
基于聚类混合采样的不平衡数据分类
2020-06-09 10:11:04史明华吴广潮
计算机与现代化 2020年5期
史明华,吴广潮
(华南理工大学数学学院,广东 广州 510641)
0 引 言
在分类问题中,不平衡分类问题是许多研究者探索过的一个非常重要的分支[1-2]。它在实际应用中随处可见,如人脸识别[3]、医疗诊断[4]、故障诊断[5]等。此外,随着信息技术的不断进步,不平衡问题变得越来越重要。在许多实际二分类问题中,一个类(多数类)的样本明显多于另一个类(少数类),具有这种特征的数据集被称作不平衡数据集[6]。对于不平衡数据集,传统分类器的分类结果更多地偏向于多数类。
目前,针对不平衡数据集分类性能提高的解决办法主要围绕在数据层面和算法层面展开。数据层面通过欠采样、过采样以及混合采样等数据重采样方法,算法层面通过改进已有的分类算法,如代价敏感学习[7-8]、单类学习[9]和集成学习[10-11]等来提高分类性能。本文从数据层面上来平衡数据分布。
欠采样通过减少多数类样本使之与少数类平衡,最简单常用的欠采样方法是随机欠采样,该方法缩短了训练时间,但是易丢失多数类样本中的关键信息。而过采样与欠采样相反,最简单常用的过采样方法是随机过采样,该方法使得少数类样本中有大量重复数据,在训练中容易过拟合。为了避免随机过采样中出现过拟合问题,文献[12]提出了SMOTE算法,该算法对少数类及其近邻之间进行随机线性插值得到新的少数类样本,可以在一定程度上避免过拟合问题,但是增加了类之间重叠的可能性。文献[13]提出了一种自适应数据合成方法ADASYN,该方法可以根据少数类样本的分布自适应地合成少数类样本,相比较容易分类的区域,在较难分类的区域合成更多的样本,可以减少原始不平衡数据分布引入的学习偏差,还可以自适应地改变决策边界,专注于那些难以学习的样本。混合采样则是欠采样与过采样的结合。文献[14-15]中的实验显示,混合采样后分类器的性能几乎都是优于单个采样方法的。
本文提出一种新的平衡数据方法,该方法先对样本聚类,然后根据每一簇中多数类样本与少数类样本的比值(不平衡比(Imbalance Ration, IR))大小对簇中样本进行处理,构建新的样本集,再采用GBDT分类器对样本进行分类。
1 相关知识
1.1 SMOTE算法
SMOTE算法是由Chawla等人[12]提出的一种过采样算法,该算法的主要思想为:先对少数类样本计算其少数类k近邻,接着在少数类样本之间进行线性插值生成新的少数类样本。对于少数类中每一个样本xi,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其最近邻,随机选取近邻xj,然后由以下公式构建新的样本:
xnew=xi+δ(xj-xi)
其中,δ为0~1之间的随机数。
1.2 K-means算法
