
基于熵驱动域适应学习的单幅图像阴影检测方法
2020-08-06 08:29袁园,吴文,万毅
计算机应用 2020年7期
袁 园,吴 文,万 毅
(1.新疆理工学院信息工程系,新疆阿克苏 843100;2.温州大学电气与电子工程学院,浙江温州 325035)
(*通信作者电子邮箱1119764335@qq.com)
0 引言
受到光源的遮挡,日常生活中的多数场景均存在着阴影。阴影能保存场景动态及其对象的重要信息,如建筑物和植被区检测[1]、通过卫星图像中的阴影对云进行定位[2];另一方面,阴影同样是误差和不确定性的主要来源,如动态目标跟踪任务中,阴影可能被误标记为目标[3]。因此,识别图像中的阴影能显著提高诸多视觉任务的性能。阴影的形状、亮度取决于光源的强度、方向、颜色以及遮挡物的几何形状和反照率,根据阴影的强度,可将阴影分为硬阴影和软阴影。硬阴影具有较为清晰的阴影边界,而软阴影常在光源强度较低时产生,阴影边界模糊。已有的大多阴影检测方法,常常局限于硬阴影的检测。而相较于视频阴影检测,单幅图像阴影检测因缺少前后帧的相关信息,显得更具有挑战性。
传统阴影检测方法大多建立于阴影像素的亮度与非阴影像素不同的基础上[4-5]。此外,文献[6]基于统计学习方法,首先将图像分成多个图像块,然后使用最小二乘支持向量机(Least Squares Support Vectors Machine,LSSVM)对这些块进行分类以得到阴影检测结果。近年来,基于深度学习的诸多方法[7-12]以其良好的效果与运算效率迅速成为业内标杆。其中,文献[7]结合条件随机场(Conditional Random Field,CRF)和卷积神经网络(Convolutional Neural Network,CNN)用于提取图像中阴影像素的局部特征。文献[8]首次基于大规模阴影检测数据集提出栈式卷积神经网络(Stacked CNN,Stacked-CNN),它令一个CNN 学习到的语义特征去训练另一个CNN并提炼阴影区域的细节。最近,文献[9]基于条件生成对抗网络(Conditional Generative Adversarial Network,CGAN)提出了一种新颖的阴影检测的方法,该框架受益于特殊的敏感因子和对抗学习框架,可以得到较为准确的阴影掩膜。文献[10]基于对抗学习的思想,训练一个阴影图像衰减器以生成额外具有挑战性的图像数据以加强阴影检测的鲁棒性。文献[11]提出栈式条件生成对抗网络(STacked Conditional Generative Adversarial Network,ST-CGAN),使用两个CGAN 分别用于阴影检测任务和阴影去除任务,多任务相互督促以实现共同提升。文献[12]基于U-Net[13],通过更改网络的内部连接保留阴影的全局的语义特征以加强模型阴影检测的能力。
以上方法大致可分为基于自定义特征[4-6]的传统机器学习方法和基于深度学习的特征学习方法[7-12]。因缺乏光源或遮挡物的先验信息,基于自定义特征的传统机器学习方法[4-6]常缺乏鲁棒的自定义特征而无法准确地理解阴影。经过诸多实验验证,基于深度学习的诸多方法[7-12]虽然比传统方法[4-6]更为准确,但其通常仅在同源的测试集上才具有较好的结果。又因常见数据集中的阴影图像大多是通过人为遮挡进行捕获的强阴影图像,然而阴影的形状、场景却不仅仅局限于此类阴影,如建筑物上的阴影,或是当光源不够强时投射的软阴影,它们不具备清晰的阴影边界。使用深度学习方法[7-12]检测这些目标域中的阴影图像(目标数据集)常常只能得到结构不完整、锯齿状的阴影检测结果。
为了解决上述问题,本文提出一种新颖的无监督域适应的阴影检测对抗学习模型。该模型在源数据集上使用监督学习进行训练,但对于未曾接触的目标数据集,因考虑到复杂的人为标注过程从而进行无监督的域适应学习,以使得模型在目标数据集上具有同样的性能,从而加强模型的鲁棒性。具体的,首先在模型特征提取的过程中结合多层特征域适应策略,最小化源域和目标域之间的数据偏差;其次,提出边界对抗分支,使用边界生成器和边界判别器以加强软阴影检测结果的边界结构性;最后,引入熵对抗分支以降低模型处理目标阴影图像中阴影边界区域的不确定性,进一步得到边界平滑、准确的阴影掩膜。
1 域适应对抗学习网络
不同的“域”实则为不同的数据集,域适应的过程旨在使一个模型去适应多个不同的“域”,其目的是为了使模型可以更好地泛化到其他的数据集。诸多基于监督学习的深度学习方法[7-12]虽然可以为阴影自动检测带来显著的性能提升,但因跨域差异(Cross-domain Discrepancy)[14]导致模型在目标数据集上却无法得到令人满意的结果。如图1 所示,通过诸多实验与分析,文献[11]在源数据集ISTD 上训练的深度网络通常仅能为其同源的测试图像生成较为准确的阴影结果,当应用于目标数据集SBU[8]时,阴影检测结果边界结构性较差,见图1(b)。而所提模型不仅在源数据集上表现优异,在目标数据集上依然具有较好的检测能力,见图1(c)。相较于这些方法[7-12],当面临新鲜的数据集时,所提方法不再需要繁琐的人工标注工作为训练数据提供相应的阴影标签数据,而是采取无监督学习的方式,旨在使得模型在面临新数据集时可以轻易地实现域适应从而获得与源数据集同样准确的阴影检测结果。

