
基于医疗过程挖掘与患者体征的药物推荐方法
2020-08-06 06:18李鹏飞鲁法明包云霞曾庆田朱冠烨
计算机集成制造系统 2020年6期
李鹏飞,鲁法明,包云霞,曾庆田,朱冠烨
(1.山东科技大学 计算机科学与工程学院,山东 青岛 266590;2.山东科技大学 电子通信工程学院,山东 青岛 266590)
0 引言
科学用药对于提高疾病治疗效果具有重要作用,目前的用药方案主要由医生根据自身经验和知识制定。受限于个人认知的局限性,用药方案的制定难免存在不足。实际上,随着医疗信息化水平的不断提高,各类医疗信息系统中记录了大量的历史病患诊疗数据。由这些医疗数据出发,挖掘其中隐藏的用药方案制定规律和知识,进而为医生制定用药方案提供科学合理的决策支持和药物推荐,这对于疾病治疗的科学用药具有重要意义。
当前,已有很多研究工作对各类医疗数据进行挖掘和分析,以辅助构建医疗过程模型或推荐诊疗方案[1]。例如,文献[2]采用时序数据挖掘的方法从医疗日志数据中挖掘疾病诊疗的临床路径,并以糖尿病的临床诊疗路径为例对所提方法进行了验证;文献[3]将过程挖掘技术应用于医疗过程的发现,使用模糊挖掘算法从患者的临床治疗日志中重构医疗过程模型;文献[4]综合考虑医疗过程的模型结构和医疗资源调度的限制,给出了资源约束前提下从医疗收费数据中抽取医疗过程模型的方法,并将其应用于患者诊疗方案的制定;文献[5]对基于过程挖掘进行医疗过程重构的工作进行了综合分析,指出经典的过程挖掘算法在医疗过程挖掘中存在事件粒度过细的不足,由此得到的医疗过程模型不易被理解和使用。
为得到更为简洁和容易理解的医疗过程模型,文献[6]将医疗过程进行的抽象和归纳转换为一个优化问题,并借助动态规划算法给出了由医疗日志重构医疗过程模型的方法;文献[7]从医嘱指令数据出发,对医嘱指令进行聚类,进而结合时序分析和相似度计算方法进行患者医疗过程的挖掘与治疗方案的推荐;文献[8-9]将医疗信息系统中记录的患者诊疗日志和单个诊疗活动分别类比为隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)主题模型[10]中的文档和词语,将语义上相似的多个诊疗活动聚类为一个主题,并在此基础上进行疾病诊疗主题模式的发现;文献[11]在文献[8]的基础上将诊疗活动的时间信息纳入挖掘到的医疗过程模型中;文献[12]将基于领域本体生成的诊疗日志相似性约束加入到诊疗活动的LDA主题训练模型中,提出一种基于优化主题模型的临床路径算法,并在此基础上借助过程挖掘技术进行了临床路径的重构。文献[13]从医疗信息化系统中记录的患者处方数据出发,将处方数据与DrugBank数据库中记录的药物功效融合生成患者的每日用药疗效文档,在此基础上结合LDA主题模型和概率后缀树提出了药物治疗临床路径的挖掘方法。此外,文献[14]指出医疗过程存在数据敏感和非结构化的特点,由此提出一种数据驱动的医疗过程模型,给出了由日常医疗数据挖掘该模型的方法,并以前列腺癌的医疗过程挖掘为例说明了方法的可行性。
上述工作主要着眼于临床路径或者医疗过程模型的挖掘。针对具体患者进行治疗方案推荐时,除了要考虑疾病治疗的标准临床路径或者医疗过程模型外,患者的体征状态也应作为重要参考指标。为此,本文提出一种基于医疗过程挖掘与用户体征的药物治疗方案推荐方法。相比已有工作,本文有如下特色:
