
基于PSO-FWSVM的糖尿病预测模型∗
2020-07-13 12:47朱玉全
计算机与数字工程 2020年5期
缪 琦 朱玉全
(江苏大学计算机与通信工程学院 镇江 212013)
1 引言
糖尿病治疗时间长,没有立竿见影的治疗方法,并且随着病情的加重,有着严重的并发症。糖尿病前期的及时发现对于控制糖尿病的发展有极其重要的意义。中国糖尿病最新数据显示:糖尿病前期发现率仅有35.7%,其中70%的人群是以餐后血糖为主。而目前常规体检仅测空腹血糖,这会造成大量的糖尿病漏诊。若在体检中加入餐后血糖则会带来人力物力时间上的巨大消耗,因此可以建立一个有效的数学模型协助医生对糖尿病前期进行有效的判断,从而提高糖尿病前期的诊断率。
目前糖尿病数据挖掘常采用的分析方法有神经网络[1],决策树[2]和支持向量机[3~4]等。相对于其他的方法,支持向量机的优点是显而易见的[5],它以VC理论和结构风险最小化准则为理论基础,找到当前有限样本下的最优解,模型的泛化性较好;少量支持向量决策出结果,模型的鲁棒性较好等。但是支持向量机在糖尿病预测的准确率上稍逊色,并且训练时间相对较慢。本实验针对这两个问题对SVM糖尿病预测模型进行改进,提出新的PSO-FWSVM糖尿病预测模型。
传统的SVM算法假设所有的特征对预测结果的重要性是相同的,但应用在具体的数据集时,样本的不同特征与目标函数的相关性往往是不同的。通过特征加权可以筛选出对于糖尿病分类更相关的特征,增强这部分特征对结果的作用,并除去部分冗余的特征,在一定程度上可以提高SVM模型的准确率和分类速度。
因为惩罚因子和核函数参数是影响准确率的重要因素,寻找到合适的参数对建立SVM模型非常重要。目前有很多的优化算法,比如交叉检验算法、遗传算法、网格搜索算法和粒子算法等。其中网格搜索算法是目前普遍使用的方法,即在参数列表中进行穷举搜索,这种方法在范围足够大和取值足够多的情况下可以找到全局最优解,但是这样会浪费时间。而粒子群算法是一种发展很快的全局优化算法,无需遍历范围内的所有参数组,寻优策论简单,收敛速度快,能较快获取合适的σ σ和C;局限性是容易出现局部收敛现象,自适应改进惯性权重的PSO[6]可以缓解这一问题。
2 支持向量机SVM
2.1SVM原理
SVM是一种二类分类模型,其基本模型定义为特征空间上间隔最大的线性分类器,其学习策略便是间隔最大化,求解办法就是将其转化为一个凸二次规划问题[7]。
对于线性可分的样本,找到一个超平面f(x)=wTx+b使得样本可分,该平面离数据点的几何间隔越大,则分类的可靠性都越高。则参数要满足以下的约束条件。

式(1)本身就是一个凸二次规划问题,使用拉格朗日乘子法可将其转化成“对偶问题”,可以更高效地解决这一问题。对式(1)的每条约束添加乘子αi≥0得到函数如下所示。

要想得到式(2)的解,则是先求(w,b)的极小,再求αi的极大得到式(1)的对偶问题:
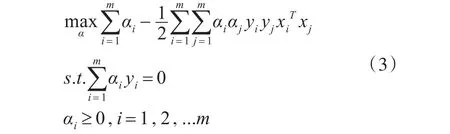
对于非线性样本,样本空间是有限维的,则一定存在高维空间使得样本线性可分。用ϕ(x)表示x映射后的特征向量,经过式(2)、(3)得到的公式如下。
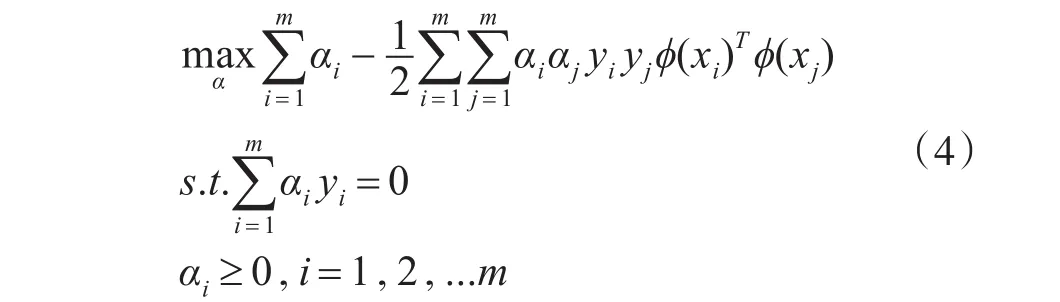

