
基于PCR和RBF神经网络的城市智能增长水平评价模型
2020-06-09 10:11朱红章李连艳任晓斌隋晓亮
计算机与现代化 2020年5期
朱红章,李连艳,任晓斌,隋晓亮
(1.武汉大学土木建筑工程学院,湖北 武汉 430072; 2.武汉大学GNSS研究中心,湖北 武汉 430072)
0 引 言
世界经济和城市化进程的脚步不断加快,导致目前城市形态的扩张是肆意和不科学的[1]。伴随着城市人口的增加,相关研究表明到2050年世界上超过66%的人口将是城市人口,这意味着超过25亿农村居民将要迁移到城市[2-3]。随着人口的不断增加和城市规模的不断扩大,在无节制的资源消耗和资源有限的困境下,人们开始以环境为代价获得短暂的满足。然而,生态环境的进一步恶化、温室效应的进一步加剧以及生物物种的濒临灭绝导致了不可持续的城市增长模式,这些模式都表明了城市发展与自然环境之间的失衡正在加剧。因此,“智能增长”的概念应运而生[4]。当经济增长可持续,环境适宜人居住,人文社会更加繁荣,自然资源的消耗可以在最小的环境破坏下产生更大的价值,不同的利益相关者可以共同参与、共同努力实现共同目标,这样一个城市的增长被认为是智能的[5-6]。然而,目前在全球范围内智能成长仍然是一项模糊而艰巨的任务。欧共体甚至已经制定了一个名为“灯塔”的前沿计划,以寻找数字驱动的智能可持续城市发展模式。
智能增长与可持续性经济繁荣、社会公平和环境可持续息息相关。然而,智能增长的作用一直存在争议。首先,从系统的角度对传统的规划方法进行比较,发现智能增长模式可以通过开放的政治背景和政府集中决策来达到预期的结果[7]。然后,在人口方面证明了智能增长可以促进城市中心人口密度的增加,这也可以通过提出综合模型实现节能目标[8]。相反,一些研究揭示了智能增长的潜在负面环境影响,这使许多政策制定者感到失望[4]。通过分析现有文献,发现由于城市的不同特征,智能增长可能会产生独特的影响。如果政策规划者能够利用城市发展中智能增长的优势,那么它的益处无疑可以无限放大。
本文旨在提供一个评估城市智能增长计划的数学模型,建立的模型不仅可以对不同城市当前的发展规划进行定量评估,还可以明确规划中的资源配置问题,为城市决策者及相关政策的制定提供一定的参考。
1 模型与方法
1.1 构建评价指标体系
智能增长成功的评估模型包括2个部分:1)对城市现状的评估;2)指导城市社会、经济和环境资源的调整[9-10]。
表1 模型回顾
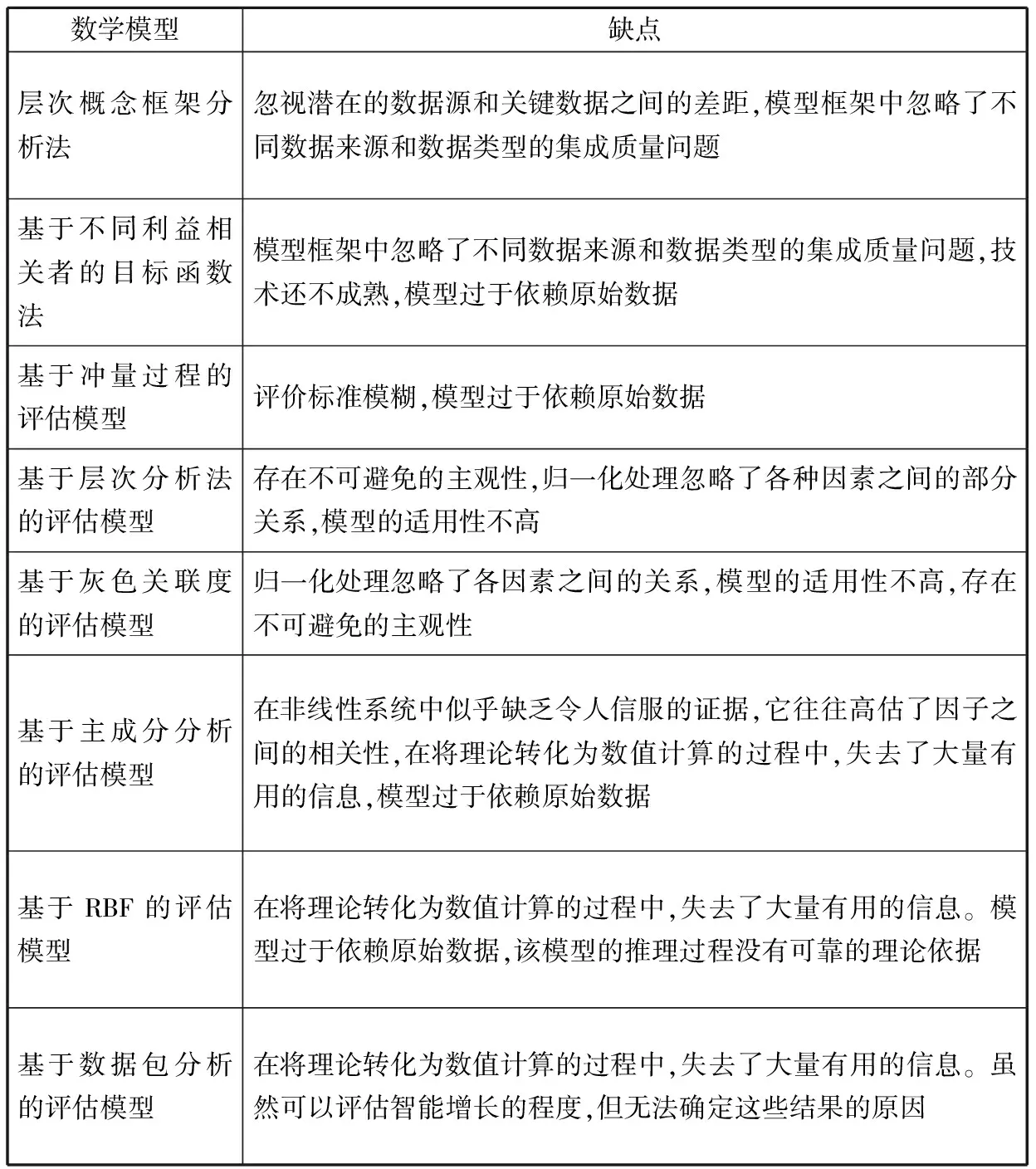