(1)基于处方数据的药物功效聚类与诊疗日功效主题挖掘 鉴于处方数据在医疗信息系统中的准确性和完整性,本文提出从处方数据出发生成患者的每日用药清单,进而借助LDA主题模型训练各个诊疗日的功效主题分布以及每个功效主题下药物分布。
(2)基于不定阶马尔科夫模型的医疗过程建模 将患者每个诊疗日的药物治疗方案抽象为一个药物功效组合标签,将患者的药物治疗过程抽象为功效组合标签序列,假设药物治疗过程服从不定阶马尔科夫性质,在此基础上训练概率后缀树作为医疗过程模型。
(3)医疗过程模型与患者体征数据融合的药物推荐 首先基于概率后缀树模型计算树中各节点后续治疗所采取药物功效组合的概率分布,然后将上述计算结果与病人的体征向量作为联合特征,使用XGBoost分类方法[15]训练多分类模型,并将该模型用于药物推荐。
本文以MIMIC-Ⅲ(medical information mart for intensive care Ⅲ)临床数据库[16]中糖尿病患者的处方日志和特征数据为例,对所提方案的可行性和有效性进行了评估,下面对论文工作进行具体介绍。
1 研究路线
本文运用LDA主题模型和过程挖掘方法构建疾病治疗的过程模型,综合考虑挖掘到的过程模型与患者的体征数据进行后续药物治疗方案的推荐,具体研究路线如图1所示。
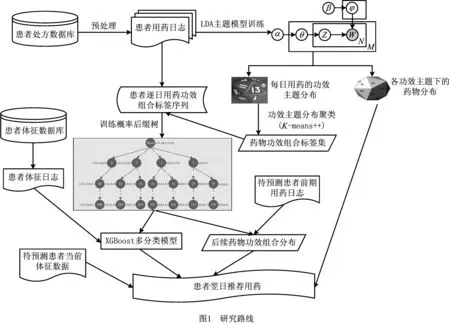
首先,基于医疗信息系统中记录的患者处方数据生成用药日志,借助LDA主题模型从用药日志中挖掘药物治疗的功效主题,同时得到各诊疗日的药物功效主题分布;然后,使用K-means++算法对每日功效主题分布进行聚类,每个簇对应一个功效组合标签,由此可将患者的药物治疗过程转变为药物功效组合标签序列;进一步,利用所有患者的功效组合标签序列训练概率后缀树作为疾病药物治疗的医疗过程模型,基于该模型计算树中各节点后续治疗所采取药物功效组合的概率分布,并将上述计算结果与病人的体征向量作为联合特征,将病人真实用药对应的功效组合作为分类标签,采用XGBoost方法训练多分类模型;最后,将待预测患者的当前体征数据、依据概率后缀树得到的后续药物功效组合分布作为XGBoost多分类模型的输入,模型输出后续治疗方案对应的药物功效组合标签出现概率,再结合各功效主题下的药物分布计算出各个药物的出现概率,按照出现概率对药物排序即得到推荐结果。
2 基于LDA主题模型与概率后缀树的医疗过程挖掘
本章给出由患者处方数据挖掘疾病药物治疗过程所对应概率后缀树模型的具体方法。
2.1 数据源与患者用药日志生成
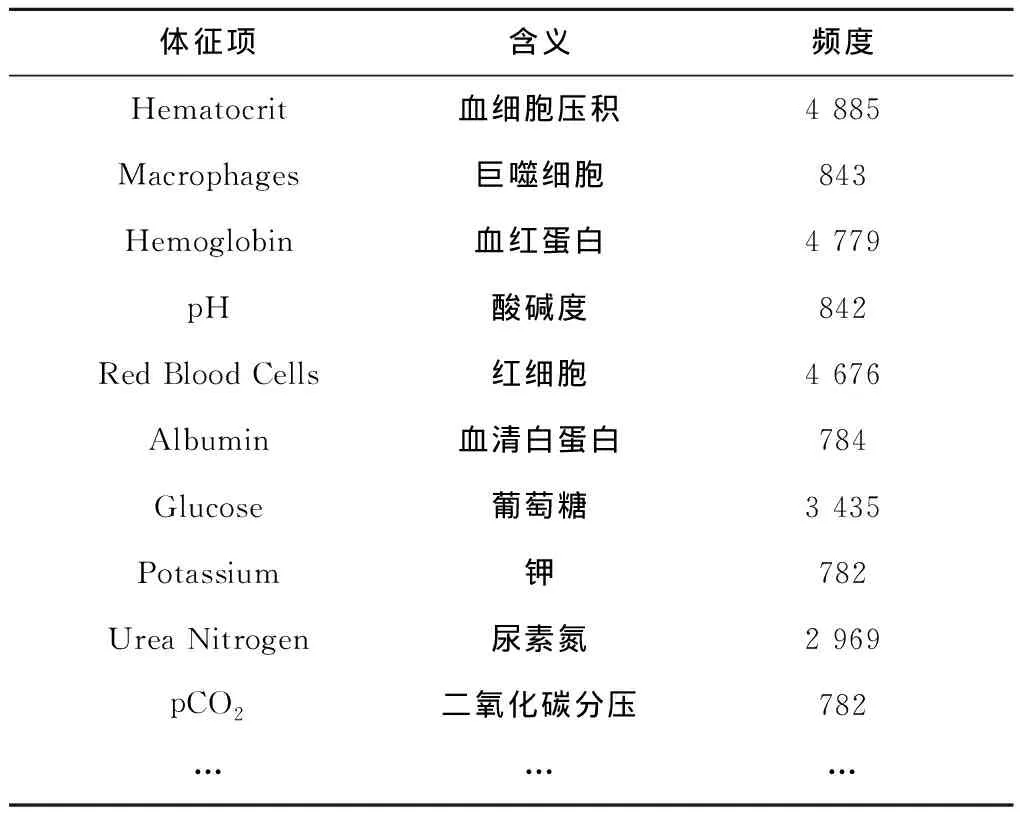
本文结合MIMIC-Ⅲ数据库中记录的医疗数据对所提方法进行了说明和实验验证。MIMIC-Ⅲ临床数据库记录了45 000余名患者在贝斯以色列迪康医学中心以及飞利浦医疗中心的58 000余次住院数据,具体数据项包括病人的基本信息(如病人的性别、出生日期、死亡日期、入院时间、出院时间、种族、语言、宗教等)、诊断信息、体征检验数据等。
接下来介绍如何由患者处方数据生成患者用药日志。MIMIC-Ⅲ数据库中的患者处方数据(PRESCRIPTION)如表1所示。显然,将各药物处方记录根据其时间跨度分散到每一天便可得到患者的每日用药记录,称为用药日志。表1的处方数据对应的用药日志如表2所示。

表1 患者处方表示例
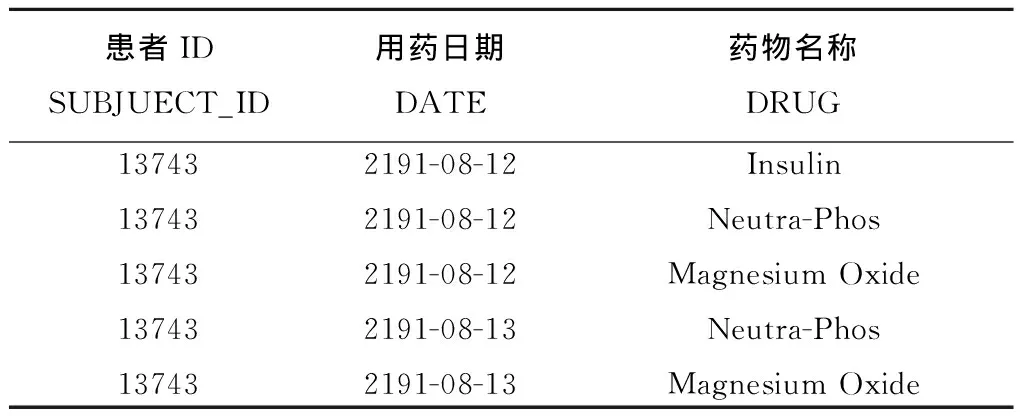
表2 患者用药日志示例
