
结合注意力机制与残差网络的远程监督关系抽取*
2020-06-18 09:08谌予恒王
计算机与数字工程 2020年4期
谌予恒王 峥
(1.武汉邮电科学研究院 武汉 430074)(2.烽火通信科技股份有限公司南京研发部 南京 210019)
1 引言
关系抽取旨在识别句子中实体对的关系和属性。例如此句“Barack Obama was born in Honolulu,Hawaii.”关系抽取器的目标就是识别出其中的关系“bornInCity”。关系抽取是构建知识图谱的关键组成部分,对语义分析,智能问答等自然语言处理任务也是极其重要的。
在关系抽取中,一个主要挑战就是标注样本的缺失,针对这个局限性,Mintz等(2009)[1]提出了远程监督的思想,远程监督假设,一个同时包含两个实体的句子蕴含了该实体对在Freebase中的关系,并将这个关系作为该句子的标签。Mintz等在远程监督标注的数据上训练了关系抽取模型,有效解决了关系抽取的标注数据规模问题。但它同样也带来了一个新的问题——误标记问题。例如,句子“BillGatesofMicrosoft is the richestman。”并没有表达关系“founder”,但在样本中仍被标记为“founder”。近年来,深度学习被广泛应用于各个领域,Zeng等(2015)[2]提出采用卷积神经网络进行关系抽取,提出了一种新的网络结构PCNN,取得了远远高于基于特征的关系抽取模型的识别效果。次年Lin等(2016)[4]提出了一种新的选择注意力机制用于关系抽取任务,充分利用所有信息句,缓解远程监督关系的错误标记问题,取得了当时最好的效果。但这种Attention机制作用于句子级别,在缓解错误标记问题的同时却没有深入提取句子内部的信息。
本文通过结合Attention机制和ResNet结构,提出了一种改进的CNN网络用于进行关系抽取任务。ResNet充分利用了有效样本的信息并且通过Attention减少了噪音数据的干扰,在远程监督的关系抽取方面取得了较好的结果。
2 用于关系抽取的网络模型
在这一节中,我们描述了一种用于远程监督的关系抽取的新的深度学习网络模型。图1描述了我们的整体网络结构。
2.1 输入表示
本文采用的数据格式由实体对、关系、句子三部分组成,设wi为句子的第i个单词,e1、e2是相应的实体对。每一个单词将会经由两个映射表分别得到Word Embedding WFi和position embedding PFi,拼接这两个embedding后得到每个单词的词向量[WFi,PFi],设为xi。
2.1.1 Word Embeddings
Word Embeddings的目的是将词转化为分布式表示,从而捕捉词的句法意义和语义意义。所有的分布式表示包含在一个映射矩阵中,该映射矩阵可以表示为Xw∈Rdw×|V|,其中dw表示词向量大小,V表示一个固定大小的词汇表。然后wi在经过映射矩阵后可以得到一个实值对WFi。
2.1.2 Position Embeddings
在关系抽取任务中,我们的主要目标是识别句子中的实体对的关系,一个启发性的观点是距离实体对越近的单词越有可能包含了决定实体对之间关系的信息。因此,我们选择了Ps来标识句子中当前单词分别距离句子中两个实体e1、e2的相对位置。例如,在这个例子中“russia,turkey and india were off about 30 percent。”单 词“india”距 离head entity“russia”的相对位置是P1=3,距离tail entity“turkey”的相对位置是P2=2。Position Embeddings的映射矩阵Xp∈Rdp×|P|是经过随机初始化得到的,其中dp表示位置向量大小,|P|是固定的距离集合。应该指出,如果一个词离实体太远,它可能与关系无关。因此,我们选择最大值emax和最小值emin作为相对距离的上限制和下限值。最后我们将P1和P2通过矩阵映射为位置向量PF1和PF2。图1假设词向量大小dw=4,位置向量大小dp=1,结合词向量和两个位置向量后,一个实例将被映射为一个矩阵S∈Rs×d,s表示句子长度,d=dw+dp*2。矩阵S={x1,x2,…,xs}是网络的最初输入。
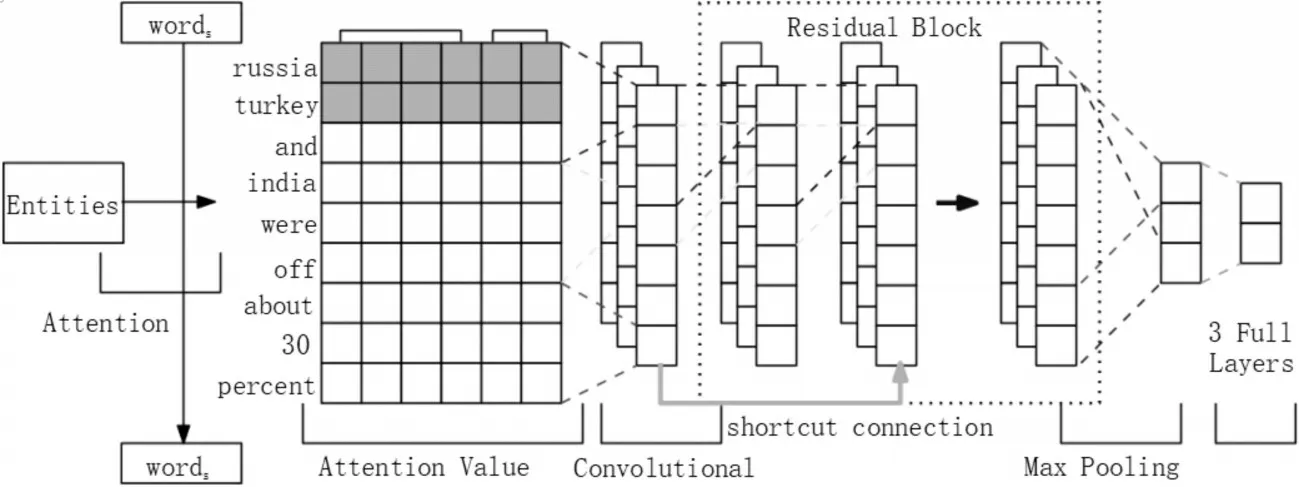
图1 用于关系抽取任务的ARCNN结构
2.2 Attention
Attention机制的思想来自于人类视觉注意力机制,人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,而后对这一区域投入更多注意力资源,抑制其他无用信息,本文设计的Attention架构也遵循这一思想。关系抽取任务的主要目的是获取与句中实体对相应的关系。因此,考虑与句子中实体对关系越近的单词越有可能包含实体对之间的关系信息,通过加强对这些单词的注意力权重,抑制其他的无用信息,使网络可以更好地读取需要的信息。
我们设计的Attention模型具体计算方式如下,首先将实体对与句子中的每个单词进行相似性计算得到每个单词与实体对的相似度作为注意力权重。

