
基于频域注意力时空卷积网络的步态识别方法
2020-06-22 10:29:50SamahManssor
网络安全与数据管理 2020年6期
赵 国 顺 ,方 建 安 ,瞿 斌 杰 ,Samah A.F.Manssor,孙 韶 媛
(1.东华大学 信息科学与技术学院,上海201620;2.数字化纺织服装技术教育部工程研究中心,上海201620)
0 引言
步态特征,通俗来说就是人行走时的姿态外观,具体包括手臂、大腿、小腿等身体轮廓的变化,由于步态的采集不需要与被识别者有物理上的接触,也不需要近距离的接触,因此应用场景比较完善。 医学研究表明,每一个人的步态都有自己的形态,具有唯一性[1],使用步态识别具有一定的安全性,不会导致信息的错误。 将步态识别技术应用于当今智能监控领域,可以在多场景下对人员进行监控,防止意外情况发生,也有利于锁定犯罪嫌疑人,节省人力物力。
目前,关于步态识别的方法主要有两种。 一种是基于步态模板的方法,主要是通过构建步态特征,比如关节点的位置变化、重心的起伏周期等几何数字特征,将一个人的行走视频序列压缩成一个模板,然后通过匹配待预测行人的步态与模板的相似度进行识别[2-4]。 另一种方法是通过深度学习直接抽取原始图像序列的步态信息,通过深度神经网络学习高维时空信息来匹配行人的步态,这种方法不需要大量精细的特征构建,是一种端到端的识别方法[5-7]。
虽然基于步态模板的方法取得了一定的准确率,但是这种特征构造方法复杂,而且受角度、环境、穿着变化影响较大,同时这种特征缺失了时空信息的抽取,在精度上具有一定的限制性。 深度学习方法是一种端到端的学习方法,鲁棒性强,易于操作,但是由于模型参数巨大,如何保证准确性与实时性成了关键。
本文基于深度学习的方法,改良了三维卷积网络(C3D)的网络结构,提出频域注意力卷积操作,主要通过划分频域空间,引进频域卷积。 同时另一个创新主要是注意力机制的引入,这使得网络更加关注不同步态之间的不同,调整步态分布的重要性,提升网络学习效果。 经由中科大数据集CASIA dataset B 检测,本文方法在跨视角实验和方法对比实验中具有提升。
1 结合注意力机制的频域卷积
针对图像的高低频域所对应信息特点,引入频域卷积的思想,同时根据注意力机制的思想,针对不同信息给予不同注意力。 通过频域卷积思想,可以进一步减少冗余信息的干扰,同时注意力的加入有利于增强模型的学习能力,达到精简结构、提升网络能力的效果。
1.1 频域卷积
卷积神经网络(CNN)生成的特征图的空间维度上存在大量冗余,其中每个位置独立存储自己的特征描述符,而忽略了可以一起存储和处理的相邻位置之间的公共信息。 自然图像可以分解为描述平滑变化的结构的低频分量和描述快速变化的精细细节的高频分量[8-9]。同样,如果卷积层的输出特征图也可以分解为不同空间频率的特征,高频和低频特征如何映射到不同频率特征的组这一信息将会被CNN 学习到,通过在相邻位置之间共享信息以减少空间冗余,可以安全地降低低频组的空间分辨率。
为此,本文引入频域卷积(OctConv),流程如图1所示。 频域卷积将输入和输出分为高频、低频两个部分,在进行卷积操作的时候分别进行交互,输出的特征图同样分为高频与低频两个部分,尺寸与输入相同。 具体公式如下:
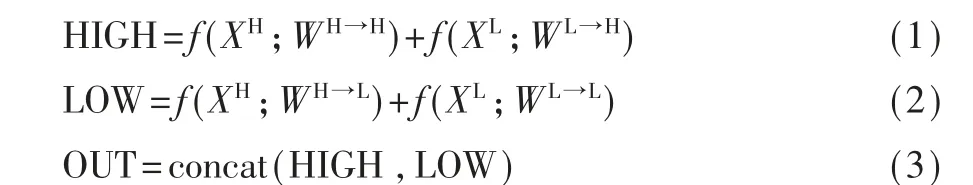
1.2 注意力机制
注意力已经被广泛用作序列建模的计算模块,因为它具有捕获长距离交互的能力,针对视觉任务已经提出了多种注意力机制, 以解决卷积的弱点。例如,Gather-Excite[10]和Squeeze-and-Excitation[11]使用从整个特征图抽取信号重新赋值特征通道,而BAM[12]和CBAM[13]在通道和空间维度上独立地定义卷积特征。 在非局部神经网络中[14],通过在卷积架构中使用一些采用自注意力的非局部残差块,使视频分类和目标检测得到了改进。 但是,非局部模块仅在ImageNet 预训练之后才添加到网络结构中,并以不破坏预训练的方式进行初始化。

