
信息技术产业创新社群网络研究和模拟仿真
2020-08-13 02:43:00□曹平陆松,2
管理现代化 2020年4期
□ 曹 平 陆 松,2
(1. 广西大学 商学院, 广西 南宁 530004; 2. 中国移动 广西公司, 广西 南宁 530028)
一、引 言
创新是知识经济的主要特征,研究范围包括组织创新、服务创新、管理创新、产业创新等领域。产业创新系统作为一种系统性研究产业创新发展规律、动力机制和绩效的手段,近年来取得了很多成果。
随着互联网时代到来,经济社会已进入复杂性网络领域。经济系统中的行为人相互之间显示出强烈的非线性特征;信息和知识的交互和闭环反馈在以信息技术为代表的现代化技术中高度重要,行为人不断从正向和负向反馈中学习,技术的高度迭代使得传统的产学研合作模式发生了极大的改变。企业为了匹配高速变化的市场环境和商业模式,追求快速进出市场,技术导向的企业中传统的层级管理方式更多转为问题解决或项目小组决策的工作方式。作为一种社会系统,产业创新系统本质上是各种不同个体和组织之间的模式化关系网络的统一呈现,因此,从网络角度着手,对产业创新系统进行研究是可行的和有必要的。
复杂网络是指具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质的网络。当前常见的复杂网络包括规则网络、随机网络、小世界网络、无标度网络等。
国内基于复杂网络对创新进行的研究包括小世界特性创新孵化网络[1],产学研合作创新复杂网络[2],利益驱动的创新网络合作行为演化影响[3],极少数大度数中枢节点对复杂网络整体运行效率[4],市场导向和多主体协同影响下的复杂网络创新扩散[5]等。随着技术复杂度增长,有良好组织的网络成为创新成功的关键,推动创新网络自组织化,以及技术组织去中心化是其中的关键[6]。Johnsen和Ford[7]研究了复杂网络中的协同创新管理。Mccullen等[8]构建了一个多参数的复杂网络创新扩散模型,把行为人作为网络节点,用变量表示行为人对创新的采纳程度,网络节点状态被邻居节点影响。其他研究包括复杂网络中自主学习知识获取的动力学机制[9],R&D复杂网络的地理协作关系及效率[10],复杂网络优化演化算法[11]等。Majchrzak等[12]指出,不同的网络拓扑和结构形状及与此匹配的网络密度、路径长度、网络集聚程度等关键变量与组织创新绩效密切相关。在小世界网络和随机网络的研究基础之上产生了随机聚类网络的研究,例如社交网络和生物网络往往呈现出模块化的结构特性,可以称为社群[13]。社群的节点集合满足一个基本条件,属于同一个社群的节点有许多相互连接的边,而不同的社群由相对较少的边相连接。创新系统是一个由相互关联的子单元构成的系统,子单元构建的微结构能够扩散到更大的结构之上,因此研究创新系统社群网络,对于辨析系统中的创新扩散效率和系统动力机制具有意义。Gulati等[14]将组织间的网络存在归纳为局域连接和桥接两种类型,认为网络中多个社群通过桥接关系构成的小世界网络的进化模式呈现倒U型,在局域连接和桥连接的双重作用下,网络能够适度获取异质性资源,促进整体组织创新。Dahlander和Frederiksen[15]发现社群之间的桥接存在连接成本,较高的成本将会抑制整体网络的创新绩效。Sytch等[16]指出社群网络内部紧密连接,外部稀疏的结构与创新绩效的提升正相关,并进一步研究了社群间桥接形成的影响因素[17]。魏龙和党兴华[18]从组织间关系的非对称视角探究网络社群动态变化对双元创新的差异性影响,认为社群动态的二维变化对突破式创新具有正向影响,与渐进式创新呈现倒U 型关系。已有研究集中于网络结构和特性对创新能力和绩效的影响,通常假定了网络的形状并假设其参数来开展,对于网络实际的构建,针对特定产业的特点来设计网络中的节点的关键属性和网络中的权值,以及关键变量对网络形状和特性的影响缺少研究。
二、研究假设和方法
信息技术产业是从事信息技术设备制造以及信息的生产、加工、存贮、流通与服务的新兴产业部门。全球各国的信息技术产业发展都体现出高速迭代、涌现式创新的特点,以互联网、人工智能、物联网、云计算、大数据为代表的创新技术不断涌现,推动信息产业向纵深发展。将信息技术产业创新行为视为一个复杂组织网络,融合应用创新系统的相关研究和复杂性科学的相关概念,研究网络的构成及要素,网络的特征(例如形状、拓扑等)以及网络的动态(例如演进和变化)。在此基础上进一步研究知识网络构建、集群企业知识溢出、隐性知识传播和创新绩效,对于更好地辨析产业的创新动向和驱动因素具有重要的意义。