数学模型缺点层次概念框架分析法忽视潜在的数据源和关键数据之间的差距,模型框架中忽略了不同数据来源和数据类型的集成质量问题基于不同利益相关者的目标函数法模型框架中忽略了不同数据来源和数据类型的集成质量问题,技术还不成熟,模型过于依赖原始数据基于冲量过程的评估模型评价标准模糊,模型过于依赖原始数据基于层次分析法的评估模型存在不可避免的主观性,归一化处理忽略了各种因素之间的部分关系,模型的适用性不高基于灰色关联度的评估模型归一化处理忽略了各因素之间的关系,模型的适用性不高,存在不可避免的主观性基于主成分分析的评估模型在非线性系统中似乎缺乏令人信服的证据,它往往高估了因子之间的相关性,在将理论转化为数值计算的过程中,失去了大量有用的信息,模型过于依赖原始数据基于RBF的评估模型在将理论转化为数值计算的过程中,失去了大量有用的信息。模型过于依赖原始数据,该模型的推理过程没有可靠的理论依据基于数据包分析的评估模型在将理论转化为数值计算的过程中,失去了大量有用的信息。虽然可以评估智能增长的程度,但无法确定这些结果的原因
目前已存在很多评估城市智能增长影响的方法,表1总结了目前几种常用的模型及模型的缺点,发现现有的数学模型在理论框架搭建过程中,往往从特定的角度进行,模型的框架不够完善,整体性不高,并且模型在数据处理和应用方面也不完善,例如指标的自然属性被忽略,在数据处理过程中数据本身的特点被忽略、评价标准模糊等[10-14],所以构建一个更加优化的模型显得尤为重要。
为了确定城市智能增长成功程度的标准,理性度(Rational Degree, RD)被定义为城市智能增长水平。构建智能增长评估系统是一项复杂的系统工作,涵盖社会、经济和生态领域。基于系统分析的角度,本文从世界上智能增长的权威机构的相关文件和政策中,提取出用于选择指标的评价标准,如表2所示。最终本文以RD为最终目标构建指标体系评估模型。确定的一级指标层是社会、生态和经济效益。下属评价指标为城镇居民基本生活质量(BLQUS)、社区土地混合使用(MUCL)、城市公共基础设施(UPI)、和谐城市(HC)、高效管理机制(EMM)、友好环境(FE)、经济因素(EF)、经济结构(ES)。
表2 指标选取标准
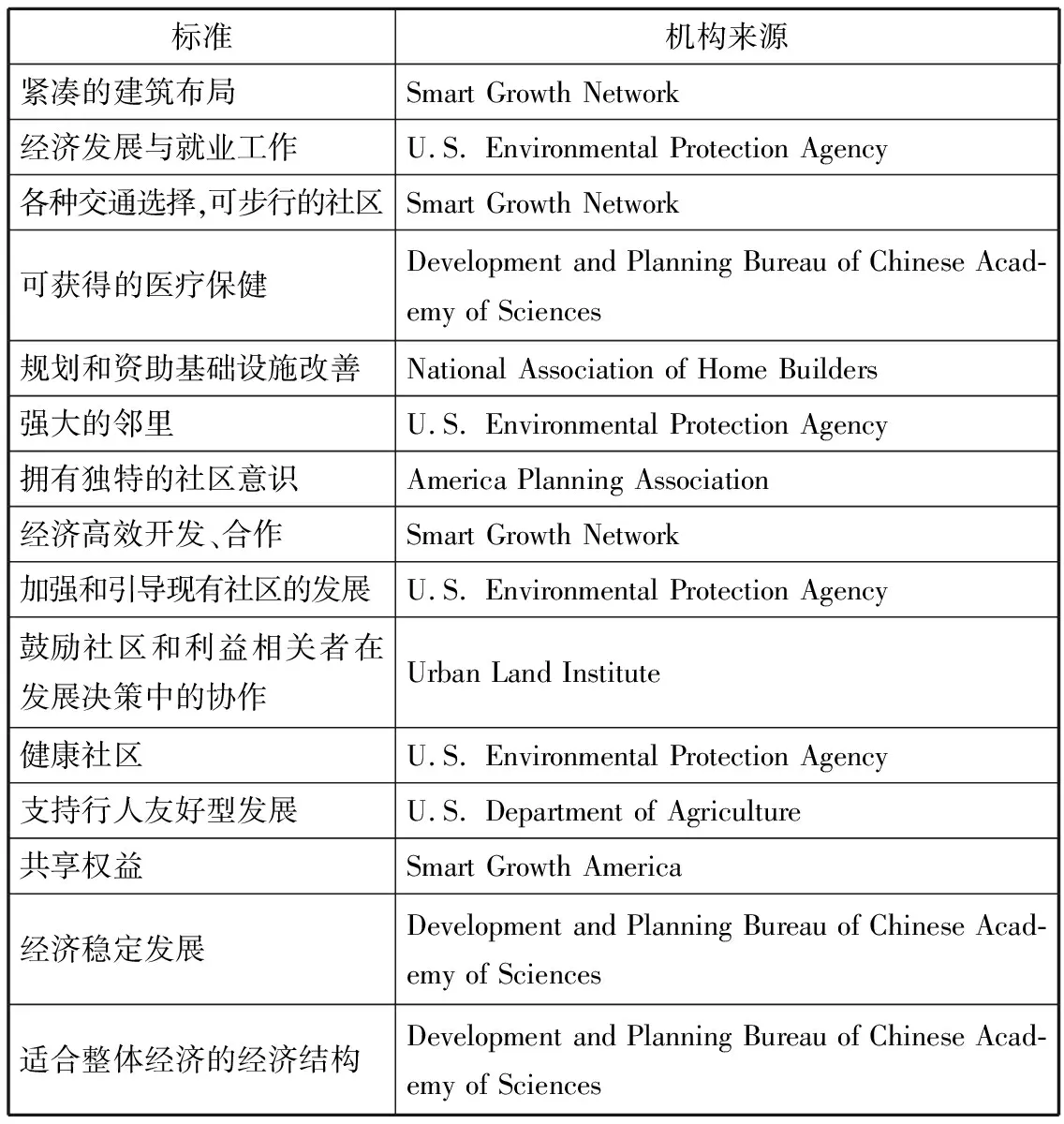
标准机构来源紧凑的建筑布局SmartGrowthNetwork经济发展与就业工作U.S.EnvironmentalProtectionAgency各种交通选择,可步行的社区SmartGrowthNetwork可获得的医疗保健DevelopmentandPlanningBureauofChineseAcad-emyofSciences规划和资助基础设施改善NationalAssociationofHomeBuilders强大的邻里U.S.EnvironmentalProtectionAgency拥有