
融合基于语言模型的词嵌入和多尺度卷积神经网络的情感分析
2020-06-06 02:07赵亚欧张家重李贻斌付宪瑞
计算机应用 2020年3期
赵亚欧,张家重,李贻斌,付宪瑞,生 伟
(1. 浪潮集团金融信息技术有限公司,济南250101; 2. 济南大学信息科学与工程学院,济南250022;3. 山东大学控制科学与工程学院,济南250061)
(*通信作者电子邮箱zhaoyaou@inspur.com)
0 引言
情感分析(Sentiment Analysis)是对带有情感色彩的主观性文本或句子进行分析、处理和抽取的技术[1]。随着互联网技术的发展,人们的活动越来越多地集中在网络上,人们通过网络进行学习、交流、购物、娱乐,同时对社会热点事件、热门商品和相关服务进行评论。通过这些评论挖掘数据背后人们的观点、倾向是十分重要的,利用这些数据,政府部门能够及时作出反应,进行舆论引导,避免重大舆情事件;商户能够掌握用户需求,进行个性化精准营销;产品制造商也可以了解产品优劣,及时对产品进行改进。
从评论中自动提取用户观点并不容易,现在主流的方法主要有有监督和无监督两类。有监督方法主要是利用机器学习技术,如支持向量机(Support Vector Machine,SVM)、最大熵方法和朴素贝叶斯方法等[2-4],对文本进行学习,然后进行情感分类。无监督方法主要是分析文本中的情感词、语法和语义,通过抽取文本的统计特征实现情感分类。
深度学习是人工智能的一个热点,其方法也被广泛应用在情感分析领域。Socher等[5]于2011 年提出使用递归自编码网络(Recurrent Auto-Encoder,RAE)对文本特征进行抽取和分类。随后,Qian 等[6]提出使用动态卷积神经网络(Dynamic Convolutional Neural Network,DCNN)进行文本分类,DCNN 采用动态K-Max 池化操作,能够有效地捕捉词语之间的联系。Wang 等[7]提出利用长短程记忆(Long Short-Term Memory,LSTM)网络对推特文本进行情感分类,该方法利用LSTM的门控结构,能够更好存储文本特征。LSTM 随后被扩展为双向LSTM、叠层双向LSTM等一系列模型。此外,多种网络结构的融合方法也被提出,如Wang 等[8]提出的卷积神经网络(Convolutional Neural Network,CNN)和 循 环 神 经 网 络(Recurrent Neural Network,RNN)相结合的模型CNN-RNN、Guggilla 等[9]提出的LSTM-CNN 模型等。Akhtar 等[10]于2017年提出利用多个神经网络集成进行情感分类,也取得了很好的效果。
注意力机制最早应用于图像领域,它可以聚焦图像的特定区域,抽取图像的有用特征。2016 年,Bahdanau 等[11]最先把注意力机制应用到自然语言处理任务中,构造了当时性能最好的机器翻译模型。随后,研究人员也把注意力机制应用到情感分析任务中。曾锋等[12]将注意力机制和循环神经网络相结合,通过双层注意力分别对单词层和句子层进行建模,捕获不同单词和不同句子的重要性。曾碧卿等[13]将注意力机制和卷积神经网络相结合,提出一种双注意力机制的卷积神经网络模型,用来确定情感倾向。韩萍等[14]提出了基于情感融合和多维自注意力机制的微博文本情感分析模型,实现了文本中词语间依赖关系的建立以及多角度情感语义信息的获取。此外,石磊等[15]将注意力机制与树形结构的LSTM 网络相结合,提升情感分析的准确率。
使用深度学习技术对自然语言进行处理,另外一个重要的问题是如何将文字符号转化为数字特征。前人的方法大都利用Word2Vec、GloVe(Global Vectors)等词嵌入工具得到词语的嵌入向量(embedding)。但此类方法存在的主要问题是难以对多义词进行向量表示。比如苹果,由于上下文不同,可能表示的是一种水果,也可能是指苹果公司,甚至可能是指电影名称,然而,利用词嵌入技术,这三个不同的语义只会被表示为一个向量。为了解决这个问题,本文提出使用基于语言模型的词嵌入(Embedding from Language Model,ELMo)获取词向量。该模型获得的词向量不但包含词语本身信息,也包含其对应的上下文信息,能够表达多义词的不同语义。此外,针对中文环境下ELMo 难以训练的问题,本文提出使用预训练获得的字符向量初始化ELMo 的嵌入层,可加快模型的训练,提高训练精度。最后,针对情感分类,本文提出使用融合ELMo 和多尺度卷积神经网络(Multi-Scale Convolutional Neural Network,MSCNN)作为分类器。该模型使用不同尺度的卷积核对文本施加卷积操作,并利用最大值池化操作对获得的特征进行筛选,最后将这些特征融合,作为最终文本的特征。该方法考虑了不同尺度的短语特征,相较于单纯采用词向量或者字向量,效果更好。