本文以诊断结论为“DIABETES”(糖尿病)且用药记录数量介于200~500之间的患者处方数据为数据源。剔除处方中总出现次数少于5次、多于2 000的药物,最终得到的处方数据集中涉及400位患者、323种药物。基于该处方数据集得到患者用药日志(https://pan.baidu.com/s/1W1Onit DwPkFFtLZw2Yi_Sg.提取码: cydu),后文从该日志出发进行药物治疗过程模型的挖掘以及药物推荐实验。
2.2 药物功效主题聚类与每日用药功效主题分布挖掘
假设患者治疗过程所需的药物功效分为多个主题,患者每日所服药物按多项分布服务于这些功效主题,且每个功效主题下需要采用的药物也服从多项分布。此时,可借助LDA模型从历史患者用药日志中训练各个诊疗日的功效主题分布以及每个功效主题下药物的概率分布。
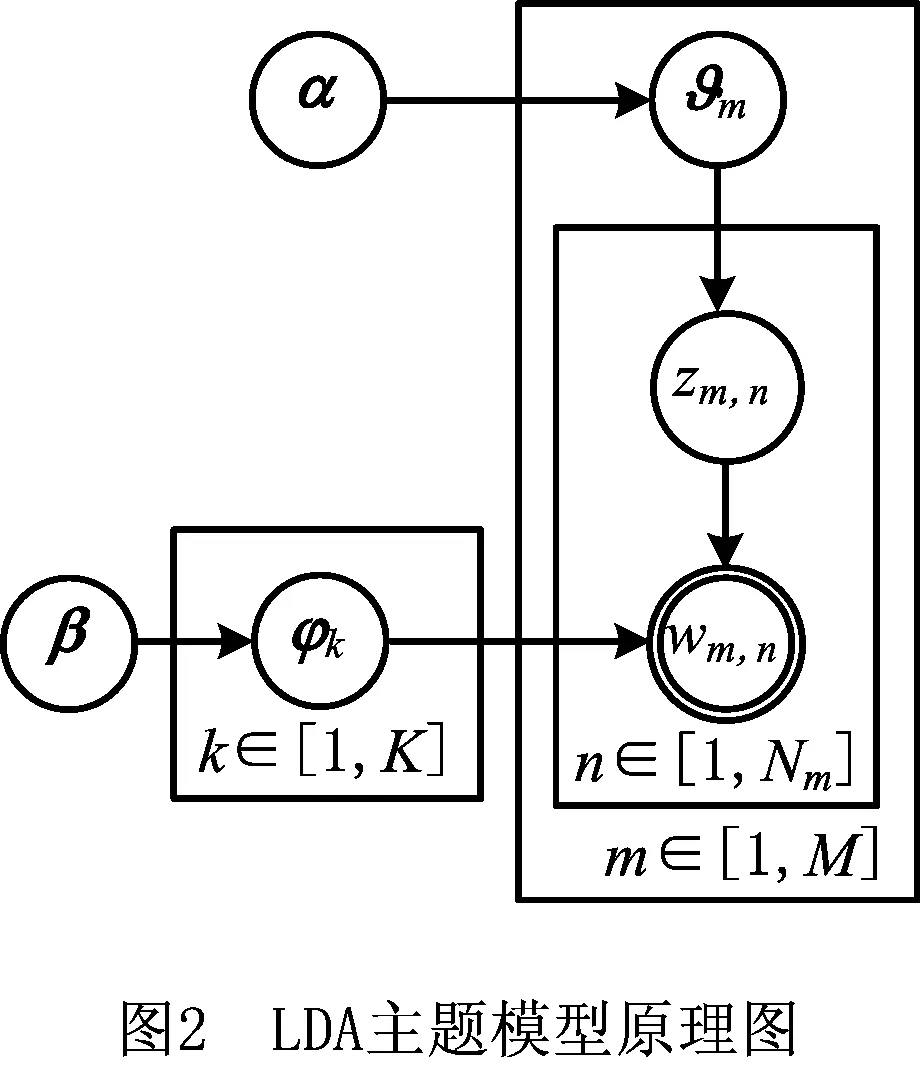
所谓LDA主题模型是一个“文档—主题—词”的三层贝叶斯模型,它假设每个文档都是主题的混合分布,而主题则是词的概率分布。一篇文档可以按照多项式分布蕴含多个主题,文档中每个词都由其中一个主题按照某个多项式分布生成。LDA模型假设文档的生成方式如图2所示,具体如下:假设存在一个超参数为α的Dirichlet分布是文档—主题分布的先验分布,从该Dirichlet分布中取样生成一个多项式分布θm,以θm作为文档m中主题的分布;然后,每次从分布θm中取样生成文档m第n个词的主题zm,n;与此同时,假设存在一个超参数为β的Dirichlet分布是主题—词分布的先验分布,从该分布中取样生成主题zm,n的词分布φk,最终可由该词语的多项式分布φk生成词语wm,n。在上述假设下,当给定文档集合后,文档主题词的联合概率分布p(w,z)如式(1):
p(w,z|α,β)=p(w|z,β)×p(z|α)
(1)
采用Gibbs抽样可反推出文档m中出现主题k,以及主题φk下出现词语t的期望概率分别为:
(2)
(3)
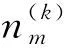
本文将患者的每日用药清单类比为一个文档,将清单中的药物类比为词,将同一疾病所有患者所有诊疗日的用药清单类比为文档集合,借助上述LDA主题模型得到的“主题”实际对应药物的功效主题,“主题—词分布”对应各个功效下药物的出现概率,“文档—主题分布”实际就是某患者某个诊疗日所服用全部药物对应的药物功效分布。
以2.1节所得到的糖尿病患者用药日志为输入,当设置主题数参数为15、聚类数参数为20时,经LDA算法处理后所得各个功效主题下概率值最大的药物清单如表3所示。根据查阅资料和咨询医疗专业人员的情况,各个主题下排名靠前的药物具有相似的功效主题。例如,主题0下“Montelukast Sodium”(孟鲁司特钠)是一种非激素类抗炎药,能够改善气道炎症,有效控制哮喘症状;该主题下第二个药物“Ipratropium Bromide Neb”(异丙托溴铵)主要用于预防和治疗与慢性阻塞性气道疾病相关的呼吸困难,慢性阻塞性支气管炎伴或不伴有肺气肿,轻到中度支气管哮喘。“Montelukast Sodium”和“Ipratropium Bromide Neb”均可作为轻度哮喘的替代治疗药物和中重度哮喘的联合治疗用药。

表3 药物主题数为15时主题下概率最大的前10个项目
2.3 药物治疗过程的概率后缀树模型挖掘
2.3.1 药物功效分布聚类
