
基于长短期记忆网络的协同过滤算法研究
2020-06-06 01:33张素智李鹏辉陈小妮
湖北民族大学学报(自然科学版) 2020年2期
张素智,李鹏辉,陈小妮
(郑州轻工业大学 计算机与通信工程学院,郑州 450000)
电子商务平台和社交服务网站,如Reddit、亚马逊和Netflix,每秒钟都吸引着成千上万的用户,因此有效向用户推荐合适的服务项目是这些在线服务的一项基本重要任务.在信息过载的时代,推荐系统是在线服务的基础,在在线购物、电影、音乐和新闻阅读等领域获得了巨大的成功.其中最具代表的是协同过滤算法(collaborative filtering,CF),它广泛地应用在推荐系统领域中,并能很好地处理信息过载问题[1],但是随着时间的推移,用户的偏好和项目的特征会随着时间而改变,数据特征都是动态的[2],而捕捉动态特征对于获得更精确的推荐非常重要,传统的CF以静态的方式建模用户项目交互,只能捕捉用户的长期偏好,没有考虑数据的时效特征,这使传统CF推荐的准确性到达了相对的瓶颈期[3].
近年来,循环神经网络(RNN)在用户短期偏好建模方面显示出了巨大的优势,尤其是在自然语言处理领域,RNN方法已经成为序列推荐的主流模型[4],而其中长短期记忆网络(long shot-term term memory,LSTM)作为特殊的RNN门控模型,被许多人进行了改进,从而解决序列的长时间依赖问题[5].
在本文中,为了解决用户项目交互行为的时效特征对推荐准确度影响的问题,提出基于LSTM的协同过滤算法模型LSMF,其利用经典LSTM中的门控机制加入时间感知特性,并采用注意力机制来动态过滤用户行为序列中不相关的动作,从而可以很好地考虑上下文时间内容信息来循环控制状态转换,自适应融合用户的长短期偏好形成统一的项目表示空间,生成用户的下一项推荐.

图1 RNN结构示意图Fig.1 RNN structure diagram

图2 LSTM结构示意图Fig.2 LSTM structure diagram
1 相关研究
1.1 传统协同过滤算法

在现实生活中,用户的兴趣偏好会随着时间的不断变化而发生改变,但是传统的推荐方法忽略了这一问题,如果不考虑具体数据的时效特征,而采用统一的标准计算用户各个时间段的行为偏好,然后为用户推荐下一项目,这显然是不符合实际情况的.窦羚源等[6]通过在传统协同过滤算法中融入标签特征和时间信息,建模用户的兴趣偏好,但是未考虑用户行为长期偏好和短期偏好的自适应权重分配问题.
1.2 循环神经网络
近年来,在各种语音识别、文字建模、机器翻译、图形字幕等应用中,基于循环神经网络(recurrent neural network,RNN)的模型取得了很好的成果[7].RNN模型擅长对于序列和列表类型的数据进行分析,其隐藏状态随着序列的变化而动态变化,大大提高了顺序点击预测的性能.网络结构如图1所示.
RNN是一种具有多个隐藏层的递归体系结构[8],它由一个输入层、一个输出单元、多个隐藏层以及内部权重组成.隐藏层的激活值计算如下:
(1)

