
K-means 的应用混合数据算法
2020-06-15 12:04张宇亭
现代计算机 2020年13期
张宇亭
(南京理工大学,南京 210000)
1 介绍
每个组织在某个时候都会经历一场数据驱动的革命。企业采用大数据工具,从社交媒体活动、网络浏览、手机使用、视频、音频、图像、短信,以及移动网络的、物联网中获取新的数据,这些数据中有大量的细粒度的数据,需要另外进行区分和保存。对大数据的分析有望产生深刻的见解和预测,从而彻底改变管理层的决策。大数据提供了一种方式,将世界上许多从未被量化的方面呈现了出来,这个过程也被称为“数据化”。
在Hadoop 平台中,依据HDFS 文件系统,可以对大量的进程进行处理,主要依据的是MapReduce 的计算框架。此外,还有用于分析各种业务用途的信息的其他功能和工具(例如机器学习算法)。能够结合大数据工具与不同的数据分析工具,如Apache Hive 和Apache Pig!,以及为处理数据而设计的各种其他大数据工具,如ETL。Apache 的Hadoop 是一个平台,通过HDFS 存储、管理、读、写和操作大量数据/文件的能力,HDFS 是一个基于谷歌文件系统(GFS)的系统,可以分析不同目的的信息。虽然这些方法提高了处理大量数据的可能性,但它们并没有提供用于分析和决策有效数据的结构算法。例如IBM 的沃森可能在自然语言处理方面处于前沿,但就系统通过互联网吸收和解释大数据的相关数据,它还有很长的路要走。这些观察结果反映出,在一个新兴的大数据生态系统中,需要开发新的方法来结构化和分类大量数据。
依据K-means 算法的特征,在处理非数值数据的时候,依据经验,可以有如下的解决方案。首先创建一个过程,“扁平化”所有数据,从分类和数字数据到纯数字的数据。根据分类组合将所有分类过滤成不同的组,这样就可以单独分析每个组(因为我们处理的是大数据,所以分组过程和K-means 过程都是通过大数据平台进行的)。也就是说,只对其余的数值变量执行K-means 算法。最后,根据所做的实验,对结果集进行分析,这些结果集可以作为进一步研究的基础。
本研究提出了一种以前不可能处理大数据中混合数据的方法。该方法提高了处理大量数据的能力,例如在决策中,因为可以更有针对性的方式执行分析、预测。
2 模型开发
我们认为,将K-means 算法应用于大数据生态系统中的混合数据,可以增强决策能力,使决策者能够处理海量数据。因此,本研究分析了K-means 算法在大数据平台中应用于数值和分类(非数值)数据时的影响。该模型假设数据集包含m 个分类变量和n 个定量变量,分类变量j 可能具有j≥2 种不同状态。K-means算法程序:
要求1:大数据中的非数值数据可以赋值。
证明:首先对数据集执行K-means 算法,步骤如下:
(1)创建∏mj=1 不同类型的组,它们的类别变量的值不同。对于每个记录,都会有相应的分组,然后把每个记录放到相应的分组中去。
(2)第一步生成的每个组都是大数据平台中的一个文件(或其他存储格式)(这将在接下来的步骤中启用并行计算)。
(3)根据数值变量对所有组执行并行K-means算法。
(4)将步骤3 中的所有集群(每个组中的K 个集群)聚合到一个结果,以进行进一步分析,如第4 节所述。
