
金融领域机器阅读理解模型
2020-06-15 12:04黄敏珍
现代计算机 2020年13期
黄敏珍
(广东工业大学,广州 510006)
0 引言
在人的日常生活中,几乎每个人都离不开金融。提到金融很多人会想到股票、基金、证券等,感觉这些离我们生活很遥远,其实不然,人们常用的银行、车贷、房贷、养老保险、市场物价等都离不开金融,它其实是市场的映射,与我们生活息息相关。对于机器阅读理解的数据集有很多,但用在金融领域的数据集不多,常用的机器阅读理解数据集有SQUAD[1]、SearchQA[2]、MS MARCO[3]、Dureader[4]。SQUAD 是文章段落类型数据集,问题和答案都是人工生成的,答案是文章中的一段,但部分答案未必在文章中出现;SearchQA 的问题和文章爬虫而得,答案是由程序而得,通常是一到两个词;MS MARCO 数据集相比前两者差异较大,问题和文章是搜索引擎收集的,答案是人工生成得;Dureader 是2017 年由百度团队发布规模最大的中文机器阅读理解数据集,其数据来源是百度搜索和百度知道,数据结构是一个问题对应多篇文章,且一个问题只含一个标准答案。而近年来抽取式的机器阅读理解模型成为主流,其主要代表模型有Seo 等人于2016 年提出的双向注意力流(Bidirectional Attention Flow,BiDAF)[5],Wang等人于2016 提出的一种结合M-LSTM 和PointerNet的模型Match-LSTM[6],Yu 等人于2018 年提出一种编码器仅由卷积和self-attention 组成的QANet 模型[7]。
本文在Match-LSTM 基础上提出一种多重注意力机制的端到端的抽取式机器阅读理解模型。首先对数据重构,增强问题与文章的关联,再对融合后的文档作自注意力机制(self-attention)加深问题与文章的关联,突出文章中与问题关联较深的特征,然后联合多篇文章再作self-attention 突出文章语义特征与文章间的关联性,我把这种联合了多篇文章的注意力机制称为mul-attention。整个模型在相同数据集下与BiDAF、Match-LSTM、QANet 作对比,并分析了本文模型对问题类型的影响。
1 相关工作
1.1 Match-LSTM
Match-LSTM 是一种结合 M-LSTM 和 PointerNet的模型(Machine Comprehension Using Match-LSTM and Answer Pointer,Match-LSTM)。它主要在匹配层采用M-LSTM,计算文章中每个词关于问题的注意力分布向量,再将注意力分布向量与问题编码向量作点乘,计算文章中每个词对问题的关联,最后用同样的方法倒序再运行一遍,结合这两次运算得到文章向量的新表示形式。然后作答层采用PointerNet,即该文在答案预测上提出了两种模式,第一种是认为答案不是连续的,答案可从文章各处零碎拼接而成,第二种是认为答案是连续的,只需预测答案在文章中的始末位置就可预测出答案,该文实验证明答案预测始末位置相比从文章各处拼接效率和准确率更高,但这种方法对于长度较长的答案预测效果有待提高。整个Match-LSTM更适合实体类问题的解答。
