
基于OutbackCDX的增量式Web信息采集研究
2020-07-13 03:15白如江
山东理工大学学报(社会科学版) 2020年4期
高 婷,白如江
一、引言
当今社会互联网信息技术飞速发展,随着网络信息资源数量和种类飞速增加,网络信息资源逐渐变为人类数字文化遗产中重要的组成部分。由于网络信息资源具有更新快、易丢失的特点,导致其消亡的速度很快,特别是一些重要的历史性的网页信息会随着网页的消失而丢失,这些信息如果消失就难以找回或复原,从而造成难以估量的损失。
2015年,互联网数据传输协议的缔造者之一,谷歌副总裁温特·瑟夫(Vint Cerf)指出了一个令人们为之一颤的忧虑,他担心随着数字技术的不断迭代演化,今天人类保存在互联网上的图片、文档或文件等信息可能彻底丢失,在进入一个“数字黑暗时代”后,未来的人类可能根本没有关于21世纪的历史记录。
美国数字信息基础架构和保存项目(NDllP)的报告中指出,网络信息的平均寿命为44天,这就导致相当一部分有价值的网络信息资源面临着消失的危险[1]。由此来看,人类将失去大量具有重要价值的学术、文化、科学信息。随着对网络信息资源保存的认识日益深入,越来越多的国家政府和机构将网络信息资源作为文化遗产进行保存。
目前,世界各国的政府、组织、机构纷纷开始开展与Web Archive相关的研究和实践,其中,美国、加拿大、西班牙和澳大利亚等国家的政府、档案馆和图书馆对网页归档的研究和实践应用较多。
在国内,对Web Archive进行研究的项目主要有中国国家图书馆网络信息资源保存实验(Web Information Collection and Preservation,WICP)和中国Web信息博物馆两个项目。且中国国家图书馆网络资源保存实验不完全针对网页归档,其主要研究是对电子资源的一个保存归档,只有“中国Web信息博物馆”是在国家“973计划” 和“985工程 ”项目支持下,由北京大学计算机系网络与分布式系统实验室开发建设的中国网页历史信息存贮与展示系统[2]。国内对网页归档的研究与应用开展较晚,与国外差距比较大。国内Web 信息的特殊价值和作用使国内科研机构对这方面的研究和实践日益重视。2014年11月,国家档案局局长杨冬权在会见阿里巴巴集团副总裁兼“阿里云”总裁胡晓明及其团队时表示,将尽快启动为各级国家政府网站网页存档工作[3]。
我们在国内外现行网络归档研究项目的基础上,借鉴国内外网络信息资源采集工具的先进技术[4-5],针对我国网络资源增量采集过程中遇到的困难,提出一种网页归档的增量采集方案。
二、Web信息档案保存项目
(一)互联网档案馆(Internet Archive)
在美国,1996年成立了“互联网档案馆”(Internet Archive),致力于实现全球互联网信息的收集、存储和获取。目前档案馆从不同领域超过2亿个网站和40多种语言中挑选出来的各类项目已收录超过3510亿个网页。此外还有大量的视频、音频、软件和电子书。该互联网档案馆数据库随着因特网的扩展而扩展,每月增长近100TBs(压缩)。通过Wayback使Web集合平均处理每秒400~500个请求。
(二)国际互联网保存联盟(IIPC)
2003年,由12个国家机构共同成立了国际互联网保存联盟(IIPC),中国国家图书馆也在2007年加入了该联盟。其最初的协议有效期为三年,会员资格仅限于特许机构。IIPC现在向世界各地的图书馆、档案馆、博物馆和文化遗产机构开放。IIPC成员来自45个国家,其主要包括国家、大学和地区图书馆和档案馆。
