
基于方面情感的层次化双注意力网络*
2020-06-22 10:29陈战伟
网络安全与数据管理 2020年6期
宋 婷 ,陈战伟
(1.太原科技大学 计算机科学与技术学院,山西 太原030024;2.中国移动通信集团山西有限公司,山西 太原030001)
0 引言
情感分析是自然语言处理任务之一,文本中针对某实体给出总体评价的同时,对于实体的不同属性也会分别给出各自观点,由此文本的方面级情感分析是情感分析的重要任务之一,实现对文本观点更深层次的情感挖掘。如何利用自然语言处理现有技术从社交网络大量信息中获取文本的情感倾向,是方面情感分析的主要研究工作。
方面级情感分析首先对方面词进行提取,方面词可以是一个单词,或者是一个短语;接着针对提取出的不同方面分别获取情感信息。 例如:“Good food but dreadful service at that restaurant”,句中的评论实体是餐厅,分别对它的两个方面即两种属性描述观点,两种属性分别是food 和service,相对应的情感极性分别是积极和消极。 由此得出两个方面情感极性可能相同,也可能相反。
深度学习在自然语言处理领域被广泛应用,深度神经网络模型早期在机器翻译、文本情感分类等任务中取得了比以往更好的效果。 注意力机制的结合使神经网络模型高度关注特定目标的特征信息,当前使用较多的结合注意力机制的神经网络模型有卷积神经网络(CNN)和循环神经网络(RNN)[1-2]。文献[3]提出基于多注意力机制的CNN,计算词向量、词性、位置信息的注意力机制,结合卷积神经网络,在不依赖外部知识的情况下获取方面级情感极性。 文献[4]提出首先利用长短期记忆网络(LSTM)获取句子的上下文信息,再使用卷积神经网络提取注意力获得具体的句子表示,模型中嵌入了方面信息,取得较好的分类效果。 基于注意力机制的CNN使用滤波器获取文本特征,仅得到局部单词间的依赖关系,未得到整体句子中所有单词间关系。 基于注意力机制的RNN、LSTM 等循环神经网络考虑前一时刻的状态信息,对过往信息具有记忆功能,但文本中单词间的依赖关系随着距离的增大逐渐减弱。 上述两种情况均使用单一注意力模式。 本文提出层次化双注意力GRU 网络的方面级情感分析模型,主要贡献如下:
(1)提出采用双注意力机制模式进行方面级情感分析,通过特定方面目标在句中的注意力机制和文本上下文自注意力机制,抽取方面特征信息和句子的全局依赖信息,从而深层次地获取情感特征。
(2)利用层次化的GRU 网络获取句子内部和句子间的依赖关系。 网络下层嵌入特定方面信息,获取了针对方面目标的局部特征信息,网络上层通过双注意力机制和词语层的输入,获取针对特定方面整体文本的特征依赖信息。
(3)在SemEval 2014 两个数据集和Twitter 数据集上进行对比实验,验证了该方法的有效性,针对方面级情感,分类准确率均得到了有效提升。
1 相关工作
