
基于Python的BIC语音分割算法的实现与应用*
2020-06-18 09:07王方丽傅嘉俊
计算机与数字工程 2020年4期
王方丽 傅嘉俊
(华南理工大学广州学院计算机工程学院 广州 510800)
1 引言
目前,随着网络技术的发展,人们可以通过各种不同的途径获得各种视频资源,但有些视频资源少有翻译版本,不利于学习和使用。因此,如果能够对于视频中的音频进行直接翻译并加载到视频中,就能大大方便人们获取和利用资源。要实现这一功能,主要是对于视频中的音频进行识别、分割和翻译。语音分割是语音识别以及翻译处理的基础,很多语音分割技术都是基于BIC算法实现的,如运用改进型BIC算法对语音进行分割[1~3]、检测说话人改变实现语音分割[4],综合利用BIC及PSO[5]实现语音识别;文献[6]以基于BIC的说话人分割系统作为基线系统,对比分析重叠语音检测对说话人分割性能影响等。
本文主要采用基于贝叶斯信息准则的语音分割原理对于获取的声音资源进行分割,并运用Python技术实现相关的算法。在语音分割前,主要利用FFmpeg工具进行视频的声音提取;语音分割后,利用IBM接口实现语言识别和有道接口进行翻译,最后字幕加载采用FFmpeg开源工具。
2 语音分割算法的研究
2.1 基于贝叶斯信息准则实现语音分割
音频分割是指将音频流分为若干片段,使得每个片段在内容类别上具有一致性[7]。基于BIC的分割方法不需要先验知识,不需要设定门限阈值,且具有较好的准确度[8],因此被广泛采用。贝叶斯信息准则作为一种常见的模型选择准则[9],可用于判断模型好坏。假设给定数据y={y1,y2,…yn},候选的模型集合为Mk={Mk1,Mk2,…MkL},并假设任一个候选的模型Mk都是有独特的参数向量qk定义,定义如式(1)所示:

音频分割也称跳变点检测[10~11],假设有一段语音对话,在第i时刻有一个跳变点,则可以把连续的高斯过程和有跳变点的高斯过程这两个假设模型进行选择的问题作为跳变点问题的等价问题,采用独立多变量高斯分布描述这两个模型的语音信号的特征序列,如式(2)和式(3)所示:

其中:xi∈Rd(i=1,2…N,是观测数据),N是多变量高斯模型,m和S是该模型的参数,d是特征向量维数。使用贝叶斯信息准则进行判断,如果第一个模型的概率比第二个模型概率大表明该语音在第i时刻无跳变点,反之则表明该语音在第i时刻存在跳变点。
假设跳变点存在,那么对应的对数最大似然比为式(4):

其中,Σ是所有数据的协方差矩阵,Σ1是开始时刻到第i时刻的数据集{x1…xi}的协方差矩阵,Σ2是第i时刻后的数据集{xi+1…xN}的协方差矩阵。符号 ||Σ代表矩阵Σ的行列式。
比较两个模型:一个模型的数据符合两个高斯过程,另一个模型的数据只符合一个高斯过程。它们之间的不同通过对贝叶斯信息准则添加惩罚项来修正,得到贝叶斯信息准则值的计算,见式(5):
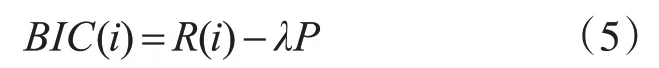
其中,R(i)是上面定义的对数最大似然比,惩罚项的权重λ一般取为1,而P为式(6):

式(5)与式(1)相比,有一个-1/2的系数,因此问题解决的关键从求解贝叶斯信息准则值的极小值变为极大值,即式(7):

