
东巴象形文字特征部件的自动计算与提取算法
2020-06-06 01:33康厚良杨玉婷
湖北民族大学学报(自然科学版) 2020年2期
康厚良,杨玉婷
(1.苏州市职业大学 体育部,江苏 苏州 215000;2.苏州市职业大学 计算机工程学院,江苏 苏州 215000)
东巴文是一种十分原始的图画象形文字[1],作为人类早期图画文字向象形文字、标音文字过渡的文字形式,它既具有图画文字以图表意的特点,又具有象形文字象形、会意、指事、形声的功能[2].2003年,使用东巴文撰写的东巴古籍被联合国教科文组织列入世界记忆遗产名录[3-4].

表1 东巴字素的分类
Tab.1 Classification of Dongba hieroglyphic

图1 字符的二值图及不同分辨率的采样结果Fig.1 Binary map and sampling results of different resolutions

(1)小图的特征曲线及简化图 (2)大图的特征曲线及简化图图2 不同采样下东巴字的特征曲线和简化曲线Fig.2 The feature curve and simplified curve of Dongba character under different sampling
从文字的结构要素分析[5-7],东巴字可细分为单素字和复素字,如表1所示.单素字作为东巴文字的基本结构,它的图画特性使人们研究文字特征时可以参考计算机视觉中形状的处理方法[8-12].提取单素字轮廓的特征部件,分析其中所包含的共性元素,对于研究东巴象形文字的分类算法,分析同类单素字的结构特征,研究东巴文字的造字方法有着非常重要的意义.
目前,对东巴字的检索和识别研究主要围绕东巴字的预处理[13-14]、东巴字的特征提取[15-17]、文字识别[18-21]等3方面展开,涉及东巴字的基础分类[13]、文字图像去噪、线条细化、字符特征曲线提取[15-16]、简化[16]及识别[17-20]等内容.而关于东巴文字特征部件提取的相关研究很少,仅在讨论CDPM算法时有少量涉及字符局部特征曲线提取的内容[16].
在形状匹配领域中广泛应用的部件表示法(part-based representations)能够有效提高形状识别算法的健壮性,同时在形状分类理论中也发挥着重要作用[21].因此,深入分析东巴象形文字的图画特征,结合形状匹配领域中的部件表示法,给出了一种适用于东巴象形文字的特征部件自动计算与提取算法(automatic calculating and extracting feature parts,ACEFP).该算法通过双分辨率采样独立分析单个文字的轮廓特征曲线并自动提取东巴字的特征部件,然后使用少量样本即可准确计算同类字符的特征部件数量,与传统的形状局部特征曲线提取算法相比[22-24],ACEFP能够自动完成对象特征曲线中特征部件的提取和统计工作,得到的解稳定、可靠,保证了同类文字所包含的特征部件及数量完全保持一致.
ACEFP算法包括3个部分:①独立分析单个文字的特征,提取字符的特征曲线;②提取东巴字的特征部件;③使用少量样本统计同类文字应包含的部件数量.
1 东巴字的特征分析
特征部件指的是从对象特征曲线中提取的直观的、容易被观察者直接获取的包含对象局部特征的曲线[21].为了保持人类观察事物的习惯并使用计算机自动提取东巴字的特征部件,使用双分辨率采样法在快速获取东巴字整体特征的同时,还能保留其细节特征.其中,低分辨率采样能够保留字符的整体特征,减少字符特征曲线中潜在的异常点(特别是凹点),更容易确定局部曲线的分割点.但是,由于低分辨率采样可能存在细节特征丢失过多的情况.因此,以高分辨率采样获得的字符特征曲线作为部件提取的对象,参考低分辨率特征曲线中获得的分割点完成高分辨率特征曲线的分割,使得到的特征部件完整、有效,且能够保留字符的绝大多数特征.虽然高分辨率采样也包含字符的总体特征,但是由于其中存在较多的噪音点和异常点,容易影响特征部件分割点提取的准确性,因此将两者结合起来,最大限度弥补各自的不足.
以字符外接矩形中较短的边为基准,通过多次试验,最终选择短边长为50像素的采样作为低分辨率采样,而短边长为75像素的采样作为高分辨率采样,采样结果如图1所示.为了方便描述,将低分辨率采样得到的采样图称为小图,而将高分辨率采样得到的采样图称为大图.
然后,采用基于链码的连通域优先级标记算法(CDPM)和东巴象形文字特征曲线简化算法[16]提取东巴字的特征曲线、去除曲线中的冗余点和异常点.对图1中采样字符的处理效果如图2(1)、(2)所示.此时,由小图得到的简化结果,其局部特征曲线分割点显著,噪音点较少,但部分细节特征丢失严重;而大图得到的简化结果,几乎保留了文字的所有细节,但曲线中存在较多的噪音点和冗余点.因此,采用两种不同分辨率采样弥补了各自的不足.