假设疾病的药物治疗过程分为多个阶段,每个阶段包含的各个诊疗日采用相似的药物功效组合,则相同阶段各个诊疗日的药物功效应该聚为一类。由此,在2.2节所得各个诊疗日用药清单所对应药物功效主题概率分布的基础上,可利用K-means++算法对这些概率分布进行聚类。聚类后,同属于一个簇的功效主题分布认为具有相同的药物组合功效,用统一的药物功效组合标签对其进行标注,由此可将每个患者每个诊疗日的用药方案转换为一个药物功效组合标签。
仍然以2.1节中所得糖尿病患者的用药数据为例,经LDA模型训练后,对得到的各个诊疗日的药物功效组合进行聚类,最终得到的聚类数量以及各个类别标签对应的功效主题如表4所示。表4中仅保留了各功效组合标签下出现概率大于30%的功效主题,功效主题的含义是根据各个主题的Centroid聚类中心药物,查阅该药物的功效说明并咨询医生确定的。
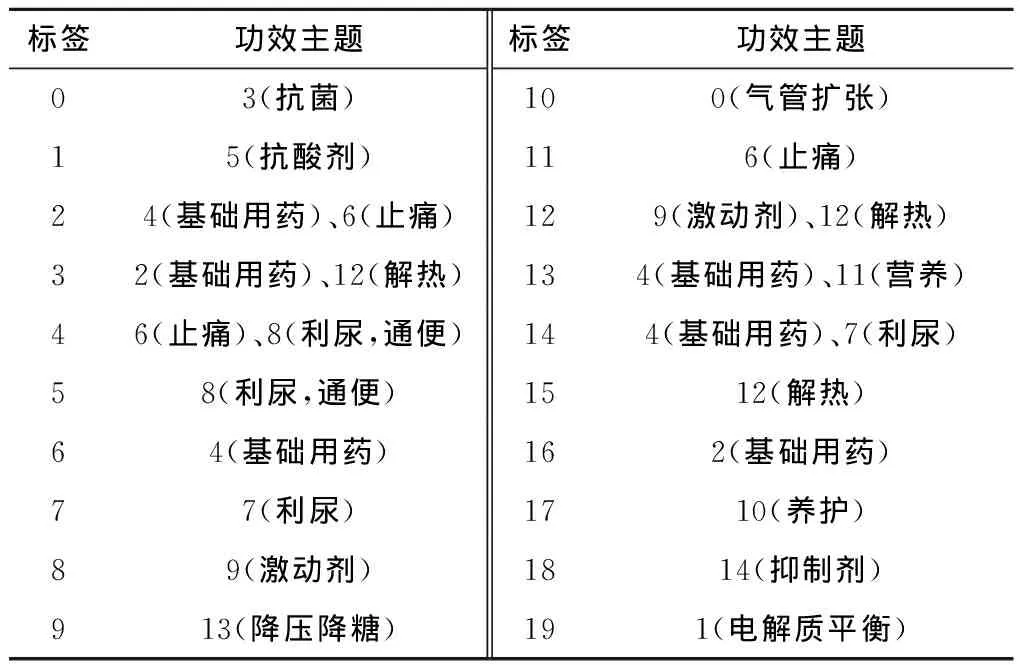
表4 药物功能组合标签及其对应的功效主题
需要指出,无论是前述LDA主题模型的训练,还是K-means++聚类算法,两者分别需要指定主题个数以及聚类数量等参数,对于这两个问题,本文的处理方案是枚举可能的参数取值,选择使得药物预测准确率最高的参数值作为最终模型参数。
2.3.2 药物治疗过程的概率后缀树模型构建
经2.3.1节的处理后,患者的每日用药方案被转换为一个药物功效组合标签,患者完整的药物治疗过程对应一个药物功效组合标签序列。假设同一类疾病的治疗过程中,患者每日用药对应功效组合具有变阶马尔科夫性质,则可借助所有患者用药历史对应的药物功效组合标签序列构造概率后缀树,本文将该概率后缀树作为疾病药物治疗的过程模型。
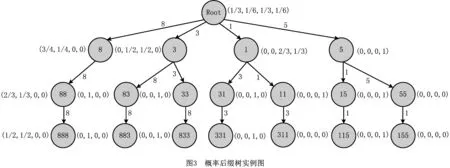
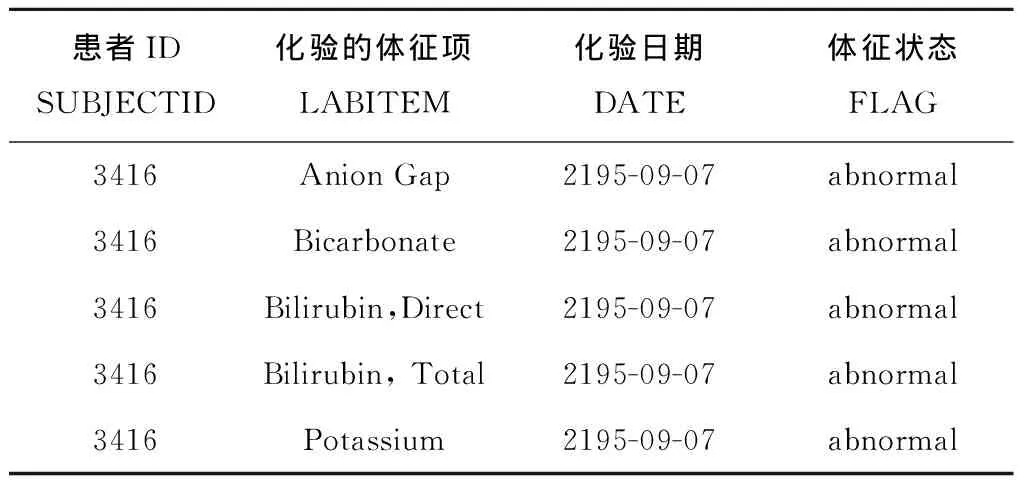
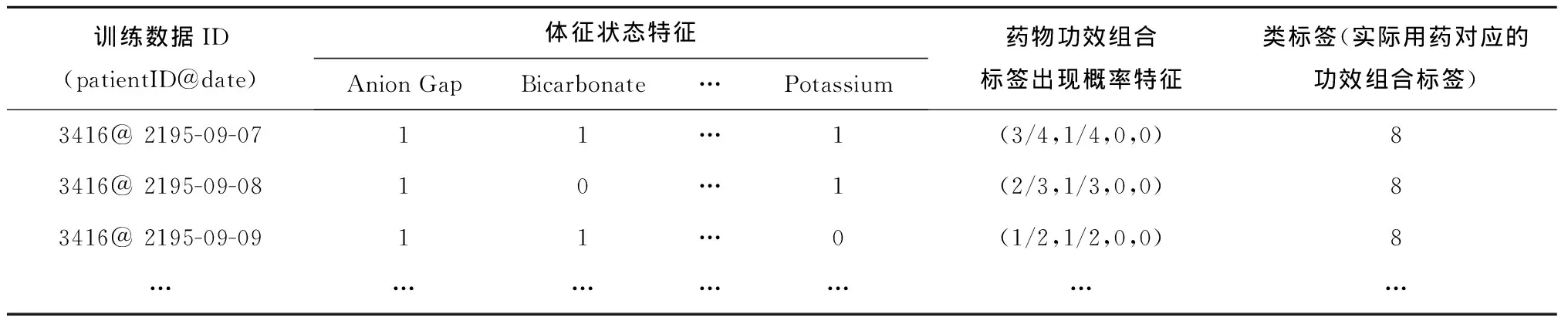
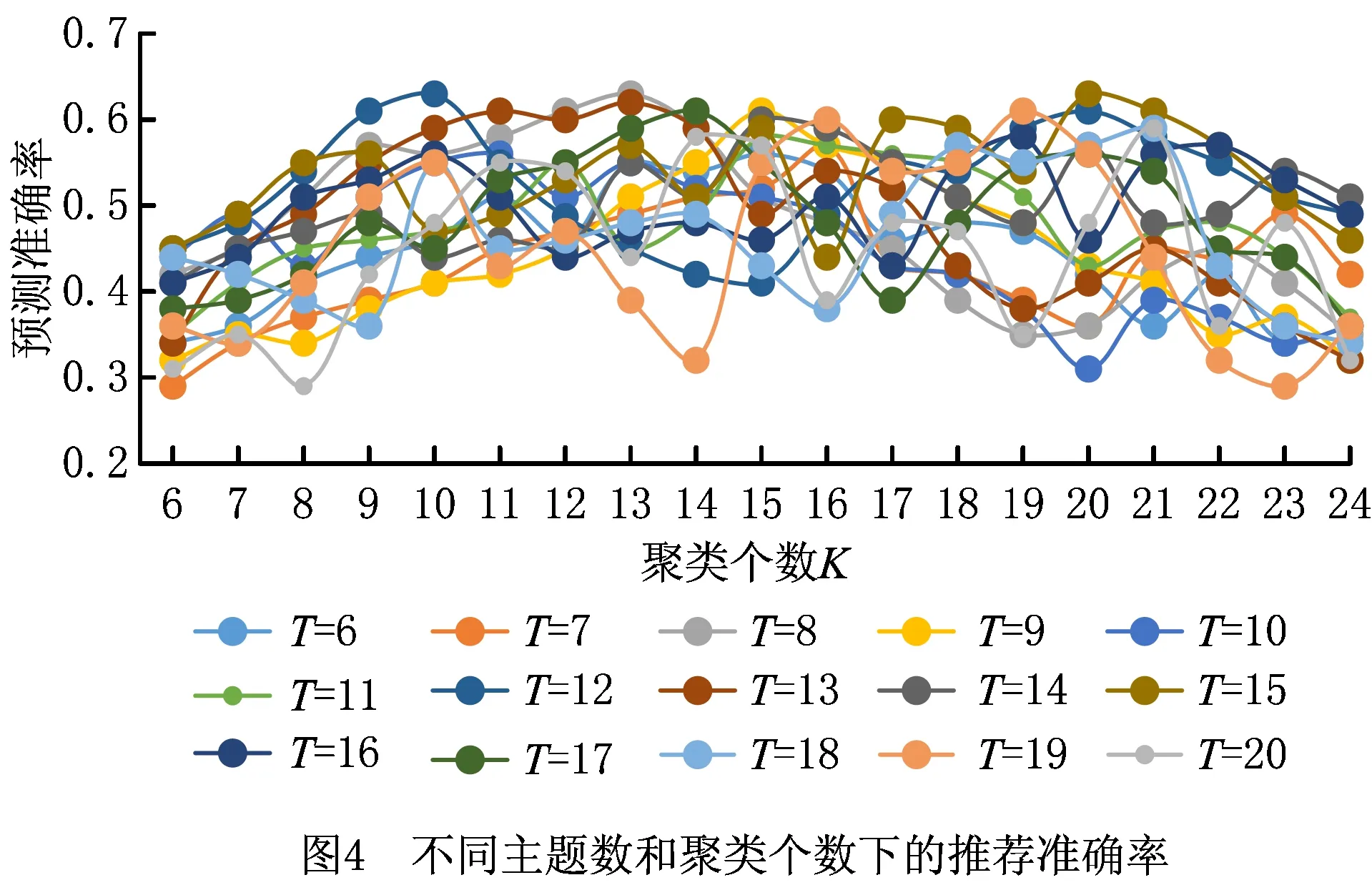
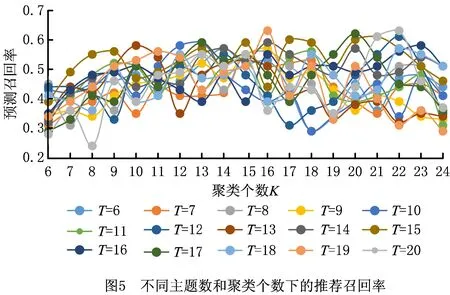
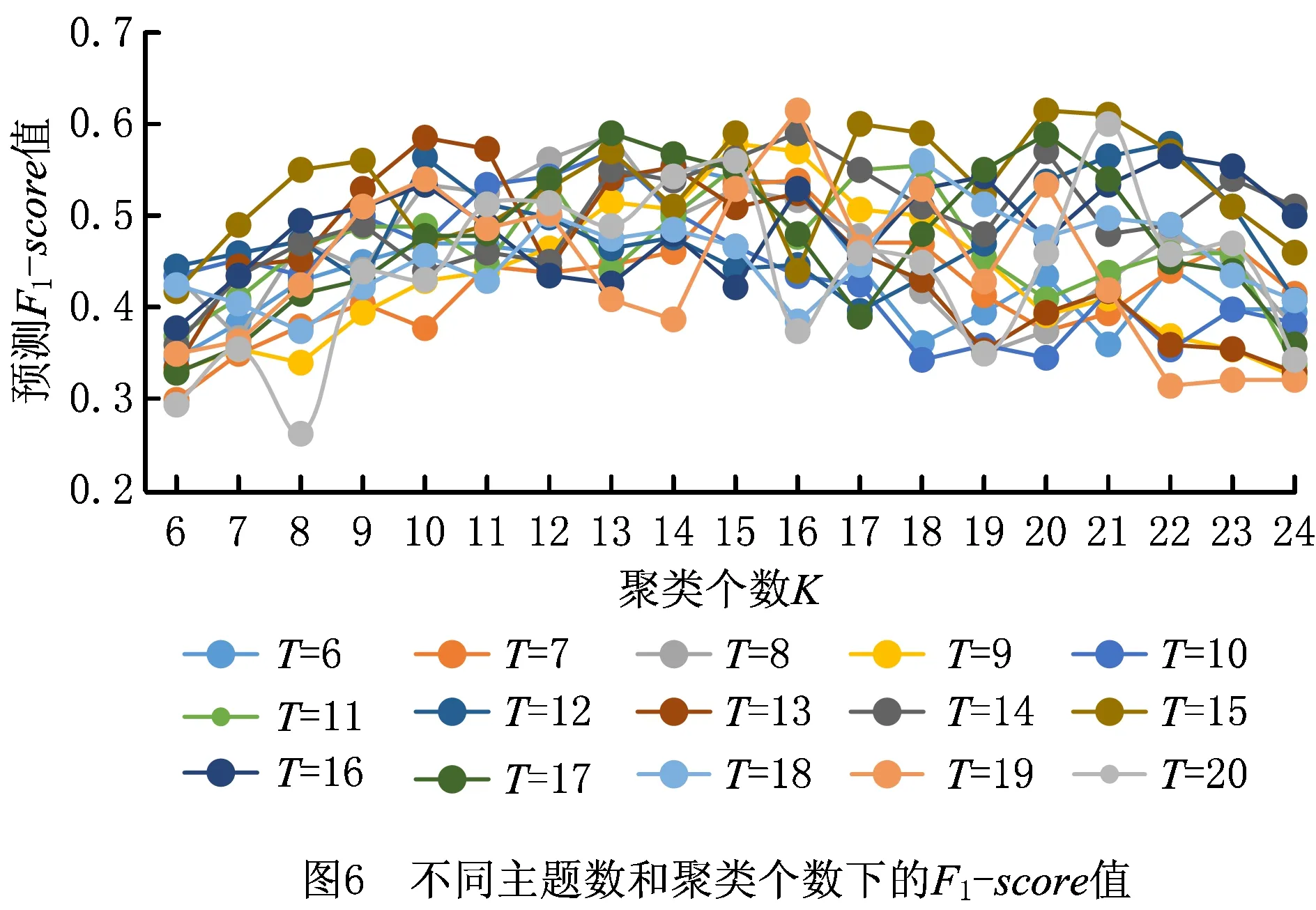
传统的定阶马尔科夫模型(设为L阶马尔科夫模型)假定系统下一时刻的状态分布由其前面L个时刻的状态序列决定,而概率后缀树是一种不定阶的变长马尔可夫模型,它允许各个状态下马尔科夫模型的阶数L动态自适应变化。即对于观测序列x1,x2,…,xt-1,xt,其中:1≤t≤n,n为序列的最大长度,对于以往的一段序列x=x1,x2,…,xt-1,则存在一个L,0 p(xt|x1,x2,…,xt-1)=p(xt|xt-L,x2,…,xt-1) (4) 仍以前述糖尿病患者的用药数据为例,表5展示了部分患者的药物治疗过程对应的药物功效组合标签序列。由前两位患者序列生成的概率后缀树如图3所示。 表5 部分病人药物功效组合标签化诊疗序列 概率后缀树除根节点之外的每个节点都标有一个状态标签序列以及下一个时刻各个标签的出现概率向量。以第三层中序列“88”的节点为例,其关联的概率向量为{“8”:2/3,“3”:1/3,“1”:0,“5”:0},这意味着,出现状态序列“88”的前提下,下一时刻出现标签“8”、“3”、“1”、“5”的条件概率分别为2/3、1/3、0、0,即:p(“8”|“88”)=2/3,p(“3”|“88”)=1/3,p(“1”|“88”)=0,p(“5”|“88”)=0。 需要指出的是,构建概率后缀树时通常采用一定的概率平滑技术,以避免训练数据集中未出现的序列被推断出现概率为0。