方面级情感分析属于细粒度情感分析,早期研究中使用情感词典、机器学习等传统方法[5-6],需要大量预处理过程、复杂的特征工程和外部知识分析,耗时且模型效果差。
近期,深度学习在方面情感分类中有了较大突破,取得比传统方法更好的效果。 文献[7]提出基于门控制的卷积神经网络模型,根据特定的实体方面属性选择性地输出结果,模型速度和准确率得到较好效果。 文献[8]提出将Senti-LSTM 模型应用于方面情感分析,同时结合情感常识获得了较好的情感分类效果。 文献[9]提出AE-LSTM 神经网络和ATAELSTM 神经网络模型,二者都嵌入了方面信息,通过LSTM 获取文本上下文特征信息,最终建模生成注意力向量,后者比前者嵌入效果增强。 文献[10]提出将卷积神经网络和循环神经网络联合用于方面情感预测,方法中使用了投票策略。
早期,注意力机制首先应用到机器翻译中,提出全局和局部两种注意力机制[11]。 文献[12]利用长短期记忆网络结合注意力机制获取方面情感分类,方法中关注方面属性和情感术语的内在联系。 文献[13]提出将卷积操作和注意力机制结合,通过卷积操作得到某一方面的注意力。 文献[14]提出将卷积神经网络和注意力机制结合用于句子对建模,在卷积、池化的同时都进行注意力计算。 文献[15]提出利用全局注意力获取某一方面的粗略信息特征,利用语法指导的局部注意力获取距离某一方面较近的单词,最终合成全局注意力和局部注意力,避免句中与某一方面情感获取低相关的单词获得高注意力分数。 文献[16]提出基于注意力机制的Transformer 网络,其中使用大量自注意力获取句中单词关系,提出多头注意力机制,不再是传统的单一注意力,通过线性变换过程获取深层次的注意力表示。 由此证明注意力机制在方面级情感分析领域的有效性,近期研究较多围绕深度神经网络和注意力机制进行。
2 层次化双注意力GRU 网络
本节主要介绍层次化双注意力GRU 网络的方面级情感分析模型的相关细节。 图1 为网络模型图,由4 大部分组成:双注意力层(包含方面目标词注意力机制和上下文语义注意力机制)、单词层GRU 网络、句子层GRU 网络、情感输出层。 具体描述如下:
(1)方面注意力层。 通过获取方面词嵌入矩阵和文本上下文语义词嵌入矩阵的注意力值,得到方面的注意力信息。
(2)上下文语义自注意力层。 获取句中每一个位置上的单词与句中其他单词的依赖关系,计算两者间的注意力得分,从而获取文本全局上下文语义间的依赖关系。
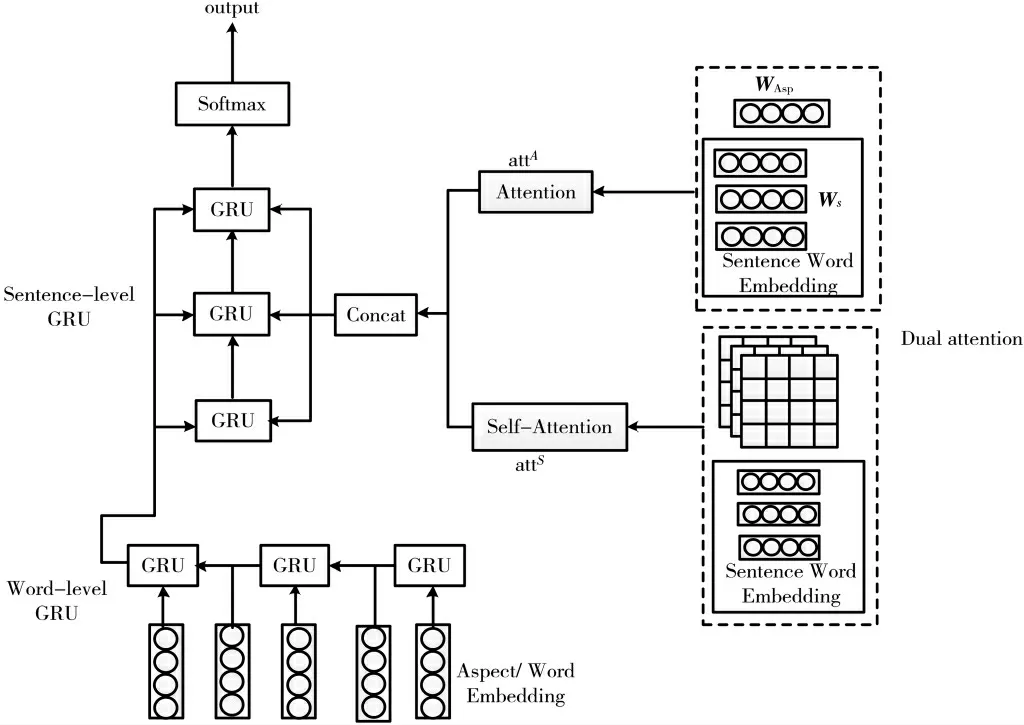
图1 层次化双注意力网络模型
(3)单词层GRU 网络。 其中在传统GRU 网络嵌入了方面特征,当前时刻状态由上一时刻输出和新嵌入信息决定。
(4)句子层GRU 网络。 双注意力层输出和词语层GRU 的输出合并进入句子层GRU 网络,从而得到整体文本间的依赖关系。
2.1 任务定义
2.2 方面注意力机制
本节针对句中的特定方面分析句中的哪些内容与其有较高相关度,比如句中情感词、与方面相对应的观点词等。
