
基于机器学习的出行目的推算方法比较
2020-06-29 11:20
交通与港航 2020年3期
同济大学建筑设计研究院(集团)有限公司
0 引 言
近年来,随着智能交通系统的不断建设和发展,各类设备提供了多种多样的被动的交通数据(如智能公交卡数据、手机数据、车载GPS数据等)。这些数据为进一步的交通规划与分析提供了丰富、准确的数据基础,然而这些数据也存在固有缺陷,由于设计初衷为监控或管理,其不包含有出行目的,而出行目的为交通出行行为中的重要属性,对进一步的交通规划分析尤为重要。因此,国内外学者在出行目的推测方面展开了深入研究,尝试采用不同的方法来推测出行目的。
从研究方法上看,该领域的研究主要分为两个阶段。第一个阶段为基于简单规则的判断[1-5],主要利用时间属性进行初步筛选,再根据空间属性和个人信息特征对出行目的进行判断。该类方法在不同的数据源和逻辑规则结构下,推算的准确率差异较大,整体准确性不高,大约在70%左右。第二个阶段主要采用机器学习类的方法[6-13]。该类方法类型较广,不同的方法间运行效率和准确性差异较大,但推算的准确性整体较高,大约在75%~95%之间;相较基于规则类的方法,机器学习方法对多维度数据的处理能力较强,模型的适应性较强。该类方法主要包含有支持向量机、贝叶斯网络、决策树、随机森林、神经网络等。
尽管在该领域国内外的研究方法较为丰富,但对出行目的的研究大多数是不同的学者在不同的数据源和不同的模型条件下的单一方法的准确性分析或少量方法的对比分析,尚未对该领域几类表现较好的方法应用较广泛的方法进行相同条件下的横向比较。
因此,本文通过总结国内外在该领域的研究方法,总结出表现较好,较为广泛应用的五类方法——决策树、随机森林、支持向量机、神经网络、贝叶斯网络;在此基础上,根据德阳和资阳的居民出行调查数据,在相同数据源条件下,对这几类方法的推算准确性进行比较(见表1)。

表1 国内外研究方法概况
1 研究数据处理
1.1 数据说明
为探索各类机器学习方法在出行目的推算上的准确性与普遍性规律,排除单一数据源的偶然性,本文以德阳和资阳两个城市的居民出行调查数据为基础,同时考虑到出行目的推算的后期应用以智能公交卡数据为主,因此在研究中提取居民出行调查数据中的公交出行数据,并根据智能卡所能获取的数据属性类型进行两种条件的设置(见表2),即完整变量条件的模型和不含有个人属性特征下的模型[14]。
德阳出行调查数据包含3 217个家庭共计21 287次出记录(见表3);资阳居民出行调查数据包含3 347个家庭共计25 096次出记录(见表4)。对于每一位出行者,其包含有出行目的在内的18种属性特征[15]。
1.2 数据清洗
根据国内外研究经验及Spearman检验可知:出行次序、停留时间与出行目的具有相关性(见表5)。由于在基础数据中不含有这两个属性,因此在本文中主要补充两个字段:出行的停留时间、出行次序。
停留时间lt(lasting time)是指该出行者在目的地的停留时间,其为同一出行者下一次的出发时间sti+1(i=1,2,3……n)和上一次的到达时间ati(i=1,2,3……n)之差;对于一天内最后一次出行的停留时间的计算,假设该出行者第二日与第一日相同,当日第一次出行的出发时间st1与当日最后一次出行的到达时间atn(i=1,2,3……n)的之差,既停留时间lt=24-atn+st1。
出行次序则是依时间排序的同一出行者当日的第1次出行到第N次出行的时间顺序。
据此规则,进行数据补充和清洗。
最终得到德阳共有2 296次公交出行,资阳为2 424次公交出行。