(一) 研究假设
复杂网络可以用图来表示,图上的节点代表实际系统中的个体,边代表节点间的相互作用。度指节点所连接的边的数量,在一定程度上反映了节点的重要性。通常具有大度数的节点在系统动力学中具有比小度数节点更加重要的地位。
现实网络例如引文网络、互联网、细胞网络等都具备明显的无标度网络特征,即网络中的极少数节点与非常多的节点相连,拥有很高的度数,网络的度服从幂律分布。复杂系统经过自组织最终生成无标度网络,主要是因为生长和择优连接这两个特性。生长即网络的节点数在不断增加,对于开放性的网络,新节点的加入将使得网络规模不断扩大。择优连接则是指新的节点加入网络时,往往更倾向于与那些具有较高度数的“大”节点相连接,由此将导致网络中个体间的差异逐渐放大。例如在互联网创新领域,新的网站会优先连接到谷歌或者百度等重要的节点上,以便形成更好的传播效应,新的APP应用会优先连接到苹果APP Store、Google Play或者微信,以减少初期的传播和宣传成本。Powell等[19]对美国生物科技产业网络(482家企业样本)1988—1999年网络演变进行拓扑分析、Pajek网络呈现和统计分析等实证研究,发现择优连接现象在网络演化全过程中均显著存在。
产业创新系统的行为人主要包括产业链上的企业、大学、科研院所、中介服务机构、政府部门等,产业创新系统的环境主要包括国家的宏观政策和公共服务平台等。创新系统的本质是研究创新知识如何有效地在行为者之间生成、选择、交互和改进,以形成新的产业机会和市场模式。产业创新系统则是根据不同的产业的技术知识特点进行研究。不同产业的创新系统的主要差异是创新的来源、参与者、特性、边界和组织。从知识流动的角度来看,一个产业创新系统框架关注4个维度:知识和技术领域、行为者、政府和制度、交互网络,作为创新系统中知识流动的结构性基础,网络的形状和拓扑直接影响隐性/显性学习和知识流动的效率[20]。信息技术产业创新系统是一个动态的、演化的复杂网络。首先,信息技术产业创新系统的各行为主体之间相互关联,并通过交互网络形成知识流动,具有明显的网络形态特征;其次,信息技术产业创新系统中的网络节点呈现出复杂性的特点,产业链上的企业、大学、科研院所、中介服务机构、政府部门等,都是具有高度自主性的个体或组织,具备自组织和网络化学习的复杂系统行为;最后,信息技术产业创新网络具有高度复杂的结构,并随着节点的进入和退出不断发生演化。突破式创新,或者技术冲击会对无标度网络形成宏观上的解构,在微观上最终都会趋向于形成新的无标度网络构造。因此得到假设H1。
H1:信息技术产业创新网络在微观上呈现无标度网络特征。
众多研究表明,小世界网络是一种普通存在的网络形态,即大多数节点可以经过少数的几个边到达另外一个节点Baum等[21]通过研究1952—1990年间加拿大投资银行集团网络演化拓扑结构,证实集群网络具有典型的小世界网络特征;Uzzi和Spiro[22]研究发现了百老汇音乐产业形成过程中的小世界特性。由于交流、效率、成本等原因,真实网络中存在着“捷径”,且“捷径”的数量与需求相匹配。从图论角度出发,“捷径”就是随机重连过程中添加的长边,在规则网络中添加极少量的长边,不仅使长边两端的节点路径长度变小,而且节点的邻居乃至之间距离的也随之变小。由于“捷径”的生成和维护往往需较高的“代价”,因此无法轻易解构。
复杂系统中普遍存在着组织化学习,显性学习是对已经公开的知识进行学习,例如从技术论坛上学习新的程序语言和编码技术,或者从国际学术会议上了解最新的业界动态等;隐性学习则是区域性的或者网络社群性质的沟通与知识传递,这种自组织将形成相当数量的“捷径”。以硅谷为代表,信息技术企业都在寻求向科技创新以及应用场景的趋近,通过开展组织化学习和网络化学习,去寻求已经完成聚类和编码的,被证明有应用性能和生产效率的知识。此外,在信息技术产业中,主导企业往往会通过制定通用标准来建立固守标准的战略联盟,例如IEEE标准、3GPP标准、5G标准等,从而形成路径依赖和锁定,进一步推动“捷径”的生成和固化。由以上分析可知,信息技术产业创新网络的独有特点有利于在区域或者特定范围内形成小世界网络,因此得到假设H2。
H2:信息技术产业创新网络在中观上体现出小世界网络的特征。
