
PSO-LSSVM用于近红外光谱预测混合制浆材Klason木质素含量
2020-07-23 11:16熊智新刘耀瑶房桂干
中国造纸学报 2020年2期
熊智新 刘耀瑶 王 勇 梁 龙 房桂干
(1.南京林业大学江苏省制浆造纸科学与技术重点实验室,江苏南京,210037;2.中国林业科学研究院林产化学工业研究所,江苏南京,210042)
随着市场需求的扩大以及林纸一体化的现状,大型造纸企业已不局限于使用单一木材品种,而是多采用混合木材制浆[1-2]。在制浆造纸过程中,Klason木质素含量的高低直接决定漂白剂的用量[3],但由于混合木材制浆无法保证多种制浆材的混合均匀度,使得整个制浆造纸过程中Klason木质素含量不同。因此,针对不同批次、品种各异的制浆材建立统一的分析模型,实现快速、准确地检测混合制浆材中Klason木质素含量,以便在线调整漂白剂用量等工艺参数,对保证生产稳定具有重要意义[4]。然而传统的Klason木质素湿化学测量方法较为繁琐,且所使用的化学药品也会造成环境污染问题[5]。近年来,随着近红外技术的发展,结合化学计量学建模方法对木材材性进行定量分析的研究逐渐增多[6-9]。在实际生产中,制浆厂原料来源相对稳定、材性范围分布窄,短期内难以收集到大量代表性样品;木材的近红外光谱表征是多种组分综合吸收的结果;在固体状态下检测样本时,难以保证散射系数的一致性,也使光谱吸收与某一成分含量之间呈现复杂的非线性[9];这些都对制浆材近红外化学计量学分析模型的及时修正或维护十分不利。最小二乘支持向量机(Least Square Support Vector Machines, LSSVM) 是 Suykens等[10]在 支 持 向 量 机(Support Vector Machines,SVM)的基础上提出的。LSSVM在利用结构最小化原理较好解决非线性、高维数和局部极小的前提下,将约束条件转化为等式约束,大大降低了计算复杂度,具有建模速度快、泛化能力强、可针对小样本进行统计学习等优点,并已广泛应用于近红外定性定量分析[11-13],但将LSSVM回归建模应用于混合制浆材的近红外定量分析却鲜有报道;而高性能的光谱数据建模方法,能够提高光谱预测精度,也是近红外光谱分析技术能够得到推广应用的关键。本研究利用便携式近红外光谱仪,针对5种制浆材原料中Klason木质素含量,通过粒子群寻优(Particle Swarm Optimization,PSO)算法优化LSSVM模型参数建立PSO-LSSVM预测模型,并与传统的偏最小二乘回归(Partial Least Squares Regression,PLS)和主成分降维后的BP神经网络(PCA-BPNN)算法进行对比,探讨在含有较少制浆材代表性样本的情况下建立最优模型的策略,以促进近红外光谱分析技术在混合制浆材材性快速检测领域中的应用。
1 算法描述
1.1 LSSVM原理
给定n个建模集样本{xk,yk}其中,xk∈Rm,为m维建模样本输入;yk∈R,为建模样本输出。则优化问题J(ω,ξ)和约束条件 s.t.y(x) 可以分别表示为:

式中,φ(xk):Rm→Rmh,为输入空间到高维空间的非线性映射函数;ω∈Rmh,为权系数向量;C为正则化参数;b为阈值;ξk∈R,为拟合误差。引入αk∈Rm(k=1,2,…,n),定义拉格朗日函数为:
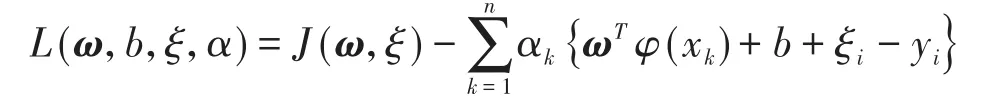
又根据KKT(Karush-Khun-Tucker)条件得到:

通过KKT条件可列出求解α和b的线性方程组:

式中,P1×n是1×n的单位列向量;Pn×1是n×1的单位行向量;I为n×n的单位阵;K(xk,xl)=φ(xk)Tφ(xl)为满足Mercer条件的核函数,其中k,l=1,2,…,n;y=运用最小二乘法求得关于α和b的回归函数如下:

核函数的选择是决定支持向量机性能的关键,常用的核函数有:线性核函数、多项式核函数、高斯核函数(RBF)、Sigmoid核函数等。本研究选用RBF函数为RBF函数的带宽。
1.2 PSO算法确定系统参数
本研究选用RBF函数,因此LSSVM中需要优化的参数为正则化参数C和RBF核函数的带宽σ。在此,采用PSO算法确定这两个参数。
假设对群体规模为m的粒子群进行搜索,粒子i在群体中的位置为Xi=(x1,x2,…,xn),运动速度为Vi=(v1,v2,…,vn)。每个粒子都有一个目标函数决定的适应度(fitness value)。粒子群初始化为一群位置和速度均随机的粒子,通过迭代找到最优解,在每一次的迭代中,粒子通过跟踪两个“最优值”来更新自己,一个为个体最优值(pbest),是粒子本身找到的最优解;另一个为全局最优值(gbest),是整个群体目前找到的最优解。粒子群更新公式如下:
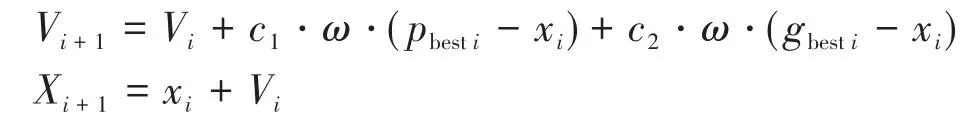
式中,ω是介于[0,1]间的随机数;c1和c2是学习因子或加速系数。通过不断更新粒子,直至满足迭代结束条件之后,得到粒子的最优位置,即为LSSVM模型对应的最优正则化参数C和带宽σ。PSO算法流程图如图1所示。

图1 PSO算法流程图
1.3 评价指标
模型建立过程采用校正结果的相关系数(Rc)和校正标准偏差(RMSEC)对模型性能进行评价,以便建立最优的校正模型[14];模型建立完成后,通常采用预测结果的相关系数(Rv)、预测标准偏差(RMSEP)、真实值与预测值间的绝对偏差(AD)和相对标准偏差(RPD)等指标综合评价模型的性能。RMSEC、AD和RMSEP越小、Rc和Rv越接近1,则所建模型的稳定性与预测性越好;RPD是用来评价模型精度的指标,当RPD大于3时,表明模型具有较高的预测精度;当RPD<1.75时,则模型不可用[15]。但由于相关系数(R)的大小与建模预测样品浓度分布范围相关,当建模预测样品的浓度分布范围宽,即使R接近于1,模型预测效果也较差;反之,若建模预测样品的浓度范围窄,R可能较小,但模型预测精度却较高[14]。故R并不能完整地反应模型预测精度,因此实际应用中,相关系数R需根据实际情况,结合RMSEP、AD和RPD综合评价模型的性能。
2 实 验
2.1 实验仪器
采用无锡迅杰光远科技有限公司生产的IAS-2000系列便捷式近红外光谱仪,仪器核心部件为基于微机电系统(Micro-Electro-Mechanical System,MEMS)技术生产的数字微镜器件(Digital Mirror Device,DMD)光栅分光系统。仪器基本参数如下:光栅规格为300刻线,DMD扫描宽度12.87 nm,波长范围900~1700 nm,分辨率10 nm,InGaAs探测器。
2.2 木材样品数据
5种常见制浆材(松木、杉木、相思木、桉木和杨木)由中国林业科学研究院林产化学工业研究所提供,共计82个原木样品。将原木样品切削成木片并磨碎,然后选取40~60目的木粉样品在近红外光谱仪上采集光谱。采集样品光谱时,将样品放入测量杯中以200 g砝码压平以使其分布均匀且需保持固定的高度,每个样品重复装样6次进行测定以获得平均光谱。每扫描完一个样品,用毛刷去除样品杯中的残留木粉,以免影响后续样品光谱的准确性。
2.3 Klason木质素标准值测定
按照GB/T 2677.8—1994进行制浆材Klason木质素的测定。用质量分数为(72±0.1)%的硫酸水解制浆材样品(样品已经过苯醇混合液抽提),然后依次测得所有制浆材样品水解残余物(即制浆材的Klason木质素)的质量,测量结果如表1所示。由表1可知,82个制浆材样品Klason木质素的含量分布范围为14.82%~34.20%,平均值为26.43%,标准差达到5.39%。由此可知,82个样品分布范围较广,具有良好的代表性,有利于建立更准确、更稳定的预测模型。