1 相关工作
自然语言处理的核心任务是抽取语言文字表象符号背后的隐藏含义,得到计算机可以理解的数据化表征。一个好的数字化表征对于后续自然语言处理任务,如情感分析、语义分析、机器翻译等十分重要,是自然语言处理研究的热点。方法从早期的独热编码(One-hot),到词袋(Bag-of-words)模型,再到后来的tf-idf(term frequency-inverse document frequency),不断涌现。
最近几年,随着深度学习技术的发展,越来越多的学者尝试使用神经网络方法抽取词语的特征:2003年,Bengio等[16]提出了NNLM(Neural Network Language Model),利用三层神经网络学习语言模型,这是神经网络在自然语言表征方面的首次 尝 试;随 后 在2013 年,谷 歌 的Mikolov 等[17]在CBow(Continuous Bag-of-words)和Skip-gram 模型的基础上构建了Word2vec 工具,该模型使用两层神经网络,去掉了隐含层,简化了神经网络结构,并且使用噪声对比估计(Noise-Contrastive Estimation,NCE)和 层 级Softmax(Hierarchical Softmax)技术,减小了算法复杂度,使神经网络的大规模应用成为可能;同一时期,斯坦福的自然语言处理小组的Pennington等[18]提出GloVe算法,也取得了不错的效果。
随着研究的不断深入,开始从研究词语表征转向研究句子表征。2015 年Kiros 等[19]提出Skip-thoughts 方法。该方法首先利用循环神经网络(RNN)对句子进行编码,然后构造另外两个RNN 对句子进行解码,通过编码-解码模型获取句子向 量。2018 年,Logeswaran 等[20]在 此 基 础 上 提 出quickthoughts 方法,该方法去掉了解码过程,直接将句子的编码作为特征接入后续网络,简化了网络结构,提高了模型性能。
虽然句子表征取得了一定进展,但效果往往不佳。2017年,McCann等[21]提出了句子特征和词语特征的融合方法。首先在机器翻译语料上训练编码器-解码器(Encoder-Decoder)模型,然后抽取编码器的输出层和嵌入层(embedding),其中,编码器的结果作为句子特征,嵌入层作为句子中词语的特征,最后将两者融合作为最终特征。该方法的意义在于,对于每一个词语特征,都融入了该词语所在的句子特征,语义表示更加准确。
相对于词语,句子的复杂度更大,需要大规模语料作为训练集,但大多数自然语言处理任务的语料规模都很小。为了解决这个问题,人们开始探索预训练的方法。2018 年Cer等[22]提出在大规模语料中预训练句子向量,然后通过迁移学习技术应用到小规模任务中,但这些方法仅考虑了句子特征,而没有考虑句中的词语特征。
2 ELMo
Peters 等[23]于2018 年提出了ELMo。该方法结合了上述模型的优点,既采用预训练的方式,又注意融合词语和句子特征。算法主要分为两步:第一步是构建基于LSTM 的双向语言模型(bilateral Language Model,biLM),并在大规模语料上进行训练,获取模型参数;第二步是将文本输入biLM,抽取biLM 的输入层和隐含层,将其进行加权组合,获得文本的ELMo特征向量。
2.1 基于LSTM的双向语言模型
和Word2vec 的思想类似,ELMo 也是通过构造语言模型获取词向量的。一个含有N个词的句子S={t1,t2,…,tN},其出现概率P(t1,t2,…,tN)可以通过计算每个词tk的出现概率P(tk)得到,而P(tk)只与tk前面出现的词语t1,t2,…,tk-1有关,因此,P(t1,t2,…,tN)可以使用式(1)计算:
如果使用LSTM 对语言模型进行建模,则tk对应LSTM 隐状态hk。如果LSTM 存在L层细胞单元(Cell),则对应隐状态集合为。将最后一层的隐状态输入softmax层获得输出ok,ok代表语言模型中tk出现概率P(tk|t1,t2,…,tk-1)。
tk出现概率不但与其前面的词有关,也可能与其后面的词有关,因此需要构建后向模型。后向模型和前向模型一样,也采用一个L层的LSTM,将tN,tN-1,…,tk依次输入网络,得到隐状态集合。将隐状态输入softmax 层得 到 输 出o′k、o′k表 示 后 向 模 型 中tk出 现 概 率P(tk|tk+1,tk+2,…,tN)。
ELMo 所采用的biLM 模型如图1 所示,从图中可以看出,biLM 的核心是两个LSTM 网络,两个网络都由多层cell 组成(一般采用二层结构),一个网络负责前向语言模型的建模,一个负责后向语言模型的建模。为了保持网络训练稳定,在两层cell 之间加入残差连接。最终层的隐状态融合前后两个网络输出,通过softmax计算上下文条件概率。