研究表明,小世界网络或随机网络在网络的动态提升和知识集聚度提升的情况下会形成社团结构,典型的例子是美国硅谷的创新社群网络。在硅谷由于国家/政府采购、产学研合作、风险投资和金融驱动等互动和协作的活跃,产业界、学术界和金融界形成了良性循环的巨大的交流网络。斯坦福大学从上世纪50年代开始就不断支持和帮扶硅谷的企业,设立专门研究园区,廉价出租工厂土地扶持具有发展潜力的创新型企业,并通过吸引人才和资金来推动创新领域的研究。对于创业者,斯坦福大学同时给予技术、资金和信息方面的支持和保障,并通过开设创业课程等方式给予指导。"斯坦福大学优等成绩合作计划"让硅谷公司的员工可以直接攻读学位。各项措施的实施,使得硅谷成功孵化和助推出惠普、思科、SUN、雅虎、谷歌等创新型领导企业,成功的企业又进一步吸引了大量的人才和资金,形成良性循环。临近的加州伯克利大学、加州旧金山大学及其他研究机构也和硅谷形成了良好的互动合作关系,依托于在基础科学、信息技术和工程学领域的领先地位,通过对硅谷产业活动的积极参与而建造形成了世界上最强大的产学创新体制和社群网络。
信息技术产业创新具有以下特点:(1)存在大量知识集聚和交互,并因为本地化知识和隐性知识学习的便利性而在地理区域上自发形成集聚,区域集聚与外部社会环境形成交互性促进,最终形成社群。(2)显性和隐性知识传播:信息技术产业,特别是互联网相关产业,为了实现标准的统一和相互连接兼容,必须公开知识,促进显性知识的形成与共享,例如RFC规范等。JAVA社区,Python社区等开源社区模式的流行更加促进了这一点。(3)知识相对开放和易模仿:不同于其他产业,信息技术产业中的计算机软件可以直接拷贝使用,设计思路可以直接借鉴,硬件可以直接拆解模仿,或者通过逆向工程学习设计方法,算法可以直接被利用,商业模式可以直接被模仿(共享经济)。(4)部分知识领域相对封闭和集中(IC、硬件、软件):例如芯片、高端硬件、通信设备等领域,知识相对封闭和集中,需要集中大量研发力量和资金,只有少量大型企业才能开展,由此导致形成密集型的社群结构。(5)信息技术产业受到风险投资和知识经济的影响,向经济高度发达地区集聚。对信息产业介入的程度的方向的不同,决定了知识的联系和创新的联结会形成社群网络,从事某一方面的企业形成小型团体,同时相互之间也有一定的联系。综合起来,信息技术产业创新社群网络形成的特点有:(1)技术高度密集但是存在壁垒;(2)属于同一技术范畴,有共同的研究基础,但是又存在很大的区别;(3)标准的规范化,兼容性要求很高;(4)随着时间增加,技术的积累效应会导致网络进一步密集。随着信息技术产业的高速发展,社群模块度不断增加,“搭便车”现象日益明显,小型企业追求快速进出市场,倾向于外包和技术模仿,导致自主创新意愿降低,并最终导致自主创新产出降低(图1)。由此得到假设H3a和H3b。
H3a:信息技术产业创新网络在宏观上体现出社群网络的特征,并且网络模块度随时间而增加。
H3b:信息技术产业创新社群网络的模块度增加,影响了产业的自主创新产出。

图1 假设的推导
(二) 研究方法
机器学习是一种将人类认知能力模型整合进入计算机算法模型中的技术,在研究信息产业创新系统的动力学机制,特别是创新的产生、选择固化和传播的动力学方面,有较好的应用前景。目前国内的研究较多采用BP神经网络方法[23-25]。国外研究包括人工神经网络(ANN)方法的创新网络研究[26],采用KN算法对创新风险进行定量分析[27],用神经模糊鲁棒性模型对微观和宏观创新潜能进行研究[28],用ANN网络研究知识管理与技术革新以及竞争优势的关系[29],使用ANN对技术创新的投资选择和风险进行研究[30]等。本文用基于网络的无监督机器学习方法来识别社群网络,并选择相应的网络指标进行衡量以及进行回归分析,以检验前文提出的假设。无监督学习通常首先将样本数据处理成向量数据集合,然后采用网络生成算法,利用相似性函数将向量数据通过运算生成关联矩阵,其中数值特征和类别特征进行不同的处理,最后进行识别社群网络,计算网络特征值,分析网络结构和特征等操作。
