
基于层次嵌入的方面抽取模型∗
2020-07-13 12:48刘漳辉肖顺鑫郑建宁
计算机与数字工程 2020年5期
刘漳辉 肖顺鑫 郑建宁 郭 昆
(1.福州大学数学与计算机科学学院 福州 350116)(2.福建省网络计算与智能信息处理重点实验室 福州 350116)
(3.空间数据挖掘与信息共享教育部重点实验室 福州 350116)(4.国网信通亿力科技有限责任公司 福州 350003)
1 引言
随着信息时代的到来,网络观点调查已经逐步取代了传统纸质问卷调查,不仅包括商品评论领域,还涉及社会公众事件、外交以及国家政策等领域。但是随着互联网便利性的增强,网络上涌现出大量的用户生成内容,除了新闻报道等客观信息外,带有主观色彩的评论数据也占据了很大一部分,且呈现出大数据化的发展趋势[1]。对这些海量的数据进行细粒度的情感分析(又称观点挖掘),不仅有利于发现、分析及控制舆论,还可以帮助生产者改进产品、服务质量,以及帮助消费者做出购买决策[2]。
对评论文本进行细粒度情感分析,即挖掘出文本中的评价对象(又称方面)、观点词及观点持有者。如在笔记本电脑评论“The battery life is long”中,观点持有者即发布这条评论的消费者,用观点词“long”对方面短语“battery life”进行描述。如今,观点挖掘技术被广泛应用于自然语言处理、人工智能等领域。
在细粒度情感分析中,可以将方面抽取问题当成一个序列标注任务,并使用诸如隐马尔可夫(Hidden Markov Model,HMM)、条件随机场(Condi⁃tional Random Fields,CRF)和循环神经网络(Recur⁃rent Neural Network,RNN)等序列标注模型进行训练。在对数据进行处理的时候,可以使用BIO标注体系进行标注[3],其中B代表方面短语的第一个单词,方面短语剩余的部分都用I进行标注,非方面短语的部分用O标注。表1为使用BIO标注体系对上述评论进行标注。

表1 BIO标注体系示例
现有的方面抽取研究大多集中于基于规则或基于传统机器学习模型的方法[4]。基于规则的方法简单易行、执行效率高,但性能严重依赖于专家制定的规则质量和语料中语法的正确性;基于传统机器学习模型的方法,大多采用HMM模型和CRF模型,本质上是将方面抽取看成是一个序列标注任务,获得比基于规则更高的性能,但是该类方法需要大量的特征工程,性能也严重依赖于所选特征的质量。
深度学习模型被应用于自然语言处理的各个领域,如词性标注、句法分析、语义分析、中文分词等。其中,深度学习模型中的RNN本质上是一种序列标注器,其性能在多个领域都被证明优于CRF且具有多种变体,如为了解决文本中的长期依赖而提出的长短期记忆网络(Long Short-Term Memory,LSTM)。
在自然语言处理的深度学习模型中,使用诸如N-Gram、TF-IDF等特征作为模型输入容易造成维度过大导致训练时间过长以及难以对语言规律和模式进行编码。词嵌入是一种分布式文本向量表示方法,它将词汇表中的每个词都表示成一个具有连续真实值的向量,相比于传统的One-Hot向量表示方式,具有高密集、低维度等特性,且能对文本中各个词的语义特征进行编码,常被用作深度学习模型的特征输入。词嵌入只能获得词与词之间的关系,难以获得词的内部特征。字符嵌入类似于词嵌入,它对单词内部的各个字符进行编码,可以获得词内的语义特征,有利于处理方面为低频词以及未登录词的情况。