图1 基于LSTM的双向语言模型(biLM)架构Fig. 1 Architecture of bilateral language model based on LSTM
模型采用的损失函数为句子中所有词tk对应概率乘积的似然,即:

其中:θ、θ′分别对应前向LSTM 模型和后向LSTM 模型的待优化参数。
2.2 ELMo特征向量
将后续分类任务中的文本输入biLM 模型,获取biLM 每一层隐状态,…,。将tk对应的词嵌入向量xk与每一层隐状态进行线性组合,获得tk的ELMo表示,其计算公式为:

其中:γ为缩放因子,sj为归一化的系数,表示每个特征的占比,这些参数都需要在后续任务中进行二次训练获得。
2.3 基于字符的卷积神经网络
在实际使用过程中,ELMo 的输入既可以是词向量,也可以是字符向量。如果输入的是字符向量,则需要额外添加一个基于字符的卷积神经网络(character Convolutional Neural Network,char-CNN),用其生成字符对应单词的嵌入向量。其对应的结构如图2所示。
这样做的优点是:1)能够避免词典外词语无法表示的问题(Out Of Vocabulary,OOV);2)无需存储词典中词语的词嵌入向量,只需存储char-CNN 的模型参数即可,减小了存储空间占用。
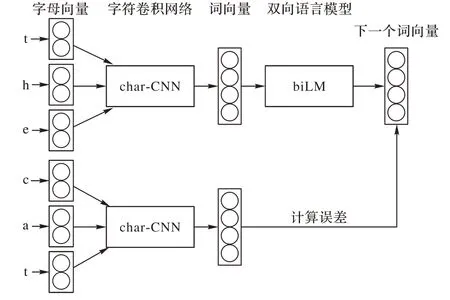
图2 char-CNN模型结构Fig. 2 Architecture of char-CNN model
3 ELMo和多尺度卷积神经网络融合模型
3.1 基于预训练字向量的ELMo
虽然采用基于字符的卷积神经网络有诸多好处,但如果直接迁移到中文语料中,还存在一定的问题。主要是因为英文字符的初始向量一般采用随机初始化的方式产生,但英文仅有26 个字母,加上特殊符号,也不会超过256 个。然而,中文系统中汉字数量一般都在5 000以上,如果也采用和英文相同的随机初始化方式,则向量的不确定性太大,后续char-CNN网络将难以训练。
为了解决这个问题,本文提出使用预训练的中文字符向量来初始化ELMo。该方法首先在大规模语料中预训练中文字符向量,然后将训练得到的字符向量作为char-CNN 模型的初始向量。这种方式预先加入了汉字的语义信息,与随机初始化相比,不确定程度大大降低,有助于加快模型的训练,提高训练精度。
该算法分为两步,第一步利用Word2vec 工具对汉字字符进行预训练,获取字符向量,其模型结构如图3所示。