表2 模型设置条件

表3 德阳居民出行调查数据样例一

表4 德阳居民出行调查数据样例二

表5 属性变量相关性分析
2 出行目的推测模型构建及分析
本文主要采用五类机器学习方法进行目的推测,分别分析在不同的数据源和不同的输入变量条件下模型的准确性及整体的稳定性。
2.1 模型评价参数
一个性能良好的机器学习模型可以从海量训练数据集中提取出那些最有实际意义和价值的信息,并进行处理,生成能够清晰的描述分类问题的规则集。分类准确率(召回率)用于描述机器学习模型应用于测试数据集或未知数据集时的分类能力高低,其公式为Recall=TP/(TP+FN)。本文以推测的出行目的准确性为目标,因此采用准确率(召回率)作为主要指标,当准确率相同时以精确率(Precision=TP/(TP+FP))作为同条件下的次要指标,最终根据测试数据的准确率和精确率以评价模型优劣(见表6)。

表6 机器学习性能指标
2.2 模型构建及准确性分析
2.2.1 决策树(CHAID)
决策树模型是基于熵或Gini指标判断不同的类别间的最佳区分节点得到的树模型结构(见图1)。在模型设置过程中,由于出行目的为分类变量,因此利用卡方自动检验算法来自动搜索变量产生最大差异的方案,以构建最佳决策点的分枝过程。在该模型中设置50%为训练数据,50%为验证数据,最大树深度为3层,并设置95%的置信水平防止其过拟合。在模型的训练及验证过程中,通过大量试验,保证其训练集和测试集的准确性差异较小(一般小于5%),以得到模型的准确性的最终结果。由此得到的准确性分类结果如表7所示。
由模型的准确性可知,在条件一和条件二下,同城市的模型准确性变化较小(小于5%),即模型在不同的输入条件下推测能力较为稳定,准确性约为83%左右。
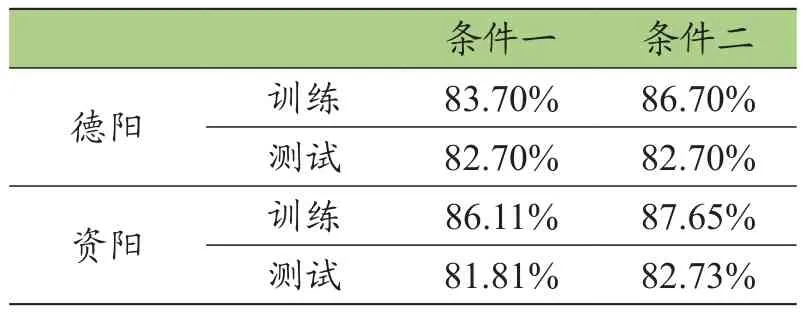
表7 决策树模型准确性分析
2.2.2 随机森林(RF)
随机森林是建立在CART决策树基础上的组合算法模型,其通过自助法重采样技术,不断生成训练样本和测试样本,由训练样本生成多个分类树组成随机森林,测试数据的分类结果按照分类树投票多少形成的分数而定,由此得到最终的分类结果(见表8 )。
由模型的准确性可知(见表9),在条件一和条件二下,德阳模型的准确性在条件一时最佳约为93%,在条件二时准确性相比决策树也较高,约为87%。资阳的模型准确性较稳定,约为86%,优于决策树模型。
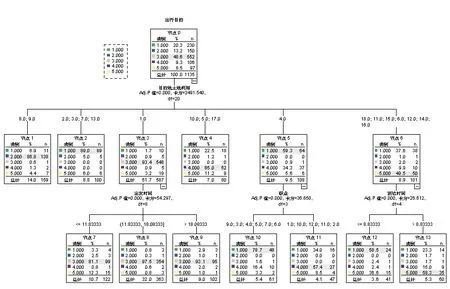
图1 决策树模型结构(德阳条件一样例)

表8 随机森林决策规则(德阳条件一样例)
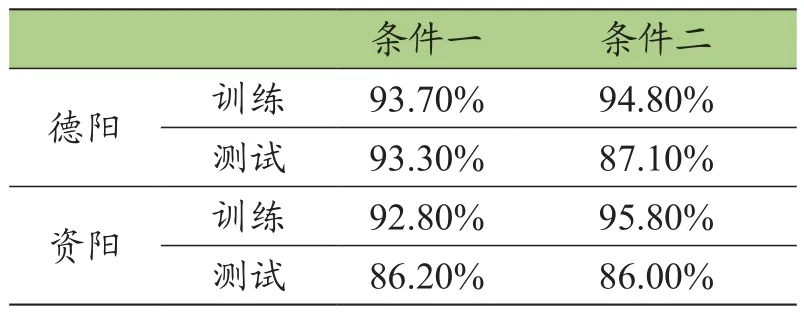
表9 随机森林模型准确性分析
2.2.3 神经网络(MLP)
MLP神经网络是基于BP算法的多层感知器模型。
在两种条件下,由模型的准确性分析可知其预测数据的准确性变化幅度较小(小于2%),模型整体较为稳定,准确率大约在82%左右(见图2、图3、表10)。