Wu C等[9]首次利用循环神经网络RNN来建模用户的时间序列行为,解决多个异构时序的推荐问题,但普通RNN假设序列中连续项之间的分布是均匀的,这些RNN的结构目标只是通过加入更大的时间尺度来捕获序列中的长期依赖关系.在实际的推荐系统中,预测目标的时间点与相关信息的时间点间隔可能会很长,而RNN的时间依赖性随序列中位置的变化而单调变化,很难学习这种长依赖关系.因此在行为建模场景中,普通RNN很难很好地对上下文进行建模.因此长短时记忆网络作为RNN的变体脱颖而出,LSTM是目前RNN中处理时序信息最先进的模型,能够很好的捕捉序列的长依赖关系[10].
本文使用LSTM循环神经网络来捕获用户和电影之间的时间序列长依赖关系,建立短期偏好模型,通过这种方式,能够以一种综合的方式预测未来的交互轨迹,其具体结构如图2所示,其中细胞状态ck是LSTM的核心,用贯穿细胞的水平线表示,细胞状态像传送带一样,它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNN.
在第k个交互步骤中,每个交互的隐藏状态hk由前一个隐藏状态hk-1、当前项目的嵌入向量xk和当前行为向量bk来更新,首先输入信息通过fk遗忘门的sigmoid单元进行过滤,通过查看hk-1和xk信息输出一个0-1向量,决定ck-1中信息是否保留在ck中,同时通过输入门ik决定哪些信息更新在ck中,如公式(2)所示.
fk=σ(Wf[hk-1,xk]+bf),
ik=σ(Wi[hk-1,xk]+bi),
ck=fk·ck-1+ik·tanh(Wc[hk-1,xk]+bc).
(2)
其中,W∈RD×D是可训练的参数,D表示RNN中输入嵌入和隐藏层的维数.fk、ik、ok分别表示遗忘门、输入门和输出门,ck表示传递的细胞状态,xk表示第K项的输入嵌入,σ是sigmoid函数.
更新完细胞状态ck后经过tanh层得到一个-1到1之间值的向量,将该向量与将输入经过输出门ok的sigmoid单元得到的判断条件相乘,就得到了最终该单元的输出,如下公式所示:
ok=σ(Wo[hk-1,xk]+bo),
(3)
hk=ok·tanh(ck).
(4)
Wu C Y等[11]通过采用LSTM学习用户和项目在每一时刻的动态隐表示,形成稳定和时变的两部分评分,通过聚合两类隐表示的内积实现单一时刻的评分预测,但是未考虑上下文内容语义的不规则性[12].因此本文将在第三章改进LSTM门控结构,使其能够融合时效特征和注意力机制,更好的模拟连续行为之间的状态演变.
1.3 推荐描述
给定目标用户u的行为序列su={(xu,v1,t1),(xu,v2,t2),…,(xu,vk,tk)},推荐任务是预测目标用户u在下一次访问中最有可能访问的项目vk+1,通过最大化一个模型函数值来生成一个由排名最高的项目推荐列表,如下公式所示:
R=argmax·f(s).
(5)
其中f(x)是一个模型激活函数,用于输出候选项目的排序分数.
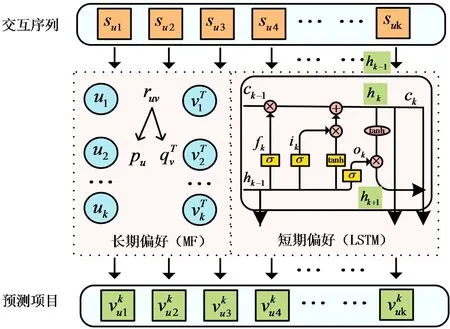
图3 LSMF结构示意图Fig.3 LSMF structure diagram
2 LSMF模型
LSMF模型的结构如图3所示.在交互序列su中,首先将输入按顺序项转换为统一的嵌入空间,然后基于LSTM体系结构学习短期偏好信息,再通过矩阵分解模型学习长期偏好信息,最后自适应融合两者得出预测项目.
实际生活中,用户项目的交互行为内容要复杂得多,而且面临着时间不规则性和语义不规则,例如两个连续行为之间的时间间隔可以是多种多样的,以及用户行为序列中的属性可能并不总是共享相同的语义.为了解决时间不规则问题,改进了LSTM中的门控逻辑,使其对时间变化敏感.为了解决语义不规则问题,融合了注意力机制的内容控件,来抑制偏离目标方向的交互信息.
2.1 融合时效特征
本节介绍了两个时间感知特征,即时间间隔特征δtk和时间跨度特征stk,时间间隔特征δtk编码两个连续状态之间的相对时间距离,而时间跨度特征stk编码当前状态tk与预测状态tp之间的绝对时间距离,当Wδ,Ws∈RD时,如下公式所示:
δtk=tanh(Wδlog(tk-tk-1)+bδ),
(6)
stk=tanh(Wslog(tp-tk)+bs).
(7)
当Wtδ,Wts∈RD×D,并添加一个完全连接的层,将时间感知特征转换为密集向量(δtkWtδ和stkWts),相应的时间门Tδ和Ts计算如下:
Tδ=σ(xkWxδ+δtkWtδ+btδ),
(8)
Ts=σ(xkWxs+stkWts+bts).
(9)
因此输入门ck和输出门ok更新如下:
ck=fk·Tδ·ck-1+ik·Ts·tanh(Wc[hk-1,xk]+bc),
(10)
ok=σ(xkWxo+δtkWδo+stkWso+hk-1Who+bo).
(11)
2.2 融合注意力机制
实际推荐中应为信息更多的行为分配更高的权重,因此在模型结构中引入注意力机制.项目的注意力分数由下式表示:
ek=[tanh(Wf[hk-1,xk]+bf)]T,
(12)
(13)
其中ek表示要进行预测的项目的嵌入向量,Wf为权重向量,bf为偏置向量,xj表示第j个交互行为,Wk为随机初始化的注意力矩阵,注意力评分ak决定了应根据目标项目强调或忽略哪些内容,利用这些分数来循环更新细胞状态和隐藏状态.如下公式:
(14)
(15)
这里不使用最后一个隐藏状态作为用户表示,而是将用户的短期形式表示为所有隐藏状态的加权平均值.
(16)