(1)轮廓曲线 (2)曲线中的凹点 (3)分割图图3 小图采样的字符轮廓及分割Fig.3 Character contour and segmentation of small image sampling

图4 直线段的合并Fig.4 Merging of straight line segments

(1)曲线分割 (2)2点曲线的合并 (3)3点曲线的合并图5 局部曲线的合并Fig.5 Merging of local curve
2 特征部件的提取
曲线的凹凸特性是人类视觉识别的重要特性[25],在形状匹配领域常使用形状中的凸弧来表示形状的局部特征[26],因此,以字符特征曲线中的凹点[27]作为分割点完成曲线的分割.
由于小图中包含的顶点数量较少,意味着其中可能潜在的冗余点和异常点也较少,更容易得到准确的特征部件分割点.因此,以小图的字符特征曲线为处理对象,标记曲线上的凹点,并以凹点为分割点实现字符特征曲线的初次分割,分割过程如图3(2)、(3)所示.
显然,仅仅依靠凹点分割得到的局部特征曲线过细、过碎,并且还包含若干无效曲线.为保证每个特征部件都至少包含一个特征,需要对曲线的分割结果进行合并.分析图3(3)的分割结果可知,需要合并的局部曲线包含两种类型.
1)由两个连续凹点组成的曲线,如图3(3)中的①所示.它实际上是一条直线段,线段的端点是两个连续的凹顶点,这类曲线不包含字符的任何特征,可以合并.
2)由1个凹顶点+1个凸顶点+1个凹顶点等3个顶点组成的局部曲线,这类曲线有的包含了字符的特征,如图3(3)中的②包含了“鹿”犄角的一个尖端,不应被合并;而与②相邻的曲线段③,它虽然也和②具有相同的结构,但是它不包含任何字符特征,应被合并.因此,对于此类曲线,若满足条件,才可以合并;否则,保留.
2.1 直线段合并
根据东巴象形文字特征曲线简化算法可知[16],在曲线简化的每个阶段,一般使用一条新的线段替换原有的一对相邻的线段s1和s2,这条新的线段是通过连接s1∪s2的两个端点得到的,而线段的合并顺序按照度量K值从小到大的顺序进行,K的计算公式为:
其中,β(s1,s2)为线段s1和s2的顶点转向角,而l表示归一化后的线段长度.由于K(s1,s2)∝β(s1,s2).因此,局部直线段应与K值(或β值)较小的一端合并,保留K值较大的一端.如图4所示,假设待合并的直线段是由顶点P1和P2组成的C2,而C1和C3是与C2相邻的局部曲线段,那么若转向角β12>β23,则C2与C3合并;否则,C2与C1合并.
2.2 由三个顶点组成的曲线合并
由三个顶点组成的局部曲线可能包含字符的独立特征,例如“嘴巴”、“耳朵”或者“犄角”等,此时组成曲线的两条线段一般都有较大的转向角以表征字符特征,并且该转向角与曲线段中唯一的凸顶点相对应,因此当曲线中凸顶点的转向角≥90°时,保留原曲线;否则,合并.
合并时,由于三个顶点组成的曲线中包含两条线段,因此,将两条线段分别与它邻近的曲线合并即可.如图5所示,小图的特征曲线经过两次合并,字符中所包含的局部曲线由原来的13条减少到7条,且每条都包括至少一个或多个字符特征.
通过合并,每条局部曲线都至少包含一个或多个形状特征,但是合并过程也可能造成原有分割点由凹点变为凸点,使局部特征曲线的完整性受到影响.因此,合并后需进一步校正分割点,保证所有分割点都为凹顶点,如图6所示.