3 算法案例的实现
(1)将数据集和分类文件上传到HDFS(在Apache Hadoop 中),每个类别变量的值可能的组合在一个单独的文件中。每个文件都会有相应的记录,这是一个强制性步骤,因为需要根据定义/业务需求创建所有可用状态的组合。注意,如果没有具有相应分类值的记录,则可能存在空文件(组)。
(2)将所有文件(从步骤1 开始)相乘以创建多行。每一行都描述了一个独特的组合。所有行都存储在HDFS 文件中(在Apache Hadoop 中),用于并行分析(在大数据平台中)。
(3)过滤每个惟一文件的数据集(从步骤2 开始),并将相关的定量变量发送到相关文件。
(4)在每个文件上运行(通过bash 脚本)K-means算法(Apache Mahout),这些文件位于一个单独的目录中(步骤3),参数如下:
●迭代次数的可配置参数x(在本例中,我们对所有K-means 运行使用5 次迭代);
●集群的数量,K,这受到每个唯一文件的记录数量的影响(从步骤3 开始)。每个文件的数量增加的时候,在集群中,对应的k 的数量也会相应的增加。
(5)将所有集群收集到一个定义的结构中,以进行额外的分析(比较集群、顺序、分析等)。
4 端到端的程序实现案例研究
4.1 数据集
对于数据集的生成,本文生成了3 个数据集,分别对应的变量的数量为14 个、8 个、6 个。它包含1100万条记录,总共约为1.05GB。所有变量(分类变量和数值变量)的列表如下:
数量变量:年龄、工作年限、工资、受教育年限、房屋数量、子女数量、每年旅行次数、车辆数量。
表1 对给出了相应的可能性的数值。注意,这六个分类变量的组合最多可以创建1600 个不同的特征。
根据每个集群记录数的预定义,创建了5000 个集群。
4.2 过程流
图1 描述了端到端用例的端到端技术实现。主要内容有:
(1)HDFS 是一个分布式的文件系统。完整的数据集被上载到HDFS。然后,创建所有不同的组合,并从完整的数据中筛选相关字段。所有过滤器都存储在HDFS 中,用于分析过程。
(2)MapReduce ,这是主组件,它处理和管理所有并行处理在分析数据时完成(在实现示例中,我们使用Apache Mahout 作为 K-means 算法)。
(3)bi,这个组件是可能性的需求,包括了智能需求。显然,需求会随着组织的不同而变化,但是针对特定专业文件的需求在不同的业务中可能是相同的(在查询的目的中,可以通过查询值本身、数据、预期结果等来区分这些需求)。
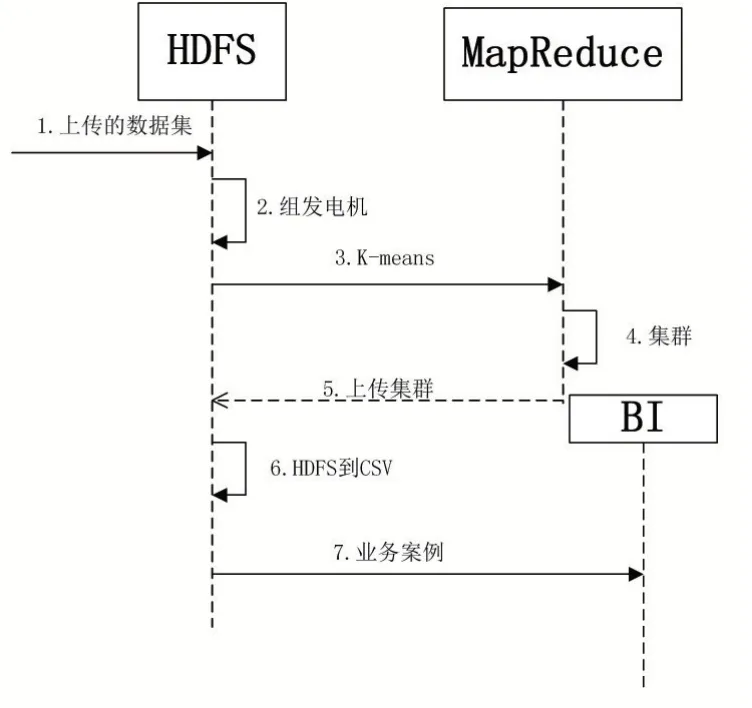
图1 用例的端到端技术实现图
4.3 运行标准
运行该过程后,集群被聚合到一个包含所有结果和时间戳的文件中。注意,不是房屋所有者、而是金融专家的记录,没有数值。总的来说,通过过滤过程,确定了40 个数值为空的组类型。在100 个目录的组中执行K-means 算法,其中预定义的集群数量。

表1 分类变量
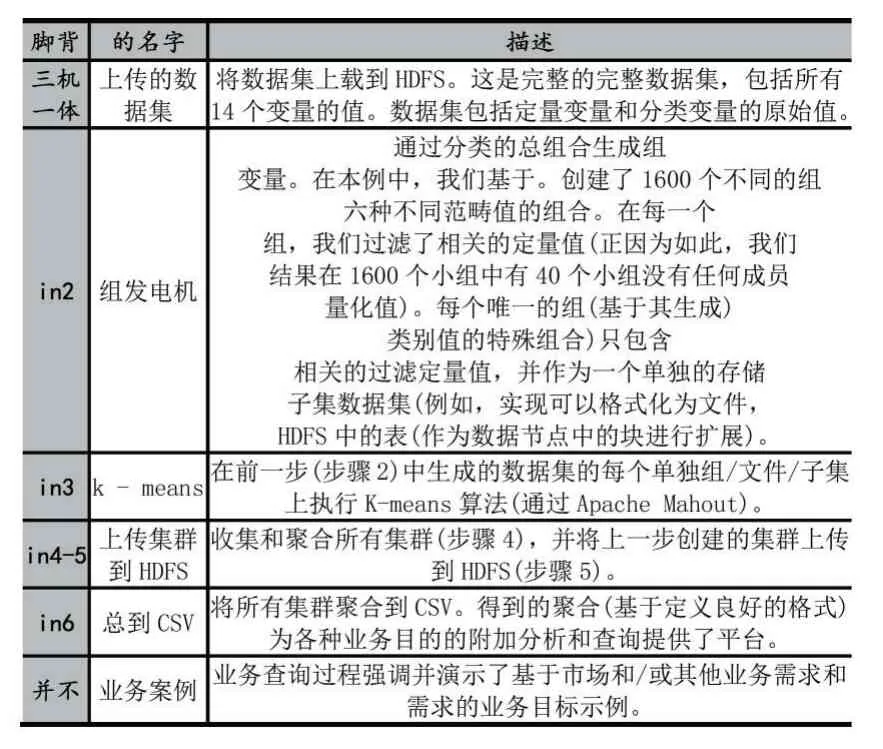
表2 过程步骤
根据每组/文件/子集数据集的重新排序次数选择,如表3 所示。每个K-means 过程的迭代次数为5 次。
