
软件生态系统的负熵流模型
2020-06-15 12:04韩雨泓祝鹏程
现代计算机 2020年13期
韩雨泓,祝鹏程
(1.四川大学计算机学院,成都 610000;2.中国人民解放军32620 部队,西宁 810000;3.中国人民解放军78100 部队,成都 610000)
0 引言
软件工程自20 世纪60 年代末诞生以来,有效解决了“软件危机”,推动了软件产业的持续快速发展。但随着软件复杂度不断提高,研究人员逐步认识到,传统软件工程中源于传统工业领域的工程化思维和基于还原论的研究方法,在复杂系统软件的研究中存在诸多局限,面临重大挑战[1]。近年来,受到开源软件的启发,越来越多的研究者把开源软件的成功,定性为软件生态系统的成功,转向对软件生态系统的反思与研究[2]。但目前国内外对软件生态系统还没有统一的定义,研究也主要集中于开源软件生态系统的技术报告,分析方法与框架、过程与技术、工具及表达等方面研究还比较少[3]。
本文分析了现有的软件生态系统分析方法与框架,对软件生态系统的负熵机制进行了研究,提出了“软件以输出负熵为使命”的观点,构建了一种基于软件负熵流的形式化分析模型——软件负熵流(Software Negative Entropy Flow,SNEF)模型,并对该模型进行了实证分析和可行性研究。
1 软件生态系统的研究现状
1.1 定义与元模型
软件生态系统(Software Ecosystem,SECO)最早由Messerchmitt 等人[4]于 2003 年提出,认为“软件生态系统是一系列具有一定程度共生关系的软件产品集合”,而后十多年内研究人员又从不同角度对软件生态系统的定义进行了丰富和创新。Manikas 等人[5]在2016 年对软件生态系统的定义进行了总结,认为“软件生态系统是在公共的技术基础上,软件产品与服务以及相关涉众相互作用形成的复杂系统”。2019 年,董瑞志等人[3]以Manikas 提出的定义为基础,对Tekinerdogan 等人[6]提出的元模型进行了丰富,形成了内涵和外延较为完整的软件生态系统元模型(图1)。
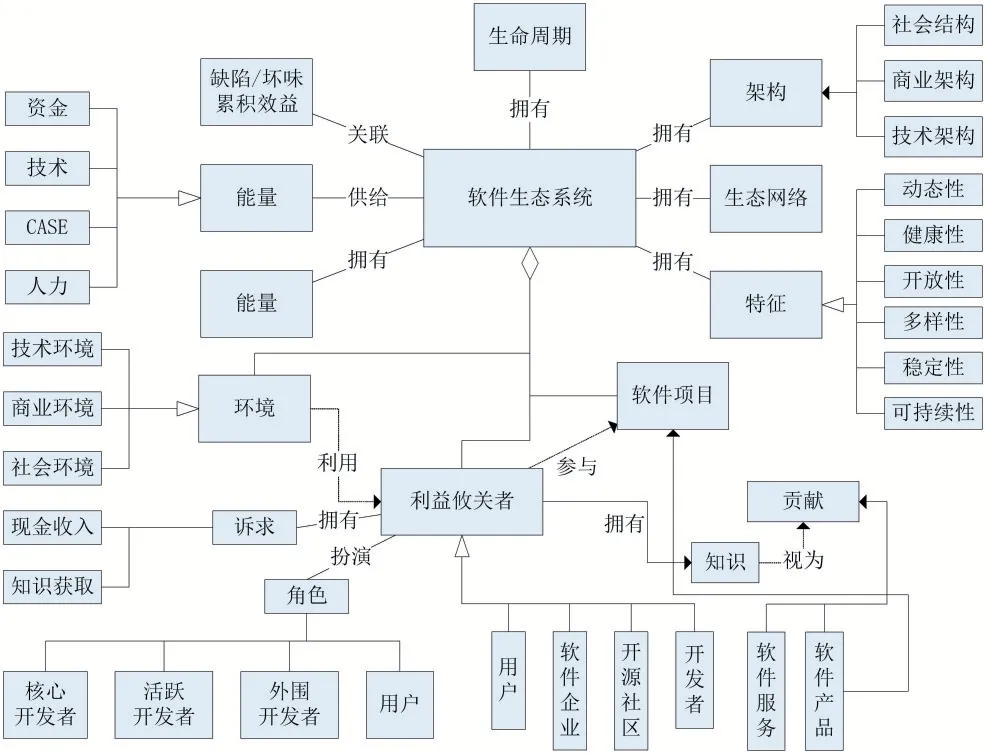
图1 软件生态系统的元模型
1.2 研究内容的划分
