
基于双流卷积神经网络和生成式对抗网络的行人重识别算法*
2020-06-22 10:29林通,陈新,唐晓,贺玲,李浩
网络安全与数据管理 2020年6期
林 通,陈 新,唐 晓,贺 玲,李 浩
(中国人民解放军空军预警学院,湖北 武汉430019)
0 引言
行人重识别(ReID)的目的是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。 由于其在安全和监控方面的重要应用,受到了学术界和工业界的广泛关注。这一任务极具挑战性,因为不同相机拍摄的图像往往包含由背景、视角、人体姿势等变化引起的显著变化。
在过去的几十年中,大多数现有的研究都集中在度量学习和特征学习上,设计尽可能抵消类内变化的算法已经成为了行人重识别的主要目标之一。起初,行人重识别的研究主要是基于全局特征,即基于全局图像获得特征向量。 为获得更好的效果,开始引入局部特征, 常用的局部特征提取方法包括图像分割、骨架关键点定位和姿态校正。 行人重识别任务还面临一个非常大的问题,即很难获得数据。 到目前为止,最大的数据集只有几千个目标和上万张图片。随着生成性对抗网络(GAN)技术的发展,越来越多的学者试图利用这种方法来扩展数据集。 然而,大多数现有的针对行人重识别的算法需要大量标记数据, 这限制了它在实际应用场景中的鲁棒性和可用性,因为手动标记一个大型数据集是昂贵和困难的。最近的一些文献在使用无监督学习来解决此问题,改进人工标注的特征。 由于不同数据集之间的图像有明显差异,在提取图片特征问题上效果仍不理想。本文方法的贡献主要有两个方面。 一方面,采用均衡采样策略和姿势迁移方法对数据集进行扩充有效地缓解了行人姿势各异造成的干扰。 另一方面,利用两种不同的网络结构从图像的不同方面提取特征,使模型能学习到更为丰富全面的信息。 实验结果表明,该方法具有较高的精度。 例如,在Market-1501 数据集上,这一模型Rank-1 准确度达到了96.0%,mAP达到了90.1%,与现有算法相比,性能有较大提升。
1 相关理论方法
1.1 局部特征
行人重识别的研究最开始主要是基于全局特征,即基于全局图像获得特征方向。 为了得到更好的性能,研究人员逐步研究局部特征。 常用的局部特征提取方法包括图像分割、骨架关键点定位和姿态校正。 图像分割是一种非常常用的提取局部特征的方法。 将图片垂直分成几个部分[1-2]。 然后,将分割后的图像块按顺序送入神经网络。 最后一个特征融合了所有图像块的局部特征。 然而,这种方法的缺点是对图像对齐的要求相对较高。 如果两幅图像没有对齐,很可能会造成头部和上身的对比,从而导致模型判断错误。 为了解决图像错位问题,一些文献首先利用先验知识对行人进行对齐。 这些先验知识主要是经过训练的人体姿势(骨架)模型和骨架关键点(骨架)模型。 例如,文献[3]首先利用姿态估计模型对行人的关键点进行估计,然后利用仿射变换对相同的关键点进行对齐。
1.2 基于生成式对抗网络的数据扩充
行人重识别任务面临一个非常严重的问题,那就是很难获得数据。 到目前为止,最大的行人重识别数据集只有几千个行人和上万张图片。 随着生成式对抗网络(GAN)技术的发展,越来越多的学者试图利用这种方法来扩展数据集。
