
基于角度的多数据流异常检测方法*
2020-06-18 09:08黄东东
计算机与数字工程 2020年4期
黄东东 徐 建 张 宏
(南京理工大学计算机科学与工程学院 南京 210049)
1 引言
随着云计算技术以及大数据技术的发展,单个计算节点的计算能力难于快速、有效地处理大数据,所以大规模数据的计算任务越来越依靠同构计算系统,比如Map Reduce[1~3]、Bulk Synchronous Parallel(BSP)[4]等来完成。同构[4~5]计算系统运行过程中,计算节点会受到网络攻击,软件衰退[5~6]等因素影响而产生异常。因此,通过计算节点的监测数据发现异常节点对于快速的系统恢复和管理有重要作用[7]。
每个计算节点持续采集的数据可以视为一个由多个维度,如CPU、内存、I/O信息、网络等构成的高维数据流,而整个计算系统的多个节点产生的数据流则可视为多条高维数据流。针对多数据流中的异常检测一直是异常检测领域中的研究热点。面临的挑战主要包括:1)动态性[8],与传统静态数据不同,数据流异常检测的研究对象是不断输入数据的数据流,具有动态的;2)无限性[9],数据流会源源不断地输入数据,存储资源的限制使得考虑所有历史数据的可能性是不存在的;3)迁移性[8],数据流的异常检测更加注重数据流的当前数据,历史数据包含的信息价值会随着时间的推移而逐渐减弱。
数据流的异常检测的难点是如何度量多数据流间的相似性,与整体相似性较高的数据流被视为正常数据流,与整体相似性较低的则被视为异常数据流。基于不同的理论和应用,提出了不同数据流异常检测方法,主要有基于密度的异常检测[7,10,15],基于网格的异常检测[11]和基于距离的异常检测[12~16]。
上述方法在实际应用过程中存在以下问题:1)阈值难以设定[18]。上述异常检测方法要么采用top-k方式把异常量化值最高的k个数据流作为异常,要么把异常量化值超过预定义阈值的数据流作为异常。阈值的合理设定需要对应用程序的底层机制非常熟悉,这对于一般应用者而言,难度太大;2)异常的数目一直在变化[17]。某个时刻可能存在超过k个异常数据流,采用top-k方式会遗漏这些真实存在的异常;3)在数据流为高维的情况下,以上的异常检测方法不够稳定。针对以上问题,本文以角度作为相似性度量指标,提出了一种基于上下文的高维多数据流异常检测方法,并在其中采用了无指导的学习方法自动获取阈值,尽量减少了参数的设定。
本文的贡献在于:
1)使用了在高维下表现更加稳定的角度作为高维数据流相似性度量,从而避免了基于欧式距离等其他度量方式的缺陷。
2)充分考虑高维多数据流的特点,结合历史信息以及当前多数据流之间的相似性,计算并比较数据流之间的整体相似性,并且考虑到数据流历史信息的迁移性对数据流历史信息进行衰减,提高异常数据流检测的准确率。
3)采用无指导的学习方法自动获取动态变化的异常检测阈值,能够更好地适应异常频繁改变的场景,同时减少了人为干预。
2 相关技术
