
基于可变权重损失函数和难例挖掘模块的Faster R-CNN改进算法
2020-08-18 07:56:54李金耿钱惠敏项文波
计算机与现代化 2020年8期
施 非,邱 臻,韩 勤,李金耿,钱惠敏,项文波
(1.河海大学能源与电气学院,江苏 南京 211100; 2.浙江华云信息科技有限公司,浙江 杭州 310008;3.南京理工大学自动化学院,江苏 南京 210098)
0 引 言
目标检测是计算机视觉研究领域中的一个研究热点,在交通监控、图像分析、自动驾驶等方面有着广泛的应用。目标检测的主要任务是从静态图像或动态视频中检测并定位感兴趣的目标对象,即识别并定位感兴趣目标。目前,基于深度卷积神经网络的目标检测算法[1]已成为目标检测领域的研究热点。常用的基于卷积神经网络的目标检测算法包括基于区域提议的两阶段目标检测算法和基于位置回归的一阶段目标检测算法。前者的代表性算法主要包括R-CNN[2](Region-based Convolutional Neural Network)、Faster R-CNN[3]、Mask R-CNN[4]等;后者的代表性算法主要包括YOLO[5](You Only Look Once)、SSD[6](Single Shot Multibox Detector)等。两阶段目标检测算法得益于预先的区域提议,检测精度较高,一阶段检测算法则检测速度较快。
在目标检测中,训练算法所用的图像通常会事先标出所含目标的类别和区域,训练时会在图像中采用区域提议或基于锚机制的方法提取一系列候选区域[7],且根据指标IoU(Intersection over Union),即候选区域和标记的目标区域的交集与并集比是否超过给定的阈值(一般取0.5)确定为正样本(IoU0.5)或负样本(IoU<0.5)。在训练样本集中,通常会出现样本数据的类间不平衡问题[8]和简单样本-难分样本数量不平衡问题[9-10](指训练数据集包含过量简单样本)。样本数据的类间不平衡问题包括:1)不同类别目标的训练样本数量不平衡[11],即有些类别的训练样本数量较多,而另一些类别的训练样本数量较少,从而影响目标分类的准确性;2)基于锚机制生成的正、负锚样本数量的比例悬殊[12],从而影响目标检测的准确性;3)背景像素的数量远大于前景像素的数量,从而影响目标分割的准确性。而简单样本-难分样本数量不平衡问题是指训练样本中的易识别样本过多,难识别样本相对很少,此种情况下,会导致模型在训练过程中稀释有效梯度[13],从而影响算法的检测准确率及泛化性能。样本数据的类间不平衡问题和简单样本-难分样本数量不平衡问题通常会同时出现,并导致模型退化。
向鸿鑫等[14]综述了在分类问题中存在不平衡数据的处理方法,分为预处理方法和挖掘方法。这些方法分别从数据分布及分类器选择角度出发,改善基于不平衡数据的分类器的分类性能。在基于深度神经网络的目标检测算法中,数据的特征表示学习和分类是一个整体过程,通常考虑从修改数据分布角度改善数据不平衡引发的问题。