K-means算法[16]是经典的基于划分的聚类方法。该算法按照相似度将样本分成不同的簇,簇间相似度低,簇内相似度高。具体算法流程描述如下:
输入:数据集X={x1,x2,…,xn},生成簇个数k
输出:簇集{c1,c2,…,ck}
1)从X中随机选取k个值作为初始簇心{μ1,μ2,…,μk}
2)foriinndo
forjinkdo
dji=‖xi-μj‖2//计算样本与簇心之间的欧氏距离,将样本与距离最近的簇心归为一簇
3)forjinkdo
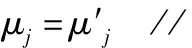
返回步骤2,直到当前簇心不再更新
1.3 GBDT算法
梯度提升决策树(Gradient Boost Decision Tree, GBDT)是2001年由Friedman等人[17-18]提出的一种有效的机器学习算法,可以用于解决分类和回归问题。该算法将损失函数的负梯度作为当前模型数据残差的近似值,根据近似残差值拟合一个CART回归树,不断重复此过程,进而减少上个模型的残差,并在残差减少的梯度方向上训练建立新的模型。GBDT的具体算法的流程描述如下:
输入:数据集{(x1,y1),(x2,y2),…,(xn,yn)},迭代次数M(生成树的树目)
输出:强学习器F(x)
1)初始化弱学习器:
2)forminMdo
foriinndo
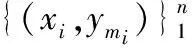
forjinJdo
//括号中内容为真则I=1,否则I=0
3)返回:
2 基于聚类的混合采样算法
对于均衡不平衡数据,大多数的采样方法针对类间不平衡问题,即类与类之间数量的不平衡,没有考虑类内样本的分布不均衡问题。这2种不平衡问题均会对分类效果造成影响,因此本文提出基于聚类的混合采样(Hybrid Sampling Based on Clustering, HSBC)算法。该算法通过控制参数去噪声,并由混合采样均衡对应簇的2类样本数量。
2.1 基于聚类的混合采样算法
本文提出新的算法平衡数据集,首先对数据集做聚类,对每一簇样本求不平衡比(IR),当IR过大或过小时,将该簇中数目较少的样本视作噪声删去,其余的簇根据IR分别作混合采样,以均衡类内分布。HSBC算法合成样本过程如下:
1)由K-means算法将原始数据集分成多个簇。
2)对每一簇样本计算不平衡比。
3)根据IR对相应簇进行剔除部分样本或混合采样处理。
4)输出新数据集。
详细算法步骤如下:
输入:数据集S
输出:新数据集Snew
1)Snew=[] //放置新样本
2)Kmeans(S)→clusters
//Kmeans算法生成多个簇clusters
3)forc∈clusters do
if IR(c)>=m1:
Snew.append(maj_sample)