表1 5种制浆材样品Klason木质素含量分布
2.4 数据处理软件
本研究采用NIRSA 4.5系统以及Matlab2010a软件平台。NIRSA4.5系统是本实验室自主研发的专门用于近红外光谱数据处理的化学计量学软件(计算机软件著作权登记号2007SR06801),主要用于近红外光谱预处理、样品集的划分以及PLS算法和PCA-BPNN算法建模;Matlab2010a平台则主要用于PSO算法确定系统最优参数以及LSSVM算法建模的程序编制。
3 结果与分析
3.1 建模样品集划分与光谱预处理
用于建立模型的样品是否具有较强代表性对于所建模型的可靠性具有重要影响,目前常用的建模集样品选取的方式有含量梯度法、Duplex法、Kennard-Stone(K-S) 法[16]和 SPXY 算法[17]。为建立较广适用性的常用制浆材Klason木质素含量的预测模型,本研究采用SPXY算法选择62个样品作为建模集,剩余20个样品作为预测集,经部分调整使两个集合中都含有5种制浆材。
近红外光谱仪所采集的光谱除样品自身信息外,还包含了其他无关信息和噪声。因此,在用化学计量学方法建模时,消除光谱数据中无关信息和噪声的预处理方法变得十分关键[18]。合理的预处理方式可以有效地过滤近红外光谱中的噪声信息,保留有效信息,从而降低近红外定量模型的复杂度,提高近红外模型的稳健性。目前,常用的近红外光谱预处理方法主要有微分、平滑、多元散射校正(Multiplication Scatter Correction,MSC)、和标准正态变量变换(Standard Normal Variate Correction,SNV) 等[19]。本研究对样品集的光谱进行一阶微分(First Derivative,1st)、平滑(移动平均平滑(MA)和Savitzky-Golay卷积平滑(SG))、MSC以及SNV预处理后,再进行PLS回归,结果如表2所示。
由表2可知,原始光谱经MSC方法预处理后,模型预测相关系数Rv达到0.9811,RMSEP最小,为1.0265,RPD最大,为4.1030。综合3个评价指标分析可知,经MSC预处理后建立的PLS模型预测精度较另外4种预处理方法更优。近红外漫反射光谱(Near-Infrared Diffuse Reflectance Spectroscopy Analysis,NIRDRSA)技术是实现粉末状固体样品无损快速检测的常用技术,但是利用该技术需以样品散射系数S的一致性作为前提,而散射系数S主要受样品的粒径及其分布均匀程度等物理因素影响。样品的粒度越大,粒径分布越不均匀,散射系数S的不一致程度也越大,由此导致的误差也越大[20]。而MSC算法则能够减少各种因素导致的散射系数S差异对光谱测量的影响[19],提高近红外校正模型的精度。因此,本研究选取预测性能最好的MSC对制浆材样品的原始近红外光谱进行预处理。