本文研究现有目标检测算法解决数据不平衡引发问题的方法,并将它们分为2类:基于损失值的难例挖掘方法[1,5]和基于可变权重损失函数的数据平衡方法[6,15]。基于对2类方法的分析比较,本文提出结合2类方法的优势,更好地改善数据不平衡导致的检测准确率低的问题。本文将这种思想运用在Faster R-CNN目标检测算法中,具体地,修改Faster R-CNN的损失函数为可变权重损失函数,且对前向传播的样本损失值排序并挖掘难例加入反向传播,继而提高检测准确率。在不同数据集和不同基础网络下的实验结果表明,本文提出的Faster R-CNN改进算法可有效提高检测准确率。
1 目标检测中的不平衡数据处理方法
基于损失值的难例挖掘方法[16-17]和基于可变权重损失函数的数据平衡方法通过不同的方式处理不平衡数据。前者对训练样本的损失值排序,并根据规则挖掘损失值较大的难分样本;后者通过给每个样本对应的损失函数施加可变权重[14,18-19]的方法解决数据不平衡问题。
难例挖掘的思想在不平衡数据的处理方法[14]中已被使用,例如上采样方法[20]、训练SVM[21-22]时所使用的Bootstrapping(拔靴法)[23-24]、基于Boosting的挖掘算法[25-26]、代价敏感的挖掘算法。但这些难例挖掘方法通常需要先训练网络,并在训练完成后固定网络,使用新的样本继续训练,较大程度地增加了网络训练的时间成本。而在基于深度神经网络的目标检测方法中,通常采用在线难例挖掘方法,使得在提高网络性能的同时,有效控制训练网络所需时间成本的增加。
在基于深度神经网络的目标检测方法中采用的在线难例挖掘方法通常是基于训练损失值实现的,即在模型训练过程中,对训练样本的损失值进行排序,并根据规则挖掘难分样本(难例),将难例加入反向传播更新网络参数。常用的方法有OHEM[1,27](Online Hard Example Mining)和OHNM[5](Online Hard Negative Mining)。OHEM提出将每个batch的样本输入网络模型,并将当前损失值进行排序,选出若干最大的损失值对应的样本作为难分样本,并基于这些难分样本反向传播更新网络参数。在这种方法下,对应损失值较小的简单样本得到了抑制,从而可改善简单样本-难分样本数量不平衡问题。OHNM是OHEM的改进,在根据损失值对难分样本进行排序的基础上,以所有正样本的数量为参照,按照正负样本比例为1∶3选取负样本。OHEM既可以改善简单样本-难分样本数量不平衡的问题,又可以通过固定比例选取合适的负样本数量,改善正、负样本数量不平衡的问题。
基于可变权重损失函数的数据平衡方法旨在通过损失函数的可变权重的调节平衡数据。代表性的损失函数有Class Balance Loss[15]和Focal Loss[6]。基于Class Balance Loss的方法,给每一类目标分配一个可变权重,当某一类目标的样本数量增加时,其对应的权重逐渐减小,以达到抑制某类训练样本的数量过量的问题。因此,该方法能处理引言中说明的第一种类间不平衡问题,即不同类别目标的训练样本数量不平衡。基于Focal Loss的方法,引入了2个可变权重,一个权重用以调节正负样本的比例以改善类间不平衡问题,另一个权重则用来改善简单样本-难分样本的数量不平衡问题,分别处理了正负样本不平衡和过量简单样本问题。
本文对上述4种常用的不平衡数据处理方法的性能进行比较,如表1所示。

表1 不平衡数据处理方法性能对比
2 基于可变权重损失函数和难例挖掘模块的Faster R-CNN目标检测改进算法