文献[4]是第一篇以基于生成式对抗网络技术解决行人重识别的论文,发表在ICCV17 会议上。 虽然论文比较简单,但却引出了一系列的佳作。 行人重识别的一个问题是不同的相机提供的照片存在差异。这种差异可能来自各种因素,如光线和角度。为了解决这个问题,文献[5]使用生成式对抗网络将图像从一个相机风格迁移到另一个相机。 除了相机的差异外,行人重识别面临的另一个问题是不同数据集中存在差异。 这很大程度上是由图片拍摄环境造成的。 为了克服这种环境变化的影响,文献[6]使用GAN 将行人从一个数据集的拍摄环境迁移到另一个数据集拍摄环境。 行人重识别还要解决的困难之一是行人姿势的不同。 为了应对这一问题,文献[7]用生成式对抗网络制作了一系列标准的姿态图,共提取了8 个姿态,基本涵盖了各个角度。对每个行人生成一组标准的8 个姿势图片,以解决不同的姿势问题。
2 基于卷积神经网络和生成式对抗网络的行人重识别模型
在这部分,提出了一种新的模型来解决ReID 问题,如图1 所示。该模型包含两个部分:基于生成式对抗网络的模型和一个集成CNN 模型。 该模型先将已有的数据集进行扩充,再利用扩充的数据集训练集成模型完成行人重识别任务。
2.1 基于姿势迁移的数据集扩充模型
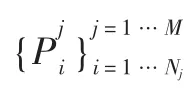
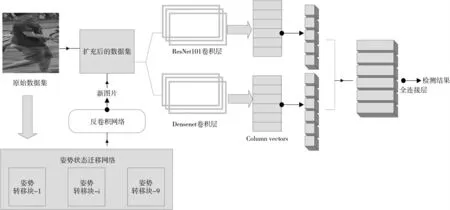
图1 模型结构
姿势图片Pc,关键点向量Sc经过2 层降采样卷积层;Pt也经过两层降采样卷积层,而后输入到姿势-注意转移网络中。 姿势-注意转移网络是由几个特别设计的姿势-状态转移块构成的,每个转移块只传输它所关注的某些区域, 逐步生成人物图像,允许每个传输块在训练上时行局部传递,因此避免了捕获全局的复杂结构。 所有姿势转移块均具有相同的结构,它有两条相互独立的支路构成:图像支路和姿势支路,分别算出生成图片的图像编码和姿势编码。 最后将姿势-注意转移网络的输出——图像编码和姿势编码输入到解码器,通过3 个反卷积网络从图像编码生成图像Pg,如图2 所示。
鉴别器也分为两部分:外观鉴别器和姿势鉴别器。 外观鉴别器用来判断Pg和原图Pt是否为同一个人,姿势鉴别器则判断Pg的姿势是否与Pc相同,两个鉴别器结构相似。 先将Pg分别与Pt、Pc在深度轴上结合,而后分别送入外观鉴别器和姿势鉴别器,得到输出外观相似度RA和姿势相似度RS。 最终的评分R=RARS。
2.2 行人重识别模型
为了解决行人重识别任务中用于识别的图片人物位置远近不一的问题,提出的行人重识别模型采用多层次的卷积核来提取图片特征,将这些特征拼接,而后进行分类,如图3 所示。
特征提取部分采用两个算法分别提取特征,将图片分别输入到ResNet[9]、Densenet[10]之中,分别提取卷积层输出,得到特征向量L1、 L2将之连接,作为特征向量L。
在全连接层,借鉴PCB 模型的思路,采用6 个全连接层和6 个分类器。 这里采用交叉熵损失函数。 在训练阶段,每个分类器用于预测给定图像的分类(人的身份)。 测试阶段,给出两张图片Ii和Ij(i和j 图片在数据集中的标签)。
图2 GAN 模型结构

图3 CNN 模型结构
使用特征提取模型提取特征并获得两个特征向量, 分别为Li和Lj。 根据余弦距离计算相似度。