表2 不同预处理方法下的PLS建模结果
3.2 定量校正模型的建立
3.2.1 PLS近红外光谱分析模型的建立
在PLS建模中,随着主成分数的增多,载荷向量对建模的重要程度逐渐降低,到一定程度后,载荷向量将变成模型的噪声,因此选择合适的主成分数显得尤为重要。本研究选定最大主成分数为15,并采用留一法交叉验证来选取预测残差平方和(PRESS)最小的主成分数作为最终的主成分数。图2显示制浆材Klason木质素建模集PRESS值随主成分数的变化,当主成分数≥11时,PRESS值趋于稳定。因此,选取11个主成分建立PLS近红外光谱分析模型,对预测集进行预测分析。PLS模型实测值和预测值散点分布结果如图3所示。
3.2.2 PCA-BPNN近红外光谱分析模型的建立
在PCA-BPNN建模方法中,采用PCA的得分作为BPNN的输入变量,这样不仅大大降低训练时间,减小网络规模,而且可在几乎不丢失光谱信息的前提下剔除噪声[21]。
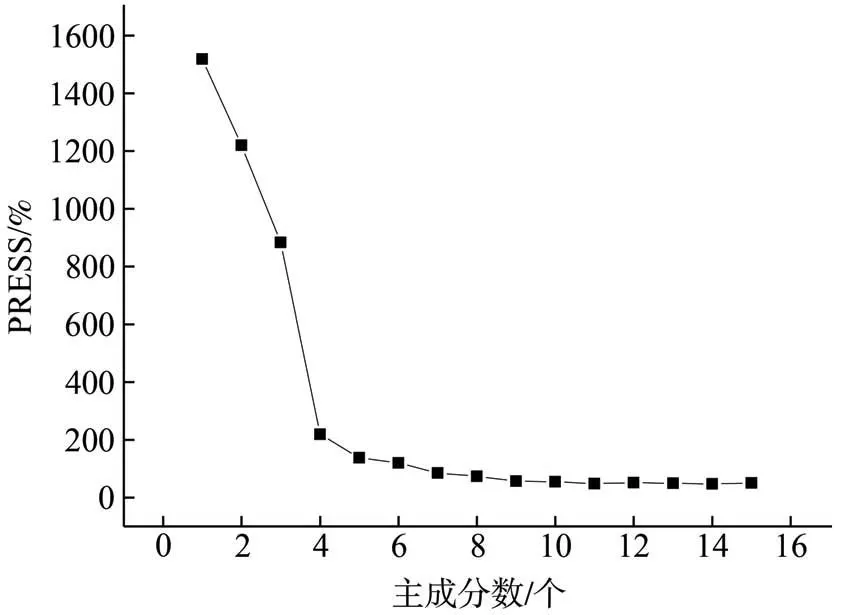
图2 建模集PRESS随主成分数的变化

图3 PLS模型实测值-预测值散点图

图4 PCA-BPNN模型实测值-预测值散点图
建立一个3层的BPNN网络。首先对光谱进行主成分分析,根据方差份额低于0.25%的标准[22]提取前7个成分作为BPNN的输入变量;然后根据经验公式[23]确定隐含层单元数的范围为6~12,在范围内经过多次试验确定最佳隐含层单元数为8。建立一个(7,8,1)网络结构的PCA-BPNN近红外光谱分析模型,对预测集进行预测分析,模型实测值-预测值散点分布结果如图4所示。
3.2.3 PSO-LSSVM近红外光谱分析模型的建立
LSSVM建模过程中,RBF核函数的带宽σ和正则化参数C的选择直接影响到模型的学习和泛化能力,如果σ过小则会产生过学习现象;如果σ过大则会造成欠学习现象[24]。
本研究采用PSO算法对LSSVM模型的参数进行优化,PSO算法参数设置为:c1=c2=1.5、ω=0.5、初始粒子数为70、最大迭代次数为300。通过对训练数据的学习及PSO算法对LSSVM模型参数的优化调整,得到LSSVM模型对制浆材Klason木质素进行预测的最优参数为σ=106.4、C=757.8;PSO-LSSVM模型实测值-预测值散点分布结果如图5所示。