例如,设定最小出现概率参数ymin为0.001,通过式(5)计算序列σ后出现标签x的概率: prob(x|σ)=(1-|Σ|×ymin)p(x|σ)+ymin。 (5) 式中|Σ|表示所有标签符号的总数。关于概率后缀树的具体构建算法及剪枝策略请参考文献[17],本文不再赘述。此外,实验所得糖尿病药物治疗的完整概率后缀树模型(完整的概率后缀树模型见:https://pan.baidu.com/s/1tQkvEqAZir AUSytu0DCwRg.提取码: res9),由于模型复杂,此处不作详细解释。 本章将药物的预测和推荐视为一个多分类问题,将患者需服用药物对应的功效组合标签作为类标签,将医疗信息系统中记录的患者体征数据、基于医疗过程概率后缀树模型得到的各节点后续功效组合标签出现概率作为特征属性,使用极端梯度提升(eXtreme Gradient Boosting, XGBoost)算法[15]训练分类模型。对于待预测患者,首先提取其当前的体征数据作为特征属性之一,再根据其前期用药历史映射到概率后缀树中某一个节点,以该节点的后续用药功效组合标签出现概率作为另一特征,然后将这两个特征作为上述分类模型的输入,模型输出结果作为后续用药所对应的药物功效组合标签的出现概率。最后,结合各功效组合标签下功效主题的出现概率以及各个功效主题下药物的出现概率,计算各种药物的出现概率,累加排序即得推荐结果。 下面对上述药物推荐过程的关键环节进行介绍。 3.1.1 患者体征数据抽取与向量化 患者每日体征数据反映了病人身体状态和病情演变状况,对于制定下一步治疗方案具有重要意义。MIMIC-Ⅲ数据库将患者每日检查化验所得的体征数据记录在LabEvents表中。表格部分属性如表6所示,最后一列取值为abnormal表示体征项异常,取值为normal表示正常。 表6 患者体征数据示例 基于上述数据,首先过滤掉体征检查结果正常的记录,对于剩余状态异常的各条记录,再去除异常出现次数小于10的体征项;然后,将体征项类比为词,所有病人各个诊疗日对应的全部异常体征类比为文档,按照TF-IDF的思想提取对当前疾病种类而言相对重要的一些体征项。以MIMIC-Ⅲ中糖尿病患者的体征数据为例,经过上述处理后,可得排名前70的体征项(全部特征项见:https://pan.baidu.com/s/1NSw-Iuj0g6AGBTmcXnf FHw.提取码:ypb3),部分特征如表7所示。最后,对于患者每一个诊疗日的体征,根据这70个体征项的状态值构造一个70维的0-1体征向量。具体而言,当第i个体征项呈现异常时,体征向量第i个分量取值为1,否则该分量取值为0。 表7 体征项及其出现频度 3.1.2 基于概率后缀树的药物功效组合标签的出现概率特征 2.3节所得概率后缀树记录了同一种疾病所有患者每日用药所对应药物功效组合标签的上下文统计概率。给定训练数据集中某个患者或者待预测患者某段时间内的用药历史数据,首先可通过LDA主题模型和药物功效分布聚类的方法,将其用药历史转换为一个药物功效组合标签序列,记为σ。然后,可将该序列映射到树中某个具体节点,映射过程为:从概率后缀树的根节点出发,按照序列倒序的方式匹配树中各层节点,如果无法匹配整个序列,则去掉离当前时刻最远的字符,重新从根节点开始匹配。如此重复,直到匹配成功。 假设患者前期用药历史匹配成功时位于概率后缀树的节点N处,记该节点关联的条件概率向量为probNext(σ)。