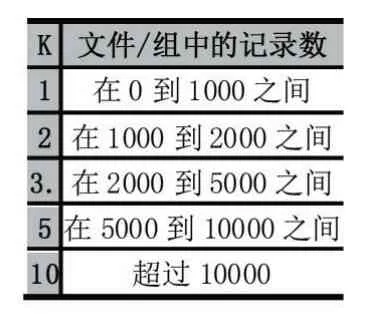
表3 根据预定义的集群数量记录数目
根据表3,K-means 算法总共创建了5940 个集群(对于1560 个有值的组,每组1 到10 个集群)。注意,识别40 个没有包含任何数量信息/值的概要文件是非常重要的,因为可能有不同的业务需求和需求需要对概要文件进行标识,而没有任何值或没有任何记录/观察。
4.4 BI用例
主要问题是:组织如何使用聚集成一个大型数据集的大量集群来进行决策?聚合的集群数据集包含独特的概要文件和组,形成了一个有价值的信息模式,可以针对特定的人群进行定位。
本节演示一个用于特定决策需求的用例示例。我们假设已经收集并创建了聚合的集群数据集,并且公司希望根据公司的目标和需求来检查投资于特定的概要文件细分是否有利可图。

表4 目标查询值
作为一个示例,我们从1560 个组生成的5940 个集群开始。5940 个集群总共包含1100 万个特定资源(其中每个资源都是一个特定的用户观察)。表4 显示了为定义目标人口的需求指定的值(在本例中)。
如表 5 所示,5940 个配置文件中只有 5 个(clus⁃ter)满足目标配置文件的要求。由于这种分析过程,公司只能关注这些概要文件中的用户。
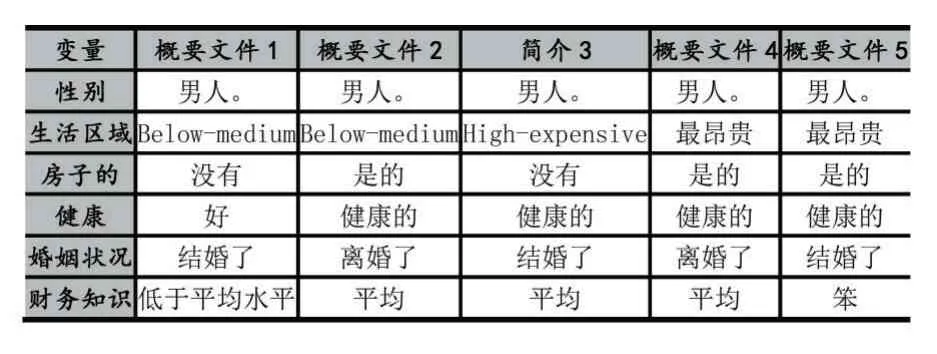
表5 业务查询目标概要文件
5 结语
在本文中,提出了一种新的方法,克服了在大数据环境下使用混合数据进行决策的困难。根据业务需求将概要文件聚类并缩小到目标组的能力改进了决策过程。在对K-means 算法的测试和实现中,发现该算法在实际运行中运行良好。然而,程序分析的复杂性必须在未来的研究中进行测试。过程的复杂性更有效率的复杂性相比,常规的K-means 算法运行在一个完整的数据集,因为它能够减少数据集的大小。该算法运行在子集,拥有更少的记录每组。这影响每个组的K-means 迭代的数量。此外,请注意,在大数据环境中,所有的K-means 计算都可以在不同的数据节点上并行进行。因此,复杂度主要受将生成的最大组。
需要注意的是,本文没有将大数据环境下混合数据的K-means 方法与混合数据的K-means 算法进行复杂度分析比较。然而,所提出的方法的复杂性更好。
(1)减少数据集大小:每组分析的观测值更少(由于过滤了相关数据;见第2 节和第3 节);
(2)分析流程并行化:大数据架构使我们能够并行执行分析流程(基于MapReduce 作业在HDFS 平台上分配的每个组/文件)。基于所有数据节点具有相同的容量和性能(在过程运行时)的假设,我们还可以假设最大的组(子集数据集)将具有最高的复杂性,因此将以最大的方式影响总体复杂性。然而,这一理论假设还有待验证。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
知识就是力量(2017年2期)2017-01-21
初中生世界·七年级(2017年2期)2017-01-20
小猕猴智力画刊(2016年6期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
小学教学参考(数学)(2006年7期)2006-12-31
