
一种基于GAN的异构信息网络表示学习方法
2020-06-09 10:11申国伟赵文波周雪梅
计算机与现代化 2020年5期
周 丽,申国伟,赵文波,周雪梅
(1.贵州大学计算机科学与技术学院,贵州 贵阳 550025; 2.贵州省智能医学影像分析与精准诊断重点实验室,贵州 贵阳 550025)
0 引 言
近年来,网络表示学习[1-3]成为无监督学习领域中的研究热点。网络表示学习的目标是将网络的节点或者关系投影到低维空间中,以求能最大化保留原始网络的结构信息、属性信息和语义信息等,为节点分类、连接预测、聚类和可视化等下游任务奠定基础。
2014年,Perozzi等人[4]借鉴word2vec的思想,提出了一种基于深度学习的网络表示学习方法DeepWalk。随后几年,LINE[5]、node2vec[6]和MMDW[7]等方法相继被提出,成为了同构信息网络表示学习的经典方法。
然而,在现实生活中,论文引用网络、新闻评论网络等异构信息网络包含多类实体和关系,蕴含更为丰富的结构信息和语义信息。因此,异构信息网络表示学习也受到学者广泛的关注。
2014年,Jacob等人[8]将异构信息网络变成同构信息网络来处理,此类方法会丢失较多重要信息。2015年,Tang等人[9]提出了PTE方法,这种方法只适用于异构文本网络,不适用于大多数异构信息网络。2016年,一种基于元路径的同类型节点间的相似性搜索方法ESim[10]被提出,其依赖用户自定义的元路径和路径权重,以此为指导学习节点的隐含表示。2017年,2种比较经典的基于元路径的异构信息网络表示学习方法Metapath2vec[11]和HIN2Vec[12]被提出,它们都使用了元路径的游走来捕获不同类型节点之间的关系。但是,这2种方法中对元路径的指定存在主观性,会导致一些语义信息丢失。2019年,RHINE[13]方法中根据结构特性定义了2种关系,以达到保留异构信息网络结构和语义信息,但是关系数量限定了其应用。
综上,目前大多异构信息网络表示学习方法局限于使用元路径或者设置适合某种网络的关系结构来保留异构信息网络的语义信息。由于需要人工定义元路径或者关系结构,主观因素会导致最终得到的节点表示包含噪声,从而导致下游任务的效果不好。