probNext(σ)对应的便是基于概率后缀树得到的下一步药物治疗对应的功效组合标签出现概率,以此作为另一个分类特征。 以图3所示概率后缀树为例,假设患者前3天用药的功效组合标签序列为“588”。首先,从根节点出发找不到与给定序列的逆序“885”完全匹配的路径,为此,舍弃原序列中的第一个标签(即逆序序列中最后一个标签)“5”;接下来查找与逆序序列“88”匹配的路径,显然这与根节点到第三层第1个节点的路径完全匹配,该节点对应的条件概率向量为(2/3,1/3,0,0)。该向量即为当前患者当前药物治疗历史下后续药物功效组合标签的出现概率,将其与患者当前的体征向量并列,共同作为分类特征。 对于数据集中ID为3416的患者,其完整药物治疗过程对应的药物疗效组合标签序列为“8-8-8-8-3-3-1-1”,在构建分类器时,不使用第1天的数据,因为空序列在概率后缀树中的预测结果没有意义,从第2天开始,可以得到其体征数据,假设为Veclb=(1,1,1,1,0,1),由第1天功效组合标签“8”,通过概率后缀树得到第2天的功效组合标签概率分布为Vecpst=(3/4,1/4,0,0),则此时放入分类器的特征数据为[(0,1,1,1,0,1),(3/4,1/4,0,0)],对应的分类标签为第2天真实的标签“8”,即[(0,1,1,1,0,1),(3/4,1/4,0,0)]→8。所有训练数据以此类推可得到表8的训练数据集。 表8 训练数据集示例 XGBoost是一种集成学习算法,它将许多弱分类器集成在一起形成一个强分类器,由于采用了正则化项等多种策略防止过拟合,具有支持并行化和稀疏数据处理等优点,在很多分类学习任务中取得了很好的效果。而且,使用XGBoost构建的分类器,其输出结果为各分类标签出现的概率。利用这一特性,以3.1节所得训练数据为输入,基于所得到的XGBoost分类器可获得下一步药物治疗对应的功效组合标签的分布,记为Vecnext。 进而,记功效组合标签x对应的功效主题多项式分布中,主题t的出现概率为Ptopic|vec(t|x),功效主题t对应的药物多项式分布中,药物drug对应的出现概率为Pdrug|topic(d|t),则对于任意药物d,在标签序列σ后其出现药物d的概率 Ptopic|vec(t|x)×Pdrug|topic(d|t)。 (6) 式中t与x分别取尽所有的药物功效主题与功效组合标签。 最终,可得基于XGBoost分类器的药物推荐算法,如算法1所示。 算法1基于XGBoost分类器的药物推荐算法。 输入:患者当前体征状态数据bflist,由概率后缀树预测得到的后续药物治疗功效标签概率分布probNext(σ),全部功效主题的集合EffList,药物功效组合标签的集合Σ,全部药物的集合DrugList,功效主题t下药物drug的出现概率Pdrug|topic(d|t); 输出:所有药物的推荐概率Pdrug(d)。 1.Vecnext=xgb.precict(bflist,probNext(σ))//得到后续药物治疗的功效组合标签分布 2. FOR EACH(d∈DrugList) //遍历每个药物 3. FOR EACH(x∈Σ) //遍历所有的药物功效组合标签 4. FOR EACH(t∈EffList) //遍历所有的药物功效主题 6. RETURN Pdrug(d) 为验证所提方法的有效性,本文进行了两个对比实验。