方面注意力机制如图2 所示。 假设句子s 中抽取的两个特定方面向量矩阵表示为WAsp=(WAsp1,WAsp2),句子s 的词向量矩阵为Ws,将每一个方面词嵌入矩阵与上下文词嵌入矩阵进行注意力计算,如式(1)所示,从而获取句子某一方面的注意力信息。

二者注意力计算采用加性相似度函数,如式(2)所示,使用的是神经网络,其中,σ(·)表示激活函数,wT是训练参数。相似度向量Eij进行归一化操作得到, 得到的注意力权重向量代表某一位置上方面词与上下文语义的相关程度,如式(3)所示。
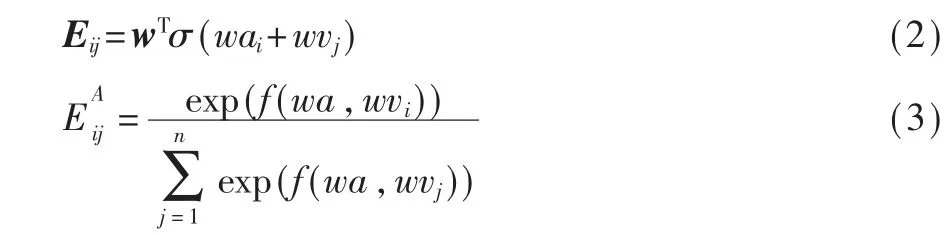
权重向量矩阵中对应元素与上下文词向量加权求和得到最终的注意力值,如式(4)所示:

2.3 上下文语义注意力机制
本节获取句中每一个位置上的单词与句中其他单词的依赖关系,计算两者间的注意力得分,从而获取全局的结构信息。 本文采用自注意力机制获取上下文语义依赖关系。
通过句子做不同的线性变换获取全面的注意

图2 方面注意力机制
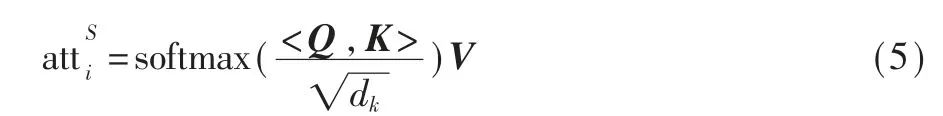
式中采用的是缩放点积注意力计算相似度,计算速度更快且减少了高维计算过程中产生的损失,其中,dk是矩阵K 中列向量维度。
2.4 层次化GRU 网络
本文使用层次化的GRU 网络分别获取句子层和词语层上下两层特征信息,下层获取句子内部单词层面之间的联系,上层获取不同句子之间的相关程度。
2.4.1 词语层GRU 网络
词语层GRU 网络针对句子特定方面目标词获取单词间特征联系,按方面划分的分句中包含了和方面相关度最大的特征信息,单词层面抽取的是单词间局部特征。
每一个GRU 单元以上一时刻隐藏层的状态和本时刻输入决定,词语层网络嵌入了方面信息获取基于方面的局部特征,如图3 所示。
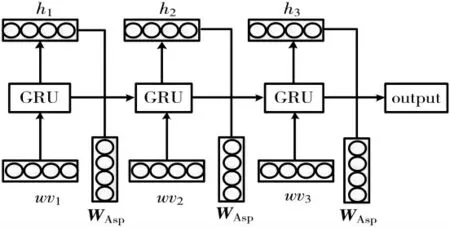
图3 词语层GRU 网络
句子s 经过GRU 网络得到每一时刻的隐藏层状态输出为h={h1,h2,…,hn},h∈Rd×n,其中d 为输出向量的维度。 将特定方面词向量WAsp和上一时刻网络的输出隐藏层状态hi线性组合,共同决定下一时刻的网络状态,如式(6)所示:

其中,Wh、Wa分别是隐藏层输出和方面向量相应的权重矩阵,通过训练过程调整权重参数达到特定方面目标的高关注度。
2.4.2 句子层GRU 网络
仅依赖词语层网络不能获取充分的特征信息,不同句子间也有着密切的联系,尤其对一些短句和表达不清的句子,需要利用句子层网络获取的整个文本情感信息来判断。
将双注意力与词语层GRU 的输出结果合并作为句子层GRU 网络的输入x′,如式(7)~式(8)所示:

其中,attA和attS分别是通过方面注意力机制和上下文注意力机制计算所得的注意力值,hn是词语层网络最末一层GRU 神经单元最终的输出。
2.5 模型训练
本文使用一个全连接层函数接收句子层GRU网络的输出,得到文本情感分类结果,如式(9)所示:

其中,W 是全连接层权重参数,b 是全连接层偏置项,hj是句子层网络的最终输出。 本文使用反向传播算法训练网络模型,通过最小化交叉熵优化模型,如式(10)所示:
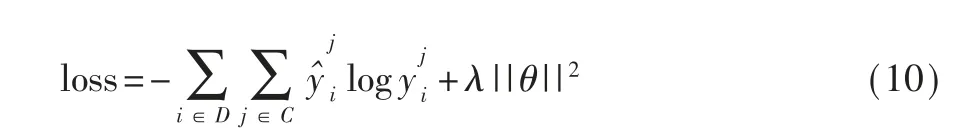
其中,D 是训练集大小,C 是数据类别数,y 是文本的预测类别,yˆ是实际的类别,λ||θ||2是交叉熵正则项。
3 实验
3.1 数据集
本文提出基于层次化双注意力GRU 网络的方面级情感分析模型(HDAG),采用SemEval 2014 Task4的Laptop、Restaurant 数据集和Twitter 数据集进行验证,数据集中包含四种情感类别:积极、消极、中立、冲突,由于最后一类数据在数据集中所占比例较低,实验用数据只保留积极、消极、中立三种。 实验数据集数据统计如表1 所示。
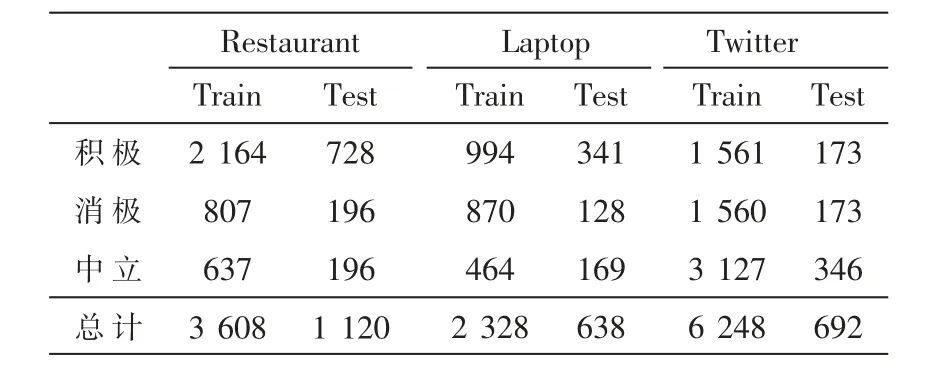
表1 实验数据信息
3.2 参数设置
本文实验的评价指标采用分类准确率,文本词向量采用Glove 进行初始化,词向量的维度为300。采用均匀分布U(-0.01,0.01)对未登录词随机初始化,偏置初始化为0,随机失活率(Dropout)设置为0.5,L2正则项系数设置为10-4,训练采用Adam 优化器更新模型参数,初始学习率设置为0.01。
3.3 对比模型
本文提出的基于层次化双注意力GRU 网络的方面级情感分析模型(HDAG)在两个领域的三个数据集上分别与以下模型进行对比,以验证模型性能:
(1)CNN:采用卷积神经网络模型,模型中输入的是独立的句子,在方面级情感分类中无方面信息和注意力机制的结合,不能获取针对方面的文本内部依赖关系,是一种最基本的卷积神经模型[17]。
(2)ATT-CNN:采用基于注意力机制的卷积神经网络,以独立句子为输入,针对特定方面目标计算注意力机制,在卷积层对方面相关情感信息高度关注,针对方面级情感分类效果有所提升,但不能获得文本句间的联系[18]。
(3)LSTM:采用最基础的长短期记忆网络,模型中输入独立的句子进行方面情感分析,不能针对特定方面目标获取相应情感信息[19]。
(4)LSTM-R:基于LSTM 的模型,整体文本评论作为模型输入,模型中关注了文本句子间的紧密联系,针对特定方面未关注其注意力机制[20]。
(5)TD-LSTM:通过两个LSTM 对左、右两个方向分别获取文本上下文信息,获得情感分类结果[21]。
(6)ATAE-LSTM: 将特定方面信息嵌入文本句子向量,利用注意力机制获取文本信息权重,从而得到情感分类结果[9]。
3.4 实验结果分析
将本文提出的网络模型(HDAG)与对比模型进行比较,实验结果如表2 所示。

表2 不同模型的方面级情感分类准确率(%)