为了克服基于规则和传统机器学习模型方法的缺点,提出一个基于层次嵌入的方面抽取模型(HierarchicalEmbedding forAspectExtraction,HEAE)。由于预处理对文本这种非结构化数据具有非常重要的影响以及现有研究大多对预处理流程没有一个有效而全面的实现,首先使用包含多种操作的预处理方案对原始数据集进行处理;然后,过滤文本中的低频词,避免模型过度学习无用信息;随后,为了获得单词内部更高层次的语义特征以更好地处理低频词,提出一种与词嵌入相对应的字符嵌入,即将单词中的每个字符都编码成一个固定长度的向量,随后将该单词的字符序列输入到字符层次的双向循环神经网络char-biRNN进行训练;接着将char-biRNN的隐藏层的输出向量与词嵌入向量进行级联,并作为单词层次的双向循环神经网络word-biRNN的输入以训练出完整的模型。实验结果表明,该模型比构造多种复杂特征的CRF模型以及未使用字符嵌入的深度学习模型具有更优的性能。
本文的主要贡献如下:
1)设计多阶段的预处理方案,可为后续研究提供一个可参考和对比的数据处理方案;
2)利用网络模型训练词嵌入和字符嵌入,可用于某些没有预训练嵌入空间的领域;
3)提出包含词嵌入与字符嵌入的层次嵌入模型,有效提高方面抽取的性能。
2 背景知识
2.1 相关工作
方面抽取是细粒度情感分析的一个重要子任务,吸引着来自文本挖掘、自然语言处理等不同领域学者的广泛研究,提出众多的具体算法。目前,方面抽取方法可以分为以下三类[5]。
1)基于规则的方法。
Hu等[6]首次提出在评论文本中抽取方面,采用人工制定的规则识别频繁出现的名词或名词短语以抽取不同的产品特征。随后有很多工作基于挖掘频繁项集合和利用句子内的依赖关系来抽取方面[7~8]。Qiu 等[9]提出一个称为双向传播的技术用于方面抽取,利用句子中词之间的语法依赖关系来同时抽取方面和观点词。Li等[10]等将方面抽取任务当成一个浅层语义分析问题,使用众多的结构化语法信息来提升短语识别的性能。江腾蛟等[11]设计了基于依存句法分析和语义角色标注的抽取规则,有效解决中文金融评论数据中方面构成的复杂性问题。基于规则的方法主要是利用模式识别和自然语言处理技术,通过挖掘语料中潜在的模板来制定规则,并使用语法分析等获得文本的语言特征,无需标注大量数据,简单易用,但是该方法严重依赖于预先定义的规则集合和依赖解析的结果,适用于方面为名词、句子结构简单且语义清晰等情况,难以处理结构复杂的数据。
2)基于传统机器学习模型的方法。
Jin等[12]提出一种词典化的隐马尔可夫模型来提取方面,能够同时识别评论中的方面和观点词。Jakob等[13]提出一个基于CRF的模型,在多个不同领域的评论数据上进行训练,并附加了诸如块、词性标注等语言特征,使得该方法更具领域适应性能力。Toh等[14]在SemEval-2014的方面抽取任务中,提出一种基于CRF的模型,并设计诸如词典、语法、句法等语言特征以及无标注数据中蕴含的聚类特征,获得了该评测任务中餐馆领域的最优结果。许多研究还采用潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)及其变体等主题模型技术来抽取方面[15~17]。基于传统机器学习模型的方法大多将方面抽取当成一种序列标注任务,比基于规则的方法具有更优的性能,但是该类方法为了获得对方面抽取有用的信息,需要大量的特征工程。
3)基于深度学习模型的方法。