IIPC的使命是为世界各地的后代获取、保存和利用互联网上的知识和信息,促进全球交流和国际关系。为实现其使命,IIPC正在努力实现三个目标:一是使来自世界各地的丰富互联网内容的收集得以保存,从而能够随着时间的推移进行存档、保护和访问;二是促进开发和使用能够创建国际档案的常用工具、技术和标准;三是鼓励和支持各地的国家图书馆、档案馆和研究机构处理互联网存档和保存问题。
目前,大多数国家的图书馆和档案馆都与国际互联网保存联盟IIPC进行合作。IIPC资助开发了一些开源的网页筛选、采集、保存和网页回放工具,这些工具已经在一些国家的图书馆和档案馆广泛应用。以IIPC为主的各成员通过分享数据和测试工具在研究和发展项目中进行合作,IIPC根据年度征求建议书中列出的目标去资助技术和教育项目。该联盟还通过共享数据和测试工具在研发项目上进行合作,成立专责小组以研究特定问题或提出建议。
以下是三个典型的IIPC合作项目。
1.第一次世界大战纪念网保存项目
第一次世界大战纪念网项目是建立与第一次世界大战有关的网站集合,它包括标志战争一百周年的网站和事件以及一般研究第一次世界大战的网站和事件。该项目旨在收集包括一系列不同类型的网站,从官方纪念活动到业余历史网站,以及在媒体上报道百年纪念。目前,来自几个不同国家和多种语言的网站已被国际互联网保护联盟的成员图书馆选中,以提供关于战争百年纪念的跨国视角。
第一次世界大战纪念网项目存档从2015年10月开始,目前共有2540条网站结果,每一条结果包含以下内容:
网址:http://10158d.esidoc.fr/rubrique/view/id/74?feature=website
在2015年11月16日和2018年12月20日这段时间内捕获了6次,包含5个视频捕获。
视频:5个视频捕获
语言:法语
覆盖范围:南比利牛斯(法国地区)
关键词为“公共:教育”
网站类型:公共类
国家:法国
文件格式选择:所有格式、HTML、纯文本、PDF、Postscript、Word
每条记录会提供具体捕获的网页存档,如图1所示。

注:*表示页面更新时间。
2.Twittervane评估项目
英国图书馆在IIPC的资助下开发了一个名为原型应用程序Twittervane,该应用程序能够分析Twitter提要并确定在给定时间段内围绕给定主题最常共享的网站。然后,这些网站可以作为网络存档的潜在标题呈现给管理者,从而节省了手动选择所需的时间和精力。
大英图书馆在2012年大会上展示了Twittervane,并向IIPC成员提供了Twittervane的源代码。来自三个国家图书馆的负责人探索并测试了该应用程序,提供了非常有用的反馈。大多数参与评估的负责人都对Twittervane方法持肯定态度,并将其视为一种补充选择工具,特别是对于基于事件的集合。
(1)Twittervane系统有2个优点
第一,允许归档机构更快地响应突发或零星事件。
第二,利用网站的普及作为选择标准,利用人群的智慧,为网络存档增加社交方面的内容。
(2)Twittervane有3个服务组件
第一,TweetView组件提供用于创建和报告Web集合的管理和报告功能。
第二,TweetStreamAgent提供用于管理来自Twitter的入站推文数据的UI和服务。
第三,TweetAnalyser对与Tweet相关联的缩短URL执行URL扩展,将Tweet解析为Web集合并管理Tweets的存储。