2.3 自适应融合方法
设计了一个自适应的信息融合方法,由特定的上下文决定长短期偏好的权重,可以很好的促进推荐结果的准确性.如下公式所示:
(17)
(18)

2.4 模型训练
将推荐任务描述为一个二进制分类问题,其中,负对数似然函数(log-loss)通常用作损失函数,如下公式所示:
(19)
其中N是培训实例的总数,Θ表示可训练参数集.yi=1表示正实例(用户已与项目交互),yi=0表示负实例.模型优化过程是将损失函数与正则化项λ*‖Θ‖2一起最小化,防止过拟合.
3 试验结果分析
3.1 试验数据集
为了研究LSMF模型的有效性,本文在Netflix竞赛数据集上对LSMF模型进行了评估.Netflix数据集[13]由1999-12—2005-12收集的100 M评级组成,这个数据集大约给出了480 189个用户和17 770部电影评级,该数据集包含电影信息、训练集、测试集组成.电影信息的数据点由电影ID、上映年份、电影标题组成;训练集的数据点由电影ID、用户ID、评分(1~5)、时间戳组成;测试集数据点由电影ID、用户ID组成.详细数据如表1.
在下面的试验中,使用了一个包含40个隐藏神经元的单层LSTM,40维输入嵌入和20维动态状态,模型是在开源的深度学习框架TensorFlow上实现的,使用ADAM优化神经网络参数,并利用随机梯度下降(SGD)来更新潜在因子,学习率为0.001.