图1 跨域差异分析Fig.1 Analysis of cross-domain discrepancy
所提阴影检测框架如图2 所示,对于源域和目标域中的阴影图像,首先分别采用单独的特征提取通道,并且从低层到高层逐一采用域判别器用于判断当前特征的所属域标签;然后分别构建两条生成对抗分支,其中边界对抗分支用于加强目标数据集中软阴影图像的检测能力,而熵对抗分支可以进一步抑制阴影边界处的不确定性,从而得到边界平滑、准确的阴影掩膜。得益于完善的目标函数以及特殊的网络连接,两个任务相互约束、相互促进以实现精准的跨域阴影检测。
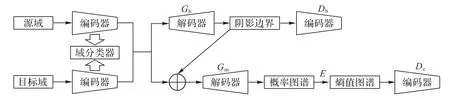
图2 本文网络结构Fig.2 Architecture of proposed network
1.1 分层域适应特征提取
传统的域适应模型[15]仅在最后一个卷积层中校正不同域之间特征分布从而实现全局域适应。然而,该方法忽略了低层特征的重要性,使得某些域敏感的局部特征削弱了域适应模型的泛化能力;其次,因存在不可转移的层[16-17],单个的域分类器难以消除源域和目标域之间的数据偏差。受到文献[18]的启发,以源域和目标域中的阴影图像为输入,在图像编码过程中,编码器中的每个卷积层均有相对应的特征图谱,提取编码器中多个中间层的输出特征图谱,在源域和目标域的编码器之间的每一个卷积层上构建相应的图像域分类器来督促中间层的特征匹配,旨在让两个不同的编码器在不同的数据集下依然具有相似的特征提取过程以达到域适应的目的,其目标函数[18]如式(1)所示:
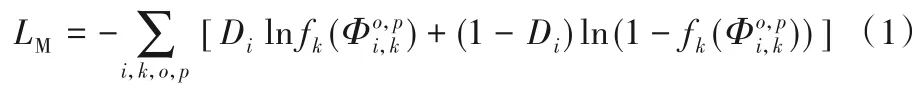
其中:Di为第i个图像的域标签;表示第i张图像中的坐标为(o,p)的像素在第k层上特征图谱的激活值;fk是其相应的域分类器。
分层域适应成分保证了两个域之间的中间特征具有相似的分布,从而加强适应模型的鲁棒性。在阴影检测过程中,消除域间的数据偏差能提高模型在目标数据集上阴影检测的准确度。如图3 所示,图3(a)为目标域[8]中的两幅阴影图像;图3(b)为标签数据;图3(c)为全局域适应的阴影检测结果;图3(d)为分层域适应的阴影检测结果。对比图3(c)和图3(d),使用分层域适应特征提取之后,模型得到了较好的泛化,对于图像中与阴影毗邻的不同颜色的文字具有更精准的检测能力。