图5 PSO-LSSVM模型实测值-预测值散点图
3.3 不同算法建模结果分析
对经过预处理后的光谱分别建立PLS、PCABPNN和PSO-LSSVM模型,各模型对制浆材Klason木质素含量的预测结果如表3所示。
由表3可知,对相同光谱数据的制浆材Klason木质素含量进行预测,PSO-LSSVM模型的预测效果优于PLS模型和PCA-BPNN模型。在建模样本的回归拟合度和精度方面,PSO-LSSVM模型的校正相关系数Rc最大,可达0.9966,校正标准偏差RMSEC最小,为0.4412%,效果最佳,表明PSO-LSSVM模型对于建模集样本具有较高的回归精度,拟合能力较强,能够通过已有的数据达到较高的训练程度,预测结果接近建模集样本的真实值;而PLS模型校正相关系数Rc最小,校正标准偏差RMSEC最大,在3种建模方法中表现最差,表明制浆材Klason木质素含量的近红外分析模型的校正过程中,非线性方法(BPNN和LSSVM)的训练能力要优于线性方法(PLS)。模型对预测集样本的回归拟合度和精度反映了模型对于预测集样本的预测能力,是衡量模型性能最重要的指标。比较3种建模方法的预测结果,PSO-LSSVM模型的预测相关系数Rv最大,为0.9857;预测标准偏差RMSEP最小,为0.7498%,比PLS模型和PCA-BPNN模型分别降低0.2767%和0.1455%;真实值与预测值间的绝对偏差AD范围在3个模型中最小,为0.0065%~1.8449%;相对标准偏差RPD最大,为5.6174,比PLS模型和PCA-BPNN模型分别提高1.5144和0.9138。
通过以上各个指标综合评价可知,相对于PLS模型和PCA-BPNN模型,PSO-LSSVM模型的预测精度有较为明显的提高,PSO-LSSVM模型能够对预测集做出精确的预测,在3种建模预测效果中表现最佳;其原因可从多方面分析:存在于制浆材木粉中的Klason木质素,其复杂的物理空间结构及化学存在状态导致其光谱吸收的复杂性,而NIRDRSA分析技术中的漫反射吸光度与被测对象含量(如Klason木质素)的线性关系只有在散射系数保持不变、样品的粒度合适,以及透射、规则反射光和仪器光谱特性影响可以忽略不计等各条件均满足时才能成立[25]。尽管MSC预处理方法能够消除部分会导致散射系数不一致的影响因素,但为了直接利用木粉样品实现快速无损检测,其样品制备和测量条件很难保证严格的规范性,使得漫反射吸光度和Klason木质素浓度必然偏离线性关系。同时制浆造纸厂木片原料的物理化学性状相对稳定,其中的化学组分含量分布范围也较窄,因此难以收集到足够数量的代表性样品。PLS方法虽然采用了非线性迭代偏最小二乘算法提取与Klason木质素相关的潜变量建立回归模型,但本质上仍是一种线性建模方法。本研究中每个木粉样品经光谱测量后,可同时获得700个波长处的吸光度,建模集光谱对应为62×700的高维矩阵,通过PCA对该高维矩阵降维,可以简化后续BP人工神经网络的拓扑结构以及计算复杂度,且是一种非线性建模方法;但人工神经网络需要大量的样本进行训练,才能较好地使网络神经元之间的连接权重充分表达Klason木质素和木粉近红外光谱之间复杂的非线性关系。当代表性木材样本有限时,PCA-BPNN建立的模型精度及其稳定性将大大降低。因此,利用LSSVM算法更利于发挥SVM在解决小样本、非线性及高维数据分析中的许多独特优势,再结合PSO方法,又可在全局范围内自动优化LSSVM模型中的参数,避免建模中的主观因素,从而获得最佳模型。

表3 不同模型对制浆材Klason木质素含量的预测结果
4 结论
为优化混合制浆材中Klason木质素含量的近红外预测模型,首次尝试将粒子群寻优-最小二乘支持向量机(PSO-LSSVM)算法用于制浆材Klason木质素含量的测定分析,并对比了线性建模方法偏最小二乘(PLS)以及非线性建模方法主成分降维后的BP神经网络(PCA-BPNN)和PSO-LSSVM 3种模型,主要结论如下。
(1)由于所测混合制浆材为木粉样品,因此装填密度、粒径分布及其均匀性在测试过程中不易控制,近红外漫反射时散射系数S一致性难以保证,导致光谱测量误差,通过多元散射校正(MSC)预处理可以部分消除此误差,有效地增强了与Klason木质素组分相关的光谱信息,提高了Klason木质素近红外分析模型的精度。
(2)与PLS算法及PCA-BPNN算法相比,PSOLSSVM算法建模后的预测效果最好;其优点在于既可以充分利用有限的代表性制浆材样品,基于光谱和Klason木质素含量测得的数据,从该非线性高维模式空间中提取分析信息,又可利用PSO算法自动优化模型参数,简化建模过程,提高模型精度。
(3)本研究采用近红外光谱仪器的全部波段,在进行PSO算法优化寻优时,所用时间较长,不利于制浆材Klason木质素含量的快速建模分析,因此未来研究中可以考虑通过降维处理或波长选择方法来减少LSSVM的输入变量,以提高建模的速度。
猜你喜欢
中国造纸(2022年9期)2022-11-25
中国造纸(2022年8期)2022-11-24
造纸信息(2022年8期)2022-11-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
轮胎工业(2021年4期)2021-12-25
建材发展导向(2021年23期)2021-03-08
新能源进展(2020年1期)2020-03-09
造纸信息(2019年7期)2019-09-10
造纸信息(2019年7期)2019-09-10
中国造纸(2019年6期)2019-09-10