2014年10月,Goodfellow等人[14]提出了GAN(Generative Adversarial Network)模型,该模型被用于各种应用中,以学习稳健的潜在表示[15-16]。GAN包含了生成模型(Generative Model)与判别模型(Discriminative Model),通过生成模型和判别模型的相互竞争,不仅可以学习底层的数据分布,还可以使模型对有噪声的数据具有更强的鲁棒性。鉴于这些优势,研究者已经在基于GAN的网络表示学习方面进行了一些初步的尝试[17-21]。
2018年,Dai等人[20]把GAN方法用在了网络表示学习领域,提出了ANE方法。该方法是一种同构信息网络表示学习方法,其主要用于保留网络的结构信息和增强表示的健壮性。同样,2018年,Yu等人[19]提出了一种基于GAN的网络表示学习的方法,该方法也是针对同构信息网络的,不适于异构信息网络。2019年,胡斌斌等人[22]提出了HeGAN方法,该方法把GAN用在了异构信息网络表示学习上,以增强异构信息网络的语义信息表示。该方法考虑了节点间的语义信息,但忽视了网络中所有节点的整体分布情况。
综上分析可知,目前异构信息网络的表示学习的研究还存在以下问题:
1)现有方法需要人为地定义一些关系结构或元路径去保留异构信息网络的语义信息,会因为主观原因导致最后的节点表示含有噪声,不能很好地保留原始网络中的真实信息。
2)现有方法着重考虑了节点间的语义信息,没有综合考虑整个异构信息网络的节点分布情况。
为了解决上述问题,本文提出一种基于GAN的异构网络信息表示学习方法HINGAN,其利用GAN博弈的过程,不仅增强了异构信息网络的语义信息表示,还考虑了异构信息网络所有节点的分布情况,使得最后节点向量表示所包含的信息更为全面。
1 问题定义
对于异构信息网络数据,本文抽象表述为:HIN=(V,E,T),其中,每个节点v和每条边e与它们相关联映射函数φ(v):V→TV和φ(e):E→TE。TV和TE表示对象和关系类型的集合,其中|TV|+|TE|>2。
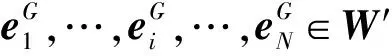
2 基于GAN的异构信息网络表示学习模型
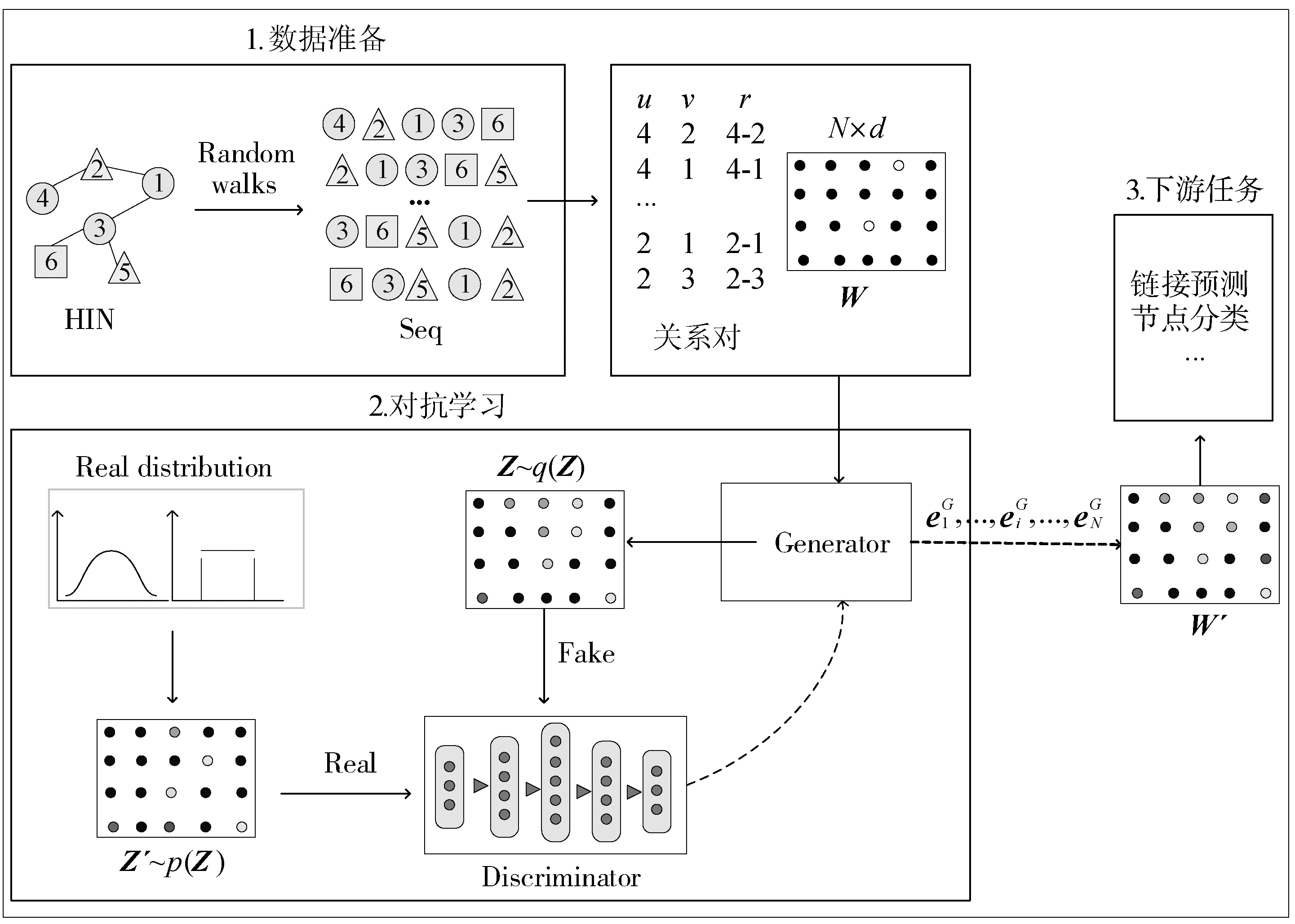
图1 HINGAN模型图