图3 汉字字符向量预训练模型Fig. 3 Pre-training model for Chinese characters
具体做法是,对于第i个汉字,首先获取其独热编码bi,编码维数为汉字字典的大小Nchar,然后与嵌入矩阵Memb相乘(Memb∈RNchar×Dchar),得到维度为Dchar的紧致编码ci,再将其与上下文矩阵Mctx(Mctx∈RDchar×Nchar)相乘,经过softmax 激励,获得输出oi(oi∈RNchar)。最后,根据oi计算似然损失函数,并利用梯度下降法调整嵌入矩阵Memb和上下文矩阵Mctx。
第二步,使用预训练的嵌入矩阵Memb初始化char-CNN 的嵌入层,并进一步精调参数。
假设句子中第k个词为tk,将tk中每一个汉字的独热编码与矩阵Memb相乘,得到汉字对应的字向量,然后输入char-CNN 网络,进行卷积、池化操作,得到对应的词向量vk。对于tk的前驱词tk-1和后继词tk+1,按照同样操作得到对应词向量vk-1和vk+1。
将vk输入biLM 模型,生成其前驱词向量v′k-1和后继向量v′k+1。比对v′k-1、v′k+1与vk-1、vk+1,计算似然损失,据此调整ELMo 对应的模型参数,包括嵌入矩阵Memb,char-CNN 和biLM的参数。其模型结构如图4所示。

图4 基于预训练汉字向量的ELMoFig. 4 ELMo based on pre-trained vectors of Chinese characters
3.2 多尺度卷积神经网络(MSCNN)
ELMo仅仅对文本特征进行了编码,进行情感分类还需要一个分类器。常用的分类器有支持向量机(SVM)、卷积神经网络(CNN)和循环神经网络(RNN)等。
句子的含义通过其组成词语来体现,然而词语并不直接组成句子,而是首先组成短语,然后通过短语组成句子。与char-CNN 的思想类似,如果对词语进行卷积,则可以得出短语对应的语义向量,如果采用不同尺度大小的卷积核,则可以获得不同尺度的短语语义向量,将这些短语向量与词向量融合,作为句子最终的特征,其语义信息比单纯使用词向量要丰富许多。基于上述思想,本文构造了多尺度卷积神经网络分类器。
假设长度为N的句子所对应的词向量分别为v1,v2,…,vN,将N个 向 量 进 行 连 接,构 成 矩 阵V,即V=[v1,v2,…,vN],V∈Rd×N,其中d为词向量的维数。假设采用的卷积核为K,K∈Rd×w,w表示卷积宽度,则V通过K进行卷积运算的公式为:
其中:· 代表卷积操作,fi为卷积之后的特征,fi∈R,i∈{1,2,…,N-w+ 1}。
将得到的N-w+ 1 个卷积特征输入池化层,按照式(5)进行最大值池化运算,其公式为:

其中y∈R。
对卷积核K,矩阵V经过卷积、池化操作后可得到输出y。假设存在不同尺度的m个卷积核,如K1∈Rd×w1,Κ2∈Rd×w2,…,Km∈Rd×wm,则经过卷积操作会得到m个输出y1,y2,…,ym。将其连接成一个向量,得到Y=[y1,y2,…,ym],Y∈Rm,Y为不同尺度短语的融合特征。最后,将Y输入到两层全连接神经网络中,并利用softmax 激励实现分类。多尺度卷积神经网络(MSCNN)模型结构图5所示。

图5 多尺度卷积神经网络模型结构Fig. 5 Model architecture of MSCNN
3.3 基于ELMo和多尺度卷积神经网络的融合模型
基于上述模型,本文提出了基于ELMo 和多尺度卷积神经网络的融合模型用于情感分析。该模型主要由两部分组成:第一部分是利用ELMo 学习预训练数据,生成句子上下文相关的词向量;第二部分是利用多尺度卷积神经网络,对词向量的特征进行二次抽取,并进行特征融合,生成句子的整体语义表示。最后,经过softmax 激励函数实现文本情感倾向的分类。
该模型的优势在:1)ELMo 是预训练模型,通常在大规模语料上进行训练,生成的特征其泛化能力更强;2)ELMo 学习的词向量不但可以准确表示多义词的多个不同语义,而且还融入了词语所在句子的语义;3)该模型既利用了循环神经网络结构(ELMo 中的双向LSTM 网络结构),也利用卷积神经网络结构(MSCNN),相对于采用单一网络结构的方法,提取的特征更加丰富多样。
4 实验
4.1 数据集
实验在两个数据集上进行(表1),一是Tan等[24]收集的酒店评论数据,该数据集由10 000个文件组成,每个文件存储一条酒店评论信息,其中7 000条为正面评论,3 000条为负面评论。该数据集按照不同规模被划分为4个数据集,分别是htl-2000、htl-4000、htl-6000和htl-10000。另一个是中文信息学会举办的自然语言处理会议公布的深度学习情感分类评测数据集(NLPCC2014 task2),包含训练数据集和测试数据集,其中训练数据集含有1万条中文产品评论数据;测试数据集包含2 500条中文产品评论数据,1250条正面评论,1250条负面评论。

