架构与算法描述
本文在基础DQN模型之上,融合了经验回放机制与策略目标网络机制,将包含司机当前的状态、做出的决策动作、决策后的状态、获得奖励的信息存储到经验回放池中,在每一个时间步定期从经验回放池随机提取一组数据,作为训练样本输入到DQN之中,从而得到Loss函数的具体取值,再使用随机梯度下降法更新策略网络参数,并在一定的时间步之后赋值给目标网络。同时采用ε-贪心策略去平衡探索和利用的收益。训练示意图如图3所示。
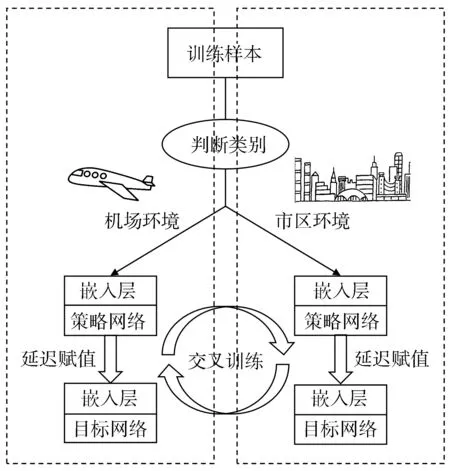
图3 DQN训练示意图
算法1基于深度强化学习的司机决策算法
初始化迭代次数num、时间步T、经验池容量C、机场决策网络Qad(x)、机场目标网络Qat(x)、市区决策网络Qcd(x)和市区目标网络Qct(x)。
fori=1,2,…,num
初始化state,x0
forj=1,2,…,T
ifx0为确定状态转移
x0=next(x0),continue
else
ε-贪心选择动作a
计算奖赏r,下一步状态next_x,和时间步Δt
经验池加入元组(x0,a,r,next_x,Δt)
随机选择经验池的样本集X,X分为Xa与Xc,Xa代表状态为机场的样本集,Xc代表状态为市区的样本集
最小化式(4)
end
end
3 实验结果与分析
3.1 实施准则与细节
本文充分考虑了机场与机场所在市区的环境,建立式(5)所示的影响司机决策的参数:
(5)
其中,p1为当前排队车辆数,p2为车辆减少速率,p3为当前排队人数,p4为平均车辆载客数,p5为到站人数速率,p6为机场到市区的距离,p7为市区规模,p8为市区人流量指标,p9为市区拥堵指标。
本文设置经验回放池容量为32,一批样本量的大小为16,ε-贪心策略的ε阈值初始值设为0.05,即几乎随机地选择动作,随着时间线性增加,最后设为0.95,即以95%的概率选择Q值最大的动作。 同时设置式(1)中r为1,a为0.3 。并且采用PyTorch框架训练网络。由于模型训练存在随机性,本文选择10次训练得到的平均值作为最后的结果。
3.2 实验结果
1)考虑机场排队车辆数p1和机场等车人数p3对决策的影响。
实验模拟上海市与上海浦东国际机场的环境,设置车辆减少速率为10,平均车辆载客数为2,到站人数速率为25,机场到市区的距离为45,市区规模为20,人流量指标为0.8,拥堵指标为0.5。
多次实验的平均结果如表1所示。

表1 DQN决策结果与p1、p3的关系
由表1可以得知,当机场排队车辆数大概大于等车人数时,司机选择空载离开是比较好的选择,而小于时,等待是比较好的选择。不过,这2种选择的期望收益并没有很大的悬殊。
2)考虑机场到市区的距离p6和市区规模p7对决策的影响。
实验分别模拟大型城市机场在远郊(上海与上海浦东机场)、大型城市机场在近郊(上海与上海虹桥机场)、中小型城市机场在远郊(徐州与徐州观音机场)、中小型城市机场在近郊(淮安与淮安涟水机场)的环境。大型城市的人流量设为0.8,中小型城市的人流量设为0.6,机场排队车辆数与排队人数都设为200,拥堵程度设为0.5。
多次实验的平均结果如表2所示。
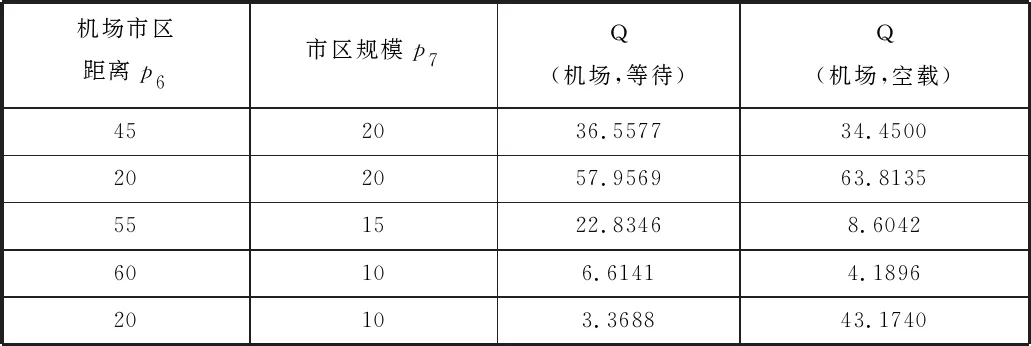
表2 DQN决策结果与p6、p7的关系
由表2第一行、第二行可以得知,对于大型城市,无论机场在近郊还是远郊,司机的期望收益差别不大。而由表2第三行、第四行、第五行可知,对于中小型城市,当机场在远郊时,等待的收益大于空载机场在近郊时,空载的收益远大于等待。