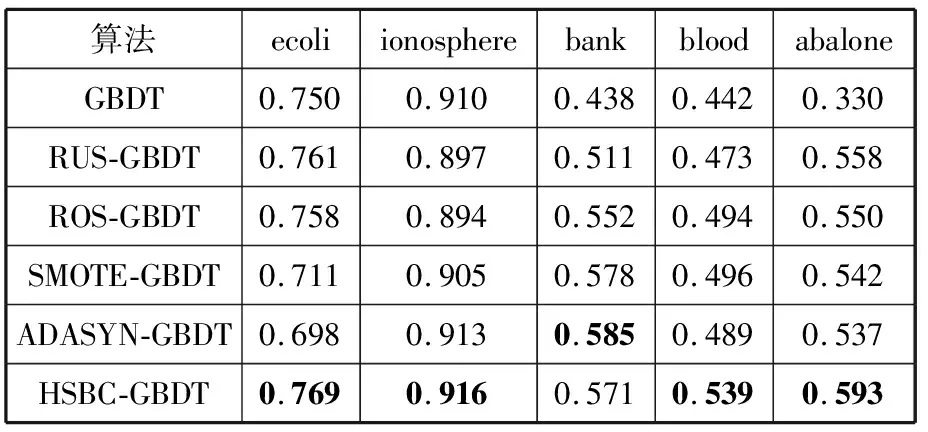
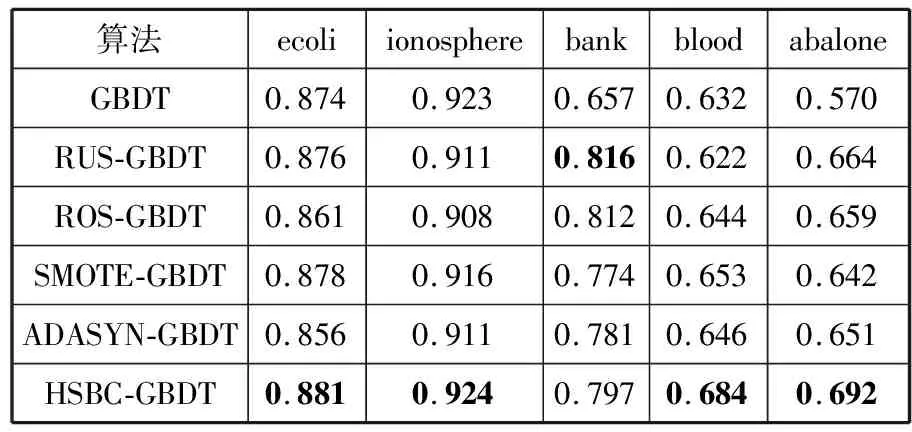
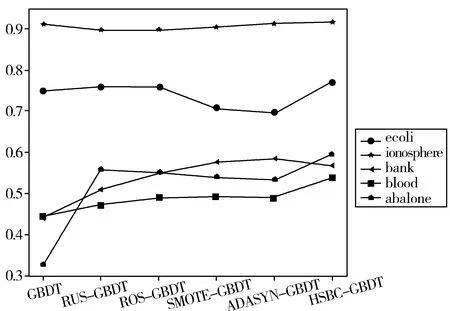
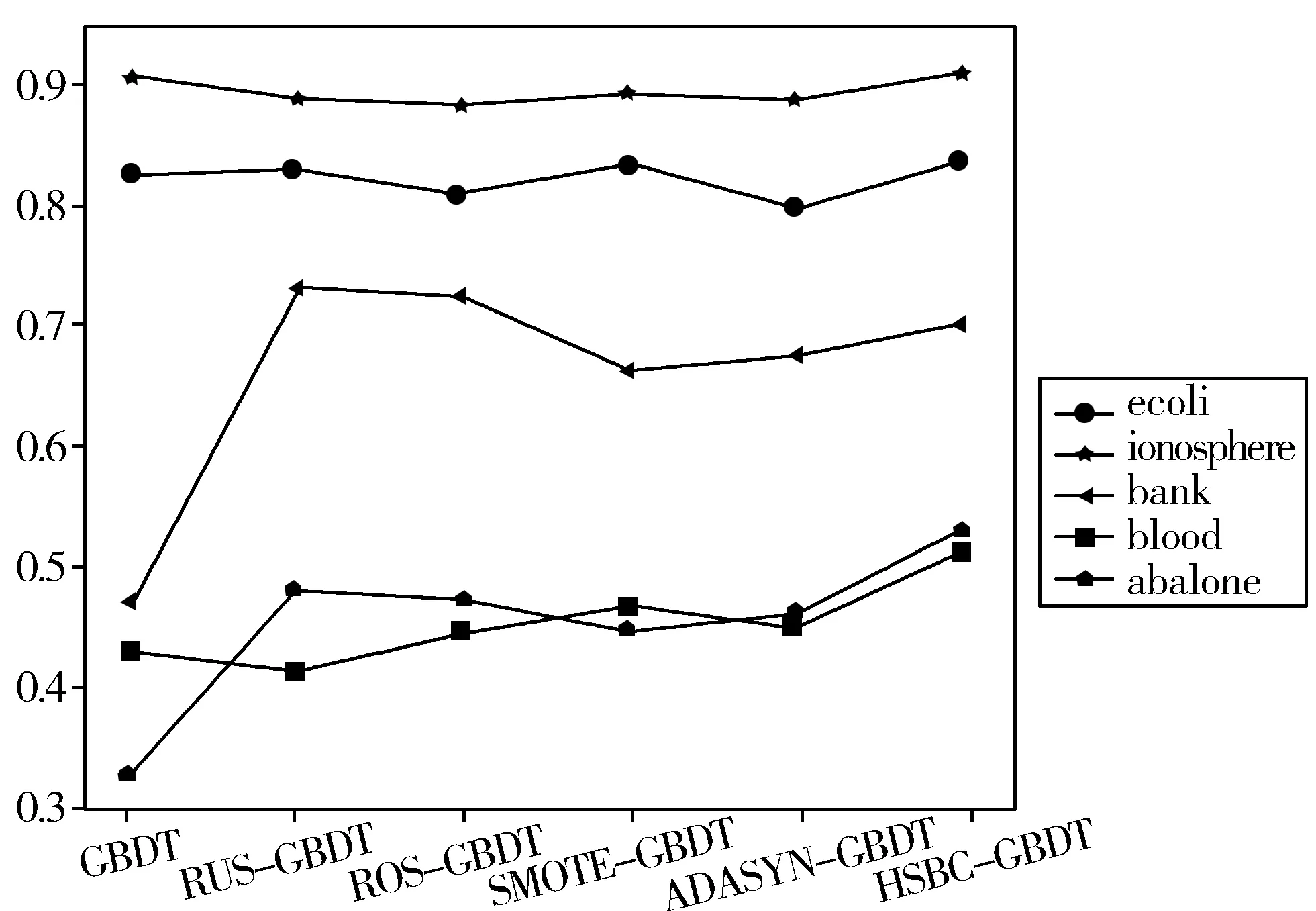
elif 1 kmeans=Kmeans(count(c)/2) center_maj=kmeans.fit(maj_sample) cluster_new=SMOTE.fit_sample(center_maj∪min _sample) Snew.append(cluster_new) elifm2 kmeans=Kmeans(count(c)/2) center_min =kmeans.fit(min _sam mple) Snew.append(center_min ∪maj_sample) else: Snew.append(min _sample) 4)ReturnSnew 其中,maj_count(c)指c簇中多数类样本个数,min_count(c)指c簇中少数类样本个数,maj_sample指c簇中多数类样本,count(c)指c簇总样本个数,min_sample指c簇中少数类样本。 当m1越大时,簇内少数类样本相对越少,IR大于m1时,将少数类样本视作噪声去掉;同理,IR小于m2时,将多数类样本去掉;若簇内IR小于m1而又大于1时,多数类样本多,少数类样本少,先对多数类样本聚成子簇,用子簇心代替多数类样本以减少样本个数,再对少数类样本运用SMOTE生成新的少数类样本;若簇内IR大于m2而又小于1时,少数类样本个数多,多数类样本个数少,对少数类样本聚成子簇以减少样本个数,再对多数类样本运用SMOTE合成新的多数类样本。通过以上操作,较好地均衡了类内样本分布。 数据集经过预处理、HSBC算法处理后得到较为均衡的数据集,然后将该数据集放入GBDT分类器。具体的算法流程如图1所示。 图1 HSBC-GBDT算法流程图 为验证算法的有效性,实验选取了5个UCI数据集[19],实验思路:先选取不平衡数据集,将字符型变量转化为数值型变量,并做归一化处理。然后用本文提出的数据处理算法与传统算法处理数据,再用GBDT分类器对数据分类。对比实验结果表明,本文提出的算法具有更好的性能。 本文从UCI数据集中采用了ecoli、bank、blood、ionosphere、abalone这5个不平衡数据集。其中ecoli数据集将类别标签为“im”的样本记作少数类样本,abalone数据集将类别标签为“F”的样本记作少数类样本。数据集分布如表1所示。 