表1 Netflix竞赛数据集Tab.1 Netflix competition data set

表2 融合因子∂随时间间隔的自适应变化Tab.2 Adaptive change of melting factor ∂ with time interval

图4 不同融合因子∂对于LSMF模型性能的影响Fig.4 The influence of different fusion factors ∂ on the performance of LSMF model
将LSMF与两种传统方法(即BPRMF、LSTM)和两种基于RNN的最新模型(即NARM、T-LSTM)进行了比较.
BPR-MF[14]是一种广泛应用的矩阵因式分解方法,它通过随机梯度下降优化成对排序目标函数.
LSTM是序列推荐的经典循环神经网络模型.
NARM[15]是一种神经注意推荐机,它通过将注意机制纳入RNN来捕捉当前会话中用户的主要目的.
T-LSTM[16]为LSTM配备时间门来模拟时间间隔,与LSMF模型不同,它不能依赖于注意力机制来为信息更多的行为分配更高的权重.
3.2 评价指标
数据集的稀疏度计算公式:
(20)
其中suv表示用户项目交互行为的数目,sN表示用户向量与项目向量的乘积,即N∈m·n.
为了验证算法有效性,本文使用召回率(recall)和平均绝对误差(MAE)来评估预测结果.Recall@20召回率是在前20个项目中被召回的正确项目的比例,这是主要的评价指标,召回率越高,推荐模型的性能越好.平均绝对误差MAE也是一个常用的选择,由式(21)给出,同样平均绝对误差越低,推荐模型的性能越好.
(21)
3.3 算法性能试验
3.3.1 融合参数∂的取值比较 LSMF模型的自适应融合机制如式(18)会根据上下文时间内容信息自动获得参数∂的取值,本文根据用户最后一次交互行为和预测项目之间的时间间隔拆分测试实例,将测试数据的预测间隔时间划分为1 h、12 h、1 d、1周、1月、1 a,如表2所示.在1 h短期偏好模型的融合参数∂是0.79,而在1 a时短期偏好的融合因子∂是0.54,通过试验观察到,随着时间间隔的增长,短期偏好模型的融合参数不断减小,长期偏好模型的融合参数不断增大.但是间隔时间在1 a范围内,短期偏好模型的融合参数∂始终大于长期偏好模型1-∂,这意味着相对于长期偏好,短期偏好始终对于推荐结果有更重要的影响作用,而在预测时间间隔较长的项目时长期偏好的影响作用不断加大.
当时间间隔为1 h时,通过图4可以观察到,当∂=0时表示只使用长期偏好模型,预测的召回率Recall@20只有0.379 4,而当∂=1时表示只使用短期偏好模型,虽然与上下文时间内容切合,但是完全没有考虑长期偏好的影响,其预测的召回率Recall@20为0.538 7;当短期偏好的融合参数∂=0.79时,模型预测的召回率Recall@20为0.657 2,显然是最优解.可见根据上下文时间内容的不断变化,模型融合参数∂的取值也会变化,以使模型的推荐性能达到最优,因此采用自适应融合机制是非常必要和有效的.
3.3.2 数据稀疏度对于LSMF模型性能的影响 本文认为用户项目的交互稀疏度对推荐系统的性能有很重要的影响,因此为了比较不同稀疏度下的算法效果,本次试验根据时间分割数据获得不同稀疏度以模拟实际情况.将Netflix训练数据集划分4组,分别是1个月、6个月、1 a、全部,其稀疏度如表3所示.可以看出,随着划分数据的时长增加,稀疏度不断提高,这是因为随着时间规模的扩大,评分交互矩阵中更新了更多的新用户和新项目,虽然用户项目交互行为越来越多,但是相对于整体数据维数的增加,可提取的特征数目比例变得更少,导致稀疏度不断增大.

表3 Netflix 数据集分组稀疏度Tab.3 Netflix data set group sparsity
在不同稀疏度上分别测试LSMF模型的平均绝对误差MAE和召回率recall @20性能,依然选择预测时间间隔为1 h进行数据对比,如图5所示.通过图5(a)可以看出随着数据稀疏度提高时,LSMF模型的平均绝对误差MAE数值逐渐上升,在0.08%稀疏度时MAE为0.648 3,而在1.2%稀疏度时MAE为0.707 6,模型推荐效果逐渐变差.通过图5(b)可以看出,当数据稀疏度提高时,LSMF模型的recall @20数值逐渐下降,在0.08%稀疏度时recall @20为0.589 6,而在1.2%稀疏度时recall @20为0.497 2,模型推荐效果也是逐渐变差.通过在不同稀疏度上的两个评价指标可以看出,当数据稀疏度不断增加时,可用来学习的交互特征就会变得更少,不能很好的满足模型训练,推荐模型的准确度就会降低.