3)考虑市区人流量p8和市区拥堵程度p9对决策的影响。
为了尽可能地减少其他参变量对模型决策产生的影响,本文设置机场排队车辆数与排队人数同为200,车辆减少速率为10,平均车辆载客数为2,到站人数速率为25,机场到市区的距离为45,市区规模为20。
多次实验的平均结果如表3所示。
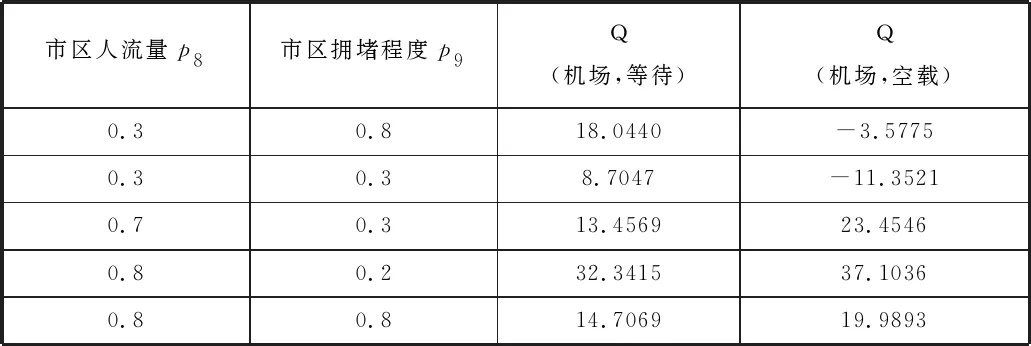
表3 DQN决策结果与p8、p9的关系
由表3可以看出,当人流量很低、拥挤程度很高时,选择等待是比较好的选择,而当人流量很高、拥挤程度很低时,选择空载是比较好的选择。当人流量和拥挤程度都较高时,模型倾向给出空载的选择,当人流量和拥挤程度都很低的时候,模型很确定地给出了等待的选择。
4)综合考虑各种参数对决策的影响。
为了充分考虑各种因素对司机决策的影响,本文在查阅有关城市人口、机场地理位置、机场人流量等数据后,模拟了4种典型的机场环境,分别为大型城市机场在远郊(上海与上海浦东机场)、大型城市机场在近郊(上海与上海虹桥机场)、中小型城市机场在远郊(徐州与徐州观音机场)、中小型城市机场在近郊(淮安与淮安涟水机场)。根据实际数据设置式(5)中环境参量的具体取值。
多次实验的平均结果如表4所示。
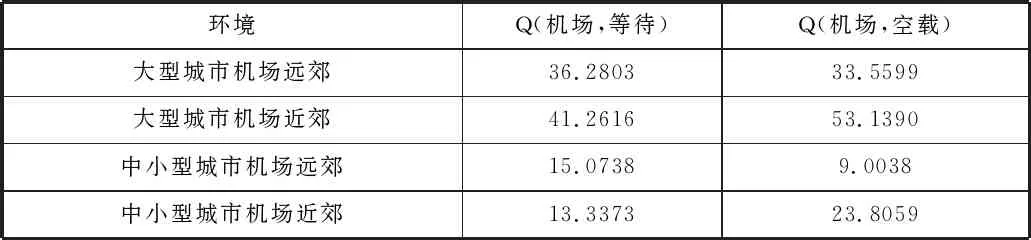
表4 典型环境下的DQN决策结果
由表4可知,大型城市的期望收益明显大于中小型城市,机场在近郊的收益明显大于机场在远郊的收益。当机场在远郊时,大型城市等待或者空载的期望收益相差不大,中小型城市等待的收益明显大于空载。当机场在近郊时,无论是大型城市和还是中小型城市,空载的收益远大于等待的收益。
3.3 嵌入层评估
嵌入层表示是利用神经网络去学习原始输入的合理表示,这种合理的表示等价于对输入进行合理的预处理,从而使得网络训练更加稳定。因此,为了评估嵌入层的效果,本文使用一个不带嵌入层的DQN作为对比,在大型城市机场远郊的环境中分别多次训练2种网络,计算2种网络输出Q值的标准差,实验结果如表5所示。

表5 嵌入层改进评估
由表5可知,加入嵌入层的DQN网络的输出结果的标准差明显减小。嵌入层改进方案使得DQN网络训练时更加稳定,显著降低了DQN输出结果由于随机性而产生的波动。
4 结束语
本文针对以机场为代表的大型交通枢纽出租车调度困难的问题,以最大化司机利益为原则,使用了深度强化学习的有关算法,并且作出了3点创新性的改进,给出了不同情况下司机做出不同决策的期望收益,从而帮助司机选择排队等待接客或者直接空驶离开,有效地完成了出租车自主调度的过程。不过,由于深度强化学习本身存在的一些问题,比如样本利用率低、过拟合严重、奖励函数设计困难等因素,模型训练的稳定性还有待提高。
猜你喜欢
课堂内外(小学版)(2025年2期)2025-02-27 00:00:00
商用汽车(2021年4期)2021-10-13 07:15:52
幼儿画刊(2018年10期)2018-10-27 05:44:38
文理导航(2018年9期)2018-08-16 17:38:46
现代经济信息(2016年34期)2017-08-12 10:06:13
中外玩具制造(2016年5期)2016-11-06 09:41:47
发明与创新(2016年16期)2016-08-21 13:56:12
发明与创新(2016年21期)2016-05-17 03:57:24
太空探索(2015年5期)2015-07-12 12:52:33
大众投资指南(2015年7期)2015-05-30 10:48:04