表1 数据集描述 数据集数目类别数目特征数目不平衡比ecoli336259,7773.36ionosphere351225,126341.79bank45214000,521167.68blood748570,17843.20abalone41772870,130782.20 对于不平衡问题,本文采用F1-value、AUC作为评价指标,其中多数类为负类,少数类为正类。分类结果的混淆矩阵如表2所示。 表2 二分类混淆矩阵 分类预测正类预测负类实际正类TPFN实际负类FPTN 查准率: precision=TP/(TP+FP) 查全率: recall=TP/(TP+FN) F1-value: ROC曲线以FP/(TN+FP)为横轴,TP/(TP+FN)为纵轴,曲线越靠近左上角分类效果越好。学习器进行比较时,若一个分类器的曲线被另一个学习器的曲线完全“包住”,则后者性能高于前者。若2条曲线交叉,则难断两者孰优孰劣,可引入ROC曲线下的面积,即AUC[20]。 本文实验均在Jupyter Notebook上运行,其中在HSBC算法中,m1取10,m2取0.2时算法总体来看效果最好,因此本次实验取该值。对于每个数据集,按7:3的比例划分为训练集与测试集,5个数据集分别经过不做均衡化处理、随机欠采样(RUS)、随机过采样(ROS)、SMOTE算法、ADASYN算法及HSBC算法后使用GBDT算法对新训练集进行分类。F1-value及AUC对比结果见表3和表4,其中最大值用粗体标出。 表3 各算法在不同数据集上的F1-value对比 算法ecoliionospherebankbloodabaloneGBDT0.7500.9100.4380.4420.330RUS-GBDT0.7610.8970.5110.4730.558ROS-GBDT0.7580.8940.5520.4940.550SMOTE-GBDT0.7110.9050.5780.4960.542ADASYN-GBDT0.6980.9130.5850.4890.537HSBC-GBDT0.7690.9160.5710.5390.593 表4 各算法在不同数据集上的AUC值对比 算法ecoliionospherebankbloodabaloneGBDT0.8740.9230.6570.6320.570RUS-GBDT0.8760.9110.8160.6220.664ROS-GBDT0.8610.9080.8120.6440.659SMOTE-GBDT0.8780.9160.7740.6530.642ADASYN-GBDT0.8560.9110.7810.6460.651HSBC-GBDT0.8810.9240.7970.6840.692 由表3可知,本文提出的采样算法提高了分类效果,在ecoli、ionosphere、blood、abalone这4个数据集上F1-value均高于其他采样算法。ecoli数据集上提高了7.1个百分点,提高最少的ionosphere数据集上也有2.2个百分点,平均提高约5.4个百分点。