(1)分割点校正前 (2)分割点校正后图6 分割点的校正Fig.6 Correction of split point
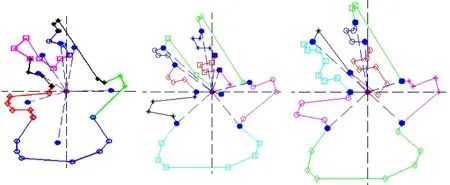
图7 提取字符的特征部件Fig.7 Extracting feature parts for characters
2.3 提取字符的特征部件
通过合并,组成小图轮廓的局部特征曲线已相对合理,如图7(1)、(2)所示.因此,以小图得到的分割点为参考,对大图的特征曲线进行分割,从而获得字符最终的特征部件.
提取大图特征部件的关键是找到大图特征曲线中与小图中对应分割点最相似的凹点,并将其作为大图特征曲线的分割点.为判断凹点的相似性,分别做轮廓外接矩形中心点与分割点的连线,则特征曲线中的顶点(包括分割点)均可以用中心点与顶点组成的向量来表示.那么,判断两个顶点(或顶点与分割点)的相似性,实际上就是判断两个向量的相似性,因此满足两个条件:①向量间的夹角应最小;②归一化的向量模的差值最小,即:

则θi为:
由于字符特征曲线中的分割点是特殊的顶点,它除了具有顶点的属性外,还起到分割局部曲线的作用.因此,使用下标vi和svi分别表示普通顶点和分割点,则对于由m个顶点组成的小图,它的顶点和分割点的下标为svi和ssvi;而由n个顶点组成的大图,它的下标为bvj和bsvj.那么,小图特征曲线中的分割点向量与大图中顶点向量间的夹角Δθ为:
Δθij=|θsvi-θbvj|i∈{1,2,…,m},j∈{1,2,…,n}.
同时,设大图的外接矩形在x方向上的长度为Lenbx,y方向为Lenby,而小图的分别为Lensx和Lensx.则将大图统一为小图的比例,大图中的顶点向量表示为:
而小图中的分割点向量表示为:
则大图的顶点向量和小图的分割点向量之间的模长差为:
因此,在所有的大图顶点中,与小图中的第i个分割点Pssvi最为相似的大图顶点Pbvj为:
Similar(Pssvi,Pbvi)={Pssvi→Pbvi|min{Δθij*ΔLenij}},i∈{1,2,…,m},j∈{1,2,…,n}}.
如图7(3)所示,根据小图的分割点重新分割大图的特征曲线,大图所包含的局部特征曲线由原来的10条减少到了8条.显然,通过二次分割及合并,已得到相对合理的字符特征部件.
3 同类东巴字的特征部件数量统计
使用第2章中的操作步骤提取“牲畜”类中10个东巴字的特征部件结果如表2所示.除了两个较特殊的字符外,其他字符的特征部件均为5个,分别描述了字符的两个犄角、耳朵、嘴巴和上半身.由此可知,“牲畜”类东巴字的特征部件数量为5条.
表2 同类字符的特征曲线
Tab.2 Feature curves of the same type of characters