Messerchmitt 等人[4]认为软件生态系统的研究包括7 个方面:过程与技术、定性分析、实证研究、分析模型、工具与表达方法、行业应用、技术报告(包括术语探讨、领域综述、在研项目报告、短文、领域介绍,等等)。在此基础上,董瑞志等人[3]对相关文献进行了归纳,发现在实际研究中“定性分析”与“结构化分析模型”、“实证研究”与“行业应用”存在较大交叉,把“定性分析”与“结构化分析模型”合并为“分析方法及框架”,把“实证研究”与“行业应用”合并为“实证研究”,把软件生态系统的研究方向从七分类调整为五分类(即:分析方法及框架、实证研究、工具与表达方法、过程与技术、技术报告)。
从相关文献来看,目前的研究主要集中于针对开源软件生态系统的实证研究和技术报告,分析方法与框架、过程与技术、工具及表达等方面研究还比较少。
1.3 常见的形式化分析方法与框架
(1)SNA 模型
社会网络分析方法(Social Network Analysis,SNA)源于社会学,是一种建立在图论基础上,通过点和线集合实现的形式化方法,用点表示参与者、线表示相互关系。近年来随着大数据、数据可视化技术的发展,研究人员在一般社会网络(General Social Networks,GSNs)的基础上(图2),进一步丰富点、线的形式,赋予不同的信息,构成形式多样的图模型。通常用点的半径表达规模(市值、流量、产品数量),用点的颜色表示组团、组群、占股关系等,点的形状来区分角色和特征,用点位置来表达结构特征;用线的方向、虚实、粗细等,来表示依赖或竞争关系等[7]。
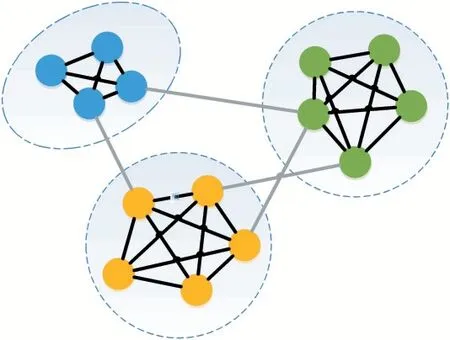
图2 一般社会网络(GSNs)
在软件生态系统的研究中,通常用SNA 模型来表示生态系统中参与者之间的关系,参与者包括:开发者[8]、公司[9]、API、技术平台或协议等(图 3)。
(2)SSN 模型
SSN(Software Supply Networks)模型是 Boucharas等人在2009 年提出的[10],是目前软件生态系统研究中使用最为广泛的模型之一。模型中的研究对象通常为IVS(独立软件厂商/公司)、SUP(软件产品或服务的供应商)、C(客户)3 种角色,以及部分非必要元素,如:客户的客户(Customer’s Customer)、贸易关系(Trade Rela⁃tionship)、网关(Gateway)等。
该模型通常区分为简单级、网络级、社区级3 个层次(图4):
(a)简单级。是软件生态系统的原始状态,各成员之间存在明确、简单的商业合作关系
(b)网络级。在这个层次中IVS 和SUP 的边界变得模糊,系统内各成员之间存在较为复杂的技术支撑关系,层次和职能存在较大交叉。
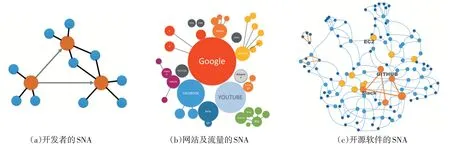
图3 软件生态系统研究中的几种典型SNA