Faster R-CNN算法在训练时采用随机抽样的方式选取正负样本。当训练数据集中简单样本-难分样本的数量不平衡(即训练数据集包含过量简单样本)时,以随机方式抽取样本会导致难分样本被抽取的概率明显小于简单样本,从而使得深度神经网络学习抽取的特征表示更偏向于简单样本,继而使得模型训练结果不是最优,且泛化性能较弱。此外,Faster R-CNN算法在区域提议部分生成的正样本数远小于负样本数,导致训练样本的类间不平衡。针对这2类数据不平衡问题,本文提出修改Faster R-CNN的损失函数为可变权重损失函数Focal Loss,且在网络中增加难例挖掘模块,选取损失值较大的前若干个样本(每个批次取一半的样本)作为难例,加入样本集进行反向传播,具体的网络结构如图1(b)(见2.2节)所示。
2.1 可变权重损失函数
Faster R-CNN算法采用的分类损失函数L为[2]:
(1)

(2)
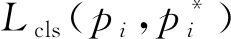
它是一种对数损失函数,特别地:
(3)
训练过程中,如果正样本的预测输出概率越大,对应的损失Lcls则越小;如果负样本的预测输出概率越小,对应的损失Lcls也越小。也就是说,简单样本对应的损失函数小。如果训练数据集中存在大量的简单样本,则网络参数的收敛速度较慢,并且可能无法逼近最优。另一方面,正负样本的损失在网络参数的更新过程中作用无差别,如果训练样本集中,负样本的数量远大于正样本的数量,则网络参数更偏向于负样本的特性。
因此,本文引入Focal Loss损失函数[9]计算每个样本的损失,表达式为:
(4)
其中,α[0,1],0,可调节样本数据中正负样本数量不平衡,及简单样本-难分样本数量不平衡问题。对于简单正样本,其预测概率pi较大,通过增大,(1-pi)会大大减小,降低权重;同样,对于简单负样本,预测概率pi较小,通过增大,pi会大大减小,降低权重,这是对于简单样本的抑制过程。α(1-pi)与(1-α)pi直接控制着正负样本对总损失的权重,直观上,α取较大值可以降低负样本的权重,但是(1-pi)和pi也在抑制负样本的权重,根据实验经验,反而要减小α值来平衡正负样本权重,本文实验中参数α、分别取0.25和2。
2.2 难例挖掘模块
虽然Focal Loss可改善简单样本-难分样本数量不平衡问题,但为了提高网络的检测性能,本文进一步提出在原Faster R-CNN网络结构中增加难例挖掘模块(见图1(b)中的Hard Example Miner模块)实现难例样本的选取,以进一步平衡简单样本-难分样本的数量比。首先,网络前向传播所有区域提议部分生成的候选区域样本,并得到其分类损失;然后,按损失值从大到小的顺序排列样本,并选取前若干个损失值较大的样本(每个batch取一半的样本),送入网络ROI池化层进行传播,更新网络参数。
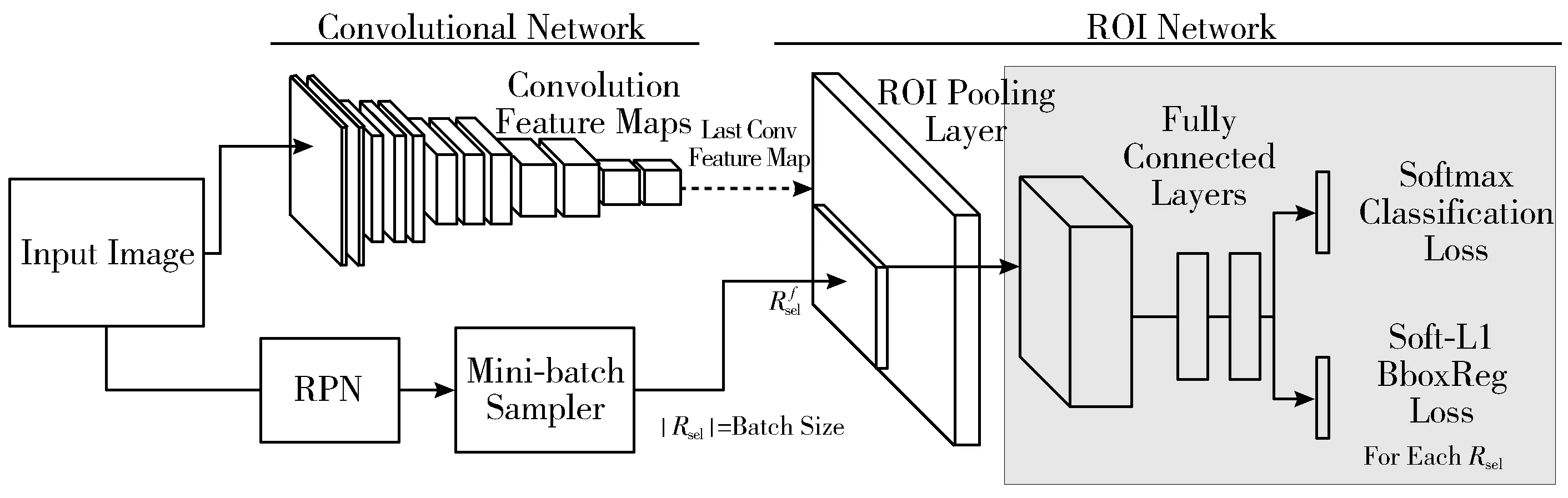
(a) Faster R-CNN
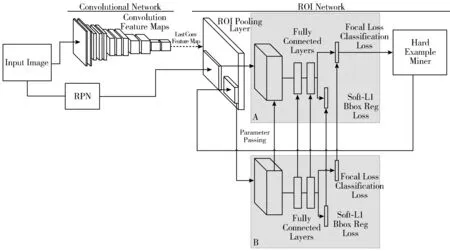
(b) 本文算法图1 Faster R-CNN与本文算法的网络结构对比