图3 分层域适应对于阴影检测效果的影响Fig.3 Effect of multi-level domain adaptation on shadow detection
1.2 边界对抗分支
已有的阴影检测数据集[8,12]因采集手段单一(在强光源下使用各种形状的遮挡物进行遮挡)而缺乏场景丰富的软阴影图像。受光源强度的影响,软阴影图像因阴影较浅不具备清晰的阴影边界。而现有的诸多深度学习方法[7-12],均无法在软阴影图像上得到较好的检测结果。如图4 所示,对于目标数据集中的软阴影图像,仅校正特征分布无法得到边界结构化的检测结果,见图4(b)。
为解决上述问题,构建边界对抗分支加强模型在目标数据集中预测结果的边界结构性,边界对抗分支旨在为阴影图像生成如图4(c)中的阴影边界图像,然后基于对抗学习的原理,使用判别器进一步提升生成图像的质量。有了阴影边界的初步定位,后续的阴影检测结果将更加具有边界结构性,最终提升软阴影的检测能力。假设源数据集为S,其标签数据为单通道的真实阴影掩膜ys,而目标数据集T无标签数据。首先,生成器Gb拟合图像中的阴影边界,分别为源阴影图像xs和目标阴影图像xt生成边界预测结果Gb(xs)和Gb(xt),其可视化效果见图4(c);其次,将判别器Db旨在判断该边界来自于源数据集还是目标数据集。加入边界对抗分支之后,对于目标域中的软阴影图像,其结果已经可以准确地标识阴影区域,见图4(d)。

图4 边界对抗分支分析Fig.4 Analysis of boundary-driven adversarial branch
对于带有域标签的源域和目标域数据集,边界判别器Db分别对Gb(xs)和Gb(xt)进行判断和惩罚,见式(2):

其中:LB为二元交叉熵损失,其定义为而N 和M 分别为源数据集和目标数据集中图像的数量。
而生成器的损失函数LGb由源数据集上的平均绝对误差损失项以及目标数据集上的对抗损失项加权组合而成,见式(3):
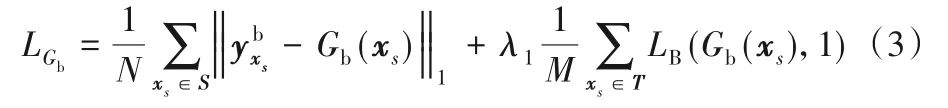
1.3 熵对抗分支
边界对抗分支之后,若直接使用额外的阴影掩膜生成器,会为目标数据集生成锯齿状的阴影检测边界(图4(b))。受到文献[19]的启发,阴影掩膜结果在阴影边界附近的区域具有较高的熵值(不确定性),会导致锯齿化边界现象。
为了抑制不确定的预测结果,熵对抗分支首先为阴影图像生成如图5(b)中的阴影概率图谱,其标识每个像素是阴影的概率。基于该概率图谱,进而使用香农熵将概率图谱转化为熵值图谱,强制目标域熵值图谱和源域熵值图谱尽量相似,从而缩减模型在目标和源数据集上的效果差异,最终以对抗学习的思想提高生成图像的质量。熵值图谱中的高熵值只应该围绕在阴影边界处。而合理的熵值分布对应着边界平滑的阴影检测结果,见图5(c)。

图5 熵对抗分支分析Fig.5 Analysis of entropy-driven adversarial branch
掩膜生成器Gm分别为源图像和目标图像生成掩膜预测结果Gm(xs)和Gm(xt)。给定输入图像x的掩膜预测结果p,使用香农熵可计算熵值图谱(图5(c)),如式(4)所示:

熵判别器De旨在校准E(xs)与E(xt)的分布。与边界驱动的对抗学习类似,熵判别器De判断熵值图谱是来自于源域还是目标域,其目标函数如式(5)所示:
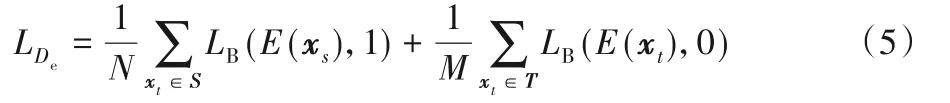
生成器的损失函数LGm包含由源数据集上的像素级的交叉熵损失以及目标数据集上的对抗损失项目加权组合而成,见式(6):
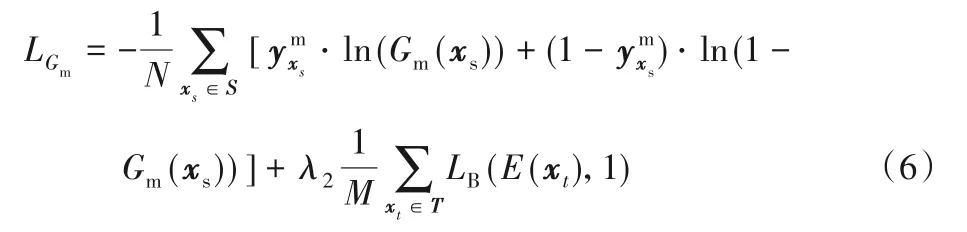
1.4 网络结构与训练方式
因所提网络并未集成任何注意力模型成分,理论上任何编码-解码的网络结构均可以适用于所提框架。在本文中,所提网络的生成器采用文献[20]中的U-Net 结构,U-Net 结构由一个收缩通道和一个扩张通道组成,其中收缩通道用于提取语境特征,而与其对称的扩张通道则用于图像上采样以得到一幅生成图像。所提网络的判别器同样与文献[20]一致,其包含多个卷积块,每个卷积块中,卷积层都紧跟着批标准化[21]和激活函数LeakyReLU。判别器的最后一层为一个Sigmoid函数,其输出为某对图像为真的概率值。受到文献[15,18]的启发,在训练过程中,使用交替梯度更新策略优化生成网络和判别网络。首先优化边界和熵判别网络,分别最小化目标函数式(2)和式(5);其次优化生成器网络,优化生成损失(式(3)和式(6))以及分层域适应损失(式(1)),生成器网络的整体损失函数如式(7)所示:

2 实验结果与分析
所提方法的实验软件平台以Python程序设计语言为编码核心,辅以第三方TensorFlow 包搭建网络结构。其硬件实验平台建议在内存为16 GB、八核Inter I7 CPU、NVIDIA GTX 1080Ti 的Ubuntu 18.04 操作系统上。在网络中,将LReLU 的斜率设置为0.25,使用Adam 优化目标函数。将数据集中286 ×286 的图像裁剪成多个256 ×256 的子图像并翻转以增大训练数据量。通过大量实验,超参数初始化如下:λ1=0.5,λ2=0.5。如图6 所示,展示了源数据集[11]中三组不同的训练图像,这三组图像分别代表了简单几何边界阴影、文字混合阴影以及复杂结构阴影图像。场景多样的训练数据集更有利于网络模型的泛化。