为了进一步研究网络特性对创新扩散的影响,采用复杂网络上的演化计算方法进行模拟仿真。演化计算是一种以计算模型为基础,以微观个体为出发点或以微观规律为出发点,以研究复杂经济系统的整体演化过程或结局为目的的方法。元胞自动机、系统动力学仿真方法、NW产业演化模型以及“多代理人系统”等演化计算方法受到了非常多的关注。基于复杂网络的知识扩散参考单海燕等[31]、孙耀吾[32]、Cowan和Jonard[33]的研究。社会现象例如创新知识扩散是知识借助知识主体之间的交互与合作进行的,可以被视为一种类似病毒传染的过程。病毒传播又称为流行病模型,目前应用最广泛的是SIR和SIS模型。相关的研究包括Bass[34]的创新扩散的“疫病学”量化模型,Tsai[35]开展的创新知识引入与扩散对知识资产增值和企业效益提升影响的影响,Zhang等[36]基于社区认知分析框架的集群知识扩散模型,以及苏家福等[37]基于改进元胞自动机进行的协同产品创新系统知识扩散研究。本文结合元胞自动机和“多代理人系统”方法,利用SIS病毒传播模型进行混合模拟仿真。
三、网络节点属性
(一) 属性选取
根据文献[38-39],选择发明专利授权数量和研发投入变量作为企业自主创新的度量标准,因为发明专利从申请到授权有3年的滞后期,因此补充发明专利申请数量来衡量企业的创新意愿。区域集聚会影响创新协同和传播,企业的创新成果往往会先在邻近区域进行试用,以降低试错成本,另一方面中小企业会更多与本地强势领先企业开展协同创新以降低学习成本。为了体现区域集聚和用户参与对产业创新的影响,选择企业所在省份的GDP数值、信息技术产业从业人口数量和省份人员的受教育程度、企业实际控股人的性质、政府补贴金额等变量。此外还加入总资产、营业利润率、所有者权益比例、资产周转率、资产负债率、销售和业务费用占收入比例,以及管理费用占收入比例等企业层面属性变量(表1)。
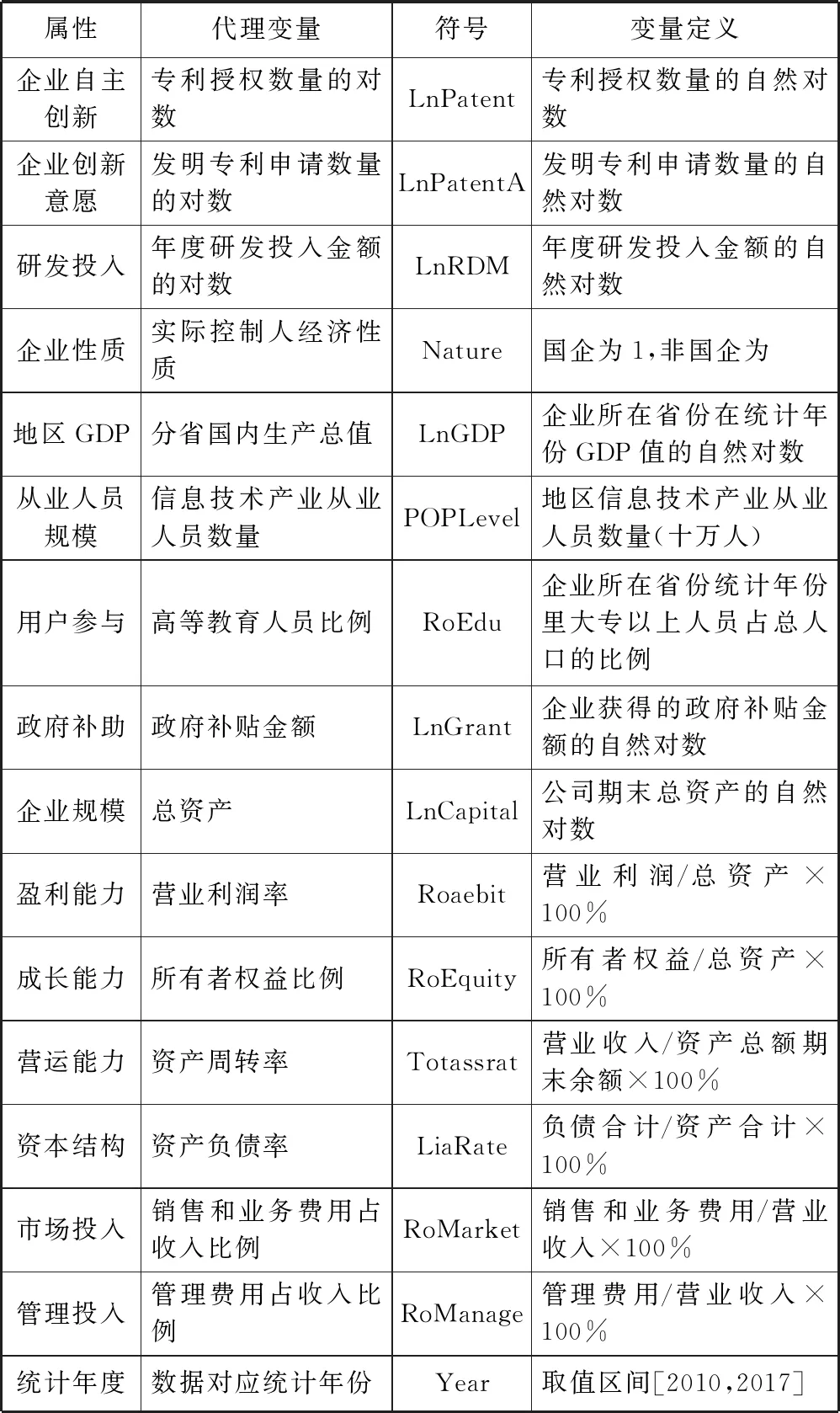
表1 网络属性设定
(二)样本选取
宏观数据通过相关统计年鉴进行收集,专利数据通过国家知识产权局网站手工收集。通过国泰安、锐思和万德数据库的2010—2017年上市公司数据,以及欧洲创新研究所的2010—2017年相关数据和时间区间内的上市公司年报。由于阿里巴巴、腾讯、百度、新浪、搜狐、网易等重点企业受到我国A股的制度限制而在海外上市,通过美国证监会和香港证券交易所的网站下载企业年报进行分析和数据补充。没有在股票市场上市的代表性企业(华为),通过企业官方网站上公布的年报后进行数据补充。美元或港币根据国家统计局公布的2010—2017年人民币年度平均汇率进行换算。对于同一指标在不同数据库和企业年报中的含义,进行了核对以确保数据口径一致性。按惯例剔除ST、*ST及主变量存在严重缺失的公司样本。对主要变量进行描述性统计特征分析,样本上市公司发明专利授权数量和申请数量平均值分别为1.820 4和2.188 1,中位数分别为1.386 3和2.197 2,最小值均为0,最大值分别为8.502 3和8.962 3,说明专利授权数量和申请数量均有明显右向偏移,这体现了信息技术产业中存在的技术外包和技术借鉴现象。其余变量中,例如资产周转率、资产负债率、市场投入和管理投入都具有较明显的右向分布,这也和信息技术产业的负债经营倾向形成了对应。
四、信息技术产业创新网络构建
(一) 关联矩阵
本文采用两步法形成创新网络,先根据国家专利局网站上的检索结果,基于联合专利申请构造初步网络(形成矩阵),然后用聚类方法进一步加强网络,采用向量方法补充权重和连接边,得到更完善的网络。为了避免过度连接,先预设一个阈值,低于阈值的认为相似度太低,可认为无连接边。然后根据机器学习方法识别社群网络,计算关键变量。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强[40]。两个变量xi和xj之间的皮尔逊相关系数按以下公式计算:

(1)
(二) 聚类启发式算法网络构建
常见的复杂网络构建方法有k-近邻方法,ε-半径方法,b-匹配网络,线性邻域网络方法,松弛线性邻域网络方法,聚类启发式网络方法,重叠直方图网络方法,时间序列网络方法等等。本文采用聚类启发式算法,因为一方面效率较高,另一方面也趋向于保持原始数据集的集群结构。聚类启发式算法具体步骤如下[41]。
1. 输入上一步生成的相异矩阵来表示所有样本簇间的距离,最初的样本簇都是单个节点;
2. 识别两个最近的样本簇,分别用G1和G2表示;
3. 计算G1和G2内节点(数据样本)之间的平均皮尔森相异度,分别用D1和D2表示;
4. 在G1和G2之间选择最相似的k对节点,并按照它们之间的相异度是否小于阈值dc(dc=ρmax(d1,d2),ρ取值0.3),在k对节点之间建立连边;
5. 根据步骤4中的计算结果更新相异矩阵;
6. 如果簇的数目>1,则返回步骤2.