其中:C是惩罚系数。
2.2 特征加权核函数
本文选取RBF函数建立SVM模型,它能够实现非线性映射,通常可以取得很好的效果且模型参数少、复杂度低。SVM模型运用到实际情况时,数据集中各个特征与分类结果的相关性是不同的,导致不同的特征对预测结果会产生不一样的影响。为了解决这个问题,本文对RBF核函数进行特征加权处理,即依据重要性对各个特征赋予不同的权重,并将其运用到核函数的计算中,从而使核函数的计算可以偏向强相关的特征[9~10]。
若Kp-RBF表示RBF核函数,X为其特征向量矩阵,P是n阶的权重矩阵,n是输入矩阵空间的维度,则加权RBF核函数的公式为

权重矩阵P取n阶的对角矩阵,表达式为

特征的重要性度量值,也表示在特征加权矩阵中第i个特征值的权重。通过对不同特征赋予不同的权重,从而使具有更小权重的特征在分类中起到更小的作用。
由此可见wi的求取很重要,本文在随机森林(RF)的模型中衡量各个变量的预测可以力,即求各个变量的信息值(VI)作为wi;以gini不纯度作为最优条件的选择依据,量化每个特征对于分类的贡献。假设RF中共有n棵树,第i棵树中,节点m的gini指数K表示m节点中有K个类别,pmk表示节点m中类别k所占的比例;节点m分枝前后的gini指数变化量∆G=GIm-GIl-GIr,后两项分别表示m节点分枝后新节点的gini指数;特征 Xj在节点m的重要性表示节点的样本数量nj占总样本数量N的比重;特征Xj在决策树中出现的节点在集合特征M 中,那么Xj在第i棵树的重要性对n棵树中特征Xj的VI值求和并归一化,则最终特征 Xj的重要性
2.3 参数优化
该模型的性能很大程度上取决于核参数σ和惩罚因子C。参数σ越小,核函数对x的衰减越快,对x x的变化敏感,SVM的分离面更细致,则推广能力降低;参数σ越大,核函数对x的衰减变慢,对x的变化迟钝,SVM的分离面更平滑,则推广能力提高。惩罚系数C的取值影响置信范围区间的确定,C取值小表示对经验误差的惩罚小,学习机器的复杂度小而经验误差值较大;C取无穷大,则会造成过拟合,这就表示训练样本全部被正确分类。每个特征子空间可以找到一个或多个合适的值使得SVM泛化能力达到最佳状态[11],本文将使用改进后的自适应PSO算法对SVM模型进行参数寻优。
3 粒子群算法(PSO)
3.1 标准的粒子群算法(PSO)
粒子群优化算法是一种自动的寻优技术,它的基本思想是:通过个体的行为和种群信息的共享得到最优解。因为它容易实现并且参数相对简单,可以被运用在函数优化、模糊系统控制等各个领域。
在PSO算法中,每个可能的解被抽象成没有质量和体积的粒子,经过无数次迭代得到的最佳位置就是模型合适的参数解[12]。这些粒子的初始速度和位置是随机的,假设当前为第t代,在N维搜索空间中的粒子可以表示如下所示。
粒子位置:

粒子速度:

粒子群运行到t代,通过比较每个粒子的历史最佳适应度,可以得到粒子个体本身的最优解,通过比较所有粒子的最佳适应度,可以得到的群体最优解,其公式如下所示。
个体最优:

种群最优:
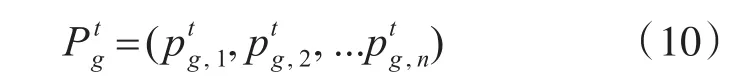
在t+1代,根据这两个极值,重新更新粒子的速度和位置,其公式如下所示。
粒子新速度:


3.2 改进的PSO算法
PSO参数的常见选择是:取c1=c2=1,自身经验和群体信息的作用相同。r1和r2为(0,1)中的随机数。w取线性递减权值0.4,随着迭代次数的增多,w值逐渐减小,这在一定程度上缓解了局部缺陷。因为一开始更好的全局索搜能力可以帮助粒子快速来到最优解的附近,而之后则需要较强的局部搜索能力确定这个最优解。但是w仅与迭代次数有关,在解决该问题上还存在不足[14]。
影响PSO算法性能的主要因素是参数c1,c2,w以及粒子领域的拓扑结构,本次实验选择调整PSO的主要参数w来平衡全局搜索性能和收敛速度,避免“早熟”现象。根据处理数据过程中表现的数据特征来调节w,充分发挥自适应调节的能力,可以使得不同状态的粒子拥有不同的权重,避免陷入局部最优[15]。在本文的公式中,选择的数据特征是适应度,即预测模型的交叉验证准确率。根据个体验证准确率的大小,将粒子群分成两个子集,分别采用不同的权重公式,使得群体的惯性权重层次更加丰富。
具体实现的思路是:假设粒子群的个数为n,在k次迭代中粒子Pi的验证准确率为 fi,最优粒子的验证准确率 fmax;粒子群的平均验证准确率为 fˉ,高于 fˉ的那部分准确率再求平均值得到-f',则剩余准确率低于 fˉ的部分再求平均值得到-f''。惯性权重的公式如下所示。
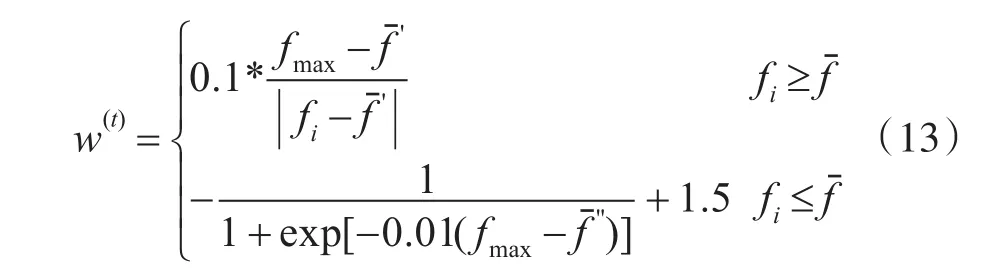
以上式子保证了较优粒子有较小的w,会加快全局收敛的速度;较差粒子的w范围在[0.5,1],使其在迭代后期避免陷入局部收敛。
3.3 自适应PSO-FWSVM模型
糖尿病数据集包含多个特征,每个特征对预测结果的影响不同,并且无关的特征不仅会增加模型的建立时间,还会降低分类的准确率,所以采用随机森林算法对数据集进行特征选取。
核参数σ和惩罚因子C对糖尿病模型的预测结果有很大的影响,因此本文利用粒子种群对FWSVM模型进行参数寻优,将识别的交叉验证准确率当作PSO的适应度函数,在进化过程中根据适应度自适应地调整参数,找到最佳解[16]。PSO-FWSVM模型流程如图1所示。

图1PSO-FWSVM模型流程图
实验具体步骤如下。
1)利用随机森林算法对实验数据进行初步筛选,通过设定阈值,删除对分类结果贡献比较小的特征,得到新的特征集。用新的特征集建立新的随机森林,调整树的深度和个数进行多次实验,其中分类精度最高的一次计算出的特征重要度即一一对应特征权重矩阵中的数值,已删除的特征对应的权重数值为0。
2)设置核函数的初始参数,如核参数变化范围,惩罚参数的变化范围,随机设置一组值。
3)设置粒子群的初始参数,比如种群规模,位置和速度等,以FWSVM模型算法所求得的交叉验证准确率作为粒子的适应度函数。
4)采用PSO算法更新单个粒子的速度和位置,产生新的粒子并计算其适应度值。
5)判断当前粒子的个体极值是否为种群的最优解,若是则将当前的个体极值替换为全局最优解,若不是,则返回步骤4)。
6)重复步骤4)、5),直至达到最大迭代次数。历史迭代中,单个粒子的个体极值是全局最优解且满足 C值最小时,其对应的参数组即为最佳解。
7)将得到的最佳解用于FWSVM模型训练,并对糖尿病测试集进行预测。
4 实验及结果分析
4.1 实验数据
原始数据由某医院提供,经筛选后共有936个观测值。糖尿病患者和非糖尿病患者人数比为1:3.5,每个样本包含13个特征如血糖指数、舒张压、BMI等,由于这些特征的量纲不同,会影响到数据分析的结果,需对样本的每个特征维度分别进行归一化处理。经过试验对比,将数据归一化至[-1,1]区间时,效果最好,处理后的数据即为实验数据。从实验数据中随机抽取70%作为训练集,30%作为测试集。
4.2 实验评价指标
仅依靠准确率来判断模型的好坏是不全面的,必须加上更加复杂和全局性的标准。为了比较模型的好坏,采用了三个常用评价指标—敏感性、特异性、约登指数,它们的表达式如下。