1.2 self-attention
self-attention 即自注意力机制,是由注意力机制[8]演变而来,模拟人类大脑的关注能力,把特征关键点放大增强。self-attention 自身既是观察者也是被观察者,被观察者被看做是固定的序列,观察者中的每一个元素与被观察者作点积,再将每个元素求得的值加权求和,得到一个两者间的注意力分布,这个分布在原始的attention 中看作两者间的相似度,对于self-attention 就相当于自身特征的增强。在自然语言处理的领域中,self-attention 首先是由 Bahdanau 等人[9]于 2014 年提出用于机器翻译上,后来发现在自然语言处理的其他领域也有不错的效果,渐渐地被应用到机器阅读理解上,许多实验[10-12]都发现它在机器阅读理解有增强文章的语义,使其附带上下文的语义信息的作用。
2 数据
本模型的数据从百度搜索和百度知道而得,包含经济、股票、汇兑、价格、储蓄、贷款等多方面的信息统称为金融领域。一共有1 万个问题,每个问题对应一个标准答案,5 篇文章,文章一般是篇幅较大得解答,答案选自一个精确简短的解答,答案未必一字不漏的出现在文章中,但文章中部分片段包含与答案相似的含义,其中把6000 个问题用于训练,2000 个用于测试,2000 个用于验证。在训练集中有2010 个描述类问题,3244 个实体类问题,746 个是非类问题,其中训练集中有1604 个事实类问题,4396 观点类问题,具体数据类型分布如图1。
3 模型
模型主要分成4 个模块:数据重构模块、融合后文章self-attention 模块、多篇文章mul-attention 模块、作答模块。其中作答模块与Match-LSTM 相同。
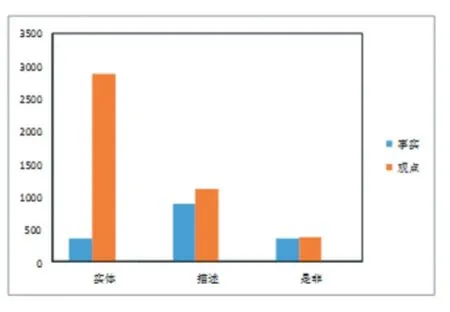
图1 数据类型分布
3.1 数据重构模块
由于网上的文章参差不齐,数据量繁多,因此需要在有限的长度内截取有用的信息,本模块根据文章与问题或者答案的相关性做排序提取有用信息。数据采用jieba 分词,用Word2Vec[13]从1.3G 的中文维基百科语料训练获取文字的词向量,词向量的维度m 为150。其中多个问题记为 Q={q1,q2,…,qn},n 为问题个数,多个答案记为A={a1,a2,…,an},问题q1对应的文章记为P1={p1,p2,p3,p4,p5}。文章p1对应的句子记为为p1 的句子总数。在训练时,根据式(1)算出文章p中的句子s 与答案a 的相关度并根据相关度从大到小的顺序对文章重新排列。测试和预测时,根据式(2)算出文章p 中的句子s 与问题q 的相关度并根据相关度从大到小的顺序对文章重新排列。以上排序后均只截取文章前max_p 个词,问题只截取前max_q 个词,答案只截取前max_a 个词。重构的数据作为下一层的输入。