3 实验与分析
所有实验是在Pytorch1.0.1、Python3.6 环境下实现的,硬件设备是2 块Titan RTX,显存24 GB,E5-2680 v3 24 核处理器。
3.1 数据集
当前的ReID 数据集已大大推动了有关的研究。 充足的训练数据使得有可能开发更深的模型并展现出较强的识别能力。 尽管目前的算法已在这些数据集上实现了很高的精度,但距离在实际场景中得到了广泛应用还很遥远。 因此,有必要分析现有数据集的局限性。
与实际场景中收集的数据相比,当前数据集在四个方面存在局限性:(1)任务种类和摄像机的数量不够大,尤其是与真实监控视频数据相比时。目前,最大的数据集DukeMTMC-reID 也只有8 个摄像头,不到2 000 个人物身份。 (2)现有的大多数数据集仅包括单个场景,即室内或室外场景。 (3)现有的大多数数据集都是由短时监控视频构建的,没有明显的光照变化。 这些局限性使得采用一些方法扩充或增强数据集很有必要。
这里采用DukeMTMC-reID 数据集,它是Duke-MTMC 数据集的子集,用于基于图像的行人重识别。有1 404 个行人出现在两个及以上的摄像头中,408个行人只出现在1 个摄像头。 选择702 人作为训练集,其余702 人被用作测试集。 在测试集中,为每个摄像机中的每个行人选取一张查询图像,并将其余图像放入图库中。 这样,就可以得到702 个人的16 522 张 训 练 图 像, 其 他702 人 的2 228 张 查 询 图像和17 661 张图库图像。 每张图像都包含其相机ID 和时间戳。
3.2 模型训练
由于行人重识别数据集由不同人的图像组成,每个人都有不同数量的图像样本。 通常情况下,每批次练训练数据是从全部训练集中随机选取的,这样就会使输入的训练数据对于每个ID 不平等,拥有更多图像样本的ID 训练的次数就越多,图像样本越少的ID 训练得越少。 这样训练出来的模型会对拥有更多图像样本的ID 提供更多的信息,但是每个人都应具有同样的重要性,应该受到平等的对待, 因此引入了均衡采样策略。对于样本少的ID,利用GAN 模型加以扩充。
在训练姿势迁移网络时,采用Adam 优化器,迭代120 轮,β1=0.5,β1=0.999,初始学习率为2×10-4,采用指数衰减。 在每一层卷积层和归一化层后使用Leaky ReLU 做激活函数,负斜率系数设置为0.2。 将生成图片与原数据集合并,得到一个10 万张图片的训练集。
在CNN 部分,先进行图像预处理将图像尺寸调整为384×192×3,然后以0.5 的概率对图像水平翻转,改变图像的亮度对比度为1.7 和饱和度1.5,并使用随机擦除,用均值[0.485,0.456,0.406]和标准差[0.229,0.224,0.225]分别对每个通道的数据进行正则化。
Resnet 采用Pytorch 预训练的模型resnet101,Densenet 采用Pytorch 预训练的模型densenet121,均使用训练好的参数。 将两个模型卷积层的输出设置为1×1 024,将两个输出连接得到1×2 048 的向量作为图片特征向量。