图1 频域卷积示意图
给定尺寸为(H,W,Fin)的输入张量,将其展平为矩阵X∈RHW×Fin, 按照Transformer 体系结构中的多头注意力结构[15],单头h 的自我注意机制的输出可以表示为:

然后将所有头部的输出连接并再次拼接,如下所示:
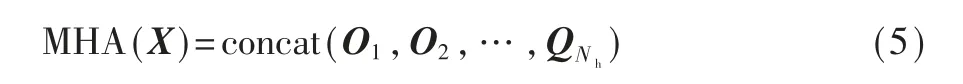
其中Wo∈Rdv×dv是学习的线性变换。 然后将MHA(X)重塑为(H,W,dv)形状的张量以匹配原始空间尺寸。 多头注意力会导致O((HW)2dk)的复杂性和O((HW)Nh2)的存储成本提高,因为它需要存储每个头的注意力图。
1.3 频域注意力融合卷积模块
注意力是一种对于图像局部信息重要性的一种度量,在图像特征中对于高频和低频应该有着不同的注意力,同时对于不同时间的步态应该也有着不同的注意力。 在引入注意力机制后,有利于学习步态的时间和空间信息,而且有利于进一步减少冗余信息的学习。 因此,本文在频率卷积的基础上结合注意力机制提出频率注意力卷积模块。
改进的频率注意力模块结构如图2 所示,输入HIGH:H ×W ×αC,LOW:0.5H ×0.5W ×(1 -α)C, 由Oct-Conv 卷积生成Q、K、V 频率特征图,其尺寸分别为:



图2 频域注意力卷积流程示意图及模块结构

其中,head-h 表示每个头部的高频特征输出尺寸,head-l 表示每个头部的低频特征输出尺寸。 经过试验发现,多头注意力相比较单注意力机制具有更好的表现能力,故采用Nh=2 的多头注意力机制,将两个频率注意力头部进行拼接操作,得到多头频率注意力特征图MFHA(Multiple Frequency Head Attention)尺寸为:

为了提高精度,防止由于注意力机制忽略对于某些位置信息的学习,将原始输入经过Oct-Conv 得到频率特征图:

其中,Oct-Conv-High 表示频率卷积高频输出特征图尺寸,Fout表示频率卷积输出通道数,Oct-Conv-Low 表示频率卷积低频输出特征图尺寸。 将其与MFHA 进行拼接,得到结合频率信息与注意力信息的特征图,输出尺寸为:

其中,HIGH 表示Atten-Oct-CNN 高频输出尺寸,LOW 表示Atten-Oct-CNN 低频输出尺寸。
2 改进的C3D 步态识别网络

图3 改进的C3D 步态识别网络结构图
给定3DCNN 块的局部时空特征, 可以认为3DCNN 模块关注了值得注意的时空的显著空间信息区域。 另一方面,由于频域注意力卷积会将特征图划分为高频和低频两个部分,故当首次输入到频域注意力卷积First-3D 模块中时,内部会将低频通道进行池化以缩小特征图尺寸。 当输入Media-3D 中时,将进行正常频域卷积操作,而输入Last-3D 中会将低频部分上采样进行尺寸恢复。 本文使用C3D网络作为主体,引入硬线层[16]划分输入,使用三个3DCNN 层, 同时将里面的三维3DCNN 更换为本文改进的卷积模块,全连接改为FC-512、FC-124,具体网络结构如图3 所示。
3 实验
3.1 实验环境配置
本文实验使用Pytorch 框架,实验的软硬件环境如表1 所示。