图2 德阳5种目的准确性(条件一样例)
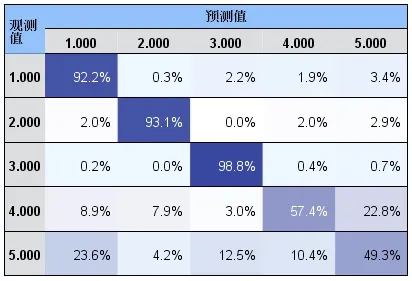
图3 资阳5种目的准确性(条件一样例)
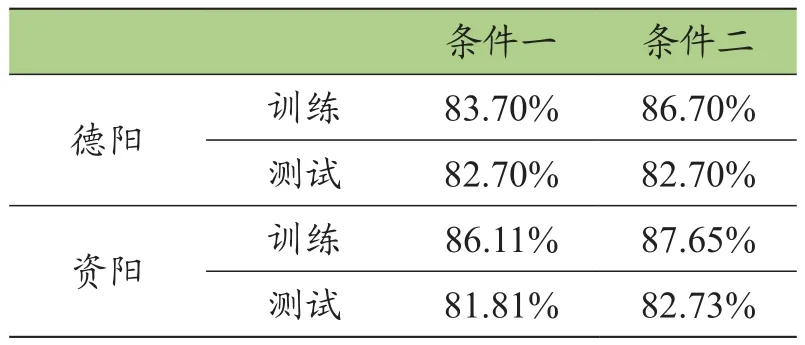
表10 MLP神经网络模型准确性分析
2.2.4 支持向量机(SVM)
支持向量机根据最优分类面将样本进行分类,当其不能在超平面进行线性划分时,则通过核函数将其映射到多维空间再进行划分。
在训练模型时,为防止模型过度拟合,需充分调整训练数据和测试数据的随机种子,使训练数据和测试数据准确性差异小于5%,以避免其过拟合,当其达到较为稳定的状态时以此状态下的最高准确性作为模型分类的结果。
由此,得到最终的模型准确性如表11所示:

表11 支持向量机准确性分析
由分析结果可知,该模型在两种条件下准确性普遍较高,大约在90%~93%,相较其他方法训练较为充分,模型整体较为稳定,准确率高。
对于城市的规划和建设来说,居住区是一个重要的组成部分,他是城市居民生活的地方,是人们基本生存生理需要的地方。在住宅小区园林景观设计的过程中,主要是生态绿化、生活品质等方面的综合应用,除此之外,在推动住宅小区生态景观设计的基础上,如何创造符合各个年龄段居民需求的运动、活动空间,提高居住环境的舒适度与幸福感都是需要景观设计过程中关注的问题。通过规划设计来增强居民的归属感和舒适度,并在和谐的环境中相互交流,增强邻里之间的沟通。
2.2.5 贝叶斯网络(BAYESIAN)
贝叶斯分类方法是一种展现已知数据集属性分布的方法,其最终计算结果完全依赖于训练样本中类别和特征的分布(见图4)。
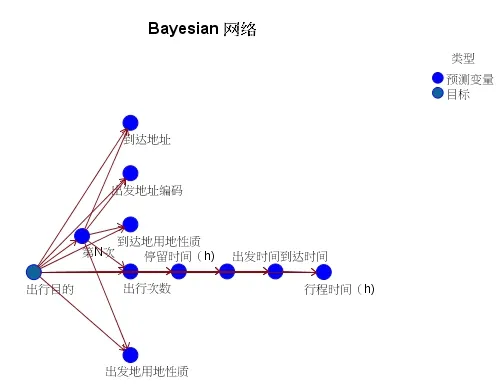
图4 贝叶斯网络准确性分析
由分析结果可知,对于德阳的出行目的推算结果准确性相对较低,大约在57%~67%,对于资阳的模型则是训练数据和测试数据相差较大,模型不稳定且推测的准确性相对其他模型较低,约为73%~75%(见表12)。
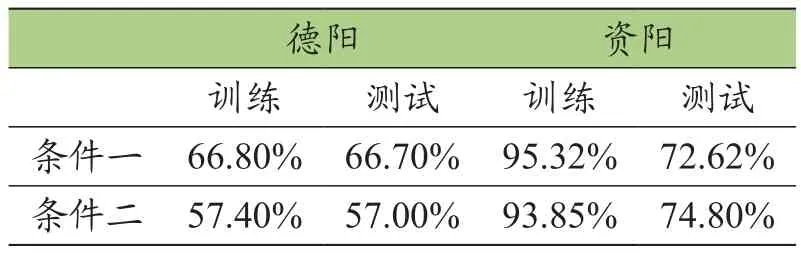
表12 贝叶斯网络准确性分析
3 模型准确性比较及总结
对比不同条件下相同城市的各类机器学习方法推测的准确性,以此判断是否存在较为稳定的模型对于出行目的推测类问题具有良好的适应性。
由图5可知,RF和SVM准确性在90%以上,CHAID在85%作用,MLP模型准确性略低于CHAID模型,总体的推测准确性为RF>SVM>CHAID>MLP;BAYESIAN准确性相对这四类较低。
由图6可知,SVM推测准确性在90%以上,RF和CHAID大于85%,总体的推测准确性为SVM>RF> CHAID;MLP准确率略低于CHAID;BAYESIAN准确性相对这四类较低,差异较大。
由图7可知,S V M推测准确性在90%以上,RF、CHAID和MLP大于80%,总体的推测准确性为SVM>RF>CHAID>MLP;BAYESIAN准确性相对这四类较低。
由图8可知,SVM推测准确性在90%左右,RF、MLP和CHAID大于80%,总体的推测准确性为SVM>RF>MLP>CHAID;BAYESIAN准确性相对这四类较低。
根据模型的准确性分析可知,在五种模型四种条件下,模型的分类结果整体呈现出较为稳定的排序,既SVM>RF>CHAID>MLP>BAYESIAN,在这五类方法中,模型的准确性平均高于80%,而BAYESIAN模型准确性波动较大、不稳定,且模型准确性不高。CHAID和MLP模型准确性较为相近,但CHAID整体准确性略高于MLP。
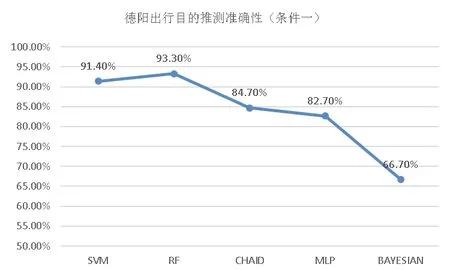
图5 德阳模型间对比分析(条件一)

图6 德阳模型间对比分析(条件二)

图7 资阳模型间对比分析(条件一)

图8 资阳模型间对比分析(条件二)
由此分析可知,在出行目的推断中SVM对模型推断有较为良好的准确性,为推测中的最优模型。
4 研究结论
本文在分别探索了两种数据源,两类模型设置条件下五种机器学习方法模型的准确性,由图5~图8可知,在四种情况下,SVM、RF模型的准确性较高且较为稳定,普遍呈现出SVM>RF>CHAID的趋势,即这三类方法对于出行目的推测这个领域表现较好,适应性较强。
在不同的条件下,同数据源模型的准确性普遍变化较小,这也说明了个人属性特征对于出行目的的推测影响较小,由此可知在变量较少的条件下出行目的推测模型也具有稳健性,故该类模型对采用被动数据进行出行目的挖掘具有可实施性和应用前景。
猜你喜欢
电子制作(2018年16期)2018-09-26
江西社会科学(2018年8期)2018-08-29
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
小说界(2016年3期)2016-06-06
智能系统学报(2015年4期)2015-12-27
中国房地产业(2015年9期)2015-11-17
浙江大学学报(工学版)(2015年2期)2015-05-30
郑州大学学报(医学版)(2015年1期)2015-02-27