本文提出的基于GAN的异构信息网络表示学习模型如图1所示,其主要包括3个部分:数据准备、对抗学习和下游任务。数据准备部分,首先采用随机游走获得游走序列Seq,根据游走序列Seq生成关系对,同时,初始一个N×d的矩阵W,其中N为网络节点数,d为节点表示的维度。对抗学习部分,首先,把上一阶段的数据送入Generator模型,生成服从于q(Z)的异构信息网络表示矩阵Z作为假数据,采样服从高斯分布p(Z)的矩阵Z′作为真数据,然后把Z和Z′同时送入Discriminator模型,Discriminator模型则去判断输入的是Z还是Z′。然后,根据判别情况,继续训练Generator模型。通过迭代训练的过程,得到包含更多信息的网络表示,最后用于节点分类、链接预测等下游任务。
在本模型中,GAN模型的整体损失函数定义如公式(1)所示:
(1)
2.1 Generator模型
Generator模型包含2个部分,一部分用于保留节点间的语义信息,一部分用于生成接近真实数据的假数据。语义信息保留部分,通过判断2个节点之间是否有某种关系来实现。模型如图2所示。
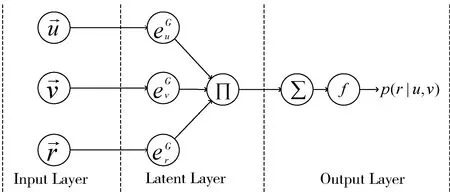
图2 语义信息保留模型
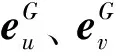
(2)
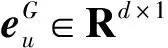
如果节点u和v间有关系r,那么L(u,v,r)=1表示节点间有关系r,反之L(u,v,r)=0表示节点间没有关系r。因此Generator模型的保留语义信息的损失函数如公式(3)所示:
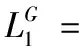
(1-L(u,v,r))log(1-p(r|u,v))
(3)
同时,为了生成接近真实数据的假数据,即为了增强网络的表示,在Generator模型中定义了另一个损失函数,如公式(4)所示:
(4)
Generator模型总的损失函数如公式(5)所示:
(5)

2.2 Discriminator模型
本文中,Discriminator模型采用的是一个简单的3层神经网络来实现的,如公式(6)所示:
(6)
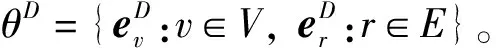
LD=EZ′~p(Z)(logD(Z′))+EZ~q(Z)(log(1-D(Z)))
(7)
3 基于GAN的异构信息网络表示学习算法
算法1为本文方法的整体训练过程,主要包括了判别模型训练过程和生成模型训练过程。
算法1基于GAN的异构信息网络表示学习训练模型。