利用Python[14]实现贝叶斯信息准则计算主要采用语音的Mel频率参数进行,该参数可以用矩阵表示。当获得该参数时,先计算该段语音的Mel频率矩阵的平均协方差矩阵和最小值。得到这些参数后,先对整个语音段进行遍历,选出模型的分割点(可能不存在分割点),再将整个语音段按照一个步数进行划分(如该语音段长50,以步数5进行划分则分成10个部分)。对这些部分进行遍历,假设遍历到第i段,则将语音端分成part1和part2两个部分,再分别计算它们的似然矩阵det1和det2,再计算贝叶斯信息准则量,最后将该贝叶斯信息准则量存到一个数组x中,Python实现如下:

遍历完成,就得到一个根据指定步数对语音端划分的贝叶斯信息准则量数组,由贝叶斯信息准则量越大则越大几率符合该模型的定理可以知道,只需要对该数组求最大值就能判断出语音端的说话人分割点。
2.2 语音多点分割
对语音进行多点分割时,先设置一段窗口范围作为语音的检测窗口,通过这个检测窗口对语音进行贝叶斯信息准则量的计算。如果在这一段存在分割点,记录分割点位置,移动检测窗口检测下一部分;如果不存在分割点,则调整检测窗口的大小继续检测。一直重复上述过程直到这段语音检查结束,最后输出该语音段的分割点位置数组。该算法伪代码如下:
输入:该语音段的Mel频率倒谱系数矩阵Mel=[mij]
输出:通过贝叶斯信息准则计算的该语音段分割点数组[r1,r2,…,rn],
1)初始化检测窗口,设置为[wStart,wEnd]。
2)在[wStart,wEnd]这个时间段内运用贝叶斯信息准则算法检测是否有分割点。
3)根据2)计算的贝叶斯信息准则量进行判断:
(1)如果值大于0,存在分割点,记录该分割点位置wStart+BICioc,调整检测窗口位置。
(2)如果值小于等于0,则不存在分割点,则增大检测窗口。
重复2)、3)步直至语音段检测完毕,算法结束,输出该语音段的分割点位置数组。
2.3 使用语音活性检测对分割点进行筛选
语音活性检测(Voice Activity Detection,VAD)是对连续带噪语音信号进行检测,准确地定位语音的起止位置,其检测结果直接影响着语音识别效果[15]。将语音进行分割后,可能会把一些静音的语音端也切割处理,此时就可以运用语音活性检测进行分割点的筛选。
假设一段由四个说话段组成的语音,使用贝叶斯信息准则计算语音分割点,结果如图1所示。贝叶斯信息准则基本上可以将这段语音完美的分割,但是它把语音开头的静音部分也进行了切割,实际上不需要将该段静音段切割开来,这样反而增添了后续处理的复杂度。因此,就需要使用语音活性检测对分割点进行筛选,将静音的分割点去除,使贝叶斯信息准则计算出的分割数组更符合实际应用情况。

图1 贝叶斯信息准则语音分割点示例
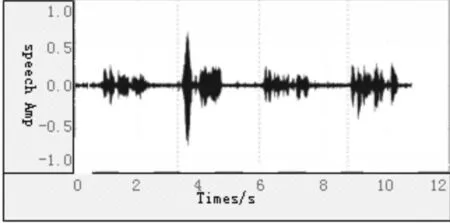
图2 语音活性检测处理过的语音分割点示例
语音活性检测过程如下:先运用BIC计算分割点,再使用语音活性检测检测每段划分的语音,如果语音活性检测检测不到有语音端点,则剔除该分割点;如果语音活性检测检测到有语音端点,则保存该分割点不做处理。对图1中的语音经过语音活性检测处理过的语音分割点数组如图2所示,对比没有进行语音活性检测的分割点数据,进行了语音活性检测的分割点数组更加贴近实际,更具有使用价值。
3 算法实现与应用
3.1 视频语音翻译流程
视频语音翻译流程如图3所示,其中,视频转换是采用开源工具FFmpeg提取原视频的语音文件;语音分割利用第二部分算法对于语音段分割;语音识别是将分割后的每一段小语音都采用IBM的语音转文字接口进行语音的识别,将语音转换成文本;语音翻译则是把上一阶段识别出来的语音文本采用有道的外文翻译接口进行翻译;字幕加载使用FFmpeg工具实现,字幕加载的时间长度取决于分割的语音段长度。