近年来,RNN及其变形被成功的应用于各种序列预测任务,如词性标注[18]、语音识别[19]、语言模型[20]。Irsoy等[21]使用 RNNs[22]模型将观点表达式抽取当成一种序列标注任务,利用Google提供的word2vec模型得到文本的向量表示。Yin等[23]提出一种使用依赖路径嵌入的无监督方法来提高词嵌入的质量,随后使用CRF进行训练。Liu等[24]提出结合训话神经网络和词嵌入的方法RNN-WE来抽取方面,并使用了词性标注和语句块信息两种语言特征。基于深度学习模型的方法相比前两种方法,不需要制定任何规则和特征工程,且可以自动学习到文本中的高级特征。
2.2 双向长短期记忆网络
如图1所示,在一个标准的LSTM网络中,信息的输入和遗忘受一个称为记忆块的循环隐藏层单元控制,该隐藏层单元由以下四个部分组成:1)输入门i,用于控制输入到记忆块的信息。2)输出门o,用于控制输出到下一个神经元的信息。3)遗忘门 f,用于控制当前神经元要遗弃的信息。4)记忆细胞c,包含一个自连接操作。
LSTM记忆块中的各个连接权重在t时刻的更新过程如下:

其中,xt为当前时刻的输入,ht-1、mt-1分别为上一时刻隐藏层的输出和记忆细胞的输出,it、ft、mt和ot分别为当前时刻输入门、遗忘门、记忆细胞和输出门的状态,ht为该循环神经网络在t时刻的输出,门函数σ为sigmoid激活函数,τ为双曲正切函数,符号⊙代表两个向量对应元素的乘积。
双向长短期记忆网络的基本思想是对于每一个输入,使用一个前向LSTM和一个反向LSTM进行训练,随后将两者的隐藏层向量级联以作为输出层的输入。这种双向的网络结构不仅为当前时间节点的输出层提供了来自过去的完整信息,还提供了来自未来的有用信息。

3 方面抽取模型
3.1 数据处理
要从非结构化的评论文本语料中抽取出方面,不管是基于规则还是基于传统机器学习模型的方法,或者最近流行的基于深度学习模型的方法,都需要对原始数据集进行预处理,且预处理的质量对模型的最终性能有着重要的影响。RNN-WE的预处理流程包括将所有单词小写化、用“DIGIT”替换数字、用“UNKNOWN”替换只出现过一次的低频词并在构建语境窗口的时候用“PADDING”进行填充;He等[25]对语料进行移除标点符号、去停用词、去阈值小于10的低频词等操作;Wu等[3]以句子为单位进行处理,将所有的数字用“DIGIT”替换、如果一个词同时出现字符和数字则用“TYPE”替换、用“UNKNOWN”替换出现频次少于等于1的单词。
由于现有工作使用的预处理方案各不相同,使得很难在相同的输入下比较核心算法的性能。因此,为了对后续工作提供一个高效、一致的输入,设计了一个包含多个步骤的预处理方案,该方案的执行流程如图2所示。
其中,分词采用自然语言处理开源工具NLTK的正则匹配分词器并自定义匹配规则;特殊符号处理操作即对“,”、“!”、“|”等符号进行处理,采用直接移除和用“PUNCTUATION”替换两种方式;数字处理操作包括用“DIGIT”替换所有数字或者直接移除两种方式;转小写操作为将语料中的所有单词都转成小写,不管是人名、地名还是普通单词;词形还原操作采用了NLTK工具中基于WordNet的词形还原方法;词干提取操作采用NLTK工具上的Snow⁃ball Stemmer词干提取器。
3.2 模型描述