Input: number of generator and discriminator trainings per epoch:nG,nD; number of samples:n; walk length:l
Output:θGandθD
1: InitializeθGandθDforGandD, respectively
2: while not converge do
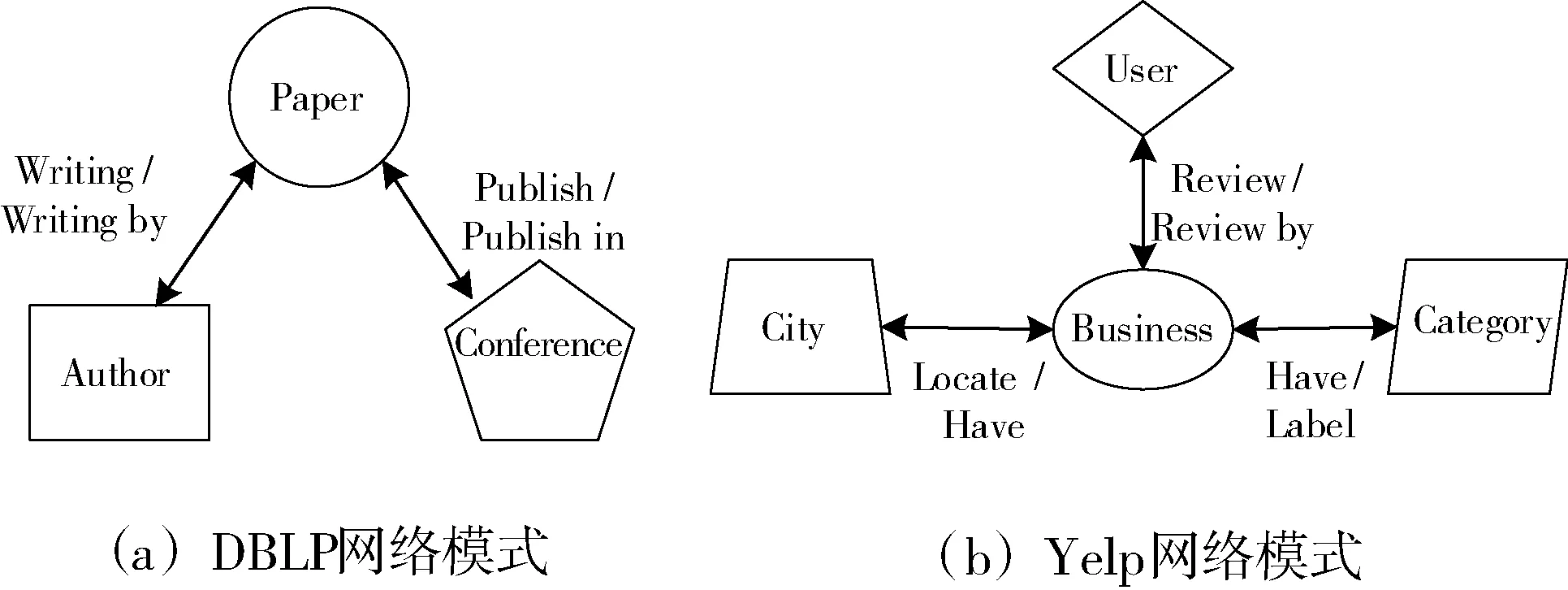
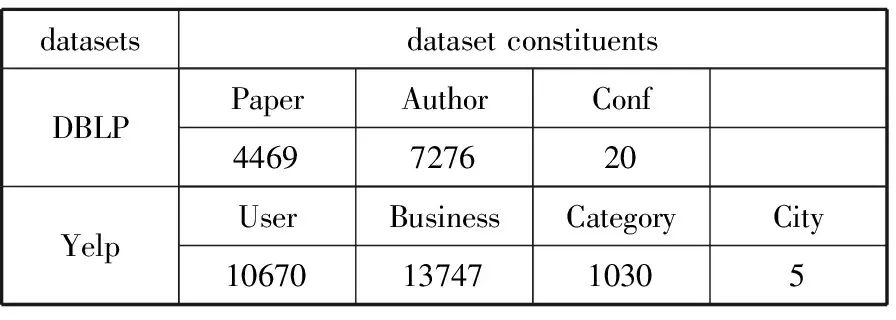
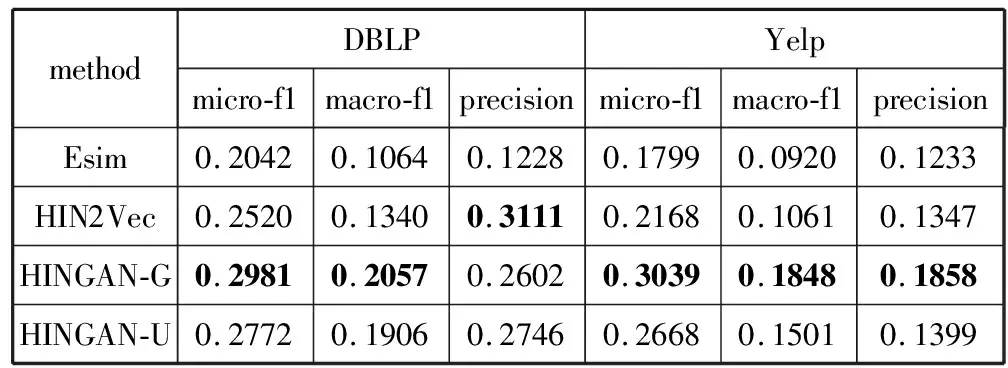
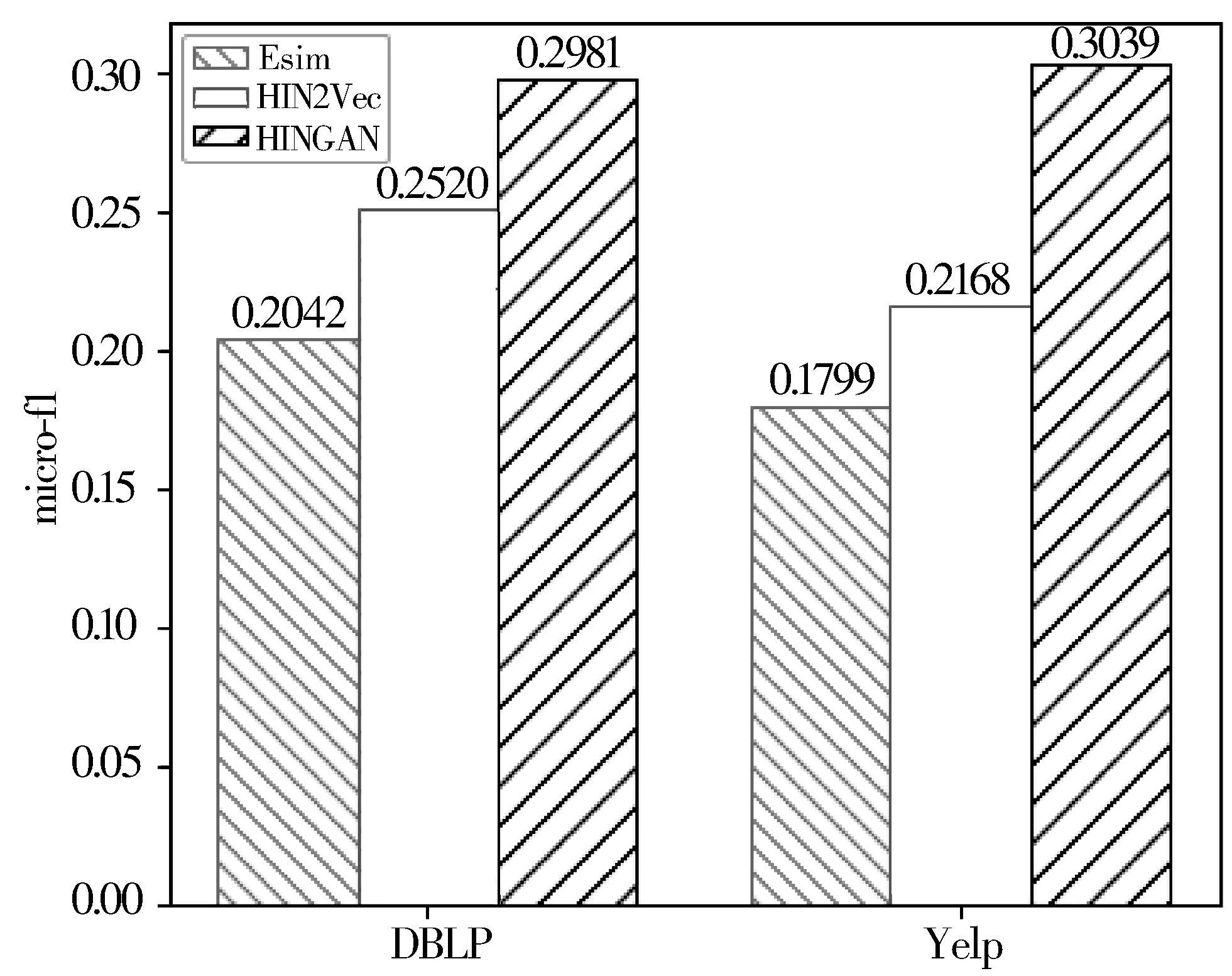
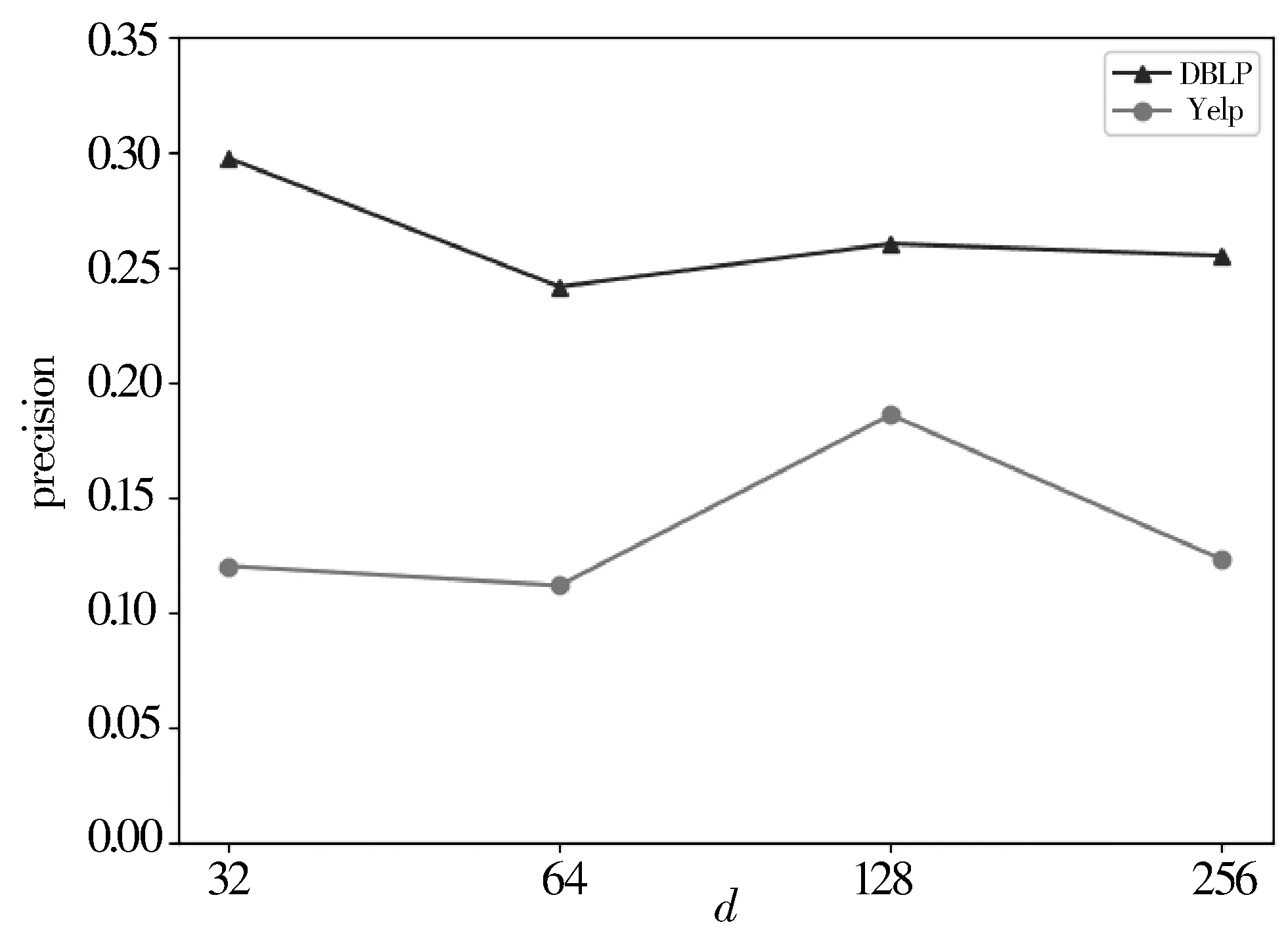
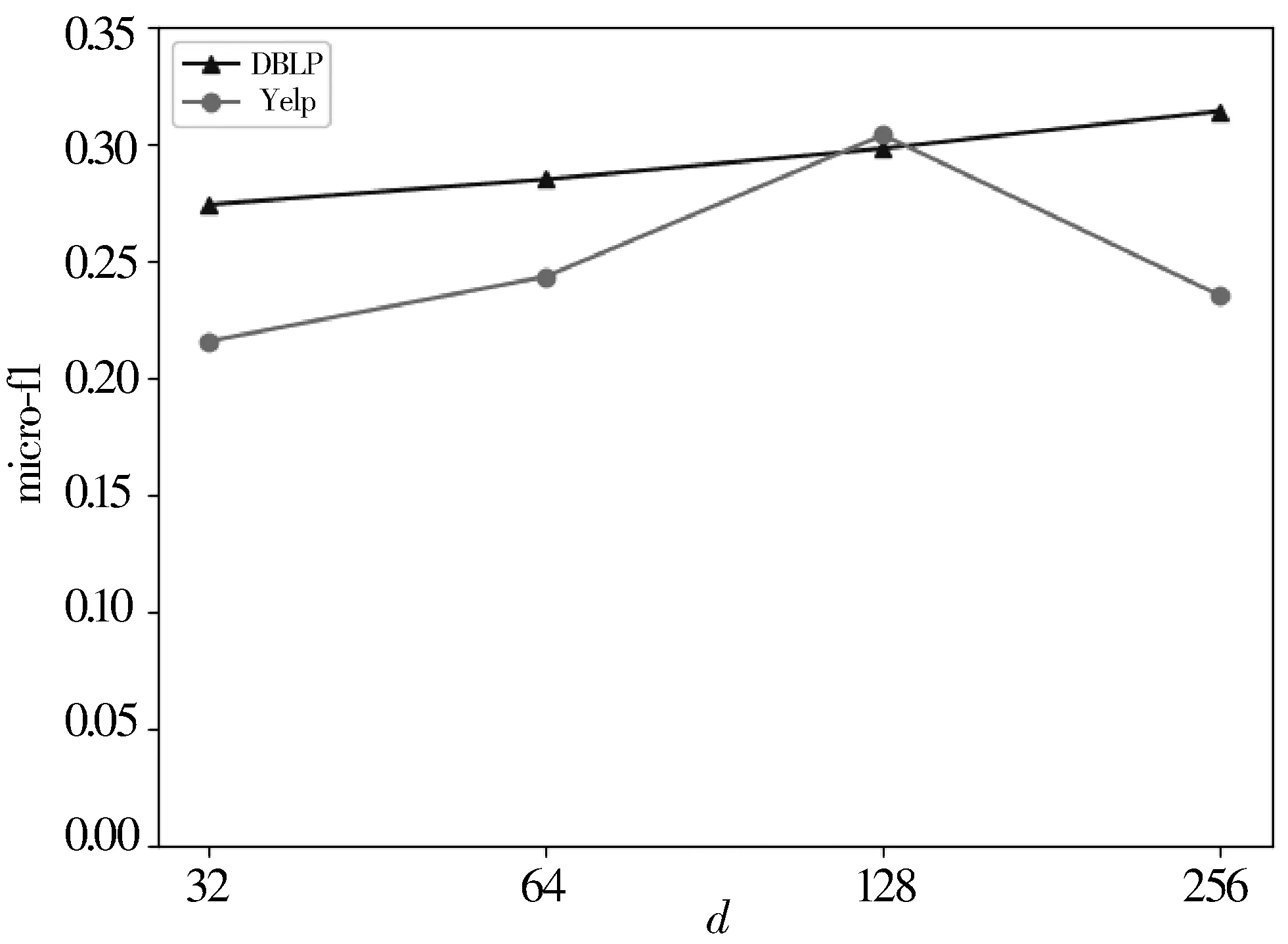
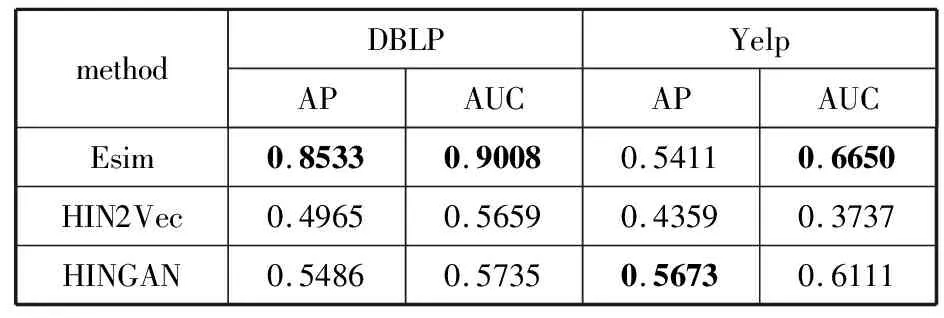
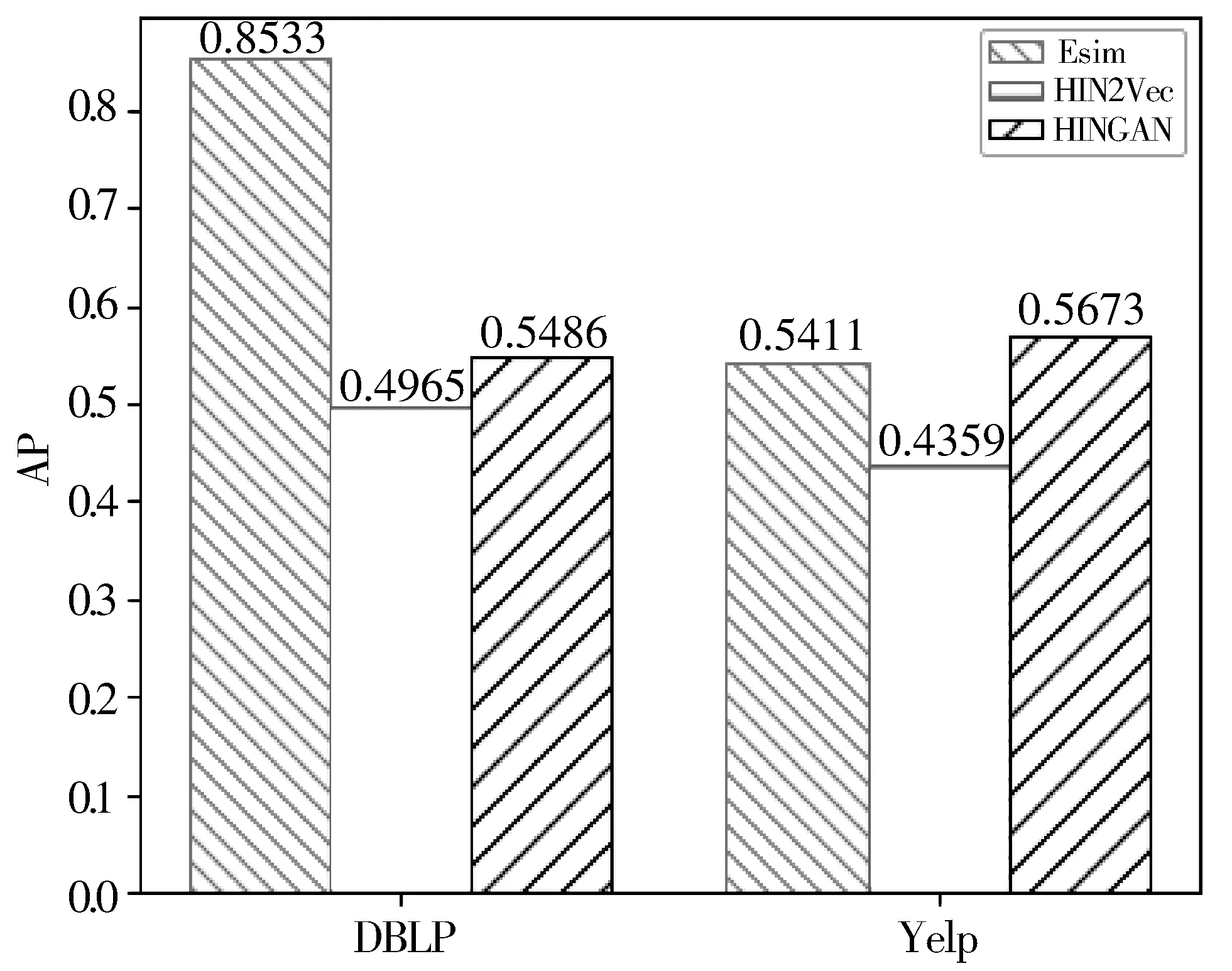
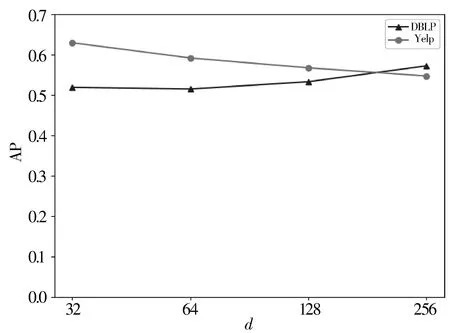
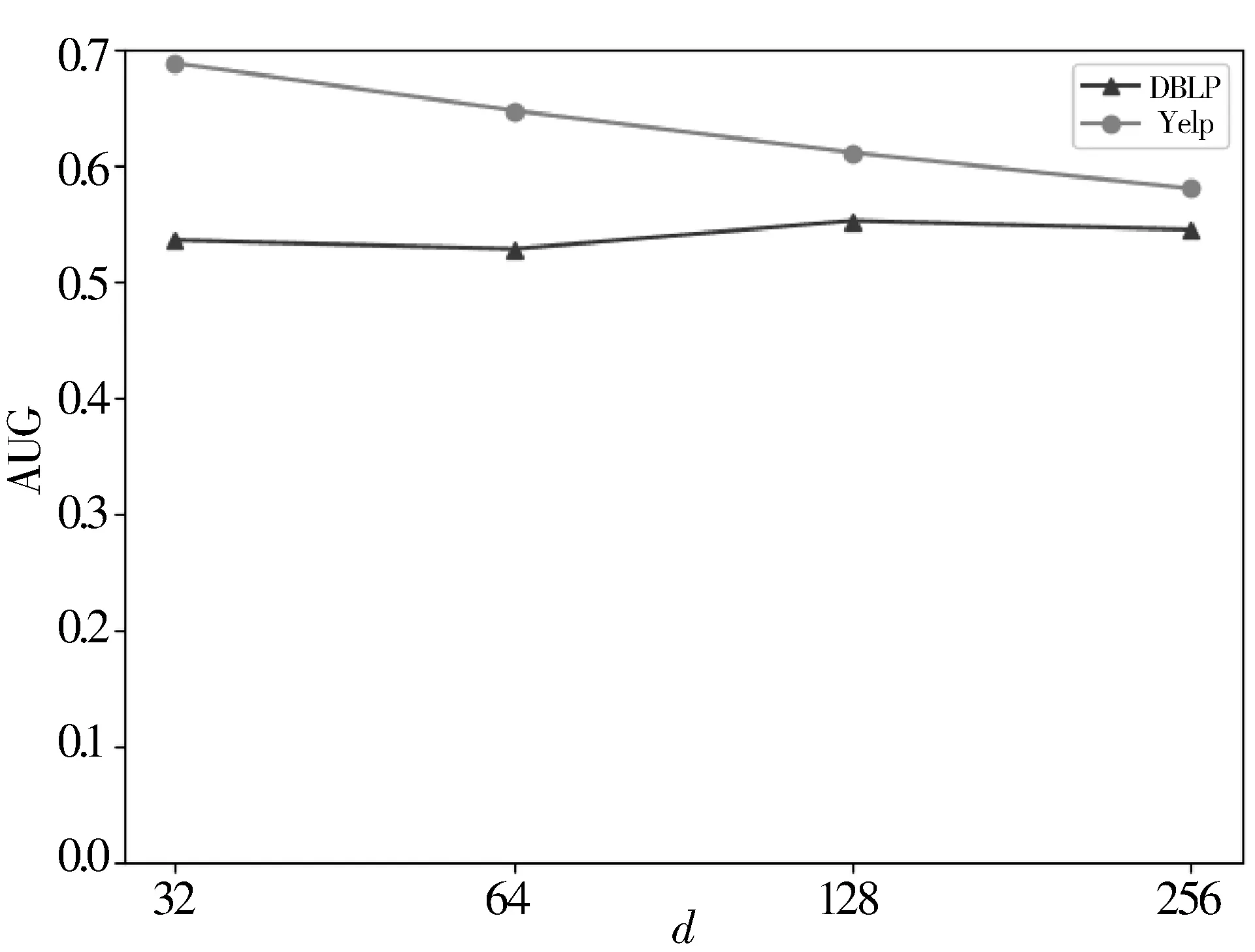
3: forn=0;n 4: Sample a real distributionZ′~p(Z) 5: Generate a fake distributionZ~q(Z) 6: UpdateθDaccording to Equation(7) 7: end for 8: forn=0;n 9: Generate a fake distributionZ~q(Z) 10: UpdateθGaccording to Equation(5) 11: end for 12: end while 13: returnθGandθD 如算法1所示,判别模型主要是根据公式(7)来判断输入是生成的假数据还是从高斯分布采样的真数据,然后,更新相关参数。生成模型则是生成接近真实数据的假数据,然后根据公式(5)来更新相关参数。 本次实验选取了2个经典的数据集DBLP和Yelp,下面分别介绍这2个数据集: 1)DBLP是收集了计算机领域内对研究的成果以作者为核心的一个计算机类英文文献的数据集。