Twittervane各部分的结构关系的展示如图2。
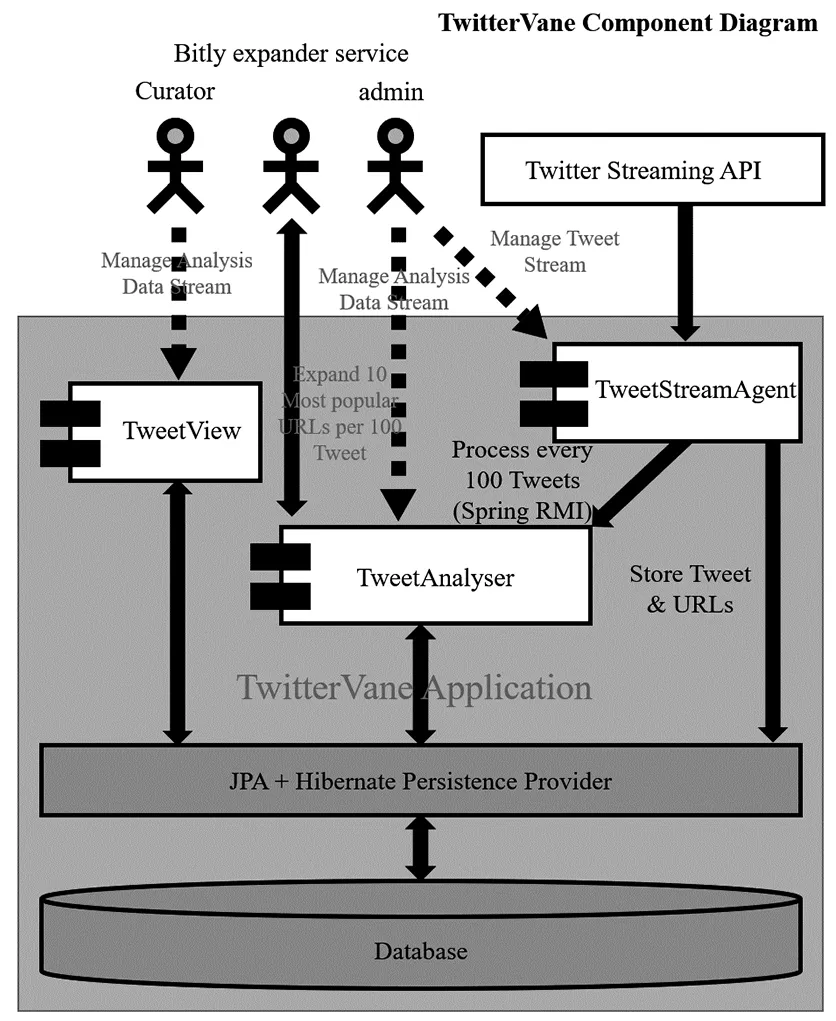
图2 Twittervane各部分之间的结构关系
(3)Twittervane主要存在的问题
第一,不允许将收集的推文存储在普通的JSON文件中执行大规模分析。
第二,没有数据清理功能,自动删除旧的分析推文。
第三,缺乏自动化后台流程以分析和处理捕获的推文。
第四,没有增量采集功能。
3.Memento项目
Memento的目标是希望能够像访问当前的网页一样直接访问过去的网页。具体来说是使用Memento可以访问过去某个日期存在的网页资源版本,方法是像往常一样在浏览器中输入该资源的HTTP地址,并在浏览器插件中指定所需的日期。显然,如果某些资源不存在,将只能看到旧版本的资源。例如,在网页存档或内容版本控制系统中将会出现这种情况。但是如果存在旧版本,并且如果这些资源由支持Memento协议的服务器托管,我们就能无缝地访问它们。
该项目的其他目标主要还有:
第一,聚合IIPC的分布式档案的元数据。
第二,提供基于Memento的开放档案馆藏访问权限。
第三,提供有限档案馆藏的知识。
第四,向IIPC成员提供IIPC的全封闭档案初始演示的知识。
Memento项目的主要参与者有:奥地利国家图书馆、国会图书馆、大英图书馆、瑞士国家图书馆、北德克萨斯大学等。
Memento项目在技术架构方面,提出了基于时间访问资源状态的HTTP框架。基于HTTP的Memento框架桥接了当前和过去的Web。它通过引入日期时间协商和TimeMaps来促进获得给定资源的先前状态表示。日期时间协商是内容协商的变体,它利用给定资源的URI和用户代理的首选日期时间。TimeMaps是枚举封装给定资源先前状态的资源URI列表。
该框架还有助于识别封装另一资源的冻结先前状态的资源。
第一,日期时间协商:它是内容协商的变体,通过该变体,用户代理表达与原始资源的表示有关的日期时间偏好,而不是例如媒体类型偏好。基于响应服务器对原始资源的过去的了解,它选择最符合用户代理的日期时间偏好的原始资源的Memento。
第二,TimeMaps:TimeMap是一种资源,可以从中获取列表,提供原始资源过去的全面概述。服务器使TimeMap可用,枚举服务器知道的所有Mementos及其归档日期时间。用户代理可以获取TimeMap并从中选择Mementos。
Memento框架定义了三种类型的资源:Original Resource,Memento和TimeGate。
第一,Original Resource:先前版本的实时Web上存在或曾经存在的Web资源。先前版本是指在过去的某个时间封装原始资源的Web资源。
第二,Memento:一种Web资源,它是原始资源的先前版本,即封装了过去某个时间原始资源的样子。
第三,TimeGate:一种基于给定日期时间“决定”的Web资源,Memento最能匹配给定日期时间周围的原始资源。
图3提供了Memento框架如何允许访问资源的先前版本的架构概述。
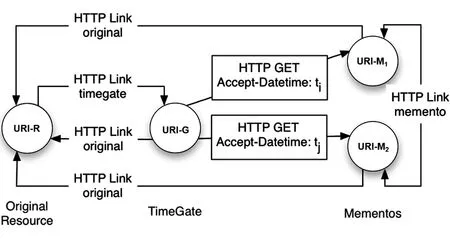
图3 Memento框架允许访问资源的先前版本架构概述