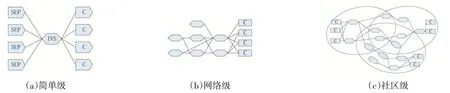
图4 SSN模型的三个层次
(c)社区级。由于基础技术、知识产权、协议标准等原因,在软件生态系统中形成了多个错综复杂的生态系统,往往需要先明确研究的边界和视角,以明确子系统的划分原则。
(3)知识链模型
研究人员认为[11],在软件生态系统中开发者、项目、用户通过知识建立联系。开发者基于基础知识,在技术合作网络的支撑下参与项目,将知识构建为实体化的软件产品,用户在使用软件的过程中形成新的需求、认识和观点,随着新知识的聚集和日益成熟再影响开发者,组成一个循环的闭环过程(图5)。与SSN 模型类似,知识链模型通常也区分为三个层次(图6)。
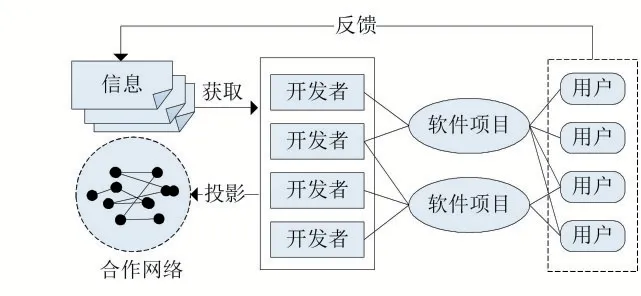
图5 知识链模型
2 软件生态系统的负熵流模型
2.1 软件生态系统的负熵机制
(1)热力学第二定律
1865 年,德国科学家克劳修斯(Clausius)提出了热力学第二定律,并将熵定义为“分子无序”的量度。玻尔兹曼和香农又分别在统计力学和信息论中引入“熵”的理论,形成了统计熵和信息熵的概念。爱因斯坦曾说:“熵理论对于整个自然科学来说是第一法则”。目前,热力学第二定律已经广泛的应用于化学、生物学、生态学、经济学、社会学等学科,并将熵作为无序程度或不确定程度的度量[12]。
(2)社会系统
人类社会以及组成人类社会的各类社会系统(包括国家、企业、群体、家庭等社会单元,以下均简称社会系统),具有如下特点:
①人类社会是复杂巨系统。从系统的角度来看,人类社会是一个复杂巨系统[13],由若干相互作用、相互依赖、相互制约的社会系统构成。
②社会系统都是开放系统。在人类社会中,没有哪个一个社会系统能够脱离其他系统、脱离社会环境单独存在,社会中不存在绝对意义的独立系统。所有社会系统都是开放系统,与外界存在物质、能量的交换,能够复制、传递信息。
③系统的熵增效应。熵是系统工程的核心概念,当系统内部各要素之间的协调发生障碍时,或者由于环境对系统的不可控输入达到一定程度时,系统就很难继续围绕目标进行控制,从而在功能上表现出某种程度的紊乱,表现出有序性减弱,无序性增加,系统的这种状态,称为系统的熵值增加效应[14]。社会系统都是非平衡态的开放系统[15],存续期间始终处于熵增趋势。
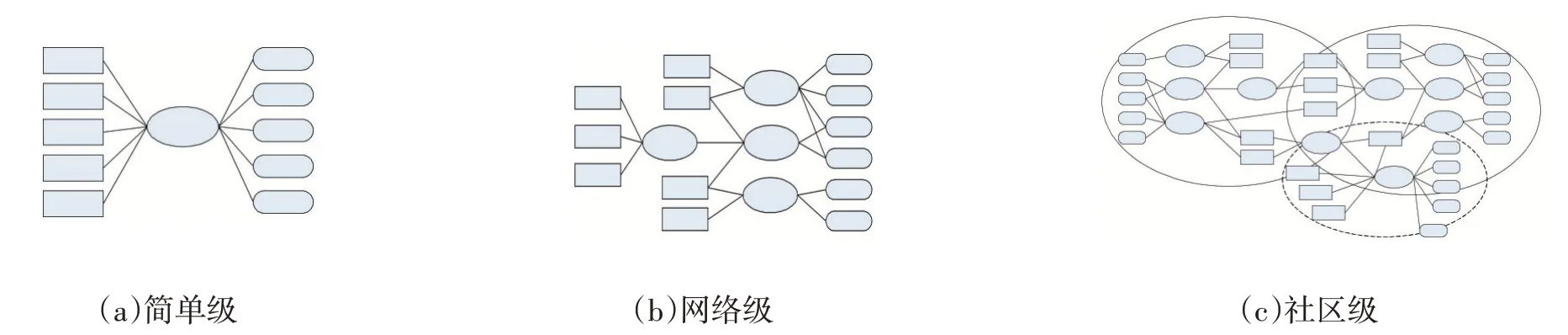
图6 知识链模型的三个层次
例如:城市的交通体系,如果没有持续投入人力物力财力予以治理,交通秩序将越来越糟糕,而随着其规模、参与成员、应用需求的不断扩张,治理的难度也就越大。