在网络中增加训练模块,不可避免地会增加训练时间,为了尽可能降低训练时间成本的增加幅度,本文分别从2个方面着手:一是仅挖掘分类损失值较大的一部分样本作为难例,重新训练网络;二是在网络训练中使用了A、B这2个相同子网络,如图1(b)所示。子网络A用于前向传播,计算损失值,子网络B根据损失值排序选择难例样本,并将这些难例样本进行反向传播,更新网络参数。
图1给出了本文改进算法与原Faster R-CNN算法的网络结构对比图。由图1可知,本文算法的改进之处包含以下几个方面:1)在分类部分,采用Focal Loss函数代替了原网络中的Softmax损失函数;2)引入了难例挖掘模块;3)在训练网络中增加了与子网络A相同的子网络B,实现难例选择及难例的反向传播。由图1可知,通过在分类部分引入Focal Loss损失函数,本文提出的基于OHEM的Faster R-CNN改进算法调整了网络结构,优化了训练方法,并在不改变数据集的情况下充分训练了数据集中的难分样本,提高了检测精度。本文的改进算法具有以下优点:1)通过引入可变权重损失函数和难例挖掘模块,改善了数据不平衡问题,提高了算法的平均检测精度;2)子网络B的引入,使得难例的选择和训练无需手动操作,实现了端到端的训练[28];3)本文提出的不平衡数据改进算法思想可拓展至其他基于深度神经网络的目标检测算法中,泛化能力较强。
3 实验与结果分析
为了验证本文改进算法的有效性,进行了2组实验,分别在不同数据集以及不同基础网络上,对比本文算法与Faster R-CNN算法的性能。
3.1 不同数据集上的实验对比及结果分析
Pascal VOC为图像分类、检测和分割任务提供了一套标准化的数据集,包括VOC 2007数据集和VOC 2012数据集。数据集中包含person、dog、car等20类生活中的常见目标。VOC 2007中包含9963幅标注过的图片,由train、val、test这3个部分组成,共标注出24640个物体。对于检测任务,VOC 2012的train、val、test包含2008—2011年的所有对应图片,其中train、val共计11540幅图片,27450个物体。
本文在相同的实验平台Caffe下,分别在Pascal VOC 2007数据集和Pascal VOC 07+12数据集上进行Faster R-CNN及本文算法性能的对比实验。
表2给出了采用Pascal VOC 2007的训练集训练不同算法,进行70000次迭代后,对Pascal VOC 2007的测试集进行测试得到的20类目标的检测精度对比结果。由表2可知,70000次迭代训练下,本文提出的Faster R-CNN改进算法(简记为Focal+OHEM+Faster R-CNN)对20类目标的平均检测精度(mean Average Precision, mAP)达到了69.8%,较原算法提高了0.9个百分点,较仅采用OHEM改进Faster R-CNN算法(简记为OHEM+Faster R-CNN)提高了0.5个百分点,较仅采用Focal Loss函数改进Faster R-CNN算法(简记为Focal+Faster R-CNN)提高了0.5个百分点。表3给出了采用Pascal VOC 07+12的训练集训练不同算法,并进行70000次迭代后,对Pascal VOC 2007+12的测试集进行测试的结果对比。由表3可知,改进算法对20类目标的平均检测精度达到了73.2%,较原算法提高了1.7个百分点,较仅采用OHEM改进Faster R-CNN算法提高了0.9个百分点,较仅采用Focal Loss函数改进Faster R-CNN算法提高了1.1个百分点。