本节介绍基于层次嵌入的方面抽取模型HEAE,即使用词嵌入和字符嵌入来抽取商品评论中的方面。首先,将词汇表Vw中的每个单词都表示成与之相对应且维数固定的特征向量vw∈Rdw,dw表示特征向量的维度大小。随后,将Vw中的每个单词及其对应的特征向量构成一张二维共享单词查找表,其中, ||Vw表示词汇表的大小。由于词嵌入能够捕捉单词间的语义关系并在嵌入空间以距离的方式反映出来,已在自然语言处理的多个领域表现出良好的性能[26],在这里使用预训练词嵌入和随机词嵌入初始化Lw。与词嵌入一样,将语料中出现的每个字符都表示成一个维度固定的向量vc∈Rdc,dc表示字符向量的维度大小,并构造一个与之对应的共享字符查找表表示字符个数,并采用随机字符嵌入初始化的方式。需要注意,Lw和Lc将作为网络的参数进行训练。
在方面抽取模型HEAE中,每个输入样本都是一个句子s=(w1,w2,…,wT),wi为句子中的每个单词,T为单词个数,wi=(ci1, ci2,…,ciK) 为单词wi对应的字符序列,cij为单词wi中的各个字符,K为单词wi包含的字符个数。首先,将该句子转换成一个索引序列S=(W1,W2,…,WT),其中Wi是单词wi在Lw中的索引位置;随后,获得每个单词wi对应的字符索引序列C=(Ci1,Ci2,…,CiK),其中Cij是字符cij在Lc中的索引位置。对于每个单词,将其字符索引序列C在Lc中的字符向量作为char-biRNN的输入,并通过一个非线性的循环隐藏层学习每个单词更高层次的表示;随后,将每一个单词经char-biRNN训练后得到的隐藏层向量与该单词在Lw对应的词向量级联以作为word-biRNN的输入,并经非线性隐藏层单元以获得输出向量,随后使用softmax来获得每个单词所对应的标注类别。
3.3 网络结构
HEAE的网络结构如图3所示。其中,图下半部分虚线框里代表的是字符级别的嵌入模型,上半部分代表的是单词级别的嵌入模型。

图3HEAE结构
在字符嵌入中,每个单词都会被拆成由字符组成的字符序列,如单词“life”会被拆成字符序列;使用一个 char-biRNN 作为字符嵌入的训练模型,该模型的输入为每个单词的字符序列对应的特征向量,即网络每个时刻的输入为当前字符在Lc中对应的字符向量;然后,将char-biRNN的前向隐藏层输出和反向隐藏层输出级联成高层次的向量表示ct。
在单词嵌入中,首先将句子切分成单词序列,如表1所示的例子,将会产生一个单词序列[‘The’,‘battery’,‘life’,‘is’,‘long’],使用预训练词嵌入方式或随机嵌入方式将每个单词都表示成一个n维的向量;使用一个word-biRNN作为序列标注模型,其输入向量为xt=[wt,ct],其中wt代表当前单词在Lw所对应的特征向量,xt为wt与ct级联后的向量。同样地,word-biRNN在输入向量的基础上,通过双向非线性隐藏层,可获得对应的高层次向量表示ht。
在获得ht之后,将其输入到网络输出层以进行分类,得到每个单词所对应的类别标签。在这里,我们使用softmax作为输出层的映射器,它会获得当前单词属于各个类别的概率分布,其计算公式如下:

其中,W∈R|ht|×N为word-biLSTM隐藏层与网络输出层之间的权重矩阵,|ht|为的隐藏层的维度,b为偏差向量,N=3 为所有的类别数,即“B”、“I”、“O”三种。
HEAE模型的训练是为了最小化目标分布和预测分布之间的交叉熵,因此采用负对数似然函数(Negative log likelihood,NLL)作为模型的目标函数即损失函数。通过最小化训练集上的NLL使模型达到最优,每条句子的损失根据如下公式计算:

其中,In是一个指示变量,如果当前单词的真实标签为n时,则In为1,否则为0;S为评论句子所对应的单词序列;θ={ }Xj,Hj,Mj,bj,W,b,Lw,Lc为网络需要训练的权重参数,Xj,Hj和Mj分别代表输入层与隐藏层、两个隐藏层和两个记忆细胞之间的连接权重;bj代表偏差向量;W和b代表word-biRNN与输出层之间的权重矩阵以及偏差向量;Lw和Lc分别代表词嵌入空间和字符嵌入空间。
4 实验与结果分析
4.1 实验配置
1)数据集
实验所采用的语料来自于自然语言处理领域权威评测比赛 SemEval-2014 Task 4[27],包含 Res⁃taurant(餐馆)和Laptop(笔记本电脑)两个领域的商品评论数据集,每个领域的数据又分为训练数据和测试数据,各自的统计数据如表2所示。

表2 语料统计信息
从表中可知,大概三分之二的方面都为单一词,剩余的部分为多个词构成的方面短语;在Res⁃taurant领域的所有数据集当中,不包含任何方面、仅包含一个方面以及包含多个方面的评论分别占31.97%、34.1%和33.92%,在Laptop领域为50.5%、31.13%和18.37%。
2)词嵌入方法
词嵌入是一种分布式向量表示方式,相比于传统的One-Hot表示,词嵌入具有高密集、低维度等特性,且包含了单词在文本中潜在的语义和语法信息。采用如下三种方式初始化Lw。
Google Embeddings Mikolov等[26]提出两个不同的基于大语料的非线性神经网络来训练词嵌入空间。其中,基于词袋的模型称为CBOW,它是通过上下文语境信息来获得当前单词的词向量;另一个为skip-gram模型,与CBOW相反,它是在给定当前单词的语境信息来推断其上下文的词向量。作者开源了一个称为word2vec的数据集,该word2vec是在一个包含1000亿个单词的谷歌新闻语料上,使用CBOW模型训练而来的,其向量维度为300维。
Amazon Embeddings Poria 等[28]使 用 Mikolov等[26]提出的CBOW模型在一个大规模的商品评论数据集上训练得到一个面向商品领域的词嵌入,其向量维度为300维。该数据集为Amazon评论数据集,共包含34686770条评论(约47亿个单词),涉及从1995年6月到2013年3月内的2441053个产品。
Random Initialization除了使用上述数据集来预训练词嵌入空间外,还通过随机的方式初始化任意维度的词嵌入空间,即每个向量中的元素都被赋予(0,1)中的任意数值。
3)评估方法
参照SemEval-2014 Task 4的评估方法,采用查准率(Precision)、查全率(Recall)和F1值三种评估方式,其各自计算公式如下:

其中,TP为真正类(True Positive),FP为假正类(False Positive),FN为假负类(False Negative)。需要注意的是,采用精确匹配的方式进行评估,即只有当一个评价短语完全被识别出来才算识别正确,如在表1中的例子,只有当“battery”被标注为“B”且“life”被标注为“I”时,才算正确识别。
4)网络配置