独特的社区意识AmericaPlanningAssociation经济高效开发、合作SmartGrowthNetwork加强和引导现有社区的发展U.S.EnvironmentalProtectionAgency鼓励社区和利益相关者在发展决策中的协作UrbanLandInstitute健康社区U.S.EnvironmentalProtectionAgency支持行人友好型发展U.S.DepartmentofAgriculture共享权益SmartGrowthAmerica经济稳定发展DevelopmentandPlanningBureauofChineseAcad-emyofSciences适合整体经济的经济结构DevelopmentandPlanningBureauofChineseAcad-emyofSciences
1.2 选取评估指标
通过对政府工作报告和专家意见的分析,为了确定对城市智能增长做出最大贡献的重要因素,主成分回归(Principal Component Regression, PCR)通过描述数据集中的最大和最小变异(方差)来估计主成分[15-16]。当多重共线性发生时,最小二乘估计将是无偏的,但它们的方差会很大,因此它们可能远离真实值。通过在回归估计中增加一定程度的偏差,可以减少主成分回归中的标准误差。在运用PCR模型的过程中,通过保持正交角度与旋转成分来获得最明显的4个主成分(PC1,PC2,PC3,PC4),变量之间的相关性在0.05的显著性水平上进行测试,指标的权重范围在[0,1],当评价指标的权重接近1时,表示该指标对总体结果影响较大。图1显示了每个PC的贡献率。PC1的贡献率为82.0997%,这表明它具有最强的解释能力。PC2的贡献率为12.623%,2个主成分的累积贡献率为94.7227%。

图1 PCR模型输出结果
选择指标的原则如下:1)累积贡献率大于94%;2)每个指标的权重系数应保证在特定区间范围内。本文要求在PC1中的指标的权重系数应为-0.15和0.15,在PC2中的指标的权重系数应为-0.05和0.05。如图2所示。
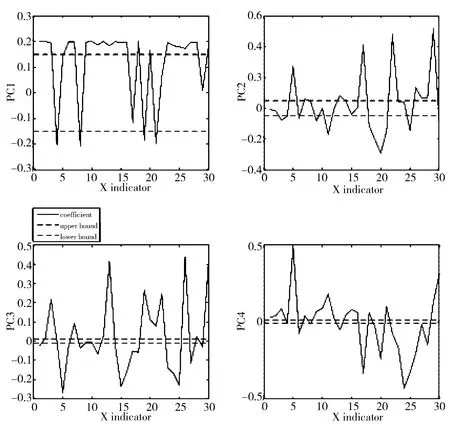
图2 主成分系数
所以最终的评价体系如表3所示。
表3 评价指标体系
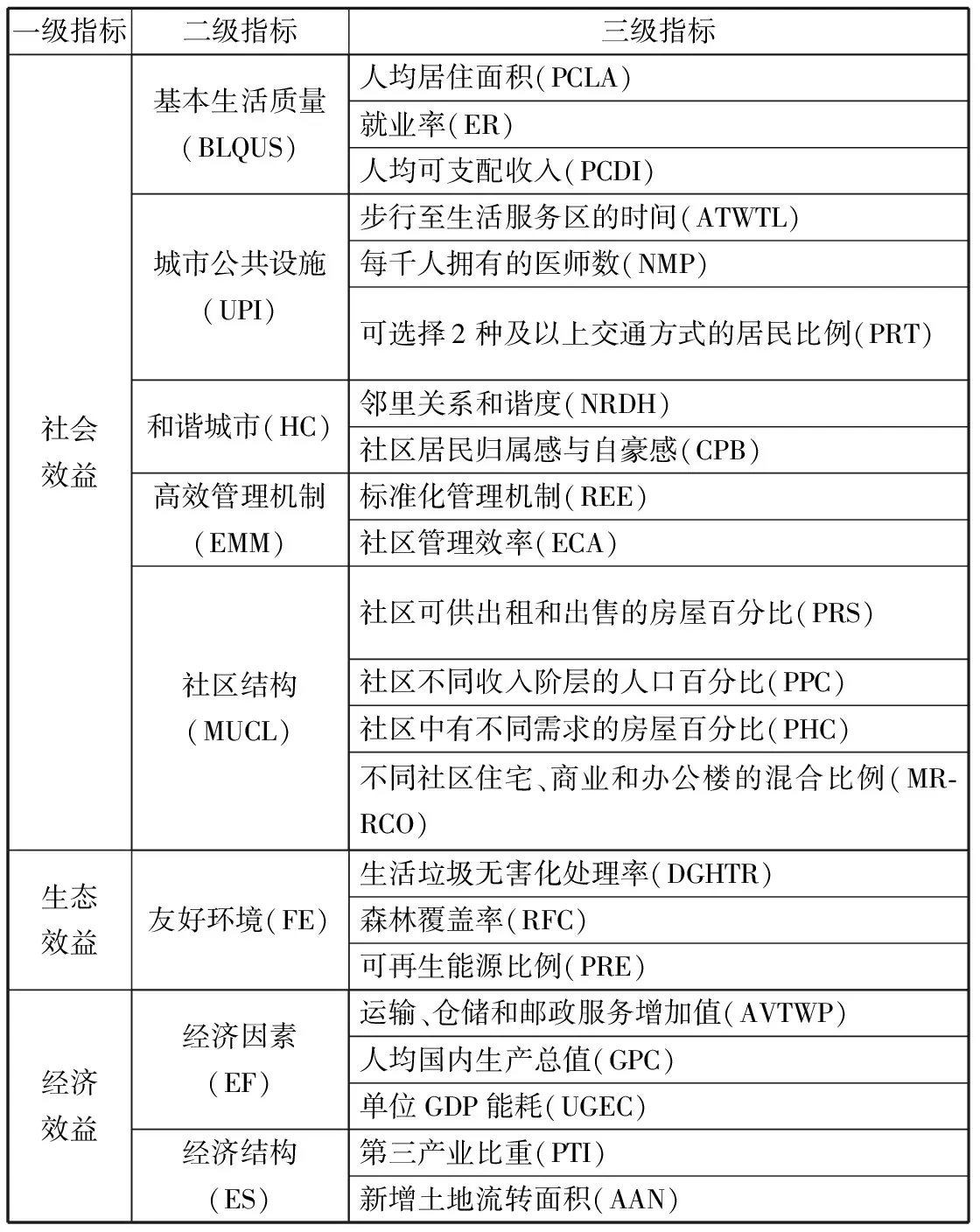