表4实验数据同样表明了HSBC算法的优越性,除了bank数据集,其他数据集经HSBC-GBDT操作后AUC更高,其中blood数据集上最多提高了6.2个百分点,提高最少的ionosphere数据集上也有1.6个百分点,平均提高约3.6个百分点。 由表3和表4可知,本文新提出的HSBC-GBDT分类模型在数据集ecoli、ionosphere、blood、abalone上,F1-value与AUC相对更高,分类效果比对比模型更好。在数据集bank中HSBC-GBDT的F1-value与AUC稍微偏低,这是因为bank数据集不平衡率较高,易将少数类样本视作噪声删去,导致HSBC-GBDT算法表现效果稍差。 图2 F1-value变化曲线 图3 AUC变化曲线图 为了更直观地分析各算法的分类效果,图2和图3分别绘制了5个数据集放入6种算法中F1-value及AUC折线图。由图可以观察到:当不平衡数据集不做任何处理,直接用GBDT算法分类时,效果较差,说明重采样对解决不平衡问题有显著效果。在ecoli、bank、abalone数据集中,经过随机欠采样处理后分类效果较好,这是因为随机欠采样的随机性,效果时好时坏。总体来说,HSBC-GBDT相比较其他算法分类性能更优,具有更强的鲁棒性。 本文针对不平衡数据分类问题,提出了一种基于聚类的混合采样算法,首先对原始数据集聚类,然后对每一簇样本计算不平衡比,根据不平衡比的大小对该簇样本做出相应处理,以实现数据集的均衡。实验结果表明,本文所提算法与一般采样算法相比具有更好的性能,并提高了不平衡数据集的分类效果。但本文算法仍然存在不足,对于不平衡率较大的数据集,HSBC算法中m1取值较大时,相应簇中少数类样本过少,对该簇进行混合采样,容易造成过拟合,取值较小时又不能很好地去除噪声样本。接下来的工作将致力于在HSBC算法的基础上继续改进,使其能很好地适用于不平衡率较大的数据集。2.2 HSBC-GBDT算法
3 实验结果与分析
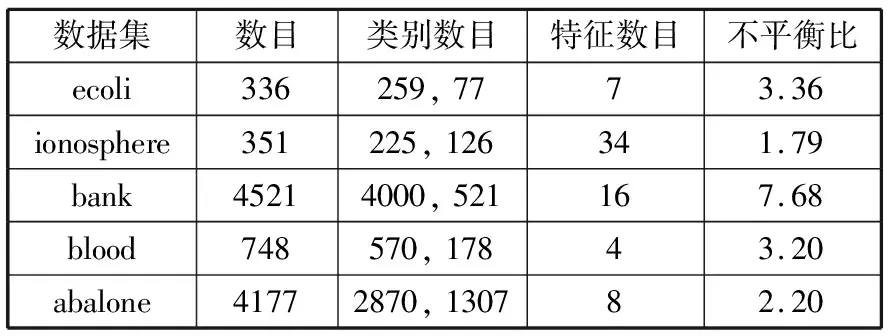
3.1 数据集
3.2 评价指标
3.3 实验结果
4 结束语
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44数学物理学报(2019年6期)2020-01-13 06:08:16中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46电子测试(2018年1期)2018-04-18 11:52:35数学物理学报(2017年5期)2017-11-23 07:51:31光学精密工程(2016年4期)2016-11-07 09:05:00光学精密工程(2016年3期)2016-11-07 09:03:33