第一个实验不使用LDA模型和K-means++算法对药物以及药物功效组合进行聚类,直接以患者每日用药序列作为输入来训练概率后缀树,再通过该概率后缀树模型直接进行药物推荐;另一个实验采用本文完整的方案,首先基于LDA模型对药物进行功效主题聚类,再借助K-means++对每日用药的功效主题分布进行聚类得到若干功效组合标签,基于功效组合标签序列构造概率后缀树并进行药物功效组合预测,通过提取病人对应诊疗日的体征项目,构建体征向量,结合概率后缀树的预测结果训练多分类模型;最后,以待预测病人前期各个诊疗日用药的功效组合标签序列和体征数据序列为输入,对后续用药进行预测。下面就这两个实验的数据准备、处理以及预测结果的度量评价进行说明,并将本文实验结果与其他药物推荐方面的工作进行对比。 (1)基于原始用药序列的药物推荐实验 在2.1节所得用药日志的基础上,根据患者的每日用药清单构建治疗过程对应的用药序列。将其中320人的用药序列作为训练数据,剩余80人的用药序列真前缀作为测试数据,之后使用基于概率后缀树的药物预测方法预测下一诊疗日的用药。由于该类病人每天的平均用药数量为15,每次预测给出的推荐药物数量设定为15。 在此设置下,采用传统的准确率、召回率、F指标度量预测结果,具体计算公式如下: (7) (8) (9) 其中:P为准确率,R为召回率,TP为预测药物中被病人下一个诊疗日真实服用的药物数量,FP为预测药物中未在下一个诊疗日使用的药物数量,FN为患者下一个诊疗日实际服用而未被预测到的药物数量。此外,给定药物序列得到的概率后缀树在结构上有一定的随机性,因此本实验进行了10次重复实验,每次实验的准确率和召回率指标如表9所示,预测准确率、召回率F1值均值分别为20.1%、16.4%和18%。 表9 使用药物序列与PST序列生成预测结果 (2)基于本文完整方案的药物推荐实验 采用本文所述完整的技术方案进行患者死亡风险预测,通过提取糖尿病病人对应诊疗日的体征项目,构建体征向量,结合概率后缀树的预测分布结果训练分类器,训练数据和测试数据的划分与上一个实验相同,预测药物数量也为15个,为了保证实验结果尽可能优秀,在本次实验中,LDA主题模型的训练,K-means++聚类个数,以及概率后缀树的剪枝高度,通过“定一动二”的方式选择使得药物预测准确率最高的参数值作为最终模型参数。由于结果太多,此处不进行一一展示,以下实验结果仅展示推荐结果准确率最佳,得到的实验结果如图4~图6所示。 由图4可见,当LDA聚类主题个数为15个且K-means++聚类个数为20时,各项指标达到最佳,预测准确率为0.61。结合图5和图6可以发现,主题数为15、聚类个数为20时召回率为0.6,F1-Score值为0.61,该参数设置下的预测效果较其他参数设置方案有一定优势。 表10展示了部分病人从第2天推荐处方用药准确率的值。可以发现,开始几天预测准确率较低,随着序列增长,预测准确率有所提升。开始几天预测准确率较低,原因可能是病人初期病情不稳定,用药种类也有极大的不确定性,但是随着诊疗序列增加,患者病情也逐渐趋于稳定,可见准确率逐步提升。 表10 部分病人逐日用药推荐准确率 (3)实验结果对比较 分析上述两个实验结果可见,采用本文所给方案得到的药物推荐准确率、召回率和F1值均优于直接从原始用药序列出发、结合概率后缀树进行药物推荐的相应指标。究其原因:①疾病的治疗是一个复杂过程,通常是由多种药物相互作用、共同服务治疗于某一病症,本文所提技术方案通过功效主题聚类的方法有效模拟了这一现象;②患者的诊疗过程是按阶段进行的,而基于K-means++的每日用药功效组合聚类恰恰能反映这一阶段性特征;③同一疾病不同身体状况的患者,使用的药物也有所不同,结合患者特征数据对患者进行药物推荐,更贴近实际的治疗方式。 