(3)软件的负熵
薛定谔在《生命是什么》一书中提出“负熵”概念,认为“生命需要通过不断抵消其生活中产生的正熵,使自己维持在一个稳定而低的熵水平上”“生命以负熵为生”,并将生命活力称为负熵。“负熵”同样也适用与社会系统,研究人员提出了“组织熵”的概念[16],认为每一个社会系统都需要从环境中获取负熵,维持运行、抵消熵增、保持低熵状态,熵的变化对社会系统的生存、发展有着重要影响[17]。
随着计算机和通信技术的飞速发展,信息化的理念已经深入人心,通过软件将知识固化为行业规则,通过软件对人、设备、设施、数据等系统内的资源实施有效管理,对组织结构进行优化,是目前社会系统引入“负熵”效率最高的形式。同时,引入软件系统通常还够引起社会系统按耗散结构理论[18]发生结构性变化。
2.2 负熵流模型
(1)研究对象
①社会系统(图7 中,用椭圆形表示)。是在特定领域或区域,具备一定关联关系或共同特征,短期内处于相对稳定的系统或群体,是组成人类社会的子系统。社会系统的大小可根据研究需要灵活划定,通常有2 种:
类型I,从对象范围来划分。可区分为国家、地区、城市、企业、项目组、家庭、个人等多个层次。
类型II,从社会职能来划分。如交通体系、物流体系、商业体系、教育体系以及城市道路交通体系、车辆停放体系(为了和类型I 作出区分,故使用“体系”命名)。
②软件生态子系统。是软件生态系统研究的基本单元,是以软件为中心,在不同社会人群中建立了相互联系的特定社会系统(图8),是一种是在公共技术的基础上,将能量(人力、物力、财力)以及特定的知识,转化为某个组织或行业“负熵”(秩序、效率、降低不确定性、降低风险等)的复杂系统。软件生态系统与自然生态系统一样,通常固定的层次和大小,视研究场景可大可小。
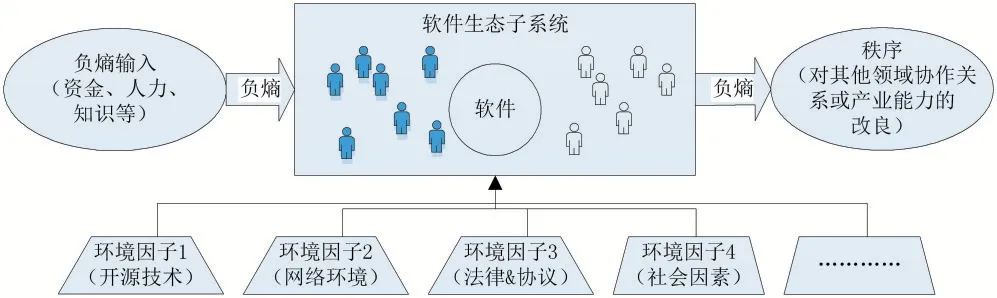
图7 软件生态负熵流模型的基本构成
例如:电商平台生态系统,包括:商品供应商、平台服务商、消费者;打车软件生态系统,包括司机、乘客、平台服务商;有些时候也包括广告商、赞助商。
又比如,在同一个公司内部不同层级的人员通过ERP 软件构成一个系统,其概念和范围与“该企业”大致相同,但又存在一些特例,如:公司内部没有与这个软件发生联系、或关联关系较弱能够忽略的人员(保洁、保安)可以不在该软件生态系统内,公司之外的个别人员又可能被划入软件生态系统,如软件外包商、服务商以及供应商、合作方、客户等。
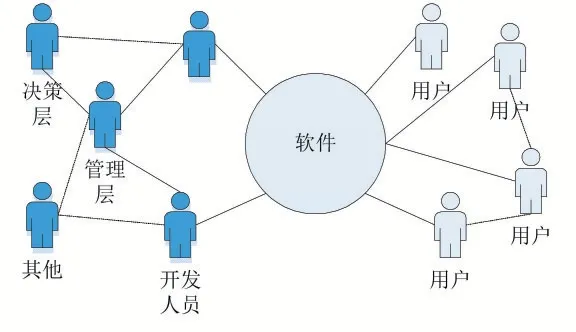
