
改进的Kohonen网络在航空发动机分类故障诊断中的应用
2020-06-13 06:18郑波,马昕
航空发动机 2020年2期
郑 波,马 昕
(中国民用航空飞行学院教务处1,空中交通管理学院2:四川广汉618307)
0 引言
航空发动机长期在高温、高压、强振动等恶劣工作环境下,受到腐蚀、磨损、疲劳、积污等侵害,不可避免地发生性能衰退、振动加剧、磨损严重等故障征兆[1]。开展航空发动机故障诊断研究对提高排故效率、缩短维修周期、降低维护成本、保障飞行安全具有重要意义。自20世纪60年代以来,航空发动机生产厂商和用户对发动机的故障监测、诊断方法进行了大量研究,逐渐形成了基于发动机气路性能监控、滑油系统监控、振动监控和无损检测的发动机故障诊断技术,使得航空发动机的维修保障水平得到显著提高。美国联合西方国家开发的联合攻击战斗机(Joint Strike Fighter,JSF)项目,通过状态监控与健康管理技术,使得JSF与F-16战斗机相比,在人力费用方面降低约30%,设备保障费用方面降低约50%,而架次生成率却提高了约25%[2]。国内自80年代开始逐渐开展航空发动机的故障诊断技术研究,有效提升了中国航空发动机的维修保障水平。1988年,北京飞机维修工程公司等4家单位联合开发了发动机监控和诊断(Engine Monitoring and Diagnosis,EMD)系统,实现了航空发动机的趋势预测和故障诊断的功能[3];国内学者在总结航空燃气涡轮发动机故障诊断中的各类数学模型方法的基础上,出版了航空燃气涡轮发动机故障诊断理论专著《航空发动机故障诊断导论》[4],提高了中国航空发动机故障诊断的理论水平。
随着传感器技术的快速发展,基于数据驱动的故障诊断技术得到了广泛应用。传统Kohonen(Traditional Kohonen,T-Kohonen)网络作为基于数据驱动的智能数据处理方法,在样本分类、模式识别中有广泛应用[5]。范作民、白杰等利用Kohonen网络的自组织特效,提取航空发动机的运行特征,进而识别航空发动机的运行状态[6]。基于Kohonen网络的数据聚类特性,Kohonen网络在航空发动机滑油系统健康状态评估中得到了广泛应用[7],同时也被广泛地应用于电力[8]、机械[9]、网络[10]等其他工业系统的故障诊断中。T-Kohonen网络采用无导师竞争学习策略调整权值,使不同的神经元对不同的输入类别敏感,从而特定的神经元在分类诊断中可以充当某一输入类别的判别器。研究表明:针对大样本数据聚类问题,存在聚类结果不惟一性和不可辨识性的问题,限制了T-Kohonen网络的应用效果。
本文提出1种带监督策略的改进的Kohonen(Improved Kohonen,I-Kohonen)网络,该网络利用混合粒子群优化(Hybrid Particle Swarm Optimization,H-PSO)算法优化网络初始权值,克服T-Kohonen网络存在的缺陷,以确保识别结果的惟一性和可辨识性。
1 T-Kohonen网络
1.1 T-Kohonen网络学习算法
T-Kohonen网络的拓扑结构如图1所示。输入层神经元为1维阵列,神经元数等于输入向量的维数m,竞争层神经元按2维阵列形式排列,取神经元数为n,输入层和输出层神经元之间由可变权值ω1ij(i=1,2,…,m;j=1,2,…,n)连接。
T-Kohonen网络采用基于winner-take-all规则的竞争学习策略[11],具体学习过程如下:
(1)网络初始化。随机设定m×n维权值ω1的初始值,设定领域范围 R∈(rmin,rmax),学习效率 η∈(ηmin,ηmax)以及网络学习次数gmax的初始值。
(2)计算并确定获胜神经元。第t次学习的输入样本 x(t)=(x1,x2,…,xm)与竞争层神经元 j之间的距离为欧式距离。把与输入样本x距离最小的竞争层神经元c(t)作为t次学习获胜神经元,并令P为神经元的位置,其中Pc(t)为获胜神经元c在第t次学习时的位置,Pk为神经元k的位置。
(3)产生优胜领域。以获胜神经元c(t)为中心的优胜领域为