4.3 实验结果
通过随机森林算法筛选出建立预测模型使用的8个特征以及其对应的重要性度量值如图2所示。
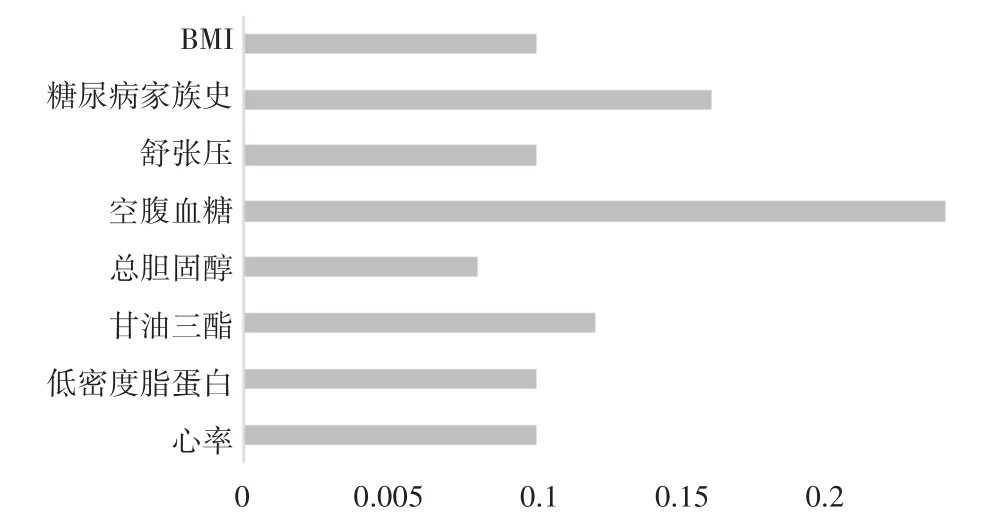
图2 特征重要性排序
将训练集数据输入FWSVM模型中,利用自适应PSO算法找到最优参数组(C,σ),初始种群为20,进化代数为100,c1=c2=1。为了避免模型不可靠,寻优过程中引入3折交叉验证法,得到的平均准确率作为适应度,寻优结果如图3所示。
图3中,x轴代表进化代数,y轴代表适应度值即训练集的识别准确率。从图可知,自适应PSO算法仅需数次迭代就可以达到最佳适应度为90.77%,此时得到核参数σ和惩罚因子C分别为4.2194和1.0714。运用找到的最优FWSVM模型对验证集进行预测。
为了验证本方法的有效性,同时采用网络搜索-SVM、决策树和BP神经网络对实验数据进行训练和预测,四个模型的详细比较见表1。
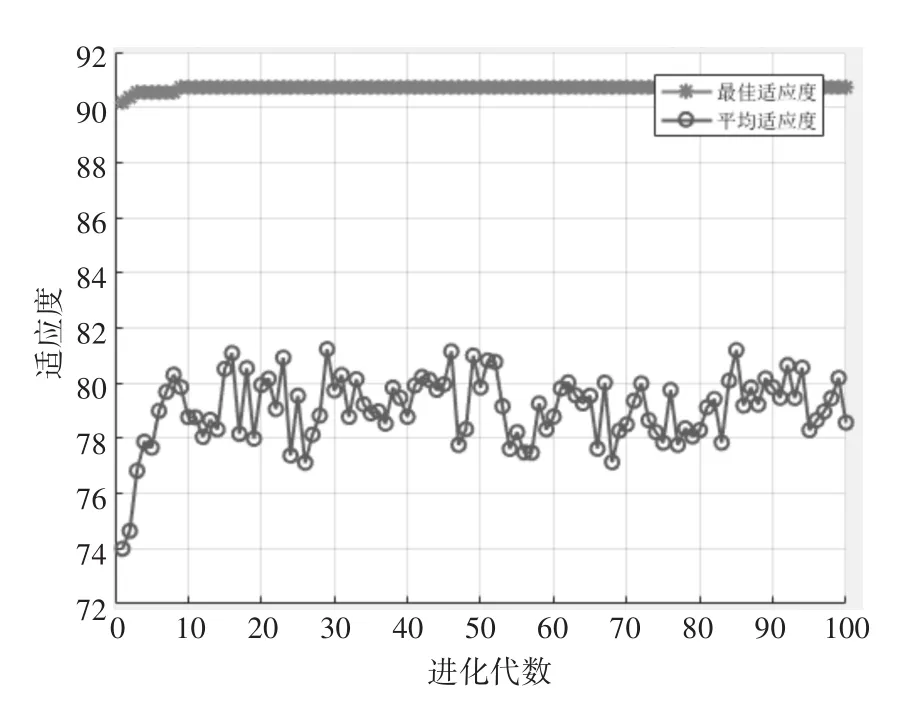
图3 自适应PSO寻优结果
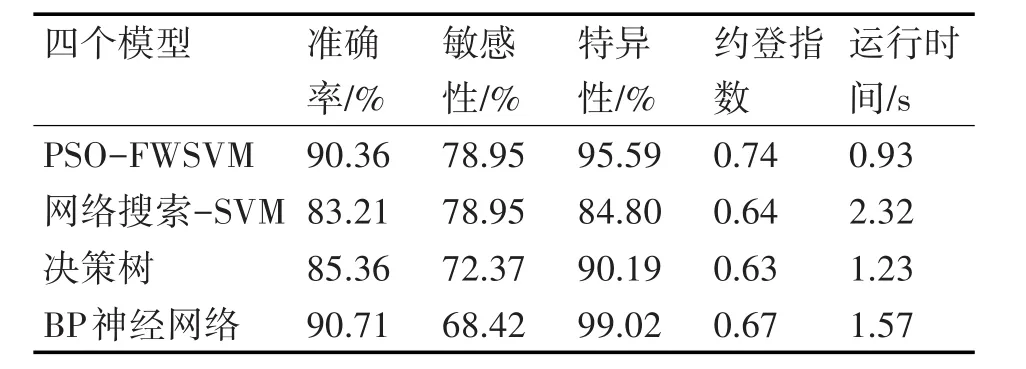
表1 四个模型的准确度、敏感性、特异性、约登指数、运行时间比较
从表1中可以看出,PSO-FWSVM模型对糖尿病数据的分类准确率略低于BP神经网络模型为90.36%,且运行时间最短为0.93s;从三个评价指标上来看,PSO-FWSVM模型是可靠程度最高的,对糖尿病病人的正确识别达到78.95%,对非糖尿病患者的正确排除达到95.59%,模型预测结果的真实性较高。综合来看,PSO-FWSVM模型的性能优于其他的模型,具有一定的适用性,可用于糖尿病的预测。
5 结语
PSO-FWSVM可以用于建立糖尿病预测模型。通过特征加权,筛选出对分类效果影响较大的参数,从而使得分类结果更加准确,并且由于删除了不必要的特征,在一定程度上提高的模型运行速度;通过自适应PSO优化算法寻找SVM模型的最优参数,提高模型的正确识别率并缩短训练模型的时间。
从最终结果可以看出,非糖尿病患者比糖尿病患者更容易被正确识别出来。这可能是由于考虑各个特征对识别结果的重要程度时,没有考虑样本数量的不平衡和从多个维度去衡量各个特征的影响力。在之后的研究中,收集更丰富的糖尿病样本集,科学改进筛选特征的方法,并通过加入新的模型性能判断指标,更加全面地验证该模型的分类效果,使得PSO-FWSVM糖尿病预测模型具有更快的运行速度和更准的分类效果。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
昆明医科大学学报(2022年1期)2022-02-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
分析化学(2018年12期)2018-01-22
当代旅游(2016年10期)2017-04-17
飞碟探索(2015年8期)2015-10-15
财经理论与实践(2015年2期)2015-04-16