表1 实验环境
3.2 实验过程
实验使用中科院自动化所公开的大型步态数据库CASIA dataset B。 该数据库包含124 个行人,每个行人有11 个视角,分别从0°~180°每18°产生一个步态序列,每个视角下有三种步态状态,分别为正常状态(Normal)、穿大衣状态(Coat)以及背包状态(Bag)。
实验都是在同种状态下进行对比,Normal 状态下有6 个序列01~06,其中01~04 序列用来训练模型,05~06 用来测试网络模型;Bag 状态有两个序列01~02,01 序列作为训练集,02 序列作为测试样本;Coat 状 态 有 两 个 序 列01 ~02,01 序 列 作 为 训 练 样本,02 序列作为测试样本。
3.3 相同状态下的实验结果与分析
实验采用了GenI、GPPE、STIPS 与Deep CNN 作为对比方法,在Normal、Bag 与Coat 三种状态下,这几种方法Normal 状态识别准确率最高均为90%以上。而初始准确率最低的穿大衣状态起初只有50%多的准确率,随着方法的创新,Deep CNN 已经达到89%的准确率。 最后在本文方法下,正常状态下准确率提高了0.3%,背包状态下提升了4.7%,穿大衣状态下提高了3.7%。实验结果对比如表2 所示。

表2 不同状态下各方法实验结果对比 (%)
3.4 相同状态下各视角实验结果与分析
进一步地,检查每个角度下单独的准确率可以发现,Normal 状态比较均衡,在126°时有略微下降,在18°~108°之间本文方法具有显著提升,这表明注意力比原先对于这两个角度有了较多关注。 同时Bag状态提升较为明显,在28°、54°、90°与144°分布与Deep CNN 分布不同,注意力重新划分。 Coat 状态下的分布规律较为一致,同时在频域卷积的强大学习力下准确率有很大的提升。各视角准确率曲线如图4 所示。
4 结论
由于传统基于步态模板的识别方法对于图像的预处理较多,大多使用步态能量图(GEI)模板,而GEI 对于时间维度上步态的先后顺序没有要求,缺失了时间维度上的重要信息,本文通过硬线层将输入划分为5 组图像序列进行输入, 结合三维卷积的时空信息抽取能力, 实现了一种端到端的学习方法。 同时针对普通网络参数量大、 步态特征的重要性分布不均提出一种频域注意力卷积的操作方法, 通过合理分配网络学习的注意力分布,同时划分频域特征,大大减小了冗余信息。 通过在CASIA dataset B 的数据集进行实验, 发现本文方法在相同状态下的识别准确率具有显著提升, 同时对于每种状态的不同角度也有一定的准确率提升。
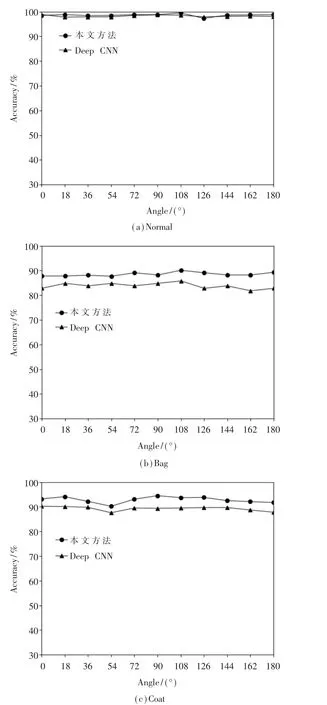
图4 各视角准确率曲线
猜你喜欢
科学大众(2024年5期)2024-03-06 09:40:34
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
电子制作(2018年18期)2018-11-14 01:48:04
自动化学报(2018年6期)2018-07-23 02:55:42
雷达学报(2018年3期)2018-07-18 02:41:34
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
火控雷达技术(2016年1期)2016-02-06 02:17:55
无线电通信技术(2015年3期)2015-12-23 11:37:02
电测与仪表(2015年3期)2015-04-09 11:37:24