式中:k=1,2,…,n;函数 norm(·)用于计算 2 神经元间的欧氏距离;函数find(·)用于确定符合要求的神经元;按下式自适应更新R和η

(4)更新神经元c(t)及其优胜领域Nc(t)(k)的权值

(5)若 t+1<gmax,则返回步骤(2),否则结束学习过程。
1.2 T-Kohonen网络存在的问题
通过研究文献[12]中的大样本数据聚类问题,发现T-Kohonen网络存在聚类结果不惟一性和不可辨识性问题。文献[12]中的网络入侵数据见表1,因入侵数据有38维,则输入神经元数为38,入侵数据来自5个类别,竞争层神经元往往要大于实际类别数,这是为了避免竞争所产生的死神经元对聚类的影响[13],故竞争层采用6×6的2维阵列。

图1 T-Kohonen网络拓扑结构

表1 网络入侵数据[12]
1.2.1 未知样本识别的不可辨识性
对于一些分属不同类别,但差异性较小的训练数据,可能会出现映射同一神经元的情况,导致未知样本识别时的不可辨识性。对4000组训练数据聚类后的获胜神经元分布如图2所示。
对于位置为(1,1)的神经元而言,映射该神经元的是100个类别为2的数据。但注意位置为(3,3)、(4,4)、(6,4)、(6,5)的神经元,2 种类别的数据被映射到同一神经元。在未知样 本 被 划 分 到(3,3)、(6,5)这 2个神经元时,其为小数据类别的概率分别只有8.3%、4.6%,这一概率相对较小,可将未知样本判入大数据类别;在未知样本被划分到(4,4)、(6,4)这 2 个神经元时,其为小数据类别的概率分布是10.2%、38.4%,这一概率相对较大,则不宜再判入大数据类别。这就造成了对未知样本识别时的不可辨识性。

图2 获胜神经元分布
1.2.2 分类结果的不惟一性
网络连接权值随机设定,导致在划分未知样本类别时,用不同初始权值可能得到不同分类结果,使得分类结果具有随机性,不利于工程应用。如分别利用T-Kohonen网络对文献[12]中的数据进行5次识别试验,就能得出5个不同的准确率数据,这正是由于初始权值随机设定而造成的。
针对T-Kohonen网络存在的2大问题,本文提出基于监督的 Kohonen(Supervised Kohonen,SKohonen)网络,使最终输出结果为确定的类别,同时,利用H-PSO算法对初始权值进行优化,并将交叉验证(Cross Validation,CV)产生的分类精度的平均值作为适应度值,既能保证获得分类的准确率最高,又能保证分类的结果惟一。
2 S-Kohonen网络
2.1 S-Kohonen网络算法
S-Kohonen网络拓扑结构如图3所示。通过在竞争层后加入输出层,将无导师的学习策略变为有导师监督的网络,输出层神经元数与数据类别数相同,设为l,当表征某一类别时,令该类对应的神经元为1,其余神经元全为0。输出层和竞争层通过n·l维权值矩阵ω2连接。

图3 S-Kohonen网络拓扑结构
权值调整时,在调整输入层和竞争层优胜领域内神经元权值的同时,还要调整竞争层优胜领域内神经元与输出层之间的权值

式中:j=1,2,…,n;s=1,2,…,l;η1(t)为学习效率;YL为训练样本所属类别标签向量。
从输入层到竞争层,为使同类神经元逐渐集中,学习效率η随学习次数逐渐减小,但从竞争层到输出层,为使代表数据类别的输出层神经元获得较大的权重值,从而清晰地表征未知样本类别,学习效率η1随学习次数逐渐增大,其自适应更新为