Kriegel等[22]提出一种基于角度的异常点检测算法ABOD(Angle-based Outlier Detection)。该算法的基本思想是以角度分布度量高维数据间的相似性:如果数据集中某点与数据集中其他点构成的向量与基准向量夹角角度方差值越小,该点就越有可能是异常点,反之则很有可能为正常点。如图1所示,以分布在空间中的2维数据集为例,图中的坐标轴数值仅仅表示数据点的位置信息,没有实际含义。观察图1(a)中离群点O到数据集中其它数据点构成的向量,这些向量与基准向量所构成的角的大小较为接近,即这些角度的方差较小;而图1(b)中点O处于数据集内部,比较其与数据集中其他点构成的向量与基准向量夹角,角度差异较大,即这些角度的方差较大。基准向量可以随机选取,但必须统一。实验结果表明由于在高维空间中,角度比距离更加稳定[23],并且不会出现实质性恶化,所以运用基于角度分布的方法来度量高维数据的相似性相对于基于距离的方法表现更加稳定。

图1 数据分布图
3 多数据流异常检测方法
3.1 框架
本文提出了一种基于上下文以角度作为相似性度量指标的高维多数据流异常检测方法,其框架如图2所示,所采用的基本思想如下。
1)基于角度的方法计算出同构计算系统中每一个计算节点当前时刻的异常值。
2)考虑计算节点的历史异常值,度量该计算节点对应的数据流整体异常值。由于数据流具有迁移性,所以随着时间的推移,越是久远的数据所携带的信息越少,计算时对于数据流历史异常值进行衰减处理。
3)建立数据流整体异常值的动态阈值机制,即根据当前时刻数据流的整体异常值动态的决定异常数据流的异常阈值。
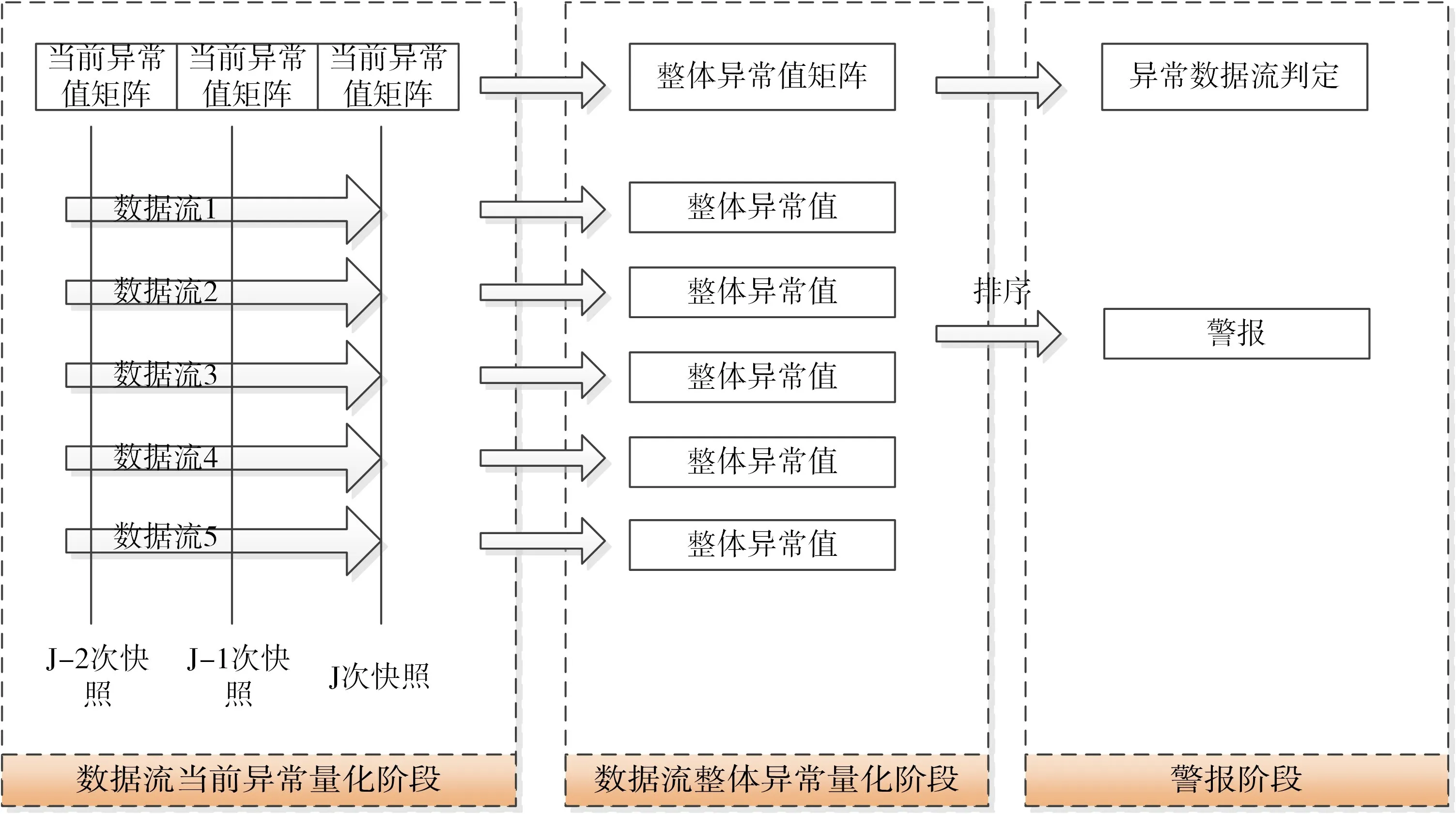
图2 基于角度的高维多数据流异常检测算法框架
3.2 数据流当前异常量化阶段
根据基于角度的数据相似性度量理论,本节提出了数据流当前异常值的概念,定义如下。
对于一个包含n个节点的同构计算系统,该系统中每个计算节点都在源源不断地产生数据,每个计算节点对应着一条数据流,整个计算系统中包含了n条数据流。
采集每一个计算节点的m个维度的数据,并对每一个计算节点的m个维度的数据每隔一段时间便进行一次快照。
每个计算节点的m个维度的数据形成一个m维矩阵,整个系统能够形成n个m维矩阵;第j次快照所形成的数据矩阵为,矩阵Fj中的数据fji为第i个节点第j次快照所得到的m维数据矩阵。
根据定义1计算出该同构计算系统所产生数据流在第j次快照时的当前异常值矩阵,其中valji表示第i个节点在第j次快照时的当前异常值。的具体计算过程如下:


即

3.3 数据流整体异常量化阶段
由于数据流数据的动态性,无限性,而数据流的当前异常值仅仅显示了数据流当前时刻的异常情况,所以只根据数据流当前某个时间点的异常值来判断数据流是否异常容易产生误报和漏报。因此在对数据流进行异常度量时,考虑历史信息显得很有必要。
传统的解决方法是设定滑动窗口[25~26],以滑动窗口内的信息来代表整个数据流的异常情况。但是这样的方法存在如下缺陷:1)窗口长度难以确定。窗口过短不能真正表示出整体数据流的异常情况而窗口太长又很可能将真正的异常信息掩盖;2)窗口内信息具有迁移性。窗口内不同时间出现的信息的价值不同;3)窗口外的信息被忽略。基于滑动窗口的异常度量只能考虑到滑动窗口内部的信息,而对于更早产生的信息则会忽略,这是不符合实际的。
所以本文提出了结合数据流历史异常值,从整体考虑数据流的异常情况,定义了数据流整体异常值的概念。其具体定义如下:
数据流i的第j次快照时总体异常值vali'j具体计算过程如下:

其中λ为衰减系数。
由此可以构造出j次快照时整个同构系统中数据流的整体异常值矩阵。
根据以上理论数据流整体异常值VAL'j考虑了全部的历史信息,并对历史信息进行了衰减,越久的信息对数据流整体异常值的影响越小。因为考虑了历史信息,所以该计算模型能够抵抗数据流的瞬时波动,大大降低了误报的可能。另外根据式(4),该方法只需要储存每个时间点的数据流整体异常值,数据流整体异常值的更新的空间和时间复杂度都为O(1),那么更新数据流整体异常值矩阵的时间复杂度则为O(n),所以以上算法可以高效地计算出数据流的整体异常值。
3.4 告警阶段
根据以上方法,可以计算出每一个计算节点的整体异常值,异常值越高的节点越有可能是异常节点。本文提出了一种无指导的学习方法来自动获取动态变化的异常检测阈值,能够更好地适应异常频繁改变的场景,并且减少人为干预,避免对于异常阈值的设定。
3.5 算法
本节说明算法的实现流程。具体算法如下。
输入:为预处理后得到数据集合Fj,j为快照次数输出:异常节点
2)取数据集合Fj中任意点,计算该点与数据集中其他所有点形成的向量同基准向量夹角的余弦值;
3)根据式(3)计算2)中所有余弦值的方差,取倒数,存入数据流当前异常值矩阵中;
4)取数据集合Fj其他点重复2)、3)步骤;
5)根据式(4)计算出j次快照时整个同构计算系统中数据流的整体异常值矩阵。
6)对数据流整体异常度进行排序,根据公式(5)判定异常点。
在算法计算数据流当前异常值的阶段,假设数据集合中共有n个数据流,选定数据集中某一条数据流,计算该点与数据集中其他点连成的向量同标准向量之间夹角的余弦值,并通过方差求出该点当前异常值的时间复杂度为O(n-1),遍历数据集合中的所有数据点计算所有点的当前异常值的时间复杂度为O(n(n-1));而在计算数据流的整体异常值矩阵阶段,根据3.2节式(4),我们只需要储存每个时间点的数据流整体异常值,数据流整体异常值的更新的空间和时间复杂度都为O(1),那么更新数据流整体异常值矩阵的时间复杂度则为O(n);在异常数据流的判定阶段,主要是对于数据流整体异常值的排序,采用快速排序算法平均时间复杂度为O(n log n)。综合以上基于角度的高维多数据流异常检测算法的时间复杂度为O(n2)。而以往的基于角度的异常数据检测方法如ABOD(Angle-based Outlier Detection)算法采用的计算某点与数据集中任意两点连成向量所构成的角,所以其时间复杂度为O(n3)。相比于以往的算法,本文的算法效率更高。本文在后续的实验结果也表明该算法的效率较高。
4 实验
本节针对基于角度的高维多数据流异常检测方法进行测试分析,通过不同类型的数据集进行实验对比。本文所有的实验都运行在3.1GHz Intel处理器、内存2GB的Windows平台上,算法均由Java实现。
4.1 实验数据集
本节仿照真实同构计算系统的实际情况生成了人造数据集,以测试算法的性能。人造数据集中包含1000个数据流,每个数据流包含50个维度,每个维度的数据均为随机生成,相同维度的数据生成策略相同,分别在空间上符合高斯分布、正弦变化、泊松分布等。图3是一条示例数据流的前6属性数据,6个维度的数据分别符合不同分布,并且在500s时该数据流的第1和第4维度的数据开始出现异常。本文在该数据集上对异常数据流检测准确性进行测试。