图6 网络训练所需的数据集Fig.6 Datasets for network training
图6中:图6(a)和图6(b)用于训练熵对抗分支;而图6(a)和图6(c)用于训练边界对抗分支。其中,图6(c)中的阴影边界标签数据是基于图6(b)中的阴影边界内外拓展3个像素得到窄宽带(经过诸多实验验证,跨度为6 个像素的窄宽带区域足以囊括大部分的软阴影边界,而宽度过大则会影响结果的精度)。
2.1 结果分析
将所提方法与三种最新的阴影检测方法[10-12]进行对比,其中文献[10]提出一种名为A+D Net 的网络结构,其中A Net旨在原训练数据集的基础上生成额外符合物理光照模型的阴影图像以增强模型对不同类型阴影的泛化能力,而D Net则负责检测图像中的阴影;文献[11]基于两个CGAN 构建一种名为栈式条件生成对抗网络(STack Condition Generative Adversarial Network,ST-CGAN)的网络结构,使用多任务学习的模式先后进行阴影检测和阴影去除任务,两个任务之间相互学习、相互督促;文献[12]基于传统U-Net 图像生成模型,通过更改编码、解码过程中的网络连接来保留每个卷积层的语义信息以提高阴影检测的精度。将所提方法与文献[10-12]方法对ISTD 数据集进行训练,并在同源的ISTD 测试集上做对比分析。图7 展示了不同方法在四幅不同阴影场景下的阴影检测效果。对比图7(c)、(d)、(e)、(f)可以发现熵驱动的对抗学习模型在源域上同样有较大的性能提升。面对跨纹理、文字混淆、形状不规则等较为复杂的阴影场景,同样能得到较好的检测结果,具有较好的鲁棒性。值得注意的是,相较于文献[11]内部不够完整的阴影检测结果,同样可以侧面体现出边界对抗分支的必要性。
为了验证所提方法的跨域检测性能,将所提方法与文献[10-12]在SBU 数据集上做跨域对比实验。图8 展示了不同方法在四幅不同阴影场景下的跨域检测性能,第一行中,因结合了多层域适应特征提取过程,所提方法不会将运动员的黑色短裤误作阴影。同样的,所提方法相较于其他两种方法,在第三行和第四行中的软阴影图像中也具有较好的准确度,因本文提出边界对抗分支并结合信息熵引入熵对抗分支,使得阴影检测结果具有较好的边界结构性,并且阴影边界平滑、自然。

图7 不同方法在源数据集ISTD上的表现Fig.7 Performance of different methods on source dataset ISTD

图8 不同方法在SBU数据集上的跨域表现Fig.8 Cross-domain performance of different methods on SBU dataset
2.2 客观评价指标
因阴影检测任务常需要考虑输出结果中不同类别像素间的不平衡分布情况[12],因此本文并不使用文献[22]中的均方根误差(Root Mean Squared Error,RMSE)作为衡量指标,而选用平衡误差率(Balance Error Rate,BER),如式(8)所示:

其中:TP、TN、FP以及FN分别为正确检测的阴影像素、正确检测的非阴影像素、错误检测的阴影像素以及错误检测的非阴影像素。同样,本文也考虑到不同区域的平均像素的错误率(Per pixel Error Rate,PER)。
表1 展示了图7中各个方法使用ISTD 数据集所做的同域检测分析。在BER 的测试数据上,所提方法比较为先进的CPNet(文献[12]方法)降低约10.5%。表2展示了图8中各个方法使用SBU训练集所作的跨域检测分析。

表1 各个方法在ISTD数据集上的源域阴影检测性能Tab.1 Comparison of source domain shadow detection performance among different methods on ISTD dataset

表2 各个方法在SBU数据集上的跨域阴影检测性能Tab.2 Comparison of cross-domain shadow detection performance among different methods on SBU dataset
将表2中的各项数据与表1进行横向比较,可以观察到所有方法都会出现性能缩减,但使用所提域适应阴影检测方法,在BER 的测试数据上,比CPNet 降低约18.75%,该数据可以说明所提方法具有较好的跨域检测性能。
3 结语
因已有的阴影检测方法仅在同源数据集上才具有较好的阴影检测性能,本文提出一种新颖的阴影检测方法,该方法欲在目标数据集上得到和源数据集上同样准确的检测结果。首先,结合分层域适应特征提取方法,在特征提取的每个卷积层后均加入域分类器,用于缩小域间数据差异,从而提升模型的鲁棒性;其次,先后采用边界对抗分支和熵对抗分支以得到边界结构化、平滑的检测结果。相较于最为先进的几种阴影检测方法,所提方法不仅在源域上具有较大的提升,在目标域上同样具有优势。在未来进一步的研究工作中,将考虑从生成多样性的阴影图像数据的角度进一步提升模型的性能。
猜你喜欢
故事作文·高年级(2022年2期)2022-02-24
计算机研究与发展(2022年1期)2022-01-19
纺织科学研究(2021年7期)2021-08-14
计算机应用(2020年12期)2020-12-31
文苑(2020年11期)2020-11-19
现代装饰(2020年4期)2020-05-20
中国诗歌(2019年6期)2019-11-15
小猕猴智力画刊(2017年6期)2017-07-03
数学大王·中高年级(2016年4期)2016-05-14
文苑(2015年9期)2015-09-10