表1 实验数据集Tab. 1 Datasets used in the experiment
4.2 评价标准
本文使用正确率(Accuracy)对实验结果进行评价,其计算公式为:
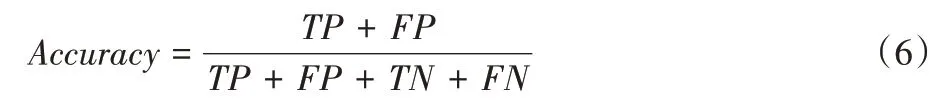
其中:TP(True Positive)代表真阳性,TN(True Negative)代表真阴性,FP(False Positive)代表假阳性,FN(False Negative)代表假阴性。
4.3 预训练
在进行情感分类之前,需要对ELMo 进行预训练,以获得上下文相关的词向量信息。预训练在百科类问答数据集上进行,该数据集通过爬取社区问答数据获得,含有150 万个预先过滤的问题和答案,数据大小为1.48 GB。
原始数据为json 格式,预处理首先抽取每一条数据的content 部分,去除内容中的空行、特殊符号,过滤词语少于5的句子。然后,利用北京大学提供的通用切词工具pkuseg,对句子进行切词。处理后得到9 205 479 个句子,每个句子占一行,句子词语之间用空格分隔。样例如图6。

图6 预处理后的训练语料样例Fig. 6 Sample of preprocessed training corpus
ELMo 的训练分为二步:第一步采用Word2vec 工具的skip-gram 模型,学习字符预训练语料,获取字符向量,实验中字符向量的维度设为128,上下文窗口大小设为5;第二步训练ELMo,利用上述学习到的字符向量初始化char-CNN 的嵌入层,然后学习分词语料,获得模型参数,实验中char-CNN 的输出维数为256,biLM 模型层数设为2,隐状态的维数为512,展开深度设为30。
实验对比了采用预训练字符向量初始化和采用随机向量初始化两种方法,ELMo 的训练误差曲线如图7 所示。从图中可以看出,对于采用预训练向量初始化的ELMo,其训练收敛速度更快,训练精度更高。

图7 采用不同初始化方法的ELMo训练误差曲线Fig. 7 Training error curves of ELMo with different initialization strategies
4.4 多尺度卷积神经网络进行情感分类
利用上述方法对酒店评论数据进行预处理,将处理后的句子输入改进ELMo,获取对应的ELMo 特征向量,最后将特征输入MSCNN模型,进行分类。
为了获得MSCNN 的最优卷积尺度,分别在酒店评论和NLPCC2014 task2 两个数据集上进行测试,实验结果如图8所示。

图8 不同卷积尺度下MSCNN的分类结果Fig. 8 Classification results of MSCNN on different convolution scales
图中卷积尺度1-n表示同时使用卷积尺度为1,2,…,n的卷积核。卷积尺度为卷积核的宽度,代表卷积核所覆盖的词语数目。卷积核的实际大小为512×卷积核的宽度,其中512为ELMo 的特征向量维数。卷积核的尺度越大,对应卷积核的数目也应该越多。实验中,对于尺度为1 的卷积核,卷积核数目设为64;尺度为2、3 的卷积核,数目设为128;尺度为4、5的卷积核,数目设为256。
从图8 可以看出,分类正确率随着卷积尺度的增大而逐渐增加,这说明使用多尺度特征确实有助于提高分类精度。当选用卷积尺度为1-4 时,效果最好。当选用卷积尺度为1-5时,效果不如1-4,这有可能是由于汉语中距离超过4 的词语之间的语义联系较弱的缘故。
最终确定最优卷积尺度为1-4,在该尺度下对酒店评论数据集进行实验,效果如表2所示。
从表中可以看出,对不同规模的数据集,本文方法的分类正确率始终维持在93%以上,即使是针对不平衡数据集htl-10000,正确率也达到了93.3%,和平衡数据集相比,几乎没有下降,这说明本文方法有很好的鲁棒性,并且能够处理不均衡样本集。

