
基于医疗数据的聚类挖掘策略研究
2020-07-15 05:03王艳娥王红刚丁心安
计算机技术与发展 2020年7期
王艳娥,安 健,王红刚,丁心安,杨 倩
(1.西安思源学院 理工学院,陕西 西安 710038;2.西安交通大学深圳研究院,广东 深圳 518057)
0 引 言
聚类是数据挖掘中有效分析数据的手段之一,根据物以类聚的思想,将相关性较高的数据划分为一类,相关性较低的数据划分为不同类。聚类的优势是不需要数据的先验知识,算法会根据数据的内部特征,使用一定的相关性测量方法分析数据,从而得到隐藏在数据内部的数据之间的关系。聚类被广泛应用在图像处理[1]、大数据[2]、人工智能[3]等众多领域。现在随着医疗的信息化,医疗数据越来越庞大,医疗的图像、病理记录等以数据方式存储在电脑上,为有效协助医护人员对病情进行预测和诊断,聚类算法被越来越多地应用在医疗数据中[4-5]。常用的聚类算法有基于划分、基于层次、基于密度、基于模型和基于网格的聚类方法[6]。
K-medoids算法是划分式聚类算法的经典算法之一,因其原理简单,易实现得到广泛应用。传统的K-medoids算法虽对噪声数据不敏感,但随机选取初始聚类中心,导致聚类结果不稳定。因此众多学者对K-medoids算法进行优化,提高算法的聚类准确率和稳定性。传统K-medoids算法的经典代表是PAM算法[7],PAM算法随机选择初始聚类中心,且通过全局搜索更新聚类中心使得聚类时间消耗太大。优化PAM算法的经典算法是快速K-medoids算法(Park算法)[8],该算法选择距离最小的样本作为初始聚类中心,克服聚类中心随机选择导致的不确定性,同时更新初始聚类中心时采用类内进行迭代,大大减少聚类时间,但Park算法选择出的聚类中心常处于同一个类中,并不符合样本集的实际分布。为克服Park算法的缺点,初始聚类中心的选择仍是Park算法研究的热点之一。基于样本集方差优化K-medoids初始聚类中心选择[9],选择方差最小且处于不同区域的样本作为初始聚类中心,虽然在一定程度上选择稳定的初始聚类中心,但这些样本仍然处于同一个类簇中,并不能反映样本的实际分布。基于宽度优先搜索的K-medoids聚类算法[10],以粒计算初始化获取初始有效粒子,再根据二叉树宽度优先搜索原理迭代出最优聚类中心,在一定程度克服传统K-medoids算法存在的缺陷,但对多维的医疗数据而言聚类时间消耗过大。
文中主要基于医疗数据研究K-medoids算法,在PAM和Park算法的基础上优化K-medoids,以期优化后的算法能够在医疗数据上有较好的聚类效果。
1 PAM算法和Park算法
PAM算法的思想是在样本集中随机选取K个样本作为初始聚类中心,剩余样本按照与K个聚类中心距离的远近分配到最近的类簇中;然后反复选取任意非类中心样本取代聚类中心,再重新分配非类中心样本,直到满足一定的评价标准,聚类结束。
Park算法针对PAM算法随机选取初始聚类中心和更新聚类中心时使用的是剩余全部样本进行搜索迭代这两个缺点进行优化。基本思想是以距离为基础计算每个样本的密度,选择前K个密度最大的样本作为初始聚类中心,在更新聚类中心时选取同一类簇中距离其他样本距离和最小的样本作为新的聚类中心,直到满足一定的评价标准,聚类结束。Park算法虽然有效克服了PAM算法存在的问题,但是Park算法选择的K个初始聚类中心并不符合样本的实际分布,K个样本常处于同一个类中,使得聚类的结果并不理想。
这两种算法评价标准的目标是使同类的样本尽可能相似,不同类的样本尽可能相异,采取常用的聚类误差平方和[11]作为评价结果的指标,聚类误差平方和越小说明同类簇的相似性越高,不同类相似性越低,聚类的结果符合样本的实际分布,聚类效果越好。
2 改进的K-medoids算法
设待聚类的样本集为X,X={x1,x2,…,xn},其中xi是一个包含p维数据的样本。将样本集划分为K类,聚类中心集为C,C={c1,c2,…,ck},其中ci表示第i类的聚类中心。文中算法以样本之间的距离度量样本的相似度,以聚类误差平方和作为目标函数,动态选择样本密度最高的K个样本且处于不同区域作为初始聚类中心,在更新聚类中心的过程中采用类内和类外相结合的方法,优化聚类中心的选择,减少聚类迭代次数,加快聚类过程。
2.1 相关概念
定义1:样本xi,xj的欧氏距离为d(xi,xj):