对测试样本ttest的识别通过如下2步实现:
(1)令Ptk为与ttest欧氏距离最短的第k个神经元在分布图中的位置,则Ptk为

T-Kohonen网络正是通过位置为Ptk的神经元所代表的训练数据类别来表征ttest的所属类别。
(2)ttest的类别标签为

式(7)表明权值矩阵ω2的Ptk行最大值元素所对应的列位置lo就是测试样本ttest惟一的类别标签输出。因用YL-ω2js(t)来更新ω2js(t+1),则ω2的初始值应设为n·l维0值矩阵,使得在同一标准下权值逐渐累加,实现判别ttest类别的效果。
S-Kohonen网络由于网络连接权值ω1和ω2都是随机设定的,利用文献[12]中的4000组训练数据训练网络,并分别利用4000组训练数据和500组测试数据检验网络的分类能力,共进行5次试验,结果见表2。虽然S-Kohonen网络很好地解决了对未知样本识别时的不可分辨性,但表2也直观地反映了其分类结果不惟一性的问题依然存在。
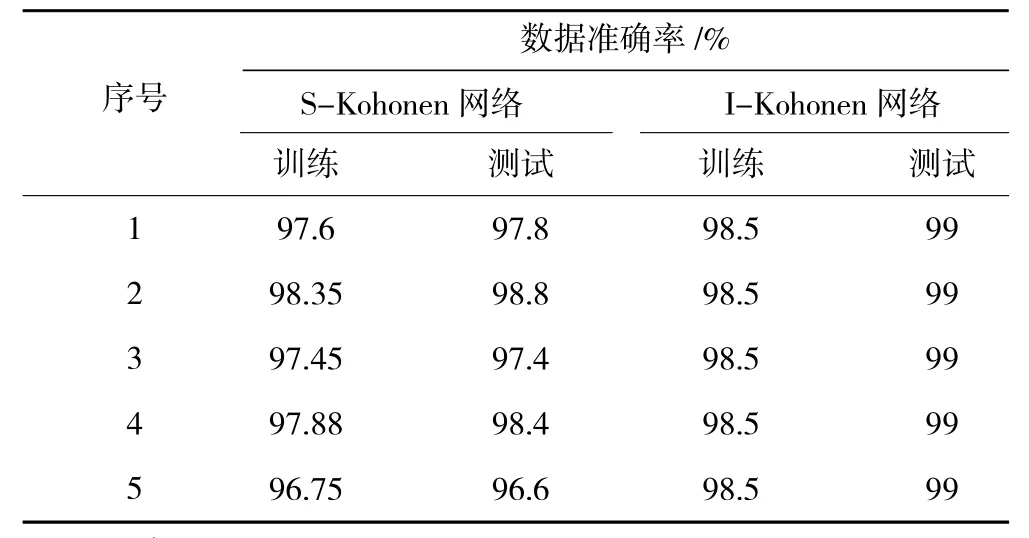
表2 分类准确率结果比较
2.2H-PSO算法
普通PSO(General Particle Swarm Optimization,G-PSO)算法见文献[14],本文提出H-PSO算法采用基于最优个体策略的粒子自适应继承方式(Adaptive Inheritance Mode Based on the Best Individuals Strategy,AIM)策略来拓展整个解空间,同时引入自适应检测响应机制(Adaptive Detecting Response Mechanism,ADRM)引导粒子群跳出局部最优空间,确保获得全局最优解。
2.2.1 AIM策略
每个粒子代表1个潜在解,因对连接权值寻优,则单个粒子可表示为 pi=(p1,…,pm·n),设群体极值为pg,通过随机设定继承系数 s1、s2,其中 1≤s1<s2≤m·n,将群体极值 pg=(pg1,…,pgm×n)的 s1~s2位间的值复制到粒子pi的s1~s2位间,通过继承产生1个保留群体极值信息的新粒子pinew。
对pinew是否具有进化下去的价值,则采用优秀个体策略判断,判断方式为:若fitness(pi)<fitnetss(pinew),则继承有效,用pinew替换pi,否则继承无效,放弃pinew,其中fitness(·)为适应度函数,用于表征PSO算法的寻优效果。
2.2.2 ADRM策略
ADRM策略的原理为:每间隔α代进化作1次适应度值检测,若当前进化到第α+i代,则检测适应度值 fitnessα+i(pg)<fitness(pg)的变化是否超过规定阈值e。若超过,表明粒子群还在继续搜索最优解;若没超过,则可能陷入局部最优解,算法保存当前最优解,并触发响应:随机更新粒子群中一定比例粒子(本文选取50%的粒子更新)的s3~s4位间的值,s3和s4也是随机设定的,其中 1≤s3<s4≤m·n,使部分粒子自动跳出该搜索区域,转入其他区域继续搜索。以后每隔α代继续检查,根据检查结果作出是否响应的判断,直到满足终止条件。
2.2.3 适应度函数的确定
文献[15]将 k-CV(k-Cross Validation)的交叉验证精度作为适应度函数值,其具体算法为:将原始数据随机分成k组,将每组数据分别作1次测试数据,相应的(k-1)组数据作为训练数据,则可得k个分类准确率,将k个分类准确率的平均值作为适应度值。本文同样采用基于k-CV算法的适应度函数来计算粒子Pi的适应度值,以保障样本训练时的分类准确率。
利用I-Kohonen网络对文献[12]中的数据进行处理(表2),通过对比可得:
(1)I-Kohonen网络不仅避免了对未知样本识别时的不可辨识性,还增强了Kohonen网络在实际应用中的通用性和容错能力。
(2)AIM策略能保证群体极值信息被保留,并拓展了粒子搜索能力,确保对整个解空间的搜索。
(3)ADRM策略确保在长期进化过程中引导粒子主动跳出局部最优空间,避免了因连接权值随机设定而导致的分类结果不惟一性问题,同时只随机更改部分粒子s3~s4位间的值,保证了对粒子群“社会信息”的良好继承,使得转入其他区域搜索时,避免重复搜索,加快了收敛速度。