(三) 基于网络的无监督学习方法识别社群网络
识别检测社群网络常用两种基准,Girvan-Newman基准和Lancichinatti基准[42]。由此发展的常用的基于复杂网络的无监督学习技术包括Girvan-Newnam的介数方法[43-44],变色龙算法[45]谱平分法[46]基于粒子竞争模型的社团检测[47]基于空间变换和群体动力学的社团检测[48-49]等。本文采用Blondel的网络折叠方法[49],以与上一步通过聚类启发式算法生成的网络匹配。Blondel的网络折叠方法主要步骤是通过网络折叠和社群重组,迭代直至获得最大的模块度(Modulaity)Q值为止,当Q>0.3时,说明该网络存在较强的社群结构现象。在识别出社群网络之后,即可测量识别出来的网络的模块集中度和其他指标,判断其效率。
(四) 网络衡量指标
综合文献[50-53],本文选定网络密度、富人俱乐部指数、模块度、节点相似度和网络健壮性进行衡量。
1. 网络密度
网络密度用于刻画网络中节点相互连接边的密集程度,一个N个节点和L条连接边的网络的网络密度计算公式为

(2)
2. 富人俱乐部指数
度数较大的节点(关键节点)之间具有紧密相连的趋势,从而形成团状结构或者近似结构,如果一个节点拥有较多的连接,称其为“富有”节点。“富有”的节点更容易形成紧密的相互连接的子图。

(3)
对于给定的阈值k,N>k表示度数大于k的节点数量,E>k表示与N>k个节点相关的边的数量。N>k(N>k-1)表示N>k个节点可能存在的最大边数。本文设定K值为10。
3. 模块度
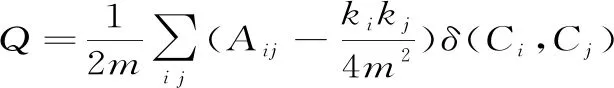
(4)
4. 节点相似度
(5)
如果两个节点的共同邻居很多,则相似度很高。其中τ(i)表示节点i和i所有邻居的集合。

(6)

五 结果分析
(一) 微观层面的无标度性
利用Ucinet软件选取2011,2013,2015和2017年度数最大的节点及其关联节点构成局部网络,分别占整体网络规模的11.34%、14.37%、13.77%和16.78%,拟合后的系数R2均>0.9,且幂指数γ∈(1.5,2.3),如图2所示,说明信息技术产业创新社群网络在微观上具有无标度特性。

图2 微观无标度性网络
无标度性说明网络中少量和个别节点拥有大多数连接,而部分节点只能与少数几个节点形成关联。新增加的节点将更倾向于具有更高连接度的节点相连接。例如进入手机APP服务性领域的厂商,都会优先考虑与阿里(支付宝)和腾讯(微信)形成关联,以快速形成生产力。而在电信领域,设备供应商和软件商都会优先考虑与中国移动和华为等企业开展创新合作。
(二) 中观层面的小世界性

应用Python编程自动生成同等规模随机网络,并使用Ucinet进行分析,结果显示信息技术产业创新网络呈现较为明显的小世界性,如表2所示。即网络在具有较小的平均路径长度的同时,还具有较高的集群系数,因此创新网络中的行为人可以高效快速地与其他行为人进行创新交流和知识交换,对于创新的扩散具有正面的推动作用。小世界商数随着时间呈现增长体现了网络的集群性增加(图3)。

表2 信息技术产业复杂网络小世界特性