图8 按同类型字符部件数量合并字符的局部曲线Fig.8 Merging local curves according to the number of character parts of the same type
东巴字“鹿”的特征部件过多是由于与其他文字相比,它的犄角包含了过多的细节特征.但是,这并未影响到“牲畜”类字符特征部件数量的统计.说明,即使字符包含较多细节特征,也不会对统计结果产生过大的影响,并且通过对字符“鹿”在图7(3)中的局部曲线进行进一步合并,发现它的特征部件呈现出与“牲畜”类字符相一致的局部形态特征,如图8所示.
4 算法的复杂度分析
ACEFP包括3个组成部分.若假设字符G的特征曲线为Cur,其中包含p个顶点,m条局部曲线,k个特征部件,且m≥k.本质上k即为最终统计得出的部件数量,那么:
1)提取字符特征曲线.本阶段采用CDPM算法和东巴文字简化算法实现字符特征曲线的提取及简化操作,由于两种算法的时间复杂度均为O(p),因此本阶段的时间复杂度O(n1)≈O(p).
2)提取字符的特征部件.本阶段包括3个步骤:①以凹点为分割点完成字符特征曲线的初次分割,时间复杂度为O(p);②判定m条局部曲线的类型完成局部曲线的初次合并(包括直线段合并和三点合并),时间复杂度为O(m);③将局部曲线合并为指定的k个特征部件.最坏情况下,在上一个步骤中没有任何曲线发生合并,则此时的时间复杂度为O(m).因此,本阶段的时间复杂度O(n2)=O(p)+O(m)+O(m),由于p≫m>k,可得O(n2)≈O(p).
3)统计同类型东巴字的部件数量.由于同类型东巴字的个数十分有限,因此本阶段的时间复杂度O(n3)=1.
由上可知,东巴象形文字特征部件的自动计算与提取算法的综合时间复杂度O(n)=O(n1)+O(n2)+O(n3)≈O(p),说明算法的时间复杂度是线性的.
5 验证性试验
5.1 准确性测试
为验证ACEFP的正确性,选取10类具有相同特征的东巴字符作为样本,其中包括:鱼虫、鸟、花、手、山、房屋、水、祭祀、牲畜和山坡等.由于每种类型所包含的字符数量不同,随机选择每类的前一半作为训练样本用于计算该类型所包含的特征部件数量,而剩下的另一半作为测试样本,用来检测分割及合并算法的准确性,如表3所示.

表3 10类东巴字符列表
Tab.3 List of 10 types of Dongba characters
测试时,根据每类特征部件的数量分割测试文字,测试结果如图9所示.测试文字中,小图的特征部件提取正确率为100%,而大图的为93.5%,其中,鸟类、手类和牲畜类的大图部件提取均出现了1个错误,这是因为与其他类型的文字相比,它们在某些局部的变异较大而引起的.