图4 GE90发动机4种损伤
3 航空发动机损伤数据分类
利用孔探图像可识别航空发动机内部因过热、振动、磨损、侵蚀、撞击等形成的裂纹、撕裂、腐蚀、卷边、烧伤、凹槽等各类损伤,这些损伤往往发生在发动机特定部件上,直接威胁发动机运行安全。利用基于内容的图像检索(Content-Based Image Retrieval,CBIR)技术从颜色、纹理、形状等提取图像特征,建立图像数据知识库,有利于对未知图像特征进行识别[16]。
文献[17]利用孔探GE90发动机获得关于叶尖卷边、腐蚀、裂纹和撕裂4类损伤的图像,如图4所示。提取4张图像的10个纹理特征分别建立4类损伤图像数据库,共112组数据(见表3),其中特征f1为角2阶矩均值,f2为角2阶矩方差,f3为对比度均值,f4为对比度方差,f5为相关性均值,f6为相关性方差,f7为方差均值,f8为方差方差,f9为逆差矩均值,f10为逆差矩方差,D为损伤类型,1为叶尖卷边,2为裂纹,3为撕裂,4为腐蚀。
为便于与文献[17]进行比较,将第1~42号数据作为训练数据,第43~84号数据作为测试数据1,第85~112号数据作为测试数据2,分别验证网络的分类能力。
设I-Kohonen网络的最大学习次数gmax为1000,优胜领域范围R∈(0.4,1.5),学习效率η∈(0.01,0.1),η1∈(0.1,1),输入层神经元数 m=10,因类别数为4,采用6×6的竞争层分布,竞争层神经元数n=36,输出层神经元数l=4。