为了允许HTTP客户端访问原始资源(URI-R)的先前/存档版本,该资源提供HTTP链接头,其关系类型为“timegate”,指向其TimeGate(URI-G)。TimeGate支持日期时间维度中的内容协商。在与TimeGate协商时,HTTP客户端使用Accept-Datetime标头来表示URI-R的先前/存档版本的所需日期时间。TimeGate响应匹配版本的位置,名为Memento(URI-M1或URI-M2),允许HTTP客户端访问它。使用Memento-Datetime标题,Mementos表达他们的版本/存档日期时间。
关系类型为“原始”的HTTP链接头从TimeGate和Mementos返回到原始资源,允许HTTP客户端回溯其步骤。Memento可以使用关系类型为“memento”的HTTP Link标头指向其他Mementos。它可以指向其时间上相邻的Mementos,它分别结合了“prev”和“memento”关系,以及“next”和“memento”关系。
TimeGate和Memento都可以分别通过组合“first”和“memento”关系以及“last”和“memento”关系,使用HTTP链接头指向URI-R的第一个和最后一个Memento。每当 “memento”关系类型在HTTP链接头中表示的链接中使用时,它必须附带一个“datetime”属性,该属性传递链接Memento的存档日期时间。
通过上述项目调研分析发现,目前Web Archive工作中最主要的困难是关于信息增量采集的问题,也就是说在不影响网络信息采集质量和全面性的基础上,如何实现避免因重复搜集未变化的网页而带来时间上的浪费。我们在前期调研基础上发现OutbackCDX(1)Outbackcdx[EB/OL].https://github.com/nla/outbackcdx/blob/master/README.md.、UKWA-Heritrix(2)Ukwa-heritrix[EB/OL].https://github.com/ukwa/ukwa-heritrix.两个工具的有机结合可以满足网页动态采集需求。
三、OutbackCDX的网络信息动态采集
Web信息增量采集的主要思路是维护一个增量采集数据库,该增量采集数据库记录着每个资源的历史记录,这样可以用于确定等待获取的资源的优先级队列中的顺序。利用自适应重新访问技术更准确地捕获其范围内在线资源的变化,从而使爬虫程序能够更频繁地重新访问每个页面。此外,重新访问不受爬行周期的约束,因为任何页面都可以在任何时间出现进行重新访问,而不是在爬虫运行期间仅出现一次。
根据上述总体思路,我们运用与需求结合比较成熟的Heritrix和OutbackCDX工具实现网络信息增量的采集。
(一)OutbackCDX
OutbackCDX是一个基于rocksdb的捕获索引(cdx)服务器,能够支持增量更新和压缩。可以用作OpenWayback、PYWB和Heritrix的后端。我们采用OutbackCDX作为增量采集数据库,用来记录抓取资源的历史信息。因为该数据库可以实时增量更新。
OutbackCDX的主要特征有:
1.同时支持OpenWayback(XML)和PyWb(JSON)CDX协议;
2.可以实现实时,增量更新;
3.能够压缩索引(varint packing + snappy),通常是CDX文件大小的1/4 ~1/5;
4.可以进行访问控制。