一级指标二级指标三级指标社会效益基本生活质量(BLQUS)城市公共设施(UPI)和谐城市(HC)高效管理机制(EMM)社区结构(MUCL)人均居住面积(PCLA)就业率(ER)人均可支配收入(PCDI)步行至生活服务区的时间(ATWTL)每千人拥有的医师数(NMP)可选择2种及以上交通方式的居民比例(PRT)邻里关系和谐度(NRDH)社区居民归属感与自豪感(CPB)标准化管理机制(REE)社区管理效率(ECA)社区可供出租和出售的房屋百分比(PRS)社区不同收入阶层的人口百分比(PPC)社区中有不同需求的房屋百分比(PHC)不同社区住宅、商业和办公楼的混合比例(MR-RCO)生态效益友好环境(FE)生活垃圾无害化处理率(DGHTR)森林覆盖率(RFC)可再生能源比例(PRE)经济效益经济因素(EF)经济结构(ES)运输、仓储和邮政服务增加值(AVTWP)人均国内生产总值(GPC)单位GDP能耗(UGEC)第三产业比重(PTI)新增土地流转面积(AAN)
1.3 理性度评价模型
通过上节的PCR模型选择了22个对RD有显著影响的指标,同一指标可能对不同城市产生不同影响,评估模型需要量化这些影响,因此该模型包括2个部分:1)每个指标的重要性系数;2)每个指标的权重系数。RD模型可以表示为:
Ri=ciqi
(1)
其中,i是第i个评价指标,i=1,2,…,22,qi是第i个指标的权重系数,Ri是指标i的理性度值,将所有指标的理性度值相加便可以得到城市发展计划的理性度,ci是第i个指标的重要性系数,通过将指标映射至区间[0,1]得到。重要性系数ci的表达式为:
(2)
其中,本文选择径向基函数神经网络(RBFNN)模型来获得指标的权重。RBFNN技术由于其高精度和有效处理高维空间中的散乱数据的能力而被广泛应用于科学和工程的各个领域。RBFNN用作隐藏单元的“基础”以形成隐藏层空间,因此输入向量可以直接映射到隐藏空间而无需权重连接[17]。当确定RBF的中心时也确定了该映射关系。从隐藏层空间到输出空间的映射是线性的,即网络的输出是隐藏单元输出的线性加权和,权重是网络的可调参数。其中,隐藏层的功能是将矢量从低维映射到高维,网络从输入到输出的映射是非线性的,而网络输出对于可调参数是线性的。网络的权重可以通过线性方程直接求解,这极大地加速了学习速度并避免了局部最小问题。RBF的基本原则和步骤如下[18-19]。
1)确定参数。
①取得初始的输入向量、输出向量和预期向量:
(3)
其中,X是输入向量,n代表输入层的数量,Y代表输出向量,O是预期的输出向量,q是输出层的单元数。
②初始化隐含层至输出层的连接权值:
Wk=[wk1,wk2,…,wkp]T,k=1,2,…,q
(4)
其中,p是隐藏层单元数。参考中心初始化的方法给出隐藏层到输出层的权值初始化方法为:
wkj=kmin+j(kmax-kmin)/(q+1)
(5)
其中,kmin是训练集中第k个输出神经元中所有期望输出的最小值;kmax是训练集中第k个输出神经元中所有期望输出的最大值。