图3 语音翻译流程
3.2 语音分割实现
语音分割的核心是运用贝叶斯信息准则判断说话人的语音分割点,该算法可以判断说话人的停顿点并将一段长语音分割成多个完整的、短小的说话人语音,具体过程如下:首先对文件进行处理,通过librosa库的load方法获取音频文件的时间级数和y,然后根据该级数和通过librosa库来提取Mel频率矩阵;接着使用speech_segmentation来获取分割点数组seg_point;由于该数组是非时域的,再将数组乘以步长后进行适当的填充,最后的结果才是语音时间域上的分割点数组。
获取最终分割点数组seg_point后,再对该数组进行语音活性检测,代码如下:
for i in range_loop://range_loop为数组长度-1
temp=y[seg_point[i]:seg_point[i+1]]//相邻分割点之间的时间级数
#计算vad判断是否为空白点
x1,x2= vad.vad(temp,sr=sr,frame_size=frame_size,frame_shift=frame_shift)
if len(x1)==0 or len(x2)==0:continue//静音段不处理
else:output_segpoint.append(seg_point[i+1])
最后输出的数组output_segpoint就是剔除静音段后的语音分割点数组。
3.3 语音识别模块
语音识别采用IBM接口实现,使用开源项目speech_recognition(集结了主流的语音识别接口并提供统一的Python调用方法),调用该接口算法的伪代码如下:首先要实例化一个speech_recognition的对象;接着用speech_recognition框架里的Wav-File方法获得文件的数据源;再通过speech_recognition的对象调用record方法将音频文件的数据源转换成audio类型对象;最后使用speech_recognition对象的recognize_ibm方法来调用IBM的接口方法即可。该接口会以字符串的格式直接返回翻译好的译文。
3.4 语音翻译模块
语音翻译是采用有道接口实现的,Python实现如下:
data=get_url_encoded_data(query_text)//获 取url编码过的数据
target_url=url+‘?’+data//构造目标url
request=re.Request(target_url,headers=headers)//构造请求
response=urlopen(request)//发送请求
return parse_html(response.read())//解析,显示翻译结果
其中get_url_encoded_data方法是将待翻译文本进行重新编码,将编码文本与接口路由拼接获得target_url,之后使用request库生成一个url访问对象,然后使用urlopen方法通过该对象发送请求获得接口的请求回复response,然后解析该结构就可以得到翻译后的文本。
3.5 功能测试
对于该语音分割算法测试如下:
第一步,进入窗口界面,选择需要识别的视频(支持MP4、AVI格式),然后可以开始进行转换。
第二步,转换过程中,进度条会显示转换进度,等待一段时间后,系统完成工作。
第三步,查看视频,即可看到已经将翻译后的字幕加载到视频中。
通过实际测试,该项功能能够正常使用,字幕可以正常翻译成中文,且字幕加载时长与实际说话人时长一致。根据实际的需要,运用其他的翻译接口,可以对于其他种类的语音资源进行翻译和字幕加载。
4 结语
本文主要研究了基于贝叶斯信息准则的语音分割算法。同时,结合语音识别、翻译等技术,将该算法运用于具体的实践中,用以解决视频语音翻译中语音分割和视频字幕加载时间长度的确定。
猜你喜欢
电脑报(2022年13期)2022-04-12
中国注册会计师(2021年10期)2021-11-22
电脑报(2020年24期)2020-07-15
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
电脑爱好者(2017年22期)2017-12-04
数学学习与研究(2017年10期)2017-06-22
初中生之友·中旬刊(2015年4期)2015-06-10
消费导刊(2014年12期)2015-02-13