可以在https://github.com/nla/outbackcdx/网站上下载OutbackCDX并安装,安装好OutbackCDX后就可以加载爬行数据了。OutbackCDX不包括用于读取WARC或ARC文件的CDX索引工具。因此,需要使用OpenWayback或PYWB附带的CDX索引器脚本。可以通过在(11-field)cdx格式的wayback中发布记录,将记录加载到索引中,具体实现方法如下:
$ cdx-indexer mycrawlw.warc.gz > records.cdx
$ curl-X POST--data-binary @records.cdx http://localhost:8080/myindex
Added 542 records
如果需要删除数据,可以执行以下代码:
$ curl-X POST--data-binary @records.cdx http://localhost:8080/myindex/delete
Deleted 542 records
查询数据代码:
$ curl 'http://localhost:8080/myindex?url=example.org'
org,example)/20030402160014 http://example.org/text/html 200 MOH7IEN2JAEJOHYXIEPE
EGHOHG5VI===--2248 396 mycrawl.warc.gz
查询出的数据是json格式,如下所示:
$ curl 'http://localhost:8080/myindex?url=example.org&output=json'
[
[
"org,example)/",
20030402160014,
"http://example.org/",
"text/html",
200,
"MOH7IEN2JAEJOHYXIEPEEGHOHG5VI
===",
2248,
396,
"mycrawl.warc.gz"
]
]
(二)UKWA-Heritrix
UKWA-Heritrix在Heritrix做了部分功能扩展,UKWA-Heritrix项目包含了一些类,这些类允许OutbackCdx用作Heritrix爬行的重复数据源。因此可以借助UKWA-Heritrix结合OutbackCdx实现网络信息的增量爬取。
UKWA-Heritrix主要功能还是网络爬虫功能。其主要工作原理是从一个或若干初始网页的URL开始,利用HTTP等标准协议读取文档,将文档中所包括的URL放入URL队列中,然后从队列中新的URL处开始进行漫游,把爬过的网页搜集起来,直到没有满足条件的新的URL为止。
UKWA-Heritrix与Heritrix的组织结构基本一致如图4所示,包含了整个组件和抓取流程。
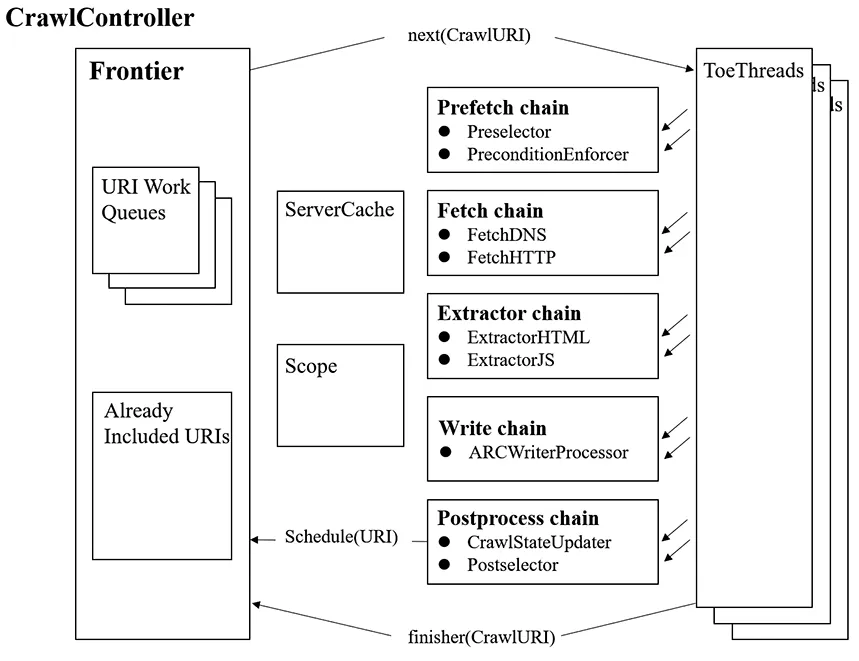
图4 UKWA-Heritrix系统架构
Heritrix自带了部分用于主题增量爬虫抓取方案,比如:
1.将不需要爬取的URL写入Heritrix的log文件recover.gz中。该文件自动记录了已抓取的URL信息,Heritrix每次抓取时会访问该文件,在该文件中的URL将放弃抓取,从而实现避免重复抓取。
2.将Heritrix的配置文件order.xml中的
但是,这些方法在爬取时都需要Heritrix重启新的爬取任务,无法对指定URL记录进行增量爬取。因此,我们将OutbackCDX引入Heritrix与UKWA-Heritrix结合实现增量信息采集。加入OutbackCDX后Heritrix的下载控制器形成结构如图5所示。