词嵌入的初始化采用预训练和随机两种方式,预训练方式包括使用Google Embeddings和Ama⁃zon Embeddings将其初始化维度为300维的向量;此外,还使用随机的方式将其初始化成维度分别为[50,100,150,200,250,300]的向量;在预训练方式中,如果某个词不存在于这两个嵌入中,则使用随机初始化方式。对于字符嵌入,采用随机初始化的方式,其维度为100。词嵌入和字符嵌入都将作为HEAE模型参数的一部分进行训练,以使嵌入空间更加适应于当前领域。
DyNet[29]是一种基于动态计算图的框架,它会为每一个训练样例动态地定义一个计算图,并且会自动初始化和训练循环神经网络中诸如隐藏层与隐藏层、输入层与隐藏层以及记忆单元之间的各种参数。HEAE使用的各种序列标注模型都是基于DyNet框架的。
以下所有实验结果的性能指标都为F1,单位为百分比。使用SemEval-2014 Task4提供的验证集进行参数选择,使用得到的模型重复运行5次并取平均值作为最后的性能。在预处理实验中,只采用词嵌入和word-biRNN层次的网络结构,其中词嵌入采用随机初始化为300维向量的方式;在方面抽取实验中,在Restaurant领域和Laptop领域分别采取维度为100的随机初始化方式。此外,我们将学习率固定设置为0.01,char-biRNN和word-biRNN的隐藏层维度大小都为150,训练方式采用随机梯度下降法SGD,迭代次数为30轮。
4.2 结果与分析
1)数据处理
在各种预处理步骤中,由于特殊符号、数字的处理对后续的词干提取、词性还原等步骤没有影响,因此先进行特殊符号和数字的处理,随后依次进行转小写、词形还原、停用词处理以及词干提取。预处理方案包含的各个步骤对网络性能的影响如表3所示,性能度量指标为F1值。
从表3可以看出,如果不对文本这种非结构化数据进行预处理就对其进行挖掘,将严重影响模型的整体性能。
特殊符号处理采用替换为“PUNCTUATION”和直接移除两种方式。由于这些特殊符号不会为方面抽取提供任何的语义信息,采用替换方式会让每条评论引入过多的无效信息,使得模型过度解读这些无效信息,导致性能下降。因此,采用直接移除所有特殊符号的方式,即表3中的rem_pun。
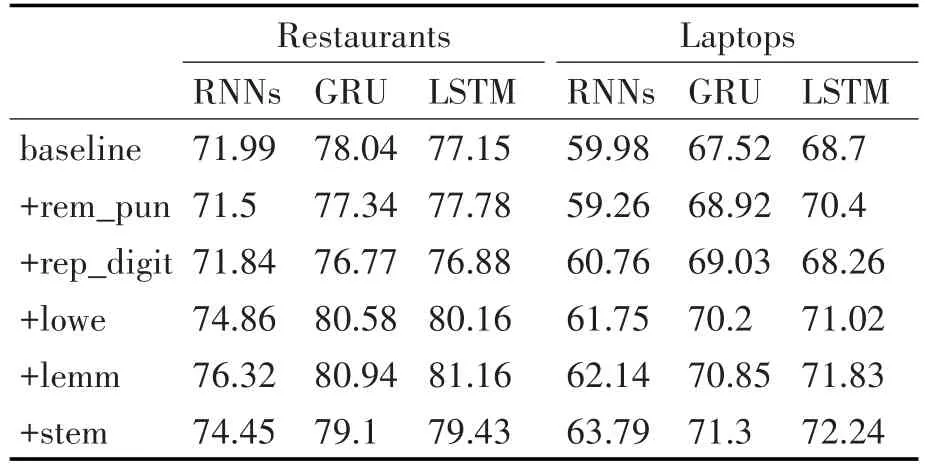
表3 预处理结果
数字处理采用移除和用“DIGIT”替换两种方式。由于数字通常会用来修饰方面,能为方面抽取提供上下文信息,且不管一个数字是多少,它提供的信息都是类似的。因此采用“DIGIT”替代的方法,即表3中的rep_digit。
转小写操作就是将语料中包括人名、地名以及机构名等所有单词都转换成小写形式,该操作可以使得语料中的单词在形式上更为统一,避免大小写造成的信息分散问题,使得模型在训练的时候对相同信息学习出不同的结果。基于以上观察,对语料中的所有数据都进行转小写操作,即表3中的low⁃er。
词形还原操作就是将一个词的各种形式还原到最基本的形式,如将过去时态的“drove”还原到“drive”,其作用与转小写操作类似,可以避免在一个模型中,同一种事物有多种形式的表达造成的信息分散问题。词形还原操作为表3中的lemm。
词干提取操作在Restaurant领域上的性能低于Laptop,这可能是因为餐馆领域涉及的方面个数较少,进行词干提取会降低模型学习的信息量,相比之下,Laptop领域中的方面比较不集中,且存在较多一个词有多种表达的现象,词干提取可以将同一个事物的多种表达转换成一个统一的形式,使得模型能够更加精准地学习相应的信息。表3中的stem为词干提取操作。