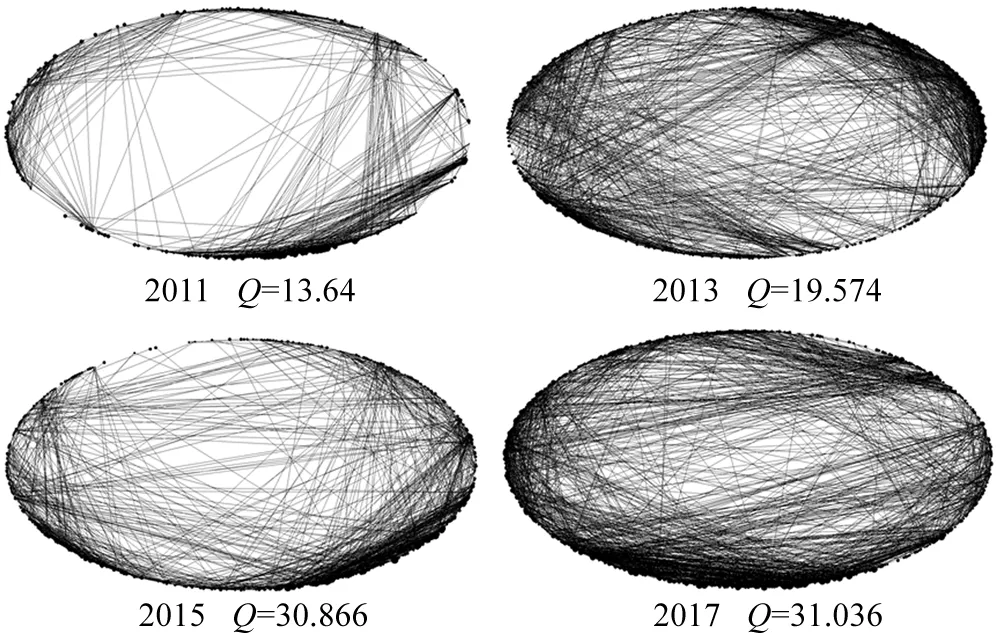
图3 信息技术产业小世界网络特征
(三) 宏观层面社群网络特征情况
按统计年度为一个时间窗口,通过Python编写代码,结合Ucinet软件计算网络社群规模情况(设定社群最小规模为5),结果如图4所示。

图4 信息技术产业社群网络宏观特征
从图4可以看到,信息技术产业创新网络的节点和连接边数随时间不断增长,整体网络密度呈缓慢下降趋势,模块化指标Q值均大于0.3,说明网络存在明显的社群结构,社群规模平均值逐步递增。随着社群规模的增长,富人俱乐部指数相应增加,说明少数核心节点对于社群结构的贡献度增大,节点相似度也随着正向增长,说明节点在创新行为和关联上有趋同的倾向。对识别出来的社群网络,采用Unicet网络分析软件进行绘图,可以看到,信息技术产业创新呈现较为明显的社群网络特征,且随着时间增加,社群集中度有增加的趋势。表3汇报了社群和其他网络指标的数值。
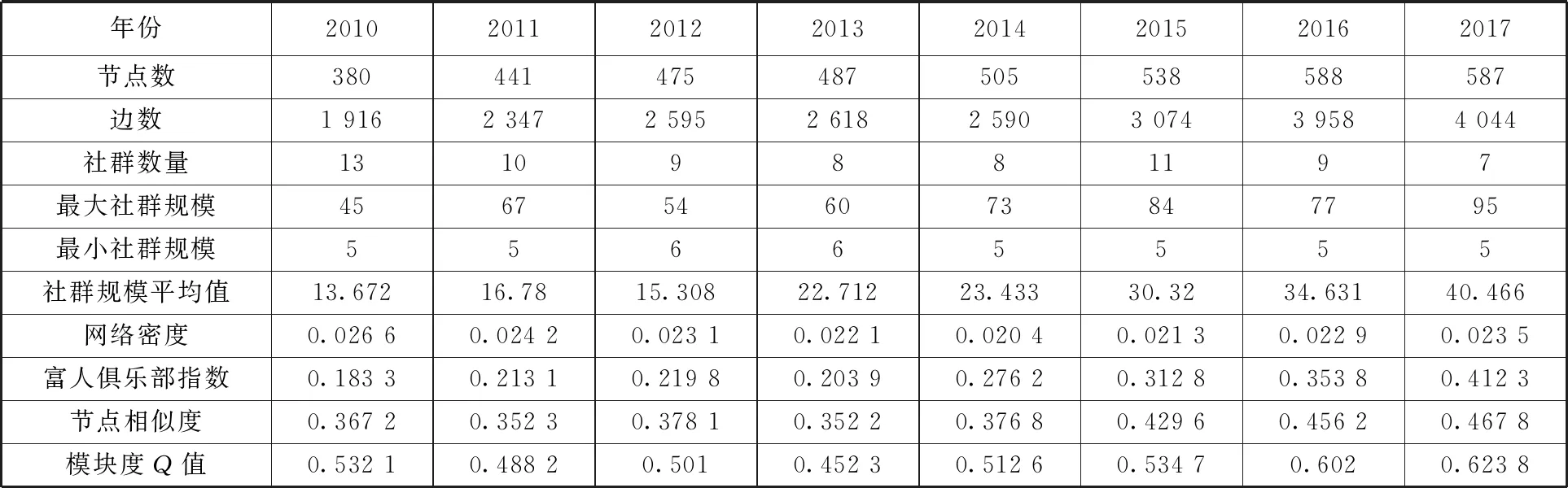
表3 信息技术产业社群网络特征
六、回归分析和模拟仿真
(一) 回归分析
为了进一步验证假设,建立10个回归子模型,其中模型1~5分析各种变量和专利授权平均情况的回归情况,模型6~10检验专利申请平均值的回归情况。表4报告了回归分析的结果。
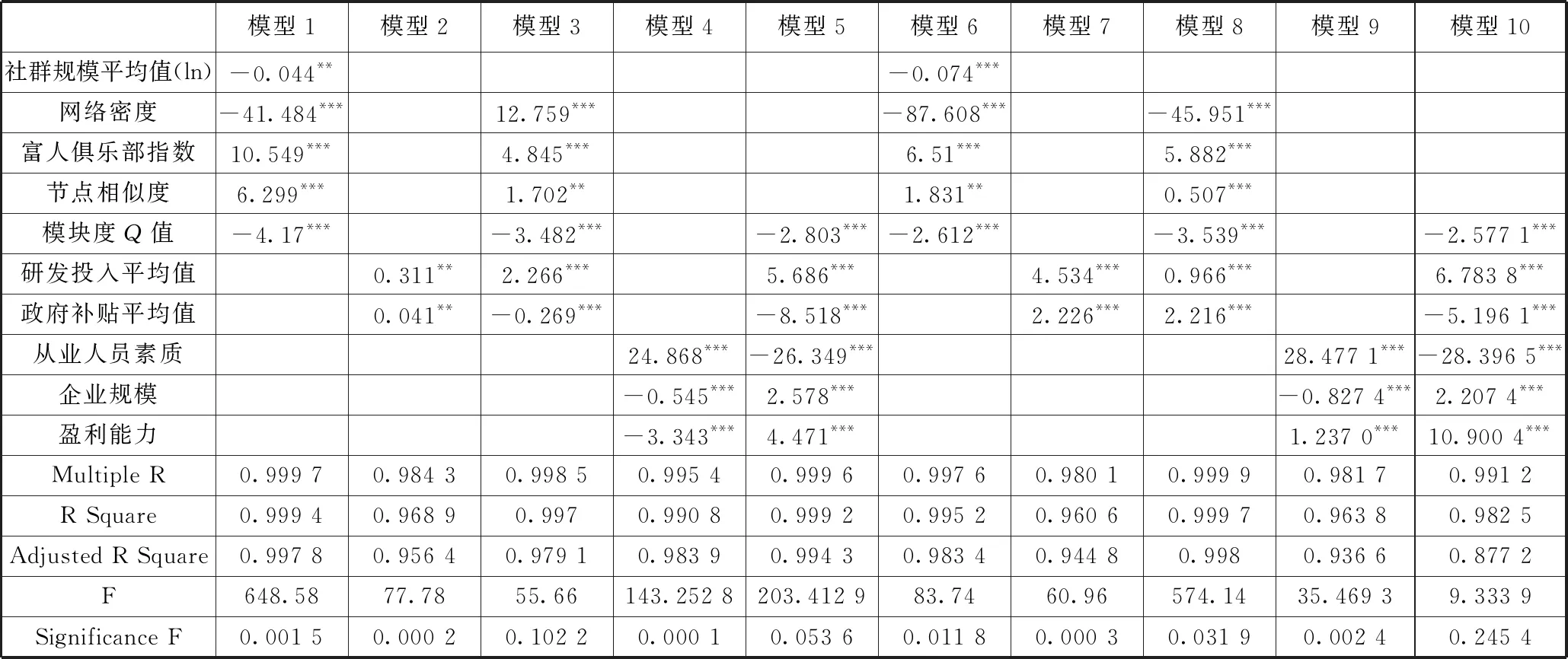
表4 回归分析结果
模型1是网络特征的回归分析,模型2是研发投入和政府补贴的回归分析,模型3将网络特征、研发投入和政府补贴作为变量,模型4则是从业人员受教育程度、企业规模和盈利能力作为变量,模型5是模块度Q值、研发投入、企业规模等的综合回归分析。从结果上看,模块度Q值与专利授权平均值呈现负相关,这说明随着网络的社群结构日益增强,自主创新产出将会受到抑制,由此H3b得到验证。富人俱乐部指数与专利授权平均值之间存在显著正向关系,这则从另一个侧面反映了总体上自主创新的受抑制情况,由于少数大型企业掌控大量知识和资源,因此大量产出创新。根据国家专利局网站上的数据汇总,华为公司在2010—2017年间共提出36 962次专利申请,获得23 328个专利授权,远多于其他企业。领先企业大量申请专利,导致行业专利的总量上看是增长的,但具体到每一个企业,则会出现明显的技术外包和技术跟随现象,实际上产业的自主创新活力受到了抑制。
另外值得关注的,是在模型3和模型5中发现,当模块度Q值和政府补贴平均值同时纳入模型之中时,均呈现明显的负向关系。对样本数据进行检视发现,地方政府往往倾向于给本地领先企业更多补贴,例如华为公司的年报披露,每年平均获取政府补助金额超过10亿元人民币[56],因此,网络的社群效应越明显,领先企业优势越明显,得到的资源将更多,在创新方面占据重要地位,反而会对产业的自主创新水平形成一定抑制。模型6~10检验专利申请平均值的回归情况,同样可见,模块度Q值与专利申请平均值也是负相关关系。其余结论与模型1~5也基本一致。
(二) 模拟仿真
1. 模型设置