在本文中,主要从数据库、数据挖掘、机器学习和信息检索4个研究领域的20个会议中抽取了2018年发表的论文,构成以论文(P)、作者(A)、会议(C)为节点,以论文作者(P-A)、论文地点(P-C)为边的网络,该网络的网络模式如图3(a)所示。 2)Yelp是一个社交媒体数据集,包含了美国最大点评网址Yelp的数据,在Yelp数据集挑战中发布。本次实验提取了商户最多的5个城市(Las Vegas、Phoenix、Toronto、Charlotte、Scottsdale)的数据,形成了以用户(U)、商户(B)、类别(T)和城市(C)为节点,以商铺城市(B-C)、用户评论关系(B-U)和商铺类别关系(B-T)为边的网络,该网络的模式图如图3(b)所示。 图3 构建的网络模式图 本文实验中,从上述2个网络中抽取的节点数统计于表1中。 表1 节点数统计 datasetsdatasetconstituentsDBLPPaperAuthorConf4469727620YelpUserBusinessCategoryCity106701374710305 本文将对以下3种方法开展对比实验和分析:HIN2Vec[12]、Esim[10]、本文方法HINGAN。 1)HIN2Vec。 该框架的核心是一个神经网络模型,旨在利用节点之间不同类型的关系来捕获HINs中嵌入的丰富语义。同时联合学习了节点和关系的表示,以保留丰富的语义信息。 2)Esim。 基于元路径的同类型节点间的相似性搜索方法,模型接受用户定义的元路径,以此为指导学习节点的隐含表示,然后使用向量的余弦相似性度量节点间的相似性。 3)本文方法HINGAN。 该方法通过引入GAN,通过GAN的生成模型和判别模型的博弈过程,得到保留更多信息的表示。 本文的默认参数选择了2种对比方法的原论文中设置的最优参数。对于HIN2Vec方法,节点向量的维数d设置为128,负采样数n设置为5,上下文窗口w设置为3,学习率r设置为0.025。对于Esim方法,节点向量的维数d设置为50,负采样数n设置为5,上下文窗口w设置为4,学习率r设置为0.025。在本文方法中,节点分类和链接预测任务使用了同样的参数,其中维度d设置为128,判别模型和生成模型的学习率r都设置为0.001。语义保留模型的学习率r设置为0.05,负采样数n设置为5,上下文窗口w设置为3,游走长度l设置为10。 本文的评估指标选用节点分类和连接预测常用的评估指标。