表2 不同酒店评论数据集上的实验结果Tab. 2 Experimental results on different hotel review datasets
论文同样对比了其他方法,如支持向量机(SVM)、朴素贝叶 斯(Naïve Bayes,NB)、融 合 字、词 的 双 向LSTM 模 型(Character,Word and Part-of-Speech Attention model based on Bi-LSTM,CWPAT-Bi-LSTM)和卷积神经网络(CNN),结果如表3所示。

表3 不同方法在酒店评论数据集上的正确率指标比较Tab. 3 Classification accuracy of different methods on hotel review datasets
从表3 中可以看出,本文方法明显优于SVM 和NB 方法,与SVM 方法相比正确率平均提升12.56个百分点,与NB方法相比正确率平均提升24.93 个百分点。这说明由于神经网络方法具有特征自动抽取的能力,能够获得更有效的语义特征,从而得到了更高的分类正确率。对比神经网络方法,本文方法相对卷积神经网络模型,正确率平均提升了3.56 个百分点。即使对比当前最好方法,基于注意力机制的循环神经网络模型,正确率也平均提升了1.08 个百分点。主要原因是本文方法实际上是循环神经网络模型和卷积神经网络的混合模型,在词向量生成阶段,使用双向LSTM 构造上下文相关词向量,在分类器阶段,利用多尺度卷积进行词向量的融合,进一步抽取可用的语义特征。该混合模型综合了两种模型的优势,所以效果更好。
为进一步验证本文模型的性能,实验还在NLPCC2014 task2数据集进行了测试,其结果如表4所示。

表4 不同方法在NLPCC2014_task2数据集上的实验结果Tab. 4 Experimental results of different methods on dataset NLPCC2014_task2
从表中可以看出,与经典的循环神经网络模型LSTM 和门控循环单元网络(Gated Recurrent Unit,GRU)相比,本文方法的正确率提高了11.68个百分点和4.4个百分点,与卷积神经网络相比,正确率提高了4.96 个百分点。该结果和酒店评论数据集上的结果是一致的,说明本文模型迁移到新数据集上同样有效。与LSTM 和CNN 的混合方法相比,正确率也提高了2.16个百分点。虽然本文模型从表面上看也是LSTM 和CNN 的混合模型,但本文的LSTM 是蕴含在ELMo 中的,而ELMo采用的是预训练的方式,是从大语料而非任务语料中训练语义向量,得到的词语表征其泛化程度更高,这是基于任务的训练模型无法比拟的。
5 结语
不同于传统的将词嵌入向量作为神经网络的输入,本文提出将ELMo 获得的词语向量作为网络输入,该向量融合了词语本身和词语所在上下文的语义特征,可以很好地表示多义词的不同语义。此外,针对中文语料,本文提出采用预训练的汉字字符向量初始化ELMo 的嵌入层,可加快ELMo 的训练,提高训练精度。最后,分类器采用多尺度的卷积神经网络(MSCNN),该分类器能够融合不同尺度的短语特征,有利于后续分类。实验结果表明,本文提出的方法能有效提高情感分类的正确率。
最近几年,基于多头自注意力的网络,如Transformer模型在自然语言处理领域崭露头角,Transformer能够有侧重地进行语义向量的融合,其本质更像是针对自然语言的卷积操作,下一步也尝试将ELMo 和Transformer 模型混合,分别利用ELMo 和Transformer各自的优势,构造更适用于情感分析的模型。
在句子语法层面,中、英文是有显著的区别的。例如,中文句子往往是由很多小的短句构成(大量逗号分隔的短句),而英文一般只会有1~2 个从句,而且从句大都不以子句的形式存在(中间没有逗号分隔)。因此,如何改进ELMo 结构,使其更适用于中文语法结构,也是下一步的研究方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
马克思主义哲学研究(2020年1期)2020-11-26
太空探索(2016年5期)2016-07-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