该预处理方案还进行简单词过滤和去停用词操作,但是两种操作都导致模型性能降低,后续实验将不采用这两种操作。通过将经本预处理方案处理后的数据用在RNN-WE模型上,可以验证本预处理方案的有效性,其在性能度量指标F1上的对比结果见表4。

表4 预处理对比
从表4中可以看出,在两个领域、五种模型的十个结果当中,有九个结果优于RNN-WE所使用的预处理方案。
2)低频词过滤
在Restaurant领域和Laptop领域上的低频词阈值对比实验结果如图4所示。
从图4可以看出,在Restaurant领域,低频词过滤对性能的提升有较大的作用,且随着阈值的增加,性能维持在相对稳定的水平,在三种循环神经网络中,GRU和LSTM在阈值为1的时候取得最好的结果,RNNs对阈值的变化较为敏感,波动范围大。这主要是因为在该领域中,涉及到的方面较少且其在语料中的出现频次较高,低频词过滤并不会去掉潜在的方面,相应的还可以移除一些无用的低频词。在Laptop领域中,低频词过滤对性能的提升效果较小甚至导致效果变差,随着阈值的增加效果逐步下降,对LSTM的影响最为明显。使得该领域获得跟Restaurant领域不一致结果是因为该评论数据集中,涉及到的方面比Restaurant领域多,导致每个方面的出现频次较低,使得低频词过滤容易移除一些潜在的方面。综合两个领域在各个阈值上的结果,后续实验都采用阈值为1的低频词过滤方案。

图4 低频词阈值
3)随机嵌入维度
除了采用预训练初始化词嵌入外,还采用了随机初始化为不同维度的方式,其结果如图5所示。
从图5中可得,随着维度的增加,两个领域上三个不同的模型都表现出上下波动的现象,但总体还是趋于平稳。在Restaurant领域,RNNs、GRU和LSTM分别在250维、100维以及100维时取得最佳性能,在Laptop领域,对应地在200维、150维以及100维时取得最好结果。虽说采用随机初始化的方式在大部分情况下没有预训练方式好,但是相
比于传统机器学习方法各种复杂的特征工程,将随机初始化的词嵌入作为神经网络参数的一部分进行训练,也能获得同样好的性能。
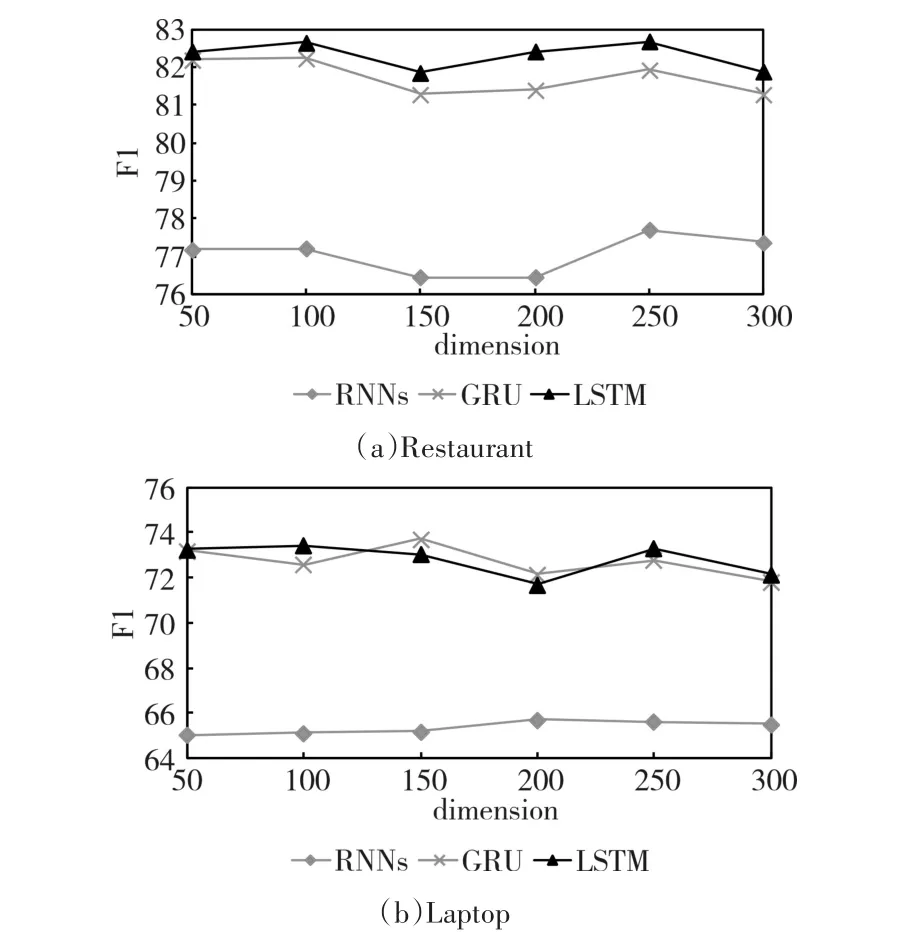
图5 随机嵌入维度
4)方面抽取
本节将HEAE与多个模型在两个数据集上进行比较,其在性能度量指标F1上的结果如表5所示。

表5 方面抽取性能
在HEAE中,词嵌入采用Amazon Embeddigns和Google Embeddings两种预训练方式以及随机初始化方式,采用DyNet提供的多种循环神经网络,包括RNNs、GRU、LSTM和CVLSTM四种。HEAE模型在网络结构为CVLSTM以及采用Google Em⁃beddings预训练方式时取得最优性能,在Restaurant和Laptop分别为84.16%和76.8%。
在两个领域数据集上,无论使用何种序列标注模型,Google Embeddings在多数情况下获得比Am⁃azon Embedding和随机方式更优的性能,在十二组对比实验中占了十组;紧接着就是随机初始化方式,在八组对比实验中优于Amazon Embeddings。一般情况下,在特定领域数据集上训练而来的嵌入空间,相比于应用于其他不同领域,会更加适合用于相关领域,如在亚马逊商品评论数据集上训练而来的Amazon Embeddings应该比Google Embeddings在Restaurant和Laptop领域上有更优的性能,但HEAE使用的三种嵌入方式中,亚马逊嵌入却取得最差的效果,这主要是由于Poria等[28]在创建该嵌入时,所采用的预处理方式与HEAE不同,使得经预处理后的众多词不存在于该嵌入空间当中。