用Softmax 进行分类,在训练阶段,6 个分类器独立预测给定图像的类别(人的身份),从而获得更高的准确性。 将Dropout rate 设置为0.3,使用SGD 优化器,并将momentum 设置为0.9,权重衰减因子设置为5×10-4,训练时初始学习率设置为0.1,每训练40 个epoch 衰减为原来的0.1,一共训练120 轮。
3.3 实验结果与分析
该算法分别在Market-1501 和DukeMTMC-ReID上进行了测试。 与现有的算法相比,取得了更好的效果。
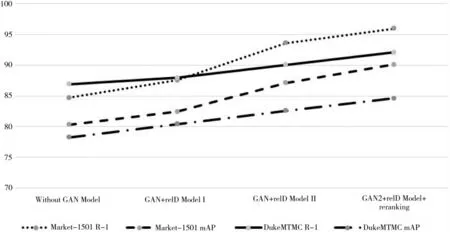
图4 采用不同的识别策略的性能
从图4 可以看出,在没有使用GAN 扩充数据集前,单纯的ReID Model 在DukeMTMC-reID 数据集数据集上测试时,Rank-1 为86.90%, mAP 为78.25%。在使用了GAN 模型,随机对一些行人的图片进行扩 充(GAN+reID Model Ⅰ)后,Rank-1 和mAP(mean average precision)分别提高到了87.95%、80.41%,但是效果提升并不明显。 而针对性地挑选出图像相对较少的行人进行GAN 增强, 并采用了一系列数据增强措施, 在ReID Model 部分采用resnet101 代替resnet50(GAN+reID Model Ⅱ)后,可以看到模型的效果 有 明 显 提 升。 最 后, 使 用 re-ranking 方 法,在Market-1501 数据集上Rank-1 的提升到96.00%,mAP 提升到90.10%,在DukeMTMC-reID 数据集上Rank-1 提升到92.10%,mAP 提升到84.60%。
将这一模型与最近的方法[11-15]进行比较,在Market-1501 数据集上就行测试。 这些方法主要是基于表示学习、局部特征和GAN 映射的行人重识别方法。 详情见表1。 在每个数据集上,这种方法都有很好的性能,并且与以前的方法相比性能有所提高。
4 结论
本文提出的基于姿势迁移和CNN 的模型应用在行人重识别中,通过两个方面提高模型性能。 首先,使用均衡采样策略和姿态转移方法来扩展数据集,从而解决了数据量少和不平衡的问题。 这使得能够训练更复杂的神经网络并提取更多特征。 其次,该方法使用两种不同的卷积网络结构提取图像特征,使所获得的信息更加全面,从而进一步提高了准确性。 尽管该方法有效,但仍有待改进。 更好的策略是考虑使用不同尺寸的卷积核以提取不同级别的特征。 在未来的工作中将继续研究更有效的模型。
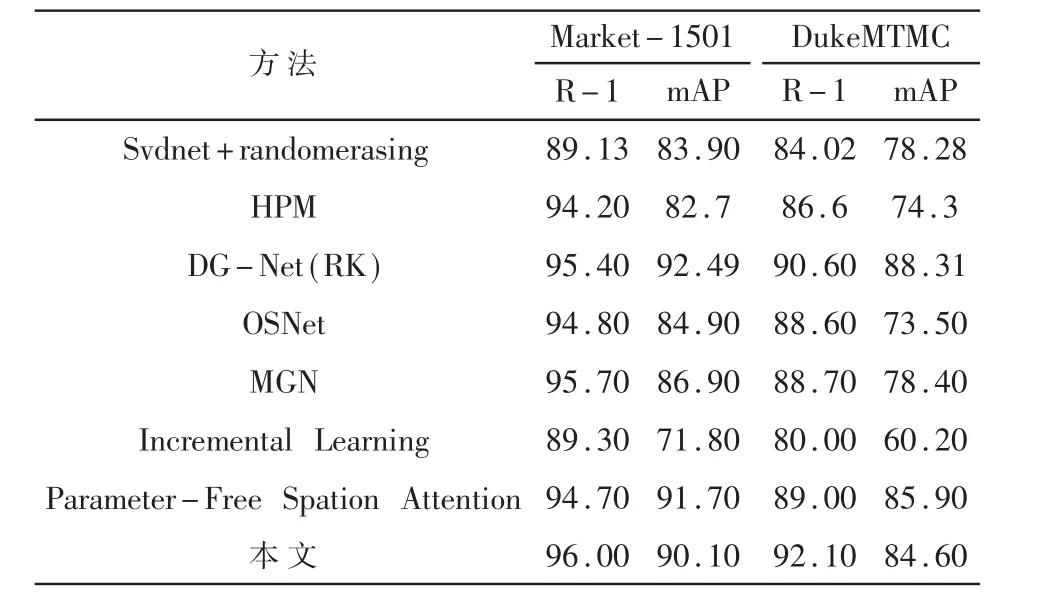
表1 模型性能比较
猜你喜欢
北京工业大学学报(2022年9期)2022-09-15
计算机系统应用(2022年7期)2022-08-04
西北工业大学学报(2022年2期)2022-05-11
意林(2021年5期)2021-04-18
现代计算机(2020年18期)2020-08-07
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
扬子江(2019年1期)2019-03-08
学校教育研究(2017年30期)2017-08-13
小天使·一年级语数英综合(2017年6期)2017-06-07