元胞自动机(cellular automata,CA) 是一种时间、空间、状态都离散,空间相互作用和时间因果关系为局部的网格动力学模型,具有模拟复杂系统时空演化过程的能力。通过将元胞空间和元胞定义拓展为“多代理智能体”的方式,可以更好地模拟复杂网络中的扩散行为。

(7)
每个节点在t时刻的状态是一个三元组(e,NE,S),其中e表示该节点的度数,通过遍历获得数值,NE是一个代表节点的邻居集合的数组,取值范围为[0,n],S表示感染状态,取值范围为(0:未感染,1:已感染,2:感染后已恢复)。
在元胞自动机中,邻域决定了元胞之间的交互关系,为了不失一般性同时加快仿真速度,采用扩展Moore邻域方式,如图5所示。
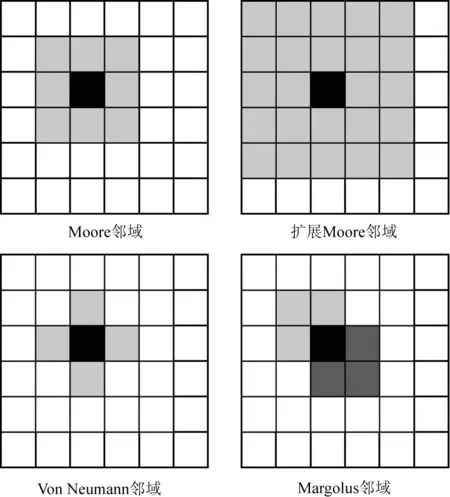
图5 常见的元胞邻域
多智能体方法和病毒传播模型中,最关键的一点是转换(感染)的规则,假设信息技术产业社群网络中,创新来源(易感染者)、创新知识学习者(感染者)和创新非选择者(免疫者)的比例分别为x,y,z,在每一个时间点,一个易感染者以概率α被另一个感染者感染,感染者的恢复概率为β,假设感染者在恢复之后可能会再次回到易感染状态,则SIS模型的动力学过程可用下列方程组表示:
(8)
根据文献[42-44]以及病毒传染模型的原理推导,假设从高度数节点的传染性,要比低度数节点的传染性更强,而处于未感染状态的节点,要比感染后恢复的节点更容易被感染。因此,从节点a到节点b的感染概率按以下公式计算(假设a为感染状态节点,b为未感染或感染后恢复状态):

(9)

2. 仿真结果
设置初始状态下所有节点都未受到感染。初始感染概率μ符合[0,1]随机分布,恢复概率按[0,0.1]随机分布,仿真时间单位选择为周(7天),时长T=50,仿真50次以后计算平均值,统计网络中感染比例,起始节点随机选择。
从仿真结果图6可以看到,随着模块度的增加,创新传播的速度明显增加,更早达到均衡状态,同时更高的模块度使得网络能达到更高比例的感染(扩散)水平。因此,可以认为网络的社群性增加,将会更有利于创新的扩散。这也从另一个角度验证了假设H3b,由于社群网络结构对创新扩散有促进作用,企业获取创新的成本和代价更低了,搭便车和外包倾向也更加明显,因此对网络的自主创新产生了抑制。
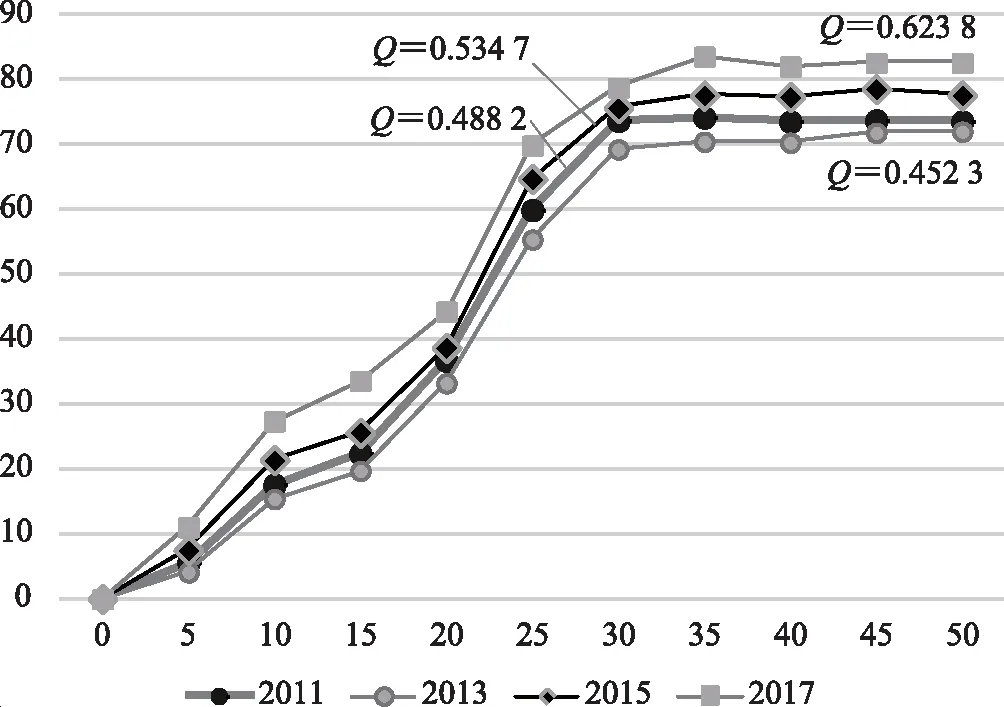
图6 SIS仿真结果
七、小结和讨论
本文基于实证数据,以信息技术产业创新网络为对象,分析其在宏观、中观和微观上的特征,并对网络结构与自主创新产出的关系进行了研究,得到以下结论。
首先,基于2010—2017的样本数据,我国的信息技术产业创新网络,体现出宏观上大社群,中观上小世界,微观上无标度的特征。社群网络的集中度有逐年增加的趋势。信息技术产业高度依赖于创新,产业动态与信息和知识的创造与传播高度关联。信息技术是不断迭代上升发展的,突破性技术和创新涌现对产业演化形成巨大的推动力。产业创新系统是为了有利于知识的创造、传播与转移的体系,通过产学研合作、国家政策、产业地理集聚等方式实现知识的集聚和传播。可以认为,产业的知识动态就等同于产业的演化与成长。2010年以来,随着以微信为代表的移动互联网经济的高速发展,我国的信息技术产业知识动态处于高度演进的动态过程之中,在创新网络的演进上得到充分的体现。