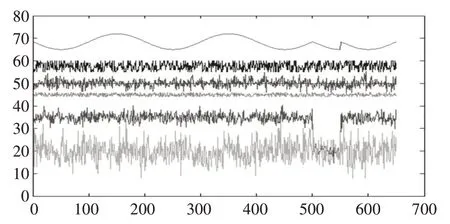
图3 示例数据流
4.2 实验结果分析
评价多数据流异常检测方法的重要指标就是告警的准确性。实验中关于准确率的定义如下。
实验中将本文提出的基于角度的高维多数据流异常检测方法同基于距离的k-means异常检测方法进行对比试验,采用的数据集如图5所示,图7展示了两种方法在时间段1~100的对比效果,其中横轴代表时间,纵轴代表准确率,虚线和实线分别代表基于角度和基于距离两种异常检测方法。

图4 高维情况下异常数据流检测效果
从图4的实验结果中可以看出:
1)基于角度的方法表现优于基于距离的方法。由此可以得出结论:在数据为高维的情况下,相比于基于距离的方法,基于角度的高维多数据流异常检测方法准确性更高;
2)基于距离的异常检测方法的准确率出现不稳定波动(如时间点6,8,17,61,96等),而基于角度的异常检测方法则表现相对较为稳定。由此可以得出结论:在高维多数据流的情况下,基于角度的异常检测方法表现的更加稳定;
3)在数据流刚抵达(时间点1)或者(时间点50)异常刚出现的时候,两者的准确率都出现了较大程度的下降。这是数据流整体异常值计算机制导致的,充分考虑了历史信息,可以抵抗数据流的瞬时波动,当数据流出现持续异常(时间点50~100),准确率逐渐升高并趋于稳定。
5 结语
在同构计算环境中,每一个计算节点承担的计算任务较为类似,所以每一计算节点的运行状态也较为类似。每一计算节点在运行过程中源源不断产生的信息可以看成一条包含多个维度数据(例如,CPU、内存、I/O信息等)的信息数据流,而整个计算系统产生的信息数据则可以看成多条高维数据流。为此,本文以角度作为相似性度量指标结合上下文以及同一时间点下的同构数据流,提出了一种基于上下文以角度作为差异衡量指标的高维多数据流异常检测方法,并在其中采用了无指导的学习方法来自动获取阈值,尽量减少了参数的设定。实验表明该方法有效地解决了高维多数据流的异常检测问题,并且具备高准确性,抗干扰性等特点。
在后续的研究工作中,将围绕以下几个方面进行研究。比如,对于异常数据流检测精度的合理性选择进行更加详细的讨论,提出更加有效合理的精度选择方法;对于数据流中不同维度数据不同权重的讨论,加入对于数据流维度数据权值的讨论;提出增强该算法对于不同类型数据的适用性的详细方法等等。此外,还可以利用更加有效的采样技术、降维等技术提高算法的效率,进一步降低算法的时间和空间复杂度,从而更好地应用于实际问题中。
猜你喜欢
航空学报(2022年7期)2022-09-05
计算技术与自动化(2022年1期)2022-04-15
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
科学导报(2020年85期)2020-01-13
初中生世界·七年级(2019年8期)2019-08-29
网络空间安全(2019年10期)2019-03-20
神州·下旬刊(2017年6期)2017-10-28
世界知识画报·艺术视界(2017年7期)2017-07-27
今日中国(2017年3期)2017-03-31