分析表2 实验结果,类似第一行和第三行没有嵌入方面信息及注意力机制的模型,情感分类效果欠佳;基于LSTM 的模型优于基于CNN 的模型,是因为LSTM 缓解了句子的长距离依赖问题;ATT-CNN和ATAE-LSTM 加入注意力机制获取情感分类结果的模型分类准确率普遍高于无注意力机制模型,证明注意力机制对方面情感分类有一定提高作用,由于CNN 的局限性,加入注意力机制的CNN 不如注意力机制与LSTM 相结合的网络的分类效果好,ATAE-LSTM 嵌入了特定方面的情感特征,分类准确率在几种对比模型中相较最高;LSTM-R 将整体文本作为输入,获取了文本中句子间的关系,比以独立句子作为输入的模型情感分类效果更好,由此可得文本句间的相互关系对情感分类的重要性。
本文提出的网络模型在特定方面的情感分类准确率优于对比模型,验证了模型的有效性,对比模型中均使用单一的注意力机制,本文使用双注意力机制获取文本全局的依赖信息,使用分层的神经网络模型获取文本全局的情感特征信息,从而得到更好的分类效果。
3.5 不同注意力机制分析
本文计算特定方面目标的注意力机制和文本句子自注意力机制分别采用的是加性注意力和缩放点积注意力机制。
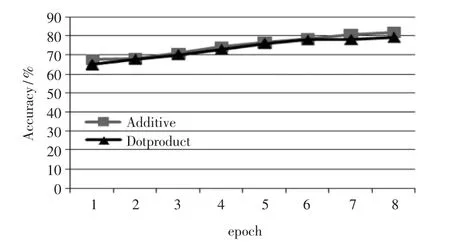
图4 注意力机制准确率
图4 是分别采用两种注意力机制的模型在三个数据集上不同迭代次数的平均准确率,加性注意力采用的是神经网络模型,在不同的迭代次数下略高于缩放点积注意力机制。 图5 是两种注意力在三个数据集上的运行时间,加性注意力需要训练参数,可以看出缩放点积注意力机制下的运行时间更短。
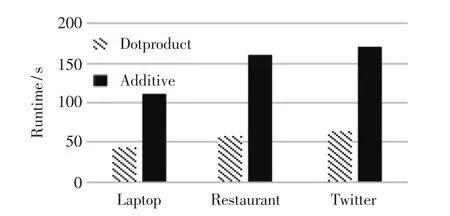
图5 不同注意力机制下的运行时间
因此本文方面注意力采用加性注意力机制;句子的自注意力过程需要多次线性变换,故采用点积注意力机制。
4 结束语
在以往工作中,方面情感分析模型仅考虑单一层面注意力机制,且无法获取句子间依赖关系。 本文提出一种层次化的双注意力神经网络模型用于方面级情感分析,针对特定方面引入方面目标的注意力机制以及文本上下文自注意力机制,获取方面特征信息和句子的全局依赖信息; 设计层次化GRU 网络,其中单词层嵌入特定方面信息,获取针对方面目标的句子内部特征信息,句子层网络通过双注意力机制和词语层的输入,获取句子间的特征依赖信息,从而实现深层次的方面情感分类。 模型没有考虑文本的时序性问题,以及针对跨领域词汇,模型的分类效果还有待提升,此工作将是下一步研究的重点。
猜你喜欢
现代电力(2022年2期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
电子制作(2019年19期)2019-11-23
当代陕西(2019年9期)2019-05-20
电子制作(2019年24期)2019-02-23
文苑(2018年21期)2018-11-09
北京航空航天大学学报(2017年12期)2017-04-23
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年12期)2015-12-10