其次,信息技术产业创新社群网络的网络模块度随时间增加。产业演化指产业的发展、进步、结构转变和动态竞争。一个良性发展的产业,总是在不断的创生、选择、失衡和重新均衡之中向前推进的。创新使得产业产生新的活力和推动力,推动产业按照均衡、失衡到再均衡的路径不断演进。产业中具有不同的知识和能力的异质性个体(企业)之间形成互动,通过学习形成驱动力,使得创新网络的模块度随时间不断增加。
最后,信息技术产业创新社群网络的模块度增加,影响了企业自主创新产出。由于产业高速发展导致社群模块度增加,小型企业追求快速进出市场,倾向于外包和技术模仿,“搭便车”现象日益明显,从而导致自主创新意愿降低,或者进入“低端锁定”的路径依赖,导致自主创新产出降低。路径依赖可能会因为成熟技术的迭代演进而节省成本,带来效益递增,但也可能会因为固守成规错过创新机会导致“低端”锁定,一个典型的案例是近年的“共享自行车”困局。此外,路径依赖和锁定会因为冲击性技术而解构,导致新的不均衡,经过市场博弈之后演进到下一个较为稳定的路径和锁定。在信息技术产业创新网络自组织形成的过程中,个体往往会从自身已有的核心能力和技术优势出发,选择自己认为最优的一条技术路径进行演进,并将演进方向锁定在某个既定的技术领域。如果网络中已经存在非常集聚的社群结构,后入者容易直接“锚定”而影响自主创新意愿。后续应当采取措施适当降低社群网络的模块度,推动形成良好的多个小社团共存的局面,鼓励更多中小企业自主创新。同时应促进知识流动,避免过度集聚。政府要通过政策信息释放信号,推动信息技术创新的形成和流动,制定促进知识流动和网络化学习的措施。要从国家层上保护知识产权,针对数字产权专门考虑,促进知识流动,做好配套(文化、制度、政策)。此外,地方政府往往倾向于给本地领先企业更多补贴,在网络社群效应明显的情况下,领先企业将得到更多资源,占据创新优势地位,对产业的自主创新造成进一定抑制。建议地方政府对补助范围和对象进行进一步审视。
本文的研究中还存在一些局限之处:首先,社群识别方法忽略了成员的动态变化和社群结构本身的动态演化,也没有考虑社群可能存在重叠的现象。其次,样本存在一定局限性,个别对创新能力具有衡量作用的变量无法获取或者数据不完备。最后,研究只针对信息技术产业的相关数据,存在产业差异性局限。以上都是下一步要继续研究的方向。□
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
新一代信息技术(2021年16期)2021-11-13 08:10:18
国际眼科杂志(2021年9期)2021-09-15 03:24:42
新一代信息技术(2021年23期)2021-03-08 09:13:28
新一代信息技术(2021年15期)2021-03-08 02:10:10
装备制造技术(2020年2期)2020-12-14 03:09:16
甘肃教育(2020年2期)2020-09-11 08:00:44
现代家电(2019年4期)2019-06-12 15:59:52
中国卫生(2015年12期)2015-11-10 05:13:34
创业家(2015年9期)2015-02-27 07:54:23