图8 某软件生态子系统的内部关系
(2)环境因子
类似于自然生态系统中的阳光、氧气、温度。可以不受制约使用,使用后不会衰减,使用成本较低可以忽略不计的因素,以及对软件生态系统发展的宏观制约因素,统称为环境因子(图7 中的梯形表示)。环境因子的变化,对生态系统内所有子系统都会产生影响。
①开源技术。能够直接获取、免费使用,且在实践中经过检验的,与软件开发有关的知识产品,包括:基础理论、开源软件、开发平台、模型、工具、算法、数据等。
②网络环境。软件开发、运行、维护所依托的网络系统,主要分为互联网和专用网络两个类别。对于大多数软件系统而言都是依托互联网运行,不需要自己建立和维护网络。但也有一些对网络安全性、实时性、稳定性等要求较高的领域,需自建网络的场景,网络环境的建设、维护成本以及不稳定性仍然是不可忽视因素。
③法律和协议。包括软件开发和运行过程中应当普遍遵循的商业规律、地区法律、软件协议等。
④社会因素。指社会对软件的接受能力和普遍态度,包括基本操作水平、认识水平、价值偏见等。
⑤其他。潜在的,可以对软件开发构成影响的因素。例如,“云计算”随技术的不断发展和普及,应用成本将不断下降,可靠性不断提升,将会与互联网一样成为软件生态系统中能够被普遍低成本使用的公共资源。这也解释了,互联网、云计算、开源软件等技术受到普遍关注,取得巨大成就的原因,可以说,这些技术都引起了环境因子变化,从底层改变整个软件生态系统,是推动整个软件生态系统发展的关键技术。
(3)负熵流
在自然生态系统的研究中,通常依托食物链或食物网模型,研究能量、营养的流动,分析生物之间的关系和生态系统的发展趋势。对软件生态系统而言,可以围绕“软件的负熵”来研究软件系统与环境之间、在软件系统之间的关系。为了简化软件生态系统模型,简化软件与软件、软件与环境之间的能流交换过程,将系统之间通过软件实施产生的熵差称为:软件负熵流(Software Negative Entropy Flow)。
生物需要从自然界不断的输入“负熵”,对抗自身的熵增,维持其生命活动。与之类似,软件生态子系统也必须从软件生态环境中持续的获得负熵,通常为软件开发、运行、维护必须的人力、物力、财力,以及特定的知识或知识产品、软件产品等。在环境因素的作用下,通过软件的开发、实施等工作,形成可以被目标社会系统接收的“负熵”,例如秩序、规则、管理效益等。软件产生的负熵具有如下特征:
①通常只对特定的目标系统有效,移植到其他领域需要再开发。
②软件负熵的载体以信息流和能量流为主,物质流通常可以忽略。