图9 测试文字的分割结果Fig.9 The segmentation result of testing characters

图10 按照不同类别的特征部件数量合并待测字符的局部曲线Fig.10 Merge local curves of characters according to the number of feature parts of different types
另外,在实际应用中,由于待测文字的类别是未知的,需按照各类字符所包含的部件数量对待测字符进行合并,然后将得到的结果与模板字符的特征部件逐个进行比较,以此确定待测字符所属的类别及所包含的部件数量.根据表3中的分类可知,“山”类和“房屋”类均包含1个部件,“水”类、“手”类、“祭祀”类和“山坡”类包含2个部件,“鸟”类包含3个部件,“鱼虫”类和“花”类包含4个部件,“牲畜”类包含5个部件.因此,以字符“鹿”为待测文字,从表3的每一类中选择1个东巴字作为模板字符,按照特征部件数量为1~5的顺序提取各模板字符的部件,同时合并待测字符的8个部件,合并结果如图10所示.
图10中,根据模板字符所属类别包含的部件数提取部件并按照部件数量进行归类,然后将待测字符“鹿”的部件数按照1~5的顺序进行合并,并按部件数量归类到每一行.容易发现,与每行的前几个模板字符比较,当“鹿”的部件数为5时,部件的分割点选择合理、独立性好,并与模板字符有较好的对应性;而当“鹿”的部件数为其他值时,它与该行的前几个模板字符也具有较为明显的差异性,说明ACEFP算法在保证字符局部特征完整性的同时,也能与其他无关字符显著区分,在显示字符整体曲线特征的同时,通过特征部件也能充分反映字符的局部特征.
5.2 鲁棒性测试
测试算法鲁棒性时,首先采用数据增广技术通过对待测字符进行旋转、压缩和拉伸、左/右倾斜等变换,然后使用ACEFP算法提取各个字符的特征部件,结果如图11(见下页)所示.图11中的第1行为字符“鹿”的变换结果,第2行为字符小图采样的特征部件,第3行为字符大图采样的特征部件.显然,当字符发生少许形变时,仍然能够得到正确的、基本一致的特征部件,说明算法的鲁棒性较好,且具有良好的尺度、平移和旋转不变性.
6 结语
东巴文字作为一种图画象形文字,具有非常浓厚的图画特征,因此,结合形状匹配领域中的部件表示法,给出了适用于东巴象形文字的特征部件自动计算与提取算法(ACEFP).与传统的形状局部特征曲线提取算法相比,ACEFP算法对字符特征部件的提取及部件数量的统计都是自动完成的,不需要任何人为的干预,这使得整个部件提取过程更加客观,而由此所得出的确定解也为研究东巴文字的组成结构、造字过程等提供有力的技术支持.
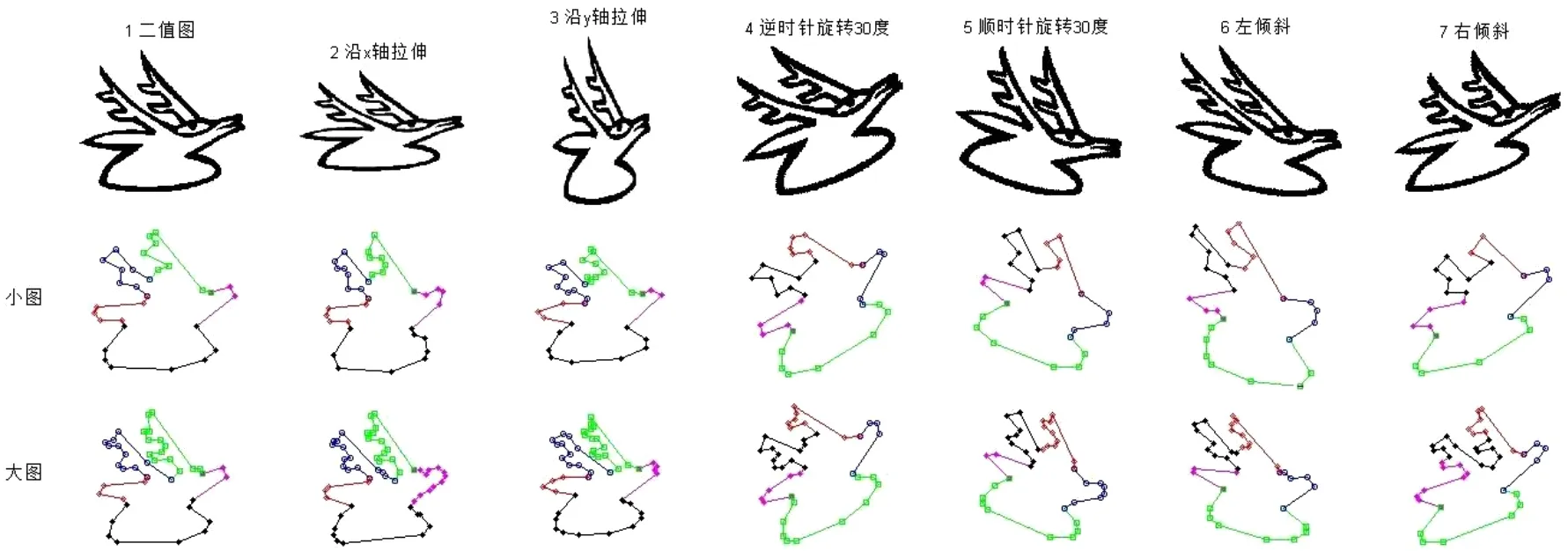
图11 形变字符的特征部件Fig.11 Feature parts of deformed characters
猜你喜欢
云南档案(2021年1期)2021-04-08
壹读(2019年6期)2019-12-18
环球慈善(2019年6期)2019-09-25
读友·少年文学(清雅版)(2019年10期)2019-05-21
读者(2019年6期)2019-03-07
小天使·二年级语数英综合(2018年10期)2018-10-15
小小艺术家(2018年8期)2018-10-11
小朋友·快乐手工(2018年7期)2018-08-15
大众文艺(2015年14期)2015-03-12
西南学林(2013年1期)2013-11-22