节点分类任务选用宏观f1值(macro-f1)、微观f1值(micro-f1)和精确度(precision),链接预测选用AUC评分平均精度(AP)。 4.4.1 节点分类 节点分类是评估网络表示学习模型的方法之一。在本实验中,使用的分类器是一个具有五折交叉验证的线性SVM分类器。标签设置如下: 在Yelp中,选择餐厅类别中的10种主要菜系作为标签,对餐厅节点打标签。在DBLP中,使用4个研究领域作为标签,如果作者在某个会议上发表了该领域的文章,就为他分配一个标签,形成一个标签数据集,用于对作者进行分类。对于节点分类任务,当学习节点的表示时,在Yelp中去掉类别节点T、DBLP中删除会议节点C。 本节点分类实验中,节点分类的结果如表2所示。其中,HINGAN-G和HINGAN-U分别表示采用高斯分布和均匀分布为真实数据的实验结果。 表2 节点分类结果统计表 methodDBLPYelpmicro-f1macro-f1precisionmicro-f1macro-f1precisionEsim0.20420.10640.12280.17990.09200.1233HIN2Vec0.25200.13400.31110.21680.10610.1347HINGAN-G0.29810.20570.26020.30390.18480.1858HINGAN-U0.27720.19060.27460.26680.15010.1399 表2的实验结果表明,真实数据服从高斯分布或均匀分布时,本文提出的方法除了在DBLP数据集上的precision外整体上都优于对比方法。而HINGAN-U的各项指标也是除了在DBLP数据集上的precision外整体上都略低于HINGAN-G,因此,下面其它的实验结果都是采用高斯分布作为真实数据。 在图4中,展示了在DBLP和Yelp数据集上的分类结果。从图4中可以看出,在DBLP数据集上,本文方法HINGAN的micro-f1值达到0.2981,相对于HIN2Vec方法提高了4.61个百分点,相对Esim方法提高了9.39个百分点。在Yelp数据集上,本文方法HINGAN的micro-f1值达到0.3039,相对于HIN2Vec方法提高了8.71个百分点,相对Esim方法提高了12.4个百分点。 图4 3种方法节点分类micro-f1值对比 本文节点分类实验中,还验证了嵌入维度d对节点分类结果的影响。其中,分别实验了维度d取32、64、128和256时,3个节点分类指标值的变化。