③软件输出的负熵与软件自身消耗的负熵,通常没有直接关系。软件生态子系统输入的负熵,主要用于维持该软件开发、运行所需,是抵消自身的熵增,通常与软件复杂度、用户规模、开发团队组织能力有关;软件输出的负熵,是针对目标系统而言的秩序或管理效益,主要取决于通过软件引入的知识量及知识的有效性。软件输出的效益相对于软件自身消耗的负熵而言,往往不在一个数量级,目标社会系统越大,输出和输入的负熵比越大,即收益越大。
2.3 负熵流关系
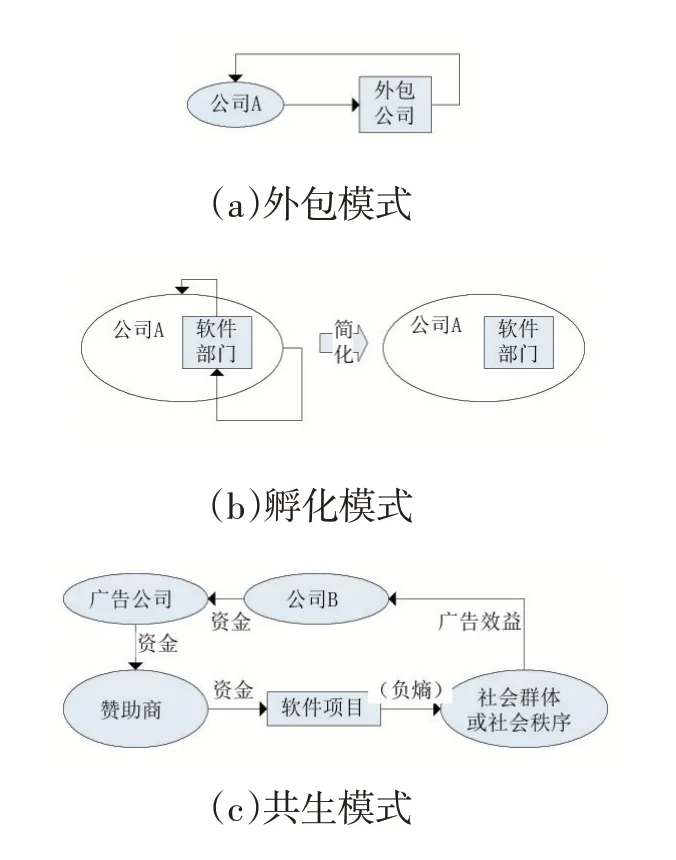
图9 常见的软件负熵流关系
常见的负熵流关系(图9)所示:
(1)外包模式。公司A 通过资金向外包公司输出负熵,外包公司通过软件产品再将负熵输出到公司A。
(2)孵化模式。公司A 内设软件部门,从公司A的整体收入划拨一部分资源输入软件部门,软件部门通过软件项目改良公司内部的运行秩序,提高公司A的效率。在后续的研究中,可以对这种模式进行简化,默认不需要再画出负熵的流动关系。
(3)共生模式。多主体的协作共生模式,通常为软件公司通过运作某个软件,对某些社会群体或某种社会秩序产生效益(输出负熵),再通过第三方得到收益。如:导航软件生态系统中最终受益的是整个社会的交通秩序,而使用群体带来流量形成广告效益(以及数据效益等),公司A 受益后通过广告公司向软件项目提供资金支持,形成负熵的循环。
3 分析
(1)分析之一:软件分包模式
在大型软件的开发中,组织者往往需要将项目整体外包或拆分外包,被外包的部分还可能再次被拆分外包,形成复杂的合作关系。图10 所示,A 公司将项目总包给B,B 又将部分内容外包给5 个分包公司,又向公司C 采购了软件产品供部门3 使用。
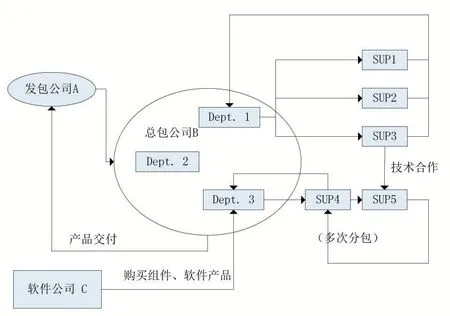
图10 大型软件项目的分包模型
(2)分析之二:开源软件社区模式
这是近年来新兴研究方向,在上一实例中(图10)各个公司之间主要还是传统的商业合作关系,关系较为明确、清楚,但在开源社区模式中相互关系就更为复杂。图11 中举例说明了某开源软件社区的运行情况,其中,A 公司将本公司所开发的项目B 开源,基金F 支持了项目C,生产商1、2 都从开源社区中获益,但生产商1 并未向开源社区做出贡献,生产商2 通过基金向对开源社区予以了支持。
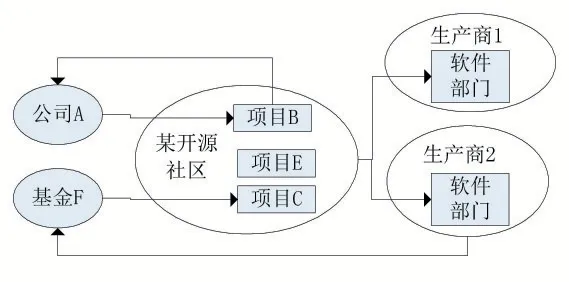
图11 开源软件社区模型
(3)可行性总结
通过以上两个实例的分析,相对现有的模型而言,软件负熵流模型具有如下特点:
①实现不同层次研究对象的统一。在以往的研究模型中,通常参照自然生态系统中的作法,区分为多个层次进行研究,既有宏观对象如开源社区的“大系统”,也有微观对象如软件项目、用户、赞助商等“小系统”,无法体现不同层次对象之间的关系。本模型将研究对象统一视为“非稳定态的开放系统”,为研究“小系统”对“大系统”关系提供了便利,更符合软件行业中“小系统”、个别企业、微观技术,影响或带动整个软件生态系统的独有特点。
②将复杂的交互关系,简化为单向流动关系。首先,实现了由复杂向单一的抽象,负熵流能够覆盖软件生态系统中形式多样的关联关系,例如:资金、股权、理论、产品、经验、人才、数据等,都可以看做为“负熵”。其次,实现了由交互到单向的抽象,系统之间通常存在复杂的物质、能量、信息交互,在本模型中,可以把那些能够量化关系进行抵消,形成单向的“负熵流”;也可以从研究视角出发定性的判断负熵流方向,将交互的关联关系简化为单向的负熵传输关系。
③实现了内外部效益的统一。在项目管理的研究中,研究人员从提出了软件熵、管理熵的概念,认为软件在开发和运行的过程中,随着软件复杂度、使用人群、累积数据、特殊情况的不断累积,以及软件团队人员的变动、知识换代,都将导致软件项目管理的熵增加[19]。本文将软件项目内部的熵增,与软件工程实施所需输入的负熵,以及软件实施之后输出“负熵”三者统一在一起,为同步研究软件项目管理、软件生态系统、软件实施效益等问题,提供了方法和工具。
4 结语
采用合适的软件生态系统模型,对于复杂系统软件的研究至关重要,选择、构建和改良的软件所处的生态环境,将成为未来软件实施成败的关键环节。本文总结了当前软件生态系统研究中常用的分析方法和工具模型,引入熵的概念对软件生态系统的负熵进行了研究,提出了新的研究模型。但由于研究水平和研究时间的限制,还有很多问题没有展开,特别是,需要从软件负熵的角度,对软件生态系统的耗散结构、平衡态、竞合关系、生命周期等问题进行研究,形成完整的研究框架。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小天使·三年级语数英综合(2022年4期)2022-04-28
体育师友(2022年1期)2022-04-17
英语文摘(2021年10期)2021-11-22
软件导刊(2021年1期)2021-02-05
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
软件和集成电路(2019年7期)2019-08-30
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