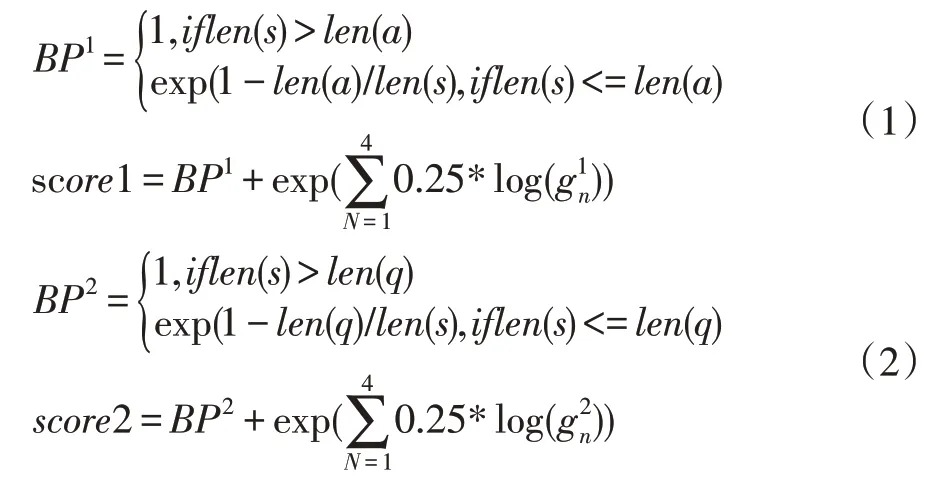
3.2 融合后文章self-attention模块
匹配模块分为两个部分:Match-LSTM 匹配融合和self-attention。
(1)Match-LSTM 匹配融合
这一部分实质是让文章携带问题信息,把问题看作前提,文章为假设。首先用单向LSTM 编码问题和文章,如式(3):

再计算文章上问题的注意力分布,并softmax 归一化,式(4):
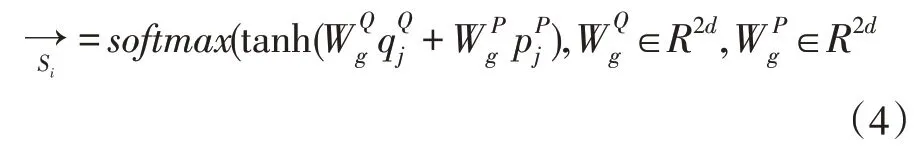

(2)self-attention
在融合的前提作self-attention 加深问题与文章的关联,突出文章中与问题关联较深的特征,融合后的文章看作两个序列,一个看作一个固定的key-value 序列,另一个看作有移动序列,移动序列中的每一个词都会遍历一次key-value。由上一部分得到融合后文章,首先将固定序列每一个key 与移动序列每个元素作点积,计算融合后文章本身的注意力分布,然后用Soft⁃max 归一化,如式(6),最后加权、拼接,如式(7),得 PS=
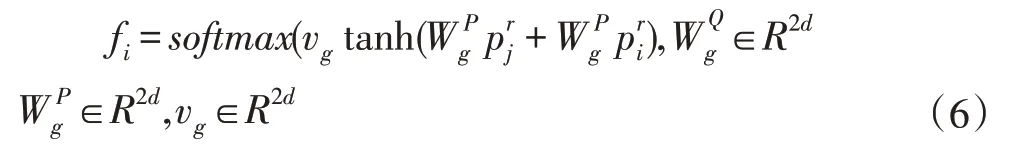
其中d 为隐藏层维数。
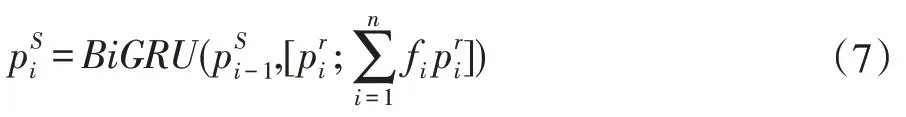
3.3 mul-attention模块
这一模块把同一个问题对应的所有文章拼接在一起看作一个整体,对这个整体作self-attention,由4.2模块得第i 个问题self-attention 后的文章为内含5 篇文章,即则一个问题对应的文章这个整体表示为其根据式(8-9)作自注意力机制。
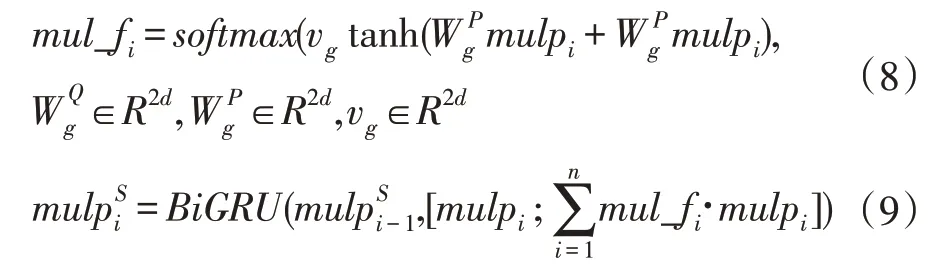
4 实验
4.1 实验设置
本实验从百度搜索和百度知道获取的金融类型数据,一共1 万条数据,6000 条用于训练,2000 条用于测试,2000 条用于验证,一条数据包含一个问题、一个标准答案、5 篇文章,词向量维度为150。文章截取的最大长度max_p 为400,问题截取的最大长度max_q 为60,batch 的大小为16,答案截取的最大长度max_a 为200,隐藏层的维度d 为64,实验的迭代次数epoch 为10 次,模型构建采用 TensorFlow1.2.0,Python3.5,采用Adam 优化模型参数,学习率为0.0001。实验运行硬件条件为E5-2660 10 核、16G 内存。训练时间为7 小时17 分钟。
4.2 实验结果
本次实验评价指标为Rouge-L 和BLEU-4,首先以 BiDAF、Match-LSTM、QANet 为对比模型,对比在相同数据集下模型的性能,如表1 所示,Match-LSTM 与BiDAF 性能相近,QANet 与其他模型差距较大,本实验模型相比其他模型Rouge-L 至少提升2.72,BLEU-4至少提升了7.08。