(1)
定义2:样本xi的密度为density(xi):

(2)
其中,f(xi,r)表示以xi为中心、半径为r的球体内样本的个数,在r值确定的情况下,该值越大说明xi处于样本集越密集区域,r=var*tp,且0tp≤1,tp为经验值。bwd(xi)等于所有球体内样本到非球体内其他样本距离之和,wid(xi)为球体内所有样本之间距离和,值越大表示同类相似性越大,不同类相似性越低。所以density(xi)的值越大,xi作为初始聚类中心的几率越大。
定义3:样本xi的距离均值m(xi):
(3)
定义4:样本集的均方差var:
(4)
定义5:样本集聚类误差平方和E:
(5)
其中,ci是第i类的聚类中心,x是非i类的样本。E值越小,类内样本之间相似性越高,聚类效果越好。
2.2 优化K-medoids算法实现
输入:样本集X={x1,x2,…,xn},类簇数K;
输出:样本集的K个划分w1,w2,…,wk,以及K个聚类中心c1,c2,…,ck,其中w1∪w2∪…∪wk=X,wi∩wj=φ,i≠j。
算法实现步骤:
(1)根据定义2计算每个样本的密度, 并对样本按照密度的从大到小排列。

(4)重新将剩余样本与距离最近的聚类中心划分为一类。
(5)根据定义5计算聚类误差平方和,判断是否满足条件。如果不满足转到(3),如果满足转到(6)。
(6)输出样本集的K个划分,完成聚类。
2.3 算法分析
根据以上的算法步骤,在计算样本密度时,需计算样本之间的距离以及样本集的方差。样本集的规模为n,样本之间的距离根据定义1计算时,时间复杂度为O(n2),计算样本的方差时,距离已知,时间复杂度为O(n)。更新聚类中心时,计算每个样本的类内和类间时间复杂度为O(n2)。因此文中算法的时间复杂度为O(n2)+O(n)+O(n2)。
选择初始聚类中心时,文献[9]选择高密度区域距离固定的样本作为初始聚类中心。不管这个距离过大或过小,选择的初始聚类中心都不能反映样本集聚类中心的实际分布,如果距离过大可能导致选择离群点作为初始聚类中心,或无样本可作为初始聚类中心。文中通过不断动态调整后续待样本与已选择聚类中心之间的距离,选择满足一定距离且密度最高的样本作为初始聚类中心,保证初始聚类中心的选择始终在样本集的密集区域,且能够符合样本集的实际分布。
3 实验结果分析
为验证文中聚类算法在医疗数据上的有效性,选择UCI机器学习数据库[12]中三个乳腺癌样本集进行测试,并与PAM算法与Park算法进行对比。实验仿真环境:Windows7,64位操作系统,intel CORE i5-4200,CPU1.6 GHz 2.3 GHz,内存8 G;编程环境matlab R2012a。
聚类结果的评价方法采用聚类误差平方和、聚类时间、聚类准确率和Rand Index[13]。
3.1 医疗数据集分析
文中用于测试的乳腺癌数据集为wdbc[14]、breast-cancer-wisconsin[15]和Breast Cancer Coinmbra[16],其中wdbc和breast-cancer-wisconsin数据信息在1995年完成,Breast Cancer Coimbra数据信息在2018年完成。关于这三个数据集的信息见表1。
表1 乳腺癌数据集
wdbc数据集包含569个样本(实际的病例数据),分为2类,样本无缺失数据。数据集中每个样本包含32个属性,其中第1个属性为样本的编号,第32个属性为样本的真实类别,其余属性为乳腺细胞相关测量数据,如半径、纤维、光滑度等。
breast-cancer-wisconsin数据集包含699个样本,分为2类。该数据集共有11个属性,第1个属性为样本编号,第11个属性为样本类别,其余属性为乳腺细胞测量数据。数据集中有16个样本缺失数据,文中按照数据挖掘缺失数据中取平均值方法,对缺失数据进行补充完整,保证数据集的样本数量。
Breast Cancer Coimbra是2018年完成采集的一组乳腺癌数据集,包含116个样本,分为2类,无样本缺失数据值。该数据集每个样本包含10个属性,第1属性值为年龄,第10组为类别,其中64个样本为癌症,52个为健康病例。
为验证文中算法在选择初始聚类中心的有效性,生成人工样本集。该样本集包含75个样本、每个样本含有2个属性,分为3类,且符合正态分布。生成样本集的参数如表2所示。