如图5~图7所示。 图5 维度d对precision值的影响 图5显示了随维度d变化,在DBLP和Yelp数据集上precision值的变化。从图5可以看出,随着d值的逐渐增大,precision值整体上呈现先降低,再升高,最后又降低的趋势。 从变化趋势来看,当d=32时,在DBLP数据集上,precision的值接近0.3,达到了最大。在Yelp数据上,precision的值在0.13左右。当d=64时,precision值下降,然后,当d=128时,在DBLP和Yelp数据集上,值上升,但当d=256时,值又开始下降。 图6和图7展示了随着d的变化,在DBLP和Yelp数据集上micro-f1和macro-f1值的变化趋势,实验结果表明:在DBLP数据集上,随着d的增加,micro-f1和macro-f1值呈上升趋势;在Yelp数据集上,随着d的增加,micro-f1先上升后下降,当d=128时,micro-f1和macro-f1都达到极大值。 图6 维度d对micro-f1值的影响 图7 维度d对macro-f1值的影响 综合图5~图7中本文方法在数据集DBLP、Yelp的实验结果来看,当d=128时,precision、micro-f1、macro-f1总体效果最优。因此,本文选取维度d为128。 4.4.2 链接预测 表3 链接预测实验结果统计表 methodDBLPYelpAPAUCAPAUCEsim0.85330.90080.54110.6650HIN2Vec0.49650.56590.43590.3737HINGAN0.54860.57350.56730.6111 在本文链接预测实验中,数据集被分成训练集和测试集,比例为9:1。表3展示了链接预测的实验结果。可以看出,本文方法HINGAN的链接预测结果相对于对比方法HIN2Vec有了明显提高;对于Esim方法,由于其元路径长度为4,包含了更多的语义信息,在DBLP上的链接预测效果更好。 图8展示了2个数据集上本文方法和2种对比方法的链接预测结果AP值的变化情况。在DBLP数据集上,本文方法比HIN2Vec方法高出了5.21个百分点。在Yelp数据集上,本文方法比HIN2Vec高出了13.14个百分点,比Esim实验结果高出2.62个百分点。 