③初始化隐含层各神经元的中心参数。
不同隐含层神经元的中心应有不同的取值,并且与中心的对应宽度能够调节,使得不同的输入信息特征能被不同的隐含层神经元最大地反映出来。在实际应用中,一个输入信息总是包含在一定的取值范围内。RBF神经网络中心参数的初始值如公式(6)所示:
(6)
其中,p为隐含层神经元总个数,j=1,2,…,p。
④初始化宽度向量。
宽度向量影响着神经元对输入信息的作用范围,宽度越小,相应隐含层神经元作用函数的形状越窄,那么处于其他神经元中心附近的信息在该神经元处的响应就越小。宽度向量计算公式为:
(7)
其中,df为宽度调节系数,取值小于1,作用是使每个隐含层神经元更容易实现对局部信息的感受能力,有利于提高RBF神经网络的局部响应能力。
2)计算隐含层第j个神经元的输出值zj,具体计算公式如下:
(8)
Cj=[cj1,cj2,…,cjn]
(9)
Dj=[dj1,dj2,…,djn]T
(10)
其中,Cj是隐含层第j个神经元的中心向量,由隐含层第j个神经元对应于输入层所有神经元的中心分量构成,Dj为隐含层第j个神经元的宽度向量,与Cj相对应,Dj越大,隐含层对输入向量的影响范围就越大,且神经元间的平滑度也比较好,‖·‖为欧氏范数。
3)计算输出层神经元的输出,具体计算公式如下:
Y=[y1,y2,…,yq]T
(11)
(12)
其中,wkj为输出层第k个神经元与隐含层第j个神经元间的调节权重。
4)权重参数的迭代计算。
本文中RBF神经网络权重参数的训练时选择梯度下降法。通过学习将中心、宽度和调节权重参数自动调整至最理想值,其计算公式如下:
(13)
(14)
(15)
其中,wkj(t)为第k个输出神经元与第j个隐含层神经元之间在第t次迭代计算时的调节权重,cji(t)为第j个隐含层神经元对于第i个输入神经元在第t次迭代计算时的中心分量,dji(t)为与中心cji(t)对应的宽度,η为学习因子,E为RBF神经网络评价函数,计算公式如下:
(16)
其中,olk为第k个输出神经元在第l个输入样本时的期望输出值,ylk为第k个输出神经元在第l个输入样本时的网络输出值。
5)计算均方根误差:
(17)
如果RMSE≤ε,神经网络的训练就结束,否则,需要从步骤3开始重新进行训练。
另外,RBFNN传输参数的格式用高斯函数表示(y=e-x2)。训练过程可分为2步:1)无监督学习,其核心目标是确定输入层和隐藏层之间的权重;2)监督学习和训练,以确定隐藏层和输出层之间的权重。最终指标的权重计算公式如下:
qi=cjwkj
(18)
2 案例分析与讨论
2.1 研究区域