SemEval-2014 Task4在Restaurant领域和Lap⁃top领域上最好的系统分别为DLIREC[14]和IHS_RD[30]。HEAE无论是在哪个领域的评论语料都具有更好的性能,在Restaurant数据集上获得0.18%的提升,在Laptop领域上获得3%的提升。需要注意的是,DLIREC和IHS_RD都构建了复杂的特征工程,包括单词的情感倾向、命名实体、依赖关系以及词聚类等特征,而HEAE模型只用到词嵌入和字符嵌入两种特征以及神经网络学习高层次特征的能力。
与该数据集上的其他模型相比,HEAE同样具有较优的性能。如与基于规则的模型BS[31]相比,HEAE在两个数据集上都获得较大的性能提升。RNN-WE模型在Restaurant数据集上最优的模型为biElman+Feat,而HEAE未使用任何附加的语言特征也使得性能提升了2.6%;RNN-WE模型在Laptop领域的最优模型为LSTM+Feat,HEAE获得了2.5%的性能提升。与基于规则和深度学习的Hier-Joint模型[32]相比,HEAE模型在Restaurants领域获得了8%的性能提升,但在Laptops领域性能有所下降,主要是因为Hier-Joint模型使用基于规则的方法来获得辅助标签,使用于数据量少、涉及方面多的领域如Laptops领域。
HEAE分为预处理、低频词过滤、字符嵌入等步骤,各个步骤对模型的总体性能在F1指标上的影响如表6所示。

表6 HEAE各步骤性能
该实验使用到的词嵌入是以随机初始化方式获得的,其维度为300维。除了Restaurant数据集上的LSTM外,其余性能都随着步骤的增加而提升,充分证明了本模型涉及到的各个步骤对模型性能的显著提升。在Restaurants领域,char-LSTM比char-biLSTM获得更佳的性能主要是因为该领域的涉及的方面较为集中,单向网络就可以很好地捕获特征;相反,Laptops领域涉及的方面众多,平均出现次数较少,双向网络更有利于捕获特征。
5 结语
本文提出一种基于层次嵌入的方面抽取模型HEAE。HEAE模型主要基于词嵌入、字符嵌入以及各种神经网络序列标注器,与其他模型相比,既不需要专家制定特定领域的语言模板,也不需要构造复杂的特征工程。HEAE使用一个包含多阶段的预处理方案,并引入字符层次的嵌入和循环神经网络以获得字符间的语义关系,可以进一步获得词的高层次表征,有利于处理出现次数较少的方面。实验结果表明,HEAE模型可以有效提高模型自动化,并获得较优的结果。
在未来的工作当中,考虑在以下几个方面展开进一步的研究:提出更全面、高效的预处理方案;以特定的预处理方案构建特定领域的嵌入空间;使用诸如词性、句法分析等语言特征。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康体检与管理(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
建材发展导向(2021年23期)2021-03-08
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
高中生学习·高三版(2016年9期)2016-05-14