图8 3种方法的链接预测AP值对比 从图8可以看出,在数据集DBLP上Esim方法的链接预测指标AP的值比本文方法的高,主要原因是:链接预测任务中,本文方法为统一参数,链接预测任务与节点分类任务的上下文窗口w均为3,可得到的元路径长度最多为3。而对比方法Esim中DBLP数据集的元路径定义为A-P-C-P-A,其长度为4,它包含了更多的语义信息。因此,在DBLP数据集上,Esim方法链接预测的结果要更好。 在链接预测任务中,本文还在2个数据集上测试了维度d对AP和AUC值的影响,结果如图9和图10所示。 图9 维度d对AP值的影响 图10 维度d对AUC值的影响 从图9可以看出,在Yelp数据集上,随着维度d的增加,链接预测指标AP的值逐渐下降;在DBLP数据集上,随着维度d的增加,AP的值缓慢上升。 从图10可以看出,在Yelp数据集上,随着维度d的增加,链接预测指标AUC的值呈下降趋势;在DBLP数据集上链接预测的AUC值趋于平稳。综合AP、AUC值随着维度d的变化来看,Yelp数据集上d=32时效果最好,DBLP数据集上d=128时效果较好。考虑到在节点分类中,维度d=128时效果最优,本文链接预测设置维度d=128。 本文提出了一种异构信息网络表示学习方法HINGAN,通过引入GAN,增强异构信息网络中语义信息的保留,为下游任务奠定基础。在HINGAN中,设计了一个生成模型和判别模型,判别模型能区分出真实数据和生成数据,生成模型生成一个接近真实数据的假数据,然后生成模型和判别模型进行博弈,最终使得网络的嵌入表示更加稳健,保留的语义信息更多。本文在多个数据集上的实验结果验证了HINGAN方法在节点分类和链接预测任务上的有效性。下一步考虑将GAN用于带属性信息的异构信息网络,以增强异构信息网络的属性信息的保留。4 实验分析
4.1 数据集
4.2 对比方法及默认参数
4.3 评估指标
4.4 实验结果分析

5 结束语
猜你喜欢
小学教学研究(2022年5期)2022-04-28数学年刊A辑(中文版)(2020年2期)2020-07-25数学物理学报(2019年6期)2020-01-13商周刊(2019年1期)2019-01-31唐山师范学院学报(2018年6期)2018-12-25计算机测量与控制(2017年6期)2017-07-01中国交通信息化(2017年12期)2017-06-06中央社会主义学院学报(2017年1期)2017-04-16中国洗涤用品工业(2017年2期)2017-04-16通信电源技术(2016年6期)2016-04-20