本文选择玉门和Otago这2个城市作为研究对象。玉门位于甘肃省西北部,其总面积为13500 km2,目前总人口为18万人,其冬季平均气温可达6.9 ℃。年温差可达30 ℃左右,玉门生态环境压力较大,常年遭遇沙尘暴灾害,人口少经济发展缓慢,主要支柱产业是农业和畜牧业等传统产业。Otago位于新西兰南岛南部,面积约32000 km2,2018年6月人口约232300人,是该国第三大地方区域。Otago地区内的天气状况差别很大,极端南部地区的冬季凉爽潮湿,尤其是在Otago南部的山丘和平原;相比之下,夏天往往非常温暖和干燥。Otago拥有独特的混合经济,葡萄园和葡萄酒厂近几年在Otago中部地区蓬勃发展。玉门与Otago的地理位置如图3所示。
(a)玉门
(b)Otago
2.2 城市智能增长计划评估
本文使用的数据主要来自于地方政府报告、统计局公开数据、文献资料、年鉴和NZ.Stat(http://nzdotstat.stats.govt.nz/wbos/)。应用RBF神经网络时输入和输出指标分别是所选取的22个变量。图4显示了计算过程的结构。
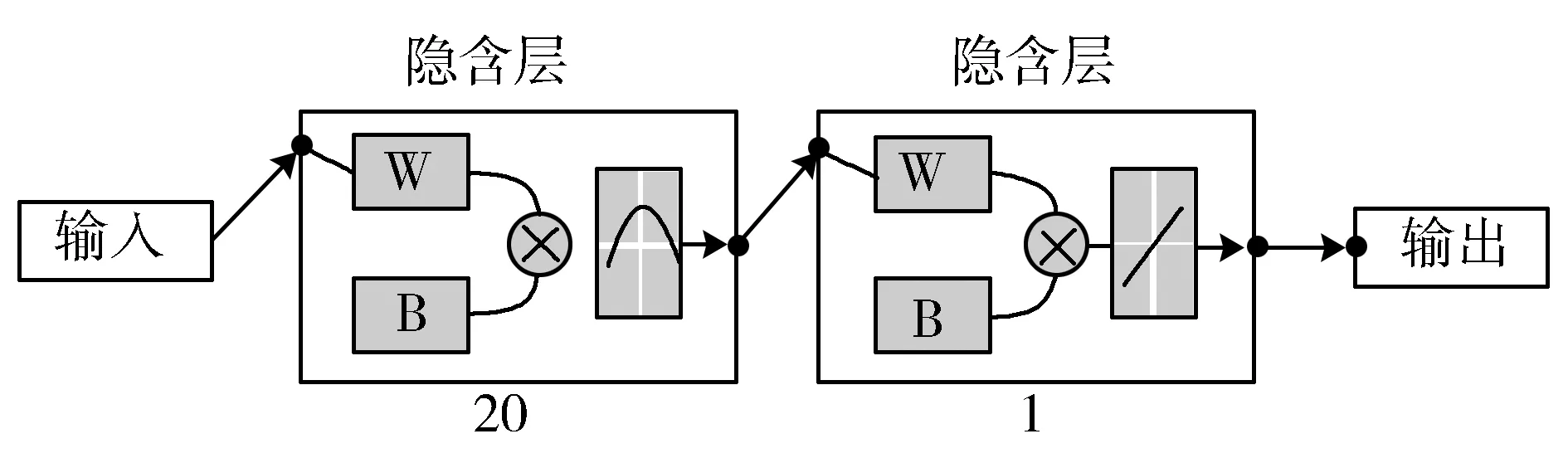
图4 RBFNN结构
通过预实验将隐藏层中神经元的数量设置为10,R2≥0.9,最大训练次数为1000次,学习精度为0.05,此时的结果是可接受的。当神经元的数量大于10时,虽然RBF的训练效果较好,但试验效果较差。评估样本的规模较小可能是造成这种反常现象的主要原因。所以本文神经元数量为10时,残差保持相当低的水平并且其平均残差小于0.05,这意味着模型的性能良好。为了评估RBFNN的性能,将预留的部分真值与算法的输出进行比较。结果显示其输出值非常接近真值(见图5),这表明神经网络的训练效果较好。最终各指标的权重如表4所示。
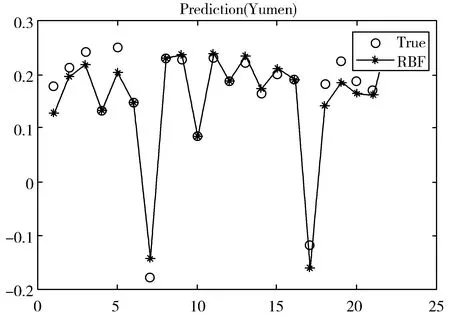
(a)玉门预测结果
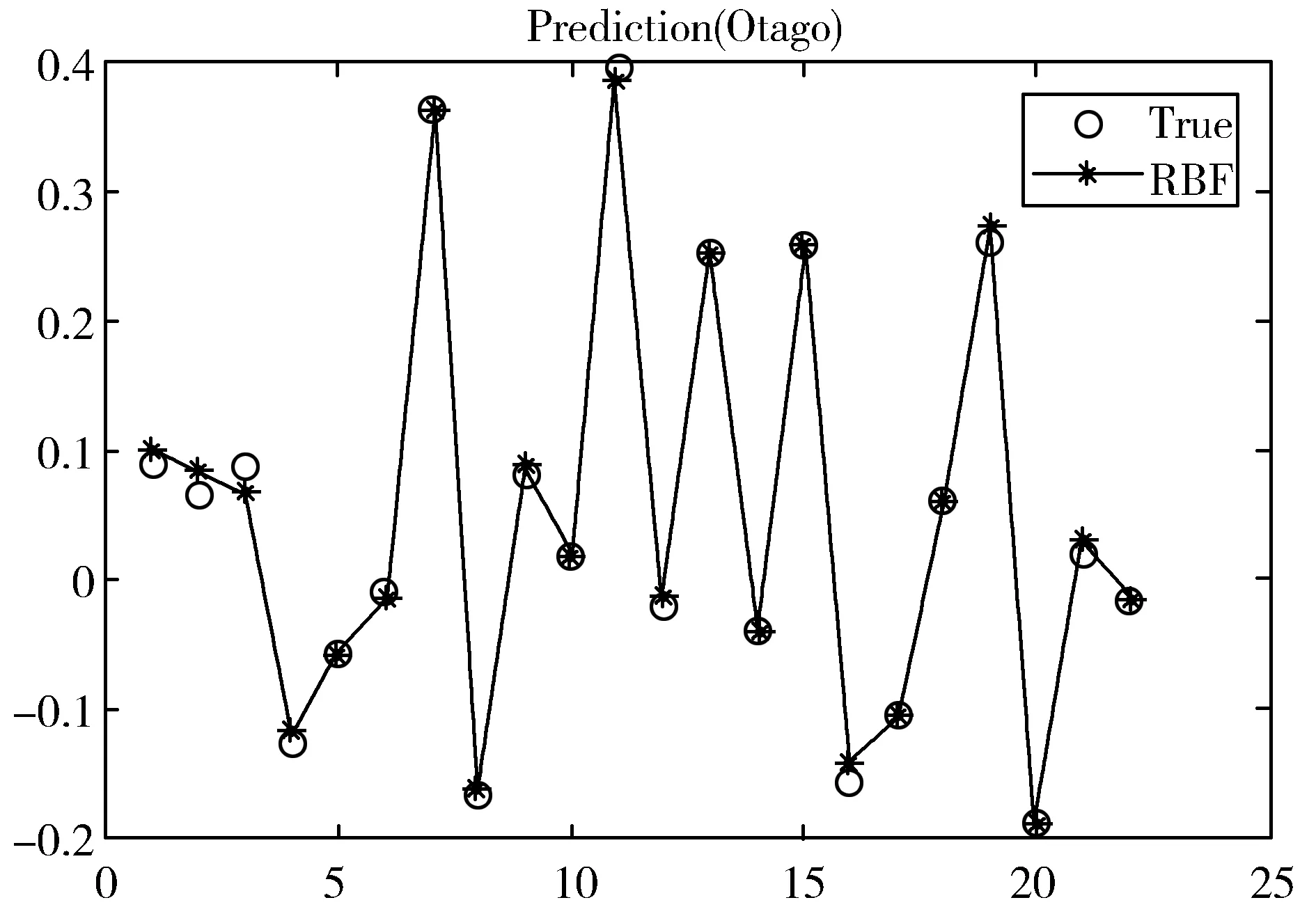
(b)Otago预测结果
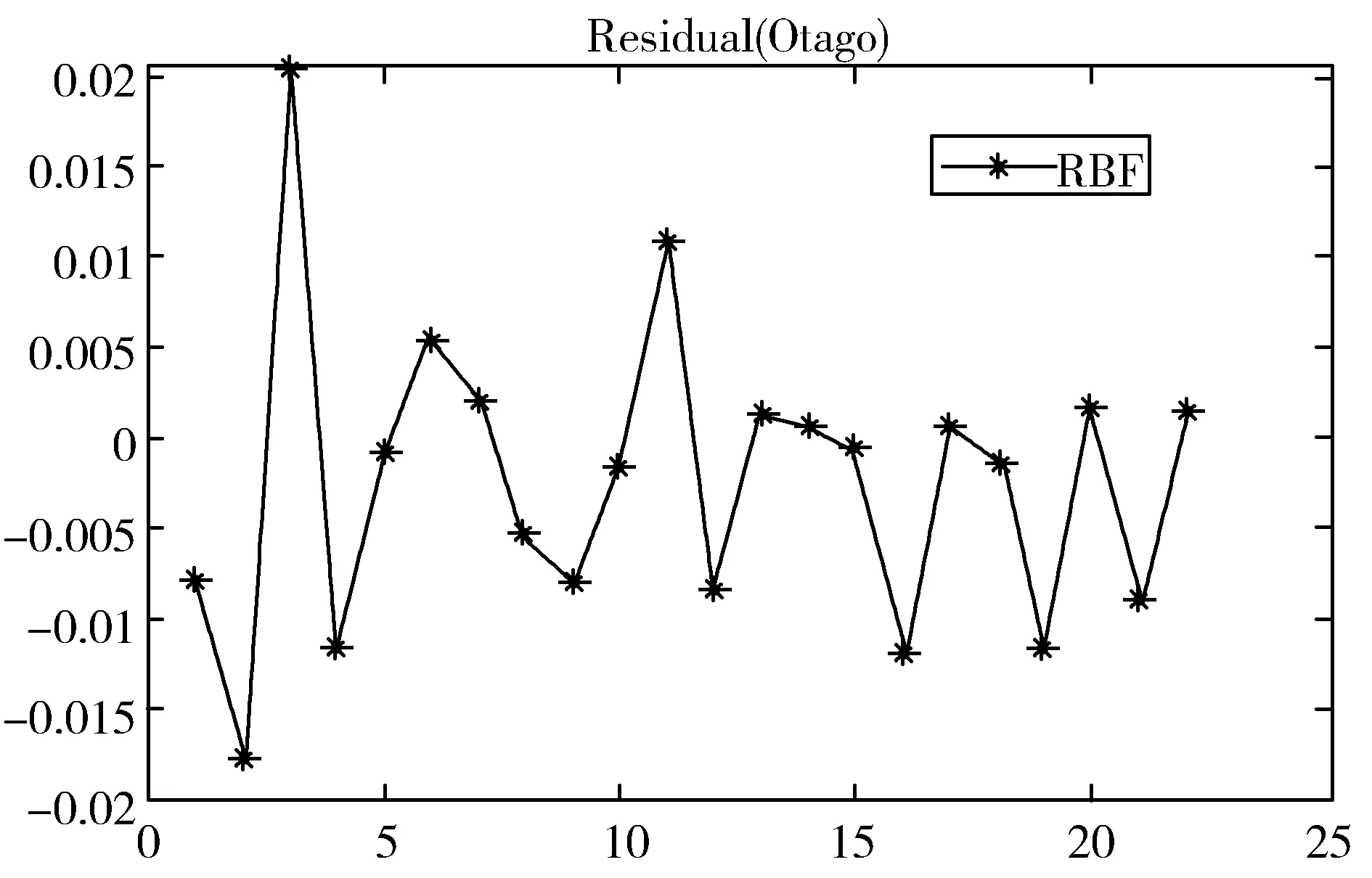
(c)Otago残差图
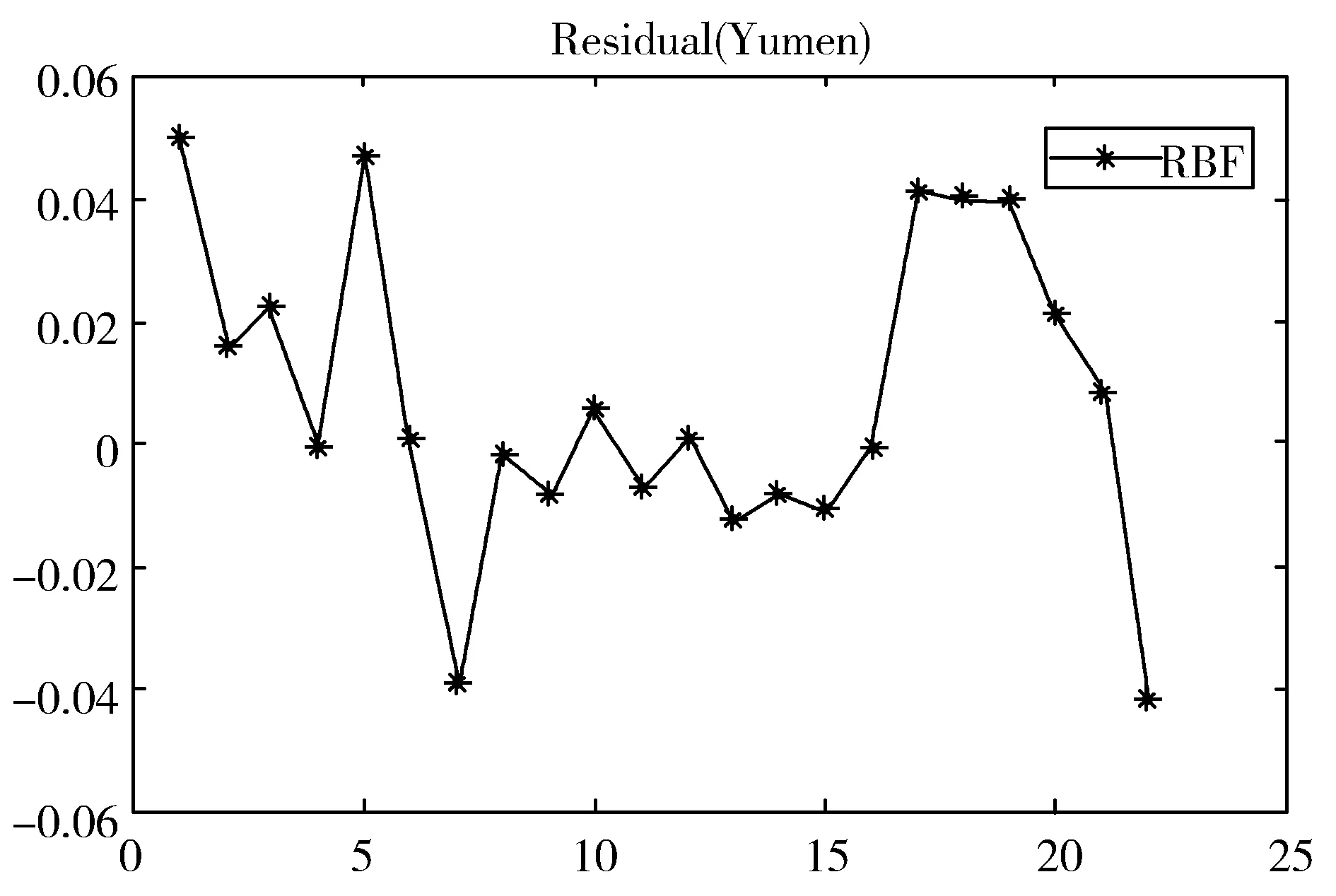
(d)玉门残差图
表4 评价指标权重值
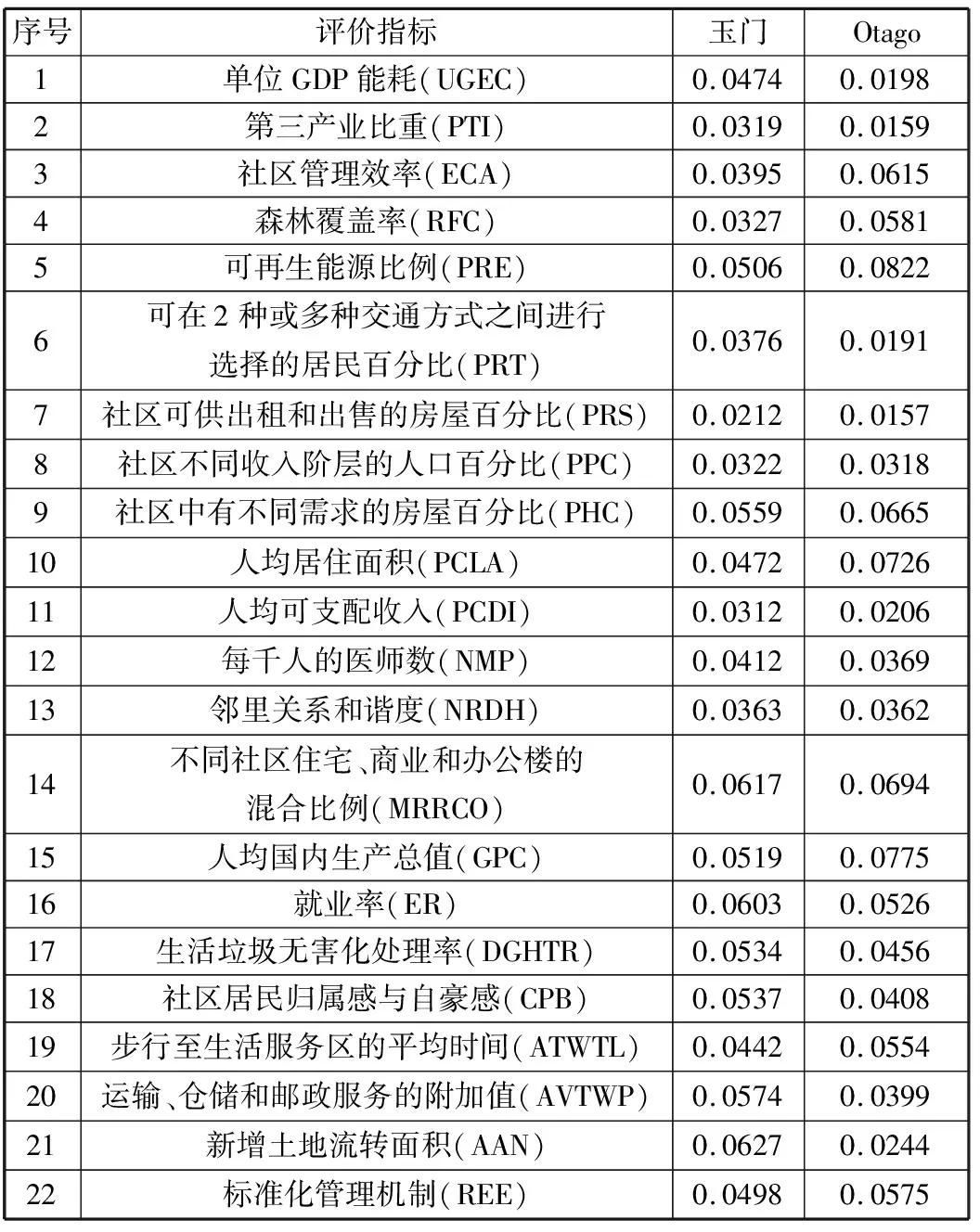