表2 人工数据集生成参数
3.2 实验结果分析
3.2.1 人工样本集结果分析
人工模式样本集的实际分布见图1。为了更好地测试文中算法在选择初始聚类中心的有效性,对人工样本集中的75个样本按照从上到下的顺序按升序编号,处在第1个位置的样本编号为1号,第75个位置的样本编号为75号。样本集划分为三类,其中样本序号1~30为第一类,样本序号31~55为第二类,样本序号56~75为第三类。在图1中第一类用“+”表示;第二类用“●”表示;第三类用“○”表示。

图1 人工数据集分布
PAM算法、Park算法和文中算法在人工样本集中选择的初始聚类中心所在样本集中的序号见表3。

表3 不同算法选择的初始聚类中心序号
由表3可知,在人工数据集中PAM算法随机选择初始聚类中心,因此聚类中心每一次都不确定;Park算法选择的初始聚类中心序号分别为45、34、35,这三个序号都属于第二类簇,所以Park算法选择密度最大的前K个作为初始聚类中心的样本位于同一个类簇中。Park算法选择的前K个样本的具体分布见图2。文中算法选择作为初始聚类中心的样本序号分别是55、4、66,这三个序号的样本分别是第二类簇、第一类簇和第三类簇的样本,选择的初始聚类中心分布在不同类,且处于不同类密度较高的区域,符合样本集实际分布。文中算法选择的初始聚类中心的分布见图3。

图2 Park算法选择的初始聚类中心

图3 文中算法选择的初始聚类中心
3.2.2 乳腺癌数据集实验结果分析
PAM算法、Park算法和文中算法在三种乳腺癌样本集的聚类误差平方、聚类时间见表4、表5。为了方便表示,breast-cancer-wisconsin在表中简写为bcw,Breast Cancer Coimbra简写为BCC。

表4 三种算法的聚类误差平方和
由表4可见,文中算法的聚类误差平方和均小于PAM算法和Park算法,因此文中算法的聚类结果同一类样本的相似度最高。Park算法聚类误差平方和优于PAM算法,PAM算法的聚类误差平方和最差。
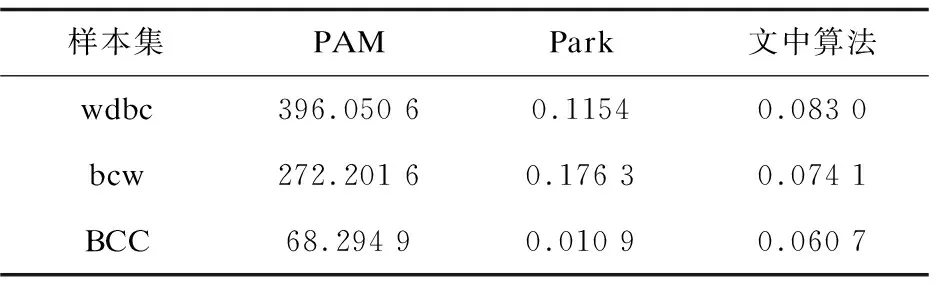
表5 三种算法的聚类时间
由表5可见,文中算法在wdbc和breast-cancer-wisconsin的聚类时间明显优于其他两种算法,但Park算法在Breast Cancer Coimbra样本集中的聚类时间优于文中算法,PAM算法的聚类时间最差。
三种算法在乳腺癌数据集上的聚类准确率和Rand Index如图4和图5所示。

图4 三种算法的聚类准确率

图5 三种算法的Rand Index值
图4为三种聚类算法在不同乳腺癌样本集上的聚类准确率,结果显示Park算法的聚类准确率在wdbc和Breast Cancer Coimbra两个样本集上优于PAM算法,PAM算法在breast-cancer-wisconsin中的聚类准确率优于Park算法,而文中算法的聚类准确率最优。图5为三种聚类算法在不同乳腺癌样本集上的Rand Index值,结果显示PAM算法的结果最差,Park算法较优于PAM算法,而文中算法的指标最优。
4 结束语
基于医疗数据,针对K-medoids算法存在的不足进行优化,优化后的K-medoids算法通过实验验证,选取的初始聚类中心更符合样本的实际分布,聚类误差平方和、聚类准确率等指标均优于其他两种算法。该算法虽然在乳腺癌数据集中具有较好的聚类效果,但随着医疗大数据的产生,将优化的聚类算法应用于医疗大数据也是未来研究的方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
现代仪器与医疗(2021年1期)2021-06-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2018年5期)2018-07-18