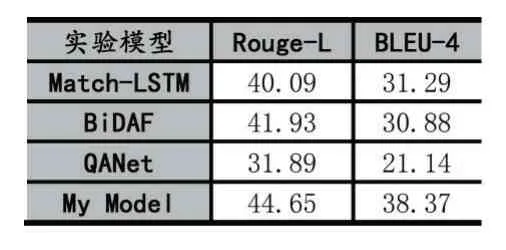
表1 不同模型验证结果
接着以Match-LSTM 为基线,增量式对比数据重构、融合后文章self-attention、mul-attention 对整个模型的影响,实验结果如表2 所示。由表所示数据重构后整体性能涨幅明显Rouge-L 提升了4.2,BLEU-4 提升了5.52。融合后文章self-attention 与mul-attention对模型的提升接近,前者Rouge-L 和BLEU-4 分别提升了 0.26、0.94,后者 Rouge-L 和 BLEU-4 分别提升了0.1、0.62。
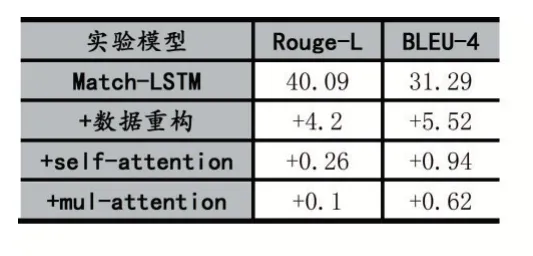
表2 增量式验证结果
最后从问题类型的角度观察模型,统计在本文数据集中实体类型、描述类型、是非类型问题在本文模型的效果,然后以Match-LSTM 为基线,针对问题类型增量式对比数据重构、融合后文章self-attention、mul-at⁃tention 对整个模型的影响,实验结果如表3 所示。其中数据重构对每一类问题都有一定程度实验效果的提升,self-attention 对是非类问题类型提升效果更高,mul-attention 对实体类问题类型实验效果提升更高。综合而言整个模型对实体类和描述类问题类型实验效果的提升接近,对是非类问题类型的提升相对较小。
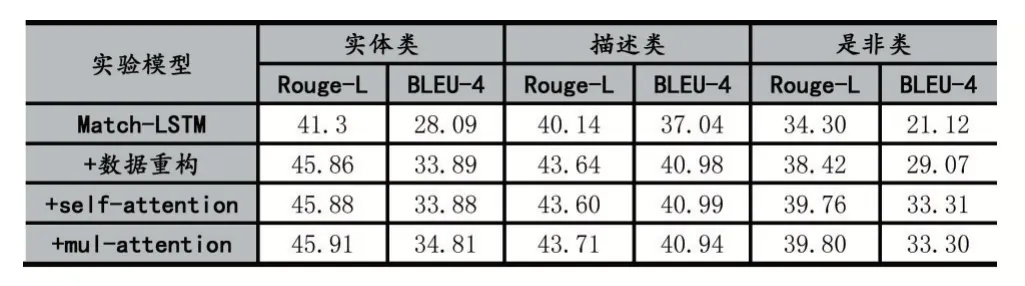
表3 不同问题类型下增量式验证结果
5 结语
本文在Match-LSTM 基础上提出一种多重注意力机制的端到端的抽取式机器阅读理解模型。首先提出了一种数据重构的方法,使得重构后的文章对问题更具有关联性,大幅度的提高模型的训练效果,然后对融合后的文档作自注意力机制(self-attention)加深问题与文章的关联,突出文章中与问题关联较深的特征,最后联合多篇文章再作self-attention 突出文章语义特征与文章间的关联性。最终验证结果达到Rouge-L 和BLEU-4 分别为44.65、38.37。其次本文还针对问题类型对本模型作出数据分析,实验表明模型对每一个问题类型实验效果都有提升,实体类和描述类问题的提升相对较高。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
当代陕西(2022年4期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
天津诗人(2017年2期)2017-11-29
第二课堂(课外活动版)(2016年2期)2016-10-21
中学生数理化·高一版(2016年6期)2016-05-14
中学英语之友·高一版(2008年10期)2008-12-11