(a) (b)图5 不同稀疏度上LSMF模型的性能测试Fig.5 Performance test of LSMF model with different sparsity

图6 不同时间间隔下各个模型的性能评估Fig.6 Performance evaluation of different models at different time intervals
3.3.3 不同模型的recall性能评估 在不同时间间隔(最后一次评分与预测项目的时间间隔)上分别测试LSMF、BPRMF、LSTM、NARM、T-LSTM的recall @20性能,如图6所示.LSMF模型的性能在所有场景下明显优于所有其他方法.而不同方法面对不同时间间隔时的效果高低不同,这说明最后一次评分与预测项目的时间间隔确实会影响推荐系统的性能.通过间隔时间为1~24 h的数据可以看出,LSMF、LSTM、T-LSTM这三个具有短期偏好的模型性能要高于NARM、BPRMF,其中最好的LSMF模型的recall @20数值为0.657 0,最差的BPRMF模型的recall @20数值为0.302 5,因此在考虑预测较短时间的交互行为特征时,具有短期偏好的模型都比长期偏好模型BPRMF效果和注意力机制模型NARM效果要好,而通过间隔时长为1 a的数据可以看出,LSMF、BPRMF这两个具有长期偏好的模型性能要高于NARM、LSTM、T-LSTM,其中最好的LSMF模型的recall @20数值为0.687 6,最差的LSTM模型的recall @20数值为0.451 4,因此在考虑预测较长时间的交互行为特征时,具有长期偏好模型的LSMF、BPRMF效果要比LSTM、NARM、T-LSTM这些短期模型要好,即用户的历史稳定偏好在长时间的推荐性能上是有效的.
这其中LSTM仅获取用户项目交互矩阵的长依赖关系来推荐短期偏好,而BPRMF仅使用矩阵分解技术获取用户的长期稳定偏好,相对于前两者,T-LSTM模型在门控组件中加入了时间特性来模拟用户项目交互的动态特征,NARM模型融入了注意力机制,来捕获当前会话中用户的主要目的,因此T-LSTM和NARM的模型性能在大多数情况下都优于LSTM和BPRMF,而LSMF的短期组件部分则具有T-LSTM和NARM两者的全部优势,又自适应融合长期偏好部分,所以相对于其他四个模型,LSMF模型的性能表现的更加优秀,这也说明时效特征和上下文内容感知对于推荐短期偏好的准确度有很重要的作用.因此本文设计的具有时间感知和上下文内容感知的短期偏好部分,又自适应融合长期偏好部分的LSMF模型,更加善于处理来自用户项目交互的时效特征,从而获得更好的推荐准确度.
4 结语
本文提出了基于LSTM的协同过滤算法模型LSMF,并结合长期偏好综合用户目前的消费动机和历史上稳定的偏好获得更加准确的推荐.具体使用LSTM长短时记忆网络来捕获用户和项目的长时间依赖关系,并改进LSTM的门控结构,使其能够融合时效特征和注意力机制,更好的模拟连续行为之间的状态演变,并结合长期和短期偏好,自适应的形成统一的项目表示空间进行推荐.在Netflix竞赛数据集上与传统方法BPRMF、LSTM和两种基于RNN的最新模型NARM、T-LSTM相比,本文提出的LSMF模型在召回率(Recall)和平均绝对误差(MAE)上有了很好的提升,具有很好的推荐性能.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
纺织科技进展(2021年5期)2021-07-22
数学小灵通(1-2年级)(2020年11期)2020-12-28
家庭影院技术(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
小学生学习指导(低年级)(2019年3期)2019-04-22
燕山大学学报(2015年4期)2015-12-25
读写算·小学低年级(2014年4期)2014-07-24
火炸药学报(2014年1期)2014-03-20