表2 70000次迭代下使用Pascal VOC 2007数据集训练各算法的目标检测精度结果 单位:%
表4为2种数据集在70000次迭代下训练时间和FPS(Frame Per Second)指标的对比结果。可以看出,网络结构的改变,使得本文的改进算法在训练时间上增加了2 h左右,但检测速度FPS的变化很小。

表4 训练时间、FPS对比表
此外,本文给出了检测结果对比图,如图2所示。由图2可知,本文提出的基于可变权重损失函数和难例挖掘模块的Faster R-CNN改进算法在数据集Pascal VOC 2007和Pascal VOC 07+12上训练所得的检测效果图都较原Faster R-CNN算法检测出了更多的目标。

(a) Faster R-CNN检测结果图

(b) 本文改进算法检测结果图图2 原算法与改进算法的检测结果对比
3.2 不同基础网络下的实验对比及结果分析
为了进一步验证本文提出方法的有效性,将Faster R-CNN算法的基础网络VGG-16更换为更深的网络ResNet-101,并分别以Pascal VOC2007和Pascal VOC2007+12为训练集,以Pascal VOC2007为测试集,进行对比实验。实验结果如表5所示,在Pascal VOC2007数据集上训练平均检测精度提高了1.3个百分点;在Pascal VOC2007+12数据集上训练平均检测精度提高了1.5个百分点。
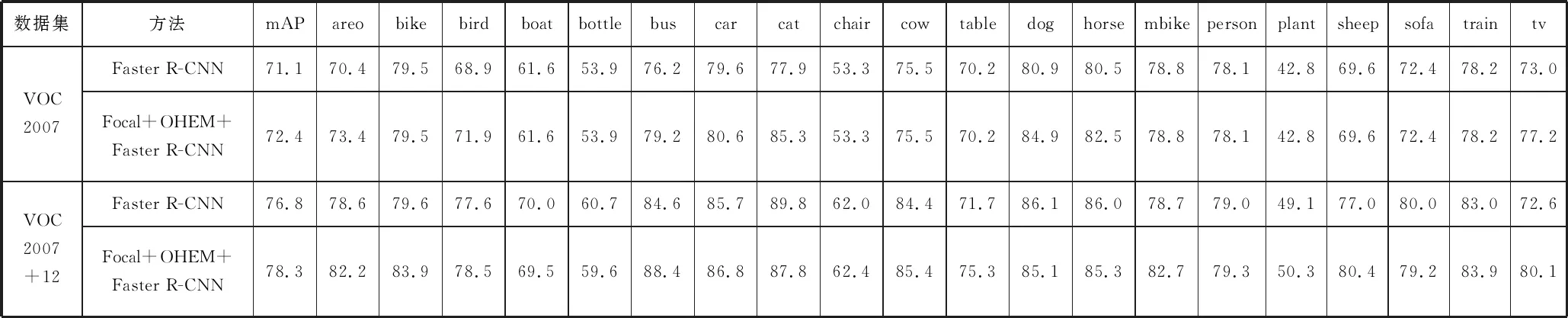
表5 70000次迭代下ResNet-101基础网络下目标检测精度结果 单位:%
更进一步地,图3给出了采用ResNet-101基础网络时2种算法的检测结果对比,由图3可看出,多目标重叠时本文的改进算法有着更好的检测效果。

(a) Faster R-CNN检测结果图

(b) 本文改进算法检测结果图图3 ResNet-101基础网络下检测结果对比
4 结束语
基于深度卷积神经网络的目标检测算法已成为目标检测领域的研究热点。训练数据集中存在的类间不平衡问题和简单样本-难分样本数量不平衡问题,影响了目标检测算法的性能。本文针对这2个问题,提出了一种基于可变权重损失函数和难例挖掘模块的Faster R-CNN改进算法。本文将改进算法与原算法在不同情况下进行对比,包括不同数据集和采用不同的基础网络,实验结果表明了本文所提出算法的有效性。后续将进一步研究提升网络训练效率和检测速度的方法[29]。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
当代陕西(2020年17期)2020-10-28 08:18:18
今日农业(2019年15期)2019-01-03 12:11:33
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