实际上,除了上述两个对比实验,本文还进行了一个中间实验,即进行药物推荐时不考虑用户体征数据,仅依赖于本文第3章得到的概率后缀树模型进行后续用药预测。这种实验方案相比前述基于原始用药序列的药物推荐实验方案而言,采用LDA模型对药物进行了主题聚类,并利用K-means++算法对每日用药功效组合进行聚类,取得的药物推荐准确率有所提高。但是,该中间实验的预测结果相比本文考虑体征向量后的药物推荐结果有一定差距。 此外,有一些研究者综合运用患者各项检查数据、医嘱指令数据,通过关联规则分析、最近邻算法、逻辑回归、贝叶斯网络等方法进行治疗手段预测和推荐,但这类方法通常要求掌握患者的病症和各项身体指标数据,而这些数据有时难以掌握和利用。文献[18]提出一种只利用患者的医嘱指令数据,基于医嘱指令共现关系的治疗手段预测和推荐方法,但文中实验结果显示其预测准确率不到40%;文献[19]使用LDA主题模型对入院24 h以内病人的诊疗记录进行聚类,结合训练到的主题模型对病人后续的治疗手段进行预测。文献[9]指出了利用LDA模型对治疗手段聚类后给后续预测带来的好处,但是,由于仅利用入院第一天的诊疗数据作为模型训练的基础,该文所提方法仅能对未来若干小时内的治疗手段进行有效预测。相比而言,本文利用的处方数据记录完备,将患者整个住院期间的每日用药数据都作为一个独立文档进行主题模型的训练,并利用不定阶马尔科夫模型对不同诊疗日之间治疗手段之间的时序依赖关系进行了建模,同时考虑了患者的特征数据,实验结果也表明本文方法预测效果有较大提高。 本文提出一种基于医疗过程挖掘和患者体征数据的药物推荐方法。首先利用LDA主题模型对患者用药数据进行训练,得到特定病种药物治疗的功效主题以及各个诊疗日的药物功效主题分布;然后,对患者各个诊疗日的功效主题分布进行聚类,将患者的药物治疗过程转换为药物功效组合标签序列,并在此基础上构建了药物治疗过程的概率后缀树模型;最后,基于概率后缀树计算各节点后续治疗所采用药物功效组合的概率分布,将其与病人的体征向量作为联合特征,病人真实用药对应的功效组合作为分类标签,使用XGBoost的分类方法训练模型,利用该模型据进行患者药物推荐。本文以MIMIC-Ⅲ数据库中糖尿病患者的处方日志和体征数据为数据源,对所提方案的可行性和有效性进行了评估。 本文工作尚存在诸多不足。例如,患者的疾病症状信息并不一定在数据库中得到完整的记录,如何弥补这种信息不完备导致的推荐效果下降等问题,这是下一步改进的一个方向。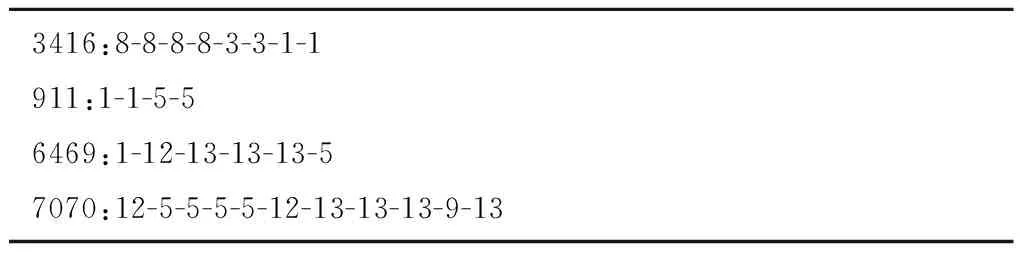
3 基于概率后缀树与患者体征的药物推荐
3.1 特征抽取与训练数据集构建
3.2 基于XGBoost的药物推荐
4 实验结果分析


5 结束语
猜你喜欢
今日农业(2022年14期)2022-09-15
今日农业(2021年14期)2021-11-25
健康女性(2017年3期)2017-04-27
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
辽金历史与考古(2016年0期)2016-02-02
医学信息(2015年5期)2015-03-31
医学信息(2015年7期)2015-03-20
中学生数理化·高考版(2008年2期)2008-11-01