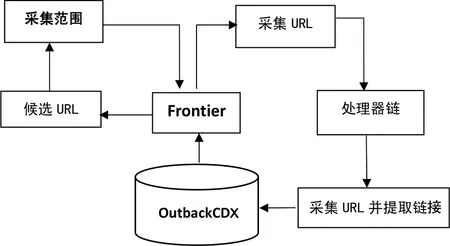
图5 基于OutbackCDX的增量信息抓取结构
图5中OutbackCDX作为URL访问存储器,Frontier决定抓取策略。具体运行过程如下。
第一步:Frontier发出抓取指令;
第二步:对Frontier发出的某一URL进行采集;
第三步:对采集回来的网页进行页面内的URL链接提取;
第四步:提取出的URL存储到OutbackCDX中;
第五步:Frontier从OutbackCDX中调取候选URL进行下一步的采集,往复进行。
由于OutbackCDX是可以直接单独访问的数据库,因此可以直接操作OutbackCDX实现特定URL的增加、删除、修改操作,实现网络信息的增量采集,而不需要Heritrix每次重新启动抓取程序。
(三)保存格式
爬取下来的文档保存格式决定着磁盘空间、管理效率与数据交换标准。Web Archive 中的文件存档格式有多种,如ARC(4)ARC[EB/OL].https://en.wikipedia.org/wiki/ARC_(file_format).、WARC[6]、CDX[7]等,IIPC 推荐使用WARC(Web ARChive)格式。WARC格式于2009年6月被正式批准成为ISO标准(ISO28500:2009)。
WARC(web archive)格式指定了一种将多个数字资源与相关信息组合成一个聚合存档文件的方法。WARC格式是Internet存档的ARC文件格式的一个修订版,传统上用于将web crawls存储为从万维网获取的内容块序列。WARC格式包含了旧格式,以更好地支持存档组织的收集、访问和交换需求。除了当前记录的主要内容外,修订版还包含相关的次要内容,例如分配的元数据、简化的重复检测事件和以后的日期转换[8]。
WARC格式文件是一个或多个WARC记录的串联。一个WARC记录由一个记录头、一个记录内容块和两个新行组成;该头具有记录日期、类型和记录长度的强制命名字段,并支持对每个收获的资源(文件)的方便检索[9]。有八种类型的WARC记录:“warcinfo”“response”“resource”“request”“metadata”“review”“conversion”和“continue”。WARC文件中的内容块可以包含任何格式的资源,例如,可以嵌入或链接到HTML页面中的二进制图像或视听文件。
综上所述,国内对网络信息增量采集的研究较少,随着网络国家记忆的需求逐步增加,网页信息增量采集将会在网络信息存档工作中扮演越来越重要的角色。目前国家档案局等单位已经对此项工作高度重视起来,但我们的有关研究还比较薄弱,希望在此方案基础上,有更多的研究机构对此进行更多的研究和实践,提高网页的爬取效率,在单位时间能获得更多高质量的页面,从而为我国的网络信息增量采集工作提供一些参考和启示。
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
云南档案(2021年1期)2021-04-08
成都信息工程大学学报(2021年6期)2021-02-12
云南档案(2019年8期)2019-12-16
妇女生活(2019年1期)2019-01-17
魅力中国(2018年5期)2018-07-30
中学科技(2016年7期)2017-05-16
中学生英语·中考指导版(2014年9期)2015-03-30