表3 GE90发动机孔探图像特征数据
3.1 验证H-PSO算法寻优效果
H-PSO算法采用非线性惯性权重

式中:ωs为初始值;ωe为最终值;Tmax为最大进化代数;t为当前进化代数。
设粒子种群数量为 50,Tmax=200,k-CV 为 10,响应 阈 值 e=10-3,ωs=0.9,ωe=0.4, 加 速 因 子 c1=1.2,c2=1.7。为验证H-PSO算法较G-PSO算法在寻优方面的优势,分别对I-Kohonen网络寻优5次,得到5组共10个10×36维的最优连接权值ω1,具体数值见表4。
第1组2种寻优算法的最佳适应度值和平均适应度值比较如图5所示。从图中可见,H-PSO算法的最佳适应度值在进化到127代时再次发生改变,达到最大值82.91%,而G-PSO算法在第33代时达到81.57%,最终适应度值再无变化。验证了H-PSO算法具备尽可能地搜索整个解空间,且可自适应跳出局部最优空间的特性。
利用H-PSO和G-PSO优化的分类结果比较见表4。从表中5组最优连接权值训练I-Kohonen网络后所得分类准确率比较可见,H-PSO算法能够获得全局最优解,使I-Kohonen网络分类准确率最高,且确保分类结果具有惟一性。