e是实体对相应的向量表示,然后对权重进行归一化处理。
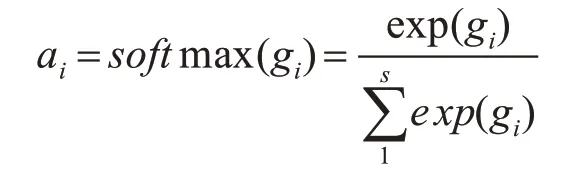
最后将权重与相应的单词进行加权求和,得到每个单词都被添加了与实体对相关信息的输入句子。
2.3 convolution
由于在关系抽取任务中,卷积被定义为权向量W∈Rl×d和输入矩阵S∈Rs×d之间的运算,l表示过滤器窗口长度,在图1中假设长度为3,即从每三个单词中提取一个新的特征。设xi:i+j={xi,xi+1,…,xi+j-1},则经过卷积后一个窗口xi:i+f生成的特征ci如下:

这里b∈R是偏置项,f是非线性函数。过滤器W将从x1滑动至xs产生特征c={c1,c2,…,cdc},dc=s-l+1。
2.4 ResNet
残差网络的学习目标是残差F(x)=H(x)-x,这种跳跃式的学习结构忽视了中间层直接将低层表示与高层表示相连接,并且极大地缓解了困扰深度网络的梯度消失问题。在我们设计的模型中,我们使用捷径连接(shortcut connections)来构建残差卷积结构。每一个残差块包含两层卷积,每层卷积层后面紧接着一层非线性层,激活函数设置为Re-LU激活函数。所有的卷积窗口大小都是l×d,在经过padding之后输出与输入保持相同的尺寸。第一层层卷积过后,第i个窗口输出结果如下:

第二层卷积过后,第i个窗口输出结果如下:

这里的b1和b2是每一层的偏置,b1,b2∈Rdc。残差块学习的目标如下:
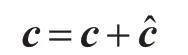
整个ResNet由四个上述残差块组成一个级联架构,最终输出结果为c,代表提取出的更抽象的关系信息,c∈Rdc×1。
2.5 Max Pooling,Softm ax Output
卷积层和ResNet层的输出依赖于输入句子的长度,为了消除这种影响,我们应用了最大池化(Max Pooling)层将ResNet层提取的特征结合起来,Max Pooling的主要目的是捕捉每个特征映射中最重要的特征,c′=max(c)合并后可以得到更高层的特征,m表示过滤器的数目。为
了计算每个关系的置信度,我们将z输入一个全连接的softmax层中:
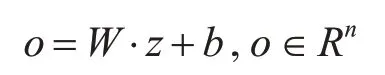
o是网络的最终输出对应于与所有关系类型相关联的分数,其中分数最大的一项为当前句子的关系,n表示需要识别的关系类型数目,最后为了避免过拟合我们选择在输出层使用dropout:
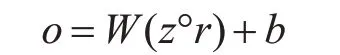
°是元素乘法操作,r是概率为p的伯努利随机变量的向量。在测试过程中,学习到的权重向量按p缩放,并用来评估实例(这里不使用dropout)。
3 实验
3.1 实验配置
在本文中,我们的Word Embedding是使用Skip-gram模型在NYT语料库上训练得到的。ARCNN算法使用的Word Embedding的尺寸是50,输入文本经过padding之后尺寸固定为100。模型采用Tensorflow框架构建,选用了自适应优化算法Adam来最小化目标函数,每批次训练数据大小设为B=64,初始学习速率设为λ=0.001。整体实验基于TensorFlow 1.7.0。所有的实验都是在三个Nvidia GTX 1080(GPU)上进行的。在表1我们展示了所有的实验参数配置。

表1 实验参数
为了评价模型效果,我们通过held-out评估方法对以下几种模型进行比较。CNN由Zeng等(2014)[3]提出,包含了一层卷积层和一层全连接层。CNN+ATT添加了注意力机制的CNN模型,由Lin等(2016)[4]提 出。ResCNN-9由Huang等(2017)提出,在CNN的基础上添加了4个残差块及两层全连接层。ARCNN-9则是我们提出的包含注意力机制的深层CNN模型。
3.2 结果
我们在一个开放使用的NYT freebase大型数据集上评估实验效果。该数据集的优点在于训练数据含有570088个实例,测试数据含有172448个实例,数据格式为(实体对,关系,句子)。与Zeng等(2015),Lin等(2016)[2,4]类似,我们采用precision/recall曲线和Precision@N(P@N)来评判模型效果。
在图2中,我们提出的模型ARCNN与其他几种深度学习模型进行了比较。首先,深层的网络模型确实取得了相比单层CNN更好的效果,假设低层,中层和高层网络分别学习了文本中隐藏的词法,句法和语义表示,ResNet的shortcut connections结构则跨过了句法直接将词法和语义相连接使ResCNN模型可以读取更关键的信息[5]。其次CNN+ATT模型取得了近似于ResCNN-9的效果,验证了Attention机制在处理噪音数据上的优良性能。最后结果显示我们结合ResNet结构与Attention机制的优点提出的新的ARCNN模型的召回率在不丢失精确率的情况下相比ResCNN模型和CNN+ATT模型有较大的提升,获得了更好的效果。

图2 ARCNN与不同的CNN模型的比较结果

表2 多种关系抽取模型的P@N
在表2中我们使用了Precision@N方法比较了各种模型的性能,当N=100时,ARCNN的precision高达84%,当N=300时,precision也不低于70%。相较CNN、ResCNN和CNN+ATT而言,本文提出的ARCNN在所有的测试设置中都达到了更好的性能。
4 结语
本文介绍了一种用于远程监督关系提取的深度学习方法。我们证明了:1)更深的卷积模型有助于从文本中提取更关键的信息;2)Attention机制可以更好地抑制远程监督数据中的噪音影响。
在实验中评估了我们的深度学习模型ARCNN,相对于ResCNN和CNN+ATT模型,在关系抽取任务中ARCNN模型表现出了更好的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
新高考·高一数学(2022年3期)2022-04-28
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2020年1期)2020-01-15