序号评价指标玉门Otago1单位GDP能耗(UGEC)0.04740.01982第三产业比重(PTI)0.03190.01593社区管理效率(ECA)0.03950.06154森林覆盖率(RFC)0.03270.05815可再生能源比例(PRE)0.05060.08226可在2种或多种交通方式之间进行选择的居民百分比(PRT)0.03760.01917社区可供出租和出售的房屋百分比(PRS)0.02120.01578社区不同收入阶层的人口百分比(PPC)0.03220.03189社区中有不同需求的房屋百分比(PHC)0.05590.066510人均居住面积(PCLA)0.04720.072611人均可支配收入(PCDI)0.03120.020612每千人的医师数(NMP)0.04120.036913邻里关系和谐度(NRDH)0.03630.036214不同社区住宅、商业和办公楼的混合比例(MRRCO)0.06170.069415人均国内生产总值(GPC)0.05190.077516就业率(ER)0.06030.052617生活垃圾无害化处理率(DGHTR)0.05340.045618社区居民归属感与自豪感(CPB)0.05370.040819步行至生活服务区的平均时间(ATWTL)0.04420.055420运输、仓储和邮政服务的附加值(AVTWP)0.05740.039921新增土地流转面积(AAN)0.06270.024422标准化管理机制(REE)0.04980.0575
使用MATLAB 软件获取ci,在工具箱中选择min-max将玉门和Otago的所有评价指标映射至[0,1]区间内,ci通过软件输出结果获得。玉门和Otago的发展水平可以通过计算RD获得。计算结果如表5所示。
表5 玉门和Otago的RD值

城市RD玉门0.04482Otago0.04591
由此可知,2个城市的增长计划在某种程度上都是成功的,玉门的智能增长水平低于Otago。
图6显示了2个城市的发展结构。在玉门,贡献率最高的社会效益为61.2%,其次是经济效益(25.13%)和生态效益(13.67%),这与玉门的实际情况相符。在过去的发展模式中,玉门一直是处于资源枯竭的状态,煤炭、石油和天然气等自然资源被无节制地消耗来换取短期经济效益和人民生活质量的暂时提高。在盲目追求经济效益最大化的同时,玉门的自然环境遭受了巨大的创伤,荒漠化、土地盐渍化等环境破坏现象比比皆是[20]。因此,玉门目前的城市智能增长计划生态效益必然是制约城市发展的短板,这也是一种不协调的发展模式。在Otago的城市发展结构中,生态效益和经济效益的贡献大致相等,这表明在其智能增长过程中注重生态环境的保护,Otago发展规划中也强调将生态效益作为重要考虑因素。在追求经济增长和生活水平提高的同时,不断加强环境治理和保护,打击不合格的化工厂和制造业,控制环境污染源,保护现有湿地和草原,注重保护大自然原始净化能力[21-22]。
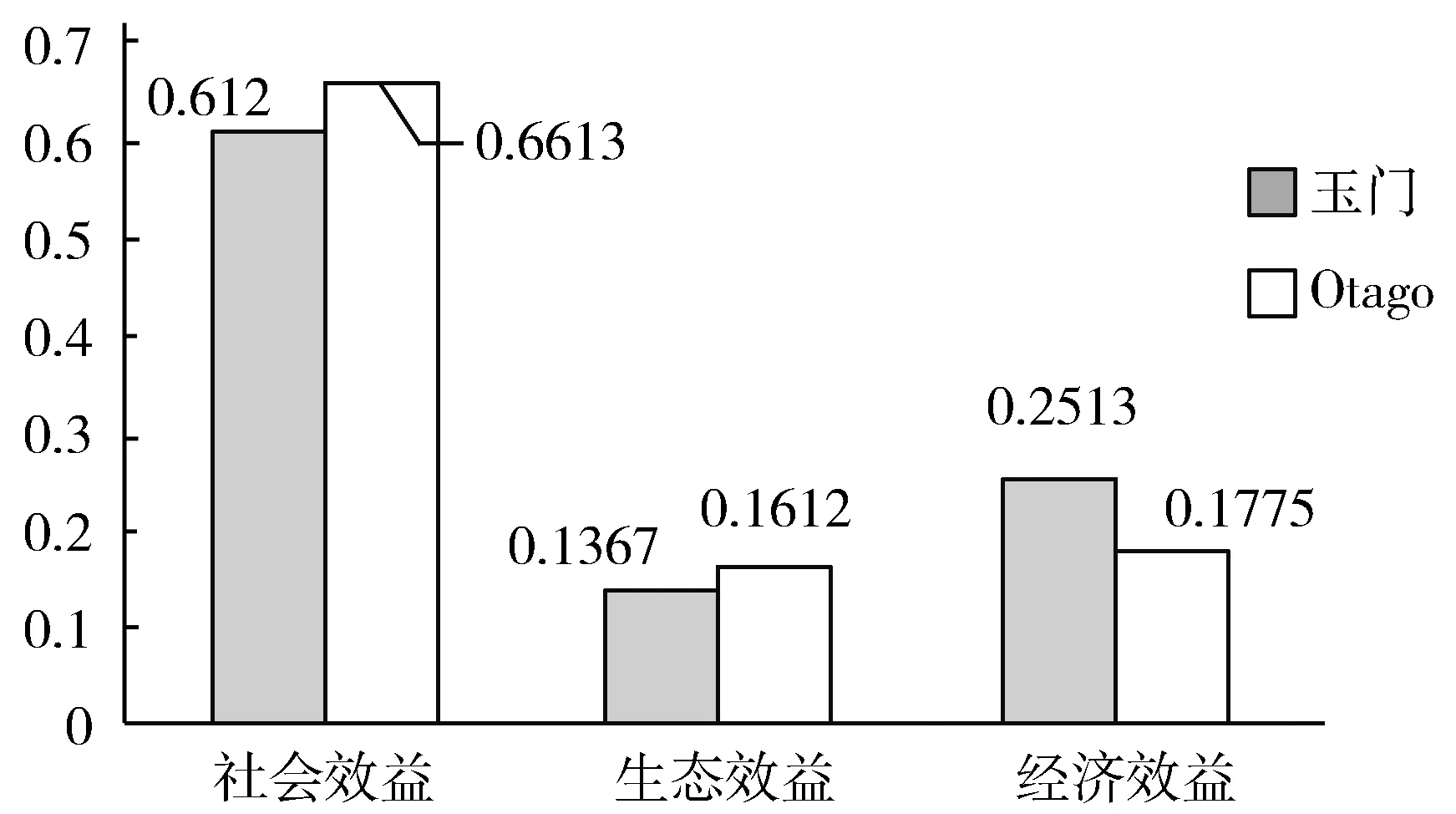
图6 玉门和Otago一级指标结构图