图5 适应度值变化的比较
3.2 验证I-Kohonen网络性能
为验证I-Kohonen网络的性能,分别从分类准确率和时间开销2方面对网络性能进行评价,并与T-Kohonen 网络、LVQ 网络[18]、BP 网络[19]、SVM[20]进行比较,同样为了验证分类结果的惟一性,任意选择每个网络的3组试验数据,分类结果比较见表5。其中在试验基础上,确定LVQ网络采用10×36的网络结构。BP网络采用10×36×4的网络结构,训练目标为0.001,网络权值随机确定。且各网络迭代次数均为1000次。SVM采用高斯核函数,并利用遗传算法对惩罚因子和核函数参数进行优化。
从表中可见,因有H-PSO对连接权值寻优,I-Kohonen网络分类准确率最高,同时时间开销也要高于T-Kohonen、BP、SVM的。而T-Kohonen依然存在不可辨识性。LVQ网络同样作为有导师监督的竞争型网络,时间开销最大,这与其学习过程中权值更新方式有关,同时也反映出I-Kohonen网络结构在学习过程中的简洁高效。BP网络采用梯度下降的误差反传算法更新权值,收敛速度快,由于对数据进行非线性映射,对相关性大的样本识别率较差[21],导致其分类准确性最差。SVM对测试样本1的分类准确率较差,这与遗传算法对其参数寻优的效果有关系。除了I-Kohonen网络,其他算法都存在分类结果不惟一性的问题。
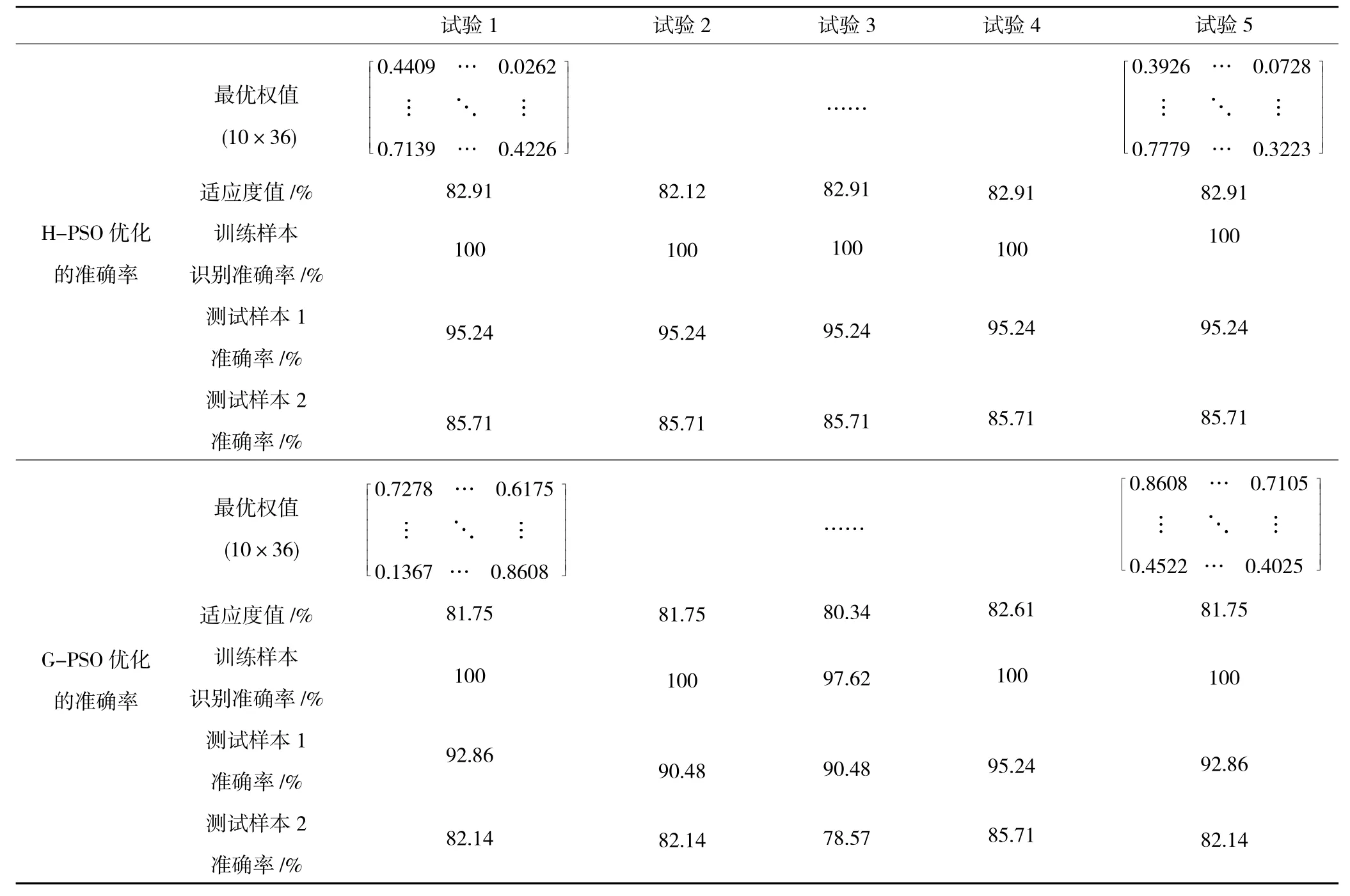
表4 利用H-PSO和G-PSO优化的分类结果比较

表5 基于不同算法的分类结果比较
4 结论
(1)本文在结构上对T-Kohonen网络进行改进,通过在竞争层后加入输出层,将无导师的学习策略变为有导师监督的网络,有效避免了不可辨识性问题,同时网络结构简洁,学习过程较快,增强了Kohonen网络在分类故障诊断中的通用性和容错能力。
(2)本文提出基于AIM和ADRM策略的H-PSO算法,拓展了粒子搜索整个解空间的能力,同时能自适应地引导粒子跳出局部最优空间,确保获得全局最优解。
(3)利用H-PSO算法优化Kohonen网络的连接权值,有效避免了T-Kohonen网络因连接权值初始值随机设定而导致的分类结果不惟一性的问题,并确保获得最高分类准确率,使得I-Kohonen网络能够满足工程需求。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
成都信息工程大学学报(2022年3期)2022-07-21
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
当代旅游(2016年10期)2017-04-17
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
财经理论与实践(2015年2期)2015-04-16
微型计算机(2009年4期)2009-12-23