其实玉门和Otago的发展模式存在相似之处。如图7所示,MUCL和FE贡献占比比较大。土地对RD的影响是比较突出的,这表明在人口持续增长的前提下,城市空间变得拥挤,合理规划和土地的综合利用对城市扩张产生了很大的影响。而土地是限制城市扩张的重要因素,所以合理利用、规划土地是影响城市智能增长的重要因素。
图8显示了在城市智能增长过程中的各指标的贡献情况。其中MRRCO、AAN、ER和PHC是影响玉门城市发展水平的关键因素,甚至可以达到24.06%。与此同时,PRE、PCLA、MRRCO和GPC对Otago的智能增长至关重要,其累计贡献率高达30.17%。显然,玉门的发展核心还是经济水平的进一步提高[23],在经济发展的基础上不断提高居民的生活质量,因此与住房需求相关的指标在玉门智能发展中起着至关重要的作用。Otago的经济水平高于玉门,其城市规划的重点主要集中在绿色城市和高质量的管理。在个人需求方面,Otago倾向于选择更高水平的服务。
3 结束语
在本文中,理性度RD被定义为城市智能增长的成功程度,可以对不同城市的增长计划在同一标准下进行衡量比较。智能增长显然与社会、经济和环境领域有关,考虑到智能增长的系统特征,利用PCR和RBFNN模型建立城市智能增长评价模型RD,该模型有2个基本功能:1)评估当前的智能增长计划;2)对各个评价指标进行排名。在玉门和Otago的案例研究中,玉门和Otago的RD分别为0.04482和0.04591,玉门应优先考虑环境发展,而Otago则优先考虑经济发展。本文提出的模型不仅可以对不同城市的当前发展模式进行定量评估,而且可以根据评估结果指导资源的分配,使模型具有更好的适用性,该模型为城市智能增长水平评价提供了强有力的参考。
RD模型的构建中,指标的选择是非常重要的,本文选择的标准主要依赖于社会效益、生态效益、经济效益指标原则,读者可以选择更科学、完整的标准体系来进行指标筛选。由于资源和时间的限制,本文中用于神经网络学习的数据量不够大,这也会影响模型的准确性。未来,还可以在上述分析的基础上考虑系统分析、深度学习方法,使评价模型更加理想。
猜你喜欢
当代陕西(2020年17期)2020-10-28
中国石油石化(2019年18期)2019-11-13
丝绸之路(2018年9期)2018-11-29
人大建设(2018年5期)2018-08-16
现代装饰(2018年5期)2018-05-26
丝绸之路(2017年15期)2017-08-21
应用科技(2015年5期)2015-12-09
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
郑州大学学报(医学版)(2015年2期)2015-02-27
